







redis网络层
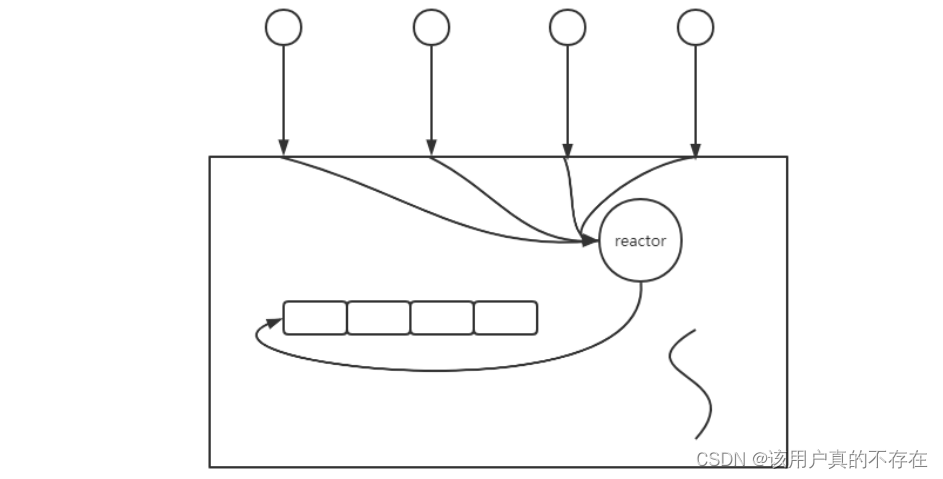
Redis使用单reactor的非阻塞I/O多路复用机制,采用单线程串行处理命令,且线程同时处理命令和网络IO。
串行:表现在单CPU上,多个线程排好队,依次执行。
并行:表现在多CPU上,每个CPU处理一个线程,多个线程可以同时执行同一段代码。
并发:表现在单CPU上:一个CPU交替执行多个线程;
表现在多CPU上:多个CPU处理多个线程,并行一定是并发。
redis pipeline
Redis 执行一条命令需要发送命令、命令排队、命令执行、结果响应四个步骤,而且Redis是基于 Request/Response协议(停等机制)的,客户端连接采用阻塞IO的方式,即:一个redis客户端连接,发出请求后,必须收到响应才能发起下一次请求。
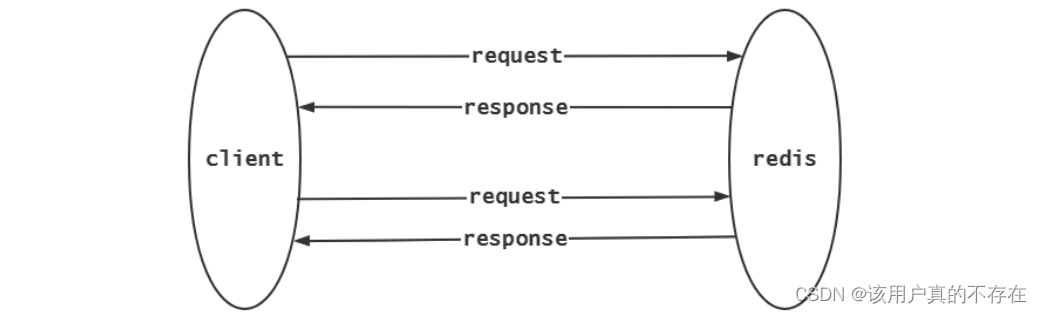
当需要批量处理命令的时候,使用上面的方式会极大降低效率。
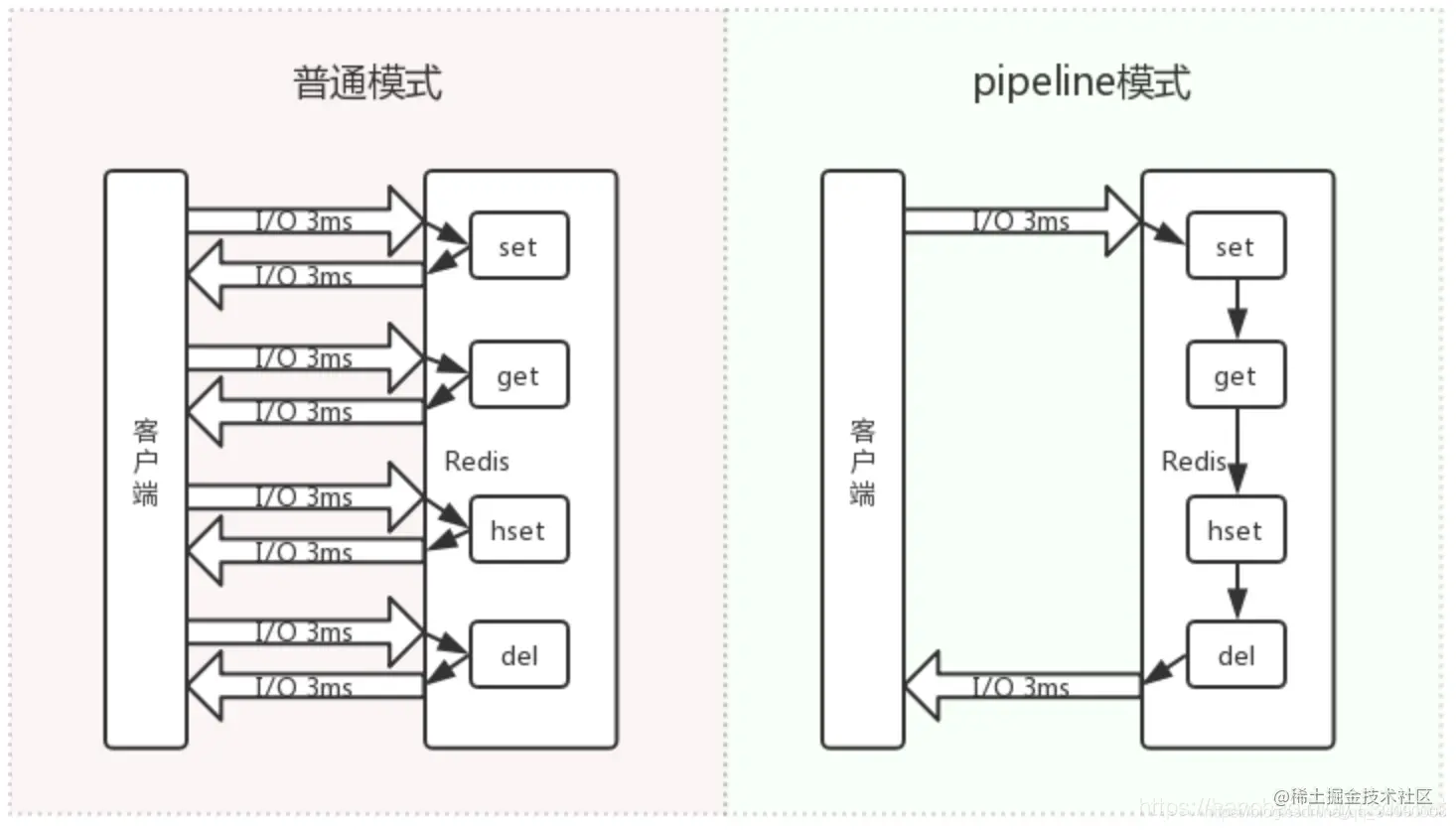
pipeline是由客户端提供的,它能将一组 Redis 命令进行组装,通过一次传输给 Redis 并返回结果集。如下是Redis批量处理命令的过程比对:
Redis pipeline注意点:
Pipeline是非原子的,在上面原理解析那里已经说了就是 Redis 实际上还是一条一条的执行的,而执行命令是需要排队执行的,所以就会出现原子性问题。Pipeline中包含的命令不要包含过多。Pipeline每次只能作用在一个 Redis 节点上。Pipeline不支持事务,因为命令是一条一条执行的。
redis事务
Redis的命令是原子性的,虽然Redis支持事务,但是redis 的事务是非原子性的。使用MULTI 开启事务,事务执行过程中,单个命令是入队列操作,直到调用 EXEC 才会一起执行。
