







 本文详细介绍了如何使用VirtualBox和Ubuntu搭建Hadoop集群的过程,包括环境配置、网络设置、静态IP分配、SSH免密码登录、Hadoop安装与配置、环境变量设定等关键步骤。
本文详细介绍了如何使用VirtualBox和Ubuntu搭建Hadoop集群的过程,包括环境配置、网络设置、静态IP分配、SSH免密码登录、Hadoop安装与配置、环境变量设定等关键步骤。
VirtualBox+Ubuntu搭建Hadoop集群(一)
- 所需环境:
- ubuntu
- Oracle VM VirtualBox
- jdk: jdk-8u221-linux-x64.tar.gz
- hadoop:hadoop-2.9.2.tar.gz
- Oracle VM VirtualBox 配置网络:需要配置两个网卡,Host-only和Network,比骄坑
管理——全局——网络:添加NetWork
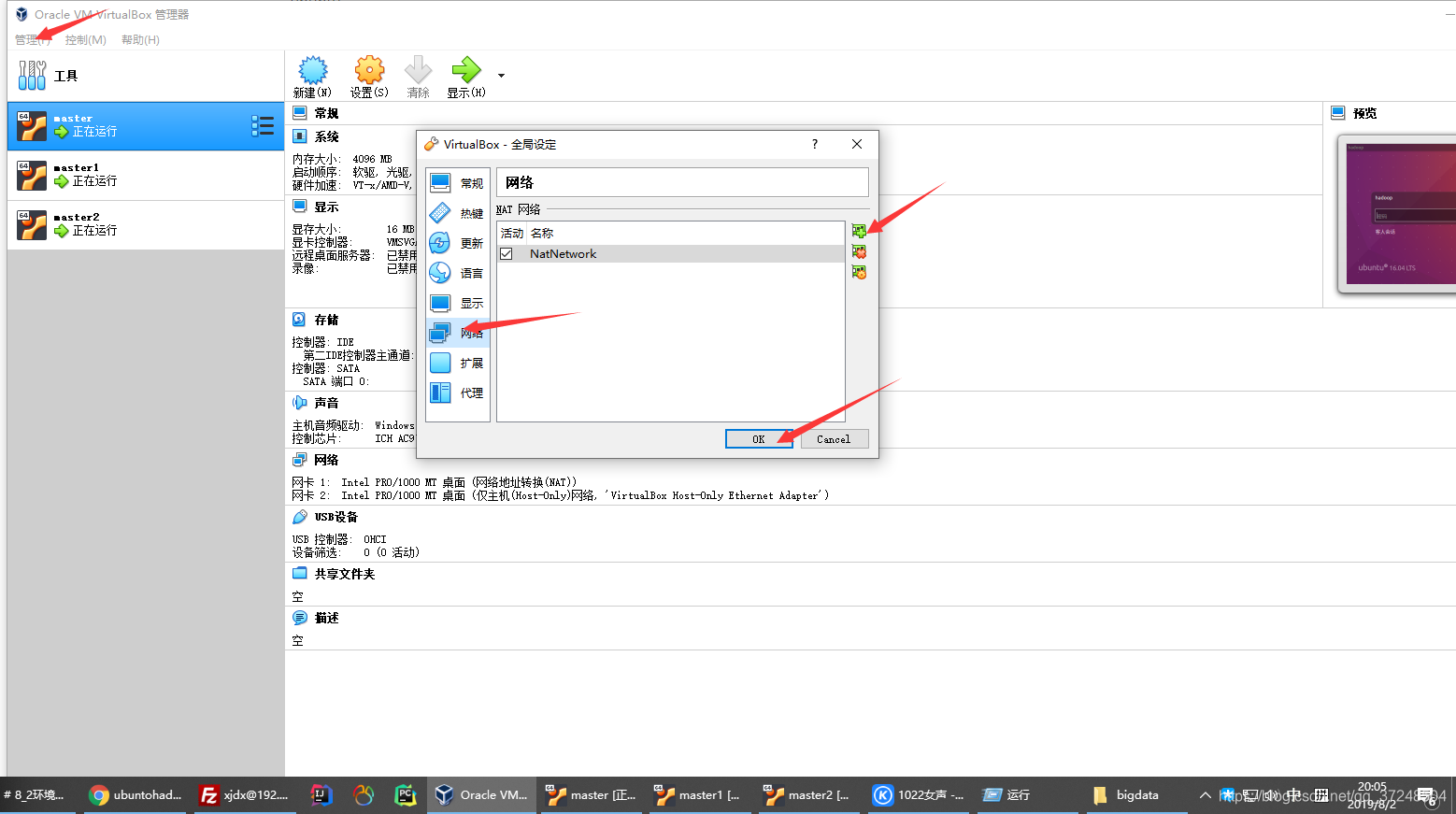
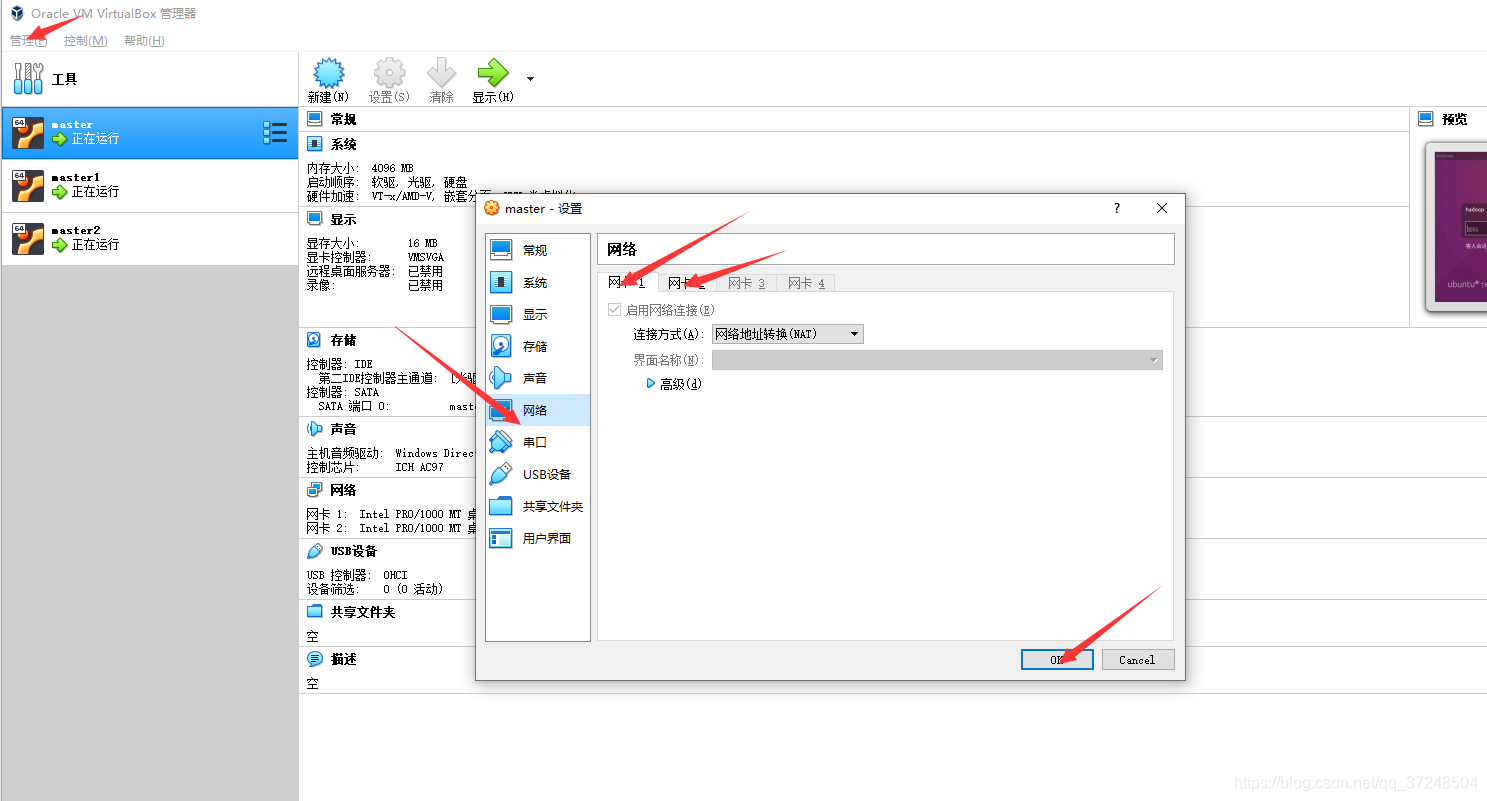
master——右键设置——网络:能看到两个网卡
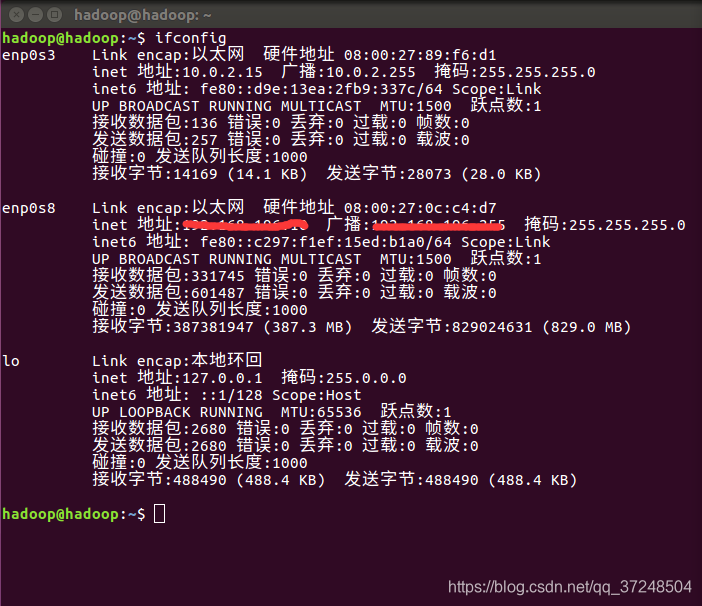
