







1、分布式锁设计
1.1、什么是分布式锁
在 JVM 中,在多线程并发的情况下,我们可以使用同步锁或 Lock 锁,保证在同一时间内,只能有一个线程修改共享变量或执行代码块。但现在我们的服务基本都是基于分布式集群来实现部署的,对于一些共享资源,例如库存,在分布式环境下使用 Java 锁的方式就失去作用了。
这时,我们就需要实现分布式锁来保证共享资源的原子性。除此之外,分布式锁也经常用来避免分布式中的不同节点执行重复性的工作,例如一个定时发短信的任务,在分布式集群中,我们只需要保证一个服务节点发送短信即可,一定要避免多个节点重复发送短信给同一个用户。
因为数据库实现一个分布式锁比较简单易懂,直接基于数据库实现就行了,不需要再引入第三方中间件,所以这是很多分布式业务实现分布式锁的首选。但是数据库实现的分布式锁在一定程度上,存在性能瓶颈。
1.2、有哪些实现方式
1.2.1、数据库实现
首先,我们应该创建一个锁表,通过创建和查询数据来保证一个数据的原子性:
CREATE TABLE `order` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`order_no` int(11) DEFAULT NULL,
`pay_money` decimal(10, 2) DEFAULT NULL,
`status` int(4) DEFAULT NULL,
`create_date` datetime(0) DEFAULT NULL,
`delete_flag` int(4) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_status`(`status`) USING BTREE,
INDEX `idx_order`(`order_no`) USING BTREE
) ENGINE = InnoDB其次,如果是校验订单的幂等性,就要先查询该记录是否存在数据库中,查询的时候要防止幻读,如果不存在,就插入到数据库,否则,放弃操作。
select id from `order` where `order_no`= 'xxxx' for update最后注意下,除了查询时防止幻读,我们还需要保证查询和插入是在同一个事务中,因此我们需要申明事务,具体的实现代码如下:
@Transactional
public int addOrderRecord(Order order) {
if (orderDao.selectOrderRecord(order) == null) {
int result = orderDao.addOrderRecord(order);
if (result > 0) {
return 1;
}
}
return 0;
}到这,我们订单幂等性校验的分布式锁就实现了。需要注意的是在 RR 事务级别,select 的 for update 操作是基于间隙锁 gap lock 实现的,这是一种悲观锁的实现方式,所以存在阻塞问题。
因此在高并发情况下,当有大量的请求进来时,大部分的请求都会进行排队等待。为了保证数据库的稳定性,事务的超时时间往往又设置得很小,所以就会出现大量事务被中断的情况。
除了阻塞等待之外,因为订单没有删除操作,所以这张锁表的数据将会逐渐累积,我们需要设置另外一个线程,隔一段时间就去删除该表中的过期订单,这就增加了业务的复杂度。
除了这种幂等性校验的分布式锁,有一些单纯基于数据库实现的分布式锁代码块或对象,是需要在锁释放时,删除或修改数据的。如果在获取锁之后,锁一直没有获得释放,即数据没有被删除或修改,这将会引发死锁问题。
1.2.2、Zookeeper 实现
Zookeeper 是一种提供“分布式服务协调“的中心化服务,正是 Zookeeper 的以下两个特性,分布式应用程序才可以基于它实现分布式锁功能。
顺序临时节点:Zookeeper 提供一个多层级的节点命名空间(节点称为 Znode),每个节点都用一个以斜杠(/)分隔的路径来表示,而且每个节点都有父节点(根节点除外),非常类似于文件系统。
节点类型可以分为持久节点(PERSISTENT )、临时节点(EPHEMERAL),每个节点还能被标记为有序性(SEQUENTIAL),一旦节点被标记为有序性,那么整个节点就具有顺序自增的特点。一般我们可以组合这几类节点来创建我们所需要的节点,例如,创建一个持久节点作为父节点,在父节点下面创建临时节点,并标记该临时节点为有序性。
