






 本文档详细记录了使用Hadoop2.7.1和JDK17在Linux环境中搭建Hadoop集群的过程,包括JDK的安装、Hadoop的解压配置、环境变量设置、防火墙和SELinux的关闭、集群配置、SSH免密设置等。过程中遇到了JDK版本不兼容问题,最终通过降级到JDK8解决了问题。
本文档详细记录了使用Hadoop2.7.1和JDK17在Linux环境中搭建Hadoop集群的过程,包括JDK的安装、Hadoop的解压配置、环境变量设置、防火墙和SELinux的关闭、集群配置、SSH免密设置等。过程中遇到了JDK版本不兼容问题,最终通过降级到JDK8解决了问题。
前提:
hadoop-2.7.1.tar.gz
jdk-17_linux-x64_bin.rpm
用户名:huser
(建议官网查看hadoop版本搭配的jdk,该jdk在最后导致搭建出现问题,替换jdk-8u311-linux-x64.rpm后恢复正常)
卸载jdk:
rpm -qa | grep jdk
yum -y remove jdkxxxxxxxxxxxxxxxxxx
jdk安装后产生的目录:
export JAVA_HOME=/usr/java/latest
1.安装jdk:
sudo rpm -ivh jdk-17_linux-x64_bin.rpm
查看版本:java -version
2.解压hadoop:
sudo tar -zxvf hadoop-2.7.1.tar.gz -C /opt/
(opt是root权限,要改为huser权限)
ls -l 查看文件夹的归属权限
改权限:
sudo chown -R huser:huser /opt/hadoop-2.7.1
ls -l
3.关闭防火墙:
sudo systemctl stop firewalld.service
sudo systemctl disable firewalld.service
4.关闭selinux:
sudo vi /etc/selinux/config
SELINUX=enforcing改为SELINUX=disabled
5.添加hadoop环境变量:
sudo vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/opt/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
6.创建HDFS的NN(namenode)和DN(datenode)工作主目录
sudo mkdir /var/big_data
sudo chown huser:huser /var/big_data
/sudo chown -R 和sudo chown (-R)看这个文件夹下有没有文件
7.hadoop文件配置修改
为hadoop提供java解释器路径信息,主要目的是解决远程访问hadoop时JAVA_HOME无法继承问题
cd /opt/hadoop-2.7.1/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
改为:
export JAVA_HOME=/usr/java/default
为yarn任务、资源管理器提供java运行环境:
vi yarn-env.sh
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME= ${JAVA_HOME}
改为:
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/user/java/default
vi core-site.xml
<configuration>
</configuration>
改为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/big_data</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
</configuration>
改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node03:50090</value>
</property>
</configuration>
配置mapreduce任务调度策略:

cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
</configuration>
改为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn资源管理角色的信息:
vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
</configuration>
改为:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
</configuration>
配置datanode节点信息:
vi slaves
localhost
改为:
node01
node02
node03
准备主机名解析文件,为后面克隆机做好准备(若不做,克隆后为每台机器重新添加即可)
sudo vi /etc/hosts
删掉原先两行内容,添加:
192.168.149.80 node01
192.168.149.81 node02
192.168.149.82 node03
然后:
sudo reboot
然后关机克隆。
关机状态下:
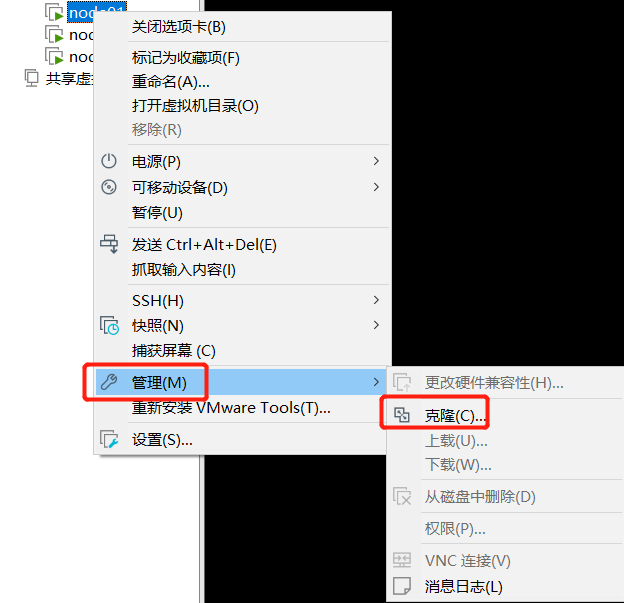
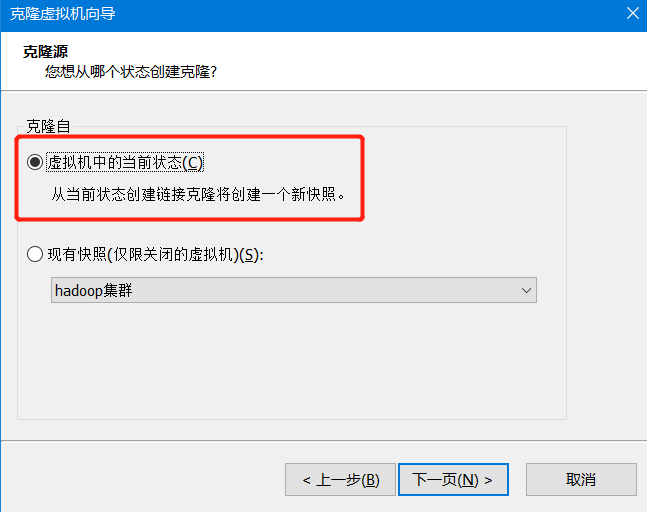
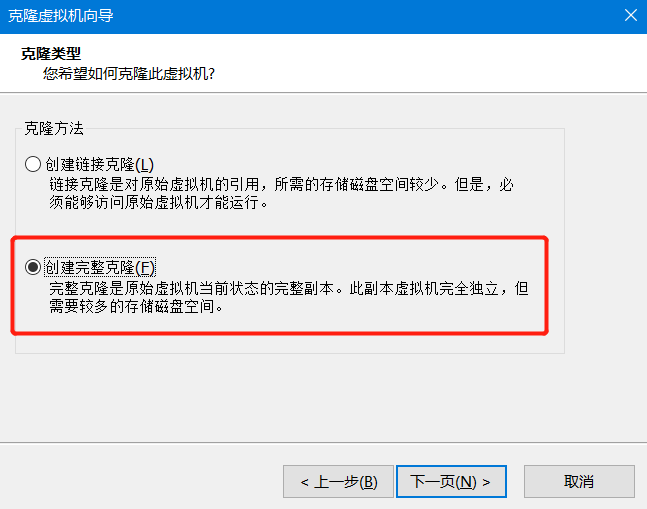
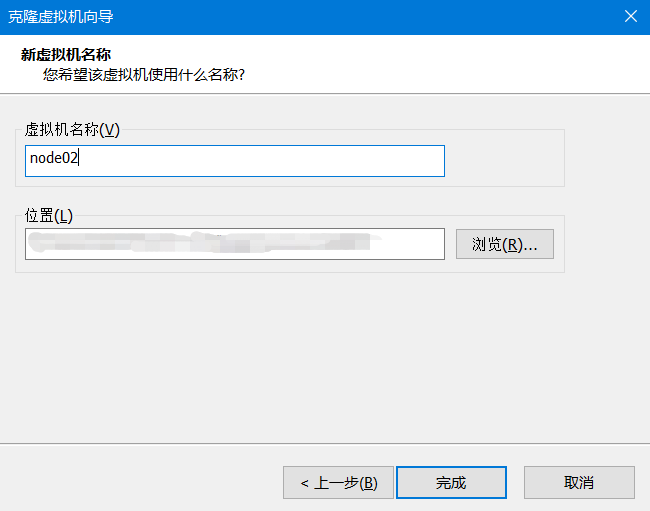
因为是完整克隆,所以主机名相同,ip地址相同。
克隆后,修改node02,node03的ip地址:
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR="192.168.149.80"
改为:
node02:IPADDR="192.168.149.81"
node03:IPADDR="192.168.149.82"
修改node02,node03的主机名:
sudo vi /etc/hostname
改为:
node02:node02
node03:node03
克隆完成。
集群的ssh免密:
xhsell的查看–>撰写栏
进行多会话窗口输入执行命令
产生自己的公钥(.ssh文件):
ssh-keygen -t rsa
将公钥拷贝给其他机器:
ssh-copy-id node01
ssh-copy-id node02
ssh-copy-id node03
免密完成。
node01进行格式化hdfs:
hdfs namenode -format
查看格式化情况:
ls /var/big_data/dfs/name/current/
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
开启集群:
start-dfs.sh
jps
/*在这儿不启动也行
start-yarn.sh
*/
(开启集群后)浏览器网址查看下情况:
192.168.149.80:50070
(开启集群后)创建目录:
hdfs dfs -mkdir /t01
创建目录遇到问题:web页面提示:
Failed to retrieve data from /webhdfs/v1/?op=LISTSTATUS: Cannot invoke “com.sun.jersey.spi.container.WebApplication.isTracingEnabled()” because “wa” is null
-----------------jdk版本问题导致。


















 4350
4350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











