







 本文介绍了如何在Mybatis中定义基类,利用注解实现通用的CRUD操作。文章详细讲解了@InsertProvider、@DeleteProvider、@UpdateProvider和@SelectProvider四个注解的作用,并展示了如何创建BaseProvider类提供SQL语句,以及如何定义BaseDao接口。通过这种方式,开发者可以快速实现单表操作的Mapper接口,同时理解其工作原理。
本文介绍了如何在Mybatis中定义基类,利用注解实现通用的CRUD操作。文章详细讲解了@InsertProvider、@DeleteProvider、@UpdateProvider和@SelectProvider四个注解的作用,并展示了如何创建BaseProvider类提供SQL语句,以及如何定义BaseDao接口。通过这种方式,开发者可以快速实现单表操作的Mapper接口,同时理解其工作原理。
项目中少不了CRUD的操作,在Mybatis中的Mapper文件中也随处可见增、删、改、查。但是,有的CRUD操作却是类似的,可以通过Mybatis提供的注解加上反射实现传入实体类就是简单的CRUD操作,这样的实现是基于对单表的操作,需要进行关联查询等操作时,还是老老实实的写在mapper文件中。
一、Mybatis中的注解
定义Mybatis基类我们需要用到org.apache.ibatis.annotations包下面四个很重要的注解:
(1)@InsertProvider,提供插入的SQL语句
(2)@DeleteProvider,提供删除的SQL语句
(3)@UpdateProvider,提供修改的SQL语句
(4)@SelectProvider,提供查询的SQL语句
@SelectProvider注解的中定义了两个属性,其中,type:指定提供SQL语句的类;method:指定提供SQL语句的方法。其他三个注解中也都有这两个属性。通过这些注解,在Mapper接口中定义方法时,我们就可以利用它来指定为这个方法指定提供SQL语句的方法,也就是这些主要用在Mapper接口中的方法上。这里我们不深入介绍Mybatis是如何通过这个注解获取SQL语句的,有兴趣的朋友可以看这篇博客https://blog.youkuaiyun.com/u012734441/article/details/86285209
@SelectProvider注解的源码如下:
/**
* @author Clinton Begin
*/
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface SelectProvider {
Class<?> type();
String method();
}二、定义Mybatis基类
这里不介绍整过环境的搭建过程,下文中主要介绍定义基类中的主要过程,也就是怎么使用上述介绍的注解类来完成向Mapper提供SQL语句的过程,也就是下文中的第三步:完成提供SQL类的方法,第四步:利用注解定义基础类接口——BaseDao。
第一,准备数据库表,表名为:user,字段定义如下:
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | varchar(10) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| gender | varchar(1) | YES | | NULL | |
| age | int(3) | YES | MUL | NULL | |
| address | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+第二,准备实体类。需要注意的是,通过主键查询时,需要告诉提供SQL的方法哪个属性是对应的主键字段,如果没有找到主键,也就是,在拼接SQL时无法指定WHERE条件,那么提供通过主键查询的方法会抛出异常。那么,我们需要怎样告诉提供SQL的方法,哪个是主键对应的属性呢?这里通过自定义注解的方式实现,自定义主键@Id,并实体中相应的字段上使用该注解,该表的主键就是id,所以需要在id属性上加上该注解,这样就等于告诉了提供SQL的方法id属性对应的列就为user表的主键。
public class User {
@Id
private String id;
private String name;
private String gender;
private String age;
private String address;
// 省略get和set方法
}第三,定义BaseProvider<T>类用于提供SQL语句,该类完成提供全部查询和通过主键查询的方法。分页查询也是同样的,将分页的参数传入拼接上即可,如果需要进行单表的条件查询,那么在解析属性的时候还需要对字段类型进行判断,以完成SQL语句的拼接。这里不演示添加、修改、删除,因为是同样的原理,不过是拼接SQL语句的过程不同而已。
在拼接的方法中使用了StringBuilder类完成SQL语句拼接的工作,可能是平时工作的习惯导致的吧。实际上,可以使用Mybaits提供的SQL类完成拼接SQL的任务,而且SQL类提供了很多方便的API可帮助我们很好的解决问题。另外,这里的BaseProvider类中为了方便将通过实体解析的字段在了Map中。
BaseProvider<T>类的代码如下:
public class BaseProvider<T> {
// 保存需要查询的字段和主键字段的名称
private Map<String,String> fieldMap = new HashMap<String,String>();
private static final String KEY_ID = "id";
private static final String KEY_QUERY = "query";
/**
* 拼接查询语句
*
*/
public String provideQueryAllSql(Class<T> clazz){
parseFields(clazz);
StringBuilder sql = new StringBuilder();
sql.append("SELECT ");
sql.append(fieldMap.get(KEY_QUERY));
sql.append(" FROM ");
sql.append(getTableName(clazz.getSimpleName()));
return sql.toString();
}
/**
* 拼接通过主键查询的SQL
*
*/
public String provideQueryById(Class<T> clazz, Serializable id){
StringBuilder sql = new StringBuilder(provideQueryAllSql(clazz));
