







目录
一、RDD简介
1、RDD定义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,形式上它一个不可变、可分区、里面的元素可并行计算的集合。
RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
2、RDD属性
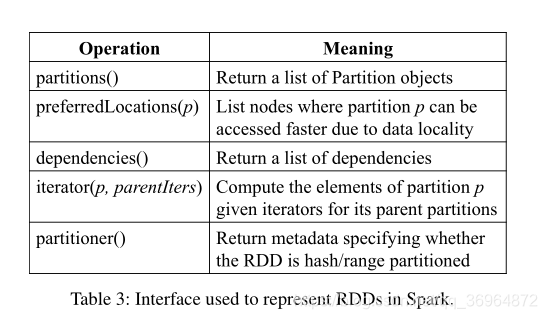
/*
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file)
*
* All of the scheduling and execution in Spark is done based on these methods, allowing each RDD
* to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for
* reading data from a new storage system) by overriding these functions.
*/- 分区列表(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
- 分区计算函数(一个用于计算每个分区的函数)。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
- RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。RDDs不需要在任何时候都具体化。相反,RDD有足够的信息来说明它是如何从其他数据集(它的谱系)派生出来的,以便从稳定存储中的数据计算分区。这是一个强大的属性:从本质上讲,程序不能引用在失败后不能重新构建的RDD。
- (可选)一个Partitioner,即RDD的分区器。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了Parent RDD Shuffle输出时的分片数量。
- (可选的)首选位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
3、RDD模型的优势
DSM即Distributed Shared-Memory
| 操作/方面 | RDDs | DSM |
| 读 | 粗/细粒度 | 细粒度 |
| 写 | 粗粒度 | 细粒度 |
| 一致性 | 不重要(不可变) | 应用到程序/实时的 |
| 错误恢复 | ·使用“血统”进行细粒度且低代价的故障恢复 | 需要检查点和回滚 |
| Straggler mitigation | 可以使用后台进程 | 较难实现 |
| Work placement | 自动根据数据的本地性进行操作 | 到应用程序(运行时的目标是透明) |
| 内存不足 | 类似于现有的数据流系统 | 表现不佳 |
二、RDD的执行原理
Spark框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD是Spark框架中用于数据处理的核心模型,以在Yarn环境下为例,RDD的工作原理包括:
1、启动Yarn进群环境
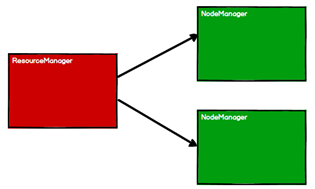
2、Spark通过申请资源创建调度节点和计算节点
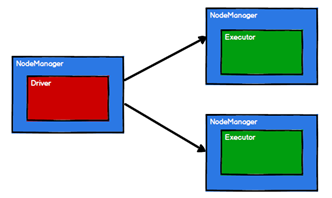
3、Spark框架根据不同的需求将计算逻辑划分成不同的任务
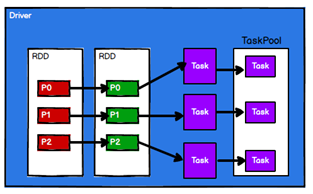
4、调度节点将任务根据节点状态发送到对应的计算节点机型计算
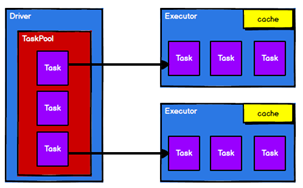
RDD的主要作用就是进行逻辑的封装,然后生成Task分发到各个Executor上进行计算。
三、RDD的算子
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作(tansformation)。只有当发生一个要求返回结果给Driver的动作(Action)时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
四、RDD创建方式
RDD的创建主要有两种方式:一种是根据已有的Scala集合(parallelize、makeRDD)进行创建,另一种时由外部存储的数据文件(textFile)创建,包括本地文件系统还有所有Hadoop支持的数据形式,如HDFS、HBase等,从其他的RDD进行创建。
其中makeRDD方法其实就是parallize方法
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
Transformation操作
| 转换 | 含义 |
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) |
|
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
| cartesian(otherDataset) | 笛卡尔积 |
| pipe(command, [envVars]) |
|
| coalesce(numPartitions) |
|
| repartition(numPartitions) |
|
| repartitionAndSortWithinPartitions(partitioner) |
|
| 动作 | 含义 |
| reduce(func) | 通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) |
|
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) |
|
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func进行更新。 |
mapPartitionsWithIndex
val func = (index: Int, iter: Iterator[(String)]) => {
iter.map(x => "[partID:" + index + ", val: " + x + "]")
}
mapPartitionsWithIndex
val func = (index: Int, iter: Iterator[Int]) => {
iter.map(x => "[partID:" + index + ", val: " + x + "]")
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func).collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
aggregate
def func1(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func1).collect
rdd1.aggregate(0)(math.max(_, _), _ + _)
rdd1.aggregate(5)(math.max(_, _), _ + _)
val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)
def func2(index: Int, iter: Iterator[(String)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
rdd2.aggregate("")(_ + _, _ + _)
rdd2.aggregate("=")(_ + _, _ + _)
val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
rdd3.aggregate("")((x,y) => math.max(x.length, y.length).toString, (x,y) => x + y)
val rdd4 = sc.parallelize(List("12","23","345",""),2)
rdd4.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
val rdd5 = sc.parallelize(List("12","23","","345"),2)
rdd5.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
aggregateByKey
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.map(x => "[partID:" + index + ", val: " + x + "]")
}
pairRDD.mapPartitionsWithIndex(func2).collect
pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
checkpoint
sc.setCheckpointDir("hdfs://node-1.edu360.cn:9000/ck")
val rdd = sc.textFile("hdfs://node-1.edu360.cn:9000/wc").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
rdd.checkpoint
rdd.isCheckpointed
rdd.count
rdd.isCheckpointed
rdd.getCheckpointFile
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
coalesce, repartition
val rdd1 = sc.parallelize(1 to 10, 10)
val rdd2 = rdd1.coalesce(2, false)
rdd2.partitions.length
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
collectAsMap
val rdd = sc.parallelize(List(("a", 1), ("b", 2)))
rdd.collectAsMap
