







 超级会员免费看
超级会员免费看
 本文介绍了Hive分区表的概念及其优势。通过`partitioned by`关键字创建分区表,数据按照子目录存储,提高查询效率。示例展示了如何导入数据到不同分区并进行指定分区查询,以实现快速定位数据。
本文介绍了Hive分区表的概念及其优势。通过`partitioned by`关键字创建分区表,数据按照子目录存储,提高查询效率。示例展示了如何导入数据到不同分区并进行指定分区查询,以实现快速定位数据。
分区关键字 partitioned by
分区就是表目录中的一个子目录,我们的数据可以分子目录存放。查询的时候也可以按子目录查询
create table t_day(ip string,url string,staylong int)
partitioned by (day string)
row format delimited
fields terminated by ',';我们先造一下数据(赋值的快捷键:yy + p)然后再复制一份
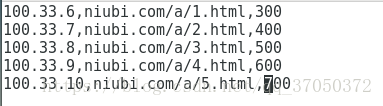
导入数到不同的分区目录:
load data local inpath '/root/web.log.1' into table t_day partition(day='2018-08-20');
load data local inpath '/root/web.log.2' into table t_day partition(day='2018-08-21');查询一下:

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











