






1. Kafka 存储在文件系统上
Kafka 的消息是存在于文件系统之上的
如果是针对磁盘的顺序访问,某些情况下它可能比随机的内存访问都要快,甚至可以和网络的速度相差无几
再加上预读机制
2. Kafka底层存储设计
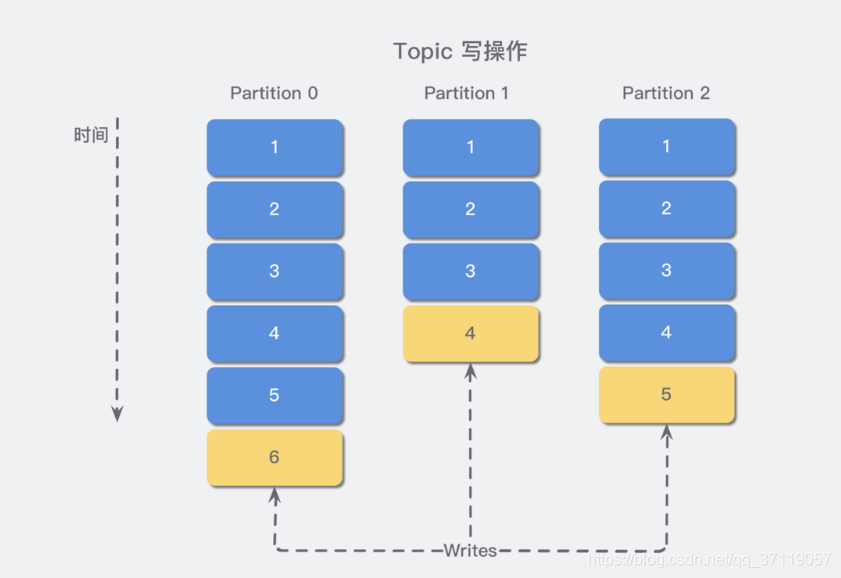
 同一个 Topic 下有多个不同的 Partition;
同一个 Topic 下有多个不同的 Partition;
每个 Partition 都为一个目录;
而每一个目录又被平均分配成多个大小相等的 Segment File ;
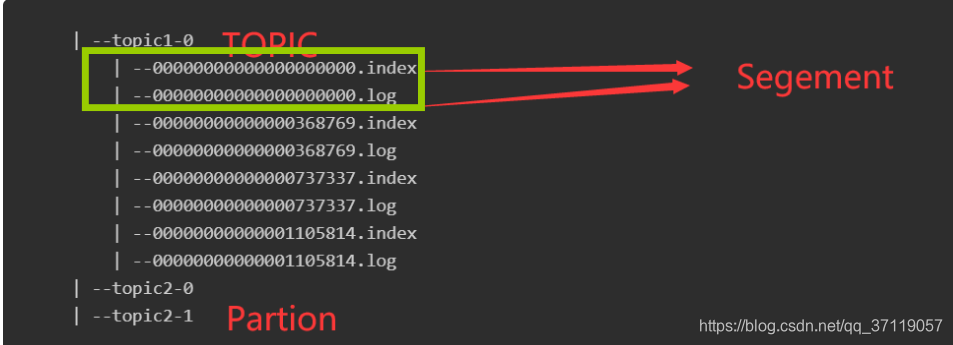
- Topic
- Partition
- Segement File
- index 索引文件
- log data文件
- Segement File
- Partition
index和log的关系
以索引文件中元数据 <3, 497> 为例,
依次在数据文件中表示第 3 个 message(在全局 Partition 表示第 368769 + 3 = 368772 个 message)以及该消息的物理偏移地址为 497
3. 生产者的设计
- 每条消息都是很关键且不能容忍丢失么?
- 偶尔重复消息可以么?
- 我们关注的是消息延迟还是写入消息的吞吐量?
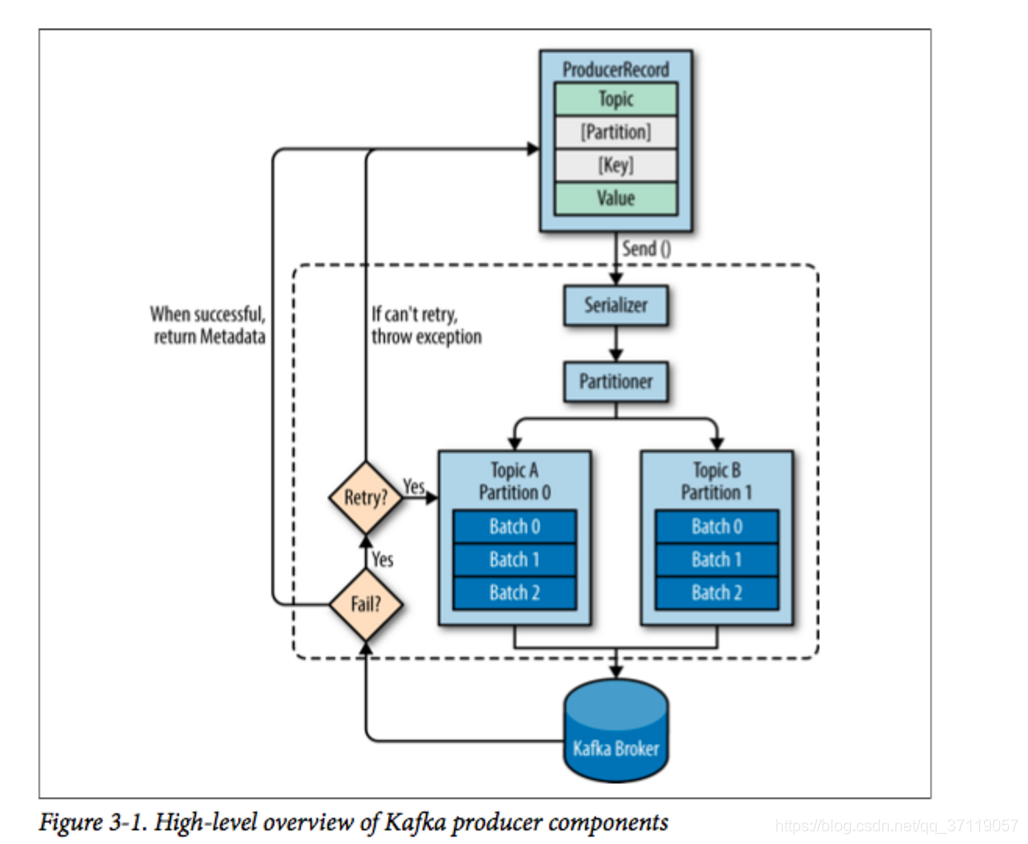
流程如下:
- 首先,我们需要创建一个ProducerRecord,这个对象需要包含消息的主题(topic)和值(value),可以选择性指定一个键值(key)或者分区(partition)。
- 发送消息时,生产者会对键值和值序列化成字节数组,然后发送到分配器(partitioner)。
- 如果我们指定了分区,那么分配器返回该分区即可;否则,分配器将会基于键值来选择一个分区并返回。
- 选择完分区后,生产者知道了消息所属的主题和分区,它将这条记录添加到相同主题和分区的批量消息中,另一个线程负责发送这些批量消息到对应的Kafka broker。
- 当broker接收到消息后,如果成功写入则返回一个包含消息的主题、分区及位移的RecordMetadata对象,否则返回异常。
