







 Redis是一个基于内存的高性能数据库,其优势在于快速的内存操作和高效的单线程模型。通过使用非阻塞的IO多路复用技术,如epoll,Redis能并发处理大量连接。单线程避免了线程切换和竞争条件,简化了代码。此外,Redis提供多种数据结构,如字符串、列表、哈希、集合和有序集合,优化了数据存储和访问。Redis的持久化和集群同步则在后台线程中执行,确保了主要操作的高效率。
Redis是一个基于内存的高性能数据库,其优势在于快速的内存操作和高效的单线程模型。通过使用非阻塞的IO多路复用技术,如epoll,Redis能并发处理大量连接。单线程避免了线程切换和竞争条件,简化了代码。此外,Redis提供多种数据结构,如字符串、列表、哈希、集合和有序集合,优化了数据存储和访问。Redis的持久化和集群同步则在后台线程中执行,确保了主要操作的高效率。
完全基于内存实现
Redis是基于内存的数据库,跟磁盘数据库相比,完全吊打磁盘的速度。
对比一下,内存操作和磁盘操作的差异
内存操作 是由CPU控制的,也就是CPU内部集成的内存控制器,所以说内存是直接与CPU对接,享受最优的带宽。
redis 将数据存储在内存中,读写操作不会因为磁盘的IO速度限制,所以速度飞一般的感觉。
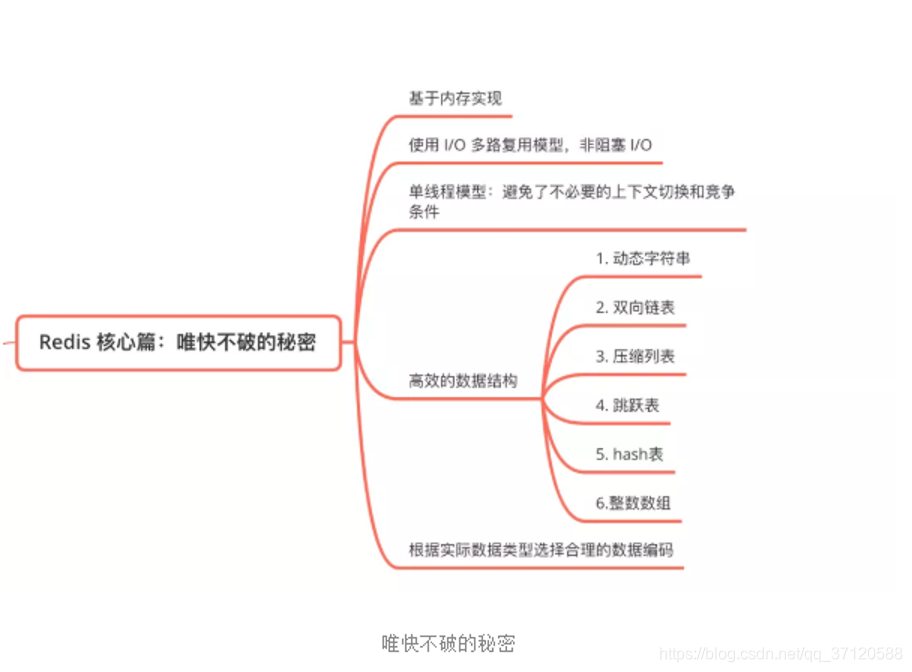
高效的数据结构
Redis常用的五种数据类型和应用场景
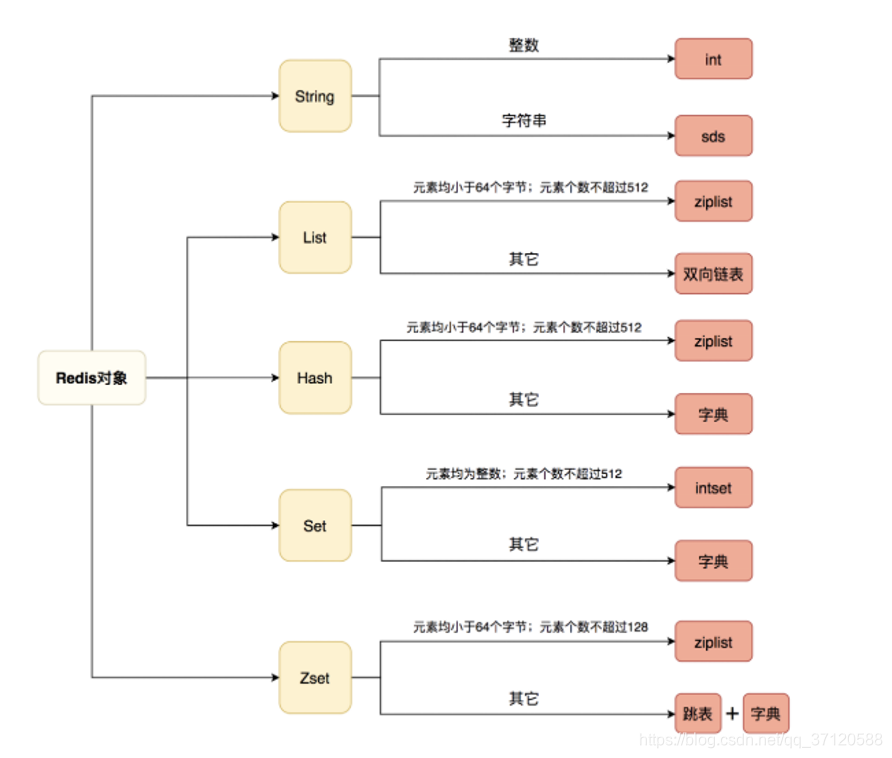
string 缓存、限制器
list 链表、队列,朋友圈
hash 用户信息、hash
set 去重、投票、共同好友
zset 排行榜
单线程模型
redis的单线程模型指的是Redis的网络IO以及键值对指令读写是由一个线程来执行。对于redis的持久化、集群数据同步、异步同步删除等都是由其他线程执行的的。
为啥使用多线程?
多线程,通常可以增加系统吞吐量,充分利用CPU资源。但是使用了多线程后,没有良好的系统设计,前期吞吐量会增加,再进一步新增线程时,系统的吞吐量几乎不再新增,甚至会下降。
在运行每个任务之前,CPU 需要知道任务在何处加载并开始运行。也就是说,系统需要帮助它预先设置 CPU 寄存器和程序计数器,这称为 CPU 上下文。
这些保存的上下文存储在系统内核中,并在重新计划任务时再次加载。这样,任务的原始状态将不会受到影响,并且该任务将看起来正在连续运行。
切换上下文时,我们需要完成一系列工作,这是非常消耗资源的操作。
