




 论文提出了一种方法来过滤Visual Genome数据集中视觉不相关的关系样本,创建了VrR-VG数据集,挑战了仅依赖统计的视觉关系检测。通过visually-relevant relationship discriminator,过滤掉可通过非视觉信息预测的关系,使得数据更加聚焦于真正的视觉关系,推动了高阶图像理解的研究。
论文提出了一种方法来过滤Visual Genome数据集中视觉不相关的关系样本,创建了VrR-VG数据集,挑战了仅依赖统计的视觉关系检测。通过visually-relevant relationship discriminator,过滤掉可通过非视觉信息预测的关系,使得数据更加聚焦于真正的视觉关系,推动了高阶图像理解的研究。
VrR-VG
文章
本文想解决的问题是,对于视觉关系检测这一任务来说,在目前常用的权威数据集Visual Genome的一个子集VG150(VG中出现频率最高的150类物体和50类关系)上,直接可以依赖统计的方法解决得比较好,这不利于关系检测的进一步研究,因此文章设计了一个网络可以滤除掉VG数据集中那些视觉无关(visually-irrelevant)的关系样本。在新的数据集上,基于频率的方法不再有效。
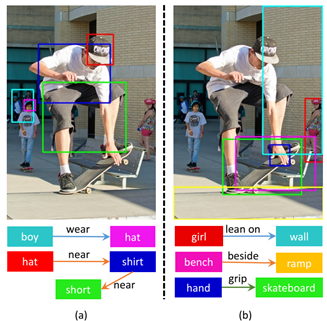
如上图(a)就是VG150中的一个场景图描述,(b)则是本文的的方法对VG清洗之后留下的场景图描述(Visually-relevant Relationships in Visual Genome,VrR-VG)。其实我们也可以大概看出来,(b)的话更难使用频率进行关系类别的判断。
为了滤除掉视觉不相关的关系样本,本文设计了一个visually-relevant relationship discriminator,思想就是“如果一个关系样本,在利用除视觉信息以外的特征,如物体类别和边界框位置就能较好地预测得话,那么这个样本就是视觉不相关的。”下面是本文的discriminator的结构
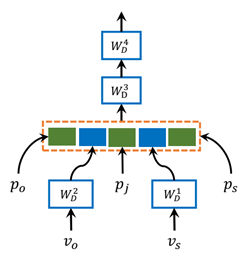
输入是主语和宾语的类别词向量和边界框的信息,p_o和p_s是主语和宾语边界框的(x,y,w,h),p_j则是两个框的一些相对位置信息如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