Redis事务相关命令:
- MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
- EXEC:执行事务中的所有操作命令。必须与MULTI命令成对使用。
- DISCARD:取消事务,放弃执行事务块中的所有命令。
- WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
- UNWATCH:取消WATCH对所有key的监视。
Redis如何确保事务的原子性
Redis使用WATCH命令来决定事务是继续执行还是回滚,那就需要在MULTI之前使用WATCH来监控某些键值对,然后使用MULTI命令来开启事务,执行对数据结构操作的各种命令,此时这些命令入队列。
当使用EXEC执行事务时,首先会比对WATCH所监控的键值对,如果没发生改变,它会执行事务队列中的命令,提交事务;如果发生变化,将不会执行事务中的任何命令,同时事务回滚。当然无论是否回滚,Redis都会取消执行事务前的WATCH命令。
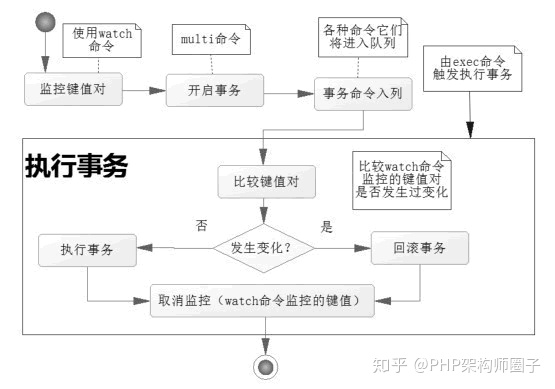
Redis执行事务
例子:事务实现 加倍操作
WATCH score:10001
val = GET score:10001
MULTI
SET score:10001 val*2
EXECRedis事务处理失败
Redis常见的事务失败是由语法错误或者数据结构类型错误导致的:
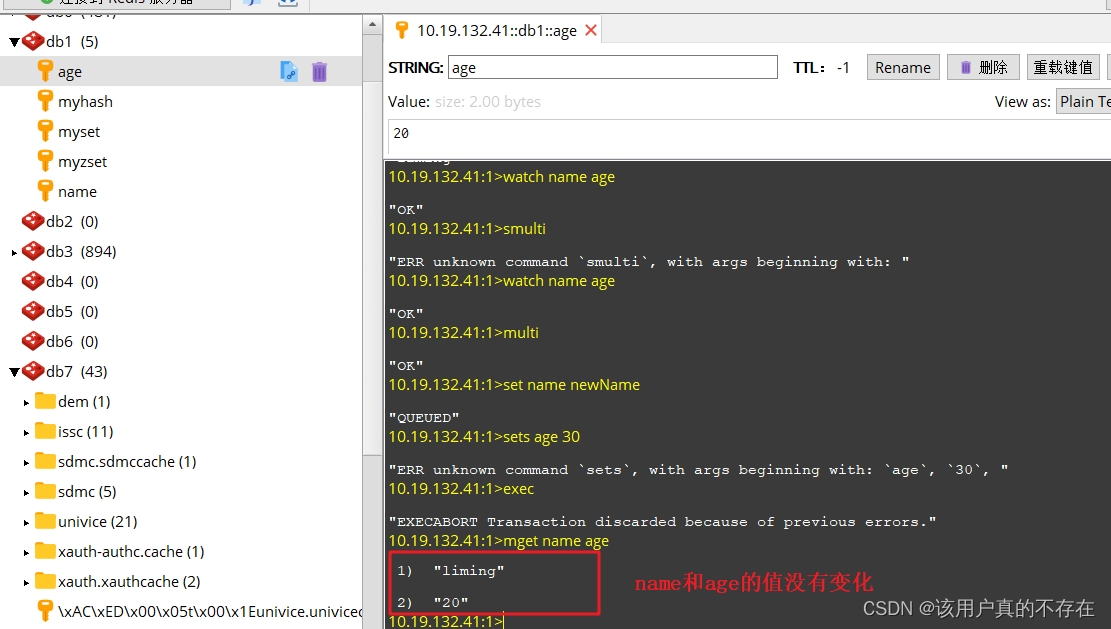
- 语法错误(编译器错误):在开启事务后,修改k1值为11,k2值为22,但k2语法错误,最终导致事务提交失败,k1、k2保留原值。
演示"语法错误"的事务执行结果:(结果表明k1、k2保留原值)
先令:
set name liming
set age 20然后按下图中的过程执行:
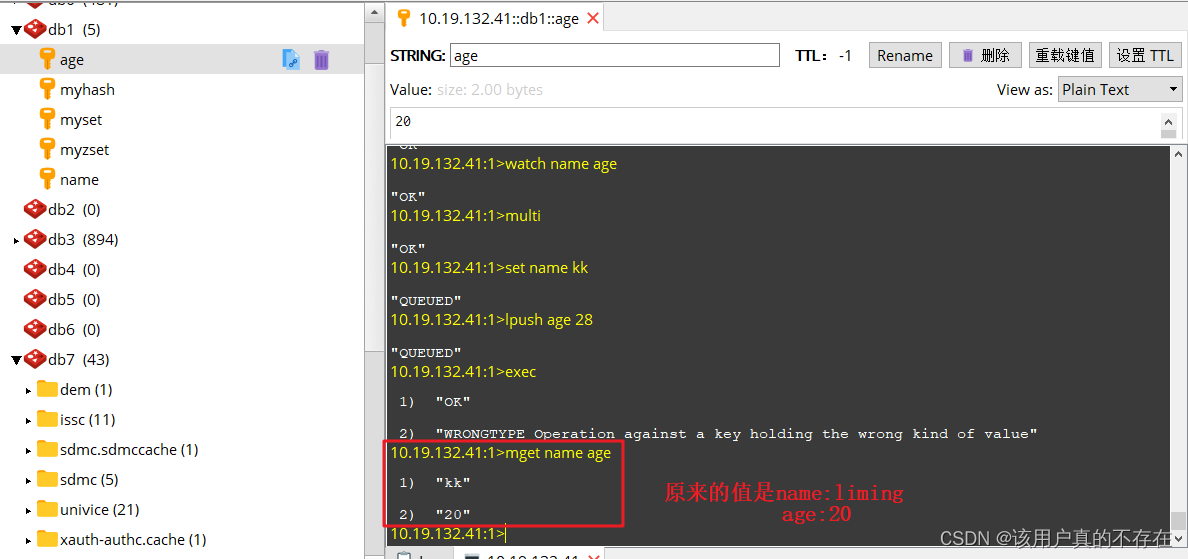
