




计算机基本硬件
计算机的基本硬件系统由运算器、控制器、存储器、输入设备和输出设备五大核心部件组成。
- 中央处理单元(Central Processing Unit,CPU):集成了运算器和控制器等逻辑部件,负责执行指令、对数据进行各种算术、逻辑运算,并控制整个计算机系统的运行
- 内部存储器(主存储器):速度高、容量小,断点易失,用来临时存放程序、数据和运算的中间结果。有较高的随机访问速度,能直接访问任一存储单元。
- 外部存储器(辅助存储器):容量大、速度较慢、断电不易失,主要采用顺序访问,不适合高速随机访问。用于长期保存数据。
- 外设:
-
- 输入设备:将外部信息输入到计算机系统(键鼠、扫描仪、麦克风等)
- 输出设备:将处理后的数据显示给用户(显示器、音响、打印机等)
CPU主要功能
CPU作为计算机的核心,负责执行程序并协调系统工作。
- 程序控制:CPU按照设定的顺序自动逐条取出、解释、执行指令,CPU最核心的功能。
- 操作控制:CPU 将指令译码后的微操作信号发送给计算机的各个相关部件,控制他们严格按照指令要求完成具体操作。
- 时间控制:CPU精确控制指令执行过程中各个微操作的开始时间、持续时间以及先后顺序,协调系统工作。
- 数据处理:CPU通过算术逻辑单元对数据进行算术运算和逻辑运算,完成对数据的加工。
- 中断响应:对系统内部(运算溢出、非法指令)和外部(打印机就绪,键盘输入)的中断暂停当前程序处理,转而处理中断时间,处理完毕后再恢复原程序执行。
CPU组成
CPU由以下部件组成,通过内部总线进行连接
- 运算器:
-
- 算术逻辑单元ALU:执行所有的算术运算(加减乘除)和逻辑运算(与、或、非)。
- 累加寄存器AC:主要存放ALU运算的结果,部分指令也可能作为源操作数的来源。
- 数据缓存寄存器DR:作为主存储器和外设的数据缓冲,暂时存放从内存中取出的指令和数据
- 状态寄存器PSW:记录ALU运算结果的状态标志(如:结果为零 Zero/ Z、结果为负 Negative/ N、溢出 Overflow/ V、进位 Carry/ C、奇偶校验 Parity/ P等)。
- 控制器:协调和控制整个CPU及整个计算机的操作
-
- 指令寄存器IR:存放当前正在执行的指令本身。
- 程序计数器PC:存放下一条待执行指令在主存储器的地址,CPU通过修改PC来控制程序的执行流程(顺序、跳转、调用等)。
- 地址寄存器AR:保存CPU当前访问的内存地址。存放CPU当前访问(读/写)的主存储器的地址
- 指令译码器ID:对指令寄存器的指令操作码进行解析,确定要执行的操作类型和所需的操作数来源,产生相应的控制信号。
- 寄存器组:通用寄存器,用于高速暂存数据、地址和运算中间结果。减少对主存的访问。
- 内部总线:在CPU各个部件之间传输数据、地址和控制信号。
校验码
码距: 两个编码。从A码 → B码 需要改变的位数。用于衡量编码的检错/纠错能力,码距越大,纠错能力越强。
如000 - 101码距为2,000-111码距是3
奇偶校验码
在原始数据后添加一位校验位,使整个编码中的1的个数满足奇数(奇校验)或偶数(偶校验)
码距 为 2,只能检查1位错误,不能纠错。
|
原始数据 |
奇校验码 |
偶校验码 |
|
10001 |
100011 |
100010 |
|
11001 |
110010 |
110011 |
CRC循环冗余校验码
通过多项式除法(模2)生成校验码,附加到原始数据后进行传输,可以检测多位错误。
