







概述
这是我学习郝佳老师的spring源码解析的学习笔记,有问题可以留言或私信,不过我基本都自己用代码debug验证过了。
这是一个总体的思维导图,有需要的可以点击链接下载(每个节点都可以展开,由于步骤太多,只能缩减显示部分内容了,具体的所有节点,我上传成了PDF)

下载链接
以上,开启正文:
Spring声明式事务让我们从复杂的事务处理中得到解脱,使我们再也不需要去处理事务开启、事务提交和回滚等操作,再也不需要在与事务相关的方法中处理大量的try…catch…finally代码。
Spring中事务的使用虽然已经相对简单得多,但是,还是有很多的使用及配置规则,有兴趣的读者可以自己查阅相关资料进行深入研究,这里只列举出最常用的使用方法。
同样,我们还是以最简单的示例来进行直观地介绍。
spring的事务使用示例
创建数据表结构
CREATE TABLE 'user' (
'id' int(11) NOT NULL auto_increment,
'name' varchar(255) default NULL,
'age' int(11) default NULL,
'sex' varchar(255) default NULL,
PRIMARY KEY ('id')
)
创建对应数据表的PO
public class User {
private int id;
private String name;
private int age;
private String sex;
//省略set/get方法
}
创建表与实体间的映射
public class UserRowMapper implements RowMapper {
@Override
public Object mapRow(ResultSet set, int index) throws SQLException {
User person = new User(set.getInt("id"), set.getString("name"), set
.getInt("age"), set.getString("sex"));
return person;
}
}
创建数据操作接口
@Transactional(propagation= Propagation.REQUIRED)
public interface UserService {
public void save(User user) throws Exception;
}
创建数据操作接口实现类
public class UserServiceImpl implements UserService {
private JdbcTemplate jdbcTemplate;
// 设置数据源
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void save(User user) throws Exception {
jdbcTemplate.update("insert into user(name,age,sex)values(?,?,?)",
new Object[] { user.getName(), user.getAge(),
user.getSex() }, new int[] { java.sql.Types.VARCHAR,
java.sql.Types.INTEGER, java.sql.Types.VARCHAR });
//事务测试,加上这句代码则数据不会保存到数据库中
throw new RuntimeException("aa");
}
}
创建Spring配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/Spring-tx-2.5.xsd">
<tx:annotation-driven transaction-manager="transactionManager" />
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!--配置数据源 -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/learn" />
<property name="username" value="root" />
<property name="password" value="root" />
<!-- 连接池启动时的初始值 -->
<property name="initialSize" value="1" />
<!-- 连接池的最大值 -->
<property name="maxActive" value="300" />
<!-- 最大空闲值.当经过一个高峰时间后,连接池可以慢慢将已经用不到的连接慢慢释放一部分,一直减少到maxIdle为止 -->
<property name="maxIdle" value="2" />
<!-- 最小空闲值.当空闲的连接数少于阀值时,连接池就会预申请去一些连接,以免洪峰来时来不及申请 -->
<property name="minIdle" value="1" />
</bean>
<!-- 配置业务bean:PersonServiceBean -->
<bean id="userService" class="lzg.service.UserServiceImpl">
<!-- 向属性dataSource注入数据源 -->
<property name="dataSource" ref="dataSource"></property>
</bean>
</beans>
测试
public static void main(String[] args) throws Exception {
ApplicationContext act = new ClassPathXmlApplicationContext("spring.xml");
UserService userService = (UserService) act.getBean("userService");
User user = new User();
user.setName("张三ccc");
user.setAge(20);
user.setSex("男");
// 保存一条记录
userService.save(user);
}
在上面的测试示例中,UserServiceImpl类对接口UserService中的save函数的实现最后加入了一句抛出异常的代码:
throw new RuntimeException("aa");
- 当注掉这段代码执行测试类,那么会看到数据被成功的保存到了数据库中
- 但是如果加入这段代码时再次运行测试类,发现此处的操作并不会将数据保存到数据库中。
注意
默认情况下Spring中的事务处理只对RuntimeException方法进行回滚,所以,如果此处将RuntimeException替换成普通的Exception不会产生回滚效果。
事务自定义标签
对于Spring中事务功能的代码分析,我们首先从配置文件开始入手,在配置文件中有这样一个配置:<tx:annotation-driven />。可以说此处配置是事务的开关,如果没有此处配置,那么Spring中将不存在事务的功能。那么我们就从这个配置开始分析。
根据之前的分析,我们因此可以判断,在自定义标签中的解析过程中一定是做了一些辅助操作,于是我们先从自定义标签入手进行分析。
查看spring-tx依赖下的spring.handlers文件,可以找到是TxNamespaceHandler处理该标签,在TxNamespaceHandler中的init方法中:
TxNamespaceHandler.init
public void init() {
registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser());
registerBeanDefinitionParser("annotation-driven", new AnnotationDrivenBeanDefinitionParser());
registerBeanDefinitionParser("jta-transaction-manager", new JtaTransactionManagerBeanDefinitionParser());
}
根据自定义标签的使用规则以及上面的代码,可以知道Spring会使用AnnotationDrivenBeanDefinitionParser类的parse方法进行解析<tx:annotation-driven为开头的配置
注意需要查看org.springframework.transaction.config也就是spring-tx下的类,spring-context下有同名的类,需要注意不要看错了
AnnotationDrivenBeanDefinitionParser
AnnotationDrivenBeanDefinitionParser.parse
public BeanDefinition parse(Element element, ParserContext parserContext) {
registerTransactionalEventListenerFactory(parserContext);
String mode = element.getAttribute("mode");
if ("aspectj".equals(mode)) {
// mode="aspectj"
registerTransactionAspect(element, parserContext);
}
else {
// mode="proxy"
AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);
}
return null;
}
在解析中存在对于mode属性的判断,根据代码,如果我们需要使用AspectJ的方式进行事务切入(Spring中的事务是以AOP为基础的),那么可以使用这样的配置:
<tx:annotation-driven transaction-manager="transactionManager" mode="aspectj"/>
configureAutoProxyCreator
我们以默认配置为例子进行分析,进入AopAutoProxyConfigurer类(AnnotationDrivenBeanDefinitionParser的内部类)的configureAutoProxyCreator:
AopAutoProxyConfigurer.configureAutoProxyCreator(AnnotationDrivenBeanDefinitionParser的内部类)
public static void configureAutoProxyCreator(Element element, ParserContext parserContext) {
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
String txAdvisorBeanName = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME;
if (!parserContext.getRegistry().containsBeanDefinition(txAdvisorBeanName)) {
Object eleSource = parserContext.extractSource(element);
// Create the TransactionAttributeSource definition.
//创建TransactionAttributeSource的bean
RootBeanDefinition sourceDef = new RootBeanDefinition(
"org.springframework.transaction.annotation.AnnotationTransactionAttributeSource");
sourceDef.setSource(eleSource);
sourceDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
//注册bean,并使用Spring中的定义规则生成beanname
String sourceName = parserContext.getReaderContext().registerWithGeneratedName(sourceDef);
// Create the TransactionInterceptor definition.
//创建TransactionInterceptor的bean
RootBeanDefinition interceptorDef = new RootBeanDefinition(TransactionInterceptor.class);
interceptorDef.setSource(eleSource);
interceptorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registerTransactionManager(element, interceptorDef);
interceptorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
String interceptorName = parserContext.getReaderContext().registerWithGeneratedName(interceptorDef);
// Create the TransactionAttributeSourceAdvisor definition.
//创建TransactionAttributeSourceAdvisor的bean
RootBeanDefinition advisorDef = new RootBeanDefinition(BeanFactoryTransactionAttributeSourceAdvisor.class);
advisorDef.setSource(eleSource);
advisorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
//将sourceName的bean注入advisorDef的transactionAttributeSource属性中
advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
//将interceptorName的bean注入advisorDef的adviceBeanName属性中
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
//如果配置了order属性,则加入到bean中
if (element.hasAttribute("order")) {
advisorDef.getPropertyValues().add("order", element.getAttribute("order"));
}
parserContext.getRegistry().registerBeanDefinition(txAdvisorBeanName, advisorDef);
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), eleSource);
compositeDef.addNestedComponent(new BeanComponentDefinition(sourceDef, sourceName));
compositeDef.addNestedComponent(new BeanComponentDefinition(interceptorDef, interceptorName));
compositeDef.addNestedComponent(new BeanComponentDefinition(advisorDef, txAdvisorBeanName));
parserContext.registerComponent(compositeDef);
}
}
上面的代码注册了代理类及3个bean,很多读者会直接略过,认为只是注册3个bean而已,确实,这里只注册了 3个bean,但是这3个bean支撑了整个的事务功能
- AnnotationTransactionAttributeSource
- TransactionInterceptor
- TransactionAttributeSourceAdvisor
其中的两个bean被注册到了一个名为advisorDef的bean中,advisorDef使用BeanFactoryTransactionAttributeSourceAdvisor作为其class属性。
也就是说BeanFactoryTransactionAttributeSourceAdvisor代表着当前bean,如图所示:
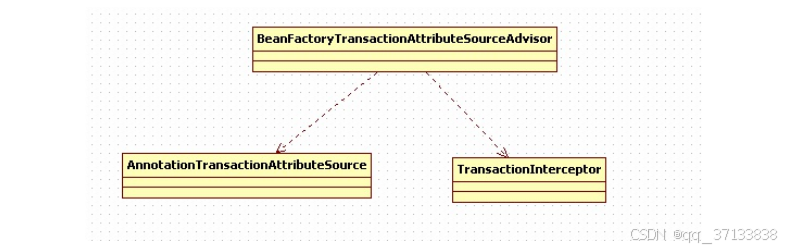
那么如此组装的目的是什么呢?我们暂且留下一个悬念,接着分析代码。上面函数configureAutoProxyCreator中的第一句貌似很简单但却是很重要的代码:
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
注册InfrastructureAdvisorAutoProxyCreator
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary
public static void registerAutoProxyCreatorIfNecessary(ParserContext parserContext, Element sourceElement) {
BeanDefinition beanDefinition = AopConfigUtils.registerAutoProxyCreatorIfNecessary(parserContext.getRegistry(), parserContext.extractSource(sourceElement));
useClassProxyingIfNecessary(parserContext.getRegistry(), sourceElement);
registerComponentIfNecessary(beanDefinition, parserContext);
}
对于解析来的代码流程AOP中已经有所分析,上面的两个函数主要目的是注册了InfrastructureAdvisorAutoProxyCreator类型的bean,那么注册这个类的目的是什么呢?查看这个类的层次
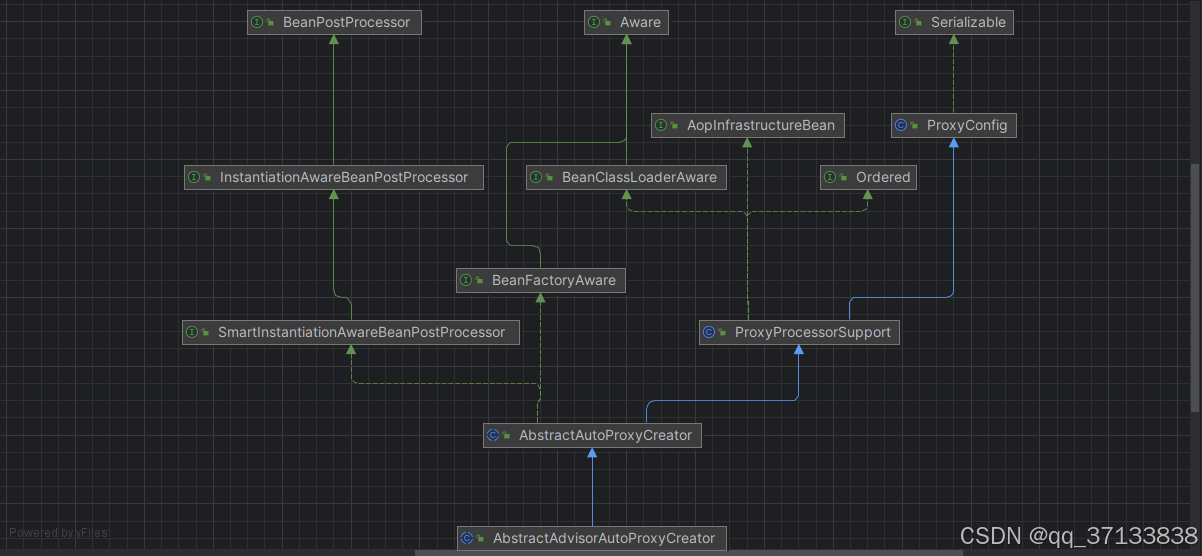
从上面的层次结构中可以看到,InfrastructureAdvisorAutoProxyCreator是一个BeanPostPeocessor
也就是说在Spring中,所有bean实例化时Spring都会保证调用其postProcessAfterInitialization方法,其实现是在父类AbstractAutoProxyCreator类中实现。
之前分析过AOP功能的实现,这里不再详细说明
按照这里的分析,可以知道spring的事务需要开启AOP功能。
isEligibleAdvisorBean
这个方法用于判断bean是否符合作advisor做条件,spring中有三种优先级的AdvisorAutoProxyCreator,这里感兴趣的可以参照我写的spring aop的文章,不再赘述
InfrastructureAdvisorAutoProxyCreator.isEligibleAdvisorBean
protected boolean isEligibleAdvisorBean(String beanName) {
return (this.beanFactory != null && this.beanFactory.containsBeanDefinition(beanName) &&
this.beanFactory.getBeanDefinition(beanName).getRole() == BeanDefinition.ROLE_INFRASTRUCTURE);
}
看代码,逻辑很简单,就是检查bean的role权限,需要bean的权限为ROLE_INFRASTRUCTURE
bean的权限
在 Spring 框架中,BeanDefinition 的 role 属性用于描述 Bean 的角色或用途。通过这些角色提示(role hint),Spring 能够更清晰地区分不同类型的 Bean,并根据其用途进行优化处理。
ROLE_APPLICATION
BeanDefinition被创建时默认是该权限
-
定义
-
核心用户定义的 Bean:表示该 Bean 是应用程序的主要组成部分,通常由用户显式定义(如业务逻辑组件、控制器、服务等)。
-
重要性:这些 Bean 是业务功能的核心实现,直接面向最终用户或业务需求。
-
-
使用场景
-
用户通过
@Component、@Service、@Repository或 XML 配置显式定义的 Bean。 -
业务逻辑组件,如订单服务、用户管理模块等。
-
ROLE_SUPPORT
-
定义
-
表示该 Bean 是某个更大配置的一部分,通常是某个外部组件的辅助部分。
-
这些 Bean 对开发人员来说仍然重要,但它们的作用是支持其他核心组件的功能。
-
它们可能不会直接暴露给最终用户,但在特定场景下仍然需要被关注。
-
-
使用场景
- 目前我还不知道有哪些场景使用
ROLE_INFRASTRUCTURE
-
定义
-
表示该 Bean 是完全后台的角色,对最终用户没有直接意义。
-
这些 Bean 是框架内部工作的组成部分,通常不需要开发者显式关注。
-
它们的存在是为了支持框架本身的运行,而不是为了实现具体的应用程序功能。
-
-
使用场景
典型场景就是我们本章的主要内容,spring transaction的三个主要组件,
- AnnotationTransactionAttributeSource
- TransactionInterceptor
- TransactionAttributeSourceAdvisor
其role权限都被设置成了ROLE_INFRASTRUCTURE
设置的地方在上面的AopAutoProxyConfigurer.configureAutoProxyCreator
正如InfrastructureAdvisorAutoProxyCreator的命名一样,这个后置处理器就是寻找容器内部基础的的advisor并进行增强
BeanFactoryTransactionAttributeSourceAdvisor
在我们讲解自定义标签时曾经注册了一个类型为BeanFactoryTransactionAttributeSourceAdvisor的bean,而在此bean中我们又注入了另外两个Bean,那么此时这个Bean就会被开始使用了。
因为BeanFactoryTransactionAttributeSourceAdvisor同样也实现了Advisor接口,那么在获取所有增强器时自然也会将此bean提取出来,并随着其他增强器一起在后续的步骤中被织入代理。
之前学习过spring的AOP功能的实现,我们知道对于每个advisor都需要通过canApply来判断当前advisor是否可以用于某个bean的增强
BeanFactoryTransactionAttributeSourceAdvisor间接实现了PointcutAdvisor。所以会将BeanFactoryTransactionAttributeSourceAdvisor中的getPointcut()方法返回值作为参数继续调用canApply方法
AopUtils.canApply
public static boolean canApply(Advisor advisor, Class<?> targetClass, boolean hasIntroductions) {
if (advisor instanceof IntroductionAdvisor) {
return ((IntroductionAdvisor)advisor).getClassFilter().matches(targetClass);
} else if (advisor instanceof PointcutAdvisor) {
PointcutAdvisor pca = (PointcutAdvisor)advisor;
return canApply(pca.getPointcut(), targetClass, hasIntroductions);
} else {
return true;
}
}
关于pointCut的实现之前已经分析过,内部会通过getClassFilter进行类的过滤同时也会通过getMethodMatcher 进行方法过滤
而getPoint()方法返回的是TransactionAttributeSourcePointcut类型的实例。对于transactionAttributeSource这个属性大家还有印象吗?这是在解析自定义标签时注入进去的。
private final TransactionAttributeSourcePointcut pointcut = new TransactionAttributeSourcePointcut() {
@Override
protected TransactionAttributeSource getTransactionAttributeSource() {
return transactionAttributeSource;
}
};
值得注意的是TransactionAttributeSourcePointcut是一个StaticMethodMatcherPointcut,默认匹配所有类然后通过不同的规则去匹配不同的方法
到这里我们不禁会有疑问,对于事务的配置不仅仅局限于在函数上配置,我们都知道,在类接口上的配置可以延续到类中的每个函数,那么,==如果针对每个函数进行检测,在类本身上配置的事务属性岂不是检测不到了吗?==带着这个疑问,我们继续探求matcher方法。
TransactionAttributeSourcePointcut
TransactionAttributeSourcePointcut.matches
public boolean matches(Method method, Class<?> targetClass) {
//避免对已生成的事务代理类(Proxy)再次进行事务增强。
if (targetClass != null && TransactionalProxy.class.isAssignableFrom(targetClass)) {
return false;
}
//自定义标签解析时注入
TransactionAttributeSource tas = getTransactionAttributeSource();
return (tas == null || tas.getTransactionAttribute(method, targetClass) != null);
}
此时的tas表示AnnotationTransactionAttributeSource类型,而AnnotationTransactionAttributeSource类型的getTransactionAttribute方法如下:
getTransactionAttribute
AbstractFallbackTransactionAttributeSource.getTransactionAttribute
public TransactionAttribute getTransactionAttribute(Method method, Class<?> targetClass) {
if (method.getDeclaringClass() == Object.class) {
return null;
}
// First, see if we have a cached value.
Object cacheKey = getCacheKey(method, targetClass);
Object cached = this.attributeCache.get(cacheKey);
if (cached != null) {
// Value will either be canonical value indicating there is no transaction attribute,
// or an actual transaction attribute.
if (cached == NULL_TRANSACTION_ATTRIBUTE) {
return null;
}
else {
return (TransactionAttribute) cached;
}
}
else {
// We need to work it out.
TransactionAttribute txAttr = computeTransactionAttribute(method, targetClass);
// Put it in the cache.
if (txAttr == null) {
this.attributeCache.put(cacheKey, NULL_TRANSACTION_ATTRIBUTE);
}
else {
String methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
if (txAttr instanceof DefaultTransactionAttribute) {
((DefaultTransactionAttribute) txAttr).setDescriptor(methodIdentification);
}
if (logger.isDebugEnabled()) {
logger.debug("Adding transactional method '" + methodIdentification + "' with attribute: " + txAttr);
}
this.attributeCache.put(cacheKey, txAttr);
}
return txAttr;
}
}
很遗憾,在getTransactionAttribute函数中并没有找到我们想要的代码,这里是指常规的一贯的套路。尝试从缓存加载,如果对应信息没有被缓存的话,工作又委托给了computeTransaction Attribute函数,在computeTransactionAttribute函数中终于的我们看到了事务标签的提取过程。
computeTransactionAttribute
AbstractFallbackTransactionAttributeSource.computeTransactionAttribute
protected TransactionAttribute computeTransactionAttribute(Method method, Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
// Ignore CGLIB subclasses - introspect the actual user class.
Class<?> userClass = ClassUtils.getUserClass(targetClass);
// The method may be on an interface, but we need attributes from the target class.
// If the target class is null, the method will be unchanged.
//method代表接口中的方法,specificMethod代表实现类中的方法
Method specificMethod = ClassUtils.getMostSpecificMethod(method, userClass);
// If we are dealing with method with generic parameters, find the original method.
specificMethod = BridgeMethodResolver.findBridgedMethod(specificMethod);
// First try is the method in the target class.
//查看方法中是否存在事务声明
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
return txAttr;
}
// Second try is the transaction attribute on the target class.
//查看方法所在类中是否存在事务声明
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
//查找接口方法
if (specificMethod != method) {
// Fallback is to look at the original method.
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
return txAttr;
}
// Last fallback is the class of the original method.
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
}
return null;
}
上述方法的整体流程是:
-
通过
ClassUtils.getUserClass(targetClass)获取原始用户类(非 CGLIB 代理类),代理类(如UserService$$EnhancerBySpringCGLIB)可能隐藏真实的事务注解,需要穿透代理找到原始类。 -
在目标类(
userClass)中找到最具体的方法实现(如果方法是接口方法,则返回实现类中的方法)。 -
如果方法中存在事务属性,则使用方法上的属性
-
否则使用方法所在的类上的属性
-
如果方法所在类的属性上还是没有搜寻到对应的事务属性,那么再搜寻接口中的方法
-
再没有的话,最后尝试搜寻接口的类上面的声明。
上面函数揭示了,当多个事务规则同时存在时,规则的获取优先级。对于函数computeTransactionAttribute中的逻辑与我们所认识的事务属性的获取规则并无差别。
但是上面函数中并没有真正的去做搜寻事务属性的逻辑,而是搭建了个执行框架,将搜寻事务属性的任务委托给了findTransactionAttribute方法去执行。
getUserClass
ClassUtils.getUserClass
public static Class<?> getUserClass(Class<?> clazz) {
if (clazz.getName().contains("$$")) {
Class<?> superclass = clazz.getSuperclass();
if (superclass != null && superclass != Object.class) {
return superclass;
}
}
return clazz;
}
getMostSpecificMethod
ClassUtils.getMostSpecificMethod
public static Method getMostSpecificMethod(Method method, @Nullable Class<?> targetClass) {
if (targetClass != null && targetClass != method.getDeclaringClass() && isOverridable(method, targetClass)) {
try {
if (Modifier.isPublic(method.getModifiers())) {
try {
return targetClass.getMethod(method.getName(), method.getParameterTypes());
} catch (NoSuchMethodException var3) {
return method;
}
}
Method specificMethod = ReflectionUtils.findMethod(targetClass, method.getName(), method.getParameterTypes());
return specificMethod != null ? specificMethod : method;
} catch (SecurityException var4) {
}
}
return method;
}
findTransactionAttribute
AnnotationTransactionAttributeSource.findTransactionAttribute
protected TransactionAttribute findTransactionAttribute(Class<?> clazz) {
return determineTransactionAttribute(clazz);
}
AnnotationTransactionAttributeSource.determineTransactionAttribute
protected TransactionAttribute determineTransactionAttribute(AnnotatedElement ae) {
if (ae.getAnnotations().length > 0) {
for (TransactionAnnotationParser annotationParser : this.annotationParsers) {
TransactionAttribute attr = annotationParser.parseTransactionAnnotation(ae);
if (attr != null) {
return attr;
}
}
}
return null;
}
this.annotationParsers是在当前类AnnotationTransactionAttributeSource初始化的时候初始化的,其中的值被加入了SpringTransactionAnnotationParser
也就是当进行属性获取的时候其实是使用SpringTransactionAnnotationParser类的parseTransactionAnnotation方法进行解析的。
SpringTransactionAnnotationParser.parseTransactionAnnotation
public TransactionAttribute parseTransactionAnnotation(AnnotatedElement ae) {
//获取注解中的属性
AnnotationAttributes attributes = AnnotatedElementUtils.getMergedAnnotationAttributes(ae, Transactional.class);
if (attributes != null) {
//解析注解中的属性
return parseTransactionAnnotation(attributes);
}
else {
return null;
}
}
上述方法获取到了注解中的属性,然后再通过parseTransactionAnnotation方法将可用的属性注入到事务属性中,具体实现如下:
protected TransactionAttribute parseTransactionAnnotation(AnnotationAttributes attributes) {
RuleBasedTransactionAttribute rbta = new RuleBasedTransactionAttribute();
Propagation propagation = attributes.getEnum("propagation");
//解析propagation
rbta.setPropagationBehavior(propagation.value());
Isolation isolation = attributes.getEnum("isolation");
//解析isolation
rbta.setIsolationLevel(isolation.value());
//解析timeout
rbta.setTimeout(attributes.getNumber("timeout").intValue());
//解析readOnly
rbta.setReadOnly(attributes.getBoolean("readOnly"));
//解析value
rbta.setQualifier(attributes.getString("value"));
ArrayList<RollbackRuleAttribute> rollBackRules = new ArrayList<RollbackRuleAttribute>();
//解析rollbackFor
Class<?>[] rbf = attributes.getClassArray("rollbackFor");
for (Class<?> rbRule : rbf) {
RollbackRuleAttribute rule = new RollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
//解析rollbackForClassName
String[] rbfc = attributes.getStringArray("rollbackForClassName");
for (String rbRule : rbfc) {
RollbackRuleAttribute rule = new RollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
//解析noRollbackFor
Class<?>[] nrbf = attributes.getClassArray("noRollbackFor");
for (Class<?> rbRule : nrbf) {
NoRollbackRuleAttribute rule = new NoRollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
//解析noRollbackForClassName
String[] nrbfc = attributes.getStringArray("noRollbackForClassName");
for (String rbRule : nrbfc) {
NoRollbackRuleAttribute rule = new NoRollbackRuleAttribute(rbRule);
rollBackRules.add(rule);
}
rbta.getRollbackRules().addAll(rollBackRules);
return rbta;
}
上面方法中实现了对对应类或者方法的事务属性解析,你会在这个类中看到任何你常用或者不常用的属性提取。
至此,我们终于完成了事务标签的解析。我们是不是分析的太远了,似乎已经忘了从哪里开始了。
我们的现在的任务是找出某个增强器是否适合于对应的类,而==是否匹配的关键则在于是否从指定的类或类中的方法中找到对应的事务属性==,现在,我们以UserServiceImpl为例,已经在它的接口UserService中找到了事务属性,所以,它是与事务增强器匹配的,也就是它会被事务功能修饰。
BeanFactoryTransactionAttributeSourceAdvisor作为Advisor的实现类,自然要遵从Advisor的处理方式,当代理被调用时会调用这个类的增强方法,也就是此bean的Advise,所以会首先执行TransactionInterceptor进行增强,同时,也就是在TransactionInterceptor类中的invoke方法中完成了整个事务的逻辑。
Spring事务属性
上面讲解了解析事务属性的流程,现在我们需要系统学些下各个事务属性的作用
ACID
在讲事务属性前,有必要了解以下事务的四个特性
**定义:**数据库的事务(Transaction)是指把一组数据库操作当作一个逻辑单元来执行,要么全部完成,要么全部不完成。
事务通过其本身的四个特性保证了事务的可靠和一致:
-
**原子性(Atomicity):**每个事务中的所有操作都需要像原子一样不可分割,要么全部成功,要么全部失败
- Mysql的Innodb提供了undo log机制,在执行数据的增删改时,都会把对应的undo log记录下来,当一组操作中某个操作出现异常,就会触发回滚动作,反向执行每次操作记录的undo log,将数据恢复到这次操作之前,等同于所有操作都没有执行
-
**隔离性(Isolation):**并发执行事务时,各事务之间需要隔离,不能互相干扰。隔离性提供了四个隔离级别定义了隔离的不同程度,用于解决不同的并发问题
- 隔离的力度和并发性能息息相关
-
**持久性(Durability):**事务一旦提交,事务中所有的更改,不会由于电源故障、系统崩溃、竞争条件在内的意外而发生变化
-
**一致性(Consistency):**事务执行前后,数据库必须保持从一个一致状态到另一个一致状态的特性。即事务的执行不会破坏数据库的完整性约束,所谓的完整性约束包括数据关系的完整性和业务逻辑的完整性。一致性是事务追求的最终目标,原子性、持久性和隔离性,实际上都是为了保证数据库状态的一致性而存在的。
什么是完整性约束?