- 数据类型错误(运行时错误):在开启事务后,修改k1值为11,k2值为22,但将k2的类型作为List,在运行时检测类型错误,最终导致事务提交失败,此时事务并没有回滚,而是跳过错误命令继续执行, 结果k1值改变、k2保留原值。
演示"数据类型错误"的事务执行结果:(结果表明k1值被修改,k2保留原值)
先令:
set name liming
set age 20然后按下图中的过程执行:
语法错误说明在命令入队前就进行检测的,而类型错误是在执行时检测的,Redis为提升性能而采用这种简单的事务,这是不同于关系型数据库的,因此Redis不支持事务回滚。
lua 脚本
Redis还使用lua脚本实现了事务的原子性。如果项目中使用了lua脚本,不需要使用上面的事务命令。
Redis中加载了一个lua虚拟机;用来执行redis lua脚本;redis lua 脚本的执行是原子性的;当某个 脚本正在执行的时候,不会有其他命令或者脚本被执行;lua脚本当中的命令会直接修改数据状态;
Lua广泛作为其它语言的嵌入脚本,尤其是C/C++,语法简单,小巧,源码一共才200多K,这可能也是Redis官方选择它的原因。Nginx也支持Lua,利用Lua也可以实现很多有用的功能。
Lua 的简单语法
Lua在Redis脚本中我个人建议只需要使用下面这几种类型:
nil空boolean布尔值number数字string字符串table表
声明类型
--- 全局变量
name = 'felord.cn'
--- 局部变量
local age = 18Redis脚本在实践中不要使用全局变量,局部变量效率更高。
判断
local a = 10
if a < 10 then
print('a小于10')
elseif a < 20 then
print('a小于20,大于等于10')
else
print('a大于等于20')
endRedis中的Lua
EVAL命令