Watch 机制:Zookeeper 还提供了另外一个重要的特性,Watcher(事件监听器)。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知给用户。
实现分布式方式:
首先,我们需要建立一个父节点,节点类型为持久节点(PERSISTENT) ,每当需要访问共享资源时,就会在父节点下建立相应的顺序子节点,节点类型为临时节点(EPHEMERAL),且标记为有序性(SEQUENTIAL),并且以临时节点名称 + 父节点名称 + 顺序号组成特定的名字。
在建立子节点后,对父节点下面的所有以临时节点名称 name 开头的子节点进行排序,判断刚刚建立的子节点顺序号是否是最小的节点,如果是最小节点,则获得锁。
如果不是最小节点,则阻塞等待锁,并且获得该节点的上一顺序节点,为其注册监听事件,等待节点对应的操作获得锁。当调用完共享资源后,删除该节点,关闭 zk,进而可以触发监听事件,释放该锁。
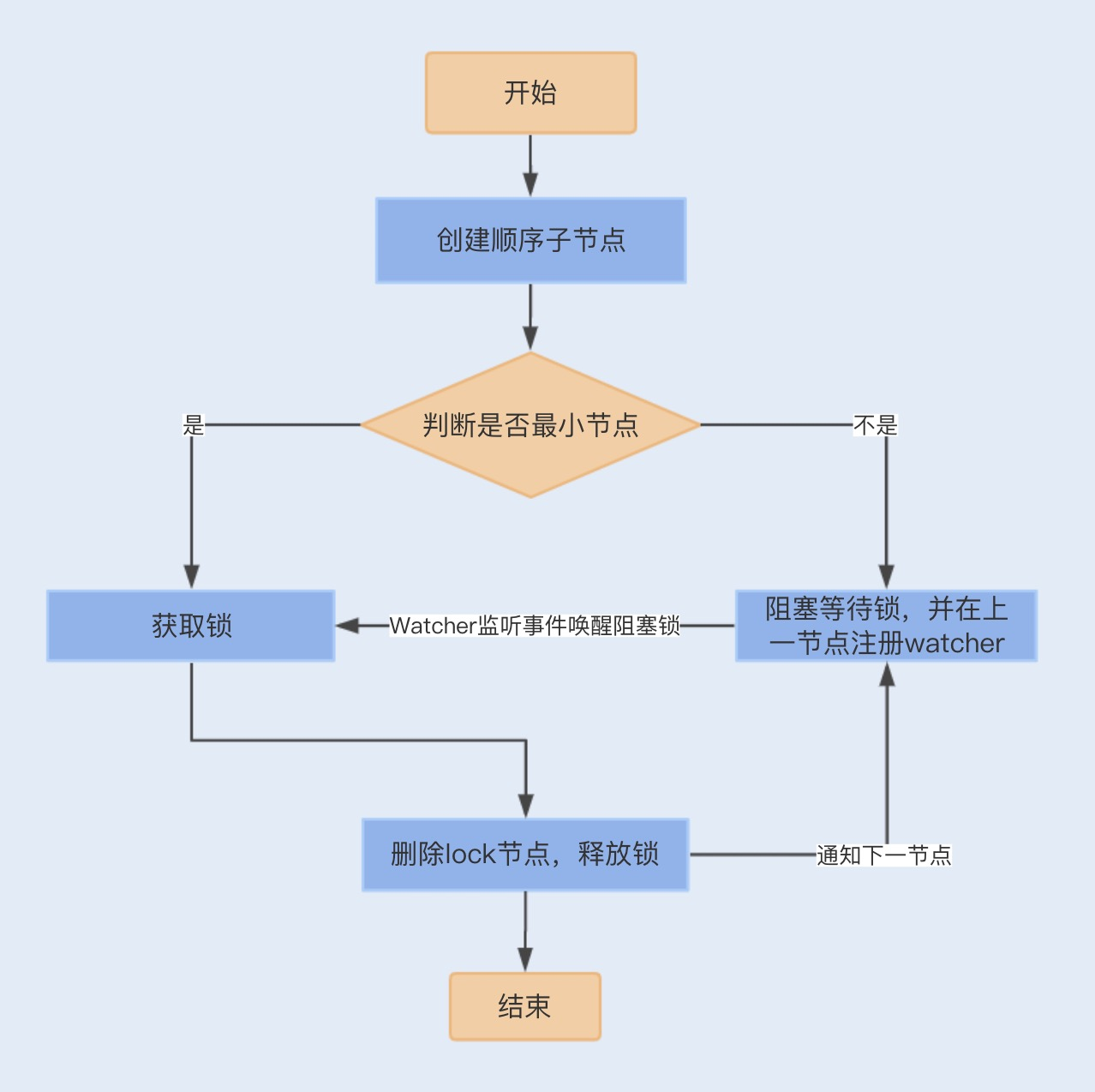
以上实现的分布式锁是严格按照顺序访问的并发锁。一般我们还可以直接引用 Curator 框架来实现 Zookeeper 分布式锁,代码如下:
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
if (lock.acquire(maxWait, waitUnit)) {
try {
// do some work inside of the critical section here
} finally {
lock.release();
}
}Zookeeper 实现的分布式锁,例如相对数据库实现,有很多优点。Zookeeper 是集群实现,可以避免单点问题,且能保证每次操作都可以有效地释放锁,这是因为一旦应用服务挂掉了,临时节点会因为 session 连接断开而自动删除掉。
不好的是由于频繁地创建和删除结点,加上大量的 Watch 事件,对 Zookeeper 集群来说,压力非常大。
1.2.3、Redis 实现
相对于前两种实现方式,基于 Redis 实现的分布式锁是最为复杂的,但性能是最佳的。大部分开发人员利用 Redis 实现分布式锁的方式,都是使用 SETNX+EXPIRE 组合来实现,在 Redis 2.6.12 版本之前,具体实现代码如下:
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
Long result = jedis.setnx(lockKey, requestId); // 设置锁
if (result == 1) { // 获取锁成功
// 若在这里程序突然崩溃,则无法设置过期时间,将发生死锁
jedis.expire(lockKey, expireTime); // 通过过期时间删除锁
return true;
}
return false;
}这种方式实现的分布式锁,是通过 setnx() 方法设置锁,如果 lockKey 存在,则返回失败,否则返回成功。设置成功之后,为了能在完成同步代码之后成功释放锁,方法中还需要使用 expire() 方法给 lockKey 值设置一个过期时间,确认 key 值删除,避免出现锁无法释放,导致下一个线程无法获取到锁,即死锁问题。
如果程序在设置过期时间之前、设置锁之后出现崩溃,此时如果 lockKey 没有设置过期时间,将会出现死锁问题。在 Redis 2.6.12 版本后 SETNX 增加了过期时间参数:
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
/**
* 尝试获取分布式锁
* @param jedis Redis 客户端
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}我们也可以通过 Lua 脚本来实现锁的设置和过期时间的原子性,再通过 jedis.eval() 方法运行该脚本:
// 加锁脚本
private static final String SCRIPT_LOCK = "if redis.call('setnx', KEYS[1], ARGV[1]) == 1 then redis.call('pexpire', KEYS[1], ARGV[2]) return 1 else return 0 end";
// 解锁脚本