- 数据库自身的完整性约束(如主键、外键、唯一性约束等)。
- 应用程序定义的业务规则(如转账金额不能超过账户余额,库存数量不能为负等)。
- 那转账举例子,A账户和B账户之间相互转账,无论如何操作,A、B账户的总金额都必须是不变的
原子性实现原理(Undo Log)
Undo Log是为了保证事务的原子性,需要再发生错误时进行回滚操作而诞生的机制,每个数据在执行相应的操作的时候都会在磁盘中创建与之对应的Undo Log,当事务异常时会根据Undo Log逐一进行撤销操作,保证了事务的原子性
对于主键的修改,涉及先删除再插入,所以会一次产生两条
应用场景
- 事务回滚,崩溃恢复;此功能主要满足了事务的原子性,简单的说就是要么做完,要么不做。因为数据库在任何时候都可能发生宕机;包括停电,软硬件bug等。那数据库就需要保证不管发生任何情况,在重启数据库时都能恢复到一个一致性的状态;这个一致性的状态是指此时所有事务要么处于提交,要么处于未开始的状态,不应该有事务处于执行了一半的状态;所以我们可以通过undo log在数据库重启时把正在提交的事务完成提交,活跃的事务回滚,这样就保证了事务的原子性,以此来让数据库恢复到一个一致性的状态。
- 多版本并发控制(MVCC),此功能主要满足了事务的隔离性,简单的说就是不同活跃事务的数据互相可能是不可见的。因为如果两个活跃的事务彼此可见,那么一个事务将会看到另一个事务正在修改的数据,这样会发生数据错乱;所以我们可以借助undo log记录的历史版本数据,来恢复出对于一个事务可见的数据,来满足其读取数据的请求。
插入时机
在事务中,每一条sql通过执行器后,第一时间就会在回滚段Undo Log Segment中申请一个Undo Log页,然后根据sql信息来构建相应的Undo Log内容,同时将其写入磁盘,以保证每次操作真正的数据之前Undo Log是完整的,这样即使发生异常也可以保证完美的撤销
需要注意的是,数据库通常会将磁盘上的数据页加载到内存中的缓冲池(如 MySQL InnoDB 的 Buffer Pool),以加速数据的读写操作。当 SQL 执行修改操作时,通常是修改内存中的数据(即缓冲池中的数据页)。这种修改称为“脏页”(Dirty Page),表示该数据页已被修改但尚未同步到磁盘。上面真正的数据就是指代的内存的数据
内存中的修改(脏页)在提交后才会被刷新到磁盘上的表空间(磁盘上的表空间是存储实际数据的地方,包括数据文件、索引文件等),这一过程称为“Checkpoint” 或 “Flush”。
这就是 WAL (Write-Ahead Logging)技术。WAL 技术指的是, MySQL 的写操作并不是立刻写到磁盘上,而是先写日志,然后在合适的时间再写到磁盘上
另外需要注意的是Undo Log不是无限申请的,Undo Log 的存储能力受限于回滚段的大小。
- InnoDB 支持多个回滚段,默认情况下会创建 128 个回滚段(从 MySQL 5.7 开始)。
- 每个回滚段都可以存储一定数量的回滚页
Undo Log格式
不同sql对于的Undo Log不但撤销操作不同,存储的内容也不同。每条undoLog包含两部分信息
-
公共部分:记录了UNDO类型(增、删、改)、表ID,头尾信息等在内的基本信息
-
不同操作和操作数据的操作信息
-
**Insert Undo:**事务Insert记录时产生的Undo Log。
- 记录完整的主键信息
- 在回滚需要彻底删除记录时,有了完整的主键信息,即可根据主键信息删除相应记录
- 在事务提交后就可以直接删除(删除和修改操作,为了服务MVCC不会马上删除)
-
**Update Undo:**除了Insert Undo外的所有Undo Log都属于Update Undo。
-
TRX_UNDO_DEL_MARK_REC(删):
-
记录事务ID、Roll Pointer、主键信息、原数据各字段信息(回滚二级索引记录)(同时,DELETE 操作会修改原记录的
delete_flag为true,从而实现逻辑删除)PUGE线程会定期清理已提交的标记为删除的数据
-
在回滚需要恢复记录时,根据记录的主键信息和字段值修改其删除标记以及恢复二级索引记录
-
-
TRX_UNDO_UPD_EXIST_REC(改)
- 不更新主键时:事务ID,roll_point、主键信息、被更新信息
- 更新了主键,会记录两条UndoLog,一条删除,一条新增
-
-
持久性实现原理
Redo Log存储的内容
物理日志
Redo log记录的是物理日志,即数据页在磁盘上的实际更改。并且采用 物理到字节 的粒度,而非记录整个页或逻辑操作。
物理日志主要有两种粒度:
- 物理到字节(Physical Byte-Level):记录数据页中具体字节的变化(如“页 X 的偏移量 Y 处写入值 Z”)。
- 物理到页(Physical Page-Level):记录整个页的变更(如“替换页 X 的所有内容为 Y”),但 InnoDB 的 Redo Log 并不使用这种粒度。
redolog采用物理日志主要有以下两个原因:
- 高效写入:仅记录变更部分,减少 I/O 和存储开销。
- 快速恢复:redolog主要用于持久化出现问题的时候,数据的恢复,直接记录修改数据页的物理位置,可以避免恢复数据时解析复杂的操作语义,效率较高。
为什么主要采用物理日志
-
**逻辑日志的局限性:**逻辑操作需依赖数据库的当前状态才能正确执行。物理记录直接记录数据页的物理修改(如“页 X 的偏移量 Y 处写入值 Z”),无需依赖数据库逻辑状态
-
性能与恢复效率
-
逻辑日志需重放 SQL 或行变更,涉及索引更新、锁竞争、事务回滚等逻辑操作,恢复速度慢。在高并发或大事务场景下,逻辑日志重放可能成为性能瓶颈。
-
物理日志直接修改数据页,恢复时无需解析 SQL 或重建上下文,速度极快。
少量逻辑信息
在特殊情况下redolog,可能包含 少量逻辑信息 以优化存储效率。
某些场景下,Redo Log 会结合逻辑信息(如行标识、索引键)来减少日志量。例如:
-
更新一个可变长度字段时
- 如果某行的某一列从
"short"更新为"a very long string",字段长度的增加可能导致该行在数据页中的位置发生移动。 - 直接记录物理修改需要详细描述每个受影响的字节(包括偏移量的变化),这会导致日志量显著增加。
- 如果某行的某一列从
-
索引分裂操作可能需要逻辑描述。
-
当插入一个新键值导致某个索引页满时,系统会将部分键值迁移到一个新的页中。
- 当某个索引页的数据量超过其容量限制时,需要进行分裂。
- 将满的页拆分为两个页。
- 重新分配数据,确保每个页的负载均衡,查询效率不受影响。
- 更新父节点以反映新的页分布。
-
如果仅记录物理修改,需要详细描述每个受影响页的字节级变化,这会导致日志量非常大且难以维护一致性。
-
总结
Redo Log 的核心是物理日志,但在特定场景中会引入逻辑信息以提高灵活性,这种设计称为 Physiological Logging。
写入时机
-
redo log 是事务开始后逐步写盘的。重做日志有一个缓存区 redo_log_buffer(默认大小8M),Innodb存储引擎先将重做日志写入 redo_log_buffer中。然后通过以下三种方式将innodb日志缓冲区的日志刷新到磁盘:
-
Master Thread 定时每秒一次执行刷新 redo_log_buffer 到重做日志文件
-
每个事务 commit 时会将重做日志刷新到重做日志文件
-
当 redo_log_buffer可用空间少于一半时,重做日志缓存被刷新到重做日志文件
-
-
事务commit提交,重做日志的状态置为commit
为什么需要两阶段提交
由于redo log的提交分为prepare和commit两个阶段,所以称之为两阶段提交。
两阶段提交的核心目标是 保证事务在存储引擎层(Redo Log)和 Server 层(Binlog)的原子性,确保:
- 要么两者都提交(事务生效,主从一致)。
- 要么两者都回滚(事务无效,数据一致)。
考虑到以下问题:事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,这样就造成两份日志之间的逻辑不一致。此时会有两种情况:
- 如果在将 redo log 刷入到磁盘之后, MySQL 突然宕机了,而 binlog 还没有来得及写入
- MySQL 重启后,通过 redo log 会将修改持久化到表空间
- 但是 binlog写入失败,所以binlog里面没有记录这条更新语句
- 这样带来的影响是:
- 在主从架构中,binlog 会被复制到从库,由于 binlog 丢失了这条更新语句,从库将不会应用修改,与主库的值不一致性
- 在使用binlog进行数据恢复时,将不能恢复丢失的数据
- 如果在将 binlog 刷入到磁盘之后, MySQL 突然宕机了,而 redo log 还没有来得及写入
- 由于 redo log 还没写,崩溃恢复以后持久化过程将不再继续,此时表空间不会应用数据的修改,但是binlog 里面记录了这条更新语句
可以看到,在持久化 redo log 和 binlog 这两份日志的时候,如果没有两阶段提交,会破坏redolog和binlog之间的一致性,这种一致性的破坏会带来各种问题。
在两阶段提交的场景下:
MySQL 重启后会按顺序扫描 redo log 文件,碰到处于 prepare 状态的 redo log,就会检查binlog:
- 若 Binlog 中存在对应 XID 且事务完整(包含
COMMIT标记),则提交事务 - 若 Binlog 中不存在对应 XID 或事务不完整,则回滚事务
可以看到,对于处于 prepare 阶段的 redo log,即可以提交事务,也可以回滚事务,这取决于是否能在 binlog 中查找到与 redo log 相同的 XID,如果有就提交事务,如果没有就回滚事务。这样就可以保证 redo log 和 binlog 这两份日志的一致性了。
如何支持持久性
当进⾏DML操作时,为了防止在持久化的过程中发生错误
-
数据库通常会将磁盘上的数据页加载到内存中的缓冲池(如 MySQL InnoDB 的 Buffer Pool),以加速数据的读写操作。当 SQL 执行修改操作时,通常是修改内存中的数据(即缓冲池中的数据页)。这种修改称为“脏页”(Dirty Page),表示该数据页已被修改但尚未同步到磁盘。
-
我们会先将修改的数据保存起来然后再通知客户已经提交完成,这样在持久化发生故障时,可以利用备份的数据完成未完成的持久化操作。具体来说数据库会将操作的数据保存到叫做Redo Log的日志文件中
-
由于修改的数据有可能只是数据⻚中很少的⼀部分内容,甚⾄有可能只修改了⼏个字节,如果每次保存整个数据⻚的话就有太多的⽆⽤数据写⼊⽇志,这样严重影响效率⽽且浪费空间,所以,为了节省空间提⾼效率,RedoLog只记录物理修改操作,即磁盘上的实际修改,而不是完整的物理数据页,⽐如当前的DML修改了哪个表空间、表空间中的哪个数据⻚,数据⻚中多少偏移量处的值修改成了什么
-
在事务提交后需要将脏页(内存中修改过的数据页)刷新到磁盘上的表空间时,如果在刷盘时系统因为异常原因崩溃,会导致部分页写入问题损坏表空间数据,这种损坏靠redolog是无法恢复的,因为redolog只记录了修改的操作,而不记录完整的数据页。
-
因此mysql会先将脏页存储到内存中的双写缓冲区,然后分两步操作
- 第一步先将内存中的双写缓冲区的脏页按顺序刷新到共享表空间的双写缓冲区,这个时候是顺序写入,因为双写缓冲区在共享表空间是块连续的物理区域
- 第二步,脏页最终需要写入表空间文件(
.ibd文件)的原始位置,这些位置通常是分散的,可能涉及随机 IO。
-
通过两步操作可以确保不管什么情况下,至少有一个部分的数据是完整的。
-
如果第一步出错,表空间数据文件的数据是完整的,此时就从数据文件中拉取原始数据根据redo log得出正确的目标数据
- redo log 是 操作日志(如“修改页 X 偏移量 Y 处的值为 Z”),需要逐条解析、定位页、应用变更。
- 如果事务涉及大量操作(如批量更新),重放日志的时间会显著增加。
-
如果第二步出错,那么双写缓冲区的数据是完整的,则可以将双写缓冲区中的数据重新写入数据文件
不需要解析和重放 redo log 中的逻辑操作,节省时间和计算资源
-
通过Redo Log和双写缓冲区等机制。可以保存事务提交后的所有更改都不会因为任何意外而发生变化
更新操作流程
当我们执行一个修改操作整体步骤如下:
- 开启事务,分配事务 ID
- 执行修改操作前,生成undo log,保证每次操作真正的数据之前Undo Log是完整的,这样发生错误可以完美的撤销
- 修改内存中的数据页(暂时还不刷入磁盘)
- 更新redo log buffer,并根据策略同步到redo log 文件中(redo log一阶段提交:日志内修改的记录状态分别置为prepare)
- 事务提交阶段
- 更新binlog buffer,并根据策略同步到binlog 文件
- redo log二阶段提交:重做日志的状态置为commit
- 最后将3中的缓冲区数据刷入数据盘
Propagation(传播行为)
事务传播 是指当==多个事务方法相互调用时==,如何定义和管理事务的行为
事务传播简单示例
当我们遇到如下代码,在一个service中调用了另一个service的方法,此时bService的事务被传播到了aServcice,这样就发生了事务的传播
@Service
public class LearnService {
@Autowired
Bservice bservice;
public void order(){
yyyyy();
bservice.xxxxx();
zzzzz();
}
public void yyyyy(){}
public void zzzzz(){}
}
因为两个service都存在事务,那么生成的sql可能如下:
BEGIN:
update yyyy;
--------------两个事务分割线---------------
BEGIN:
update xxxx;
COMMIT;
------------------------------------------
update zzzz;
COMMIT;
这里就明显存在问题,当第二个begin执行的时候,会隐式的将第一个事务直接提交了,从而导致Aservice的部分事务失效。比如在 MySQL 的 InnoDB 存储引擎中不支持真正的事务嵌套,使用同一个连接时,显式开启新的事务会导致之前的事务隐式提交
处理的几种情况
融入
第一种情况:融入A事务(干掉B的事务),形成的sql如下,这种场景是最多的:
BEGIN:
update yyyy;
--------------两个事务分割线---------------
update xxxx;
------------------------------------------
update zzzz;
COMMIT;
挂起
挂起A事务,让B事务独立于A事务运行。
当两个事务需要各自独立维护自身事务,单个事务无法独立完成,B事务启动时可以暂时将A事务挂起
事务挂起
当前线程中已经存在一个事务时,如果需要创建一个新的事务(如REQUIRES_NEW),Spring 会执行以下步骤:
- 保存当前事务的状态:Spring 会将当前事务的相关资源(如数据库连接、事务状态等)从
TransactionSynchronizationManager中移除,并保存到一个临时存储中。 - 创建新的事务:Spring 会为新事务分配一个新的数据库连接,并将其绑定到当前线程的
TransactionSynchronizationManager。
事务恢复
当新事务完成(提交或回滚)后,Spring 会执行以下步骤:
- 恢复之前的事务状态:Spring 会将之前挂起的事务资源从临时存储中取出,并重新绑定到当前线程的
TransactionSynchronizationManager。 - 清理新事务的资源:Spring 会清理新事务相关的资源(如关闭新事务的数据库连接)。
此时看起来是这样处理:
BEGIN:
update yyyy;
--------------两个事务分割线(此时事务2使用新连接开启事务)---------------
begin
update xxxx;
commit
--------------事务2提交,事务1继续执行----------------------------
update zzzz;
COMMIT;
嵌套事务
通过设置保存点,将内部的事务转化为通过保存点和回滚至保存点,实现两个事务的操作,其伪代码如下:
begin
update mystudent set score = 100 where id = 1;
SAVEPOINT a;
update mystudent set score = 100 where id = 3;
update mystudent set score = 100 where id = 4;
--以上代码有问题就会回滚至保存点
ROLLBACK TO a;
--后边的事务不受影响
update mystudent set score = 100 where id = 2;
commit;
传播行为
综上所述,spring为我们提供了以下7种传播行为。
可以简单分为两类:
-
需要事务的
PROPAGATION_REQUIRED:当前方法需要运行在事务中,如果存在当前事务,则加入该事务;否则创建新事务(默认值)。PROPAGATION_REQUIRES_NEW:始终创建新事务,表示当前方法需要运行在自己的事务中,一个新的事务将会被启动。如果当前上下文中存在事务,则挂起当前存在的事务PROPAGATION_NESTED:如果存在当前事务,则在嵌套事务中运行;否则创建新事务。- 部分回滚:嵌套事务允许内层事务回滚到某个保存点,而外层事务可以继续提交。
- 依赖 JDBC 支持:保存点功能由 JDBC 驱动和底层数据库共同支持(例如 MySQL 的 InnoDB 引擎支持,而某些数据库可能不支持)。
- 当数据库或驱动程序不支持保存点时,
NESTED的“部分回滚”能力丧失,其行为会退化为类似于REQUIRED的表现。(设置回滚标记)
PROPAGATION_MANDATORY:强制性的,方法必须在一个已存在的事务上下文中运行,否则抛出异常。
-
可能不需要事务的
-
PROPAGATION_SUPPORTS:SUPPORTS表示支持(B事务会支持A的事务),如果有当前事务则加入,如果没有则以非事务方式运行。 -
PROPAGATION_NOT_SUPPORTED:不支持事务,表示方法不应该运行在事务中,如果当前上下文中存在事务,则挂起当前存在的事务。 -
PROPAGATION_NEVER:必须以非事务方式运行,如果存在事务则抛出异常。
-
NESTED和REQUIRES_NEW的区别
| 区别 | NESTED | REQUIRES_NEW |
|---|---|---|
| 事务独立性 | 主事务的一部分,共享同一个物理事务 | 创建一个全新的独立事务,与主事务完全无关 |
| 提交时机 | 提交由主事务统一控制 | 立即提交,不受主事务影响 |
| 局限性 | 依赖保存点(Savepoint)实现部分回滚 | 不依赖保存点,独立事务完全独立提交或回滚。 |
| 资源隔离性 | 共享主事务的数据库连接 | 使用新的数据库连接(或事务上下文),资源隔离 |
Isolation(事务的隔离级别)
事务的隔离级别是定义并发事务执行时之间相互影响程度的机制。通过设置不同的隔离级别,可以控制事务之间的可见性和交互程度,每个级别解决不同的并发问题
- 事务隔离级别本质上就是用来约束程序在并发执行时所能读取到的数据范围和状态,从而保证数据库的一致性、完整性和可预测性。
- 对于写写冲突,在数据库中一般在进行增删改时会自动加上排他锁,防止其他事务修改同一数据
以下是几种常见的隔离级别
常见的隔离级别
Read Uncommitted
-
**隔离性:**允许一个事务读取另一个事务尚未提交的数据(脏读)
-
解决的问题:无。允许所有并发问题。
-
性能:无并发控制,性能最高
读已提交(RC)
Read Committed
-
**隔离性:**只能读取到其他事务已提交的数据
-
解决的问题:避免脏读,确保只能读取到其他事务已提交的数据。
-
原理
- **使用锁:**每次读取数据时加共享锁(S)
- 当其他事务有数据修改未提交时,共享锁与排他锁竞争而阻塞,等到其他事务提交后,读取数据并返回。
- 当没有其他事务操作时,加共享锁,不允许其他人修改
- **MVCC:**每次查询生成一致性视图,与数据版本比较,找出可见版本
- **使用锁:**每次读取数据时加共享锁(S)
-
性能
- **锁机制:**每次查询完,释放锁,持锁时间短
- **MVCC:**每次查询完,释放一致性视图,不影响undolog被puge线程清理
在大多数数据库系统中是默认隔离级别(如 SQL Server 和 Oracle)。
可重复读(RR)
Repeatable Read
- **隔离性:**同一事务中多次读取同一数据的结果一致
- 解决的问题:解决了不可重复读(Non-Repeatable Read),确保在同一事务中多次读取同一数据的结果一致。
- 原理
- **使用锁:**每次读取数据时加共享锁(S)
- **MVCC:**事务开始时生成一次一致性视图(整个事务使用一个一致性视图),与数据版本比较,找出可见版本
- 使用当前读(FOR UPDATE或LOCK IN SHARE MODE)的情况下,InnoDB使用Next-Key Lock
- 快照读(普通的SELECT),则是通过MVCC来实现的,不需要加锁。
- 性能
- **锁机制:**整个事务期间都持有锁,持锁时间长
- **MVCC:**长事务,一直持有一致性视图,可能会导致puge线程无法清除undolog而导致undolog占用空间越来越多
MySQL 默认使用此隔离级别
幻读问题
要讨论「可重复读」隔离级别的幻读现象,是要建立在「当前读」的情况下,而不是快照读!
