







深入理解JavaIO流
文章目录
背景
导入导出、后端文件解析等功能会经常使用Java流,熟练掌握JavaIo流对日常开发很有帮助。
引言
- 流(
Stream)是一个抽象的概念,是指一连串的数据(字符或字节),以先进先出的方式发送信息的通道。 - 数据的传输,可以看做是一种数据的流动,按照流动的方向,以内存为基准,分为输入
input和输出output,即流向内存是输入流,流出内存的输出流。
Java IO 流的重要性
- 数据持久化:把程序运行过程中的重要数据写入文件。
- 网络通信:通过
IO流来实现数据的发送和接收,进而实现客户端与服务器之间的通信。 - 标准输入输出:利用
System.in(标准输入流)读取用户从控制台输入的数据,使用System.out(标准输出流)向控制台输出信息
Java IO流核心概念
输入输出流本质
- 输入:把硬盘中的数据加载到内存
- 输出:把内存中的数据写入到磁盘

JavaIO流分类
以流的处理单位为维度主要有字节和字符两种方式
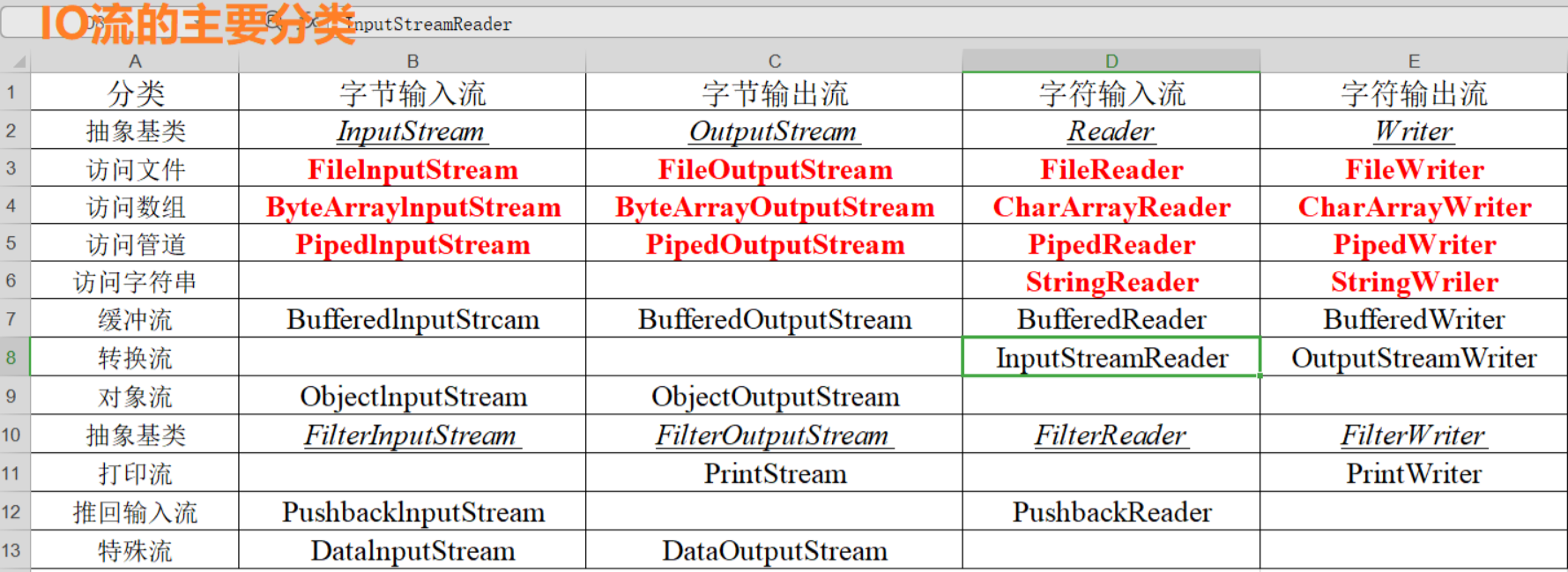
字节流
- 处理二进制文件:像图片、音频、视频等文件都是二进制文件,处理这些文件时必须使用字节流,因为字节流能精确处理每一个字节,不会对数据进行任何转换。
- 网络通信:网络传输的数据本质上是二进制的,所以在进行网络编程时,字节流是不可或缺的
- 底层数据处理:当需要对底层数据进行操作,如文件系统的读写、设备驱动的交互等,字节流可以直接操作字节数据,更符合底层操作的需求。
字符流
- 处理文本文件:对于文本文件(如
.txt、.java、.xml等),使用字符流更为方便,因为字符流会自动处理字符编码和解码,避免了字节流处理文本时可能出现的乱码问题。 - 文本数据的处理和转换:在进行文本数据的读取、写入、替换、拼接等操作时,字符流可以直接处理字符,代码实现更加简洁易懂。
- 用户输入输出:当程序需要与用户进行文本交互时,如从控制台读取用户输入或向控制台输出文本,使用字符流可以方便地处理字符数据。
处理二进制数据时应优先考虑字节流,而处理文本数据时使用字符流会更加合适。
关键设计模式
装饰器模式
- 缓冲流
BufferedInputStream包装普通输入FileInputStream
// 创建基础的 FileInputStream
InputStream fis = new FileInputStream("test.txt");
// 使用 BufferedInputStream 装饰 FileInputStream
InputStream bis = new BufferedInputStream(fis);
适配器模式
InputStreamReader和OutputStreamWriter是适配器类,InputStreamReader把字节输入流转换为字符输入流,OutputStreamWriter把字节输出流转换为字符输出流。
// 创建字节输入流
InputStream fis = new FileInputStream("test.txt");
// 使用 InputStreamReader 将字节输入流转换为字符输入流
InputStreamReader isr = new InputStreamReader(fis);
实战技巧与性能优化
避免加载全部流对象
- 读取文件、流的时候流式读取,避免所有的加载到内存中
资源释放规范
- 使用 try-resource 优雅释放资源
// 传统写法
public static void main(String[] args) {
InputStream inputStream = null;
try {
inputStream = new FileInputStream("test.txt");
int data;
while ((data = inputStream.read()) != -1) {
System.out.print((char) data);