private static final String SCRIPT_UNLOCK = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
虽然 SETNX 方法保证了设置锁和过期时间的原子性,但如果我们设置的过期时间比较短,而执行业务时间比较长,就会存在锁代码块失效的问题。我们需要将过期时间设置得足够长,来保证以上问题不会出现。
这个方案是目前最优的分布式锁方案,但如果是在 Redis 集群环境下,依然存在问题。由于 Redis 集群数据同步到各个节点时是异步的,如果在 Master 节点获取到锁后,在没有同步到其它节点时,Master 节点崩溃了,此时新的 Master 节点依然可以获取锁,所以多个应用服务可以同时获取到锁。
1.2.4、Redlock 算法
Redisson 由 Redis 官方推出,它是一个在 Redis 的基础上实现的 Java 驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的 Java 常用对象,还提供了许多分布式服务。Redisson 是基于 netty 通信框架实现的,所以支持非阻塞通信,性能相对于我们熟悉的 Jedis 会好一些。
Redisson 中实现了 Redis 分布式锁,且支持单点模式和集群模式。在集群模式下,Redisson 使用了 Redlock 算法,避免在 Master 节点崩溃切换到另外一个 Master 时,多个应用同时获得锁。我们可以通过一个应用服务获取分布式锁的流程,了解下 Redlock 算法的实现:
在不同的节点上使用单个实例获取锁的方式去获得锁,且每次获取锁都有超时时间,如果请求超时,则认为该节点不可用。当应用服务成功获取锁的 Redis 节点超过半数(N/2+1,N 为节点数) 时,并且获取锁消耗的实际时间不超过锁的过期时间,则获取锁成功。
一旦获取锁成功,就会重新计算释放锁的时间,该时间是由原来释放锁的时间减去获取锁所消耗的时间;而如果获取锁失败,客户端依然会释放获取锁成功的节点。具体的代码实现如下:
- 首先引入 jar 包:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.8.2</version>
</dependency>- 实现 Redisson 的配置文件:
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useClusterServers()
.setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒
.addNodeAddress("redis://127.0.0.1:7000).setPassword("1")
.addNodeAddress("redis://127.0.0.1:7001").setPassword("1")
.addNodeAddress("redis://127.0.0.1:7002")
.setPassword("1");
return Redisson.create(config);
}- 获取锁操作:
long waitTimeout = 10;
long leaseTime = 1;
RLock lock1 = redissonClient1.getLock("lock1");
RLock lock2 = redissonClient2.getLock("lock2");
RLock lock3 = redissonClient3.getLock("lock3");
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 红锁在大部分节点上加锁成功就算成功,且设置总超时时间以及单个节点超时时间
redLock.trylock(waitTimeout,leaseTime,TimeUnit.SECONDS);
...
redLock.unlock();2、分布式事务调优
2.1、前言
某案例是这样的,当玩家购买道具之后,扣除通宝时出现了异常。这种异常在正常情况下发生之后,应该是整个购买操作都需要撤销,然而这次异常的严重性就是在于玩家购买道具成功后,没有扣除通宝。
究其原因是由于购买的道具更新的是游戏数据库,而通宝是在用户账户中心数据库,在一次购买道具时,存在同时操作两个数据库的情况,属于一种分布式事务。而我们的工程师在完成玩家获得道具和扣除余额的操作时,没有做到事务的一致性,即在扣除通宝失败时,应该回滚已经购买的游戏道具。