在可重复读隔离级别下,普通的查询是快照读,如果此时其他事务插入新事务并提交,因为其事务ID是大于当前活跃事务ID,所以对当前版本不可见,这种情况下没有幻读问题。
如果使用当前读(FOR UPDATE或LOCK IN SHARE MODE),每次查询都会强制查询最新版本的数据,因为无法通过MVCC机制过滤掉不在当前视图的版本,从而引发幻读问题。
串行化(S)
Serializable
-
**隔离性:**同一事务中多次读取同一个结果集的结果一致
-
解决的问题:完全避免脏读、不可重复读和幻读,确保事务按顺序执行
-
**原理:**通过严格的锁机制和特定的规则实现事务的完全串行执行,确保最高的数据一致性
-
**性能:**事务串行化运行,性能最低
串行化实现原理
-
锁机制升级:在 Serializable 级别下,MySQL 摒弃了 MVCC 多版本并发控制的性能,转而采用完全悲观锁机制,所有操作均通过锁竞争实现互斥。
- 读操作:在查询时不再使用 MVCC 快照读,而是强制加锁(共享锁),阻塞其他事务写操作
- 写操作:自动加排他锁(X Lock),与其他事务的写锁或者共享锁互斥。
-
**Next-Key Lock:Next-Key Lock 是 InnoDB 存储引擎中的一种锁机制,它是行锁(Record Lock)和间隙锁(Gap Lock)**的组合,它可以锁定范围,彻底解决幻读
-
对查询涉及的记录及相邻区间加锁,阻止其他事务插入/删除范围内的数据。
如果没有合适的索引,InnoDB 的锁机制可能会退化为表级锁(Table Lock),从而严重影响并发性能
-
-
两阶段锁协议:两阶段锁(Two-Phase Locking,简称 2PL)之所以被称为“两阶段”,是因为它将事务的执行过程明确划分为两个阶段:加锁阶段和解锁阶段。
- 加锁阶段:事务执行过程中逐步获取锁。
- 解锁阶段:事务提交或回滚后统一释放锁,避免中途释放导致不一致。
**总结:**mysql的串行化通过 强制加锁 + Next-Key Lock + 两阶段锁协议 实现事务的完全串行化,以牺牲并发性能为代价,确保数据绝对一致。
幻读与不可重复读的区别
幻读和不可重复读,它们的本质区别在于问题发生的范围不同。
| 特性 | 不可重复读(Non-Repeatable Read) | 幻读(Phantom Read) |
|---|---|---|
| 问题范围 | 针对单条记录的修改或删除 | 针对**一组记录(结果集)**的插入或删除 |
| 发生原因 | 其他事务修改了当前事务正在读取的某条数据 | 其他事务插入或删除数据,导致当前事务查询的结果集发生变化 |
| 解决方法 | 提高隔离级别到“可重复读” | 提高隔离级别到“串行化” |
不可重复读的场景
-
问题描述:在一个事务内,多次读取同一条记录时,结果可能不一致。
-
原因:其他事务对这条记录进行了修改并提交。
-
例子: 假设有一个表
employees:员工ID 工资 1 5000 - 事务A 查询员工1的工资,得到
5000。 - 事务B 将员工1的工资更新为
6000并提交。 - 事务A 再次查询员工1的工资,得到
6000。
结果:事务A两次读取同一条记录得到了不同的结果。
- 事务A 查询员工1的工资,得到
幻读的场景
-
问题描述:在一个事务内,多次执行相同的查询时,结果集可能发生变化(新增或删除记录)。
-
原因:其他事务插入或删除了某些记录,导致当前事务查询到的结果集发生变化。
-
例子: 假设有一个表
employees:员工ID 工资 1 5000 2 6000 - 事务A 查询所有工资大于
4000的员工,得到[员工1, 员工2]。 - 事务B 插入一条新记录:
员工3,工资7000,并提交。 - 事务A 再次查询所有工资大于
4000的员工,得到[员工1, 员工2, 员工3]。
结果:事务A两次查询得到了不同的结果集。
- 事务A 查询所有工资大于
为什么“可重复读”不能解决幻读?
在“可重复读”隔离级别下:
- 数据库会确保事务内的多次读取同一数据的结果一致(通过锁机制或 MVCC 实现)。
- 但是,“可重复读”并不锁定整个查询范围(例如,WHERE 条件涉及的记录集合),因此其他事务仍然可以插入符合条件的记录,从而导致幻读。
只有在“串行化”隔离级别下,数据库才会完全隔离事务,确保没有任何并发操作会影响当前事务的查询结果。
Timeout(超时时间)
**事务的Timeout(超时)**是指数据库系统为事务设置的一个时间限制,规定事务在指定时间内必须完成其操作,否则将被自动终止或回滚。这一机制在数据库管理和并发控制中扮演着重要角色。
什么是事务的Timeout?
事务的Timeout是一个时间阈值,通常以秒或毫秒为单位。如果一个事务在其执行过程中超过这个时间限制仍未完成,数据库系统会认为该事务可能陷入死锁、长时间阻塞或其他异常状态,并采取措施终止它。
Timeout的作用
防止死锁
如果多个事务相互等待对方释放资源(如行锁或表锁),可能会导致死锁。虽然大多数现代数据库系统有内置的死锁检测机制,但Timeout可以作为一种补充手段,在死锁检测失败或延迟过长的情况下强制终止事务。
减少资源浪费
如果某个事务由于网络问题、程序错误或其他原因而停滞不前,但它仍然持有锁或占用资源,这会导致资源浪费。Timeout可以确保这些资源在一定时间后被释放。
使用场景
- 高并发环境:在高并发的在线交易系统中,Timeout可以帮助快速识别和处理那些因锁竞争而停滞的事务。
- 批量处理任务:对于一些需要处理大量数据的批处理任务,可以通过设置合理的Timeout来避免单个任务耗时过长。
- 分布式事务:在分布式系统中,Timeout可以用来应对网络延迟或节点故障等问题。
ReadOnly(只读标志)
什么是事务的只读标记?
只读事务(Read-Only Transaction)是数据库中仅执行查询操作而不修改数据的事务,它通过限制事务的修改能力,从而降低锁冲突使得数据库能够更高效地处理查询操作。
它对性能的影响既有优化潜力,也可能引入特定问题,具体取决于数据库实现、隔离级别和场景设计。
优点
- 共享锁的优化:某些数据库(如 SQL Server)在默认隔离级别下,读操作会加共享锁(Shared Locks),而显式声明只读事务可能允许更轻量级的锁或无锁机制(如快照读)。
- **日志的优化:**例如 Oracle对于只读事务,不启动回滚段,不记录回滚log。
潜在的负面影响
-
版本链过长(MVCC 特有)
-
问题:长期未提交的只读事务可能导致 MVCC 版本链无法清理,增加存储占用和查询延迟。
-
案例:一个运行数小时的只读事务会阻止旧版本数据的回收,导致表膨胀。
-
-
快照隔离的开销
-
维护快照一致性:在
REPEATABLE READ或SERIALIZABLE隔离级别下,数据库需要维护事务开始时的数据快照,可能消耗额外内存和 CPU 资源。 -
高并发场景的瓶颈:大量并发的只读事务可能导致快照版本管理压力增大,影响整体性能。
-
一致性视图生成规则
- 只读事务无需显式提交(如
START TRANSACTION READ ONLY后自动结束)。 - Read View 规则:
- 非 RR 级别:每条查询可能生成新 Read View(如 RC)。
- RR 级别:整个只读事务共享一个 Read View(在第一次查询时生成)。
使用场景
只读事务适用于以下场景:
- 报表生成:当需要从数据库中提取大量数据生成报表时,可以使用只读事务以避免对主数据库造成负担。
- 数据分析:在数据仓库或OLAP系统中,只读事务用于复杂的分析查询。
- 缓存预热:在系统启动或维护后,使用只读事务加载数据到缓存中。
- 监控和审计:查询系统状态或历史记录时,通常只需要只读访问。
总之,当你明确知道事务仅用于查询时,启用只读模式是一种有效的性能优化手段,它通过减少锁、日志记录的开销,显著加快数据处理速度。
Qualifier(限定符)
为事务指定一个名称或标识符,用于区分不同的事务配置。在多事务管理器的场景下,通过限定符绑定特定的事务管理器。
在事务注解中,使用value属性即可设置Qualifier
Rollback Rules(回滚规则)
Rollback Rules 是一组预定义的规则,用于决定在哪些情况下应该撤销事务中的操作。这些规则可以基于错误类型、事务状态或其他条件触发。
- rollbackFor:指定哪些异常会导致事务回滚。
- rollbackForClassName:通过类名指定哪些异常会导致事务回滚。
- noRollbackFor:指定哪些异常不会导致事务回滚。
- noRollbackForClassName:通过类名指定哪些异常不会导致事务回滚。
数据库的读写分离
这里讲主从复制其实和事务没啥关系,主要时上面讲了undo log和redo log,在这里通过读写分离再补充一下binlog。
随着应用业务数据不断的增大,应用的响应速度不断下降,在检测过程中我们不难发现大多数的请求都是查询操作。此时,我们可以将数据库扩展成主从复制模式,将读操作和写操作分离开来,多台数据库分摊请求,从而减少单库的访问压力,进而应用得到优化
读写分离就是主库实时将变更通过复制同步到存库中,确保存库也有完整的业务数据副本,而访问数据的流量分摊到主库和存库上,主库可读可写,从库只读。
实现数据库的读写分离,主要依靠以下几个技术
负载均衡
- 设置代理,代理根据预设规则将流量引导至合适的节点
- 代码层面,定制空间大,缺点是每条
sql都要决策走主库还是从库。在数据库主备切换、故障迁移的情况下,集群中,每台机器都要在配置中删除下线的服务器
binlog
MySQL Binlog 是一种记录数据库变更操作的日志文件,主要用于主从复制和数据恢复。它支持多种记录格式,并且可以通过配置启用
Binlog三种格式
MySQL 的 Binlog记录的主要是逻辑日志并且支持三种格式:Statement、Row 和 Mixed。不同格式记录的内容和方式有所不同。
-
Statement 格式:
-
记录的是 SQL 语句本身。
-
==优点:==存储空间相对较小,因为记录的是 SQL 语句,而不是每一行的变化。在数据量较少或操作较简单的情况下,可以减少 binlog 文件的大小。
-
缺点:如果 SQL 语句执行的上下文环境发生了变化(如某些数据的内容或环境不同),则可能会导致从服务器的数据不一致,因为从服务器会执行与主服务器相同的 SQL 语句。
SQL 执行可能依赖于一些外部上下文环境(如系统时间、随机数、用户变量等),而这些环境在主从服务器上可能不同,从而导致数据不一致
-
-
Row 格式:
-
记录的是每一行数据的具体变化(Before Image 和 After Image)。
-
优点:更精确,每个操作都被记录为数据行的变化,确保了主从服务器的数据一致性。在一些复杂的 SQL 操作中,ROW 格式能更好地反映数据的实际变动。
-
缺点:由于每行数据的变化都被记录下来,binlog 的存储空间相对较大。当表中数据变化频繁时,生成的 binlog 文件也会较大。
比如一条update语句或者一条alter语句,修改多条记录,则binlog中每一条修改都会有记录,每条记录都发生改变,那么该表每一条记录都会记录到日志中,这样造成binlog日志量会很大。
-
-
Mixed 格式:
- MIXED 格式是 STATEMENT 和 ROW 格式的混合体。MySQL 会根据执行的具体 SQL 语句决定使用 STATEMENT 还是 ROW 格式。
- 优点:MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的变更。
- 缺点:因为 MySQL 自动根据 SQL 语句的复杂性选择不同的日志格式,配置\调试更复杂。
为什么不记录物理日志
MySQL 的 Binlog 设计为 逻辑日志(记录 SQL 语句或行变更前后的数据),而非物理日志,核心原因如下:
-
**跨环境兼容性:**物理日志记录了数据页在磁盘上的实际更改,即具体字节的变化。由于物理日志的这种特性,其依赖数据库的硬件架构、底层存储细节(页空间大小、表空间布局等等)。binlog主要用来主从复制以及数据恢复,这两种场景中,主库和从库或者说目标环境和备份源,他们的的硬件架构和存储结构都可能不同。所以为了保证跨环境兼容性,binlog采用逻辑日志,逻辑日志(如sql语句)是通用的,即使硬件架构和底层存储细节都不一样也不影响逻辑日志的使用
-
支持多存储引擎
-
Binlog 是 MySQL Server 层的日志,需兼容多种存储引擎(如 InnoDB、MyISAM)。
-
物理日志与存储引擎强耦合(如 InnoDB 的 Redo Log 格式),无法统一描述不同引擎的物理操作。
- 即使物理日志记录的是字节级别的修改,这些修改的意义只有结合存储引擎的上下文才能被正确解读。
- 不同存储引擎对数据页的定义和操作逻辑不同,物理日志的设计必须适配这些差异。
比如:
- InnoDB的B+树节点页包含索引项、指针、事务ID等复杂字段。
- MyISAM的堆文件页则只包含行数据,没有复杂的索引结构。
如果物理日志不理解存储引擎的页结构,就无法准确描述修改的内容。因此,物理日志的设计必须与存储引擎的页结构紧密绑定。
-
逻辑日志(如“插入一行数据”)是引擎无关的,可适配所有引擎。
-
binlog的应用场景
-
**数据的复制:**binlog是mysql服务在修改数据时产生的操作日志,通过在从库上重放binlog可以重现主库的数据修改操作,进而达到主从的数据同步
-
**数据的恢复:**binlog可以支持基于时间点或者位置的恢复方式,可以精确到秒级别,非常适合于需要高精度数据恢复的场景,具体步骤如下:
-
数据库通常会定期进行全量备份(例如每天一次)。找到最近的一次全量备份文件。
-
将该备份恢复到一个新的数据库实例中
-
使用
mysqlbinlog工具提取从备份时间到误操作发生时间之间的binlog事件(更精确的是使用position确定恢复的范围)。mysqlbinlog --start-position=123 --stop-position=456 binlog.000001 > incremental.sql- 将提取的增量SQL文件应用到恢复的数据库中
如果使用了GTID,需要跳过GTID的部分
-
binlog和redolog的区别
在数据库管理系统中,日志系统扮演着至关重要的角色,它记录了数据库的所有更改,从而确保在发生故障时能够恢复数据。其中,binlog(二进制日志)和redolog(重做日志)是两种不同类型的日志,它们在功能、特点和应用场景上存在显著差异。
| 区别 | redolog | binlog |
|---|---|---|
| 功能差异 | 主要用于确保事务的持久性。当数据库发生异常宕机后,可以通过redolog来进行数据的恢复,保证已提交事务的修改不会丢失 | 主要用于数据的复制和数据的恢复。 |
| 所属层级 | redolog只属于mysql的innodb引擎 | binlog由MySQL服务器层维护,与存储引擎无关 |
| 存储格式 | 为了确保事务的持久性,并在崩溃恢复时快速重做操作。redolog主要记录的是物理日志,即数据页在磁盘上的实际更改,这样可以避免解析复杂的操作语义并重建数据页,效率较高,并且不依赖数据库的逻辑状态 | binlog主要记录的是逻辑日志,Row(记录每行数据的修改)、Statement(记录sql语句)、Mixed(根据执行的每一条具体的sql语句来区分对待记录的日志形式) |
| 存储管理 | 由固定大小的多个文件组成(如ib_logfile0、ib_logfile1),写满后循环复用旧空间。 | binlog文件会定期进行滚动,写满一个文件后会创建新文件继续写入,不会覆盖旧日志 |
| 写入时机 | 事务开始后,每次数据修改都会记录redolog,此时状态是prepare,事务提交后状态为commit | 在事务提交前才会记录修改的操作。 |
主从复制
在主从架构中,主库(Master)生成 Binlog,从库(Slave)通过读取和重放这些 Binlog 来同步主库的数据变更。
数据同步问题
由于binlog发送有延迟,会造成数据不同步,以下是几种解决方法
- 在某些场景可以让读操作强制放在主库上来执行,比如用户自己下的订单就在主库上查询,接单的商家去从库上查询。反正商家晚几秒查询订单,影响也不大。
- 通过业务流程,比如下单后先让用户抽个奖,也为从库争取了更多的同步窗口
mysql支持三种复制模式
异步复制
- 从服务器从主服务器读取二进制日志的内容,并且把读取到的信息写入本地的日志文件中,这个从服务器本地的日志文件就叫中继日志。
- 从服务器读取中继日志,并根据中继日志的内容对从服务器的数据进行更新,完成主从服务器的数据同步。
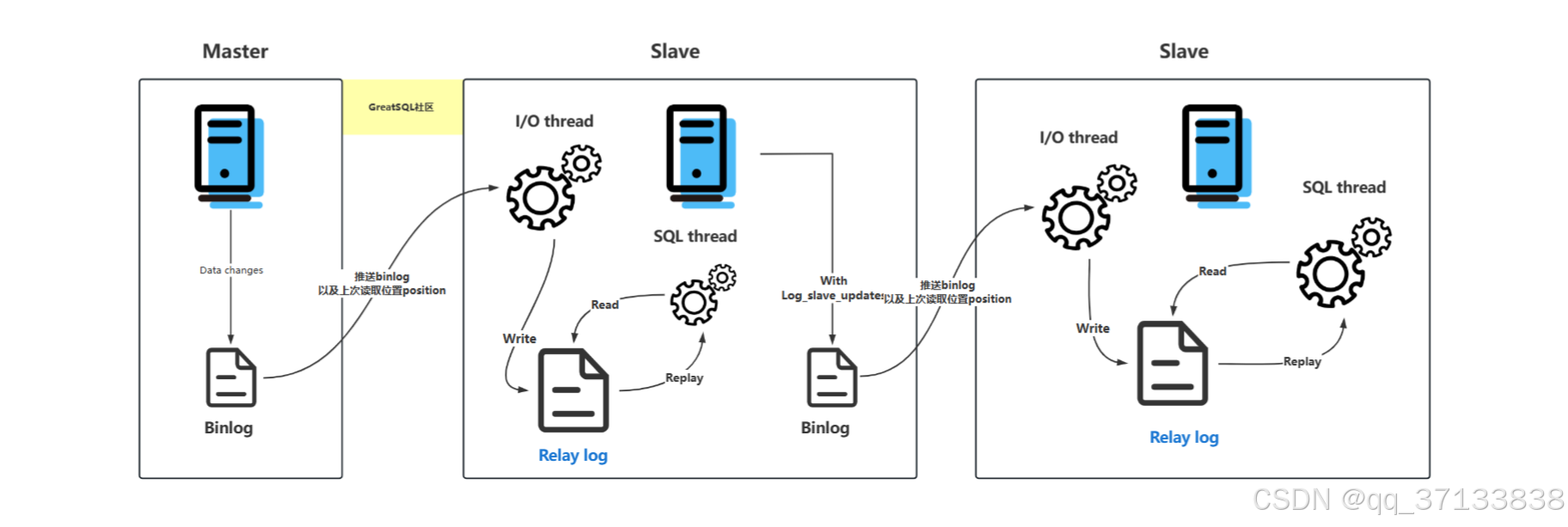
中继日志是连接mastert(主服务器)和slave(从服务器)的信息,它是复制的核心,I/O线程将来自master的binlog存储到中继日志中,中继日志充当缓冲,这样master不必等待slave执行完成就可以发送下一个binlog。
即使在网络中断或主服务器临时不可用的情况下,中继日志允许从服务器继续处理已接收但未应用的事件,确保数据的一致性和完整性。
半同步复制
在主从复制时会出现binlog还未传输,主库宕机的情况
上面那种就是异步复制模式:主库在执行完客户端提交的事务后,只要将执行逻辑写入到binlog后,就立即返回给客户端,并不关心从库是否执行成功,这样就会有一个隐患,就是在主库执行的binlog还没同步到从库时,主库挂了,
这种情况下:客户端在主库提交后立即可见数据,若主库崩溃且从库未同步,切换后数据丢失,这导致业务逻辑错误,客户会发现明明返回成功了,但是查不到数据。
所以就有了半同步模式:
主库在执行完客户端提交的事务后,要等待至少一个从库接收到binlog并将数据写入到relay log中才返回给客户端成功结果。
半同步模式比异步模式提高了数据的可用性,但是也产生了一定的性能延迟,最少要一个TCP/IP连接的往返时间
AFTER_SYNC
半同步复制模式也存在一定的数据风险,事务在主库提交完后等待从库ACK的过程中,其他事务可以看到本次的修改,因此可能会对此做出相应的动作,此时主库宕机传输binlog失败时,从库无法同步本次修改,可能会造成意料之外的错误
为了解决上面的隐患,MySQL从5.7版本开始,增加了一种新的半同步方式,新的半同步方式的执行过程是将主库提交的动作放在从库返回ACK结果之后。
MySQL 5.7.2版本新增了一个参数来进行配置:rpl_semi_sync_master_wait_point,此参数有两个值可配置:
AFTER_SYNC:参数值为AFTER_SYNC时,代表采用的是新的半同步复制方式。
AFTER_COMMIT:代表采用的是之前的旧方式的半同步复制模式
这样保证了只有从库收到了主库的binlog后,才提交主库事务。
优越性
事务隔离性保障:在AFTER_SYNC模式下,主库在等待从库确认期间,事务仍处于未提交状态(存储引擎层未提交)。此时:
- 其他事务无法读取该事务的修改(依赖隔离级别,如默认的
REPEATABLE READ)。 - 事务持有的锁(如行锁、间隙锁)不会释放,避免其他事务修改相同数据,导致锁冲突或数据不一致。
局限性
- **无法完全消除主从不一致:**若主库在binlog发送到从库前崩溃,会因为mysql的故障恢复导致事务提交(redolog二次提交机制),此时从库因为没有收到binlog不会同步。这种情况下还是会出现主从不一致
- **依赖外部机制补充:**需结合其他高可用方案,形成完整的数据一致性保障体系。
- 网络与架构优化
- 网络可靠性:使用专线、冗余网络链路,减少binlog传输中断风险。
- 拓扑简化:避免跨地域主从复制,降低网络延迟和分区风险。
- 自动化运维
- **高可用工具:**使用MHA(Master High Availability)、Orchestrator等工具,自动检测主库故障并修复数据差异。
- 实时监控:监控主从延迟、半同步复制状态,及时报警人工介入。
- 网络与架构优化
- 性能:
AFTER_SYNC模式下,等待从库ACK时,会持有更新记录的锁;与此相反,AFTER_COMMIT模式下,因为等待ACK时,事务已经提交,不再持有记录的锁;这意味着,在AFTER_SYNC模式下每个事务持有锁的时间延长了一段ACK时间,写入耗时一定会随着事务之间的锁竞争频繁度与ACK耗时体现出来。所以在处理热点数据时,AFTER_SYNC性能会很明显不如AFTER_COMMIT
GTID复制
需要注意的是:GTID是对复制机制的增强,GTID模式并不是独立的复制模式,可以与异步或半同步模式一起使用
GTID 解决逻辑层面的复制位点管理问题。
在GTID模式下可以消除对 binlog 文件名和位置(file+pos) 的依赖,通过全局事务标识符(GTID)实现复制的 逻辑自洽。
关键能力
- 主从切换友好:
切换主库时,从库自动基于 GTID 同步新主库的数据,无需人工查找位点。 - 容灾能力:
若主库的 binlog 被清理,但事务存在于其他副本(如级联从库)中,从库可直接从其他副本拉取缺失事务。
实现原理
GTID是由UUID+TransactionId组成的,UUID是单个MySQL实例的唯一标识,在第一次启动MySQL实例时会自动生成一个server_uuid,并且默认写入到数据目录下的auto.cnf(mysql/data/auto.cnf)文件里。TransactionId是该MySQL上执行事务的数量,随着事务数量增加而递增。这样保证了GTID在一组复制中,全局唯一
此时流程如下:
- master更新数据时,在事务前生产
GTID,一同记录到binlog中 - slave端的i/o线程,将变更的
binlog写入到relay log中 sql线程从relay log中获取GTID,然后对比Slave端的binlog是否有记录- 如果有记录,说明该
GTID的事务已经执行,slave会忽略该GTID - 如果没有记录,
Slave会从relay log中执行该GTID事务,并记录到binlog
示例
-
传统复制:
主库A宕机,切换至主库B。从库需手动执行:CHANGE MASTER TO MASTER_HOST='主库B', MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=154;若指定的
file+pos错误,复制将中断。 -
GTID模式:
从库自动执行:CHANGE MASTER TO MASTER_HOST='主库B';复制自动基于 GTID 继续,无需人工干预。
中继日志损坏问题
从库因 物理层面故障(如宕机、OOM-Killer、磁盘损坏)导致 relay log 文件损坏或不一致时,确保复制能安全恢复。
relay_log_recovery
采用relay_log_recovery=ON,从库重启时会检查 relay log 的完整性。如果发现 relay log 损坏或与 SQL 线程执行位置不一致,会丢弃现有 relay log,以 SQL 线程已执行的位置为起点,重新向主库请求binlog。
- **依赖条件:**主库必须保留从库请求的 binlog 位置。
- **适用场景:**物理故障(如磁盘损坏、OOM-Killer)导致的 relay log 损坏。
手动处理
在主库binlog已经删除的情况下,需要手工找到备份的binlog日志和pos点,然后重新同步。
-
操作步骤
-
停止从库复制:
STOP SLAVE; -
清理损坏的 relay log:重置
relay_log.index或删除物理文件。 -
通过
SHOW SLAVE STATUS\G获取当前复制位点(Relay_Master_Log_File和Exec_Master_Log_Pos)。 -
重新指定复制起点:
CHANGE MASTER TO MASTER_LOG_FILE='binlog.000002', MASTER_LOG_POS=154; -
启动复制:
START SLAVE;
-
-
风险:
- 若手动指定的位点错误,可能导致数据重复或丢失。
- 若主库已清理对应的 binlog,需从备份恢复。
MVCC
相比传统的锁机制,MVCC(Multi-Version Concurrency Control) 通过版本控制确保每个事务看到的数据是符合其隔离级别的要求,每个事务在操作数据时,看到的是该数据的一个特定版本,而不是实时的数据状态,这样能够显著减少锁的竞争,提升系统性能
MVCC 的实现原理
官方定义
InnoDB通过为每一行记录添加两个额外的隐藏的值来实现MVCC
实际上对应于下面的 DB_TRX_ID 和 Undo Log。
- 这两个值一个记录这行数据何时被创建
- 另外一个记录这行数据何时过期。
但是InnoDB并不存储这些事件发生时的实际时间,相反它只存储这些事件发生时的系统版本号(LSN)。这是一个随着事务的创建而不断增长的数字。每个事务在事务开始时会记录它自己的系统版本号。每个查询必须去检查每行数据的版本号与事务的版本号是否相同。
具体实现
隐藏字段
在Innodb存储引擎中每一行记录中都会隐藏俩个字段
这俩个隐藏列一个记录的是何时被创建的,一个记录的是什么时候被删除。
-
DB_TRX_ID:记录创建这条数据的事务 ID
-
DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本
MVCC通过 Undo Log 存储历史版本的数据,而 DB_ROLL_PTR 是指向 Undo Log 中某个历史版本的指针。
当一条记录被修改时,当前版本会被保留,同时生成一个新的版本,并更新 DB_ROLL_PTR 指向旧版本的 Undo Log。
示例:
假设有一条记录的初始状态如下:
| id | value | DB_TRX_ID | DB_ROLL_PTR |
|---|---|---|---|
| 1 | 100 | 5 | NULL |
-
第一次修改:
-
事务 ID 为 10 的事务将
value修改为 200。 -
新版本记录:
id value DB_TRX_ID DB_ROLL_PTR 1 200 10 PTR_1 -
PTR_1 是指向 Undo Log 中旧版本(
value=100)的指针。
-
-
第二次修改:
-
事务 ID 为 15 的事务将
value修改为 300。 -
新版本记录:
id value DB_TRX_ID DB_ROLL_PTR 1 300 15 PTR_2 -
PTR_2 是指向 Undo Log 中上一个版本(
value=200)的指针。
-
-
读取旧版本:
- 如果一个系统版本号为 8 的事务需要读取这条记录,则它会通过 DB_ROLL_PTR 追踪到 PTR_1,找到 Undo Log 中的旧版本(
value=100)。
- 如果一个系统版本号为 8 的事务需要读取这条记录,则它会通过 DB_ROLL_PTR 追踪到 PTR_1,找到 Undo Log 中的旧版本(
undo log(回滚日志)
当一条记录被修改时,InnoDB 不会直接覆盖原数据,而是将旧版本的数据存储到 Undo Log 中,并更新当前记录的 DB_ROLL_PTR 指向这个旧版本。
一致性视图
一致性视图(Read View)是什么?
