






 本文详细介绍了分库分表的原因、垂直拆分与水平拆分的策略,以及分库分表后面临的问题。同时,讨论了分布式全局唯一ID的重要性,并对比了UUID、数据库自增ID、数据库多主模式、雪花算法和Redis生成分布式ID的优缺点。
本文详细介绍了分库分表的原因、垂直拆分与水平拆分的策略,以及分库分表后面临的问题。同时,讨论了分布式全局唯一ID的重要性,并对比了UUID、数据库自增ID、数据库多主模式、雪花算法和Redis生成分布式ID的优缺点。
分库分表与分布式全局唯一性ID
一、为什么要分库分表?
如果单表的数据量达到1000w+后,会极大影响 sql 执行的性能,即使添加或优化索引,做很多操作时性能仍下降严重。
如果单库中存放了很多表,如:会员表、订单表、商品表等,那么这个数据库极大可能由于高并发造成瘫痪,并且数据维护也不方便。
| 分库分表前面临的问题 | 解决办法 |
|---|---|
| 用户请求量太大 | 分散请求到多个服务器上 |
| 单库太大 | 切分成更多更小的库 |
| 单表太大,造成CRUD慢 | 切分成多个数据集更小的表 |

一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
二、垂直拆分
2.1 垂直分库
垂直分库指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。

2.2 垂直分表
垂直分表指将一个表按照字段分成多表,每个表存储其中一部分字段,它带来的提升是:
- 为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
- 充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累

三、水平拆分
3.1 水平分库
水平分库指将一个数据库中的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上,它带来的提升是:
- 解决了单库大数据,高并发的性能瓶颈
- 提高了系统的稳定性及可用性

3.2 水平分表
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中,它带来的提升是:
- 优化单一表数据量过大而产生的性能问题
- 提高了系统稳定性和负载能力