如今,大部分公司的服务基本都实现了微服务化,首先是业务需求,为了解耦业务;其次是为了减少业务与业务之间的相互影响。
电商系统亦是如此,大部分公司的电商系统都是分为了不同服务模块,例如商品模块、订单模块、库存模块等等。事实上,分解服务是一把双刃剑,可以带来一些开发、性能以及运维上的优势,但同时也会增加业务开发的逻辑复杂度。其中最为突出的就是分布式事务了。
通常,存在分布式事务的服务架构部署有以下两种:同服务不同数据库,不同服务不同数据库。我们以商城为例,用图示说明下这两种部署:
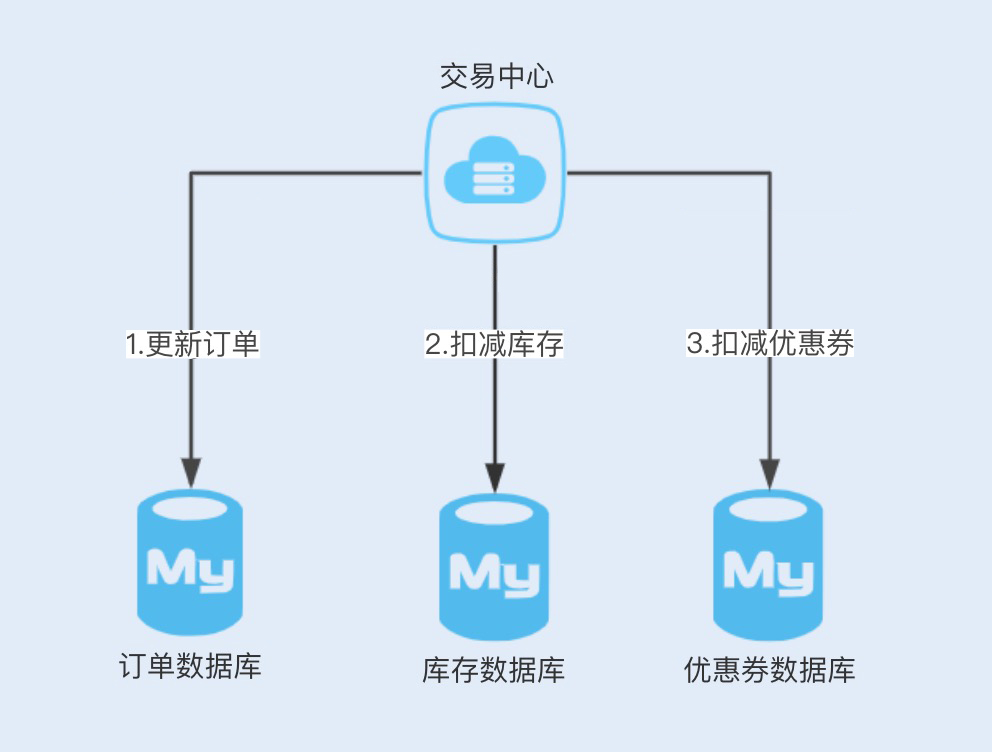
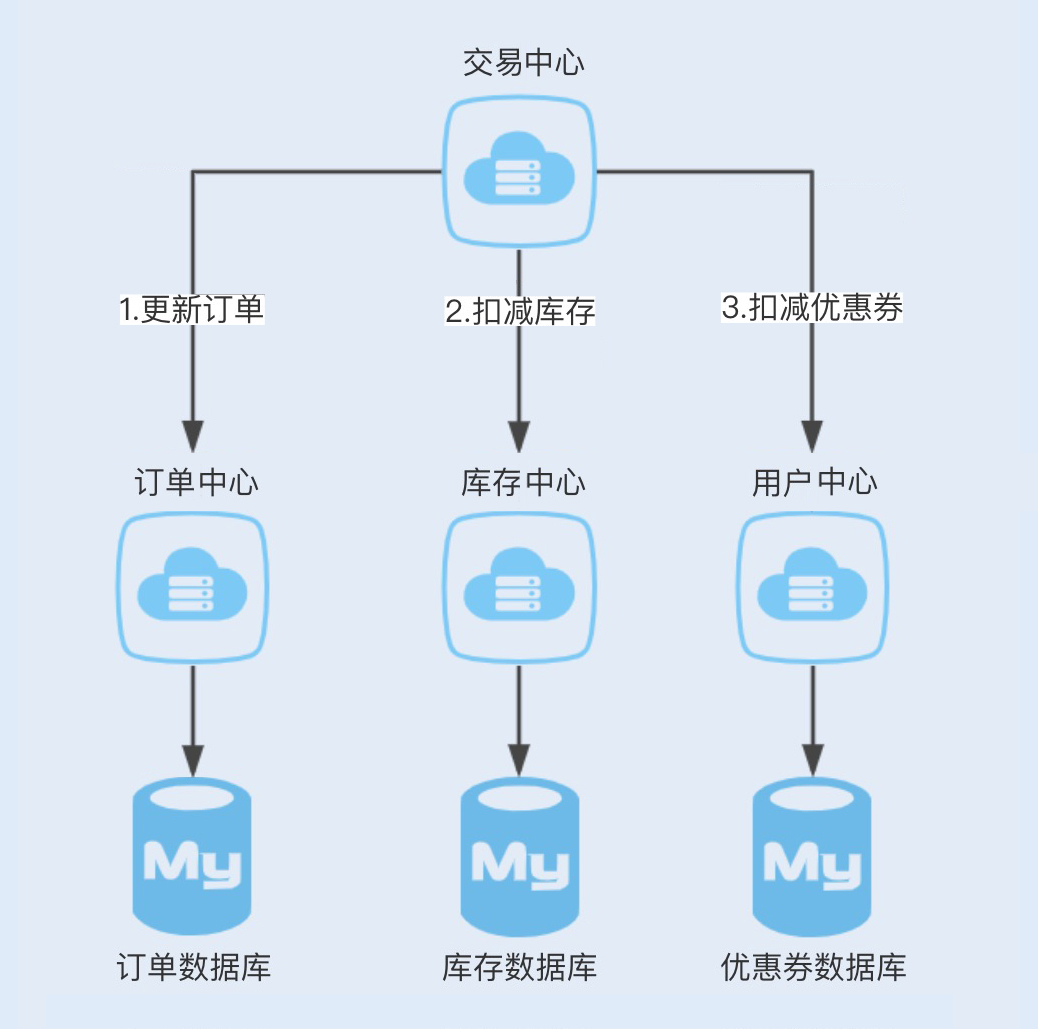
2.2、分布式事务解决方案
在单个数据库的情况下,数据事务操作具有 ACID 四个特性,但如果在一个事务中操作多个数据库,则无法使用数据库事务来保证一致性。
也就是说,当两个数据库操作数据时,可能存在一个数据库操作成功,而另一个数据库操作失败的情况,我们无法通过单个数据库事务来回滚两个数据操作。
而分布式事务就是为了解决在同一个事务下,不同节点的数据库操作数据不一致的问题。在一个事务操作请求多个服务或多个数据库节点时,要么所有请求成功,要么所有请求都失败回滚回去。通常,分布式事务的实现有多种方式,例如 XA 协议实现的二阶提交(2PC)、三阶提交 (3PC),以及 TCC 补偿性事务。
2.2.1、XA 规范
在 XA 规范之前,存在着一个 DTP 模型,该模型规范了分布式事务的模型设计。
DTP 规范中主要包含了 AP、RM、TM 三个部分,其中 AP 是应用程序,是事务发起和结束的地方;RM 是资源管理器,主要负责管理每个数据库的连接数据源;TM 是事务管理器,负责事务的全局管理,包括事务的生命周期管理和资源的分配协调等。
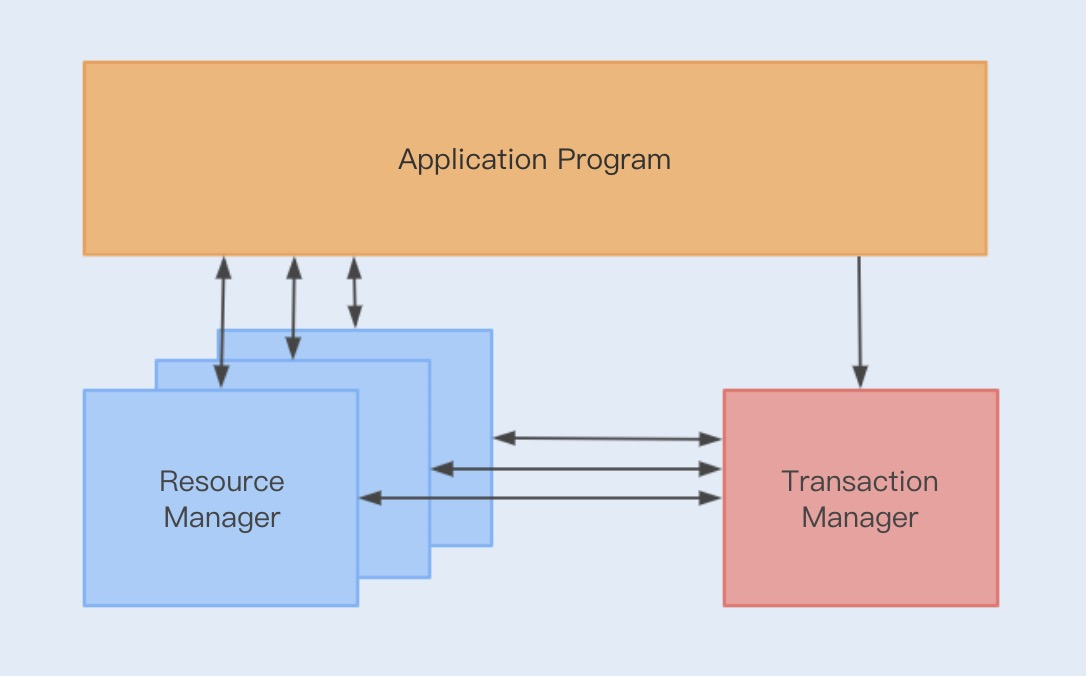
XA 则规范了 TM 与 RM 之间的通信接口,在 TM 与多个 RM 之间形成一个双向通信桥梁,从而在多个数据库资源下保证 ACID 四个特性。
这里强调一下,JTA 是基于 XA 规范实现的一套 Java 事务编程接口,是一种两阶段提交事务。我们可以通过源码简单了解下 JTA 实现的多数据源事务提交。
2.2.2、二阶提交和三阶提交
XA 规范实现的分布式事务属于二阶提交事务,顾名思义就是通过两个阶段来实现事务的提交。
在第一阶段,应用程序向事务管理器(TM)发起事务请求,而事务管理器则会分别向参与的各个资源管理器(RM)发送事务预处理请求(Prepare),此时这些资源管理器会打开本地数据库事务,然后开始执行数据库事务,但执行完成后并不会立刻提交事务,而是向事务管理器返回已就绪(Ready)或未就绪(Not Ready)状态。如果各个参与节点都返回状态了,就会进入第二阶段。
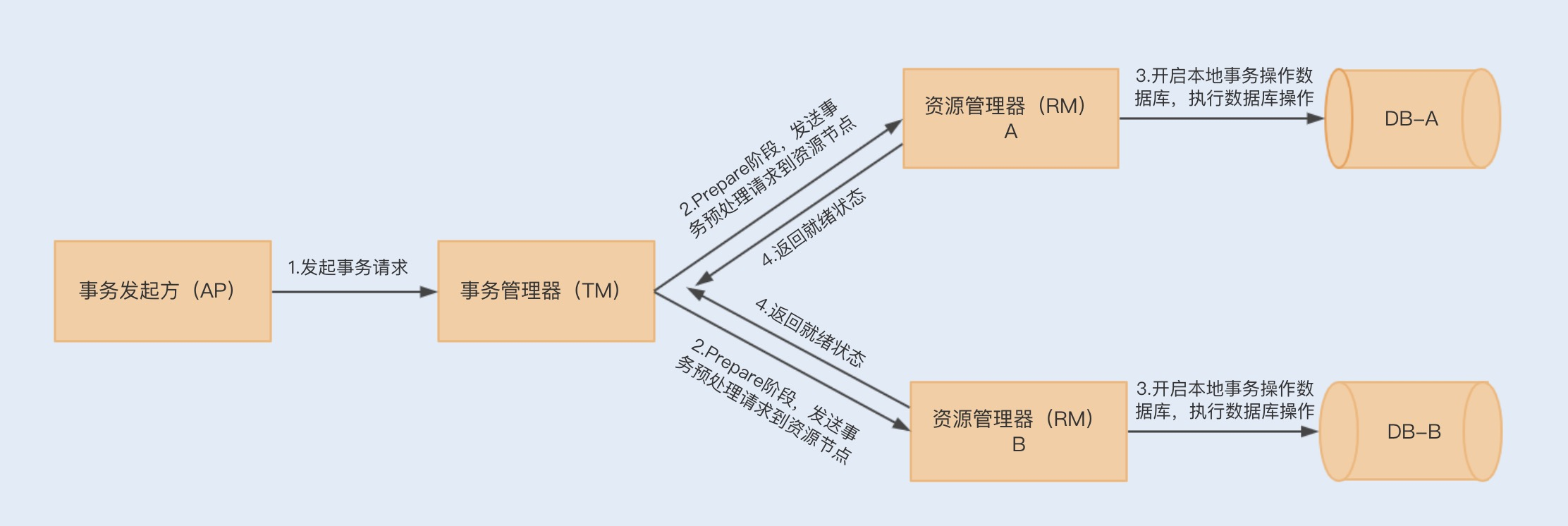
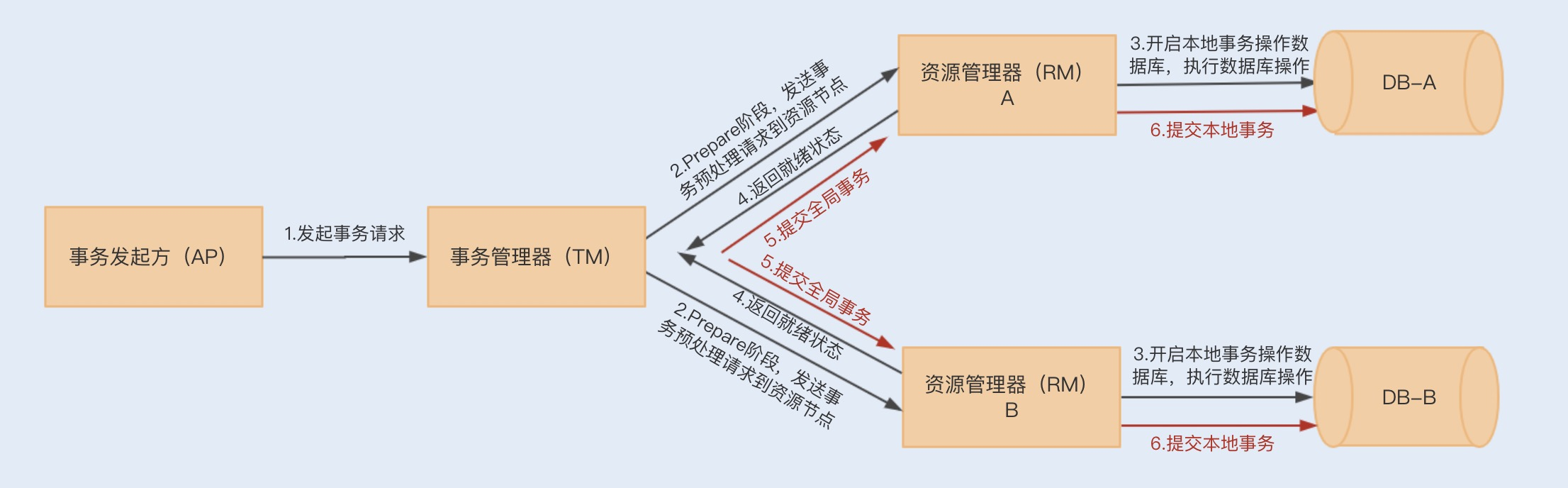
到了第二阶段,如果资源管理器返回的都是就绪状态,事务管理器则会向各个资源管理器发送提交(Commit)通知,资源管理器则会完成本地数据库的事务提交,最终返回提交结果给事务管理器。
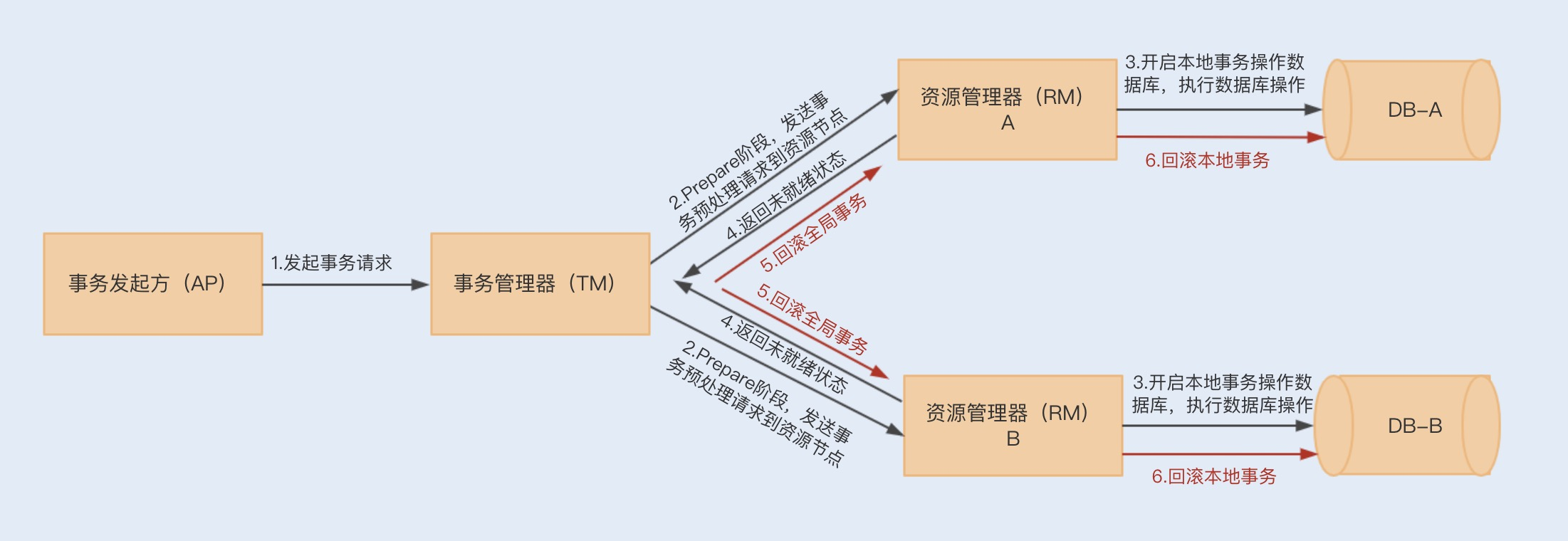
在第二阶段中,如果任意资源管理器返回了未就绪状态,此时事务管理器会向所有资源管理器发送事务回滚(Rollback)通知,此时各个资源管理器就会回滚本地数据库事务,释放资源,并返回结果通知。
但事实上,二阶事务提交也存在一些缺陷。
第一,在整个流程中,我们会发现各个资源管理器节点存在阻塞,只有当所有的节点都准备完成之后,事务管理器才会发出进行全局事务提交的通知,这个过程如果很长,则会有很多节点长时间占用资源,从而影响整个节点的性能。
一旦资源管理器挂了,就会出现一直阻塞等待的情况。类似问题,我们可以通过设置事务超时时间来解决。
第二,仍然存在数据不一致的可能性,例如,在最后通知提交全局事务时,由于网络故障,部分节点有可能收不到通知,由于这部分节点没有提交事务,就会导致数据不一致的情况出现。
而三阶事务(3PC)的出现就是为了减少此类问题的发生。