另外,当多线程并行修改共享数据的时候,为了保证数据正确,需要加锁机制就会带来额外的性能开销,面临的共享资源的并发访问控制问题。
引入多线程开发,就需要使用同步原语来保护共享资源的并发读写,增加代码复杂度和调试难度。
单线程又什么好处?
1.不会因为线程创建导致的性能消耗;
2.避免上下文切换引起的 CPU 消耗,没有多线程切换的开销;
3.避免了线程之间的竞争问题,比如添加锁、释放锁、死锁等,不需要考虑各种锁问题。
4.代码更清晰,处理逻辑简单。
单线程是否没有充分利用 CPU 资源呢?
官方答案:因为 Redis 是基于内存的操作,CPU 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章地采用单线程的方案了。原文地址:https://redis.io/topics/faq。
IO多路复用模型
Redis 采用 I/O 多路复用技术,并发处理连接。采用了 epoll + 自己实现的简单的事件框架。epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,绝不在 IO 上浪费一点时间。
总结
1.纯内存操作,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在 IO 上,所以读取速度快。
2.整个 Redis 就是一个全局 哈希表,他的时间复杂度是 O(1),而且为了防止哈希冲突导致链表过长,Redis 会执行 rehash 操作,扩充 哈希桶数量,减少哈希冲突。并且防止一次性 重新映射数据过大导致线程阻塞,采用 渐进式 rehash。巧妙的将一次性拷贝分摊到多次请求过程后总,避免阻塞。
3.Redis 使用的是非阻塞 IO:IO 多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,Redis 采用自己实现的事件分离器,效率比较高。
4.采用单线程模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
5.Redis 全程使用 hash 结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。
6.根据实际存储的数据类型选择不同编码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