Redis中使用EVAL命令来直接执行指定的Lua脚本。通常在测试脚本的时候使用这种方式。
EVAL luascript numkeys key [key ...] arg [arg ...]
EVAL:命令的关键字。
luascript:Lua 脚本。
numkeys:指定的Lua脚本需要处理键的数量,其实就是 key数组的长度。
key:传递给Lua脚本零到多个键,空格隔开。在Lua 脚本中通过KEYS[INDEX]来获取对应的值,其中1 <= INDEX <= numkeys。
arg:传递给脚本的零到多个附加参数,空格隔开。在Lua脚本中通过ARGV[INDEX]来获取对应的值,其中1 <= INDEX <= numkeys。接下来我简单来演示获取键hello的值得简单脚本:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> EVAL "return redis.call('GET',KEYS[1])" 1 hello
"world"
127.0.0.1:6379> EVAL "return redis.call('GET','hello')" 0
"world"
从上面的演示代码中发现,KEYS[1]可以直接替换为hello,但是Redis官方文档指出这种是不建议的。
numkeys无论什么情况下都是必须的命令参数。EVALSHA命令
Redis还提供了evalsha命令来执行Lua脚本,首先要把Lua脚本加载到redis服务端,得到该脚本的sha1校验码,evalsha命令使用sha1作为参数直接执行缓存在服务器中对应的Lua脚本。这样避免了每次发送Lua脚本的开销,客户端就不需要每次执行脚本内容,而脚本也会常驻在服务端,脚本功能得到了复用。
将脚本缓存到服务器的操作可以通过 SCRIPT LOAD 命令进行。
127.0.0.1:6379> EVALSHA sha1 numkeys key [key ...] arg [arg ...]