如原数据10110
- 生成多项式G(x),(一般题目给出多项式)

- 计算步骤

- 模2运算
101100000 ← 补零后的数据
⊕ 10011 ← G(x) = 10011 (首位对齐)
-------------
1010000 → 异或结果
10011 ← G(x) 对齐下一个`1`
-------------
11100 → 异或结果
10011 ← G(x) 对齐
-------------
1111 → 余数(4位)
- 验证
用相同的G(x)对最后的 10110 1111编码再做一次模2运算,余数为0则传输正确。
指令系统
计算机指令由操作码和操作数两部分组成,
- 操作码决定要执行的具体操作,(如加、减、乘、除、存储、跳转、载入等)。
- 操作数提供执行指令所需的数据 或者 数据的来源/地址。
CPU执行指令步骤:
- 取指令
-
- CPU将程序计数器(PC)当前内容送入地址总线(下一条要执行指令的地址)。
- CPU根据地址通过地址总线找到对应的指令,存入IR(指令寄存器)
- 分析指令
-
- 译码器读取IR中的指令,
- 译码器分析指令的操作码,确定要执行的具体操作。
- 译码器解析指令的操作数/地址码部分,确定要操作数据的位置
- 执行指令
-
- 根据译码器确定的操作码和操作数,算术逻辑单元ALU进行运算。将结果写入目标寄存器或目标内存地址
- 更新程序计数器(PC),执行下一条要执行的指令地址。
指令寻址方式
即如何寻找下一条要执行的指令
- 顺序寻址方式:指令在内存中连续存放,按顺序执行,程序计数器(PC)自动递增,指向下一条指令的地址
- 跳跃寻址方式:下一条指令的地址由当前指令直接给出,程序计数器(PC)更新为新的目标地址,从新地址继续顺序执行(如if/for/函数调用返回等)
指令操作数的寻址方式
- 立即寻址: 指令的地址码字段指出的不是地址,而是操作数本身。
- 直接寻址: 在指令的地址字段中直接指出操作数在主存的地址
- 间接寻址方式: 指令地址码指向的存储单元存放的是操作数的地址(指针的指针)
- 寄存器寻址方式: 地址码给出的是存放操作数的寄存器编号。
- 寄存器间接寻址: 寄存器存放的是操作数在内存中的地址
指令类型
CISC: 复杂指令集,兼容性强,指令多,长度可变,由微程序控制技术实现(微码解释复杂指令)。
RISC:精简指令集,指令少,频率接近,硬布线逻辑控制为主 (直接硬件实现简单指令),增加了通用寄存器
指令流水线
将单条指令拆分为多个功能段(如取指、译码、执行、访存、写回),每段由专门硬件执行,实现多条指令的不同阶段同时执行。通过时间重叠提升吞吐率。
RISC中的流水线技术
- 超流水线(Super Pipline):把传统的流水线阶段划分的更细,如原来的5级流水线拆分为10级,这样也就可以有更多的指令可以并行执行,可以提高CPU主频,缺点是会增加单条指令的执行延迟,因为要经过更多阶段。
- 超标量(Super Scalar):同一个处理器芯片内部集成多个执行单元(如多个ALU、多个乘法器、多个加载/存储单元),内装多个流水线同时执行多个处理,时钟频率虽然和一般流水线接近,但是有更小的IPC,以空间换时间。
- 超长指令字(Very Long Instruction Word ,VLIW):超长指令字和超标量都是20世纪80年代出现的概念,共同点都是要执行多条指令,
超标量使用硬件实现,超长指令字则是发挥软件的作用,而使硬件简化。 将发现指令间并行性的任务完全交给编译器。
