







- 准备好需要放上Hadoop执行的jar。创建作业如下图:

编辑Hadoop job executor如下:

Jar:在静态main方法里面包含Hadoop mapper和reducer job的Java JAR
Driver class:包含main方法的类
Command line arguments:输入执行时所需参数,即main方法的args。
注意:
1.Output path 必须不存在
2.Combiner class:组合器类一般不写,Pentaho默认的即可满足大部分需求,或者直接用reducer class
3.如运行的jar包含$HADOOP_CLASSPATH之外的jar,则需要将所需jars一并打包进需要执行的jar。使用Maven打包包含依赖的jar需要在build里面加以下代码:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>mapreduce.WordCountController</mainClass>
</manifest>
</archive>
<descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef><!-- 打包所有dependencies -->
</descriptorRefs>
<!-- <appendAssemblyId>false</appendAssemblyId> --><!-- 是否保存到新的jar,默认true,即生成xxx-jar-with-dependencies,false则直接替换原先生成的jar文件 -->
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
可参考:https://maven.apache.org/plugins/maven-assembly-plugin/usage.html#Resources
2. 由于Hadoop jobexecutor 不包含执行作业之前删除输出文件夹的功能,那就自己动手。创建转换(删除HDFS上的文件夹.ktr)如下图:
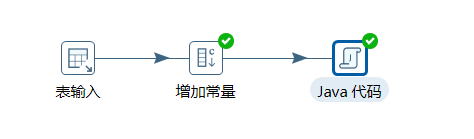
编辑表输入:SELECT SYSDATE FROM DUAL。因为只是为了使用Java而需要产生的一个流,所以随便查点什么东西都可以(DPI 9似乎不需要表输入也可以运行成功,这里由于CDH版本问题我用的是PDI 7)。
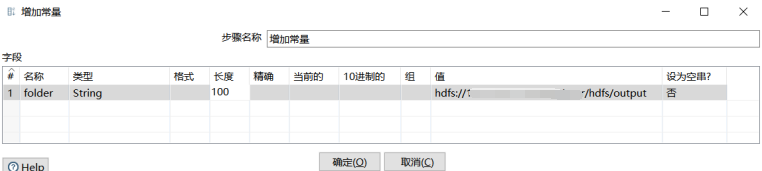
编辑增加常量:值为需要删除的HDFS上的输出路径即:output path
编辑Java代码:
import mapreduce.utils.HDFSUtil;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
String folder = get(Fields.In, "folder").getString(r);
try {
boolean flag = HDFSUtil.removeFolder(folder);
get(Fields.Out, "flagA").setValue(r, flag);
} catch (Exception e) {
putError(data.outputRowMeta, r, 1, "numErrorDescribe", "", "numErrorCode");
setErrors(1);
return false;
}
putRow(data.outputRowMeta, r);
return true;
}
Java代码的使用方法可参考:
https://blog.youkuaiyun.com/qq_37219543/article/details/121771119?spm=1001.2014.3001.5501
HDFSUtil类的代码如下(比较懒,就写了一个删除):
package mapreduce.utils;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.mapred.JobConf;
public class HDFSUtil {
private static String hdfsPath = "hdfs://IP:8020/";
private static Configuration conf;
static {
conf = config();
}
public static void main(String[] args) throws IOException {
//JobConf conf = config();
//HDFSUtil hdfs = new HDFSUtil(conf);
boolean flag = HDFSUtil.removeFolder("hdfs://IP:8020/user/hdfs/output");
System.out.println(flag);
}
/**
* 初始化配置文件
* @return
*/
public static JobConf config() {
//设置hadoop_home
System.setProperty("hadoop.home.dir", "E:\\work\\hadoop-2.6.0");
JobConf conf = new JobConf(HDFSUtil.class);
conf.setJobName("HDFSDao");
//配置文件存放在HDFS上面
conf.addResource("/sites/core-site.xml");
conf.addResource("/sites/hdfs-site.xml");
conf.addResource("/sites/mapred-site.xml");
return conf;
}
/**
* 删除文件夹及文件夹下的文件
* @param folder
* @return true:成功,false:失败
*/
public static boolean removeFolder(String folder){
Path path = new Path(folder);
FileSystem fs = null;
try {
fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.deleteOnExit(path);
//System.out.println("Delete: " + folder);
fs.close();
return true;
} catch (IOException e) {
e.printStackTrace();
return false;
}
}
需要引入的jar(具体根据自己CDH版本来):
htrace-core4-4.2.0-incubating.jar
hadoop-auth-2.7.3.2.5.0.0-1245.jar
hadoop-client-2.6.0-cdh5.10.0.jar
hadoop-common-2.6.0-cdh5.10.0.jar
hadoop-hdfs-2.6.0-cdh5.10.0.jar
hadoop-mapreduce-client-core-2.6.0-cdh5.10.0.jar
hadoop-yarn-api-2.6.0-cdh5.10.0.jar
hadoop-yarn-client-2.6.0-cdh5.10.0.jar
hadoop-yarn-common-2.6.0-cdh5.10.0.jar
这里有个坑需要注意一下:正常hadoop-2.6.0依赖的是htrace-core3,需要引入的包名为:org.htrace。但PDI支持的最低版本的JDK为1.8。那运行自动引入htrace-core4,包名为:org.apache.htrace。所以按正常的方法引入jar的话会报:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/htrace/core/Tracer$Builder
at org.apache.hadoop.fs.FsTracer.get(FsTracer.java:42)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2697)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:96)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2747)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2729)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:384)
at com.abc.test.HdfsDAO.copyFile(HdfsDAO.java:96)
at com.abc.test.HdfsDAO.main(HdfsDAO.java:34)
Caused by: java.lang.ClassNotFoundException: org.apache.htrace.core.Tracer$Builder
at java.net.URLClassLoader.findClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
... 8 more
- 保存作业,运行作业,成功的话可到输出地址查看是否有文件生成。查看方法参考:
hadoop fs -text output/part-r-00000.deflate - 常见报错信息处理:
a.Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
可能的原因为yarn里面未设置yarn.application.classpath。这里取值为Hadoop的$HADOOP_CLASSPATH,获取方式为:远程到Hadoop集群机器上执行:
hadoop classpath

















 5550
5550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