- 生产者接收到结果后,对于异常可能会进行重试。
4. 消费者设计
生产者写入消息的速度 > 消费者读取的速度快
消息堆积
如果应用需要读取全量消息,那么请为该应用设置一个消费组;
如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者.
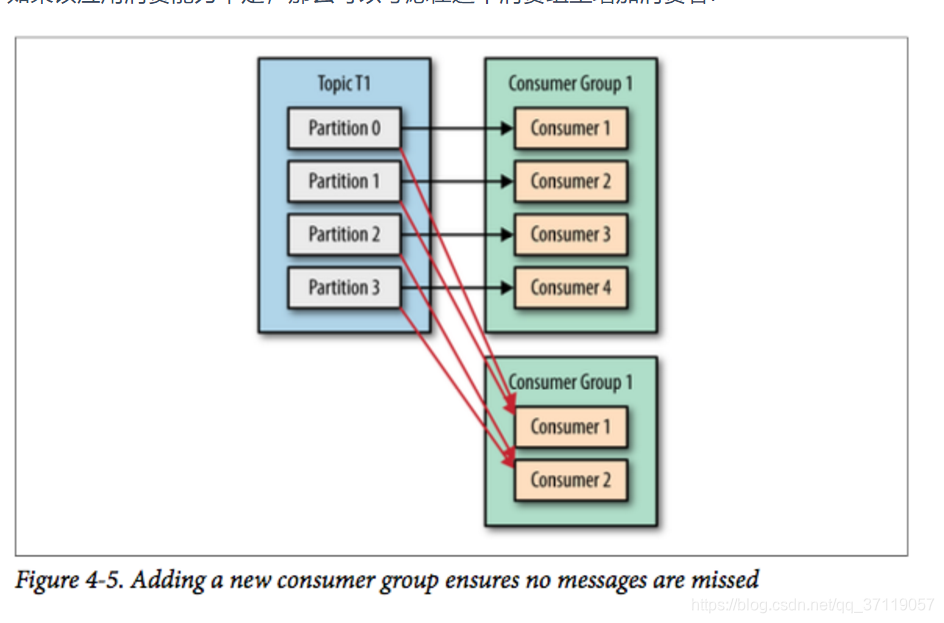
4.1 消费组分区重平衡
消费者通过定期发送心跳(hearbeat)到一个作为组协调者(group coordinator)的 broker 来保持在消费组内存活。这个 broker 不是固定的,每个消费组都可能不同。当消费者拉取消息或者提交时,便会发送心跳。
如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期。
所消费的分区会分配给其他分区
4.2 消费模型
Kafka 只会保证在 Partition 内消息是有序的,而不管全局的情况。
除非消息到期 Partition 从不删除消息
每个 Consumer Group 保存一个偏移量,记录 Group 消费到的位置
4.3 push/pull模式
push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。push 模式的目标是尽可能以最快速度传递消息,但是这样很容易造成 Consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 Consumer 的消费能力以适当的速率消费消息。
5. 可靠性保证
对于一个分区来说,它的消息是有序的。如果一个生产者向一个分区先写入消息A,然后写入消息B,那么消费者会先读取消息A再读取消息B。
当消息写入所有in-sync状态的副本后,消息才会认为已提交(committed)。这里的写入有可能只是写入到文件系统的缓存,不一定刷新到磁盘。生产者可以等待不同时机的确认,比如等待分区主副本写入即返回,后者等待所有in-sync状态副本写入才返回。
一旦消息已提交,那么只要有一个副本存活,数据不会丢失。
消费者只能读取到已提交的消息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









