







 在使用selenium进行Python爬虫时,遇到a标签href="#"无法获取有效网址。通过研究发现,实际网址信息在onclick属性中。通过解析onclick获取子路径,结合base网址构成完整URL。同时分享了如何获取页面中所有此类href的网址方法。
在使用selenium进行Python爬虫时,遇到a标签href="#"无法获取有效网址。通过研究发现,实际网址信息在onclick属性中。通过解析onclick获取子路径,结合base网址构成完整URL。同时分享了如何获取页面中所有此类href的网址方法。
今天,在利用selenium进行Python爬虫时,我遇到了下面的问题,我想得到图片中a标签中href的网址,却发现href = #,这可怎么搞哦!经过一番思索,查阅资料,网上有说抓包get获取网址的,但我比较菜鸡,就没用这种方法(以后可以研究研究)。最终,我居然发现!a标签里还有一个属性onclick,里面居然就是我想获取的网址的子路径!嗷嗷嗷嗷嗷!炒鸡兴奋的,然后方法如下: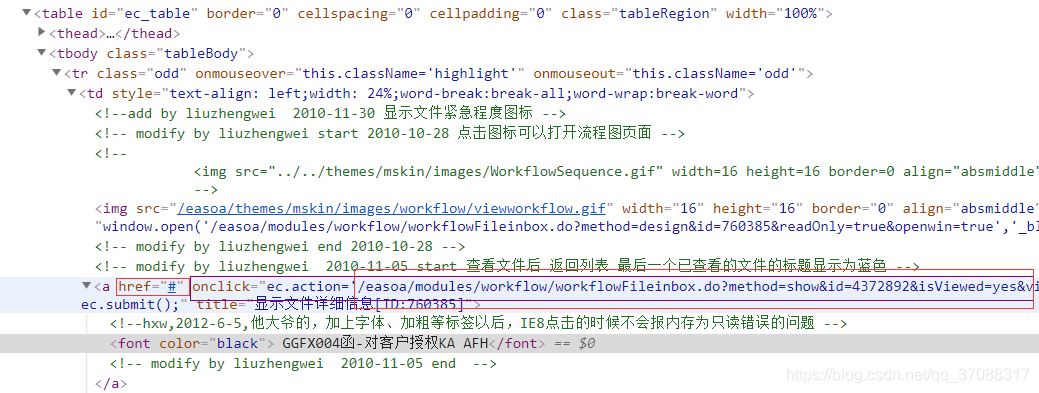
没错,在图片中可以看到,href="#", "ec.action=’/easoa/modules…’, 哇!这个’/easoa/modules…'就是我想要的子路径!只要base网址加上我的子路径就是我想要获取的网址啦哈哈哈哈!
首先,要利用xpath获取a标签里面的内容:
hrefList = browser.find_element_by_xpath('//*[@id="ec_table"]/tbody[1]/tr[1]/td[1]/a')
之后,获取onclick的内容:
subUrl = hrefList.get_attribute("onclick")
由于得出结果是:
subUrl = "ec.action='/easoa/modules/workflow/workflowFileinbox.do?method=show&id=4372892&isViewed=yes&viewId=4372892&formFlag=show&workflowsort=myDraft&searchId=';ec.submit();"
要得到子路径的话,可以根据符号 ’ 分割,所以,最后要:
subUrl = subUrl.split("\'")[1]
酱紫,最
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









