






 本文详细解读了面向对象设计的四个关键原则:单一职责原则(SRP)、开放封闭原则(OCR)、里氏替换原则(LSP)和接口隔离原则(ISP),并通过实例演示如何在实践中应用这些原则,以提升代码的可维护性和扩展性。
本文详细解读了面向对象设计的四个关键原则:单一职责原则(SRP)、开放封闭原则(OCR)、里氏替换原则(LSP)和接口隔离原则(ISP),并通过实例演示如何在实践中应用这些原则,以提升代码的可维护性和扩展性。
一、单一职责原则(SRP,Single Resposlillty Principle)
就一个类而言,应该仅有一个引起它变化的原因。
单一职责,通常意味着单一的功能,因此不要为类实现过多的功能点,以保证实体只有一个引起它变化的原因。
实例:
//违反SRP原则的代码
//modem接口明显有两个职责:连接管理和数据通信
class modem
{
public void dial(string pno);
public void hangup();
public void send(char c);
public void recv();
}
//按SRP原则修改如下
class DataChannel
{
public void send(char c);
public void recv();
}
class Connection
{
public void dial(string pno);
public void hangup();
}
class modem
{
//构造
public
modem()
{
datachannel=new DataChannel();
con =new Connection();
};
//字段
private:
DataChannel datachannel;
Connection con;
Public:
void dial(string pno)
{
con.dial(pno);
};
void hangup()
{
con.hangup();
};
void send(char c)
{
datachannel.send(c);
};
void recv()
{
datachannel.recv();
};
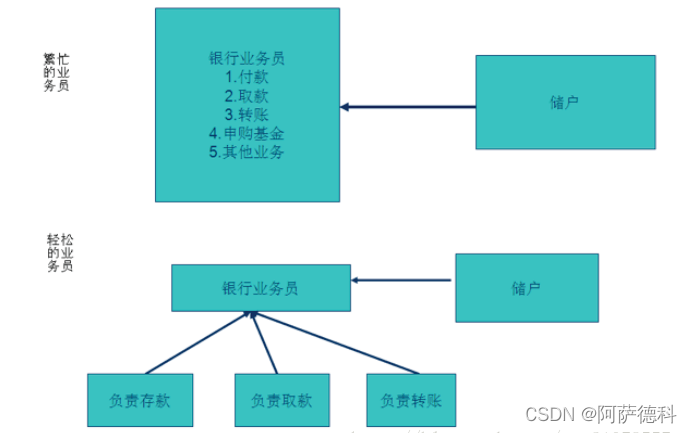
}二、开放封闭原则(OCR,Open-Closed Principle)
软件实体(类、模块、函数等)的改动是通过增加代码进行的,而不是修改源代码。
对于扩展是开放的(Open for extension),对于更改是封闭的(Closed for modification)
实例:
//普通的实现方法
#include "iostream"
using namespace std;
/*
如果需要增加新的功能,需要再次添加新的成员函数,会导致类越来越复杂
*/
class BankWorker{
public:
void save(){
cout << "save money." << endl;
}
void transter(){
cout << "transfer money." << endl;
}
void pay(){
cout << "pay money." << endl;
}
/*
如果在后期需要增加网银开通、贷款等业务,则需要在此处继续添加函数。
*/
};
int main()
{
BankWorker *bw = new BankWorker;
bw->pay();
bw->transter();
bw->save();
delete bw;
system("pause");
return 0;
}
//符合开闭原则的思路设计代码
#include "iostream"
using namespace std;
class BankWorker{
public:/*纯虚函数的设计用来抽象银行业务员的业务*/
virtual void doBusiness() = 0;
};
/*创建存钱的银行员*/
class saveBankWorker : public BankWorker{
public:
virtual void doBusiness(){
cout << "save money." << endl;
}
};
/*创建转账的银行员*/
class transferBankWorker : public BankWorker{
public:
virtual void doBusiness(){
cout << "transfer money." << endl;
}
};
/*创建取钱的银行员*/
class payBankWorker :public BankWorker{
public:
virtual void doBusiness(){
cout << "pay money." << endl;
}
};
/*后期如果需要增加新的功能,只需要再次集成一个新类实现业务函数即可*/
/*新增办理基金的银行员*/
class fundationBankWorker :public BankWorker{
virtual void doBusiness(){
cout << "fundation money." << endl;
}
};
int main()
{
/*
C++产生多态的3个必要条件
1、有继承,如saveBankWorker继承了BankWorker
2、要有重写,这里的BankWorker类的doBusiness()函数是纯虚函数,
就会被重写,这个函数也称之为接口函数
3、父类指针指向子类对象
*/
BankWorker *bw = NULL; //实例化一个父类指针
bw = new saveBankWorker; //将父类指针指向子类对象
bw->doBusiness(); //调用业务函数
delete bw; //释放空间