- Ubuntu 静态Ip设置:10.0.2.15为动态获取的Ip,下面的ip为静态显示的,只需要配置下面的静态ip
点击编辑链接,编辑有线连接,将ip设置为静态,另一个eth0动态分配就可以,如下:
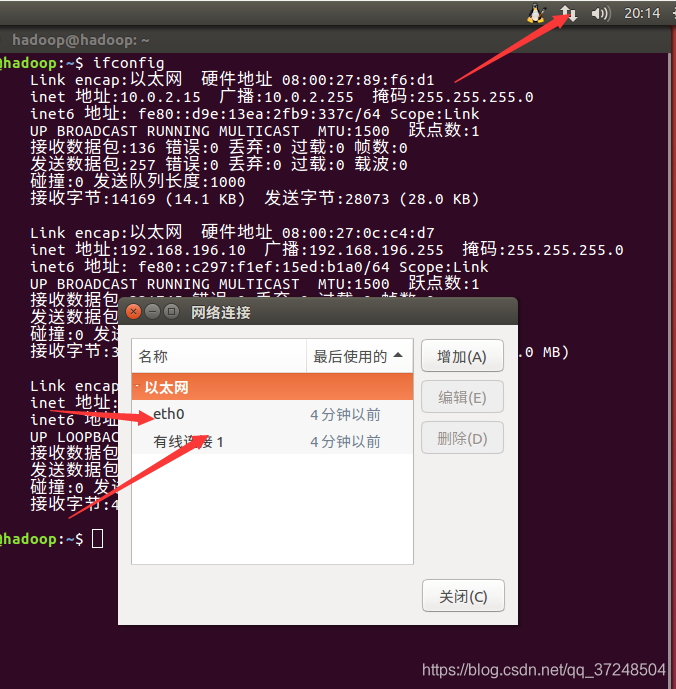
如下
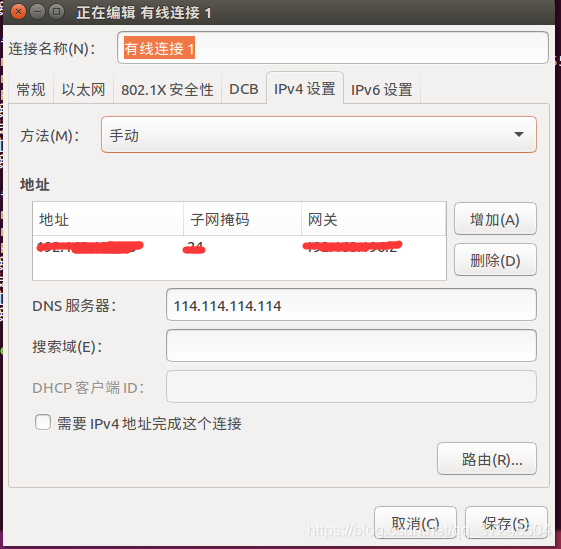
- 复制克隆另外两个节点机master1,master2,配置ip和第一台的方法一样,只是静态ip不要重复 ,例如可设置为:
193.192.168.xx.2 hadoop
192.168.xx.3 hadoop1
192.168.xx.4 hadoop2
-
要确保物理机和虚拟能互相ping通:
-
编辑Windows host:c:\Windows\System32\drivers\etc,加上
193.192.168.xx.2 hadoop
192.168.xx.3 hadoop1
192.168.xx.4 hadoop2 -
vi /etc/hosts 加上如上的信息
-
-
java环境配置
使用Filezilla上传文件jdk-8u211-linux-x64.tar.gz到服务器。然后执行:
tar -zxvf jdk-8u211-linux-x64.tar.gz
mv jdk1.8.0_211/ /usr/local/
#添加如下到~/.bash_profile
export JAVA_HOME=/usr/local/jdk1.8.0_211/
export PATH=$PATH:$JAVA_HOME/bin
- 免密码登录,就是hadoop可以不用输入密码直接登录hadoop1和hadoop2,登录hadoop
#安装ssh工具
ssh-keygen -b 4096
- 拷贝生成的公钥到其他机器上
ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@hadoop
ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@hadoop1
ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@hadoop2
VirtualBox+Ubuntu搭建Hadoop集群(二)
- 接着上篇的步骤,安装hadoop,上传hadoop-2.9.2.tar.gz到hadoop
tar -zxvf hadoop-2.9.2.tar.gz
mv hadoop-2.9.2 /usr/local
- 设定环境变量
编辑文件 ~/.bash_profile
export HADOOP_HOME=/usr/local/hadoop-2.9.2/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bash_profile
查看hadoop环境:hadoop -version
- hadoop的配置文件:cd /usr/local/hadoop文件夹
- 配置 slave
cd /usr/local/hadoop/etc/hadoop
vi slaves
加上
hadoop
hadoop1
hadoop2
- 配置 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>
- 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
- 文件mapred-site.xml,这个文件不存在,首先需要从模板中复制一份:
cp mapred-site.xml.template mapred-site.xml