}
} catch (IOException e) {
logger.error(e);
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
try-with-resources语句大大简化了资源管理的代码,提高了代码的可读性和可维护性,同时减少了资源泄漏的风险。
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream("source.txt");
OutputStream outputStream = new FileOutputStream("destination.txt")) {
int data;
while ((data = inputStream.read()) != -1) {
outputStream.write(data);
}
} catch (IOException e) {
e.printStackTrace();
}
}
缓冲区流的使用
- 缓冲区是提高
I/O操作效率的重要手段,它能减少与外部设备(如磁盘、网络)的交互次数,从而显著提升性能。 - 下面截图中显示设置缓冲区大小为
8k
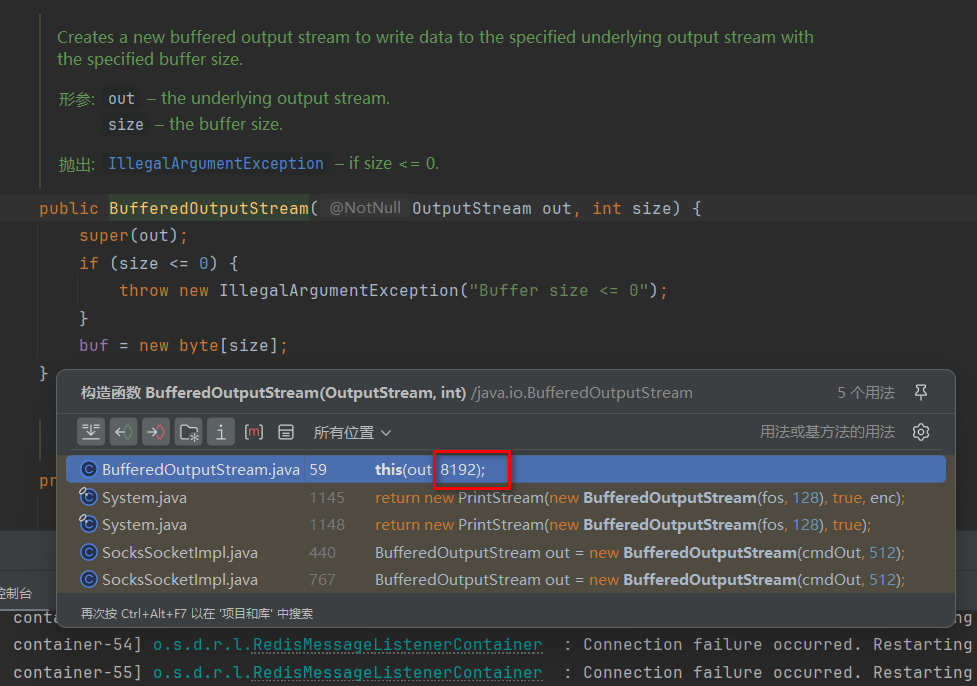
缓冲区大小设置
BufferedInputStream、BufferedOutputStream、BufferedReader 和 BufferedWriter 都提供了可以指定缓冲区大小的构造函数。默认情况下,缓冲区大小是合适的,可以根据实际需求调整缓冲区大小。
注意事项
- 及时刷新缓冲区:在使用
BufferedOutputStream或BufferedWriter时,为确保数据及时写入目标,在完成写入操作后,要调用flush()方法刷新缓冲区。在try-with-resources语句中,资源关闭时也会自动刷新缓冲区。 - 避免不必要的嵌套:虽然可以多次嵌套缓冲流,但这可能会增加内存开销,在性能提升不明显时,应避免不必要的嵌套。
缓冲流使用测试
- 普通方式读写文件
1分钟30m左右
@Test
public void test1() throws FileNotFoundException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
FileInputStream fis = new FileInputStream("C:\\Users\\Administrator\\Desktop\\tempfold\\1.exe");
FileOutputStream fos = new FileOutputStream("C:\\Users\\Administrator\\Desktop\\tempfold\\2.exe")
) {
// 读写数据
int b;
while ((b = fis.read()) != -1) {
fos.write(b);
}
} catch (IOException e) {
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("普通流复制时间:" + (end - start) + " 毫秒");
}
- 使用缓冲流复制时间 3305 毫秒
@Test
public void test2() throws FileNotFoundException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("C:\\Users\\Administrator\\Desktop\\tempfold\\1.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("C:\\Users\\Administrator\\Desktop\\tempfold\\3.exe"));
) {
// 读写数据
int b;