sha1 : 通过 SCRIPT LOAD 生成的 sha1 校验码。
numkeys: 用于指定键名参数的个数。
key [key ...]: 跟EVAL执行时的参数key一样
arg [arg ...]: 跟EVAL执行时的参数arg一样使用示例如下:
10.19.132.41:1>script load 'local val = KEYS[1]; return val'
"0eed5a3c55921764489eb93f0e1f978c3c28f394"
10.19.132.41:1>evalsha "0eed5a3c55921764489eb93f0e1f978c3c28f394" 1 kkkkkk
"kkkkkk"call函数和pcall函数
在上面的例子中我们通过redis.call()来执行了一个SET命令,其实我们也可以替换为redis.pcall()。它们唯一的区别就在于处理错误的方式。
值转换
由于在Redis中存在Redis和Lua两种不同的运行环境,在Redis和Lua互相传递数据时必然发生对应的转换操作,这种转换操作是我们在实践中不能忽略的。例如如果Lua脚本向Redis返回小数,那么会损失小数精度;如果转换为字符串则是安全的。
127.0.0.1:6379> EVAL "return 3.14" 0
(integer) 3
127.0.0.1:6379> EVAL "return tostring(3.14)" 0
"3.14"
原子执行
Lua脚本在Redis中是以原子方式执行的,在Redis服务器执行EVAL命令时,在命令执行完毕并向调用者返回结果之前,只会执行当前命令指定的Lua脚本包含的所有逻辑,其它客户端发送的命令将被阻塞,直到EVAL命令执行完毕为止。因此LUA脚本不宜编写一些过于复杂了逻辑,必须尽量保证Lua脚本的效率,否则会影响其它客户端。如果lua脚本内成功执行部分命令后就失败了退出了,则成功执行的命令对数据的修改会被保留下来。
脚本管理
SCRIPT LOAD:加载脚本到缓存以达到重复使用,避免多次加载浪费带宽,每一个脚本都会通过SHA校验返回唯一字符串标识。需要配合EVALSHA命令来执行缓存后的脚本。
127.0.0.1:6379> SCRIPT LOAD "return 'hello'"
"1b936e3fe509bcbc9cd0664897bbe8fd0cac101b"
127.0.0.1:6379> EVALSHA 1b936e3fe509bcbc9cd0664897bbe8fd0cac101b 0
"hello"
SCRIPT FLUSH:既然有缓存就有清除缓存,但是遗憾的是并没有根据SHA来删除脚本缓存,而是清除所有的脚本缓存,所以在生产中一般不会再生产过程中使用该命令。
SCRIPT EXISTS:以SHA标识为参数检查一个或者多个缓存是否存在。
127.0.0.1:6379> SCRIPT EXISTS 1b936e3fe509bcbc9cd0664897bbe8fd0cac101b 1b936e3fe509bcbc9cd0664897bbe8fd0cac1012