- 一致性视图(Read View) 是事务开始时生成的一个逻辑视图,记录了当前活跃事务的快照信息。
- 它的主要目的是帮助事务判断某行数据是否可见,从而实现隔离性。
活跃事务
在数据库系统中,活跃事务(Active Transactions) 是指那些==已经开始但尚未完成(提交或回滚)==的事务。
在事务生命周期中,一个事务从开始到结束会经历以下几个阶段:
- 开始(Start):事务被创建并分配一个唯一的事务 ID。
- 执行(Execute):事务执行一系列的操作(如读、写、修改等)。
- 提交(Commit):事务成功完成,所有更改被永久保存。
- 回滚(Rollback):事务因某种原因失败,所有更改被撤销。
只有在事务提交或回滚之前,它才被认为是活跃事务。
Read View 包含的内容
- m_ids:在创建 Read View 时,系统中所有活跃事务的事务 ID 列表。
- min_trx_id:在创建 Read View 时,当前活跃事务中最小的事务 ID。
- max_trx_id:创建 Read View 时系统分配给下一个新事务的事务 ID。
- creator_trx_id:创建该 Read View 的事务本身的事务 ID。
生成时机
获取数据库连接后
数据库连接本身并不等同于事务。多个事务可以共享同一个连接。
-
在无事务的情况下(
auto-commit = true),每次 SQL 语句都会被视为一个独立的事务,并且立即提交。这意味着:-
在 RC 隔离级别下,每次查询都会生成一个新的
read view。 -
在 RR 隔离级别下,由于每个查询是一个独立的事务,无法保证多次查询的结果一致。
-
因此,如果你希望使用事务的隔离级别(特别是 RR),必须显式关闭自动提交模式(setAutoCommit(false)),否则数据库无法正确维护事务的 read view。
- 当事务显式开启(即调用
setAutoCommit(false)或通过框架管理事务)时,数据库会为该事务生成一个初始的read view。这个read view定义了事务可见的数据版本范围。
如何确定数据的版本
确定版本的基本原则
确定数据版本的核心机制是通过比较事务开始时生成的 Read View 和数据的当前版本及 Undo Log 来实现的。
-
当前版本是否可见
-
首先检查当前版本的数据是否符合当前事务的一致性视图(Read View)。
-
如果当前版本对当前事务可见,则直接返回该版本的数据。
-
-
如果当前版本不可见
-
如果当前版本不可见,则通过 回滚指针(DB_ROLL_PTR) 追溯到 Undo Log 中的历史版本。
-
在历史版本中继续判断每个版本的可见性,直到找到一个符合 Read View 的版本或到达最早的版本。
-
具体步骤
检查版本的事务ID和一致性视图中记录的活跃事务ID,是否满足以下条件
-
如果
DB_TRX_ID < min_trx_id:说明该事务已提交,数据可见(因为所有活跃事务的 ID 均 ≥DB_TRX_ID)。 -
如果
DB_TRX_ID > max_trx_id:说明该版本是在当前 Read View 创建之后修改的,因此对当前事务不可见。- 当一个事务(记为事务 A)生成 Read View 后,其他新的事务(记为事务 B、C 等)仍然可以启动并修改数据。
- 如果这些新事务的修改发生在事务 A 的 Read View 创建之后,那么这些修改对事务 A 是不可见的。
-
如果
min_trx_id <= DB_TRX_ID <= max_trx_id需要进一步检查DB_TRX_ID是否在m_ids列表中:- 若事务 ID 不在
m_ids中,说明该事务已提交,数据可见。 - 若事务 ID 在
m_ids中,说明该事务尚未提交,数据不可见。
- 若事务 ID 不在
示例
假设当前事务开始时的一致性视图(Read View)如下:
min_trx_id = 10max_trx_id = 25m_ids = [10, 15, 20]
查询数据的历史版本(undo log)
| 版本 | value | DB_TRX_ID | DB_ROLL_PTR |
|---|---|---|---|
| V1 | 100 | 5 | NULL |
| V2 | 200 | 10 | PTR_1 |
| V3 | 300 | 15 | PTR_2 |
当前版本如下:
| id | value | DB_TRX_ID | DB_ROLL_PTR |
|---|---|---|---|
| 1 | 400 | 25 | PTR_3 |
事务 A 的读取过程
事务 A 开始时生成了上述 Read View。
事务 A 尝试读取某行数据,检查各个版本的可见性:
- 检查当前版本
DB_TRX_ID = 25- 因为
25 > max_trx_id = 25,说明该版本是在 Read View 创建之后才被创建的,因此对事务 A 不可见。 - 追溯到历史版本 V3。
- 检查历史版本 V3
DB_TRX_ID = 15- 因为
15在m_ids列表[10, 15, 20]中,说明该版本是由活跃事务修改的,因此对事务 A 不可见。 - 追溯到历史版本 V2。
- 检查历史版本 V2
DB_TRX_ID = 10- 因为
10在m_ids列表[10, 15, 20]中,说明该版本也是由活跃事务修改的,因此对事务 A 不可见。 - 追溯到历史版本 V1。
- 检查历史版本 V1
DB_TRX_ID = 5- 因为
5 < min_trx_id = 10,说明该版本是在 Read View 创建之前提交的,因此对事务 A 可见。
最终结果
- 事务 A 读取到的值为
value = 100。
Purge(清理)机制
如果一条记录被频繁修改,会产生大量的历史版本数据,而其中一些版本可能永远不会被使用。这种情况会导致 Undo Log 的快速增长,并占用存储空间。为了解决这个问题,InnoDB 引入了 Purge(清理)机制。
Purge 是 InnoDB 的一种后台清理机制,用于删除 Undo Log 中那些不再需要的历史版本数据。它的主要目标是释放存储空间,避免 Undo Log 无限增长
清理规则
- 事务已提交且不再需要的历史版本:如果某个事务已经提交,并且所有相关的读操作都已经完成(即没有事务需要再访问这些历史版本),那么这些版本就可以被 Purge。
- 活跃事务中,Read View 不再引用的版本:在 MVCC 中,每个事务都有一个 Read View,它定义了哪些版本对当前事务是可见的。当所有事务的 Read View 都不再引用某个版本时,该版本就可以被清理。
在mysql Innodb的Rollback Segment Header的history list中把所有已经提交但还没有被purge事务的undo log串联起来,purge线程可以通过此list对没有事务使用的undo log进行purge。
对于一个事务来说,早于read_view::m_low_limit_no的undo log都不需要访问了;那么如果存在一个read view,其read_view::m_low_limit_no比所有read view的m_low_limit_no都要小,那么小于此read_view::m_low_limit_no的undo log就不在被所有活跃事务所需要了,那么这些undo log就可以清理了。
局限性与适用性
适用性
MVCC 通过记录版本控制,天然适配 RC 和 RR 的核心需求(解决脏读、不可重复读),因此适用于这两个隔离级别。
- **读已提交(Read Committed):**MVCC 会为每次读操作生成一个快照版本,确保读取的是最新提交的数据版本。
- **可重复读(Repeatable Read):**MVCC 会为事务生成一个事务开始时的快照版本,确保在整个事务期间读取的数据一致。
局限性
然而对于幻读,在RR级别下,仅靠MVCC无法完全解决幻读问题,因为MVCC,只能解决快照读的幻读,而无法解决当前读的幻读,当前读的幻读仍然需要结合间隙锁解决
mysql死锁
死锁是指两个或者多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环的现象。当多个事务试图以不同的顺序锁定资源时,就可能会产生死锁。
以下是 MySQL 死锁形成的典型场景
典型场景
行锁顺序不一致
两个事务以不同的顺序访问多行数据,导致互相等待对方持有的锁。
示例:
-- 事务A
BEGIN;
UPDATE users SET balance = balance - 100 WHERE id = 1; -- 持有id=1的行锁
UPDATE users SET balance = balance + 100 WHERE id = 2; -- 请求id=2的行锁
-- 事务B
BEGIN;
UPDATE users SET balance = balance - 200 WHERE id = 2; -- 持有id=2的行锁
UPDATE users SET balance = balance + 200 WHERE id = 1; -- 请求id=1的行锁
- 死锁形成:
- 事务A持有id=1的锁,等待id=2的锁。
- 事务B持有id=2的锁,等待id=1的锁。
- 循环等待触发死锁。
间隙锁(Gap Lock)冲突
在 可重复读(RR) 隔离级别下,事务对间隙加锁,导致插入操作互相阻塞。
示例:
-- 表中现有数据:id=10, id=20, id=30
-- 事务A
BEGIN;
SELECT * FROM users WHERE id > 15 FOR UPDATE; -- 对间隙(15, 20)、(20, 30)加间隙锁
-- 事务B
BEGIN;
SELECT * FROM users WHERE id > 25 FOR UPDATE; -- 对间隙(25, 30)加间隙锁
INSERT INTO users (id) VALUES (22); -- 事务B尝试插入id=22(位于事务A的锁定间隙)
INSERT INTO users (id) VALUES (28); -- 事务A尝试插入id=28(位于事务B的锁定间隙)
- 死锁形成:
- 事务A锁定间隙(15, 30),事务B锁定间隙(25, 30)。
- 事务B插入id=22时,需要等待事务A释放间隙锁。
- 事务A插入id=28时,需要等待事务B释放间隙锁。
- 循环等待触发死锁。
为什么间隙锁与间隙锁之间是兼容的?
间隙锁是MySQL InnoDB引擎在可重复读(Repeatable Read)隔离级别下引入的一种锁机制,用于锁定某个记录之间的间隙,以防止其他事务在这个间隙中==插入数据==,从而避免幻读问题。
间隙锁的设计初衷是防止插入数据造成的不一致,而不是为了互相排他。因此,多个事务可以同时对同一间隙加锁。
-
间隙锁不锁定具体的行
-
它仅锁定记录之间的间隙,并不会阻止现有记录的更新或删除。
而已存在记录的更新和删除由MVCC或者读写锁控制
-
比如,事务A和事务B都可以锁住(id=5, id=10)的间隙,但彼此不会阻塞。
-
-
间隙锁的目的只是防止插入
- 如果间隙锁之间不兼容,任何查询操作都会互相阻塞,降低并发性能。
- 兼容性允许事务读取相同的间隙,而只阻止插入。
总结
间隙锁之间的兼容性是为了提高并发性能,同时确保数据的一致性和隔离性。在解决幻读问题的同时,不会额外增加事务的等待时间。
插入意向锁
插入意向锁(Insert Intention Lock)是MySQL InnoDB引擎在执行插入操作时加上的一种特殊的间隙锁,用来表明当前事务有意在某个间隙中插入数据。
插入意向锁的主要目的是协调插入操作与其他间隙锁之间的关系,以确保数据一致性并避免冲突。
- 如果另一个事务已经对某个间隙加了间隙锁,插入意向锁会被阻塞,直到间隙锁释放。
- 如果没有间隙锁,多个事务可以同时设置插入意向锁,并在不同的位置插入数据。
MySQL 的死锁处理机制
为了解决死锁问题,数据库系统实现了各种死锁检测和死锁超时机制。
- 死锁检测:越复杂的系统,比如InnoDB存储引擎,越能检测到死锁的循环依赖,井立即返回一个错误。这种解决方式很有效,否则死锁会导致出现非常慢的查询
- 死锁超时:当查询的时间达到锁等待超时的设定后放弃锁请求,这种方式通常来说不太好
InnoDB自前处理死锁的方法是,将持有==最少行级排他锁的事务进行回滚==(这是相对比较简单的死锁回滚算法)。
事务增强器
TransactionInterceptor支撑着整个事务功能的架构,逻辑还是相对复杂的,那么现在我们切入正题来分析此拦截器是如何实现事务特性的。
TransactionInterceptor类继承自MethodInterceptor,所以调用该类是从其invoke方法开始的,首先预览下这个方法:
TransactionInterceptor.invoke
public Object invoke(final MethodInvocation invocation) throws Throwable {
// Work out the target class: may be {@code null}.
// The TransactionAttributeSource should be passed the target class
// as well as the method, which may be from an interface.
//获取目标类
Class<?> targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null);
// Adapt to TransactionAspectSupport's invokeWithinTransaction...
return invokeWithinTransaction(invocation.getMethod(), targetClass, new InvocationCallback() {
@Override
public Object proceedWithInvocation() throws Throwable {
return invocation.proceed();
}
});
}
TransactionAspectSupport.invokeWithinTransaction
protected Object invokeWithinTransaction(Method method, Class<?> targetClass, final InvocationCallback invocation)
throws Throwable {
// If the transaction attribute is null, the method is non-transactional.
//获取对应事务属性
final TransactionAttribute txAttr = getTransactionAttributeSource().getTransactionAttribute(method, targetClass);
//获取beanFactory中的transactionManager,多个transactionManager通过注解中的Qualifier(限定符)属性指定
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
//构造方法唯一标识(类.方法,如service.UserServiceImpl.save)
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
//声明式事务处理
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// Standard transaction demarcation with getTransaction and commit/rollback calls.
//创建TransactionInfo
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// This is an around advice: Invoke the next interceptor in the chain.
// This will normally result in a target object being invoked.
//执行被增强方法
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// target invocation exception
//异常回滚
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
//清除信息
cleanupTransactionInfo(txInfo);
}
//提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
}
else {
final ThrowableHolder throwableHolder = new ThrowableHolder();
// It's a CallbackPreferringPlatformTransactionManager: pass a TransactionCallback in.
//编程式事务处理
try {
Object result = ((CallbackPreferringPlatformTransactionManager) tm).execute(txAttr,
new TransactionCallback<Object>() {
@Override
public Object doInTransaction(TransactionStatus status) {
TransactionInfo txInfo = prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
try {
return invocation.proceedWithInvocation();
}
catch (Throwable ex) {
if (txAttr.rollbackOn(ex)) {
// A RuntimeException: will lead to a rollback.
if (ex instanceof RuntimeException) {
throw (RuntimeException) ex;
}
else {
throw new ThrowableHolderException(ex);
}
}
else {
// A normal return value: will lead to a commit.
throwableHolder.throwable = ex;
return null;
}
}
finally {
cleanupTransactionInfo(txInfo);
}
}
});
// Check result state: It might indicate a Throwable to rethrow.
if (throwableHolder.throwable != null) {
throw throwableHolder.throwable;
}
return result;
}
catch (ThrowableHolderException ex) {
throw ex.getCause();
}
catch (TransactionSystemException ex2) {
if (throwableHolder.throwable != null) {
logger.error("Application exception overridden by commit exception", throwableHolder.throwable);
ex2.initApplicationException(throwableHolder.throwable);
}
throw ex2;
}
catch (Throwable ex2) {
if (throwableHolder.throwable != null) {
logger.error("Application exception overridden by commit exception", throwableHolder.throwable);
}
throw ex2;
}
}
}
从上面的函数中,我们尝试整理下事务处理的脉络,在Spring中支持两种事务处理的方式,分别是声明式事务处理与编程式事务处理,两者相对于开发人员来讲差别很大,但是对于Spring中的实现来讲,大同小异。在invoke中我们也可以看到这两种方式的实现。考虑到对事务的应用声明式的事务处理使用起来方便,也相对流行些,我们就以此种方式进行分析。对于声明式的事务处理主要有以下几个步骤。
-
获取事务的属性
- 对于事务处理来说,最基础或者说最首要的工作便是获取事务属性了,这是支撑整个事务功能的基石,如果没有事务属性,其他功能也无从谈起,在分析事务准备阶段时我们已经分析了事务属性提取的功能
-
加载配置中配置的TransactionManager
-
不同的事务处理方式使用不同的逻辑:对于声明式事务的处理与编程式事务的处理
- CallbackPreferringPlatformTransactionManager:暴露出一个方法用于执行事务处理中的回调
- 非回调方式
- 获取事务并收集事务信息:事务信息与事务属性并不相同,也就是
TransactionInfo与TransactionAttribute并不相同,TransactionInfo中包含TransactionAttribute信息,但是,除了TransactionAttribute外还有其他事务信息,例如PlatformTransactionManager以及TransactionStatus相关信息。 - 执行目标方法
- 一旦出现异常,尝试异常处理:默认只对RuntimeException回滚
- 提交事务前的事务信息清除。
- 提交事务。
- 获取事务并收集事务信息:事务信息与事务属性并不相同,也就是
获取事务属性
在对方法增强前,会通过TransactionAttributeSource解析方法的事务属性判断该方法是否需要增强,解析后的事务属性,会通过method和targetClass生成的组合key存储在缓存中,这里直接去缓存中获取。
AbstractFallbackTransactionAttributeSource.getTransactionAttribute
public TransactionAttribute getTransactionAttribute(Method method, Class<?> targetClass) {
if (method.getDeclaringClass() == Object.class) {
return null;
}
// First, see if we have a cached value.
Object cacheKey = getCacheKey(method, targetClass);
Object cached = this.attributeCache.get(cacheKey);
if (cached != null) {
// Value will either be canonical value indicating there is no transaction attribute,
// or an actual transaction attribute.
if (cached == NULL_TRANSACTION_ATTRIBUTE) {
return null;
}
else {
return (TransactionAttribute) cached;
}
}
else {
// We need to work it out.
TransactionAttribute txAttr = computeTransactionAttribute(method, targetClass);
// Put it in the cache.
if (txAttr == null) {
this.attributeCache.put(cacheKey, NULL_TRANSACTION_ATTRIBUTE);
}
else {
String methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
if (txAttr instanceof DefaultTransactionAttribute) {
((DefaultTransactionAttribute) txAttr).setDescriptor(methodIdentification);
}
if (logger.isDebugEnabled()) {
logger.debug("Adding transactional method '" + methodIdentification + "' with attribute: " + txAttr);
}
this.attributeCache.put(cacheKey, txAttr);
}
return txAttr;
}
}
寻找transactionManager
TransactionAspectSupport.determineTransactionManager
protected PlatformTransactionManager determineTransactionManager(TransactionAttribute txAttr) {
// Do not attempt to lookup tx manager if no tx attributes are set
if (txAttr == null || this.beanFactory == null) {
return getTransactionManager();
}
String qualifier = txAttr.getQualifier();
if (StringUtils.hasText(qualifier)) {
return determineQualifiedTransactionManager(qualifier);
}
else if (StringUtils.hasText(this.transactionManagerBeanName)) {
return determineQualifiedTransactionManager(this.transactionManagerBeanName);
}
else {
PlatformTransactionManager defaultTransactionManager = getTransactionManager();
if (defaultTransactionManager == null) {
defaultTransactionManager = this.transactionManagerCache.get(DEFAULT_TRANSACTION_MANAGER_KEY);
if (defaultTransactionManager == null) {
defaultTransactionManager = this.beanFactory.getBean(PlatformTransactionManager.class);
this.transactionManagerCache.putIfAbsent(
DEFAULT_TRANSACTION_MANAGER_KEY, defaultTransactionManager);
}
}
return defaultTransactionManager;
}
}
根据上述代码,可以看出寻找transactionManager经理了以下步骤:
- 获取事务属性的
qualifier属性,如果存在则获取指定的事务管理器,用于处理可能存在的多个事务管理器的情况 - 根据
transactionManagerBeanName获取(解析标签时设置)- 设置了transaction-manager,则取transaction-manager属性设置的值
- 否则设置默认的名称:transactionManager
- 根据
PlatformTransactionManager类型获取默认的transactionManager
对于第二步来说,当我们通过事务注解开启事务时,无论无何都会有一个TransactionManagerName,我们继续看看获取transactionManager的具体实现
determineQualifiedTransactionManager
TransactionAspectSupport.determineQualifiedTransactionManager
private PlatformTransactionManager determineQualifiedTransactionManager(String qualifier) {
PlatformTransactionManager txManager = this.transactionManagerCache.get(qualifier);
if (txManager == null) {
txManager = BeanFactoryAnnotationUtils.qualifiedBeanOfType(
this.beanFactory, PlatformTransactionManager.class, qualifier);
this.transactionManagerCache.putIfAbsent(qualifier, txManager);
}
return txManager;
}
- 首先通过名称从容器中获取
- 通过类型和限定名称获取
- 会获取bean的别名alias匹配
- 会获取bean的qualifier属性匹配
获取事务方法标识
获取事务方法的唯一标识,在事务名称没有显示指定时,通过该标识作为事务名称
TransactionInterceptor.methodIdentification
private String methodIdentification(Method method, Class<?> targetClass, TransactionAttribute txAttr) {
String methodIdentification = methodIdentification(method, targetClass);
if (methodIdentification == null) {
if (txAttr instanceof DefaultTransactionAttribute) {
methodIdentification = ((DefaultTransactionAttribute) txAttr).getDescriptor();
}
if (methodIdentification == null) {
methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
}
}
return methodIdentification;
}
-
第一优先级:
methodIdentification(method, targetClass)-
调用
methodIdentification(method, targetClass)方法尝试获取事务名称。 -
这个方法的具体实现未提供,为了扩展性创建的钩子方法
-
-
第二优先级:
DefaultTransactionAttribute的getDescriptor()-
如果第一步返回
null,并且txAttr是DefaultTransactionAttribute类型,则调用其getDescriptor()方法。 -
getDescriptor()提供了一个可选的描述信息 -
在TransactionAttributeSource解析事务属性时,如果返回的是
DefaultTransactionAttribute类型,则会调用第三优先级的方法生成唯一标识
-
-
第三优先级:
ClassUtils.getQualifiedMethodName(method, targetClass)-
如果前两步都无法获取事务名称,则调用
ClassUtils.getQualifiedMethodName(method, targetClass)。 -
该方法会生成一个包含类名和方法名的完整标识符,格式为:
<类名>.<方法名>。 -
这是一个默认的兜底规则,确保事务名称始终不会为空。
-
事务处理方式
- 声明式事务是通过配置或注解的方式,在不修改业务代码的情况下,将事务管理逻辑与业务逻辑分离的一种事务管理方式。
- 非侵入性:事务管理逻辑通过配置或注解实现,不需要在业务代码中显式编写事务控制代码。
- 易于维护:事务规则集中定义,便于统一管理和调整。
- 基于AOP:底层依赖Spring AOP机制,通过代理对象拦截方法调用并应用事务规则。
- 编程式事务是通过手动编码的方式,在业务代码中显式地控制事务的开始、提交和回滚。
- 侵入性:需要在业务代码中显式编写事务管理逻辑。
- 灵活性高:适合处理复杂的事务场景,例如动态决定事务行为。
CallbackPreferringPlatformTransactionManager
示例
public class MyTransactionManager extends DataSourceTransactionManager implements CallbackPreferringPlatformTransactionManager {
@Override
public <T> T execute(TransactionDefinition definition, TransactionCallback<T> callback) throws TransactionException {
//获取事务属性
RuleBasedTransactionAttribute txAttr = (RuleBasedTransactionAttribute) definition;
//新建rollback规则
ArrayList<RollbackRuleAttribute> rollBackRules = new ArrayList<RollbackRuleAttribute>();
rollBackRules.add(new RollbackRuleAttribute(MyException.class));
txAttr.setRollbackRules(rollBackRules);
T t;
TransactionStatus transactionStatus = null;
try {
//获取事务状态,内部根据事务传播行为,为我们执行特定操作并返回事务状态
transactionStatus = this.getTransaction(txAttr);
t = callback.doInTransaction(transactionStatus);
//提交事务
this.commit(transactionStatus);
}
catch (Throwable ex) {
//回滚事务
rollback(transactionStatus);
throw ex;
}
return t;
}
}
源码分析
TransactionAspectSupport.invokeWithinTransaction片段
final ThrowableHolder throwableHolder = new ThrowableHolder();
// It's a CallbackPreferringPlatformTransactionManager: pass a TransactionCallback in.
try {
//如果是CallbackPreferringPlatformTransactionManager调用它的execute方法执行事务逻辑
Object result = ((CallbackPreferringPlatformTransactionManager) tm).execute(txAttr,
//callback用于执行目标方法和回滚逻辑的处理
new TransactionCallback<Object>() {
@Override
public Object doInTransaction(TransactionStatus status) {
//旧的事务信息挂起,将传入的事务属性与线程绑定
TransactionInfo txInfo = prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
try {
return invocation.proceedWithInvocation();
}
catch (Throwable ex) {
if (txAttr.rollbackOn(ex)) {
// A RuntimeException: will lead to a rollback.
if (ex instanceof RuntimeException) {
throw (RuntimeException) ex;
}
else {
throw new ThrowableHolderException(ex);
}
}
else {
// A normal return value: will lead to a commit.
throwableHolder.throwable = ex;
return null;
}
}
finally {
cleanupTransactionInfo(txInfo);
}
}
});
// Check result state: It might indicate a Throwable to rethrow.
if (throwableHolder.throwable != null) {
throw throwableHolder.throwable;
}
return result;
TransactionAspectSupport.prepareTransactionInfo
protected TransactionInfo prepareTransactionInfo(PlatformTransactionManager tm,
TransactionAttribute txAttr, String joinpointIdentification, TransactionStatus status) {
TransactionInfo txInfo = new TransactionInfo(tm, txAttr, joinpointIdentification);
if (txAttr != null) {
// We need a transaction for this method...
if (logger.isTraceEnabled()) {
logger.trace("Getting transaction for [" + txInfo.getJoinpointIdentification() + "]");
}
// The transaction manager will flag an error if an incompatible tx already exists.
txInfo.newTransactionStatus(status);
}
else {
// The TransactionInfo.hasTransaction() method will return false. We created it only
// to preserve the integrity of the ThreadLocal stack maintained in this class.
if (logger.isTraceEnabled())
logger.trace("Don't need to create transaction for [" + joinpointIdentification +
"]: This method isn't transactional.");
}
// We always bind the TransactionInfo to the thread, even if we didn't create
// a new transaction here. This guarantees that the TransactionInfo stack
// will be managed correctly even if no transaction was created by this aspect.
