



新建Maven项目
打开 –> File –> New –> Project
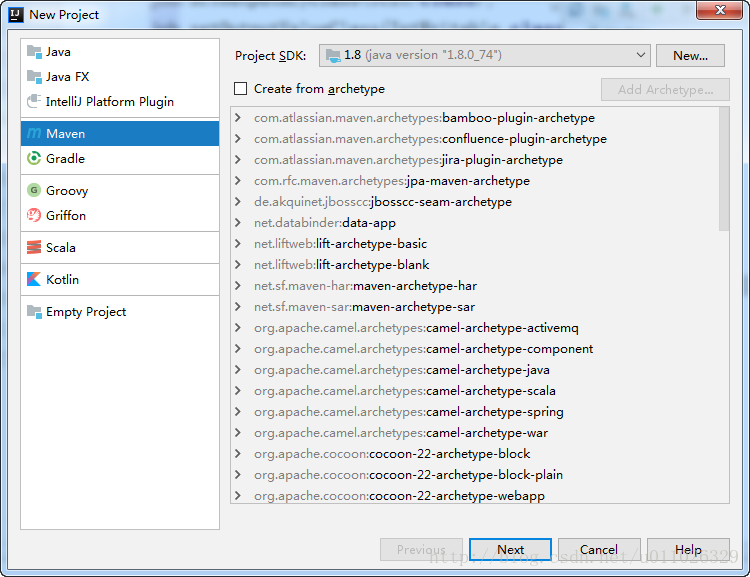
点击Next
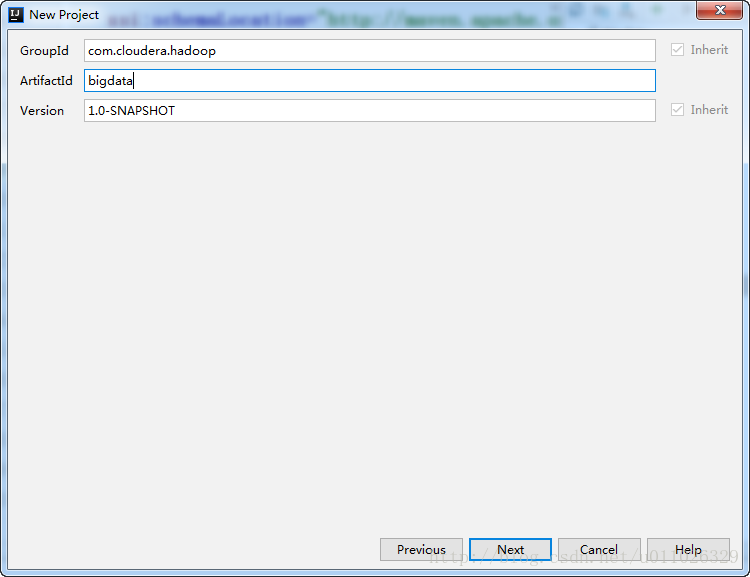
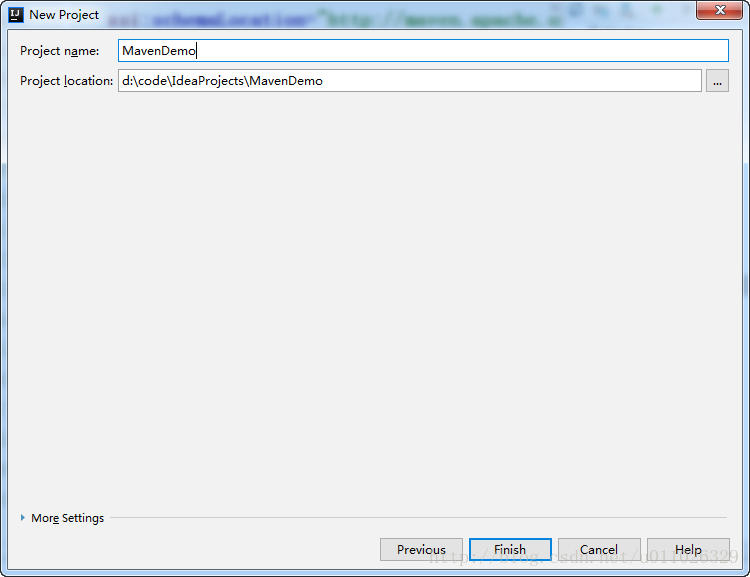
点击Finish
编写MapReduce程序
1.编写 Maven 依赖:
依照Cloudera官方文档进行配置:
Using the CDH 5 Maven Repository
Maven Artifacts for CDH 5.11.x Releases
pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.cloudera.hadoop</groupId>
<artifactId>bigdata</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<cdh.version>2.6.0-cdh5.11.1</cdh.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${cdh.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>2.6.0-mr1-cdh5.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${cdh.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.11.1</version>
</dependency>
</dependencies>
</project>2.编写程序
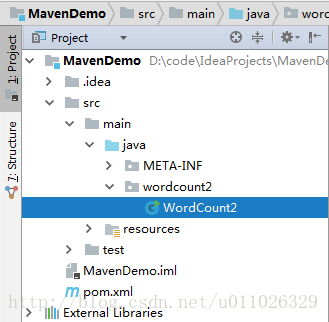
(1)WordCount2.class
package wordcount2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount2 {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable val : values){