1) (integer) 1
2) (integer) 0
SCRIPT KILL:终止正在执行的脚本。但是为了数据的完整性此命令并不能保证一定能终止成功。如果当一个脚本执行了一部分写的逻辑而需要被终止时,该命令是不凑效的。需要执行SHUTDOWN nosave在不对数据执行持久化的情况下终止服务器来完成终止脚本。
使用lua脚本的注意事项:
- 在Lua脚本中不要编写
function函数,整个脚本作为一个函数的函数体。 - 在脚本编写中声明的变量全部使用
local关键字。 - 在集群中使用Lua脚本要确保逻辑中所有的
key分到相同机器,也就是同一个插槽(slot)中,可采用Redis Hash Tag技术。
ACID特性分析
- A 原子性:事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。redis 不支持回滚;即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止。
- C 一致性:事务使数据库从一个一致性状态到另外一个一致性状态。这里的一致性是指预期的一 致性而不是异常后的一致性;所以redis也不满足;
- I 隔离性:事务的操作不被其他用户操作所打断。redis命令执行是串行的,redis事务天然具备隔离性;
- D 持久性:redis只有在 aof 持久化策略的时候,并且需要在 redis.conf 中 appendfsync=always 才具备持久性;实际项目中几乎不会使用 aof 持久化策略;
redis 发布订阅
redis发布订阅(pub/sub)是一种消息通信模式 ,消息的发布者不会将消息发送给特定的订阅者,而是通过消息通道(频道)广播出去,让订阅该消息主题(频道)的订阅者消费。发布/订阅模式的最大特点是利用消息中间件,实现解耦。
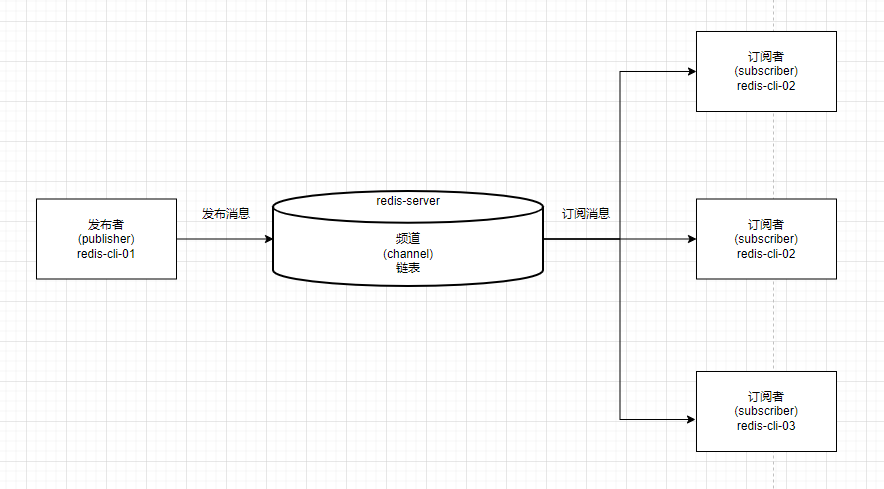
redis的发布订阅又分为两类:
- 频道的发布订阅
- 模式的发布订阅
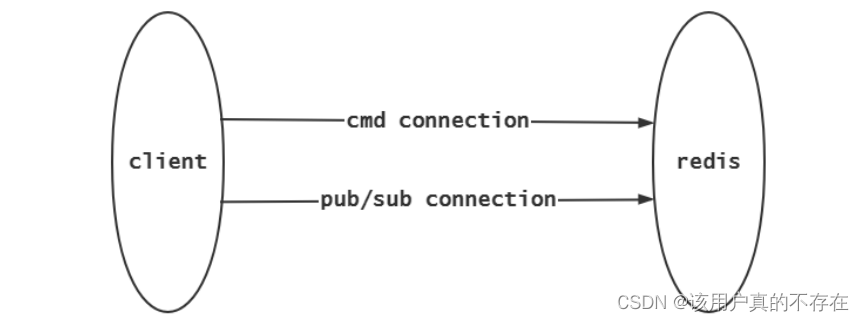
当使用发布订阅功能时需要重启开启一个连接,而非使用命令连接:因为命令连接严格遵循请求回应模式;而发布订阅连接需要一直接收redis主动推送的内容。所以实际项目中如果支持pubsub的话,需要另开一条连接用于处理发布订阅:
频道的发布订阅(subscribe/publish)
1、使用subscribe命令指定当前客户端订阅频道,一个订阅者可以订阅多个频道,若该频道不存在则会创建。
语法:
subscribe channel channel2 : 订阅一个或多个频道
测试:
10.19.132.41:0>subscribe shen-channel1 shen-channel2
Switch to Pub/Sub mode. Close console tab to stop listen for messages.