四、分库分表后带来的问题
- 主键 id 唯一性
- 分布式事务问题:在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难
- 跨库跨表的 join 问题:在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表
五、什么是分布式全局唯一性ID?
随着数据日渐增长,就需要对数据库进行分库分表,但分库分表后需要有一个全局唯一 ID 来标识一条数据,数据库的自增 ID 显然不能满足需求。
有兄弟肯定会问,什么是分布式全局唯一性 ID?
答:肯定会有兄弟想,我即使分库分表后,每条数据拆分到每个表中,由于MySQL数据库主键自增的缘故,它们的 ID 在各个表是独立的,查询的时候 select * from 表名,也能够查询出来对应的信息,欸,这也不需要唯一性 ID 啊。但我们换个角度考虑,如:淘宝双十一订单量巨大,订单数据存入数据库,肯定对数据库进行了分库分表,欸,你有没有发现每个人的订单号肯定都是不同的,这就体现了全局唯一性 ID。
六、分布式ID生成方案
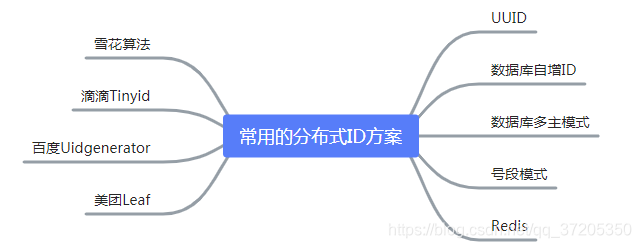
这里我们只介绍常用的几种分布式 ID 生成方案。
6.1 UUID
UUID 不适用于实际的业务需求,它的缺点:
- 无序的字符串,不具备趋势自增特性
- UUID 作为主键太长了,占用空间太大
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString().replaceAll("-","");
System.out.println(uuid); //如:c2b8c2b9e46c47e3b30dca3b0d447718
}
6.2 数据库自增ID
业务应用 A 和业务应用 B 在各自的应用代码中执行下列代码,就可以保证拿到 ID 不冲突。
begin;
//replace into尝试将数据插入到表中,如果表中已有此行数据,先删除再插入新的数据
replace into SEQUENCE_ID(stub) values('anyword')
select last_insert_id();
commit;
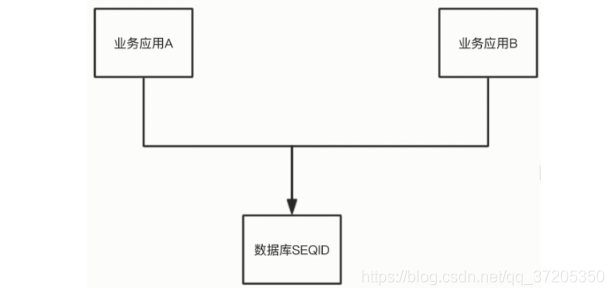
数据库自增 ID 的缺点:
- 无法保证高可用,一旦数据库 SEQID 挂掉,无法生成全局性唯一 ID
如果采用主从模式来解决高可用问题的话,可能由于主从同步的延迟性而导致可能生成的ID冲突,所以不能采用主从模式来解决高可用。
6.3 数据库多主模式
多个MySQL实例的自增ID都从1开始,会生成重复的ID怎么办?
答:为每个数据库设置不同的起始值和自增步长。
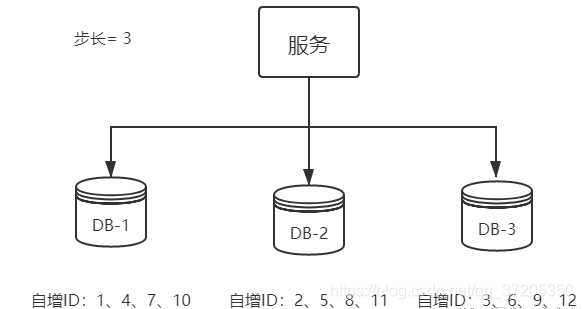
数据库多主模式的缺点:
- 不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景
增加一台数据库,需要手动修改其它 MySQL 数据库的起始值和步长,必要时可能还需要停机修改。
6.4 雪花算法
雪花算法(snowflake)是 twitter 开源的分布式 ID 生成算法,它和上面的三种生成分布式 ID 机制不太一样,它不依赖数据库。
由于生成的 id 中包含有时间戳,所以生成的 id 按照时间递增;如果部署了多台 id 生成服务器,由于每台服务器的机器编号不同,所以也不会出现 id 相同的情况。
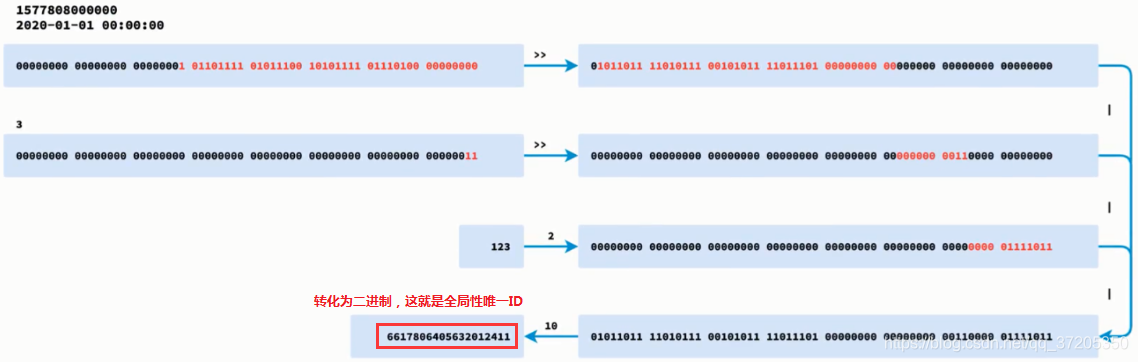
核心思想是:分布式 ID 固定是一个 long 型的数字,一个 long 型占 8 个字节,也就是 64 个 bit,原始snowflake 算法中对于 bit 的分配如下图。

- 第一个bit位代表符号位,正数是0,负数是1,一般生成的ID为正数,所以固定为0。
- 时间戳部分占41bit,这个是毫秒级的时间,不建议存当前时间戳
- 工作机器 id 占10bit
- 序列号部分占12bit,支持同一毫秒内同一个节点可以生成4096个ID
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,不需要单独去搭建一个获取分布式ID的应用。
下面我们来简单探讨一下它的实现方式:
//now - 生成的时间戳
//workID - 机器编号id
//seq - 序列号
now = time(); //获取当前毫秒时间戳
if(now == last){ //用当前毫秒时间戳和前一个ID生成的时间戳比较,如果相等,说明是同一毫秒内继续生成ID
seq++;
if(seq>4095){ //判断同一毫秒内生成的id是否已经达到最大4096,如果超过了就需要等下一毫秒
now = nexttime(); //简单理解为sleep(1ms)
seq = 0;
}
}else{
seq = 0;
}
last = now; //将最后一次id生成的时间戳更新为生成当前id的时间戳,用于生成后续的唯一id
id = now<<22 | workID << 12 | seq //拼接成64位的唯一id
雪花算法缺点:
- 严重依赖服务器的时钟,如果服务器的时钟回拨,就会导致生成的 id 重复
6.5 Redis
Redis 的所有命令操作都是单线程的,本身提供像 incr 和 incrby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。设置 id 时,每次从redis中拿,每次有相关操作时就向 Redis 服务器发送一个 incr 或 incrby 命令,保证 id 唯一。
- 优点:不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排序的结果很有帮助。
- 缺点:如果系统中没有 Redis,还需要引入新的组件,增加系统复杂度;需要编码和配置的工作量比较大。

















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