如执行三条指令1、2、3
未使用流水线的情况
|
取指 |
1 |
2 |
3 | ||||||
|
分析 |
1 |
2 |
3 | ||||||
|
执行 |
1 |
2 |
3 |
使用流水线
|
取指 |
1 |
2 |
3 | ||
|
分析 |
1 |
2 |
3 | ||
|
执行 |
1 |
2 |
3 |
流水线时间计算
- 流水线周期:指令分为不同段、执行时间最长的一段为流水线周期
- 流水线执行时间:(流水线周期*指令条数)+(一条指令总执行时间-流水线周期)
- 流水线吞吐率计算:吞吐率即单位时间内执行的指令条数,指令条数/流水线执行时间。
- 流水线加速比计算:加速比即使用流水线效率提升多少倍,不使用流水线执行时间÷使用流水线执行时间。
存储系统
分级存储体系
两级存储:cache ⇄ 主存储器,主存储器 ⇄ 辅助存储器
主要是为了解决 容量、访问速度、成本 三者之间的矛盾
目标是提供接近最快存储器的速度、最慢存储器的容量和价格。
实现方式→利用局部性原理
CPU在执行过程中,倾向于在短时间内集中访问一小块连续或相关的内存地址区域。
- 时间局部性:一个被访问的数据,在近期可能会被再次访问(如循环变量、函数参数)
- 空间局部性:相邻的地址很可能会被连续访问(顺序执行的指令,数组)
Cahce利用局部性原理,将最近可能访问的数据块从主存复制到Cache中。
容量:低 → 高 ,速度:高 → 低
CPU寄存器 → Cache → 主存储器 → 联机磁盘存储器 → 脱机光盘、磁盘存储器
Cache
高速缓存Cache 位于CPU和主存之间,
内容是主存的部分拷贝,
存储当前最活跃的程序和数据。
Cache由控制器和存储器组成,控制器判断CPU访问的数据是否存在,不存在则按照一定的规则算法从主存中提取、替换。
映像方式
地址映射:将 CPU 发出的 主存地址 转换为 Cache 地址 的规则(由硬件自动完成)。
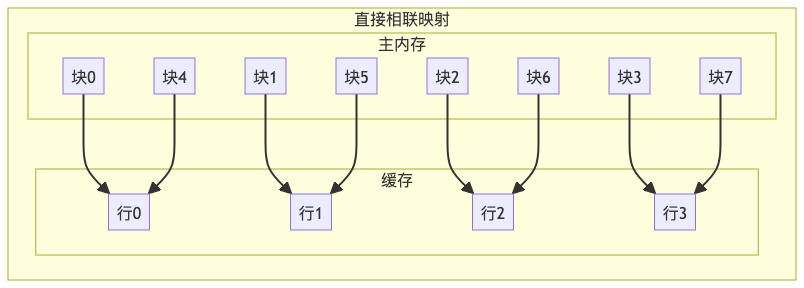
- 直接映像:将Cache存储器等分成块,主存也等分成块并编号,主存中的块和Cache中的块的对应关系是固定的,即二者块号相同才能命中,地址转换简单但是不灵活,容易造成资源浪费。
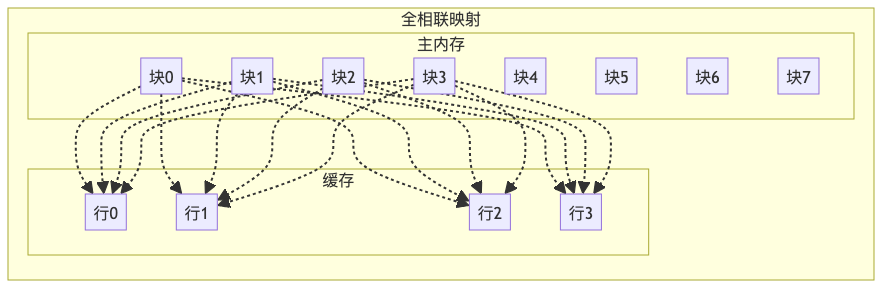
- 全相连映像:同样划分成块并且编号,cache中的任意一块都可以与主存的任意一块对应,主存中的内容可以随意调入cache,只有cache满了才会发生冲突,是最不容易发生冲突的映像方式。
- 组组相连映像:两种方式的结合,Cache和主存都是先分块后分组,组和组之间采用直接映像,组内块和块之间采用全相连映像。
替换算法
替换是因为Cache远远比内存的空间要小,所以需要替换内容以便程序使用,
替换算法的目标是使Cache尽可能的提高命中率
- 随机替换算法:随机对当前Cache的内容进行替换
- 先进先出算法:对最早的Cache内容进行替换
- 近期最少使用算法: 对近期内使用最少的内容进行替换
- 优化替换算法:需要先执行一次程序,统计Cache的替换情况,下次执行就可以使用最有效的方式进行替换。
命中率和平均时间
Cache因为远比内存容量小,所以会有数据无法命中,要去内存中去取数据,假设读取内存一次的时间为1000ns,命中cache的概率为90%,则CPU读取一次的平均时间为(90% * 1 + 10%*1000)ns,