bw = NULL; //将指针指向空,更加安全
bw = new transferBankWorker;
bw->doBusiness();
delete bw;
bw = NULL;
bw = new payBankWorker;
bw->doBusiness();
delete bw;
bw = NULL;
system("pause");
return 0;
}
结束:通过开闭原则,我们在增加银行业务员的新的业务时,我们无需修改原来类中的代码,而是通过拓展添加类的方式来实现功能,实际上是利用了C++多态的特性,也符合了设计模式中的开闭原则。
注:切记,高内聚,低耦合。高内聚,低耦合。高内聚,低耦合。
三、里氏替换原则(LSP,Liskov Substitution principle)
定义:子类型(subtype)必须能够替换掉他们的基类型(base type)。
通俗的来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。
它包含以下4层含义:
1.子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法。
2.子类中可以增加自己特有的方法。
3.当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
4.当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
就是子类必须能够完全替代 父类,否则就是不合理的继承关系。换就话说,就是父类的方法 是子类全部需要的,如果不是全部需要的,你的继承关系就存在问题。
例如。 父类(Anaimal)里有两个方法 Fly 和 Run. 但是 子类 Dog 只需要Run方法,而不需要Fly这个方法。所以这个父类就有问题。需要进一步优化,变成 飞行类动物和不会飞行的动物两个类,这两个类都继承动物类。并将 原动物类里的 方法 Fly 移动飞行类动物里,Run方法 还留在动物类里,而Dog 继承 不会飞行的动物那个。
里氏替换原则:其子类对象可以代替父类对象,但其父类对象不能代替子类对象.
如:有一个父类:
public abstract class A{}
有两个子类都继承父类A:
public class B:A{}
public class C:A[]
那么运用里氏替换原则就可以:
A a = new B();或:A a = new C();
但不可以: B b = new A();
四、接口隔离原则(ISP, Interface Segregation Principle)
指客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
实例:
//接口类IBase
class IBase
{
public:
IBase(){}
virtual ~IBase(){}
public:
virtual void func1() = 0;
virtual void func2() = 0;
virtual void func3() = 0;
virtual void func4() = 0;
virtual void func5() = 0;
};
class B:public IBase
{
public:
virtual void func1()
{
std::cout << "我是供类A调用的func1()" << std::endl;
}
virtual void func2()
{
std::cout << "我是供类A调用的func2()" << std::endl;
}
virtual void func3()
{
std::cout << "我是供类A调用的func3()" << std::endl;
}
virtual void func4(){}
virtual void func5(){}
};
class D:public IBase
{
public:
virtual void func1(){}
virtual void func2(){}
virtual void func3()
{
std::cout << "我是供类C调用的func3()" << std::endl;
}
virtual void func4()
{
std::cout << "我是供类C调用的func4()" << std::endl;
}
virtual void func5()
{
std::cout << "我是供类C调用的func5()" << std::endl;
}
};
class A
{
public:
A(){ std::cout << "我是类AAAAAAA啊"<< std::endl; }
void funcA(IBase* base)
{
base->func1();
base->func2();
base->func3();
std::cout << "*********************"<< std::endl;
}
};
class C
{
public:
C(){ std::cout << "我是类CCCCCC啊"<< std::endl;}
void funcC(IBase* base)
{
base->func3();
base->func4();
base->func5();
}
};
int _tmain(int argc, _TCHAR* argv[])
{
A* a = new A();
a->funcA(new B());
C* c = new C();
c->funcC(new D());
delete a;
a = nullptr;
delete c;
c = nullptr;
system("pause");
return 0;
}类A通过调用基类IBase的接口实现了对类B的依赖,类C通过调用基类IBase的接口实现了对类D的依赖.