然后配置修改如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 配置yarn-site.xml:
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 配置hadoop-env.sh
将行
export JAVA_HOME=${JAVA_HOME}
更改为
export JAVA_HOME=/usr/local/jdk1.8.0_211/
配置好后,将 hadoop 上的 Hadoop 文件复制到各个节点上(虽然直接采用 scp 复制也可以正确运行,但会有所不同,如符号链接 scp 过去后就有点不一样了。所以先打包再复制比较稳妥)。
cd /usr/local
sudo tar -zcf ./hadoop.tar.gz ./hadoop
scp ./hadoop.tar.gz hadoop1:/home/hadoop
scp ./hadoop.tar.gz hadoop2:/home/hadoop
在hadoop1上执行:
sudo tar -zxf ~/hadoop.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop /usr/local/hadoop
mdkir -p ~/data/dn
mkdir -p ~/data/nn
在hadoop2上执行:
sudo tar -zxf ~/hadoop.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop /usr/local/hadoop
mdkir -p ~/data/dn
mkdir -p ~/data/nn
-
格式化HDFS
`hdfs namenode -``format` -
启动HDFS
node-master上运行
start-dfs.sh -
使用jps检查各个节点
node-master -
运行Yarn
node-master 运行 start-yarn.sh
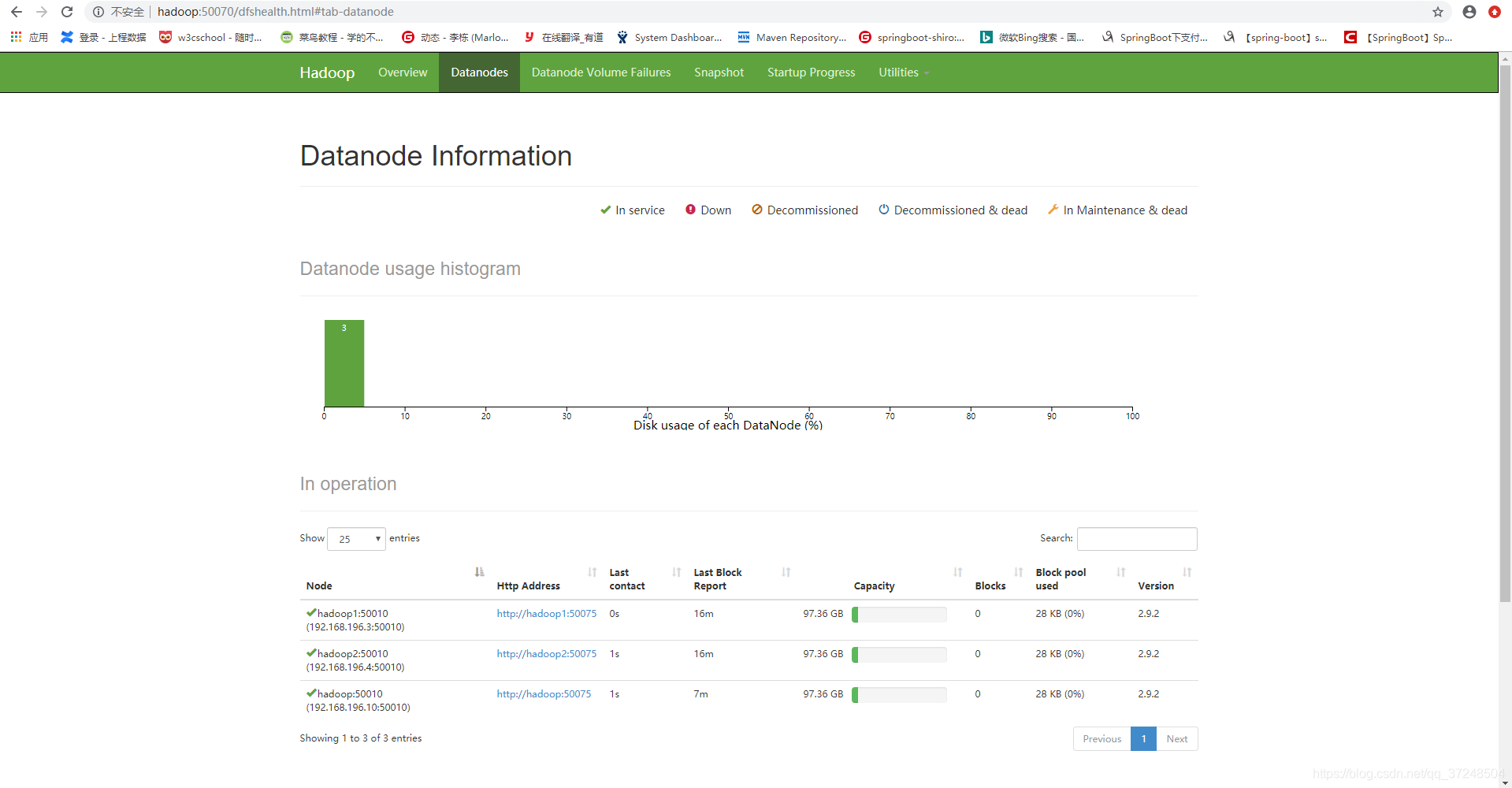
访问hadoop:50070如下:
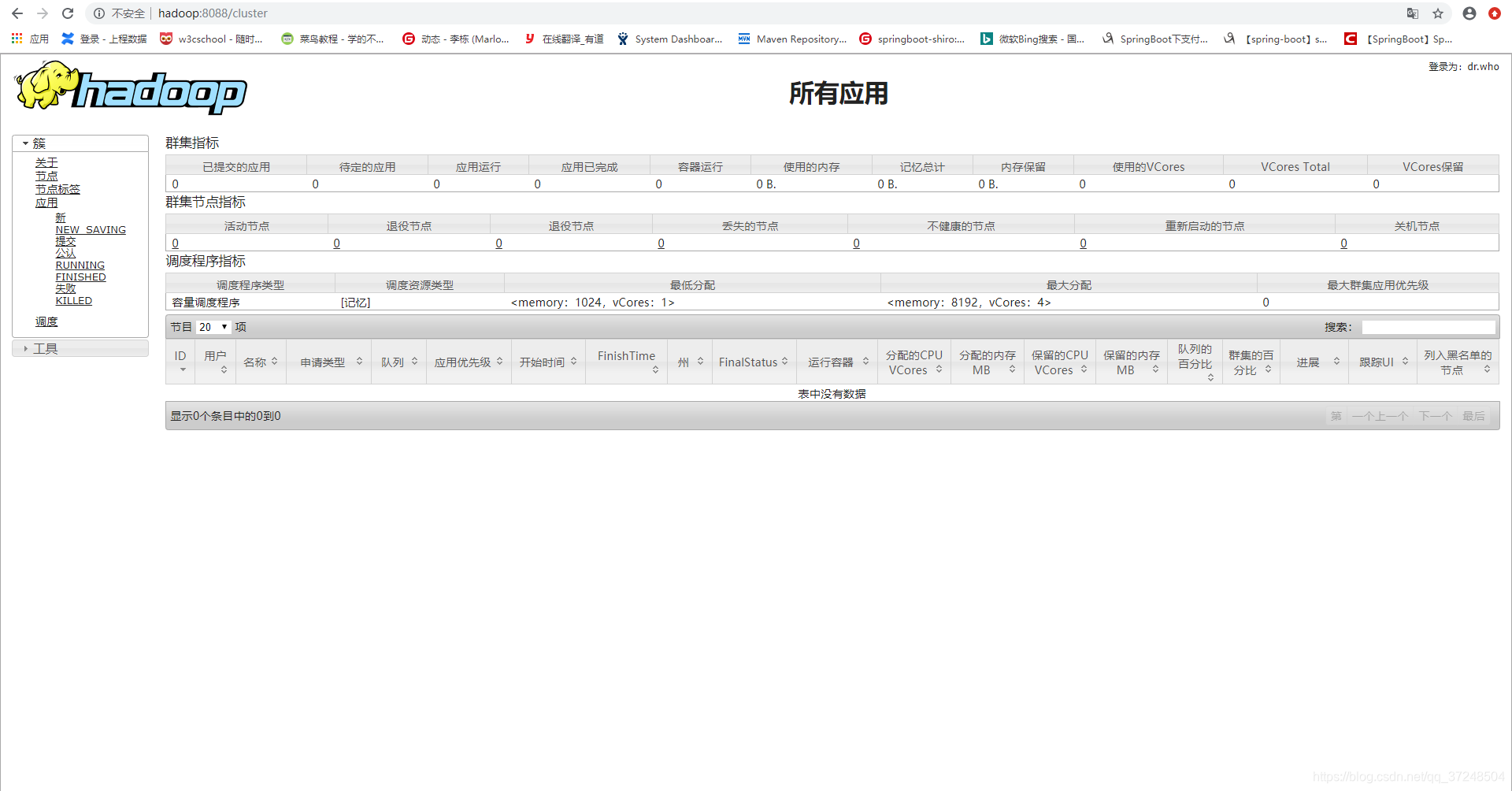
访问:hadoop:8088/cluster


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