3PC 把 2PC 的准备阶段分为了准备阶段和预处理阶段,在第一阶段只是询问各个资源节点是否可以执行事务,而在第二阶段,所有的节点反馈可以执行事务,才开始执行事务操作,最后在第三阶段执行提交或回滚操作。并且在事务管理器和资源管理器中都引入了超时机制,如果在第三阶段,资源节点一直无法收到来自资源管理器的提交或回滚请求,它就会在超时之后,继续提交事务。
所以 3PC 可以通过超时机制,避免管理器挂掉所造成的长时间阻塞问题,但其实这样还是无法解决在最后提交全局事务时,由于网络故障无法通知到一些节点的问题,特别是回滚通知,这样会导致事务等待超时从而默认提交。
2.2.3、事务补偿机制(TCC)
以上这种基于 XA 规范实现的事务提交,由于阻塞等性能问题,有着比较明显的低性能、低吞吐的特性。所以在抢购活动中使用该事务,很难满足系统的并发性能。
除了性能问题,JTA 只能解决同一服务下操作多数据源的分布式事务问题,换到微服务架构下,可能存在同一个事务操作,分别在不同服务上连接数据源,提交数据库操作。
而 TCC 正是为了解决以上问题而出现的一种分布式事务解决方案。TCC 采用最终一致性的方式实现了一种柔性分布式事务,与 XA 规范实现的二阶事务不同的是,TCC 的实现是基于服务层实现的一种二阶事务提交。TCC 分为三个阶段,即 Try、Confirm、Cancel 三个阶段。
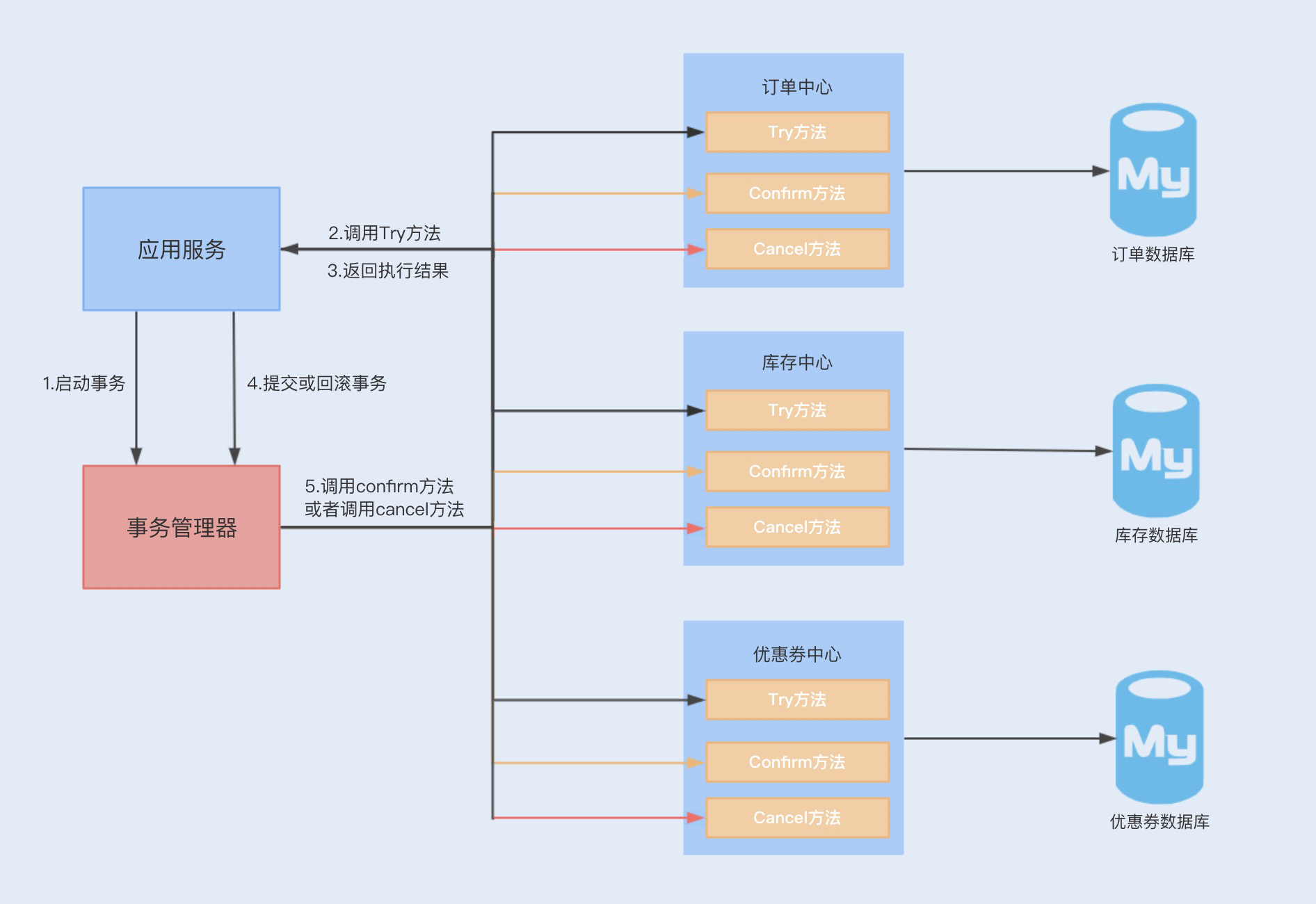
- Try 阶段:主要尝试执行业务,执行各个服务中的 Try 方法,主要包括预留操作;
- Confirm 阶段:确认 Try 中的各个方法执行成功,然后通过 TM 调用各个服务的 Confirm 方法,这个阶段是提交阶段;
- Cancel 阶段:当在 Try 阶段发现其中一个 Try 方法失败,例如预留资源失败、代码异常等,则会触发 TM 调用各个服务的 Cancel 方法,对全局事务进行回滚,取消执行业务。
以上执行只是保证 Try 阶段执行时成功或失败的提交和回滚操作,你肯定会想到,如果在 Confirm 和 Cancel 阶段出现异常情况,那 TCC 该如何处理呢?此时 TCC 会不停地重试调用失败的 Confirm 或 Cancel 方法,直到成功为止。
TCC 补偿性事务也有比较明显的缺点,那就是对业务的侵入性非常大。首先,我们需要在业务设计的时候考虑预留资源;然后,我们需要编写大量业务性代码,例如 Try、Confirm、Cancel 方法;最后,我们还需要为每个方法考虑幂等性。这种事务的实现和维护成本非常高,但综合来看,这种实现是目前大家最常用的分布式事务解决方案。
2.2.4、业务无侵入方案——Seata(Fescar)
Seata 的基础建模和 DTP 模型类似,只不过前者是将事务管理器分得更细了,抽出一个事务协调器(Transaction Coordinator 简称 TC),主要维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。而 TM 则负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。如下图所示:
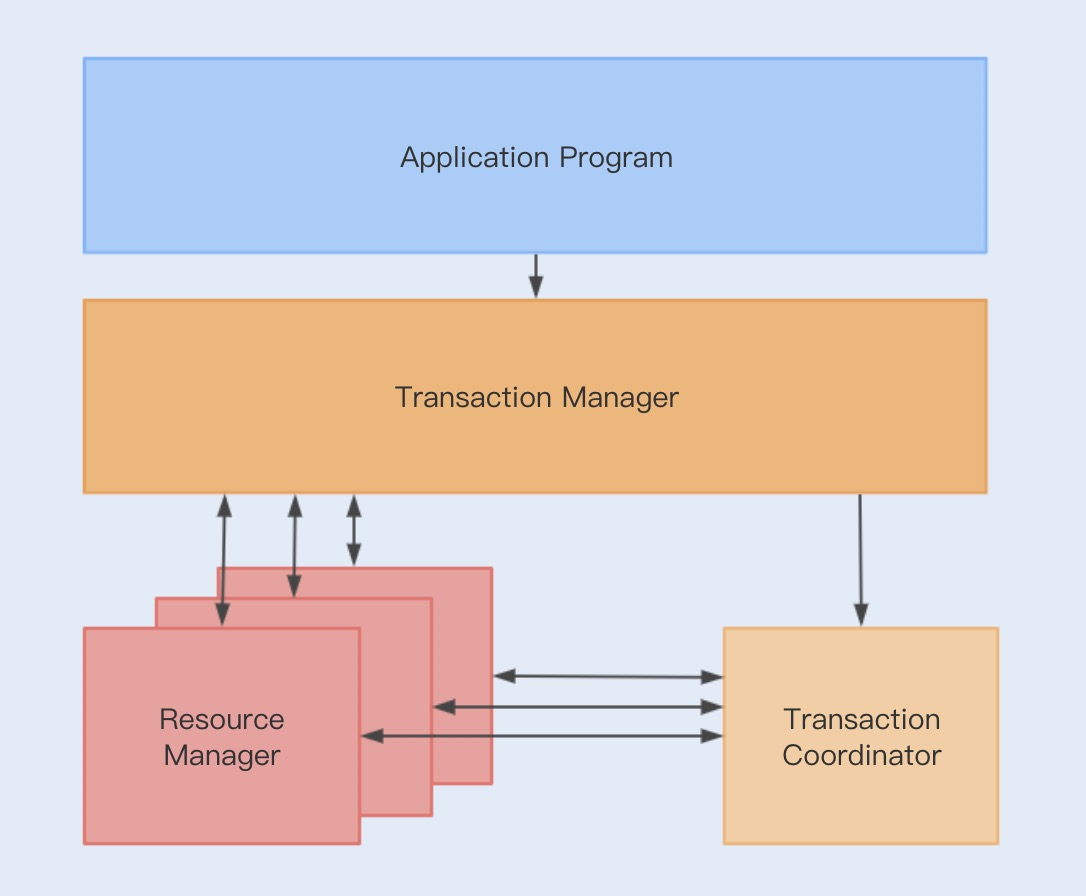
按照Github中的说明介绍,整个事务流程为:
- TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID;
- XID 在微服务调用链路的上下文中传播;
- RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖;
- TM 向 TC 发起针对 XID 的全局提交或回滚决议;
- TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
Seata 与其它分布式最大的区别在于,它在第一提交阶段就已经将各个事务操作 commit 了。Seata 认为在一个正常的业务下,各个服务提交事务的大概率是成功的,这种事务提交操作可以节约两个阶段持有锁的时间,从而提高整体的执行效率。
那如果在第一阶段就已经提交了事务,那我们还谈何回滚呢?
Seata 将 RM 提升到了服务层,通过 JDBC 数据源代理解析 SQL,把业务数据在更新前后的数据镜像组织成回滚日志,利用本地事务的 ACID 特性,将业务数据的更新和回滚日志的写入在同一个本地事务中提交。
如果 RM 决议要全局回滚,会通知 RM 进行回滚操作,通过 XID 找到对应的回滚日志记录,通过回滚记录生成反向更新 SQL,进行更新回滚操作。
隔离性如何保证呢?
