Go中的Map实现机制
一、map的使用方式
- 初始化
func main() {
// 初始化方式一 make
m := make(map[string]interface{},10)
// 初始化方式二 字面量初始化
m2 := map[string]interface{}{}
}
- 增删改查
func mapCRUD() {
m := make(map[string]string, 10)
m["apple"] = "red" // 添加
m["apple"] = "yellow" // 修改
delete(m["apple"]) // 删除
v, exist := map["apple"]
if exist {
fmt.Println(""apple is here!)
}
}
- 危险操作
- 并发读写
- map不是原子操作,这意味着多个协程同时操作map时有可能产生读写冲突,读写冲突会触发panic从而导致程序退出
- Go是在map的实现中增加了读写检测机制,一旦发现读写冲突立马触发panic
- 建议:一般map参数不要被多个goroutine同时调用;使用带锁的map实现,一般用sync/map就能直接制造想要的带锁的map实现
- 触发读写冲突的代码如下:
func TestConcurrent(t *testing.T) {
var m = map[string]int{}
t.Run("write", func(t *testing.T) {
// 加上并行
t.Parallel()
for i := 0; i < 10000; i++ {
m["a"] = 1
}
})
t.Run("read", func(t *testing.T) {
// 加上并行
t.Parallel()
for i := 0; i < 10000; i++ {
_ = m["a"]
}
})
}
- 空map
- 小结
- 初始化map时推荐使用内置函数make(),并指定预估的容量
- 修改键值对时,需要先查询指定键是否存在,否则map将创建新的键值对
- 查询键值对时,最好检查键是否存在,,避免操作零值
- 避免并发读写map,如果需要并发读写,则可以使用额外的锁(互斥锁、读写锁),可可以考虑使用标准库sync包中的sync.Map
二、实现原理
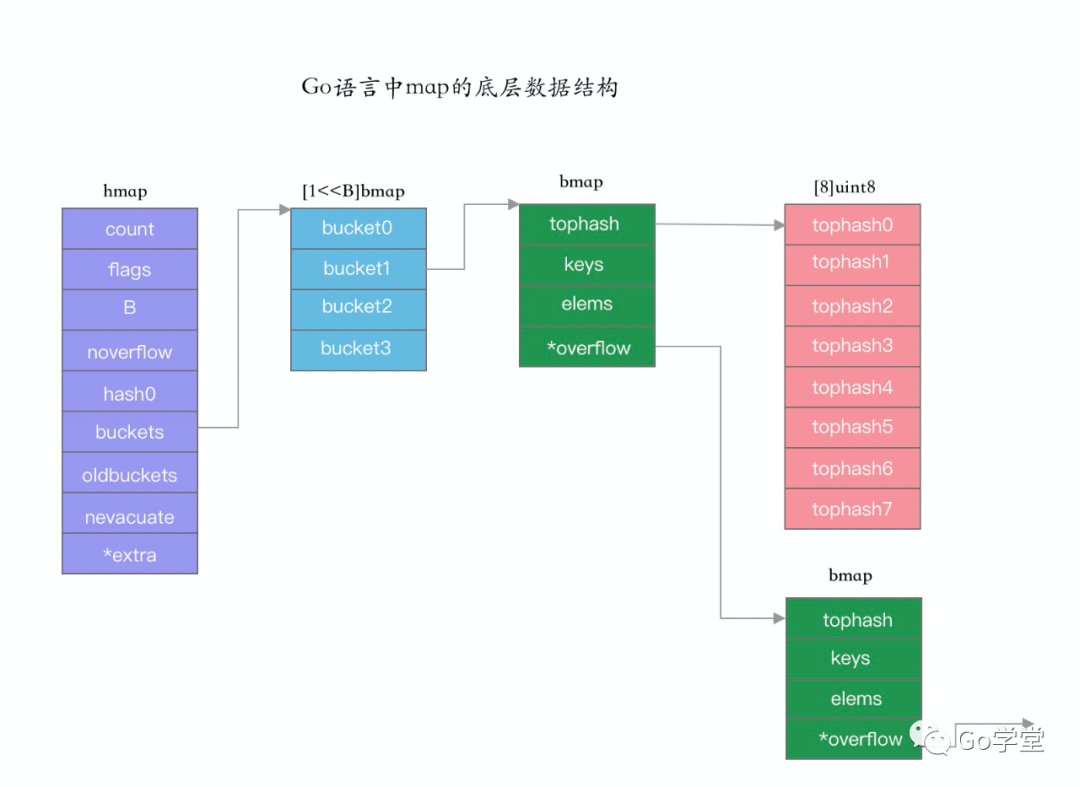
- 数据结构
- map的数据结构
// map的基础数据结构
type hmap struct {
count int // map存储的元素对计数,len()函数返回此值,所以map的len()时间复杂度是O(1)
flags uint8 // 记录几个特殊的位标记,如当前是否有别的线程正在写map、当前是否为相同大小的增长(扩容/缩容?)