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
combineByKey
val rdd1 = sc.textFile("hdfs://node-1.edu360.cn:9000/wc").flatMap(_.split(" ")).map((_, 1))
val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
rdd2.collect
val rdd3 = rdd1.combineByKey(x => x + 10, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
rdd3.collect
val rdd4 = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val rdd5 = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
val rdd6 = rdd5.zip(rdd4)
val rdd7 = rdd6.combineByKey(List(_), (x: List[String], y: String) => x :+ y, (m: List[String], n: List[String]) => m ++ n)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
countByKey
val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))
rdd1.countByKey
rdd1.countByValue
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
filterByRange
val rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1)))
val rdd2 = rdd1.filterByRange("b", "d")
rdd2.colllect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
flatMapValues
val a = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))
rdd3.flatMapValues(_.split(" "))
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
foldByKey
val rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
val rdd3 = rdd2.foldByKey("")(_+_)
val rdd = sc.textFile("hdfs://node-1.edu360.cn:9000/wc").flatMap(_.split(" ")).map((_, 1))
rdd.foldByKey(0)(_+_)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
foreachPartition
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.foreachPartition(x => println(x.reduce(_ + _)))
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
keyBy
val rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val rdd2 = rdd1.keyBy(_.length)
rdd2.collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
keys values
val rdd1 = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
rdd2.keys.collect
rdd2.values.collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
mapPartitions( it: Iterator => {it.map(x => x * 10)})#常用Transformation(即转换,延迟加载)
#通过并行化scala集合创建RDD
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
#查看该rdd的分区数量
rdd1.partitions.length
val rdd1 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10))
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x,true)
val rdd3 = rdd2.filter(_>10)
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x+"",true)
val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x.toString,true)
val rdd4 = sc.parallelize(Array("a b c", "d e f", "h i j"))
rdd4.flatMap(_.split(' ')).collect
val rdd5 = sc.parallelize(List(List("a b c", "a b b"),List("e f g", "a f g"), List("h i j", "a a b")))
List("a b c", "a b b") =List("a","b",))
rdd5.flatMap(_.flatMap(_.split(" "))).collect
#union求并集,注意类型要一致
val rdd6 = sc.parallelize(List(5,6,4,7))
val rdd7 = sc.parallelize(List(1,2,3,4))
val rdd8 = rdd6.union(rdd7)
rdd8.distinct.sortBy(x=>x).collect
#intersection求交集
val rdd9 = rdd6.intersection(rdd7)
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 2), ("kitty", 3)))
val rdd2 = sc.parallelize(List(("jerry", 9), ("tom", 8), ("shuke", 7), ("tom", 2)))
#join
val rdd3 = rdd1.join(rdd2)
val rdd3 = rdd1.leftOuterJoin(rdd2)
val rdd3 = rdd1.rightOuterJoin(rdd2)
#groupByKey
val rdd3 = rdd1 union rdd2
rdd3.groupByKey
//(tom,CompactBuffer(1, 8, 2))
rdd3.groupByKey.map(x=>(x._1,x._2.sum))
groupByKey.mapValues(_.sum).collect
Array((tom,CompactBuffer(1, 8, 2)), (jerry,CompactBuffer(9, 2)), (shuke,CompactBuffer(7)), (kitty,CompactBuffer(3)))
#WordCount
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).groupByKey.map(t=>(t._1, t._2.sum)).collect
#cogroup
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
val rdd3 = rdd1.cogroup(rdd2)
val rdd4 = rdd3.map(t=>(t._1, t._2._1.sum + t._2._2.sum))
#cartesian笛卡尔积
val rdd1 = sc.parallelize(List("tom", "jerry"))
val rdd2 = sc.parallelize(List("tom", "kitty", "shuke"))
val rdd3 = rdd1.cartesian(rdd2)
###################################################################################################
#spark action
val rdd1 = sc.parallelize(List(1,2,3,4,5), 2)
#collect
rdd1.collect
#reduce
val r = rdd1.reduce(_+_)
#count
rdd1.count
#top
rdd1.top(2)
#take
rdd1.take(2)
#first(similer to take(1))
rdd1.first
#takeOrdered
rdd1.takeOrdered(3)
10/26
cache方法,没有生成新的RDD,也没有触发任务执行,只会标记该RDD分区对应的数据(第一次触发Action时)放入到内存
checkpoint方法,没有生成新的RDD,也是没有触发Action,也是标记以后触发Action时会将数据保存到HDFS中
广播变量 broadCast: 广播出去的内容,无法再改变。如果需要实时改变的规则,可以将规则放在Redis
action:foreach、forachPartitions,会触发任务提交runJob方法
10/28
闭包:在一个函数内引用函数之外的变量
关于Spark的难点之一是在跨集群执行代码时理解变量和方法的作用域和生命周期。在其作用域之外修改变量的RDD操作经常会造成混淆。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