Seata 设计通过事务协调器维护的全局写排它锁,来保证事务间的写隔离,而读写隔离级别则默认为未提交读的隔离级别。
3、使用缓存优化性能
3.1、前端缓存技术
3.1.1、本地缓存
平时使用拦截器(例如 Fiddler)或浏览器 Debug 时,我们经常会发现一些接口返回 304 状态码 + Not Modified 字符串,如下图中的极客时间 Web 首页。
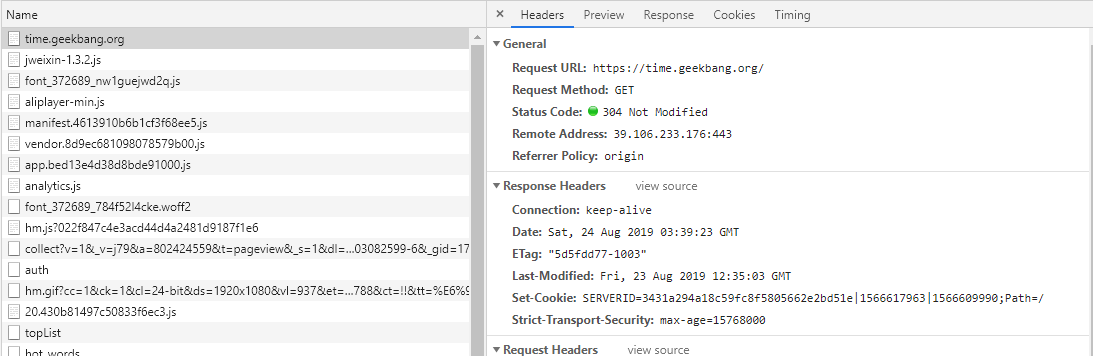
如果我们对前端缓存技术不了解,就很容易对此感到困惑。浏览器常用的一种缓存就是这种基于 304 响应状态实现的本地缓存了,通常这种缓存被称为协商缓存。
协商缓存,顾名思义就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。
一般协商缓存可以基于请求头部中的 If-Modified-Since 字段与返回头部中的 Last-Modified 字段实现,也可以基于请求头部中的 If-None-Match 字段与返回头部中的 ETag 字段来实现。
两种方式的实现原理是一样的,前者是基于时间实现的,后者是基于一个唯一标识实现的,相对来说后者可以更加准确地判断文件内容是否被修改,避免由于时间篡改导致的不可靠问题。下面我们再来了解下整个缓存的实现流程:
- 当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在 Response 头部加上 ETag 唯一标识,这个唯一标识的值是根据当前请求的资源生成的;
- 当浏览器再次请求访问服务器中的该资源时,会在 Request 头部加上 If-None-Match 字段,该字段的值就是 Response 头部加上 ETag 唯一标识;
- 服务器再次收到请求后,会根据请求中的 If-None-Match 值与当前请求的资源生成的唯一标识进行比较,如果值相等,则返回 304 Not Modified,如果不相等,则在 Response 头部加上新的 ETag 唯一标识,并返回资源;
- 如果浏览器收到 304 的请求响应状态码,则会从本地缓存中加载资源,否则更新资源。
本地缓存中除了这种协商缓存,还有一种就是强缓存的实现。强缓存指的是只要判断缓存没有过期,则直接使用浏览器的本地缓存。如下图中,返回的是 200 状态码,但在 size 项中标识的是 memory cache。
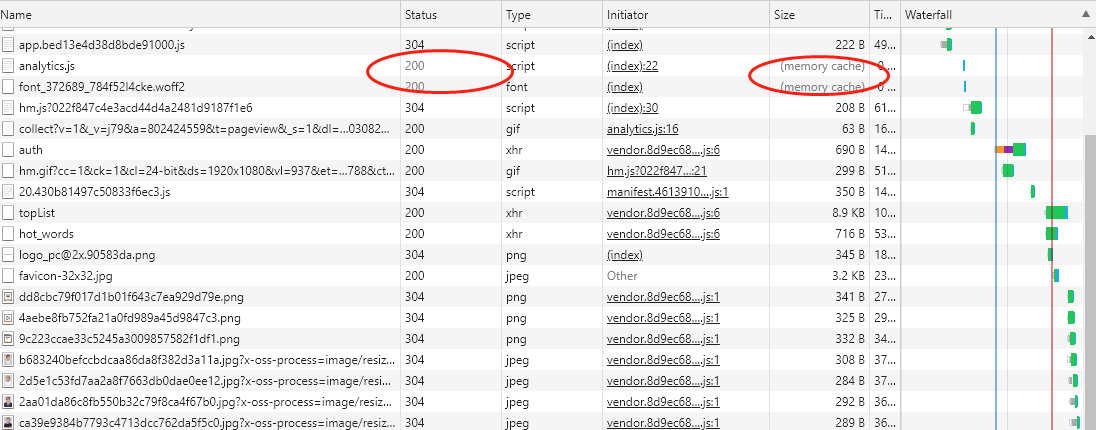
强缓存是利用 Expires 或者 Cache-Control 这两个 HTTP Response Header 实现的,它们都用来表示资源在客户端缓存的有效期。
Expires 是一个绝对时间,而 Cache-Control 是一个相对时间,即一个过期时间大小,与协商缓存一样,基于 Expires 实现的强缓存也会因为时间问题导致缓存管理出现问题。我建议使用 Cache-Control 来实现强缓存。具体的实现流程如下:
- 当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在 Response 头部加上 Cache-Control,Cache-Control 中设置了过期时间大小;
- 浏览器再次请求访问服务器中的该资源时,会先通过请求资源的时间与 Cache-Control 中设置的过期时间大小,来计算出该资源是否过期,如果没有,则使用该缓存,否则请求服务器;
- 服务器再次收到请求后,会再次更新 Response 头部的 Cache-Control。
3.1.2、网关缓存
除了以上本地缓存,我们还可以在网关中设置缓存,也就是我们熟悉的 CDN。
CDN 缓存是通过不同地点的缓存节点缓存资源副本,当用户访问相应的资源时,会调用最近的 CDN 节点返回请求资源,这种方式常用于视频资源的缓存。
3.2、服务层缓存技术
前端缓存一般用于缓存一些不常修改的常量数据或一些资源文件,大部分接口请求的数据都缓存在了服务端,方便统一管理缓存数据。
服务端缓存的初衷是为了提升系统性能。例如,数据库由于并发查询压力过大,可以使用缓存减轻数据库压力;在后台管理中的一些报表计算类数据,每次请求都需要大量计算,消耗系统 CPU 资源,我们可以使用缓存来保存计算结果。
服务端的缓存也分为进程缓存和分布式缓存,在 Java 中进程缓存就是 JVM 实现的缓存,常见的有我们经常使用的容器类,ArrayList、ConcurrentHashMap 等,分布式缓存则是基于 Redis 实现的缓存。
3.2.1、进程缓存
对于进程缓存,虽然数据的存取会更加高效,但 JVM 的堆内存数量是有限的,且在分布式环境下很难同步各个服务间的缓存更新,所以我们一般缓存一些数据量不大、更新频率较低的数据。常见的实现方式如下:
// 静态常量
public final staticS String url = "https://time.geekbang.org";
//list 容器
public static List<String> cacheList = new Vector<String>();
//map 容器
private static final Map<String, Object> cacheMap= new ConcurrentHashMap<String, Object>();除了 Java 自带的容器可以实现进程缓存,我们还可以基于 Google 实现的一套内存缓存组件 Guava Cache 来实现。
Guava Cache 适用于高并发的多线程缓存,它和 ConcurrentHashMap 一样,都是基于分段锁实现的并发缓存。
Guava Cache 同时也实现了数据淘汰机制,当我们设置了缓存的最大值后,当存储的数据超过了最大值时,它就会使用 LRU 算法淘汰数据。我们可以通过以下代码了解下 Guava Cache 的实现:
public class GuavaCacheDemo {
public static void main(String[] args) {
Cache<String,String> cache = CacheBuilder.newBuilder()
.maximumSize(2)
.build();
cache.put("key1","value1");
cache.put("key2","value2");
cache.put("key3","value3");
System.out.println(" 第一个值:" + cache.getIfPresent("key1"));
System.out.println(" 第二个值:" + cache.getIfPresent("key2"));
System.out.println(" 第三个值:" + cache.getIfPresent("key3"));
}
}
//第一个值:null
//第二个值:value2
//第三个值:value3那如果我们的数据量比较大,且数据更新频繁,又是在分布式部署的情况下,想要使用 JVM 堆内存作为缓存,这时我们又该如何去实现呢?
Ehcache 是一个不错的选择,Ehcache 经常在 Hibernate 中出现,主要用来缓存查询数据结果。Ehcache 是 Apache 开源的一套缓存管理类库,是基于 JVM 堆内存实现的缓存,同时具备多种缓存失效策略,支持磁盘持久化以及分布式缓存机制。
3.2.2、分布式缓存
由于高并发对数据一致性的要求比较严格,我一般不建议使用 Ehcache 缓存有一致性要求的数据。对于分布式缓存,我们建议使用 Redis 来实现,Redis 相当于一个内存数据库,由于是纯内存操作,又是基于单线程串行实现,查询性能极高,读速度超过了 10W 次 / 秒。
Redis 除了高性能的特点之外,还支持不同类型的数据结构,常见的有 string、list、set、hash 等,还支持数据淘汰策略、数据持久化以及事务等。
3.3、数据库与缓存数据一致性问题
在查询缓存数据时,我们会先读取缓存,如果缓存中没有该数据,则会去数据库中查询,之后再放入到缓存中。
当我们的数据被缓存之后,一旦数据被修改(修改时也是删除缓存中的数据)或删除,我们就需要同时操作缓存和数据库。这时,就会存在一个数据不一致的问题。
例如,在并发情况下,当 A 操作使得数据发生删除变更,那么该操作会先删除缓存中的数据,之后再去删除数据库中的数据,此时若是还没有删除成功,另外一个请求查询操作 B 进来了,发现缓存中已经没有了数据,则会去数据库中查询,此时发现有数据,B 操作获取之后又将数据存放在了缓存中,随后数据库的数据又被删除了。此时就出现了数据不一致的情况。
那如果先删除数据库,再删除缓存呢?
所以,我们还是需要先做缓存删除操作,再去完成数据库操作。那我们又该如何避免高并发下,数据更新删除操作所带来的数据不一致的问题呢?