//我们总是将TransactionInfo绑定到线程,即使我们没有在这里创建新事务。这保证了TransactionInfo堆栈将被正确管理,即使这个方面没有创建任何事务。
txInfo.bindToThread();
return txInfo;
}
TransactionAspectSupport.bindToThread
private void bindToThread() {
// Expose current TransactionStatus, preserving any existing TransactionStatus
// for restoration after this transaction is complete.
this.oldTransactionInfo = transactionInfoHolder.get();
transactionInfoHolder.set(this);
}
spring对CallbackPreferringPlatformTransactionManager和其他TransactionManager的处理方式不同,CallbackPreferringPlatformTransactionManager是通过回调的方式执行目标方法和回滚逻辑,且不会帮我们开启事务或者提交事务,事务状态需要由我们自己控制,所以这属于编程式事务,其执行逻辑可以分为以下几步
-
在其execute方法里可以对事务属性进行编程式的定制
-
execute方法里执行callback前,需要提供事务状态,事务状态封装了当前事务上下文信息
-
在execute里执行
TransactionCallback的doInTransaction执行目标方法 -
在声明式事务当中,spring会创建一个默认的
TransactionCallback-
从当前线程中获取旧的事务信息放入自己的oldTransactionInfo属性中,而将自身绑定到当前线程中
官方注释:我们总是将TransactionInfo绑定到线程,即使我们没有在这里创建新事务。这保证了TransactionInfo堆栈将被正确管理,即使这个方面没有创建任何事务。
此外每个事务方法执行完毕后会恢复上个事务方法的TransactionInfo信息 -
执行目标方法
-
如果报错了,检查错误是否需要回滚
- 需要回滚,抛错
- 不需要回滚,将错误记录,正常返回。
-
最终清除事务信息,恢复挂起事务
-
-
执行完毕后我们需要自己根据是否报错来控制是否回滚
总结
CallbackPreferringPlatformTransactionManager通过回调机制执行事务逻辑。- 开发者可以在
execute方法中编程式地定制事务属性。 - 事务状态需要手动获取,并在回调逻辑执行后控制提交或回滚。
- 这种方式属于编程式事务,与声明式事务的主要区别在于开发者需要显式控制事务生命周期。
非回调方式
这里是声明式的事务处理方式,由spring控制事务的管理
获取事务
获取事务状态并封装进TransactionInfo,它封装了以下三个信息
-
**transactionManager:**定义了如何获取事务的规则以及如何提交和回滚事务
-
**transactionAttribute:**保存了用户配置的事务信息
-
**transactionStatus:**事务状态,可以相当于事务的上下文环境(具体解析看后面的章节:spring事务重要组件的分析),是spring事务中非常重要的一个属性
因为获取事务的流程较为复杂,所以在下面单开一章进行解析
执行目标方法
事务增强器本质上是一个MethodInterceptor,需要通过spring的AOP模块管理,这里是直接调用bean增强时获取的拦截器链的processed方法
异常处理
当出现错误的时候,Spring是怎么对数据进行恢复的呢?
TransactionAspectSupport.completeTransactionAfterThrowing
protected void completeTransactionAfterThrowing(TransactionInfo txInfo, Throwable ex) {
//当抛出异常时首先判断当前是否存在事务上下文环境,这是基础依据
if (txInfo != null && txInfo.hasTransaction()) {
if (logger.isTraceEnabled()) {
logger.trace("Completing transaction for [" + txInfo.getJoinpointIdentification() +
"] after exception: " + ex);
}
//这里判断是否回滚默认的依据是抛出的异常是否是RuntimeException或者是Error的类型
if (txInfo.transactionAttribute.rollbackOn(ex)) {
try {
//根据TransactionStatus信息进行回滚处理
txInfo.getTransactionManager().rollback(txInfo.getTransactionStatus());
}
catch (TransactionSystemException ex2) {
logger.error("Application exception overridden by rollback exception", ex);
ex2.initApplicationException(ex);
throw ex2;
}
catch (RuntimeException ex2) {
logger.error("Application exception overridden by rollback exception", ex);
throw ex2;
}
catch (Error err) {
logger.error("Application exception overridden by rollback error", ex);
throw err;
}
}
else {
// We don't roll back on this exception.
// Will still roll back if TransactionStatus.isRollbackOnly() is true.
//如果不满足回滚条件即使抛出异常也同样会提交
try {
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
catch (TransactionSystemException ex2) {
logger.error("Application exception overridden by commit exception", ex);
ex2.initApplicationException(ex);
throw ex2;
}
catch (RuntimeException ex2) {
logger.error("Application exception overridden by commit exception", ex);
throw ex2;
}
catch (Error err) {
logger.error("Application exception overridden by commit error", ex);
throw err;
}
}
}
}
- 当抛出异常时首先判断当前是否存在事务上下文环境,这是基础依据
- 判断当前异常是否符合设定的回滚规则
- 符合,进行回滚
- 不符合,执行提交方法
rollbackOn
这里的txInfo保存的是DelegatingTransactionAttribute,在获取txInfo时通过DelegatingTransactionAttribute对RuleBasedTransactionAttribute进行了封装,主要是增加了getName方法获取事务方法的标识
RuleBasedTransactionAttribute.rollbackOn
public boolean rollbackOn(Throwable ex) {
if (logger.isTraceEnabled()) {
logger.trace("Applying rules to determine whether transaction should rollback on " + ex);
}
RollbackRuleAttribute winner = null;
int deepest = Integer.MAX_VALUE;
if (this.rollbackRules != null) {
for (RollbackRuleAttribute rule : this.rollbackRules) {
int depth = rule.getDepth(ex);
if (depth >= 0 && depth < deepest) {
deepest = depth;
winner = rule;
}
}
}
if (logger.isTraceEnabled()) {
logger.trace("Winning rollback rule is: " + winner);
}
// User superclass behavior (rollback on unchecked) if no rule matches.
if (winner == null) {
logger.trace("No relevant rollback rule found: applying default rules");
return super.rollbackOn(ex);
}
return !(winner instanceof NoRollbackRuleAttribute);
}
首先判断rollbackRules有没有设置,有的话根据设置的规则进行判断,否则执行父类的方法
DefaultTransactionAttribute.rollbackOn
public boolean rollbackOn(Throwable ex) {
return (ex instanceof RuntimeException || ex instanceof Error);
}
rollback
AbstractPlatformTransactionManager.rollback
public final void rollback(TransactionStatus status) throws TransactionException {
//如果事务已经完成,那么再次回滚会抛出异常
if (status.isCompleted()) {
throw new IllegalTransactionStateException(
"Transaction is already completed - do not call commit or rollback more than once per transaction");
}
DefaultTransactionStatus defStatus = (DefaultTransactionStatus) status;
processRollback(defStatus);
}
AbstractPlatformTransactionManager.processRollback
private void processRollback(DefaultTransactionStatus status) {
try {
try {
//激活TransactionSynchronization中对应的方法(beforeCompletion)
triggerBeforeCompletion(status);
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Rolling back transaction to savepoint");
}
//如果有保存点,也就是当前事务为单独的线程则会退到保存点
status.rollbackToHeldSavepoint();
}
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction rollback");
}
//如果当前事务为独立的新事务,则直接回退
doRollback(status);
}
else if (status.hasTransaction()) {
//如果当前事务不是独立的事务,那么只能标记状态,等到事务链执行完毕后统一回滚
if (status.isLocalRollbackOnly() || isGlobalRollbackOnParticipationFailure()) {
if (status.isDebug()) {
logger.debug("Participating transaction failed - marking existing transaction as rollback-only");
}
doSetRollbackOnly(status);
}
else {
if (status.isDebug()) {
logger.debug("Participating transaction failed - letting transaction originator decide on rollback");
}
}
}
else {
logger.debug("Should roll back transaction but cannot - no transaction available");
}
}
catch (RuntimeException ex) {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
throw ex;
}
catch (Error err) {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
throw err;
}
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
}
finally {
//清空记录的资源并将挂起的资源恢复
cleanupAfterCompletion(status);
}
}
-
在执行
rollback前需要执行triggerBeforeCompletion关于这点的解析在下面的
prepareSynchronization章节讲解-
在回滚前执行其
beforeCompletion方法 -
在回滚后执行其
afterCompletion方法
-
-
如果有保存点,则会退到保存点
-
根据保存点回滚的实现方式其实是根据底层的数据库连接进行的。
AbstractTransactionStatus.rollbackToHeldSavepoint
public void rollbackToHeldSavepoint() throws TransactionException { if (!hasSavepoint()) { throw new TransactionUsageException( "Cannot roll back to savepoint - no savepoint associated with current transaction"); } //这里其实就是使用的DefaultTransactionStatus的DataSourceTransactionObject(它继承JdbcTransactionObjectSupport,JdbcTransactionObjectSupport实现了SavepointManager) getSavepointManager().rollbackToSavepoint(getSavepoint()); getSavepointManager().releaseSavepoint(getSavepoint()); setSavepoint(null); }
-
-
如果当前事务为独立的新事务,则直接回退
-
如果当前存在事务,那么只能标记回滚状态,等到事务链执行完毕后统一回滚
-
cleanupAfterCompletion:回滚后的信息清除,对于回滚逻辑执行结束后,无论回滚是否成功,都必须要做的事情就是事务结束后的收尾工作。这点放在提交的时候一起解析
嵌套事务(NESTED)
在提交前我们需要讲下嵌套事务的逻辑
-
支持保存点时:部分回滚
- 如果数据库和驱动程序支持保存点(例如大多数关系型数据库如 MySQL、PostgreSQL 等),Spring 会通过保存点实现嵌套事务的部分回滚。
- 当嵌套事务发生异常时,Spring 会回滚到嵌套事务创建时设置的保存点,而不会影响父事务的其他操作。
- 父事务可以继续运行并最终提交。
-
不支持保存点时:整体回滚
在我们分析事务异常处理规则的时候,当某个事务既没有保存点又不是新事务,Spring对它的处理方式只是设置一个回滚标识。这个回滚标识在这里就会派上用场了,它主要用于处理嵌套事务无法设置保存点以及REQUIRED传播行为(融入到原事务)的场景。
- 当嵌套事务无法通过保存点(Savepoint)实现独立回滚时(例如某些数据库不支持保存点),Spring 会使用回滚标识来协调事务行为。
- 如果嵌套事务发生了异常,Spring 会将该事务标记为回滚状态,但不会立即执行回滚操作。
- 当外部事务准备提交时,Spring 会检查所有嵌套事务的状态。如果发现任何嵌套事务被标记为回滚,则整个事务会被回滚。(相当于
REQUIRED传播行为)
所以,当事务没有被异常捕获的时候也并不意味着一定会执行提交的过程。
比如,内层事务的回滚规则捕获了异常并设置了回滚标记,外层事务的回滚规则没有捕获此异常,去提交,发现回滚标记已设置,则会进行回滚,而不会提交
总结
- 首先判断rollbackRules有没有设置该异常类型
- 如果上一步没有的话,则判断是不是
RuntimeException
也就是说spring默认只回滚RuntimeException的异常
提交事务前的事务信息清除
TransactionAspectSupport.cleanupTransactionInfo
protected void cleanupTransactionInfo(TransactionInfo txInfo) {
if (txInfo != null) {
txInfo.restoreThreadLocalStatus();
}
}
private void restoreThreadLocalStatus() {
// Use stack to restore old transaction TransactionInfo.
// Will be null if none was set.
transactionInfoHolder.set(this.oldTransactionInfo);
}
主要用于恢复旧的TransactionInfo信息,将旧的TransactionInfo信息与线程绑定
提交事务
TransactionAspectSupport.commitTransactionAfterReturning
在有**“事务上下文”**的情况下执行commit方法
protected void commitTransactionAfterReturning(TransactionInfo txInfo) {
if (txInfo != null && txInfo.hasTransaction()) {
if (logger.isTraceEnabled()) {
logger.trace("Completing transaction for [" + txInfo.getJoinpointIdentification() + "]");
}
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
}
AbstractPlatformTransactionManager.commit
public final void commit(TransactionStatus status) throws TransactionException {
if (status.isCompleted()) {
throw new IllegalTransactionStateException(
"Transaction is already completed - do not call commit or rollback more than once per transaction");
}
DefaultTransactionStatus defStatus = (DefaultTransactionStatus) status;
//查看本地回滚标记
if (defStatus.isLocalRollbackOnly()) {
if (defStatus.isDebug()) {
logger.debug("Transactional code has requested rollback");
}
processRollback(defStatus);
return;
}
//判断全局回滚标记
if (!shouldCommitOnGlobalRollbackOnly() && defStatus.isGlobalRollbackOnly()) {
if (defStatus.isDebug()) {
logger.debug("Global transaction is marked as rollback-only but transactional code requested commit");
}
processRollback(defStatus);
// Throw UnexpectedRollbackException only at outermost transaction boundary
// or if explicitly asked to.
if (status.isNewTransaction() || isFailEarlyOnGlobalRollbackOnly()) {
throw new UnexpectedRollbackException(
"Transaction rolled back because it has been marked as rollback-only");
}
return;
}
//处理事务提交
processCommit(defStatus);
}
-
判断本地回滚标记:表示当前事务(物理事务或逻辑事务)内部显式要求回滚,代码中手动调用
TransactionStatus.setRollbackOnly()时,会设置本地回滚标记。public void save(User user) throws Exception { jdbcTemplate.update("insert into user(name,age,sex)values(?,?,?)", new Object[] { user.getName(), user.getAge(), user.getSex() }, new int[] { java.sql.Types.VARCHAR, java.sql.Types.INTEGER, java.sql.Types.VARCHAR }); TransactionInterceptor.currentTransactionStatus().setRollbackOnly(); } -
判断全局回滚标记:表示整个事务链(如嵌套事务或分布式事务)需要回滚
-
shouldCommitOnGlobalRollbackOnly:用于判断子事务设置了回滚的情况下,外层事务是否仍然需要提交-
AbstractPlatformTransactionManager默认设置的是false -
JtaTransactionManager设置的是true这里不太清楚JtaTransactionManager重写这个方法的作用,如果有知道的可以给我留言,万分感谢!
-
-
isGlobalRollbackOnly-
在嵌套事务中,子事务的失败并不会直接回滚,而是会设置事务连接的回滚标记,由外层事务判断该标记进行回滚
-
在分布式事务中,某个资源(如数据库)的失败可能触发全局回滚。
public boolean isGlobalRollbackOnly() { //调用transactionStatus的transaction的isRollbackOnly方法,当子事务回滚时会调用transaction的setRollbackOnly方法 return ((this.transaction instanceof SmartTransactionObject) && ((SmartTransactionObject) this.transaction).isRollbackOnly()); } -
-
processCommit
具体提交逻辑在processCommit里
AbstractPlatformTransactionManager.processCommit
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
prepareForCommit(status);
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
beforeCompletionInvoked = true;
boolean globalRollbackOnly = false;
if (status.isNewTransaction() || isFailEarlyOnGlobalRollbackOnly()) {
globalRollbackOnly = status.isGlobalRollbackOnly();
}
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Releasing transaction savepoint");
}
//如果存在保存点则清除保存点信息
status.releaseHeldSavepoint();
}
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction commit");
}
//如果是独立的事务则直接提交
doCommit(status);
}
// Throw UnexpectedRollbackException if we have a global rollback-only
// marker but still didn't get a corresponding exception from commit.
if (globalRollbackOnly) {
throw new UnexpectedRollbackException(
"Transaction silently rolled back because it has been marked as rollback-only");
}
}
catch (UnexpectedRollbackException ex) {
// can only be caused by doCommit
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
throw ex;
}
catch (TransactionException ex) {
// can only be caused by doCommit
//提交过程中出现异常则回滚
if (isRollbackOnCommitFailure()) {
doRollbackOnCommitException(status, ex);
}
else {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
}
throw ex;
}
catch (RuntimeException ex) {
if (!beforeCompletionInvoked) {
triggerBeforeCompletion(status);
}
doRollbackOnCommitException(status, ex);
throw ex;
}
catch (Error err) {
if (!beforeCompletionInvoked) {
triggerBeforeCompletion(status);
}
doRollbackOnCommitException(status, err);
throw err;
}
// Trigger afterCommit callbacks, with an exception thrown there
// propagated to callers but the transaction still considered as committed.
try {
triggerAfterCommit(status);
}
finally {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_COMMITTED);
}
}
finally {
cleanupAfterCompletion(status);
}
}
- 首先执行事务同步管理器的回调
- triggerBeforeCommit
- triggerBeforeCompletion
- 如果存在保存点则清除保存点信息
- 如果是独立的事务则直接提交
- 再次执行回调
- triggerAfterCommit
- triggerAfterCompletion
- 执行清理工作
triggerBeforeCommit
我们拿其中一个回调方法做分析,其他的差不多
AbstractPlatformTransactionManager.triggerBeforeCompletion
protected final void triggerBeforeCompletion(DefaultTransactionStatus status) {
if (status.isNewSynchronization()) {
if (status.isDebug()) {
logger.trace("Triggering beforeCompletion synchronization");
}
TransactionSynchronizationUtils.triggerBeforeCompletion();
}
}
isNewTransaction
并且注意,只有isNewTransaction为true时才会执行提交操作
DefaultTransactionStatus.isNewTransaction
public boolean isNewTransaction() {
return (hasTransaction() && this.newTransaction);
}
必须要满足两个条件:
-
hasTransaction:如果不满足,说明当前无事务,不需要提交,这种情况存在于
PROPAGATION_NOT_SUPPORTED,这种情况下不需要提交事务,因为是无事务运行DefaultTransactionStatus.hasTransaction
public boolean hasTransaction() { return (this.transaction != null); } -
newTransaction:如果不满足,说明不是新的事务,提交操作交给旧的事务处理,这种情况存在于
PROPAGATION_REQUIRED、PROPAGATION_SUPPORTS等情况,可能需要融入到别人的事务,通过newTransaction标记,可以判断当前事务是不是自己的事务,由此来判断需不需要自己提交
对于第一种情况,可能会有人疑惑为什么无事务运行也会进入到提交操作了,这是因为,spring判断是否执行提交,是根据有无**TransactionStatus**判断的,这里可以追溯到上面提交事务的开头,spring通过txInfo.hasTransaction判断是否需要执行提交操作
TransactionAspectSupport.TransactionInfo.hasTransaction()
public boolean hasTransaction() {
return (this.transactionStatus != null);
}
而通过AbstractPlatformTransactionManager.getTransaction获取事务时(可以查看下面获取事务的解析),无论如何都会返回一个TransactionStatus,而不管有没有实际事务,这是因为只要通过了这种方式获取事务,说明当前方法需要在spring事务上下文中运行
这种情况下不管TransactionStatus当中有没有transaction,都需要通过执行提交操作,触发其回调机制,最重要的就是清理资源操作了,就是finally代码中的cleanupAfterCompletion,比如在PROPAGATION_NOT_SUPPORTED下用于恢复挂起的事务
cleanupAfterCompletion
AbstractPlatformTransactionManager.cleanupAfterCompletion
private void cleanupAfterCompletion(DefaultTransactionStatus status) {
status.setCompleted();
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.clear();
}
if (status.isNewTransaction()) {
doCleanupAfterCompletion(status.getTransaction());
}
if (status.getSuspendedResources() != null) {
if (status.isDebug()) {
logger.debug("Resuming suspended transaction after completion of inner transaction");
}
//恢复挂起资源
resume(status.getTransaction(), (SuspendedResourcesHolder) status.getSuspendedResources());
}
}
-
设置状态是对事务信息作完成标识以避免重复调用。
-
如果当前事务是新的同步状态,需要将绑定到当前线程的事务信息清除。
DataSourceTransactionManager.doCleanupAfterCompletion
protected void doCleanupAfterCompletion(Object transaction) { DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction; // Remove the connection holder from the thread, if exposed. if (txObject.isNewConnectionHolder()) { //将数据库连接从当前线程中解除绑定 TransactionSynchronizationManager.unbindResource(this.dataSource); } // Reset connection. //释放链接 Connection con = txObject.getConnectionHolder().getConnection(); try { if (txObject.isMustRestoreAutoCommit()) { //恢复数据库连接的自动提交属性 con.setAutoCommit(true); } //重置数据库连接 DataSourceUtils.resetConnectionAfterTransaction(con, txObject.getPreviousIsolationLevel()); } catch (Throwable ex) { logger.debug("Could not reset JDBC Connection after transaction", ex); } if (txObject.isNewConnectionHolder()) { if (logger.isDebugEnabled()) { logger.debug("Releasing JDBC Connection [" + con + "] after transaction"); } //如果当前事务时独立的新创建的事务则在事务完成时释放数据库连接 DataSourceUtils.releaseConnection(con, this.dataSource); } txObject.getConnectionHolder().clear(); } -
如果有挂起的资源需要进行恢复。
AbstractPlatformTransactionManager.resume
protected final void resume(Object transaction, SuspendedResourcesHolder resourcesHolder) throws TransactionException { if (resourcesHolder != null) { Object suspendedResources = resourcesHolder.suspendedResources; if (suspendedResources != null) { doResume(transaction, suspendedResources); } List<TransactionSynchronization> suspendedSynchronizations = resourcesHolder.suspendedSynchronizations; if (suspendedSynchronizations != null) { TransactionSynchronizationManager.setActualTransactionActive(resourcesHolder.wasActive); TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(resourcesHolder.isolationLevel); TransactionSynchronizationManager.setCurrentTransactionReadOnly(resourcesHolder.readOnly); TransactionSynchronizationManager.setCurrentTransactionName(resourcesHolder.name); doResumeSynchronization(suspendedSynchronizations); } } }
获取事务
TransactionAspectSupport.createTransactionIfNecessary
protected TransactionInfo createTransactionIfNecessary(
PlatformTransactionManager tm, TransactionAttribute txAttr, final String joinpointIdentification) {
// If no name specified, apply method identification as transaction name.