B uint8 // hash桶buckets的数量为2^B个
noverflow uint16 // 溢出的桶的数量的近似值
hash0 uint32 // hash种子
buckets unsafe.Pointer // 指向2^B个桶组成的数组的指针,数据存在这里
oldbuckets unsafe.Pointer // 指向扩容前的旧buckets数组,只在map增长时有效
nevacuate uintptr // 计数器,标示扩容后搬迁的进度
extra *mapextra // 保存溢出桶的链表和未使用的溢出桶数组的首地址
}
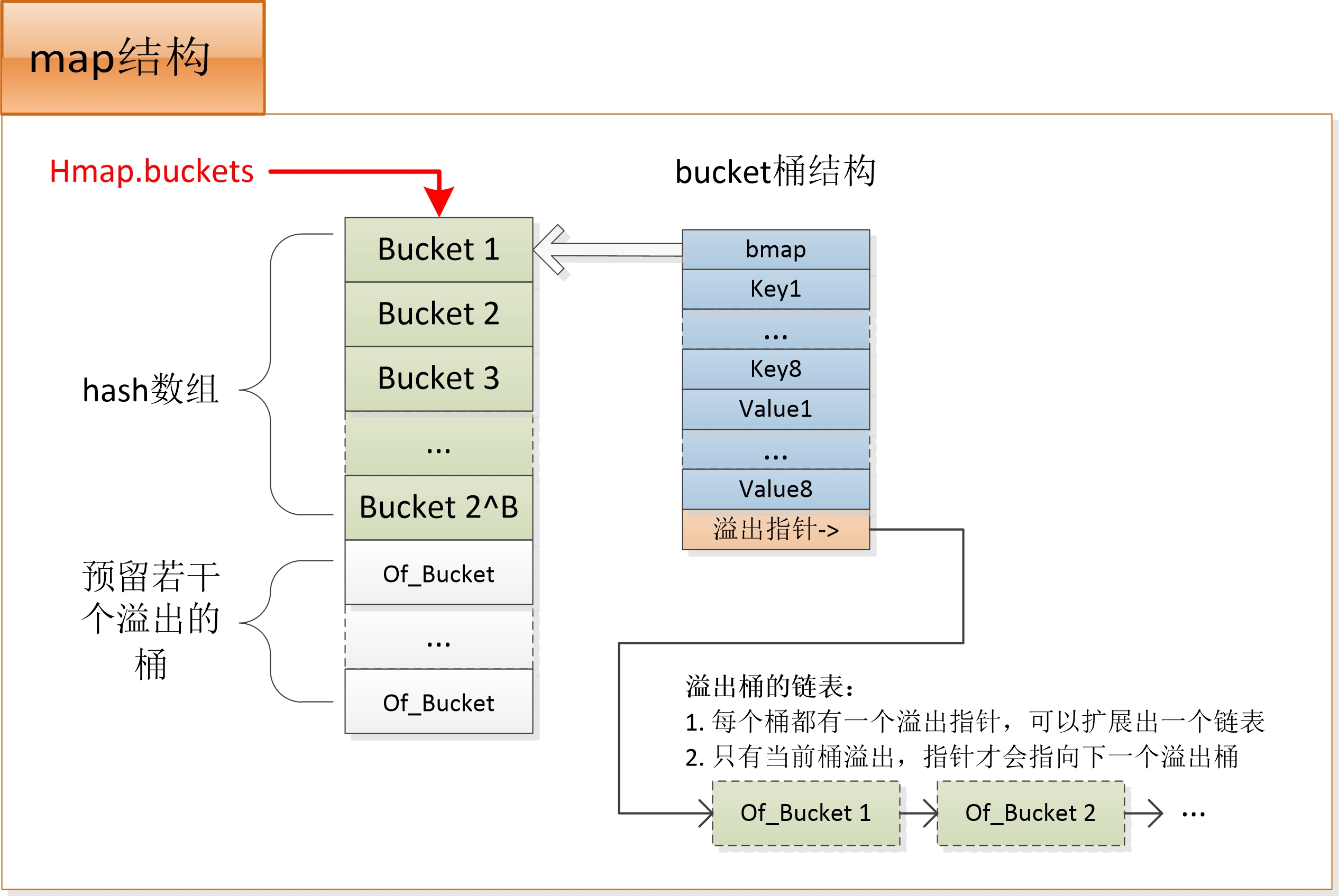
- bucket的数据结构
// 桶的实现结构
type bmap struct {
// tophash存储桶内每个key的hash值的高字节
// tophash[0] < minTopHash表示桶的疏散状态
// 当前版本bucketCnt的值是8,一个桶最多存储8个key-value对
tophash [bucketCnt]uint8
// 特别注意:
// 实际分配内存时会申请一个更大的内存空间A,A的前8字节为bmap
// 后面依次跟8个key、8个value、1个溢出指针
// map的桶结构实际指的是内存空间A
data []byte // key value数据:key/key/key/.../value/value/value
overflow *bmap // 溢出bucket地址
}
- tophash是一个长度为8的整形数组,hash值相同的键(准确的说是hash低位相同的键)存入当前bucket时会将hash值的高位存储在该数组中,以便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/…/value/value/value,如此存放是为了节省字节对齐带来的空间浪费
- overflow指针指向的事下一个bucket,据此将所有冲突的键连接起来。
- hash冲突
- 当有两个或以上数量的键被“Hash”到同一个bucket时,我们称这些键发生了冲突。Go使用链地址法来解决键的冲突。由于每个bucket可以存放8个键值对,所以同一个bucket存放超过8个键值对时就会再创建一个bucket,用类似链表的方式将bucket连接起来
- 负载因子
- 负载因子=键值数/bucket数量
- 负载因子过小,说明空间利用率低
- 负载因子过大,说明说明冲突严重,存取效率低
- go的map在负载因子大于6.5时会出发rehash
- 扩容
- 扩容条件
- 负载因子大于6.5时,即平均每个bucket存储的键值对达到6.5个以上
