




 该论文提出了一种基于组合学习的方法,用于解决人类对象交互(HOI)识别中的零样本学习问题。作者利用图卷积网络(GCN)捕捉动作的组合性质,并结合词嵌入来表示动词和名词,从而识别未在数据集中出现过的交互。实验表明,这种方法能够处理新组合,但与其他竞争方法相比,性能提升有限。
该论文提出了一种基于组合学习的方法,用于解决人类对象交互(HOI)识别中的零样本学习问题。作者利用图卷积网络(GCN)捕捉动作的组合性质,并结合词嵌入来表示动词和名词,从而识别未在数据集中出现过的交互。实验表明,这种方法能够处理新组合,但与其他竞争方法相比,性能提升有限。
Compositional Learning for HOI(ECCV 2018)
文章
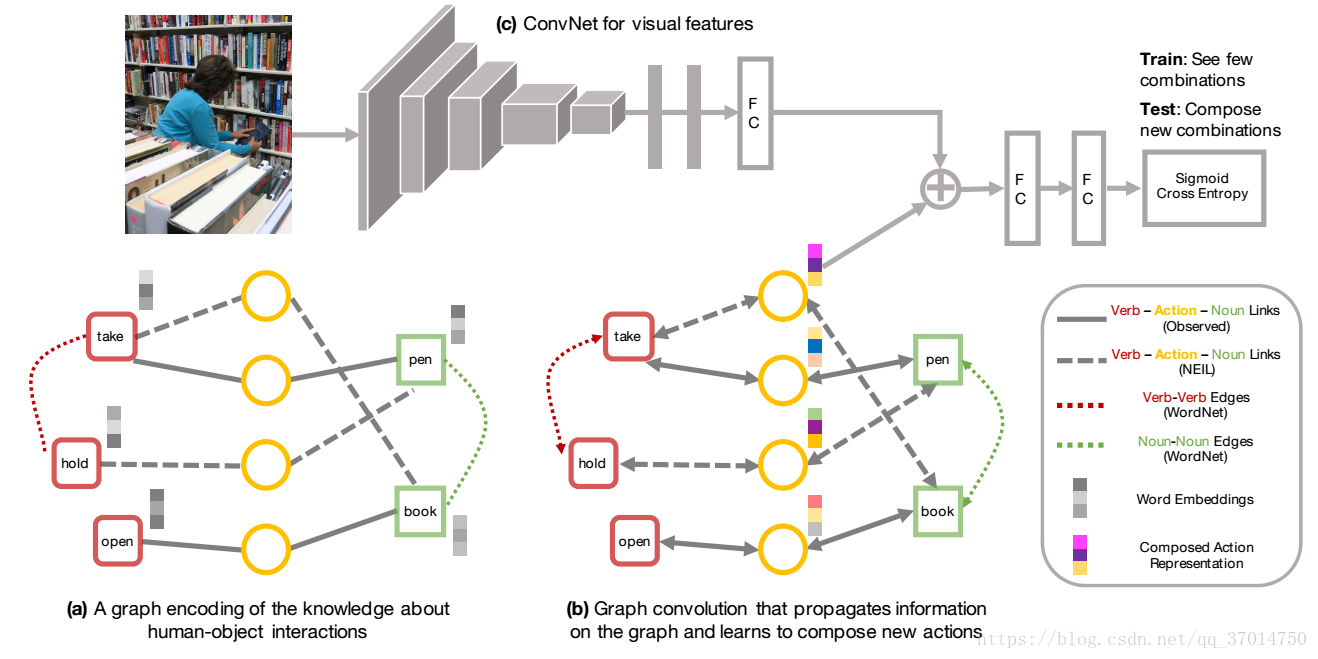
作者的的想法是因为我们很难搜集到所有组合之间的interaction,所以必须会面临的问题就是要识别在数据集中从未见到过的情况,也就是HOI的zero shot learning。作者认为人的动作是具有compositional的性质的,而且人可以用不同的物体和工具达到类似的目的。比如我们可以用hammer去hit the nail,同样也可以用hard-cover book做相同的事情。因此作者考虑可以使用这种unique composition帮助实现新的动作。
但是这种compositional的学习面临的一个主要的问题是:模型怎样可以学会在context中组合出新的动作。
作者使用下面a中的graph来表示interaction。verb和noun通过圆形的action节点相连接,然后会存在某些verb-verb连接和noun-noun连接,我想这种连接应该是代表了某种相似性和可迁移的特性。
首先,从知识库中提取出subject-verb-object(SVO)triplets建立一个外部的知识图。这个图覆盖了大部分的HOI,其中每个verb和noun节点都以其word embedding作为这个节点的特征。
对于一张图片,将其visual特征记作x,其中的HOI记作y,而y又可以分解为一个verb和一个noun,分别记作 和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