因为类A中没有用到接口func4和func5,同样类C也没有用到接口func1和func2,
但由于类B和类D继承了接口IBase,所以不得不去实现所有基类IBase的接口方法
由于这个臃肿的基类IBase ,我们不得不这样做,那么有没有更好的方法呢?
答案是有的,下面我们通过接口隔离的方法重新实现我们上述的代码逻辑
class IBase1
{
public:
IBase1(){}
virtual ~IBase1(){}
public:
virtual void func1() = 0;
virtual void func2() = 0;
};
class IBase2
{
public:
IBase2(){}
virtual ~IBase2(){}
public:
virtual void func3() = 0;
};
class IBase3
{
public:
IBase3(){}
virtual ~IBase3(){}
public:
virtual void func4() = 0;
virtual void func5() = 0;
};
class B:public IBase1,public IBase2
{
public:
virtual void func1()
{
std::cout << "我是供类A调用的func1()" << std::endl;
}
virtual void func2()
{
std::cout << "我是供类A调用的func2()" << std::endl;
}
virtual void func3()
{
std::cout << "我是供类A调用的func3()" << std::endl;
}
};
class D:public IBase2,public IBase3
{
public:
virtual void func3()
{
std::cout << "我是供类C调用的func3()" << std::endl;
}
virtual void func4()
{
std::cout << "我是供类C调用的func4()" << std::endl;
}
virtual void func5()
{
std::cout << "我是供类C调用的func5()" << std::endl;
}
};
class A
{
public:
A(IBase1* base1,IBase2* base2):m_pBase1(base1),m_pBase2(base2)
{ std::cout << "我是类AAAAAAA啊"<< std::endl;}
void funcA()
{
m_pBase1->func1();
m_pBase1->func2();
m_pBase2->func3();
std::cout << "*********************"<< std::endl;
}
private:
IBase1* m_pBase1;
IBase2* m_pBase2;
};
class C
{
public:
C(IBase2* base2,IBase3* base3):m_pBase2(base2),m_pBase3(base3)
{ std::cout << "我是类CCCCCC啊"<< std::endl;}
void funcC()
{
m_pBase2->func3();
m_pBase3->func4();
m_pBase3->func5();
}
private:
IBase2* m_pBase2;
IBase3* m_pBase3;
};
int _tmain(int argc, _TCHAR* argv[])
{
A* a = new A(new B(),new B());
a->funcA();
C* c = new C(new D(),new D());
c->funcC();
delete a;
a = nullptr;
delete c;
c = nullptr;
system("pause");
return 0;
}上面的逻辑结构中我们可以看出,类B不用再去实现func4和func5,类D不用去实现func1和func2,它们只需要实现所依赖的接口方法。
总结