1) "subscribe" --返回值类型:订阅者
2) "shen-channel1" --订阅频道名称
3) "1" --订阅成功与否 2、使用publish命令指定当前客户端向某个频道发布消息。
语法:
publish channel message : 向channel频道发送message消息
测试:
10.19.132.41:0>publish shen-channel1 11
"1" --接收到此消息的订阅者数量,无订阅者返回0
10.19.132.41:0>publish shen-channel2 helloworld
"1"
3、当发布者发送消息后,订阅者会接收到消息
1) "message" --返回值类型:消息
2) "shen-channel1" --接收的频道名
3) "11" --消息内容
1) "message"
2) "shen-channel2"
3) "helloworld"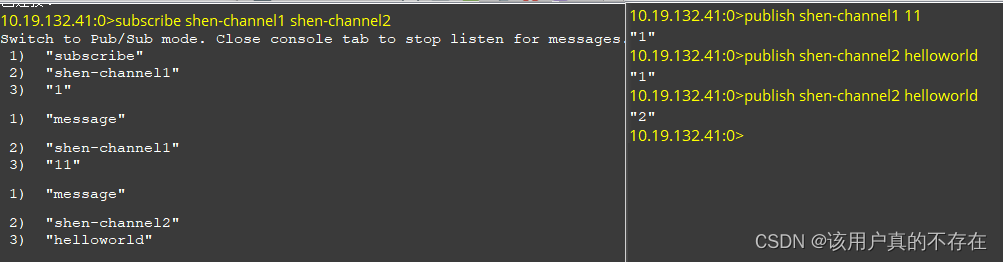
4、使用pubsub命令可以查看频道的基本信息
语法:
pubsub channels : 查看当前存在的所有频道
pubsub numsub channel : 查看指定频道的订阅者数量
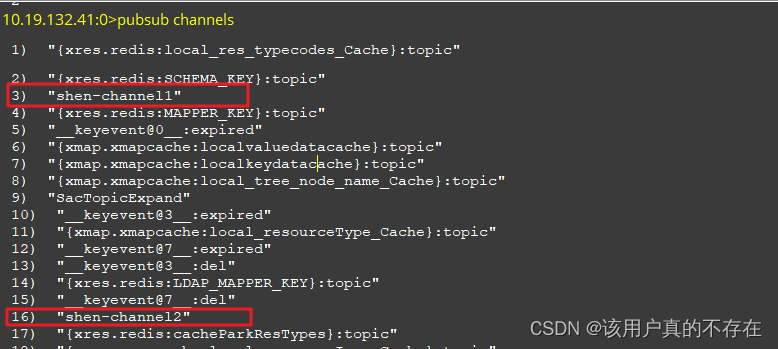

5、使用unsubscribe命令可以指定当前客户端退订1个或多个频道
语法:
unsubscribe channel1 channel2 :退订频道
测试:
10.19.132.41:0>unsubscribe shen-channel1
1) "unsubscribe" --返回类型:退订
2) "shen-channel" --退订的频道名
3) (integer) 1
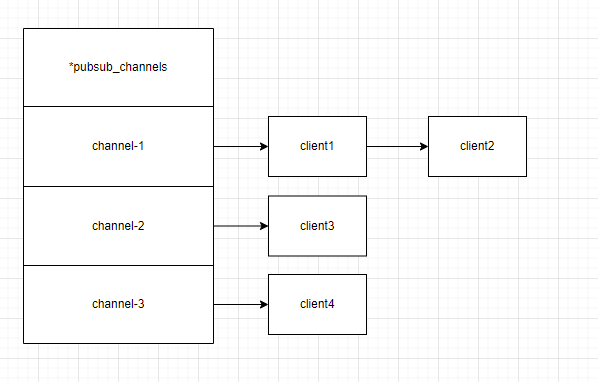
实现原理
在redisServer中有一个字典类型字段叫pubsub_channels,用来保存订阅信息,key为频道,value为订阅该频道的客户端:
struct redisServer{
pid_t pid;
//...
// 保存所有频道订阅关系
dict *pubsub_channels;
//...
}
模式的发布订阅(psubscribe/publish)
1、使用psubscribe命令进行模式订阅
语法:
psubscribe pattern-1 pattern-2 :订阅1个或多个模式频道
测试:
10.19.132.41:0>psubscribe shen*
Switch to Pub/Sub mode. Close console tab to stop listen for messages.
1) "psubscribe" --返回类型:模式订阅
2) "shen*" --订阅模式名称 shenxxx
3) "1" --订阅成功与否
2、仍然使用publish命令指定当前客户端向某个频道发布消息
10.19.132.41:0>publish shen-channel2 helloworld
"3"3、当发布者发送消息后,订阅者会接收到消息
1) "pmessage"
2) "shen*"
3) "shen-channel2"
4) "helloworld"4、使用punsubscribe命令可以指定当前客户端退订1个或多个模式
语法:
punsubscribe pattern-1 pattern-2 : 退订1个或多个模式频道
测试:
10.19.132.41:0>punsubscribe shen*
1) "punsubscribe"
2) "shen*"
3) "0"
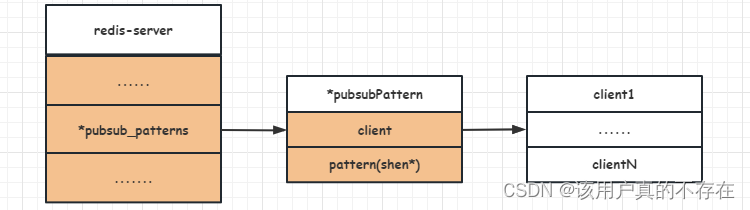
实现原理
在redisServer中有一个链表字段叫pubsub_patterns,该链表保存着所有和模式相关的信息
struct redisServer {
//...
list *pubsub_patterns;
// ...