//在未指定事务名称时动态地为事务设置一个默认名称(即 joinpointIdentification)。
//确保每个事务都有一个明确的名称,便于调试、日志记录和事务管理。
if (txAttr != null && txAttr.getName() == null) {
txAttr = new DelegatingTransactionAttribute(txAttr) {
@Override
public String getName() {
return joinpointIdentification;
}
};
}
TransactionStatus status = null;
if (txAttr != null) {
if (tm != null) {
//获取TransactionStatus
status = tm.getTransaction(txAttr);
}
else {
if (logger.isDebugEnabled()) {
logger.debug("Skipping transactional joinpoint [" + joinpointIdentification +
"] because no transaction manager has been configured");
}
}
}
//根据指定的属性与status准备一个TransactionInfo
return prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
}
- 设置事务方法标识
- 获取事务状态:事务处理当然是以事务为核心,那么获取事务就是最重要的事情。
- 根据指定的属性与status准备一个
TransactionInfo
设置事务方法标识
这里通过DelegatingTransactionAttribute对TransactionAttribute(RuleBasedTransactionAttribute)进行封装主要由以下几个原因
- 在未指定事务名称时动态地为事务设置一个默认名称(即 joinpointIdentification)。
- 确保每个事务都有一个明确的名称,便于调试、日志记录和事务管理。
- 直接修改
txAttr可能会破坏其原有的状态或导致不可预测的行为,尤其是当txAttr被多个地方共享时。通过封装,可以避免对原始对象的直接修改,同时满足当前需求。
获取TransactionStatus
AbstractPlatformTransactionManager.getTransaction
@Override
public final TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException {
Object transaction = doGetTransaction();
// Cache debug flag to avoid repeated checks.
boolean debugEnabled = logger.isDebugEnabled();
if (definition == null) {
// Use defaults if no transaction definition given.
definition = new DefaultTransactionDefinition();
}
//判断当前线程是否存在事务,判读依据为当前线程记录的连接不为空且连接中(connectionHolder)中的transactionActive属性不为空
if (isExistingTransaction(transaction)) {
// Existing transaction found -> check propagation behavior to find out how to behave.
return handleExistingTransaction(definition, transaction, debugEnabled);
}
// Check definition settings for new transaction.
//事务超时设置验证
if (definition.getTimeout() < TransactionDefinition.TIMEOUT_DEFAULT) {
throw new InvalidTimeoutException("Invalid transaction timeout", definition.getTimeout());
}
// No existing transaction found -> check propagation behavior to find out how to proceed.
//如果当前线程不存在事务,但是propagationBehavior却被声明为PROPAGATION_MANDATORY抛出异常
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) {
throw new IllegalTransactionStateException(
"No existing transaction found for transaction marked with propagation 'mandatory'");
}
else if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED ||
definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW ||
definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
//PROPAGATION_REQUIRED、PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED都需要
//新建事务
//空挂起
SuspendedResourcesHolder suspendedResources = suspend(null);
if (debugEnabled) {
logger.debug("Creating new transaction with name [" + definition.getName() + "]: " + definition);
}
try {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
/*
* 构造transaction,包括设置ConnectionHolder、隔离级别、timout
* 如果是新连接,绑定到当前线程
*/
doBegin(transaction, definition);
//新同步事务的设置,针对于当前线程的设置
prepareSynchronization(status, definition);
return status;
}
catch (RuntimeException ex) {
resume(null, suspendedResources);
throw ex;
}
catch (Error err) {
resume(null, suspendedResources);
throw err;
}
}
else {
// Create "empty" transaction: no actual transaction, but potentially synchronization.
if (definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT && logger.isWarnEnabled()) {
logger.warn("Custom isolation level specified but no actual transaction initiated; " +
"isolation level will effectively be ignored: " + definition);
}
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
return prepareTransactionStatus(definition, null, true, newSynchronization, debugEnabled, null);
}
}
当然,在Spring中每个复杂的功能实现,并不是一次完成的,而是会通过入口函数进行一个框架的搭建,初步构建完整的逻辑,而将实现细节分摊给不同的函数。那么,让我们看看事务的准备工作都包括哪些。
- 获取事务实例
- 判断是否存在事务
- 如果当前线程存在事务,则转向嵌套事务的处理。
- 否则执行下面步骤
- 事务超时设置验证。
- 事务传播行为判断
PROPAGATION_MANDATORY需要抛错,因为这种情况需要线程中存在事务PROPAGATION_REQUIRED、PROPAGATION_REQUIRES_NEW、PROPAGATION_NESTED进入下面步骤- 执行挂起操作,如果事务管理器已激活,那么需要将TransactionSynchronization挂起,另外需要执行TransactionSynchronization的suspend方法
- 获取事务同步模式
- 构建DefaultTransactionStatus。
- dobegin :完善transaction,包括设置ConnectionHolder、隔离级别、timeout,如果是新连接,则绑定到当前线程。
- prepareSynchronization
- 否则进入无事务模式,将当前的TransactionStatus的事务属性设置为null,准备同步后返回
获取事务实例
创建对应的事务实例,这里使用的是DataSourceTransactionManager中的doGetTransaction方法,创建基于JDBC的事务实例。如果当前线程中存在关于dataSource的连接,那么直接使用。这里有一个对保存点的设置,是否开启允许保存点取决于是否设置了允许嵌入式事务。
DataSourceTransactionManager.doGetTransaction
protected Object doGetTransaction() {
DataSourceTransactionObject txObject = new DataSourceTransactionObject();
txObject.setSavepointAllowed(this.isNestedTransactionAllowed());
//如果当前线程已经记录数据库连接则使用原有连接
ConnectionHolder conHolder = (ConnectionHolder)TransactionSynchronizationManager.getResource(this.dataSource);
//false表示非新创建连接
txObject.setConnectionHolder(conHolder, false);
return txObject;
}
- 新建管理事务的DataSourceTransactionObject对象
- 根据事务传播行为判断是否设置保存点
- 设置ConnectionHolder
DataSourceTransactionObject
这个对象封装了connecttion,并提供了一些操作connection的方法,用于支持事务的提交、回滚等操作
DataSourceTransactionManager.DataSourceTransactionObject
private static class DataSourceTransactionObject extends JdbcTransactionObjectSupport {
private boolean newConnectionHolder;
private boolean mustRestoreAutoCommit;
private DataSourceTransactionObject() {
}
public void setConnectionHolder(ConnectionHolder connectionHolder, boolean newConnectionHolder) {
super.setConnectionHolder(connectionHolder);
this.newConnectionHolder = newConnectionHolder;
}
public boolean isNewConnectionHolder() {
return this.newConnectionHolder;
}
public void setMustRestoreAutoCommit(boolean mustRestoreAutoCommit) {
this.mustRestoreAutoCommit = mustRestoreAutoCommit;
}
public boolean isMustRestoreAutoCommit() {
return this.mustRestoreAutoCommit;
}
public void setRollbackOnly() {
this.getConnectionHolder().setRollbackOnly();
}
public boolean isRollbackOnly() {
return this.getConnectionHolder().isRollbackOnly();
}
public void flush() {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
TransactionSynchronizationUtils.triggerFlush();
}
}
}
ConnectionHolder
连接通过事务同步管理器获取,用于获取当前线程绑定的连接
TransactionSynchronizationManager.getResource
public static Object getResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Object value = doGetResource(actualKey);
if (value != null && logger.isTraceEnabled()) {
logger.trace("Retrieved value [" + value + "] for key [" + actualKey + "] bound to thread [" +
Thread.currentThread().getName() + "]");
}
return value;
}
private static Object doGetResource(Object actualKey) {
Map<Object, Object> map = resources.get();
if (map == null) {
return null;
}
Object value = map.get(actualKey);
// Transparently remove ResourceHolder that was marked as void...
if (value instanceof ResourceHolder && ((ResourceHolder) value).isVoid()) {
map.remove(actualKey);
// Remove entire ThreadLocal if empty...
if (map.isEmpty()) {
resources.remove();
}
value = null;
}
return value;
}
当前线程已有事务
Spring中支持多种事务的传播规则,比如PROPAGATION_NESTED、PROPAGATION_REQUIRES_NEW等,这些都是在已经存在事务的基础上进行进一步的处理,那么,对于已经存在的事务,准备操作是如何进行的呢?
我是根据方法执行的逻辑,所以将已有事务的情况放在这里,里面很多逻辑都在无事务的情况解释过了,所以这里只是简单介绍了几种事务传播行为,建议直接跳过这里,看完无事务的情况再回过头来看这里
AbstractPlatformTransactionManager.handleExistingTransaction
private TransactionStatus handleExistingTransaction(
TransactionDefinition definition, Object transaction, boolean debugEnabled)
throws TransactionException {
//PROPAGATION_NEVER传播行为下,方法必须以无事务方式运行,所以需要报错
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NEVER) {
throw new IllegalTransactionStateException(
"Existing transaction found for transaction marked with propagation 'never'");
}
//PROPAGATION_NOT_SUPPORTED传播行为下,不支持事务,所以需要挂起外层事务
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NOT_SUPPORTED) {
if (debugEnabled) {
logger.debug("Suspending current transaction");
}
Object suspendedResources = suspend(transaction);
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
return prepareTransactionStatus(
definition, null, false, newSynchronization, debugEnabled, suspendedResources);
}
//PROPAGATION_REQUIRES_NEW传播行为下总是需要创建新的事务
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW) {
if (debugEnabled) {
logger.debug("Suspending current transaction, creating new transaction with name [" +
definition.getName() + "]");
}
SuspendedResourcesHolder suspendedResources = suspend(transaction);
try {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
doBegin(transaction, definition);
prepareSynchronization(status, definition);
return status;
}
catch (RuntimeException beginEx) {
resumeAfterBeginException(transaction, suspendedResources, beginEx);
throw beginEx;
}
catch (Error beginErr) {
resumeAfterBeginException(transaction, suspendedResources, beginErr);
throw beginErr;
}
}
//PROPAGATION_NESTED传播行为下,需要通过保存点处理嵌入式事务
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
if (!isNestedTransactionAllowed()) {
throw new NestedTransactionNotSupportedException(
"Transaction manager does not allow nested transactions by default - " +
"specify 'nestedTransactionAllowed' property with value 'true'");
}
if (debugEnabled) {
logger.debug("Creating nested transaction with name [" + definition.getName() + "]");
}
if (useSavepointForNestedTransaction()) {
// Create savepoint within existing Spring-managed transaction,
// through the SavepointManager API implemented by TransactionStatus.
// Usually uses JDBC 3.0 savepoints. Never activates Spring synchronization.
//如果有可以使用保存点的方式控制事务回滚,那么在嵌入式事务的建立初始建立保存点
DefaultTransactionStatus status =
prepareTransactionStatus(definition, transaction, false, false, debugEnabled, null);
status.createAndHoldSavepoint();
return status;
}
else {
// Nested transaction through nested begin and commit/rollback calls.
// Usually only for JTA: Spring synchronization might get activated here
// in case of a pre-existing JTA transaction.
//有些情况是不能使用保存点操作,比如JTA,那么建立新事务
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, null);
doBegin(transaction, definition);
prepareSynchronization(status, definition);
return status;
}
}
// Assumably PROPAGATION_SUPPORTS or PROPAGATION_REQUIRED.
if (debugEnabled) {
logger.debug("Participating in existing transaction");
}
if (isValidateExistingTransaction()) {
if (definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT) {
Integer currentIsolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
if (currentIsolationLevel == null || currentIsolationLevel != definition.getIsolationLevel()) {
Constants isoConstants = DefaultTransactionDefinition.constants;
throw new IllegalTransactionStateException("Participating transaction with definition [" +
definition + "] specifies isolation level which is incompatible with existing transaction: " +
(currentIsolationLevel != null ?
isoConstants.toCode(currentIsolationLevel, DefaultTransactionDefinition.PREFIX_ISOLATION) :
"(unknown)"));
}
}
if (!definition.isReadOnly()) {
if (TransactionSynchronizationManager.isCurrentTransactionReadOnly()) {
throw new IllegalTransactionStateException("Participating transaction with definition [" +
definition + "] is not marked as read-only but existing transaction is");
}
}
}
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
}
这里主要是对于几种传播行为做了不同的处理:
- **PROPAGATION_NEVER:**方法必须以无事务方式运行,所以需要报错
- **PROPAGATION_NOT_SUPPORTED:**不支持事务,所以需要挂起外层事务
- **PROPAGATION_REQUIRES_NEW:**总是需要创建新的事务
- **PROPAGATION_NESTED:**需要通过保存点处理嵌入式事务
- 若支持保存点,则建立保存点
- 否则使用JTA管理
- 其他情况复用现在的事务(注意会设置
isNewTransaction为false)
当前线程无事务
事务超时设置验证
if (definition.getTimeout() < TransactionDefinition.TIMEOUT_DEFAULT) {
throw new InvalidTimeoutException("Invalid transaction timeout", definition.getTimeout());
}
事务超时属性的验证,设置的值不能小于-1
MANDATORY传播行为
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) {
throw new IllegalTransactionStateException(
"No existing transaction found for transaction marked with propagation 'mandatory'");
}
PROPAGATION_MANDATORY必须运行在当前线程已有事务的情况
需要事务的三种传播行为
执行挂起操作
每次执行doBegin方法开启事务前,必定会执行suspend方法
SuspendedResourcesHolder suspendedResources = suspend(null);
虽然外层无事务,但是仍然要执行挂起操作,主要有以下两点:
-
挂起
TransactionSynchronizationManager注册的TransactionSynchronization-
TransactionSynchronizationManager是用于管理事务同步的一个核心工具类。它负责注册和触发TransactionSynchronization回调,从而在事务的不同阶段(如事务开始、提交前、提交后、回滚等)执行相应的回调逻辑。 -
TransactionSynchronization的生命周期与当前事务绑定,所以当有新事务需要开启时,需要将旧的TransactionSynchronization挂起如果你细心的话,肯定会发现每次执行DataSourceTransactionManager.doBegin方法开启事务前,一定会执行
suspend方法
-
-
执行
TransactionSynchronization的suspend方法,刚才说spring会在事务的不同阶段执行相应的回调,这里就是在新事务需要开启时执行旧的TransactionSynchronization的挂起方法
AbstractPlatformTransactionManager.suspend
protected final SuspendedResourcesHolder suspend(Object transaction) throws TransactionException {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
//挂起事务同步器,并触发事务同步器的suspend方法回调
List<TransactionSynchronization> suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
//有事务的情况需要将事务连接挂起,并把当前事务对象的ConnectionHolder设为null
suspendedResources = doSuspend(transaction);
}
//挂起一些其他资源
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
return new SuspendedResourcesHolder(
suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
}
catch (RuntimeException ex) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
catch (Error err) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw err;
}
}
else if (transaction != null) {
// Transaction active but no synchronization active.
Object suspendedResources = doSuspend(transaction);
return new SuspendedResourcesHolder(suspendedResources);
}
else {
// Neither transaction nor synchronization active.
return null;
}
}
doSuspendSynchronization
AbstractPlatformTransactionManager.doSuspendSynchronization
private List<TransactionSynchronization> doSuspendSynchronization() {
List<TransactionSynchronization> suspendedSynchronizations =
TransactionSynchronizationManager.getSynchronizations();
for (TransactionSynchronization synchronization : suspendedSynchronizations) {
synchronization.suspend();
}
TransactionSynchronizationManager.clearSynchronization();
return suspendedSynchronizations;
}
doSuspend
DataSourceTransactionManager.doSuspend
protected Object doSuspend(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
txObject.setConnectionHolder(null);
return TransactionSynchronizationManager.unbindResource(this.dataSource);
}
判断同步模式
Spring 提供了事务同步(TransactionSynchronization)机制,用于将事务与资源(如数据访问操作、缓存更新等)绑定在一起。
事务管理器的同步模式包括:
public abstract class AbstractPlatformTransactionManager implements PlatformTransactionManager, Serializable {
/**
* Always activate transaction synchronization, even for "empty" transactions
* that result from PROPAGATION_SUPPORTS with no existing backend transaction.
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_SUPPORTS
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_NOT_SUPPORTED
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_NEVER
*/
public static final int SYNCHRONIZATION_ALWAYS = 0;
/**
* Activate transaction synchronization only for actual transactions,
* that is, not for empty ones that result from PROPAGATION_SUPPORTS with
* no existing backend transaction.
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_REQUIRED
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_MANDATORY
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_REQUIRES_NEW
*/
public static final int SYNCHRONIZATION_ON_ACTUAL_TRANSACTION = 1;
/**
* Never active transaction synchronization, not even for actual transactions.
*/
public static final int SYNCHRONIZATION_NEVER = 2;
//默认是`SYNCHRONIZATION_ALWAYS`
private int transactionSynchronization = SYNCHRONIZATION_ALWAYS;
}
SYNCHRONIZATION_ALWAYS:始终启用事务同步。SYNCHRONIZATION_ON_ACTUAL_TRANSACTION:仅在实际存在事务时启用同步。SYNCHRONIZATION_NEVER:完全禁用事务同步。
newSynchronization
用于决定当前方法是不是新的事务同步管理器,即是不是首次创建事务同步管理器的同步的方法。可能这么说很拗口,可以查看下面一段代码:
AbstractPlatformTransactionManager.newTransactionStatus
protected DefaultTransactionStatus newTransactionStatus(
TransactionDefinition definition, Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, Object suspendedResources) {
boolean actualNewSynchronization = newSynchronization &&
!TransactionSynchronizationManager.isSynchronizationActive();
return new DefaultTransactionStatus(
transaction, newTransaction, actualNewSynchronization,
definition.isReadOnly(), debug, suspendedResources);
}
这是初始化TransactionStatus的一段代码:在里面会判断事务同步管理器是否已经激活,如果已经激活,那么newSynchronization会是false。因此,==只有当前事务管理器的同步模式允许,以及当前线程的事务管理器没有激活的情况,这个值才是true。==至于具体的影响,我们下面进行分析
影响事务同步管理器的回调机制的激活
AbstractPlatformTransactionManager.getTransaction
public final TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException {
//代码片段
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
//...
prepareSynchronization(status, definition);
}
AbstractPlatformTransactionManager.prepareSynchronization
protected void prepareSynchronization(DefaultTransactionStatus status, TransactionDefinition definition) {
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.setActualTransactionActive(status.hasTransaction());
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(
definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT ?
definition.getIsolationLevel() : null);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(definition.isReadOnly());
TransactionSynchronizationManager.setCurrentTransactionName(definition.getName());
TransactionSynchronizationManager.initSynchronization();
}
}
这行代码很重要,用于初始化当前线程存放执行回调机制的Synchronization机制的容器,如果同步模式设置为never将不会初始化事务管理同步器的回调器的存储容器
TransactionSynchronizationManager.initSynchronization();
TransactionSynchronizationManager.initSynchronization
public static void initSynchronization() throws IllegalStateException {
if (isSynchronizationActive()) {
throw new IllegalStateException("Cannot activate transaction synchronization - already active");
}
logger.trace("Initializing transaction synchronization");
synchronizations.set(new LinkedHashSet<TransactionSynchronization>());
}
只有事务同步管理器已经激活的情况,才可以向里面注册事务同步回调器(TransactionSynchronization)
TransactionSynchronizationManager.initSynchronization
public static void registerSynchronization(TransactionSynchronization synchronization)
throws IllegalStateException {
Assert.notNull(synchronization, "TransactionSynchronization must not be null");
if (!isSynchronizationActive()) {
throw new IllegalStateException("Transaction synchronization is not active");
}
synchronizations.get().add(synchronization);
}
影响回调机制的执行
在执行回调时triggerBeforeCommit和triggerBeforeCompletion,都会判断newSynchronization的值:
AbstractPlatformTransactionManager.triggerBeforeCommit
protected final void triggerBeforeCommit(DefaultTransactionStatus status) {
if (status.isNewSynchronization()) {
if (status.isDebug()) {
logger.trace("Triggering beforeCommit synchronization");
}
TransactionSynchronizationUtils.triggerBeforeCommit(status.isReadOnly());
}
}
AbstractPlatformTransactionManager.triggerBeforeCompletion
protected final void triggerBeforeCompletion(DefaultTransactionStatus status) {
if (status.isNewSynchronization()) {
if (status.isDebug()) {
logger.trace("Triggering beforeCompletion synchronization");
}
TransactionSynchronizationUtils.triggerBeforeCompletion();
}
}
也就是说在初次创建此事务同步管理器的回调功能的方法才会应用这两个回调,对于嵌套事务,只有外层事务才会应用这两个回调
影响事务同步管理器的清理
在commit和rollback最后都会执行清理工作:
AbstractPlatformTransactionManager.cleanupAfterCompletion
private void cleanupAfterCompletion(DefaultTransactionStatus status) {
status.setCompleted();
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.clear();
}
if (status.isNewTransaction()) {
doCleanupAfterCompletion(status.getTransaction());
}
if (status.getSuspendedResources() != null) {
if (status.isDebug()) {
logger.debug("Resuming suspended transaction after completion of inner transaction");
}
resume(status.getTransaction(), (SuspendedResourcesHolder) status.getSuspendedResources());
}
}
只有isNewSynchronization为true时才会对事务同步管理器进行清理
不影响事务连接的绑定与挂起
这里要特别注意,事务管理器的同步模式设置什么,不影响事务连接的绑定到事务同步管理器的ThreadLocal变量和将事务挂起的功能
在 Spring 的 DataSourceTransactionManager 中,即使事务同步模式设置为 SYNCHRONIZATION_NEVER,当实际事务开启时(例如传播行为为 REQUIRED、REQUIRES_NEW),依然会为当前线程绑定连接。这是因为事务的物理执行(如开启连接、设置隔离级别、提交/回滚)需要独立的连接资源,而 事务同步机制(SYNCHRONIZATION_NEVER)仅控制是否启用同步回调(如资源释放、事务事件触发),并不影响事务本身的连接绑定逻辑。
在开启事务的doBegin方法中:
DataSourceTransactionManager.doBegin
protected void doBegin(Object transaction, TransactionDefinition definition) {
//代码片段
if (!txObject.hasConnectionHolder() || txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
Connection newCon = this.dataSource.getConnection();
if (this.logger.isDebugEnabled()) {
this.logger.debug("Acquired Connection [" + newCon + "] for JDBC transaction");
}
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
//....
if (txObject.isNewConnectionHolder()) {
TransactionSynchronizationManager.bindResource(this.getDataSource(), txObject.getConnectionHolder());
}
}
可见bindResource方法与isNewSynchronization并无联系
再看看挂起方法:
AbstractPlatformTransactionManager.suspend
protected final SuspendedResourcesHolder suspend(Object transaction) throws TransactionException {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
List<TransactionSynchronization> suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
suspendedResources = doSuspend(transaction);
}
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
return new SuspendedResourcesHolder(
suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
}
catch (RuntimeException ex) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
catch (Error err) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw err;
}
}
else if (transaction != null) {
// Transaction active but no synchronization active.