while ((b = bis.read()) != -1) {
bos.write(b);
}
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流复制时间:" + (end - start) + " 毫秒");
}
大文件处理策略
逐行读取
- 针对文本文件,逐行读取是常见且有效的方法。例如:
BufferedReader逐行读取文件内容
分块读取
- 对于二进制文件或者需要处理大文件中的特定部分时,可采用分块读取的方法。实现前端分片下载文件。
多线程处理
- 对于特别大的文件,可采用多线程处理来提高处理速度。将文件分成多个块,每个线程负责处理一个块。
编码问题避坑
明确指定字符编码
- 使用
InputStreamReader和OutputStreamWriter,并明确指定字符编码。 - 避免直接使用
FileReader和FileWriter,因为它们无法指定编码。
// 明确指定 UTF-8 编码
try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("input.txt"), StandardCharsets.UTF_8)))
处理字节流和字符流的转换
- 使用
InputStreamReader和OutputStreamWriter进行字节流到字符流的转换,并明确指定编码。 - 确保读取和写入时使用相同的编码。
// 读取文件时指定相同的编码
try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("output.txt"), StandardCharsets.UTF_8)))
处理网络流的编码
在网络编程中,客户端和服务器之间的数据交换需要明确指定编码,否则可能导致乱码。
- 在发送和接收数据时,明确指定编码。
- 使用
InputStreamReader和OutputStreamWriter包装网络流。
try (Socket socket = new Socket("localhost", 8080);
OutputStreamWriter osw = new OutputStreamWriter(socket.getOutputStream(), StandardCharsets.UTF_8);
读取文件时候始终主动设置字符编码
主动flush()
flush()方法是用于强制将缓冲区的数据写入目标(如文件、网络等)的操作。对于缓冲流(如BufferedOutputStream、BufferedWriter),数据通常会在缓冲区满时自动写入目标,可以通过调用flush()方法手动触发写入。
优点
- 确保数据及时写入
- 避免数据丢失
- 在程序崩溃或异常终止的情况下,未刷新到目标的数据可能会丢失。
- 主动调用
flush()可以减少数据丢失的风险。
- 提高交互性:对于需要实时交互的应用(如聊天程序)非常重要
缺点
- 频繁调用
flush()会增加 I/O 操作的次数,导致性能下降 - 增加代码复杂性,如果出现错误需要额外的处理异常。
- 不必要的数据写入:频繁调用
flush()可能会导致不必要的数据写入,尤其是在数据量较小或写入频率较高的情况下。
| 场景 | 是否主动调用 flush() | 原因 |
|---|---|---|
| 需要实时传输数据(如网络通信) | 是 | 确保数据及时发送到目标。 |
| 需要避免数据丢失(如日志记录) | 是 | 确保数据在程序崩溃前写入目标。 |
| 性能敏感的场景 | 否 | 频繁调用 flush() 会增加 I/O 操作次数,降低性能。 |
使用 try-with-resources | 否 | 流关闭时会自动调用 flush(),无需手动调用。 |


















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