磁盘
磁盘组成
- 盘面:磁盘一般有多个盘片,每个盘片有正反两个盘面、两个磁头
- 磁道:每个盘面有多个同心圆,每个同心圆是一个磁道,所有盘片相同半径的磁道组成了一个柱面,
- 扇区:一个磁道划分为多个扇区,最小的可寻址单元,
- 磁头:每个盘面一个读写磁头,所有磁头固定在一个移动臂上,因此他们总是处于所有盘面的相同柱面上。
- 柱面:所有盘面相同半径的同心圆组成的虚拟圆柱体。
磁盘访问
磁头需要先寻找到磁道,然后磁盘进行周期旋转,旋转到指定的扇区,才能够读取数据,所以磁盘读取数据会有寻道时间和旋转延迟,
存取时间 = 寻道时间+旋转延迟+传输时间
- 寻道时间:移动磁臂到目标磁道所需的时间,磁盘的主要性能瓶颈
- 旋转延迟:等待磁盘旋转,使目标扇区移动到磁盘下方所需的时间,
- 传输时间:磁头找到对应扇区后,实际读取或写入的时间。
因为旋转只能一个方向,控制有限,并且寻道时间一般耗时最长,所以需要对寻道时间进行重点调度,有如下调度算法
-
- 先来先服务FCFS:根据访问磁盘请求的先后顺序进行调度。缺点是有可能跨度过大,效率过低。
- 最短寻道时间SSTF:优先寻道和当前位置最近的访问请求,使得每次寻道时间最短,但可能会产生‘饥饿’问题,即远端的访问请求一直未被处理。
- 扫描算法SCAN:电梯算法,磁头双向移动,磁头从里到外或者从外到里移动到这个方向再无请求。与电梯类似
- 单向扫描算法CSCAN:和SCAN相比,只做单向移动,即只会从外到里,或者只会从里到外移动。移动到尽头后再快速返回。
输入输出
内存和地址的编址方式
- 独立编址:内存地址和接口地址是完全独立的两个地址空间,访问数据所使用的指令也完全不同,用于接口的指令只能用于对接口的读/写,编写程序时容易使用和辨认,但是用于接口的指令较少,功能较弱。
- 统一编址:内存地址和接口地址在同一个地址空间中,原则上用于内存的指令全都可以用于接口,不用区分内存指令和接口指令,但是会导致地址空间分为两部分,经常会导致内存地址不连续。
外设数据交互方式
- 程序控制(查询)方式:CPU循环查询外设状态,就绪时读写数据,效率低。
- 程序中断方式:外设数据传输完毕以后,向CPU发送中断,效率相对较高
* 中断响应时间:发出中断到开始执行中断程序(ISR)。
* 中断处理时间:中断程序(ISR)处理时间
* 中断向量:提供中断程序的入口地址指针表。
* 中断嵌套:高优先级中断可抢占低优先级、依赖堆栈保存断点(PC、寄存器) - DMA(直接主存存取):CPU完成初始化操作,后续的数据传输过程有DMA控制器完成,在主存和外设之间建立直连的数据通路,传输完成后向CPU发送中断。
中断响应时机 - 在一个总线周期结束后,CPU响应DMA请求开始读取数据
- 在一条指令执行结束后,CPU响应中断。
总线
计算机设备之间进行传输的公共数据通道。由所有设备共享。
- 内部总线:芯片内组件通信(如CPU寄存器与ALU算术逻辑单元)
- 系统总线:板级总线,用于计算机各内各部分连接,CPU/内存/IO控制器
* 数据总线:双向传输数据
* 地址总线:指定内存/I/O地址
* 控制总线:传输命令/状态信号 - 外部总线:计算机和外设连接的总线,如USB、Thunderbolt、SATA

















 9505
9505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