Object suspendedResources = doSuspend(transaction);
return new SuspendedResourcesHolder(suspendedResources);
}
else {
// Neither transaction nor synchronization active.
return null;
}
}
可见即使isSynchronizationActive为false,也就是没有激活事务管理器的同步功能的时候,也会执行事务的挂起
总结
事务的核心操作(如 setAutoCommit(false)、commit()、rollback())必须基于一个独立的物理连接。连接的绑定是事务执行的物理基础,而同步机制是锦上添花的管理层逻辑(如触发回调)。
newTransactionStatus
这里不是直接调用DefaultTransactionStatus的构造方法,而是需要获取 actualNewSynchronization
AbstractPlatformTransactionManager.newTransactionStatus
protected DefaultTransactionStatus newTransactionStatus(
TransactionDefinition definition, Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, Object suspendedResources) {
boolean actualNewSynchronization = newSynchronization &&
!TransactionSynchronizationManager.isSynchronizationActive();
return new DefaultTransactionStatus(
transaction, newTransaction, actualNewSynchronization,
definition.isReadOnly(), debug, suspendedResources);
}
这里要获取actualNewSynchronization,即使外部的事务管理器获取的newSynchronization是true,还要判断当前事务同步管理器是否已经激活,在已经激活的情况下,actualNewSynchronization为false
在事务方法异常或正常返回后调用commit或rollback时,会根据当前这个状态判断是否需要清除事务管理同步器的回调。因此,如果已经被激活,那么此状态应该为false,防止在commit或rollback时被清理。
TransactionStatus
TransactionStatus 是 Spring 框架中用于表示事务状态的一个接口。
DefaultTransactionStatus通过继承AbstractTransactionStatus实现了TransactionStatus 并扩展了一些属性,比如transaction和suspendedResources,这些属性可以使其作为事务上下文的载体,用于事务提交、回滚、挂起与恢复等等多种功能
构造方法
public DefaultTransactionStatus(
Object transaction, boolean newTransaction, boolean newSynchronization,
boolean readOnly, boolean debug, Object suspendedResources) {
this.transaction = transaction;
this.newTransaction = newTransaction;
this.newSynchronization = newSynchronization;
this.readOnly = readOnly;
this.debug = debug;
this.suspendedResources = suspendedResources;
}
部分接口
doBegin(开启事务)
包括设置ConnectionHolder、隔离级别、timeout,如果是新连接,则绑定到当前线程。
DataSourceTransactionManager.doBegin
protected void doBegin(Object transaction, TransactionDefinition definition) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject)transaction;
Connection con = null;
try {
//为当前事务对象设置连接(这里两个条件,99%的情况下都会满足,因为新事务通常需要新的连接,但根据deepseek的回答,似乎是在PROPAGATION_NESTED的情况下,会复用外层连接,使用保存点来进行回滚,我对这点存疑,如果有知道情况的大佬麻烦告知一下)
if (!txObject.hasConnectionHolder() || txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
Connection newCon = this.dataSource.getConnection();
if (this.logger.isDebugEnabled()) {
this.logger.debug("Acquired Connection [" + newCon + "] for JDBC transaction");
}
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
txObject.getConnectionHolder().setSynchronizedWithTransaction(true);
//获取数据库连接connection
con = txObject.getConnectionHolder().getConnection();
//设置隔离级别
Integer previousIsolationLevel = DataSourceUtils.prepareConnectionForTransaction(con, definition);
txObject.setPreviousIsolationLevel(previousIsolationLevel);
//更改自动提交设置,由Spring控制提交
if (con.getAutoCommit()) {
txObject.setMustRestoreAutoCommit(true);
if (this.logger.isDebugEnabled()) {
this.logger.debug("Switching JDBC Connection [" + con + "] to manual commit");
}
con.setAutoCommit(false);
}
this.prepareTransactionalConnection(con, definition);
//设置判断当前线程是否存在事务的依据
txObject.getConnectionHolder().setTransactionActive(true);
//设置超时时间
int timeout = this.determineTimeout(definition);
if (timeout != -1) {
txObject.getConnectionHolder().setTimeoutInSeconds(timeout);
}
if (txObject.isNewConnectionHolder()) {
//将当前获取到的连接绑定到当前线程
TransactionSynchronizationManager.bindResource(this.getDataSource(), txObject.getConnectionHolder());
}
} catch (Throwable var7) {
if (txObject.isNewConnectionHolder()) {
DataSourceUtils.releaseConnection(con, this.dataSource);
txObject.setConnectionHolder((ConnectionHolder)null, false);
}
throw new CannotCreateTransactionException("Could not open JDBC Connection for transaction", var7);
}
}
被使用在哪些地方
doBegin方法用于需要开启事务的情况,目前有三个地方用到:
外层不存在事务:
TransactionDefinition.PROPAGATION_REQUIRED、TransactionDefinition.PROPAGATION_REQUIRES_NEW、TransactionDefinition.PROPAGATION_NESTED
外层存在事务:
PROPAGATION_REQUIRES_NEW、TransactionDefinition.PROPAGATION_NESTED
整体流程
doBegin方法整体流程:
-
设置ConnectionHolder:考虑到事务传播行为的影响
-
第一个判断条件适用于大多数条件,一般情况下,外层要么没事务,要么有事务但是事务会被挂起,这两种情况的事务对象的
ConnectionHolder会被设置为null,所以这里的ConnectionHolder都为空 -
第二个条件是有一种特殊情况,就是外层方法以无事务的方式运行,但是已经被spring的同步管理器同步过,典型的例子就是
PROPAGATION_NOT_SUPPORTED这种传播行为-
在获取事务时,
PROPAGATION_NOT_SUPPORTED传播行为会以无事务的方式运行,且会激活事务管理器的同步(prepareSynchronization方法) -
虽然此时不会将我们的ConnectionHolder绑定到线程,但是我们当我们在通过spring的工具类比如
Jdbctemplate来简化JDBC操作时,其内部获取连接通常会使用DataSourceUtils.getConnection()方法 -
这个方法在事务管理器已激活的情况下会将连接绑定到线程以便于可以在以无事务的方式频繁运行时复用连接,避免资源的浪费。
-
同时因为事务管理器已激活,又因为TransactionSynchronization的生命周期与事务绑定,每次开启事务时都会将旧的TransactionSynchronization资源挂起,并执行
TransactionSynchronization的suspend回调方法,所以每次需要开启事务时依然会执行挂起操作,这样的话DataSourceUtils可以利用ConnectionSynchronization,会将ConnectionHolder的连接释放,并解除对当前线程的绑定,所以后续的TransactionSynchronizationManager.bindResource不会失败。SuspendedResourcesHolder suspendedResources = suspend(null);
-
-
如果有连接且已被事务同步管理器管理。
isSynchronizedWithTransaction的意义:表示连接已被事务同步管理器管理(无论是否有实际事务)- 即使外层没有事务,若连接被标记为
synchronizedWithTransaction = true,内层事务必须创建新连接以 避免资源冲突 和 保证事务隔离性。- 资源竞争:外层可能在内层事务未完成时释放连接或者外层连接以失效。
- 事务隔离性破坏:复用外层连接可能导致内层事务的提交/回滚影响外层操作(即使外层没有事务,连接可能处于非预期状态)。
- Spring 通过统一的事务同步机制,确保连接生命周期与事务边界一致。即使某些场景下没有实际事务,同步状态的激活也能保证资源的正确管理。
- 即使外层没有事务,若连接被标记为
-
-
设置
ConnectionHolder的事务同步并获取数据库连接connection -
**设置隔离级别以及只读标记:**设置隔离级别的
prepareConnectionForTransaction函数用于负责对底层数据库连接的设置,当然,只是包含只读标识和隔离级别的设置。由于强大的日志及异常处理,显得函数代码量比较大,但是单从业务角度去看,关键代码其实是不多的。 -
修改自动提交,由spring管理
-
设置
ConnectionHolder激活事务(setTransactionActive(true)) -
设置超时时间
-
将当前获取到的连接绑定到当前线程(TransactionSynchronizationManager.bindResource)
public static void bindResource(Object key, Object value) throws IllegalStateException { Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key); Assert.notNull(value, "Value must not be null"); Map<Object, Object> map = resources.get(); // set ThreadLocal Map if none found if (map == null) { map = new HashMap<Object, Object>(); resources.set(map); } Object oldValue = map.put(actualKey, value); // Transparently suppress a ResourceHolder that was marked as void... if (oldValue instanceof ResourceHolder && ((ResourceHolder) oldValue).isVoid()) { oldValue = null; } if (oldValue != null) { //可能由于事务未正常挂起,需要报错。 throw new IllegalStateException("Already value [" + oldValue + "] for key [" + actualKey + "] bound to thread [" + Thread.currentThread().getName() + "]"); } if (logger.isTraceEnabled()) { logger.trace("Bound value [" + value + "] for key [" + actualKey + "] to thread [" + Thread.currentThread().getName() + "]"); } }
prepareSynchronization
这里用于准备事务管理器的同步,以便于处理事务管理器的回调机制
AbstractPlatformTransactionManager.prepareSynchronization
protected void prepareSynchronization(DefaultTransactionStatus status, TransactionDefinition definition) {
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.setActualTransactionActive(status.hasTransaction());
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(
definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT ?
definition.getIsolationLevel() : null);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(definition.isReadOnly());
TransactionSynchronizationManager.setCurrentTransactionName(definition.getName());
TransactionSynchronizationManager.initSynchronization();
}
}
当允许事务管理器同步时(根据事务管理器同步模式决定),会进行一些初始化操作,这里主要时初始化存放事务管理器的回调的容器
TransactionSynchronizationManager.initSynchronization
public static void initSynchronization() throws IllegalStateException {
//当线程中已存在事务时,会进行挂起操作将synchronizations的资源挂起,如果正常挂起,这里将不会触发报错
if (isSynchronizationActive()) {
throw new IllegalStateException("Cannot activate transaction synchronization - already active");
}
logger.trace("Initializing transaction synchronization");
synchronizations.set(new LinkedHashSet<TransactionSynchronization>());
}
TransactionSynchronization
public interface TransactionSynchronization extends Flushable {
/** Completion status in case of proper commit */
int STATUS_COMMITTED = 0;
/** Completion status in case of proper rollback */
int STATUS_ROLLED_BACK = 1;
/** Completion status in case of heuristic mixed completion or system errors */
int STATUS_UNKNOWN = 2;
void suspend();
void resume();
@Override
void flush();
void beforeCommit(boolean readOnly);
void beforeCompletion();
void afterCommit();
void afterCompletion(int status);
}
该接口定义了一些方法,spring会在提交或者回滚的不同时期执行不同的回调,可以参考上面提交事务和异常处理的部分
不需要事务的传播行为
判断同步管理器同步模式
事务同步管理器同步模式在上面已经解析过了,这里不再赘述
创建事务状态
TransactionStatus 是 Spring 框架中用于表示事务状态的一个接口。
DefaultTransactionStatus通过继承AbstractTransactionStatus实现了TransactionStatus 并扩展了一些属性,比如transaction和suspendedResources,这些属性可以使其作为事务上下文的载体,用于事务提交、回滚、挂起与恢复等等多种功能
- 它持有事务对象
transaction,用于事务的提交和回滚 - 它持有
suspendedResources,用于资源(事务、事务同步器)的挂起与恢复
另外它==提供了一系列方法来查询和控制事务的执行状态。==比如提交时需要通过TransactionStatus接口判断
- 事务是否已经提交
- 事务是否已经回滚
所以这里的功能就是创建一个事务上下文载体,且事务被设置成null。即使在无事务的情况,也需要根据同步模式初始化事务同步器的配置以便于spring通过事务同步器的回调机制更好的管理连接
注意spring判断是否进行提交或回滚(区分于数据库的提交和回滚)的操作就是判断TransactionInfo有没有TransactionStatus (事务上下文环境),这种情况下
- 可能需要执行真正的提交或回滚
- 另外也需要spring在方法结束时执行清理和必要的回调
详细解析可以移步至下面的prepareTransactionInfo方法的解析
AbstractPlatformTransactionManager.prepareTransactionStatus
protected final DefaultTransactionStatus prepareTransactionStatus(
TransactionDefinition definition, Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, Object suspendedResources) {
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, newTransaction, newSynchronization, debug, suspendedResources);
prepareSynchronization(status, definition);
return status;
}
准备同步
AbstractPlatformTransactionManager.prepareSynchronization
protected void prepareSynchronization(DefaultTransactionStatus status, TransactionDefinition definition) {
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.setActualTransactionActive(status.hasTransaction());
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(
definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT ?
definition.getIsolationLevel() : null);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(definition.isReadOnly());
TransactionSynchronizationManager.setCurrentTransactionName(definition.getName());
TransactionSynchronizationManager.initSynchronization();
}
}
根据isNewSynchronization判断是否为当前线程初始化事务管理器的同步状态
这种情况下,即使当前线程没有真正的开启事务,也需要初始化同步状态
prepareTransactionInfo
准备TransactionInfo,通过TransactionInfo属性保存了TransactionManager、TransactionAttribute、TransactionStatus等信息,用于之后的回滚和提交
TransactionAspectSupport.prepareTransactionInfo
protected TransactionInfo prepareTransactionInfo(PlatformTransactionManager tm,
TransactionAttribute txAttr, String joinpointIdentification, TransactionStatus status) {
TransactionInfo txInfo = new TransactionInfo(tm, txAttr, joinpointIdentification);
if (txAttr != null) {
// We need a transaction for this method...
if (logger.isTraceEnabled()) {
logger.trace("Getting transaction for [" + txInfo.getJoinpointIdentification() + "]");
}
// The transaction manager will flag an error if an incompatible tx already exists.
txInfo.newTransactionStatus(status);
}
else {
// The TransactionInfo.hasTransaction() method will return false. We created it only
// to preserve the integrity of the ThreadLocal stack maintained in this class.
if (logger.isTraceEnabled())
logger.trace("Don't need to create transaction for [" + joinpointIdentification +
"]: This method isn't transactional.");
}
// We always bind the TransactionInfo to the thread, even if we didn't create
// a new transaction here. This guarantees that the TransactionInfo stack
// will be managed correctly even if no transaction was created by this aspect.
txInfo.bindToThread();
return txInfo;
}
hasTransaction
这里有必要特意说明下它的hasTransaction方法,这个方法用于在AbstractPlatformTransactionManager判断是否需要进行提交或者回滚操作,从字面意义上来看,这里似乎是检查有无事务,但是上面判断的逻辑是有无transactionStatus,而不是判断transactionStatus的transaction属性(这种情况才有真正的事务)
这是因为首先transactionStatus不仅存储了transaction(实际的事务对象)还记录了suspendedResources(挂起的资源)。此时,TransactionStatus 存在的意义是 维护事务上下文的状态,而不仅仅关联事务。
所以TransactionInfo 的 hasTransaction() 方法的设计意图是判断 当前是否处于事务上下文中,而非“是否存在物理事务”。在这种设计下
-
提交和回滚时会根据特定条件来判断是否要真正进行数据库的提交或回滚,而不需要真正有事务也可以执行
commit或rollbackDefaultTransactionStatus.isNewTransaction():标记是否为新事务(需提交/回滚)。DefaultTransactionStatus.hasTransaction():内部方法,检查transaction属性是否为null。
-
其次不管有无事务,都需要进行以下操作,而这些操作都是在执行
processRollback或者processCommit里触发的- 我们的方法执行时可能挂起了一些资源,在执行完事务方法后需要恢复(NOT_SUPPORTS这种传播行为会挂起当前事务以无事务运行)
- 事务的同步回调(
TransactionSynchronization)需要执行
综上所述hasTransaction用于判断当前是否处于事务上下文中,如果存在,那么需要根据条件判断是否需要提交或回滚事务,并且不管如何都需要执行恢复挂起的事务或执行一些事务管理器的回调。
Spring事务遇到的一些问题
synchronized锁与事务
当synchronized和Transactional注解一起使用时,会出现一些微妙的错误,先看下错误示例:
@Transactional
public synchronized void takePoduct(){
Product product = productDao.findOne(2);
product.setCount(product.getCount()+1);
productDao.updateProduct(product);
}
这在实际中是有可能遇到的,当我们想修改一个全局性的变量时,比如库存,而又希望它保持事务。
首先上述程序肯定时存在问题的,我们来分析一下:
spring的事务是通过AOP实现的,spring会重写目标方法,在执行原方法前会为我们加上开启事务和提交事务的操作。
这里很关键的一个点是,我们先开启了事务,然后再执行目标方法,也就是说开始处理synchronized的逻辑
现在我们来梳理一下出错的流程。
- 两个线程同时访问takePoduct方法,因为方法已被代理,会先为两个线程分别开启两个事务
- 其中一个方法获取锁,拿到库存修改了数据
- 此时释放锁(因为目标方法执行完毕),spring再去提交事务
- 因为释放锁和提交事务不具备原子性,所以在这中间,第二个线程可以在第一个线程事务提交前获取锁并查询库存
- 由于事务的隔离性,一般数据库的默认隔离级别都是可重复读或者读已提交,对于第一个线程还未提交的数据将不会对第二个线程可见,所以第二个线程获取到了修改前的数据
解决办法
通过上面的分析,我们肯定是需要先获取锁,再开启事务
private synchronized void testTransactionalWithSynchronized() {
productService.takePoduct();
}
@Transactional
public synchronized void takePoduct(){
Product product = productDao.findOne(2);
product.setCount(product.getCount()+1);
productDao.updateProduct(product);
}
高并发优化事务性能
在高并发场景下,优化 Spring 事务性能是非常重要的。以下是 三种具体策略,分别从缩短事务时长、设置只读事务和合理选择隔离级别三个方面进行详细说明
缩短事务时长
-
尽量将事务限制在最小的代码范围内,避免将不必要的操作包含在事务中。
-
例如,将数据查询、日志记录等非事务性操作移出事务方法。
@Service public class OrderService { @Autowired private OrderRepository orderRepository; public void processOrder(Order order) { // 非事务性操作(如日志记录) logOrderDetails(order); // 事务性操作(如订单保存) saveOrder(order); } @Transactional private void saveOrder(Order order) { orderRepository.save(order); } private void logOrderDetails(Order order) { System.out.println("Logging order details: " + order); } } -
对于一些非关键的操作(如发送通知、生成报表等),可以通过异步任务处理,避免阻塞事务。
设置只读事务
-
如果某个事务仅涉及查询操作而不涉及修改操作,可以在
@Transactional注解中设置readOnly = true。 -
只读事务可以优化数据库的锁机制,减少资源争用,提高查询性能。
某些数据库(如 SQL Server)在默认隔离级别下,读操作会加共享锁(Shared Locks),而显式声明只读事务可能允许更轻量级的锁或无锁机制(如快照读)。
合理选择隔离级别
- 默认情况下,Spring 的事务隔离级别与数据库的默认隔离级别一致,大多数数据使用的隔离级别是读已提交和可重复读。如果业务场景允许,可以进一步降低隔离级别以提高性能。
- 例如,使用
ISOLATION_READ_UNCOMMITTED允许脏读,但可以显著减少锁开销。- 锁竞争:隔离级别越高(如串行化),锁粒度越粗(如范围锁),锁竞争越激烈,吞吐量下降。
- MVCC 开销:RC 和 RR 通过多版本并发控制(MVCC)实现隔离,需维护多个版本数据,增加内存和存储开销。
| 隔离级别 | 特点 | 适用场景 |
|---|---|---|
ISOLATION_READ_UNCOMMITTED | 允许脏读,性能最高。 | 数据一致性要求较低的场景,如统计分析、监控数据等。 |
ISOLATION_READ_COMMITTED | 不允许脏读,但可能有不可重复读。 | 大多数业务场景,默认隔离级别。 |
ISOLATION_REPEATABLE_READ | 不允许脏读和不可重复读,但可能有幻读。 | 对数据一致性要求较高的场景,如财务系统。 |
ISOLATION_SERIALIZABLE | 完全隔离,性能最低。 | 对数据一致性要求极高的场景,如银行转账、证券交易等。 |
三种优化方式总结
| 策略 | 具体措施 | 效果 |
|---|---|---|
| 缩短事务时长 | 减少事务边界范围、批量操作代替单条操作、异步处理非关键操作。 | 减少事务持有锁的时间,降低资源争用,提升并发性能。 |
| 设置只读事务 | 标记只读事务 (readOnly = true),利用数据库优化只读查询。 | 减少锁开销,提高查询性能,特别适用于高并发读多写少的场景。 |
| 合理选择隔离级别 | 根据业务需求选择合适的隔离级别,降低隔离级别以减少锁冲突。 | 在保证数据一致性的前提下,通过调整隔离级别提升性能。 |
通过以上三种策略的综合应用,可以有效优化 Spring 事务在高并发场景下的性能,同时确保系统的稳定性和可靠性。
日志记录
解析日志记录为什么要推荐使用 REQUIRED_NEW
REQUIRED_NEW用于推荐在日志记录中使用,主要有以下原因:
- 日志记录通常是一个独立的操作,不应依赖于业务逻辑所在的事务状态。
- 如果日志记录与业务逻辑共享同一个事务,可能会因为业务逻辑的失败导致日志记录也被回滚,从而丢失重要的日志信息。
- 从另一个方面来说,日志记录失败可能会导致整个事务回滚,从而影响业务逻辑的正常执行。这种情况下,用户的体验会受到严重影响,系统也可能出现不一致的状态。
- 使用
REQUIRED_NEW可以确保日志记录操作在一个独立的事务中完成。
注意事项
尽管 REQUIRED_NEW 在日志记录中有诸多优势,但也需要注意以下几点:
- 性能开销:每次创建新的事务会带来一定的性能开销,可能导致数据库连接池资源紧张,需合理配置数据库连接池,因此需要权衡日志记录的频率和重要性。
- 适用场景:
REQUIRED_NEW更适合用于关键日志记录(如交易日志、错误日志等),而不适用于频繁的日志记录操作。- 当日志比较频繁时可以将日志记录利用事务管理同步器的回调机制,如afterCommit、和afterCompletion等等。
spring事务重要的组件
通过上面的分析,发现spring事务有好几个组件,为了方便统一查阅,这里进行统一记录一下
AnnotationDrivenBeanDefinitionParser
首先从自定义标签,整个spring事务功能的开启开始,spring解析到<tx:annotation-driven />标签就会使用AnnotationDrivenBeanDefinitionParser注册两个组件
- InfrastructureAdvisorAutoProxyCreator
- BeanFactoryTransactionAttributeSourceAdvisor
- transactionAttributeSource(pointCut)
- TransactionInterceptor(advice)
TransactionAttribute
通过SpringTransactionAnnotationParser.parseTransactionAnnotation解析方法或类上的@Transactional注解得到的用户的事务配置信息,它一般是一个RuleBasedTransactionAttribute,在DefaultTransactionAttribute基础上扩展了异常回滚的规则。记录了一些事务相关的配置
这里记录下构造方法
DefaultTransactionDefinition
public DefaultTransactionDefinition(TransactionDefinition other) {
this.propagationBehavior = other.getPropagationBehavior();
this.isolationLevel = other.getIsolationLevel();
this.timeout = other.getTimeout();
this.readOnly = other.isReadOnly();
this.name = other.getName();
}
PlatformTransactionManager
在开启事务功能时需要提供一个事务管理器,主要是用于定义如何获取事务以及如何处理提交和回滚
public interface PlatformTransactionManager {
TransactionStatus getTransaction(TransactionDefinition var1) throws TransactionException;
void commit(TransactionStatus var1) throws TransactionException;
void rollback(TransactionStatus var1) throws TransactionException;
}
DataSourceTransactionManager
DataSourceTransactionManager实现了几个重要的方法
TransactionSynchronizationManager
TransactionSynchronizationManager事务同步管理器是存储事务连接和执行事务回调的核心组件,它有两个重要的功能,其一是存储事务连接,其二是其回调机制
存储事务连接
在开启事务时,会将连接绑定到自己的ThradLocal变量中:
DataSourceTransactionManager.doBegin
protected void doBegin(Object transaction, TransactionDefinition definition) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
Connection con = null;
try {
if (!txObject.hasConnectionHolder() ||
txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
Connection newCon = this.dataSource.getConnection();
if (logger.isDebugEnabled()) {
logger.debug("Acquired Connection [" + newCon + "] for JDBC transaction");
}
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
//省略部分代码。。。
// Bind the connection holder to the thread.
if (txObject.isNewConnectionHolder()) {
TransactionSynchronizationManager.bindResource(getDataSource(), txObject.getConnectionHolder());
}
}
catch (Throwable ex) {
if (txObject.isNewConnectionHolder()) {
DataSourceUtils.releaseConnection(con, this.dataSource);
txObject.setConnectionHolder(null, false);
}
throw new CannotCreateTransactionException("Could not open JDBC Connection for transaction", ex);
}
}
再看具体实现:
TransactionSynchronizationManager.bindResource
public static void bindResource(Object key, Object value) throws IllegalStateException {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Assert.notNull(value, "Value must not be null");
Map<Object, Object> map = resources.get();
// set ThreadLocal Map if none found
if (map == null) {
map = new HashMap<Object, Object>();
resources.set(map);
}
Object oldValue = map.put(actualKey, value);
// Transparently suppress a ResourceHolder that was marked as void...
if (oldValue instanceof ResourceHolder && ((ResourceHolder) oldValue).isVoid()) {
oldValue = null;
}
if (oldValue != null) {
throw new IllegalStateException("Already value [" + oldValue + "] for key [" +
actualKey + "] bound to thread [" + Thread.currentThread().getName() + "]");
}
if (logger.isTraceEnabled()) {
logger.trace("Bound value [" + value + "] for key [" + actualKey + "] to thread [" +
Thread.currentThread().getName() + "]");
}
}
其中resources是其类的静态变量,是一个ThreadLocal类型,用于提供一个线程隔离的全局变量
看下它在TransactionSynchronizationManager里的声明方式:
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<Map<Object, Object>>("Transactional resources");
如何确保使用同一连接
在上面我们看到,TransactionSynchronizationManager只是把连接通过自己的ThreadLocal变量绑定到线程当中了,那么如何使用呢?