接口隔离原则的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少。也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。本文例子中,将一个庞大的接口变更为3个专用的接口所采用的就是接口隔离原则。在程序设计中,依赖几个专用的接口要比依赖一个综合的接口更灵活。接口是设计时对外部设定的“契约”,通过分散定义多个接口,可以预防外来变更的扩散,提高系统的灵活性和可维护性。
单一职责原则和接口隔离的比较:
侧重职责不同:单一职责原则注重的是职责,接口隔离原则注重的是对接口的隔离
侧重对象不同:单一职责原则主要是约束类,其次才是接口和方法,它针对的是程序中的实现和细节,接口隔离原则主要约束基类接口,主要针对抽象,针对程序整体框架的构建。
建议:在平时的工作学习中,针对类、接口的设计,要花时间去考虑,可分别从依赖倒置原则,单一职责原则,接口隔离原则等方面进行考虑,磨刀不误砍柴功,好的设计才能造就好的产品。
五、依赖倒置原则 (DIP,Dependence Inversion Principle)
原始定义:高层模块不应该依赖底层模块,两者都应该依赖抽象;抽象不应该依赖细节,细节应该依赖抽象
核心思想是:要面向接口编程,不要面向实现编程
在软件设计中,细节具有多变性,抽象则相对稳定,因此以抽象为基础搭建起来的架构要比以细节为基础搭建起来的架构要稳定得多。这里的抽象指的是接口或者抽象类,而细节是指具体的实现类。
实际编程中要遵循以下4点:
- 每个类尽量提供接口或抽象类,或者两者都具备。
- 变量的声明类型尽量是接口或者抽象类。
- 任何类都不应该从具体类派生。
- 使用继承时尽量遵循里氏替换原则。
实际应用:
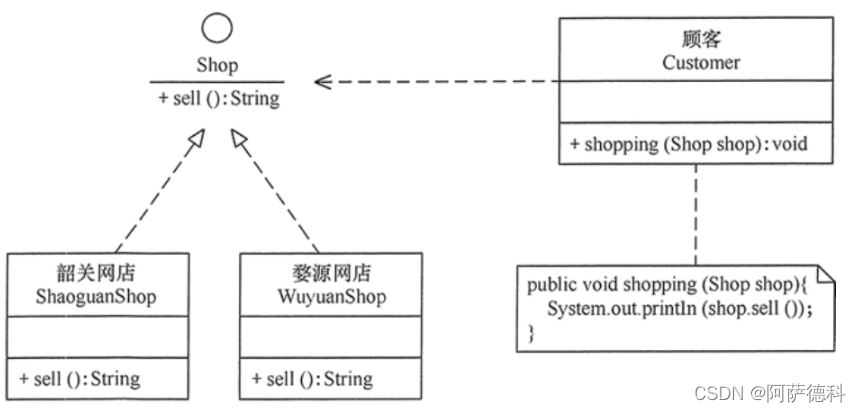
//分析:本程序反映了“顾客类”与“商店类”的关系。商店类中有sell()方法,顾客类通过该方法购物
//以下代码定义了顾客类通过韶关网店 ShaoguanShop 购物:
class Customer
{
public:
void shopping(ShaoguanShop shop)
{ //购物
shop.sell();
}
}
//但是,这种设计存在缺点,如果该顾客想从另外一家商店(如婺源网店 WuyuanShop)购物,就要将该顾客的代码修改如下:
class Customer
{
public:
void shopping(WuyuanShop shop)
{ //购物
shop.sell();
}
}
//顾客每更换一家商店,都要修改一次代码,这明显违背了开闭原则。
//存在以上缺点的原因是:顾客类设计时同具体的商店类绑定了,这违背了依赖倒置原则。
//解决方法是:定义“婺源网店”和“韶关网店”的共同接口 Shop,顾客类面向该接口编程,其代码修改如下:
class Customer
{
public:
void shopping(Shop shop)
{ //购物
shop.sell();
}
}不管顾客类Customer访问什么商店,或者增加新的商店,都不需要修改原有代码了,其类图如图所示
六、优先使用组合而不是继承原则(CARP,Composite/Aggregate Reuse Principle)
组合可以被说成“我请了个老头在我家里干活” ,继承则是“我父亲在家里帮我干活"。
类继承通常为“白箱复用”,对象组合通常为“黑箱复用”
继承在某种程度上破坏了封装性,子类父类耦合度高。
而对象组合则只要求被组合的对象具有良好定义的接口,耦合度低
继承
白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,父类的内部细节对子类可见。
如果A和B都继承C,那么意思就是说A是一种C,B也是一种C。比如:鸟(Bird)和狼(Wolf)都是动物(Animal),Bird和Wolf都继承Animal,那么Bird和Wolf就具备了Animal的一切特征,这点Bird和Wolf是完全相同的,但是Bird会飞,Wolf不会,这是他们的区别。所以可以在Bird类中增加飞的属性,这也是继承的一大优点:子类可以重写父类的方法来方便地实现对父类的扩展。
继承的缺点有以下几点:
1:父类的内部细节对子类是可见的。
2:子类从父类继承的方法在编译时就确定下来了,所以无法在运行期间改变从父类继承的方法的行为。