// 如果没有找到主键就抛出异常
if (!fieldMap.containsKey(KEY_ID))
throw new RuntimeException(clazz.getName()+":没有标识主键");
sql.append(" WHERE ");
sql.append(fieldMap.get(KEY_ID));
sql.append("='" + id + "'");
return sql.toString();
}
/**
* 获取表名
*/
private String getTableName(String className){
// 将实体名称的首字母小写之后再转换
char[] arr = className.toCharArray();
arr[0] += 32;
return parse(new String(arr));
}
/**
* 将实体中的属性全部转换,并拼接为需要查询的字段
*
* @param clazz
*/
private void parseFields(Class<T> clazz){
StringBuilder columns = new StringBuilder();
// 通过反射取到所有的属性
Field[] declaredFields = clazz.getDeclaredFields();
// 记录是否发现主键
boolean unFoundedId = true;
for (int i = 0,length = declaredFields.length; i < length; i++) {
String filedName = declaredFields[i].getName();
if(i == length - 1){
columns.append(parse(filedName));
}else{
columns.append(parse(filedName) + ",");
}
// 如果找到主键之后,将不再执行以下代码
if(unFoundedId){
Id annotation = declaredFields[i].getAnnotation(Id.class);
if(annotation != null){
fieldMap.put(KEY_ID,parse(filedName));
}
unFoundedId = true;
}
}
// 将需要查询的字段保存到到map中
fieldMap.put(KEY_QUERY,columns.toString());
}
/**
* 驼峰命名转为带下划线的列名
*
*/
private String parse(String fieldName){
StringBuilder columnName = new StringBuilder();
for (int i = 0; i < fieldName.length(); i++) {
char c = fieldName.charAt(i);
// 如果是大写字母就加上下划线,并将其变为小写
if(Character.isUpperCase(c)){
columnName.append("_").append(c += 32);
}else{
columnName.append(c);
}
}
return columnName.toString();
}
}第四、定义BaseDao接口使其继承BaseProvider<T>类,并定义查询全部和通过主键查询的方法,这样基础接口就算定义完成了,也就是当前定义的Mapper接口只要继承BaseDao接口就具备了查询全部和通过主键查询的功能。
public interface BaseDao<T> {
/**
* 查询全部数据
* @param clazz 实体类
* @return
*/
@SelectProvider(type = BaseProvider.class,method = "provideQueryAllSql")
public List<T> queryAll(Class<T> clazz);
/**
* 通过主键查询
*
* @param clazz 实体类
* @param id 主键值
* @return
*/
@SelectProvider(type = BaseProvider.class,method = "provideQueryById")
public T queryById(Class<T> clazz, Serializable id);
}第五、定义UserDao使其继承BaseDao接口,UserDao也就具有了查询全部和通过主键查询的功能。
public interface UserDao extends BaseDao<User>{
// 继承来自BaseDao的查询功能
}接下来就可以进行测试了,测试类的代码和结果如下:
public class Test {
public static void main(String[] args) throws Exception {
AnnotationConfigApplicationContext context =
new AnnotationConfigApplicationContext(AppConfig.class);
UserDao userDao = context.getBean(UserDao.class);
System.out.println(userDao.queryAll(User.class));
//System.out.println(userDao.queryById(User.class,"1"));
}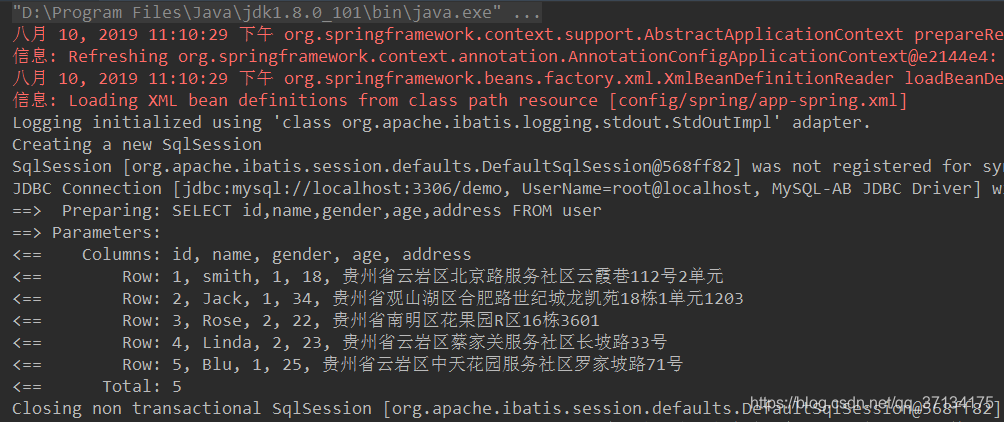
queryAll方法结果
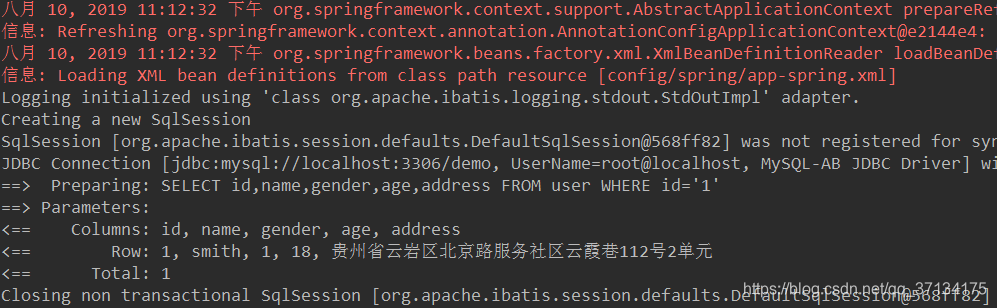
queryById方法结果
三、总结
工作中,我们也会使用到类似的方法实现类似的功能,我们不仅需要会使用更需要知道它的实现原理,不然遇到一些非常的问题时就会无从下手。此外,面试中有的面试官也会提供这方面的问题。最后,定义Mybatis基类需要两方面的内容,一方面是Java反射相关的知识,另一方面为Mybatis注解。
有不对的地方欢迎指正,希望对读者有所帮助!
四、参考资料
【1】https://blog.youkuaiyun.com/YingTao8/article/details/83116256——mybatis抽取基类BaseMapper(通用增/删/改/查)
【2】https://blog.youkuaiyun.com/u012734441/article/details/86285209——MyBatis源码分析之@SelectProvider注解使用详解

















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