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count2");
job.setJarByClass(WordCount2.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
boolean flag = job.waitForCompletion(true);
System.out.println("Succeed! " + flag);
System.exit(flag ? 0 : 1);
System.out.println();
}
}
- (2)配置运行程序的参数:
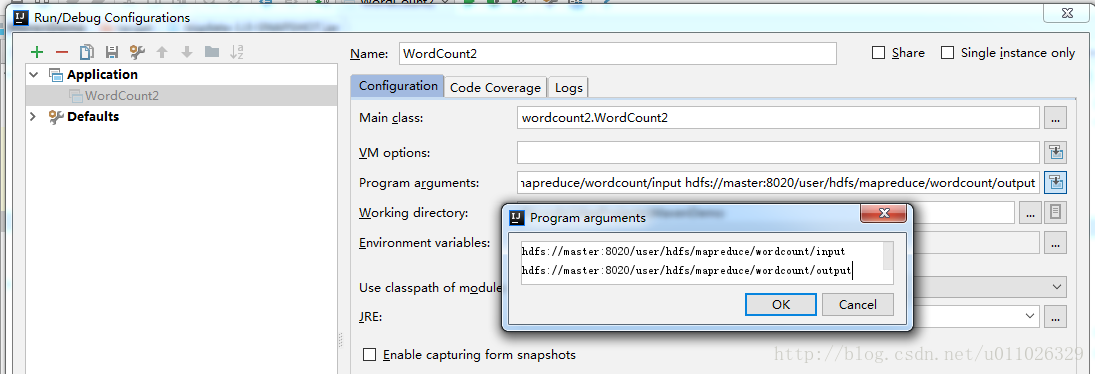
(3)hadoop配置文件
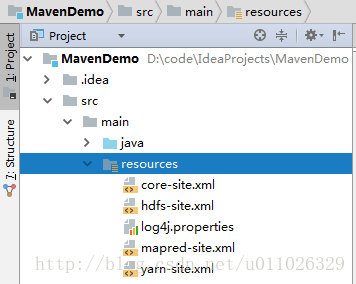
将hadoop 配置文件放到 src/main/resources文件夹下
3. mvn compile & mvn package
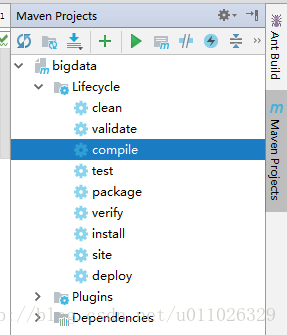
点击右侧 Maven Projects –> compile –> package
或者在终端运行 mvn compile 和 mvn package
则生成jar文件。
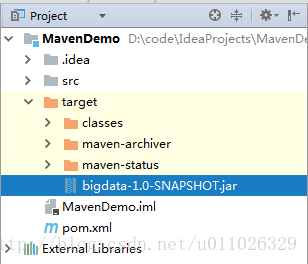
上传jar文件并运行
将jar文件重新命名为wordcount2.jar,并上传到CDH5 集群中。
在集群上执行:
hadoop jar wordcount2.jar wordcount2.WordCount2 /user/hdfs/mapreduce/wordcount/input /user/hdfs/mapreduce/wordcount/output- 1
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.youkuaiyun.com/u011026329/article/details/79173732

















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