通常的解决方案是,如果我们需要使用一个线程安全队列来缓存更新或删除的数据,当 A 操作变更数据时,会先删除一个缓存数据,此时通过线程安全的方式将缓存数据放入到队列中,并通过一个线程进行数据库的数据删除操作。
当有另一个查询请求 B 进来时,如果发现缓存中没有该值,则会先去队列中查看该数据是否正在被更新或删除,如果队列中有该数据,则阻塞等待,直到 A 操作数据库成功之后,唤醒该阻塞线程,再去数据库中查询该数据。
但其实这种实现也存在很多缺陷,例如,可能存在读请求被长时间阻塞,高并发时低吞吐量等问题。所以我们在考虑缓存时,如果数据更新比较频繁且对数据有一定的一致性要求,通常不建议使用缓存。
3.4、缓存穿透、缓存击穿、缓存雪崩
对于分布式缓存实现大数据的存储,除了数据不一致的问题以外,还有缓存穿透、缓存击穿、缓存雪崩等问题,我们平时实现缓存代码时,应该充分、全面地考虑这些问题。
缓存穿透是指大量查询没有命中缓存,直接去到数据库中查询,如果查询量比较大,会导致数据库的查询流量大,对数据库造成压力。
通常有两种解决方案,一种是将第一次查询的空值缓存起来,同时设置一个比较短的过期时间。但这种解决方案存在一个安全漏洞,就是当黑客利用大量没有缓存的 key 攻击系统时,缓存的内存会被占满溢出。
另一种则是使用布隆过滤算法(BloomFilter),该算法可以用于检查一个元素是否存在,返回结果有两种:可能存在或一定不存在。这种情况很适合用来解决故意攻击系统的缓存穿透问题,在最初缓存数据时也将 key 值缓存在布隆过滤器的 BitArray 中,当有 key 值查询时,对于一定不存在的 key 值,我们可以直接返回空值,对于可能存在的 key 值,我们会去缓存中查询,如果没有值,再去数据库中查询。
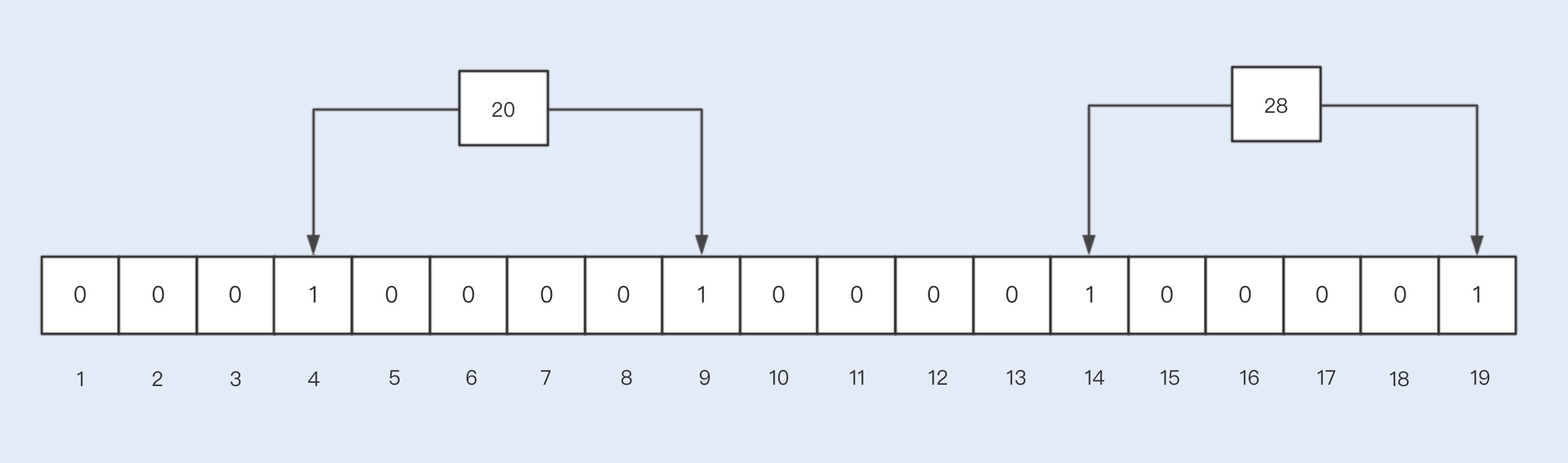
BloomFilter 的实现原理与 Redis 中的 BitMap 类似,首先初始化一个 m 长度的数组,并且每个 bit 初始化值都是 0,当插入一个元素时,会使用 n 个 hash 函数来计算出 n 个不同的值,分别代表所在数组的位置,然后再将这些位置的值设置为 1。
假设我们插入两个 key 值分别为 20,28 的元素,通过两次哈希函数取模后的值分别为 4,9 以及 14,19,因此 4,9 以及 14,19 都被设置为 1。
为什么说 BloomFilter 返回的结果是可能存在和一定不存在呢?
假设我们查找一个元素 25,通过 n 次哈希函数取模后的值为 1,9,14。此时在 BitArray 中肯定是不存在的。而当我们查找一个元素 21 的时候,n 次哈希函数取模后的值为 9,14,此时会返回可能存在的结果,但实际上是不存在的。
BloomFilter 不允许删除任何元素的,为什么?假设以上 20,25,28 三个元素都存在于 BitArray 中,取模的位置值分别为 4,9、1,9,14 以及 14,19,如果我们要删除元素 25,此时需要将 1,9,14 的位置都置回 0,这样就影响 20,28 元素了。
因此,BloomFilter 是不允许删除任何元素的,这样会导致已经删除的元素依然返回可能存在的结果,也会影响 BloomFilter 判断的准确率,解决的方法则是重建一个 BitArray。
那什么缓存击穿呢?在高并发情况下,同时查询一个 key 时,key 值由于某种原因突然失效(设置过期时间或缓存服务宕机),就会导致同一时间,这些请求都去查询数据库了。这种情况经常出现在查询热点数据的场景中。通常我们会在查询数据库时,使用排斥锁来实现有序地请求数据库,减少数据库的并发压力。
缓存雪崩则与缓存击穿差不多,区别就是失效缓存的规模。雪崩一般是指发生大规模的缓存失效情况,例如,缓存的过期时间同一时间过期了,缓存服务宕机了。对于大量缓存的过期时间同一时间过期的问题,我们可以采用分散过期时间来解决;而针对缓存服务宕机的情况,我们可以采用分布式集群来实现缓存服务。
4、抢购案例
4.1、抢购业务流程
在进行具体的性能问题讨论之前,我们不妨先来了解下一个常规的抢购业务流程,这样方便我们更好地理解一个抢购系统的性能瓶颈以及调优过程。
- 用户登录后会进入到商品详情页面,此时商品购买处于倒计时状态,购买按钮处于置灰状态。
- 当购买倒计时间结束后,用户点击购买商品,此时用户需要排队等待获取购买资格,如果没有获取到购买资格,抢购活动结束,反之,则进入提交页面。
- 用户完善订单信息,点击提交订单,此时校验库存,并创建订单,进入锁定库存状态,之后,用户支付订单款。
- 当用户支付成功后,第三方支付平台将产生支付回调,系统通过回调更新订单状态,并扣除数据库的实际库存,通知用户购买成功。
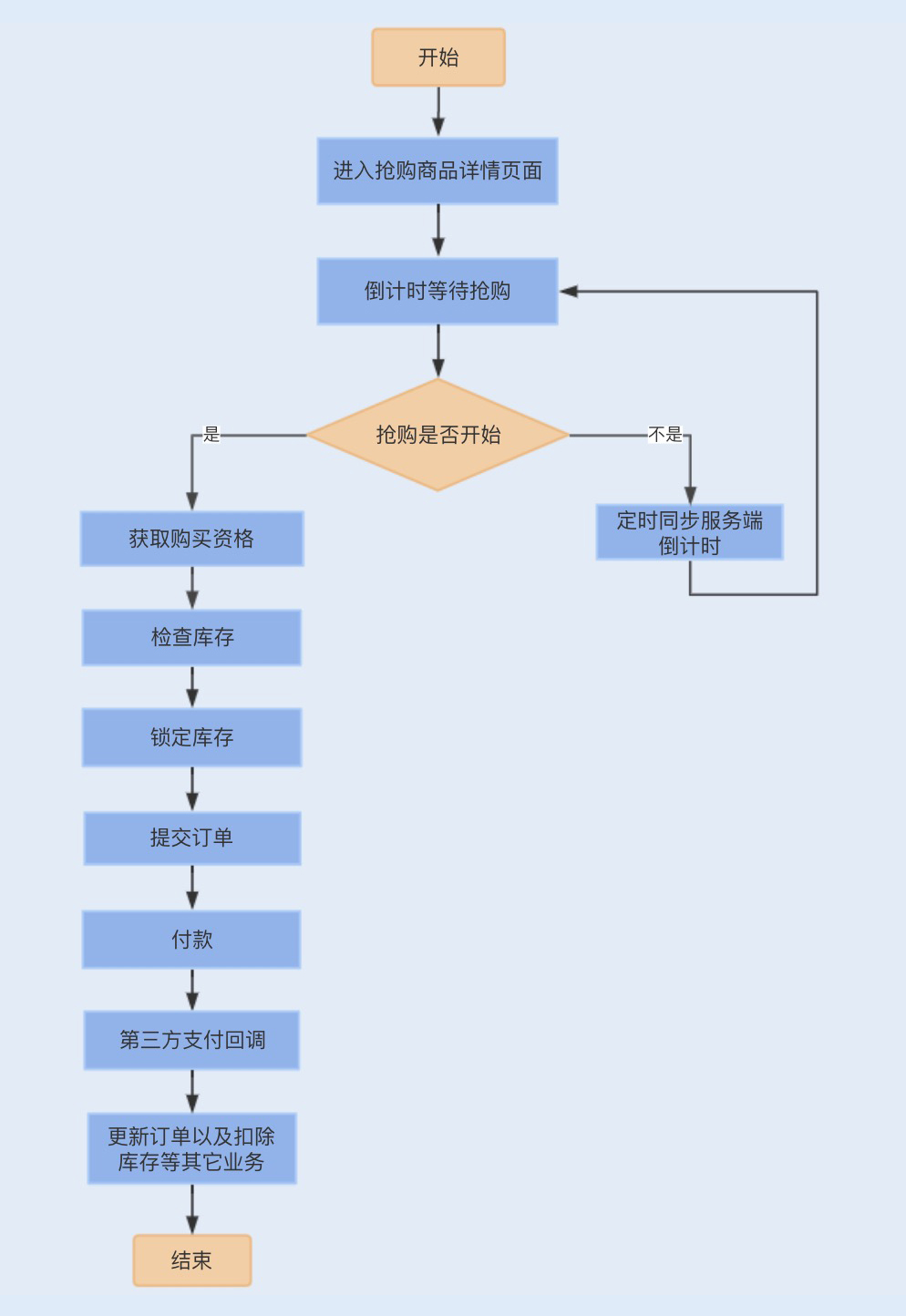
4.2、存在的性能瓶颈
4.2.1、商品详情页面
如果你有过抢购商品的经验,相信你遇到过这样一种情况,在抢购马上到来的时候,商品详情页面几乎是无法打开的。
这是因为大部分用户在抢购开始之前,会一直疯狂刷新抢购商品页面,尤其是倒计时一分钟内,查看商品详情页面的请求量会猛增。此时如果商品详情页面没有做好,就很容易成为整个抢购系统中的第一个性能瓶颈。
类似这种问题,我们通常的做法是提前将整个抢购商品页面生成为一个静态页面,并 push 到 CDN 节点,并且在浏览器端缓存该页面的静态资源文件,通过 CDN 和浏览器本地缓存这两种缓存静态页面的方式来实现商品详情页面的优化。
4.2.2、抢购倒计时
在商品详情页面中,存在一个抢购倒计时,这个倒计时是服务端时间的,初始化时间需要从服务端获取,并且在用户点击购买时,还需要服务端判断抢购时间是否已经到了。
如果商品详情每次刷新都去后端请求最新的时间,这无疑将会把整个后端服务拖垮。我们可以改成初始化时间从客户端获取,每隔一段时间主动去服务端刷新同步一次倒计时,这个时间段是随机时间,避免集中请求服务端。这种方式可以避免用户主动刷新服务端的同步时间接口。
4.2.3、获取购买资格
可能你会好奇,在抢购中我们已经通过库存数量限制用户了,那为什么会出现一个获取购买资格的环节呢?