3:子类与父类是一种高耦合,违背了面向对象思想。
4 :继承关系最大的弱点是打破了封装,子类能够访问父类的实现细节,子类与父类之间紧密耦合,子类缺乏独立性,从而影响了子类的可维护性。
5:不支持动态继承。在运行时,子类无法选择不同的父类。
//使用继承方式实现目标
class Animal
{
private:
void beat()
{
cout<<("心脏跳动...");
}
public:
void breath()
{
beat();
cout<<("吸一口气,呼一口气,呼吸中...");
}
}
//继承Animal,直接复用父类的breath()方法
class Bird :public Animal
{
//创建子类独有的方法fly()
public:
void fly()
{
cout<<("我是鸟,我在天空中自由的飞翔...");
}
}
//继承Animal,直接复用父类的breath()方法
class Wolf :public Animal
{
//创建子类独有的方法run()
public:
void run()
{
cout<<("我是狼,我在草原上快速奔跑...");
}
}
void main()
{
//创建继承自Animal的Bird对象新实例b
Bird b=new Bird();
//新对象实例b可以breath()
b.breath();
//新对象实例b可以fly()
b.fly();
Wolf w=new Wolf();
w.breath();
w.run();
}组合
黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。
如果A类在B类中有使用到,则A类是B类的一部分。例如眼(Eye)、鼻(Nose)、口(Mouth)、耳(Ear)是头(Head)的一部分,所以类Head应该由类Eye、Nose、Mouth、Ear组合而成,不是派生而成
组合的特点
1:不破坏封装,整体类与局部类之间松耦合,彼此相对独立。
2:具有较好的可扩展性。
3:支持动态组合。在运行时,整体对象可以选择不同类型的局部对象。
// 使用组合方式实现目标
class Animal
{
private:
void beat()
{
cout<<("心脏跳动...");
}
public:
void breath()
{
beat();
cout<<("吸一口气,呼一口气,呼吸中...");
}
}
class Bird
{
//定义一个Animal成员变量,以供组合之用
private:
Animal a;
//使用构造函数初始化成员变量
public:
Bird(Animal a)
{
this.a=a;
}
//通过调用成员变量的固有方法(a.breath())使新类具有相同的功能(breath())
public:
void breath()
{
a.breath();
}
//为新类增加新的方法
public:
void fly()
{
cout<<("我是鸟,我在天空中自由的飞翔...");
}
}
class Wolf
{
private:
Animal a;
public:
Wolf(Animal a)
{
this.a=a;
}
public:
void breath()
{
a.breath();
}
public:
void run()
{
cout<<("我是狼,我在草原上快速奔跑...");
}
}
void main()
{
//显式创建被组合的对象实例a1
Animal a1=new Animal();
//以a1为基础组合出新对象实例b
Bird b=new Bird(a1);
//新对象实例b可以breath()
b.breath();
//新对象实例b可以fly()
b.fly();
Animal a2=new Animal();
Wolf w=new Wolf(a2);
w.breath();
w.run();
}总结
1.除非考虑使用多态,否则优先使用组合。
2.要实现类似”多重继承“的设计的时候,使用组合。
3.要考虑多态又要考虑实现“多重继承”的时候,使用组合+接口。
七、封装变化点
软件设计最大的敌人,就是应付需求不断的变化