}
typedef struct pubsubPattern {
client *client; -- 订阅模式客户端
robj *pattern; -- 被订阅的模式
} pubsubPattern;
Redis发布订阅的缺点
发布订阅的生产者传递过来一个消息,redis会直接找到相应的消费者并传递过去;假如没有消费者,消息直接丢弃;假如开始有2个消费者,一个消费者突然挂掉了,另外一个消费者依然能收到 消息,但是如果刚挂掉的消费者重新连上后,在断开连接期间的消息对于该消费者来说彻底丢失 了;
总结:
- 发布者发布消息,却订阅者,则消息直接丢弃
- 订阅者中途断开连接,重连后也无法收到断开连接期间的消息
- redis重启后,所有的消息会被直接丢弃
应用场景
1、解耦多个应用服务,如聊天室
2、Redisson的分布式锁的实现就采用了发布订阅模式:获取锁时,若获取不成功则订阅释放锁的消息,在收到释放锁的消息前阻塞,收到释放锁的消息后再去循环获取锁。
3、异步处理:采用Redis的发布订阅模式来实现异步处理,从而提高并发量。如:秒杀功能可以这样做:
1、秒杀之前,将产品的库存从数据库同步到Redis
2、秒杀时,通过lua脚本保证原子性
(1)扣减库存
(2)将订单数据通过Redis的发布订阅功能发布出去
(3)返回1(表示成功)redis异步连接
RESP(Redis序列化协议)
Redis底层使用的通信协议是RESP(Redis Serialization Protocol的缩写),RESP协议实际上是一个支持以下数据类型的序列化协议:Simple Strings(简单字符串),Errors(错误),Integers(整形),Bulk Strings(块字符串)和Arrays(数组),但此协议只适用于Redis客户端-服务端之间的通信,Redis集群中节点间通信使用的另一种协议。
数据类型前缀
在RESP协议中,每种数据数据类型都有固定的前缀,每一部分都以\r\n结尾
- + 代表简单字符串回复(Simple Strings)比如OK,PONG(对应客户端的PING命令)
- - 代表错误回复(Errors)
- : 代表整数回复(Integers)
- $ 代表批量字符串(Bulk Strings)
- * 代表数组(Arrays)
在Redis中,RESP用作 请求-响应 协议的方式如下:
1、客户端将命令作为批量字符串的RESP数组发送到Redis服务器。
2、服务器(Server)根据命令执行的情况返回一个具体的RESP类型作为回复。
例如:
客户端执行set name liming命令,客户端会将其序列化为:
*3\r\n$3\r\nset\r\n$4\r\nname\r\n$6\r\nliming\r\n
解释:
*3:表示长度为3的数组
\r\n:特殊分隔符
$3:set的长度
$4:name的长度服务端收到请求进行处理后,返回的响应是:
+OK\r\n简单字符串和批量字符串的区别:简单字符串一般是服务器状态相关,比如'OK'、‘PONG’等;而Bulk Strings可以包含任何内容(比如换行符、控制符)
异步连接
同步和异步的优缺点
同步连接方案采用阻塞io来实现;优点是代码书写是同步的,业务逻辑没有割裂;缺点是阻塞当前线程,直至redis返回结果;通常用多个线程来实现线程池来解决效率问题;
异步连接方案采用非阻塞io来实现;优点是没有阻塞当前线程,redis没有返回,依然可以往redis 发送命令;缺点是代码书写是异步的(回调函数),业务逻辑割裂,可以通过协程解决 (openresty,skynet);配合redis6.0以后的io多线程(前提是有大量并发请求),异步连接池,能更好解决应用层的数据访问性能;
说明:redis6.0版本后添加的 io多线程主要解决redis协议的压缩以及解压缩的耗时问题;一般项目中不 需要开启;如果有大量并发请求,且返回数据包一般比较大的场景才有它的用武之地;
实现方案
参考文献:

















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