当我们使用spring的事务时,肯定需要维持事务连接的一致性,在两个方法使用同一事务时,需要确保他们使用同一个连接,因此spring提供了多个获取连接的工具类,底层都会确保我们事务连接的一致性,我们先拿最典型的Jdbctemplate来说
当我们在通过spring的工具类比如Jdbctemplate来简化JDBC操作时,其内部获取连接通常会使用DataSourceUtils.getConnection()方法
DataSourceUtils.getConnection
public static Connection getConnection(DataSource dataSource) throws CannotGetJdbcConnectionException {
try {
return doGetConnection(dataSource);
} catch (SQLException var2) {
throw new CannotGetJdbcConnectionException("Could not get JDBC Connection", var2);
}
}
DataSourceUtils.doGetConnection
public static Connection doGetConnection(DataSource dataSource) throws SQLException {
Assert.notNull(dataSource, "No DataSource specified");
ConnectionHolder conHolder = (ConnectionHolder)TransactionSynchronizationManager.getResource(dataSource);
if (conHolder == null || !conHolder.hasConnection() && !conHolder.isSynchronizedWithTransaction()) {
logger.debug("Fetching JDBC Connection from DataSource");
Connection con = dataSource.getConnection();
//当前线程支持同步
if (TransactionSynchronizationManager.isSynchronizationActive()) {
logger.debug("Registering transaction synchronization for JDBC Connection");
//在事务中使用同一数据库连接
ConnectionHolder holderToUse = conHolder;
if (conHolder == null) {
holderToUse = new ConnectionHolder(con);
} else {
conHolder.setConnection(con);
}
//记录数据库连接
holderToUse.requested();
TransactionSynchronizationManager.registerSynchronization(new ConnectionSynchronization(holderToUse, dataSource));
holderToUse.setSynchronizedWithTransaction(true);
if (holderToUse != conHolder) {
TransactionSynchronizationManager.bindResource(dataSource, holderToUse);
}
}
return con;
} else {
conHolder.requested();
if (!conHolder.hasConnection()) {
logger.debug("Fetching resumed JDBC Connection from DataSource");
conHolder.setConnection(dataSource.getConnection());
}
return conHolder.getConnection();
}
}
在阅读下面解析时,需要对事务传播行为有个简单的了解
优先获取事务绑定的连接:在数据库连接方面,基于事务处理的特殊性,Spring需要==保证线程中的数据库操作都是使用同一个事务连接。==
- spring会通过
TransactionSynchronizationManager获取ConnectionHolder,如果ConnectionHolder不为null且有连接并且被同步器管理,说明当前有事务存在,所以需要保证保证线程中的数据库操作都是使用同一个事务连接,所以从ConnectionHolder中获取并返回。- spring开启事务时,会通过
TransactionSynchronizationManager内部的ThreadLocal变量将ConnectionHolder绑定到线程,然后获取连接并为ConnectionHolder设置连接
- spring开启事务时,会通过
这里就会引发我们的一个思考了:如果需要确保事务生效,我们需要使用spring提供的工具类来获取连接,否则需要自己确保使用的连接是从TransactionSynchronizationManager中获取的
至于后面部分的解析,放在下面isSynchronizationActive再进行
注意事项
存储事务连接是其基础功能,无论TransactionSynchronizationManager是否激活,都不影响事务连接的挂起和绑定
回调机制
回调机制使得我们在执行事务的commit和rollback时应用相应的回调,我们先看看其提供哪些回调
回调接口
public interface TransactionSynchronization extends Flushable {
/** Completion status in case of proper commit */
int STATUS_COMMITTED = 0;
/** Completion status in case of proper rollback */
int STATUS_ROLLED_BACK = 1;
/** Completion status in case of heuristic mixed completion or system errors */
int STATUS_UNKNOWN = 2;
void suspend();
void resume();
@Override
void flush();
void beforeCommit(boolean readOnly);
void beforeCompletion();
void afterCommit();
void afterCompletion(int status);
}
在查看了回调接口,我们再看看其调用时机
调用时机
commit
在commit方法里:
AbstractPlatformTransactionManager.processCommit
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
prepareForCommit(status);
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
beforeCompletionInvoked = true;
boolean globalRollbackOnly = false;
if (status.isNewTransaction() || isFailEarlyOnGlobalRollbackOnly()) {
globalRollbackOnly = status.isGlobalRollbackOnly();
}
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Releasing transaction savepoint");
}
status.releaseHeldSavepoint();
}
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction commit");
}
doCommit(status);
}
// Throw UnexpectedRollbackException if we have a global rollback-only
// marker but still didn't get a corresponding exception from commit.
if (globalRollbackOnly) {
throw new UnexpectedRollbackException(
"Transaction silently rolled back because it has been marked as rollback-only");
}
}
catch (UnexpectedRollbackException ex) {
// can only be caused by doCommit
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
throw ex;
}
catch (TransactionException ex) {
// can only be caused by doCommit
if (isRollbackOnCommitFailure()) {
doRollbackOnCommitException(status, ex);
}
else {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
}
throw ex;
}
catch (RuntimeException ex) {
if (!beforeCompletionInvoked) {
triggerBeforeCompletion(status);
}
doRollbackOnCommitException(status, ex);
throw ex;
}
catch (Error err) {
if (!beforeCompletionInvoked) {
triggerBeforeCompletion(status);
}
doRollbackOnCommitException(status, err);
throw err;
}
// Trigger afterCommit callbacks, with an exception thrown there
// propagated to callers but the transaction still considered as committed.
try {
triggerAfterCommit(status);
}
finally {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_COMMITTED);
}
}
finally {
cleanupAfterCompletion(status);
}
}
rollback
AbstractPlatformTransactionManager.processRollback
private void processRollback(DefaultTransactionStatus status) {
try {
try {
triggerBeforeCompletion(status);
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Rolling back transaction to savepoint");
}
status.rollbackToHeldSavepoint();
}
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction rollback");
}
doRollback(status);
}
else if (status.hasTransaction()) {
if (status.isLocalRollbackOnly() || isGlobalRollbackOnParticipationFailure()) {
if (status.isDebug()) {
logger.debug("Participating transaction failed - marking existing transaction as rollback-only");
}
doSetRollbackOnly(status);
}
else {
if (status.isDebug()) {
logger.debug("Participating transaction failed - letting transaction originator decide on rollback");
}
}
}
else {
logger.debug("Should roll back transaction but cannot - no transaction available");
}
}
catch (RuntimeException ex) {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
throw ex;
}
catch (Error err) {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
throw err;
}
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
}
finally {
cleanupAfterCompletion(status);
}
}
suspend
AbstractPlatformTransactionManager.suspend
protected final SuspendedResourcesHolder suspend(Object transaction) throws TransactionException {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
List<TransactionSynchronization> suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
suspendedResources = doSuspend(transaction);
}
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
return new SuspendedResourcesHolder(
suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
}
catch (RuntimeException ex) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
catch (Error err) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw err;
}
}
else if (transaction != null) {
// Transaction active but no synchronization active.
Object suspendedResources = doSuspend(transaction);
return new SuspendedResourcesHolder(suspendedResources);
}
else {
// Neither transaction nor synchronization active.
return null;
}
}
再看挂起的具体实现:
AbstractPlatformTransactionManager.doSuspendSynchronization
private List<TransactionSynchronization> doSuspendSynchronization() {
List<TransactionSynchronization> suspendedSynchronizations =
TransactionSynchronizationManager.getSynchronizations();
for (TransactionSynchronization synchronization : suspendedSynchronizations) {
synchronization.suspend();
}
TransactionSynchronizationManager.clearSynchronization();
return suspendedSynchronizations;
}
resume
在commit和rollback后会清理资源,其中就包括挂起资源的恢复
AbstractPlatformTransactionManager.cleanupAfterCompletion
private void cleanupAfterCompletion(DefaultTransactionStatus status) {
status.setCompleted();
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.clear();
}
if (status.isNewTransaction()) {
doCleanupAfterCompletion(status.getTransaction());
}
if (status.getSuspendedResources() != null) {
if (status.isDebug()) {
logger.debug("Resuming suspended transaction after completion of inner transaction");
}
resume(status.getTransaction(), (SuspendedResourcesHolder) status.getSuspendedResources());
}
}
再看看resume的具体实现:
AbstractPlatformTransactionManager.resume
protected final void resume(Object transaction, SuspendedResourcesHolder resourcesHolder)
throws TransactionException {
if (resourcesHolder != null) {
Object suspendedResources = resourcesHolder.suspendedResources;
if (suspendedResources != null) {
doResume(transaction, suspendedResources);
}
List<TransactionSynchronization> suspendedSynchronizations = resourcesHolder.suspendedSynchronizations;
if (suspendedSynchronizations != null) {
TransactionSynchronizationManager.setActualTransactionActive(resourcesHolder.wasActive);
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(resourcesHolder.isolationLevel);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(resourcesHolder.readOnly);
TransactionSynchronizationManager.setCurrentTransactionName(resourcesHolder.name);
doResumeSynchronization(suspendedSynchronizations);
}
}
}
两个标志方法
在使用事务同步管理器中有两个标志方法,可能会有人不清楚他们的具体作用,这里特别说明下
isNewSynchronization
其中一个是DefaultTransactionStatus中的isNewSynchronization方法
Spring 提供了事务同步(TransactionSynchronization)机制,用于将事务与资源(如数据访问操作、缓存更新等)绑定在一起。
事务管理器的同步模式包括:
public abstract class AbstractPlatformTransactionManager implements PlatformTransactionManager, Serializable {
/**
* Always activate transaction synchronization, even for "empty" transactions
* that result from PROPAGATION_SUPPORTS with no existing backend transaction.
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_SUPPORTS
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_NOT_SUPPORTED
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_NEVER
*/
public static final int SYNCHRONIZATION_ALWAYS = 0;
/**
* Activate transaction synchronization only for actual transactions,
* that is, not for empty ones that result from PROPAGATION_SUPPORTS with
* no existing backend transaction.
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_REQUIRED
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_MANDATORY
* @see org.springframework.transaction.TransactionDefinition#PROPAGATION_REQUIRES_NEW
*/
public static final int SYNCHRONIZATION_ON_ACTUAL_TRANSACTION = 1;
/**
* Never active transaction synchronization, not even for actual transactions.
*/
public static final int SYNCHRONIZATION_NEVER = 2;
//默认是`SYNCHRONIZATION_ALWAYS`
private int transactionSynchronization = SYNCHRONIZATION_ALWAYS;
}
SYNCHRONIZATION_ALWAYS:始终启用事务同步。SYNCHRONIZATION_ON_ACTUAL_TRANSACTION:仅在实际存在事务时启用同步。SYNCHRONIZATION_NEVER:完全禁用事务同步。
newSynchronization
用于决定当前方法是不是新的事务同步管理器,即是不是首次创建事务同步管理器的同步的方法。可能这么说很拗口,可以查看下面一段代码:
AbstractPlatformTransactionManager.newTransactionStatus
protected DefaultTransactionStatus newTransactionStatus(
TransactionDefinition definition, Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, Object suspendedResources) {
boolean actualNewSynchronization = newSynchronization &&
!TransactionSynchronizationManager.isSynchronizationActive();
return new DefaultTransactionStatus(
transaction, newTransaction, actualNewSynchronization,
definition.isReadOnly(), debug, suspendedResources);
}
这是初始化TransactionStatus的一段代码:在里面会判断事务同步管理器是否已经激活,如果已经激活,那么newSynchronization会是false。因此,==只有当前事务管理器的同步模式允许,以及当前线程的事务管理器没有激活的情况,这个值才是true。==至于具体的影响,我们下面进行分析
影响事务同步管理器的回调机制的激活
AbstractPlatformTransactionManager.getTransaction
public final TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException {
//代码片段
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
//...
prepareSynchronization(status, definition);
}
AbstractPlatformTransactionManager.prepareSynchronization
protected void prepareSynchronization(DefaultTransactionStatus status, TransactionDefinition definition) {
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.setActualTransactionActive(status.hasTransaction());
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(
definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT ?
definition.getIsolationLevel() : null);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(definition.isReadOnly());
TransactionSynchronizationManager.setCurrentTransactionName(definition.getName());
TransactionSynchronizationManager.initSynchronization();
}
}
这行代码很重要,用于初始化当前线程存放执行回调机制的Synchronization机制的容器,如果同步模式设置为never将不会初始化事务管理同步器的回调器的存储容器
TransactionSynchronizationManager.initSynchronization();
TransactionSynchronizationManager.initSynchronization
public static void initSynchronization() throws IllegalStateException {
if (isSynchronizationActive()) {
throw new IllegalStateException("Cannot activate transaction synchronization - already active");
}
logger.trace("Initializing transaction synchronization");
synchronizations.set(new LinkedHashSet<TransactionSynchronization>());
}
只有事务同步管理器已经激活的情况,才可以向里面注册事务同步回调器(TransactionSynchronization)
TransactionSynchronizationManager.initSynchronization
public static void registerSynchronization(TransactionSynchronization synchronization)
throws IllegalStateException {
Assert.notNull(synchronization, "TransactionSynchronization must not be null");
if (!isSynchronizationActive()) {
throw new IllegalStateException("Transaction synchronization is not active");
}
synchronizations.get().add(synchronization);
}
影响回调机制的执行
在执行回调时triggerBeforeCommit和triggerBeforeCompletion,都会判断newSynchronization的值:
AbstractPlatformTransactionManager.triggerBeforeCommit
protected final void triggerBeforeCommit(DefaultTransactionStatus status) {
if (status.isNewSynchronization()) {
if (status.isDebug()) {
logger.trace("Triggering beforeCommit synchronization");
}
TransactionSynchronizationUtils.triggerBeforeCommit(status.isReadOnly());
}
}
AbstractPlatformTransactionManager.triggerBeforeCompletion
protected final void triggerBeforeCompletion(DefaultTransactionStatus status) {
if (status.isNewSynchronization()) {
if (status.isDebug()) {
logger.trace("Triggering beforeCompletion synchronization");
}
TransactionSynchronizationUtils.triggerBeforeCompletion();
}
}
也就是说在初次创建此事务同步管理器的回调功能的方法才会应用这两个回调,对于嵌套事务,只有外层事务才会应用这两个回调
影响事务同步管理器的清理
在commit和rollback最后都会执行清理工作:
AbstractPlatformTransactionManager.cleanupAfterCompletion
private void cleanupAfterCompletion(DefaultTransactionStatus status) {
status.setCompleted();
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.clear();
}
if (status.isNewTransaction()) {
doCleanupAfterCompletion(status.getTransaction());
}
if (status.getSuspendedResources() != null) {
if (status.isDebug()) {
logger.debug("Resuming suspended transaction after completion of inner transaction");
}
resume(status.getTransaction(), (SuspendedResourcesHolder) status.getSuspendedResources());
}
}
只有isNewSynchronization为true时才会对事务同步管理器进行清理
不影响事务连接的绑定与挂起
这里要特别注意,事务管理器的同步模式设置什么,不影响事务连接的绑定到事务同步管理器的ThreadLocal变量和将事务挂起的功能
在 Spring 的 DataSourceTransactionManager 中,即使事务同步模式设置为 SYNCHRONIZATION_NEVER,当实际事务开启时(例如传播行为为 REQUIRED、REQUIRES_NEW),依然会为当前线程绑定连接。这是因为事务的物理执行(如开启连接、设置隔离级别、提交/回滚)需要独立的连接资源,而 事务同步机制(SYNCHRONIZATION_NEVER)仅控制是否启用同步回调(如资源释放、事务事件触发),并不影响事务本身的连接绑定逻辑。
在开启事务的doBegin方法中:
DataSourceTransactionManager.doBegin
protected void doBegin(Object transaction, TransactionDefinition definition) {
//代码片段
if (!txObject.hasConnectionHolder() || txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
Connection newCon = this.dataSource.getConnection();
if (this.logger.isDebugEnabled()) {
this.logger.debug("Acquired Connection [" + newCon + "] for JDBC transaction");
}
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
//....
if (txObject.isNewConnectionHolder()) {
TransactionSynchronizationManager.bindResource(this.getDataSource(), txObject.getConnectionHolder());
}
}
可见bindResource方法与isNewSynchronization并无联系
再看看挂起方法:
AbstractPlatformTransactionManager.suspend
protected final SuspendedResourcesHolder suspend(Object transaction) throws TransactionException {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
List<TransactionSynchronization> suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
suspendedResources = doSuspend(transaction);
}
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
return new SuspendedResourcesHolder(
suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
}
catch (RuntimeException ex) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
catch (Error err) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw err;
}
}
else if (transaction != null) {
// Transaction active but no synchronization active.
Object suspendedResources = doSuspend(transaction);
return new SuspendedResourcesHolder(suspendedResources);
}
else {
// Neither transaction nor synchronization active.
return null;
}
}
可见即使isSynchronizationActive为false,也就是没有激活事务管理器的同步功能的时候,也会执行事务的挂起
总结
事务的核心操作(如 setAutoCommit(false)、commit()、rollback())必须基于一个独立的物理连接。连接的绑定是事务执行的物理基础,而同步机制是锦上添花的管理层逻辑(如触发回调)。
isSynchronizationActive
这是TransactionSynchronizationManager中的一个方法,主要用于判断TransactionSynchronizationManager是否已经激活
TransactionSynchronizationManager.isSynchronizationActive
public static boolean isSynchronizationActive() {
return (synchronizations.get() != null);
}
只有激活时,才可以向里面注册回调器,这里我们先看上面提过的DataSourceUtils获取连接的过程
DataSourceUtils.doGetConnection
public static Connection doGetConnection(DataSource dataSource) throws SQLException {
Assert.notNull(dataSource, "No DataSource specified");
ConnectionHolder conHolder = (ConnectionHolder)TransactionSynchronizationManager.getResource(dataSource);
if (conHolder == null || !conHolder.hasConnection() && !conHolder.isSynchronizedWithTransaction()) {
logger.debug("Fetching JDBC Connection from DataSource");
Connection con = dataSource.getConnection();
//当前线程支持同步
if (TransactionSynchronizationManager.isSynchronizationActive()) {
logger.debug("Registering transaction synchronization for JDBC Connection");
//在事务中使用同一数据库连接
ConnectionHolder holderToUse = conHolder;
if (conHolder == null) {
holderToUse = new ConnectionHolder(con);
} else {
conHolder.setConnection(con);
}
//记录数据库连接
holderToUse.requested();
TransactionSynchronizationManager.registerSynchronization(new ConnectionSynchronization(holderToUse, dataSource));
holderToUse.setSynchronizedWithTransaction(true);
if (holderToUse != conHolder) {
TransactionSynchronizationManager.bindResource(dataSource, holderToUse);
}
}
return con;
} else {
conHolder.requested();
if (!conHolder.hasConnection()) {
logger.debug("Fetching resumed JDBC Connection from DataSource");
conHolder.setConnection(dataSource.getConnection());
}
return conHolder.getConnection();
}
}
-
优先获取事务绑定的连接:在数据库连接方面,基于事务处理的特殊性,Spring需要==保证线程中的数据库操作都是使用同一个事务连接。==
- spring会通过
TransactionSynchronizationManager获取ConnectionHolder,如果ConnectionHolder不为null且有连接并且被同步器管理,说明当前有事务存在,所以需要保证保证线程中的数据库操作都是使用同一个事务连接,所以从ConnectionHolder中获取并返回。- spring开启事务时,会通过
TransactionSynchronizationManager内部的ThreadLocal变量将ConnectionHolder绑定到线程,然后获取连接并为ConnectionHolder设置连接
- spring开启事务时,会通过
- spring会通过
-
无事务时新建连接:若当前无事务(或未绑定连接),则新建连接,并根据 事务同步状态 (isSynchronizationActive)决定是否绑定到线程:
-
在非事务场景下,若
TransactionSynchronizationManager激活了,说明可以利用TransactionSynchronizationManager的功能,通过回调机制管理连接生命周期。-
例如,在
PROPAGATION_NOT_SUPPORTED这种事务传播行为下,不允许当前方法有事务,但是仍然会激活事务管理器TransactionSynchronizationManager的功能用于在特定时刻执行回调(suspend、beforeCommit、afterCommit等等), -
在
TransactionSynchronizationManager激活的情况,我们可以将连接通过TransactionSynchronizationManager绑定到线程,这样的话-
如果我们在非事务方法中多次调用
JdbcTemplate操作,可复用线程中的连接以减少资源开销。 -
在需要事务的时候通过回调器从将连接从线程解绑,避免阻碍事务连接绑定到线程
-
-
-
注册回调器
ConnectionSynchronization,注意以下几点:-
必须在
TransactionSynchronizationManager激活时(isSynchronizationActive),才允许将连接通过TransactionSynchronizationManager绑定到线程来复用-
只有初始化了当前线程存放TransactionSynchronization的容器才视为激活,这是因为需要借助注册的
ConnectionSynchronization回调器,将连接从线程中解绑,因为新事务肯定需要将连接绑定到线程,如果不解绑将会引发冲突 -
在内层需要开启事务的情况时,会触发TransactionSynchronization的suspend`方法==将绑定到线程的连接解绑==,并在必要时为了不占用资源,将连接释放。
- 如果你细心的话,肯定会发现每次执行DataSourceTransactionManager.doBegin方法开启事务前,一定会执行
suspend方法,需要注意的是即使外层无事务,spring依然会这样做,这是因为TransactionSynchronizationManager是用于管理事务同步的一个核心工具类。它负责注册和触发TransactionSynchronization接口的实现类,从而在事务的不同阶段(如事务开始、提交前、提交后、回滚等)执行相应的回调逻辑。TransactionSynchronization的生命周期与当前事务绑定,所以当有新事务需要开启时,需要将旧的TransactionSynchronization挂起
- 如果你细心的话,肯定会发现每次执行DataSourceTransactionManager.doBegin方法开启事务前,一定会执行
-
或者当前事务方法结束时释放连接并解除绑定
-
-
-
DataSourceTransactionObject
DataSourceTransactionObject继承了JdbcTransactionObjectSupport,JdbcTransactionObjectSupport 是 Spring 事务管理中的一个基础组件,主要用于为基于 JDBC 的事务提供核心支持。它的核心功能包括:
- 管理数据库连接(Connection)
封装ConnectionHolder对象,持有当前事务关联的数据库连接,确保同一事务中的多个操作共享同一个连接,保证事务的原子性。 - 连接点
savepoint的管理
DataSourceTransactionObject在此基础上添加了连接状态跟踪的功能,例如:
- 是否是“新连接”(
newConnectionHolder)。 - 是否需要回滚(
rollbackOnly),它主要用于处理嵌套事务或无法设置保存点的场景。
当使用声明式事务管理时,Spring会为每个事务创建一个事务对象(即DataSourceTransactionObject实例),该对象持有数据库连接,并记录连接的状态。
private static class DataSourceTransactionObject extends JdbcTransactionObjectSupport {
private boolean newConnectionHolder;
private boolean mustRestoreAutoCommit;
private DataSourceTransactionObject() {
}
public void setConnectionHolder(ConnectionHolder connectionHolder, boolean newConnectionHolder) {
super.setConnectionHolder(connectionHolder);
this.newConnectionHolder = newConnectionHolder;
}
public boolean isNewConnectionHolder() {
return this.newConnectionHolder;
}
public void setMustRestoreAutoCommit(boolean mustRestoreAutoCommit) {
this.mustRestoreAutoCommit = mustRestoreAutoCommit;
}
public boolean isMustRestoreAutoCommit() {
return this.mustRestoreAutoCommit;
}
public void setRollbackOnly() {
this.getConnectionHolder().setRollbackOnly();
}
public boolean isRollbackOnly() {
return this.getConnectionHolder().isRollbackOnly();
}
public void flush() {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
TransactionSynchronizationUtils.triggerFlush();
}
}
}
TransactionStatus
TransactionStatus 是 Spring 框架中用于表示事务状态的一个接口,并提供了一系列方法来供用户查询和控制事务的执行状态。
DefaultTransactionStatus实现了这个接口,并在此之上扩展了一些属性可以使其作为事务上下文的载体
- transaction,用于持有事务连接和管理回滚点
- suspendedResources,用于资源(事务、事务同步器)的挂起与恢复
- newTransaction:在做提交和回滚时,都要判断这个属性来决定是否真正执行事务的提交和回滚
- **newSynchronization:**用于决定是否开启事务同步管理器的回调机制的功能
- 获取事务管理器的同步模式
- 当前事务同步管理器是否已经激活
- 是否只读
也就是说TransactionStatus 不仅保存实际的物理事务资源(如 DataSourceTransactionObject),还承载事务传播行为中事务的挂起和恢复等功能。
TransactionStatus 接口的主要方法包括:
public class DefaultTransactionStatus extends AbstractTransactionStatus {
private final Object transaction;
private final boolean newTransaction;
private final boolean newSynchronization;
private final boolean readOnly;
private final boolean debug;
private final Object suspendedResources;
/*
hasTransaction():检查当前是否有事务
isNewTransaction(): 检查当前事务是否是新事务。
hasSavepoint(): 检查当前事务是否有一个保存点。
isCompleted(): 检查当前事务是否已完成。
isRollbackOnly(): 检查当前事务是否已被标记为回滚。
setRollbackOnly(): 设置当前事务为回滚状态。
createSavepoint(): 在当前事务中创建一个保存点。
rollbackToSavepoint(Object savepoint): 将当前事务回滚到指定的保存点。
releaseSavepoint(Object savepoint): 释放之前创建的保存点。
*/
}
TransactionInfo
他是TransactionAspectSupport的一个内部类,用于保存事务管理、事务属性、事务状态等信息,在提交事务或回滚事务时,需要通过其获取TransactionManager、transactionAttribute、transactionStatus等信息
protected final class TransactionInfo {
private final PlatformTransactionManager transactionManager;
private final TransactionAttribute transactionAttribute;
private final String joinpointIdentification;
private TransactionStatus transactionStatus;
private TransactionInfo oldTransactionInfo;
public TransactionInfo(PlatformTransactionManager transactionManager,
TransactionAttribute transactionAttribute, String joinpointIdentification) {
this.transactionManager = transactionManager;
this.transactionAttribute = transactionAttribute;
this.joinpointIdentification = joinpointIdentification;
}
//省略部分代码
public boolean hasTransaction() {
return (this.transactionStatus != null);
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