设计模式是“封装变化”方法的最佳阐释。无论是创建型模式、结构型模式还是行为型模式,归根结底都是寻找软件中可能存在的“变化”,然后利用抽象的方式对这些变化进行封装。由于抽象没有具体的实现,就代表了一种无限的可能性,使得其扩展成为了可能。
GOF对设计模式的分类,已经彰显了“封装变化”的内涵与精髓。
创建型模式的目的就是封装对象创建的变化。例如Factory Method模式和Abstract Factory模式,建立了专门的抽象的工厂类,以此来封装未来对象的创建所引起的可能变化。而Builder模式则是对对象内部的创建进行封装,由于细节对抽象的可替换性,使得将来面对对象内部创建方式的变化,可以灵活的进行扩展或替换。
至于结构型模式,它关注的是对象之间组合的方式。本质上说,如果对象结构可能存在变化,主要在于其依赖关系的改变。当然对于结构型模式来说,处理变化的方式不仅仅是封装与抽象那么简单,还要合理地利用继承与聚合的方法,灵活地表达对象之间的依赖关系。例如Decorator模式,描述的就是对象间可能存在的多种组合方式,这种组合方式是一种装饰者与被装饰者之间的关系,因此封装这种组合方式,抽象出专门的装饰对象显然正是“封装变化”的体现。同样地,Bridge模式封装的则是对象实现的依赖关系,而Composite模式所要解决的则是对象间存在的递归关系。
行为型模式关注的是对象的行为。行为型模式需要做的是对变化的行为进行抽象,通过封装以达到整个架构的可扩展性。例如策略模式,就是将可能存在变化的策略或算法抽象为一个独立的接口或抽象类,以实现策略扩展的目的。Command模式、State模式、Vistor模式、Iterator模式概莫如是。或者封装一个请求(Command模式),或者封装一种状态(State模式),或者封装“访问”的方式(Visitor模式),或者封装“遍历”算法(Iterator模式)。而这些所要封装的行为,恰恰是软件架构中最不稳定的部分,其扩展的可能性也最大。将这些行为封装起来,利用抽象的特性,就提供了扩展的可能。
考虑一个日志记录工具。目前需要提供一个方便的日志API,使得客户可以轻松地完成日志的记录。该日志要求被记录到指定的文本文件中,记录的内容属于字符串类型,其值由客户提供。我们可以非常容易地定义一个日志对象:
public class Log
{
public void Write(string target, string log)
{
//实现内容;
}
}当客户需要调用日志的功能时,可以创建日志对象,完成日志的记录:
Log log = new Log();
log.Write(“error.log”, “log”);客户提出,需要改变日志的记录方式,将日志内容写入到指定的数据表中
在封装变化之前,我们需要弄清楚究竟是什么发生了变化?从需求看,是日志记录的方式发生了变化。从这个概念分析,可能会导致两种不同的结果。一种情形是,我们将日志记录的方式视为一种行为,确切的说,是用户的一种请求。另一种情形则从对象的角度来分析,我们将各种方式的日志看作不同的对象,它们调用接口相同的行为,区别仅在于创建的是不同的对象。前者需要我们封装“用户请求的变化”,而后者需要我们封装“日志对象创建的变化”。
封装“用户请求的变化”,在这里就是封装日志记录可能的变化。也就是说,我们需要把日志记录行为抽象为一个单独的接口,然后才分别定义不同的实现。如图所示:
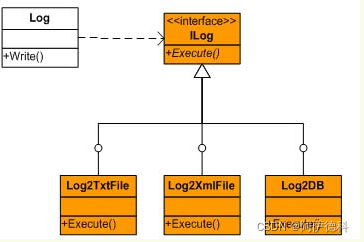
如果熟悉设计模式,可以看到图一所表示的结构正是Command模式的体现。由于我们对日志记录行为进行了接口抽象,用户就可以自由地扩展日志记录的方式,只需要实现ILog接口即可。至于Log对象,则存在与ILog接口的弱依赖关系:
public class Log
{
private ILog log;
public Log(ILog log)
{
this.log = log;
}
public void Write(string target, string logValue)
{
log.Execute(target, logValue);
}
}我们也可以通过封装“日志对象创建的变化”实现日志API的可扩展性。在这种情况下,日志会根据记录方式的不同,被定义为不同的对象。当我们需要记录日志时,就创建相应的日志对象,然后调用该对象的Write()方法,实现日志的记录。此时,可能会发生变化的是需要创建的日志对象,那么要封装这种变化,就可以定义一个抽象的工厂类,专门负责日志对象的创建,如图所示:
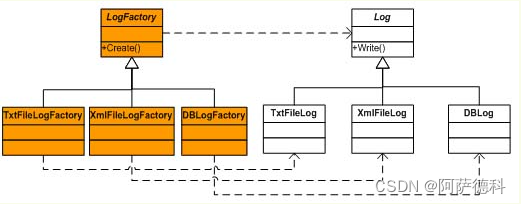
上图是Factory Method模式的体现,由抽象类LogFactory专门负责Log对象的创建。如果用户需要记录相应的日志,例如要求日志记录到数据库,需要先创建具体的LogFactory对象:
LogFactory factory = new DBLogFactory();
当在应用程序中,需要记录日志,那么再通过LogFactory对象来获取新的Log对象:
Log log = factory.Create();
log.Write(“ErrorLog”, “log”);
如果用户需要改变日志记录的方式为文本文件时,仅需要修改LogFactory对象的创建即可:
LogFactory factory = new TxtFileLogFactory();
八、针对接口编程,而不是针对实现编程
一个对象应当对其他对象尽可能少的了解,从而降低各个对象之间的耦合,提高系统的可维护性。
例如在一个程序中,各个模块之间相互调用时,通常会提供一个统一的接口来实现。
这样其他模块不需要了解另外一个模块的内部实现细节。
当一个模块内部的实现发生改变时,不会影响其他模块的使用。(黑盒原理)
首先,假设我们有一个如下的场景需求:饲养场里面有几种动物,牛、猪和鸡。你现在带着你的小孩子过来,想让他感受下每个动物的叫声是啥样子的,于是你就有这样的一个需求,拉来一种动物,就听下它的叫声。
针对实现编程:
首先我们来“针对实现编程”,假设我们调用hearSound来听到每种动物的发声。现在,先来了一只牛,我们想听到其声音,可以把hearSound()编写如下:
public void hearSound(Cow cow) {
cow.makeSound();
}调用这个方法来发声: hearSound(new Cow());
然后又来了一只鸡,我们想听其声音,就需要再编写一个针对鸡的hearChickenSound:
public void hearChickenSound(Chicken chicken) {
chicken.makeSound();
}调用这个方法来发声: hearChickenSound(new Chicken());
这就是说,每想听到一种动物的声音,你就得去新建一个与该动物相关的hearSound()方法,原来的方法没法复用,因为你已经在原来的方法里写死了只能是“牛”发声。每一个hearSound()方法与每种动物紧耦合,扩展起来不方面(可能每个heardSound方法都得去扩展相应的功能)。而且,假如我原来是只想听“牛”叫,就写个hearSound(Cow cow)方法就行了。现在不想听了,只想听“鸡”叫,那么就得修改掉hearSound()方法,还有曾经所有调用过hearSound()方法的也需要进行相应的修改,可见这种设计维护起来也很差劲。
针对接口编程
既然上述“针对实现编程”有诸多问题,就得寻找解决方式,“针对接口编程”的好处也就显现出来。我们来看看上述场景需求下,“针对接口编程”如何来实现。
Animal类还是与上述一样的,每种动物还是各自实现其makeSound()方法。不同的是,在设计hearSound()方法的时候,我们的参数设计成Animal接口,而不是具体的某种动物(牛、鸡或猪):
public void hearSound(Animal animal) {
animal.makeSound();
}这样,来了一头“牛”,我们可以这样调用: hearSound(new Cow()); ,
继续来了一只鸡,我们还可以这样调用: hearSound(new Chicken()); 。
由于hearSound()方法定义的时候调用的是接口,我们无需关心以后执行时的真正的数据类型是哪种。而在实际调用时,我们可以传入实现了Anima接口的任意一种子类(牛、鸡或猪),而且hearSound()中调用的makeSound()方法也是真正传入的类型的makeSound()方法。这种松耦合的设计理念提高了代码的复用度,需要扩展的时候也很方便。想在替换原有类型的时候也很方便,提高了可维护性。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