我们知道,进入订单详情页面后,需要填写相关的订单信息,例如收货地址、联系方式等,在这样一个过程中,很多用户可能还会犹豫,甚至放弃购买。如果把这个环节设定为一定能购买成功,那我们就只能让同等库存的用户进来,一旦用户放弃购买,这些商品可能无法再次被其他用户抢购,会大大降低商品的抢购销量。
增加购买资格的环节,选择让超过库存的用户量进来提交订单页面,这样就可以保证有足够提交订单的用户量,确保抢购活动中商品的销量最大化。
获取购买资格这步的并发量会非常大,还是基于分布式的,通常我们可以通过 Redis 分布式锁来控制购买资格的发放。
4.2.4、提交订单
由于抢购入口的请求量会非常大,可能会占用大量带宽,为了不影响提交订单的请求,我建议将提交订单的子域名与抢购子域名区分开,分别绑定不同网络的服务器。
用户点击提交订单,需要先校验库存,库存足够时,用户先扣除缓存中的库存,再生成订单。如果校验库存和扣除库存都是基于数据库实现的,那么每次都去操作数据库,瞬时的并发量就会非常大,对数据库来说会存在一定的压力,从而会产生性能瓶颈。与获取购买资格一样,我们同样可以通过分布式锁来优化扣除消耗库存的设计。
由于我们已经缓存了库存,所以在提交订单时,库存的查询和冻结并不会给数据库带来性能瓶颈。但在这之后,还有一个订单的幂等校验,为了提高系统性能,我们同样可以使用分布式锁来优化。
而保存订单信息一般都是基于数据库表来实现的,在单表单库的情况下,碰到大量请求,特别是在瞬时高并发的情况下,磁盘 I/O、数据库请求连接数以及带宽等资源都可能会出现性能瓶颈。此时我们可以考虑对订单表进行分库分表,通常我们可以基于 userid 字段来进行 hash 取模,实现分库分表,从而提高系统的并发能力。
4.2.5、支付回调业务操作
在用户支付订单完成之后,一般会有第三方支付平台回调我们的接口,更新订单状态。
除此之外,还可能存在扣减数据库库存的需求。如果我们的库存是基于缓存来实现查询和扣减,那提交订单时的扣除库存就只是扣除缓存中的库存,为了减少数据库的并发量,我们会在用户付款之后,在支付回调的时候去选择扣除数据库中的库存。
此外,还有订单购买成功的短信通知服务,一些商城还提供了累计积分的服务。
在支付回调之后,我们可以通过异步提交的方式,实现订单更新之外的其它业务处理,例如库存扣减、积分累计以及短信通知等。通常我们可以基于 MQ 实现业务的异步提交。
4.3、性能瓶颈调优
4.3.1、限流实现优化
限流是我们常用的兜底策略,无论是倒计时请求接口,还是抢购入口,系统都应该对它们设置最大并发访问数量,防止超出预期的请求集中进入系统,导致系统异常。
通常我们是在网关层实现高并发请求接口的限流,如果我们使用了 Nginx 做反向代理的话,就可以在 Nginx 配置限流算法。Nginx 是基于漏桶算法实现的限流,这样做的好处是能够保证请求的实时处理速度。
Nginx 中包含了两个限流模块:ngx_http_limit_conn_module 和 ngx_http_limit_req_module,前者是用于限制单个 IP 单位时间内的请求数量,后者是用来限制单位时间内所有 IP 的请求数量。以下分别是两个限流的配置:
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location / {
limit_conn addr 1;
}http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location / {
limit_req zone=one burst=5 nodelay;
}
} 在网关层,我们还可以通过 lua 编写 OpenResty 来实现一套限流功能,也可以通过现成的 Kong 安装插件来实现。除了网关层的限流之外,我们还可以基于服务层实现接口的限流,通过 Zuul RateLimit 或 Guava RateLimiter 实现。
4.3.2、流量削峰
瞬间有大量请求进入到系统后台服务之后,首先是要通过 Redis 分布式锁获取购买资格,这个时候我们看到了大量的“JedisConnectionException Could not get connection from pool”异常。
这个异常是一个 Redis 连接异常,由于我们当时的 Redis 集群是基于哨兵模式部署的,哨兵模式部署的 Redis 也是一种主从模式,我们在写 Redis 的时候都是基于主库来实现的,在高并发操作一个 Redis 实例就很容易出现性能瓶颈。
你可能会想到使用集群分片的方式来实现,但对于分布式锁来说,集群分片的实现只会增加性能消耗,这是因为我们需要基于 Redission 的红锁算法实现,需要对集群的每个实例进行加锁。
后来我们使用 Redission 插件替换 Jedis 插件,由于 Jedis 的读写 I/O 操作还是阻塞式的,方法调用都是基于同步实现,而 Redission 底层是基于 Netty 框架实现的,读写 I/O 是非阻塞 I/O 操作,且方法调用是基于异步实现。
但在瞬时并发非常大的情况下,依然会出现类似问题,此时,我们可以考虑在分布式锁前面新增一个等待队列,减缓抢购出现的集中式请求,相当于一个流量削峰。当请求的 key 值放入到队列中,请求线程进入阻塞状态,当线程从队列中获取到请求线程的 key 值时,就会唤醒请求线程获取购买资格。
4.3.3、数据丢失问题
无论是服务宕机,还是异步发送给 MQ,都存在请求数据丢失的可能。例如,当第三方支付回调系统时,写入订单成功了,此时通过异步来扣减库存和累计积分,如果应用服务刚好挂掉了,MQ 还没有存储到该消息,那即使我们重启服务,这条请求数据也将无法还原。
重试机制是还原丢失消息的一种解决方案。在以上的回调案例中,我们可以在写入订单时,同时在数据库写入一条异步消息状态,之后再返回第三方支付操作成功结果。在异步业务处理请求成功之后,更新该数据库表中的异步消息状态。
假设我们重启服务,那么系统就会在重启时去数据库中查询是否有未更新的异步消息,如果有,则重新生成 MQ 业务处理消息,供各个业务方消费处理丢失的请求数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