- overflow的数量达到2min(15,B)时。
- 增量扩容
- 当负载因子过大时,就新建一个bucket数组,新建的bucket数组的长租是原来的两倍,然后旧的bucket数组中的数组搬迁到新的bucket数组中
- 扩容时的处理非常巧妙,先试让hmap的数据结构中的oldbuckets成员指向原buckets数组,然后申请新的buckets数组(长度为原来的两倍),并将数组指针保存到hmap数据结构的buckets成员中。这样就完成了新老buckets数组的交接,后续的迁移工作将是从oldbuckets数组中逐步搬迁键值对到新的buckets数组中。待oldbuckets数组中所有键值对搬迁完毕后,就可以安全地释放oldbuckets数组了。
- 等量扩容
- 所谓的等量扩容,并不是扩大容量,而是bucket数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率变高,进而保证更快的存取效率。
- 在极端场景下,比如经过大量的元素增删后,键值对刚好集中在一小部分bucket中,这样会造成溢出的bucket数量增多。
- 增删查改
- 实现机制
- 对于查询操作而言,查询指定的键后获取值并返回,否则返回类型的空值
- 对于添加操作而言,查到指定的键意味着当前的添加操作实际上是更新操作,否则在bucket中查找一个空余位置并插入(待了解具体的插入实现)
- 查找过程
- 根据key值计算Hash值
- 取Hash值低位与hmap.B取模来确定bucket的位置
- 取Hash值高位,在tophash数组中查询
- 如果tophash[i]中存储的hash值与当前key的hash值相等,则获取top[i]的key值进行比较
- 当前bucket中没有找到,则依次从溢出的bucket中查找
- 如果当前map处于搬迁过程中,那么查找时优先从oldbuckets数组中查找,不再从buckets数组中查找
- 添加过程
- 根据key值算出hash值
- 取hash值低位与hmap.B取模来确定bucket的位置
- 查找该key是否已经存在,如果存在则直接更新值
- 如果该key不存在,则从该bucket中寻找空余位置并插入
- 当前map处于搬迁过程中,那么新元素会直接添加到新的buckets数组中,但查找过程仍从oldbuckets数组中开始
- 删除过程
- 删除元素实际上先查找元素,如果元素存在则把元素从bucket中清除,如果不存在则什么也不做

























 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









