







 本文讲述了如何在拉勾网反爬策略增强的背景下,通过分析接口、使用Chrome抓包工具,以及利用requests.Session()处理cookie,成功爬取Python职位信息的过程。强调了在爬取过程中需要注意的反爬策略,如设置延时和正确处理cookie,以及如何获取职位详情页的方法。
本文讲述了如何在拉勾网反爬策略增强的背景下,通过分析接口、使用Chrome抓包工具,以及利用requests.Session()处理cookie,成功爬取Python职位信息的过程。强调了在爬取过程中需要注意的反爬策略,如设置延时和正确处理cookie,以及如何获取职位详情页的方法。
学习爬虫时看的是几年前的教程,那个教程是举的一个例子就是爬取拉勾网的职位信息,但是由于这几年的反爬技术提高,拉勾网已经不能按照以前那么简单的爬了,研究了一下,终于可以爬到拉钩网的数据了。
首先我们打开拉勾网的网页 https://www.lagou.com/ 然后搜索python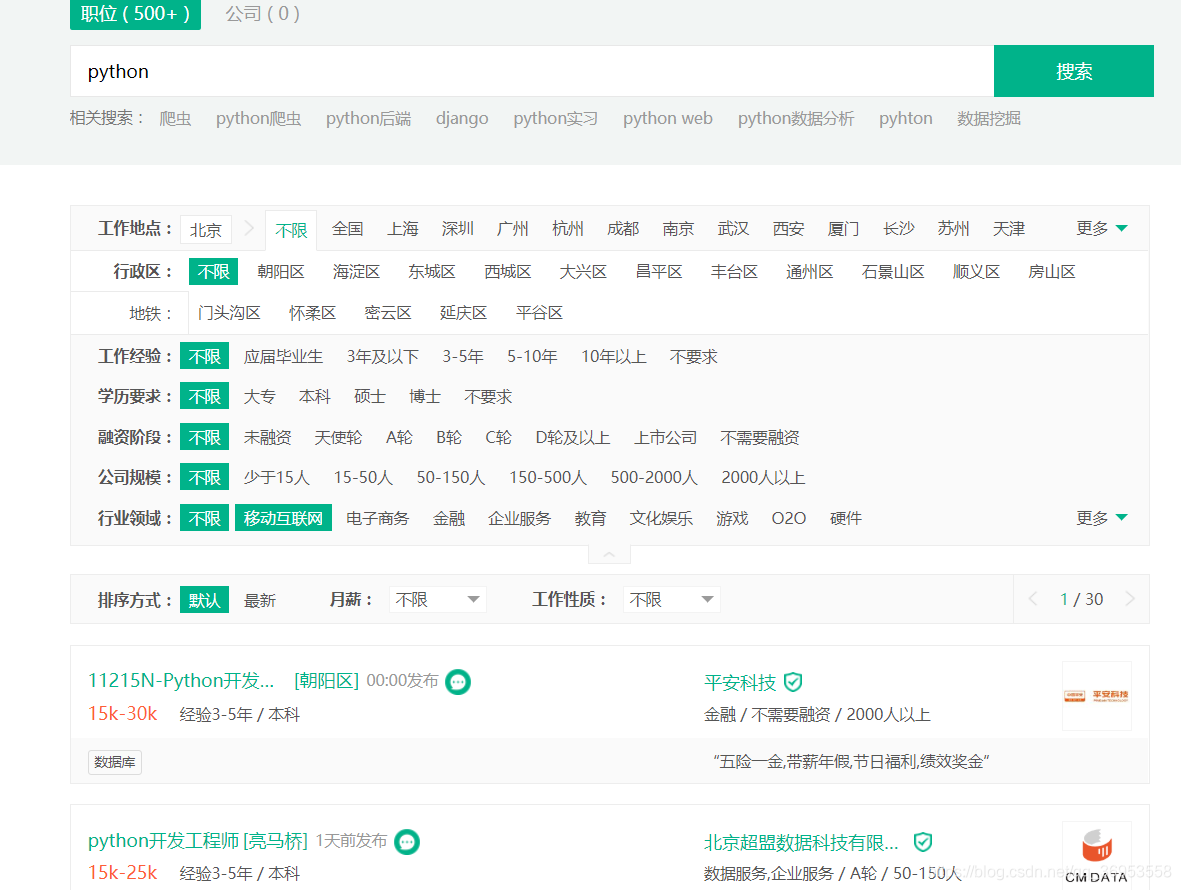
打开chrome的抓包工具 f5刷新下网页,可以看到第一个就是返回的html 但是里面却没有职位的信息。
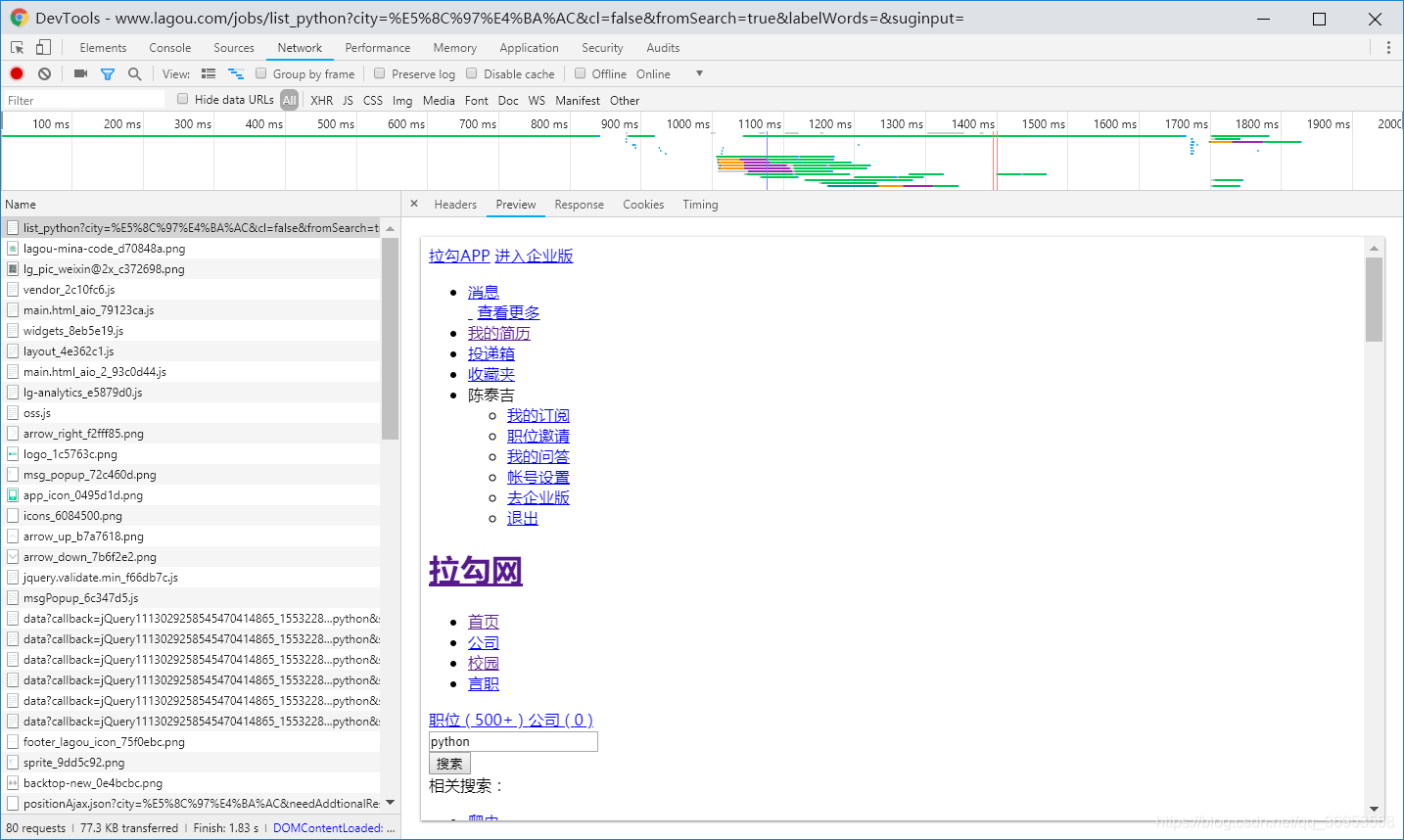 原来拉勾网的职位信息是通过ajax动态加载的 我们在抓包工具里找到ajax的包,根据名字我们可以很容易的找到那个包
原来拉勾网的职位信息是通过ajax动态加载的 我们在抓包工具里找到ajax的包,根据名字我们可以很容易的找到那个包
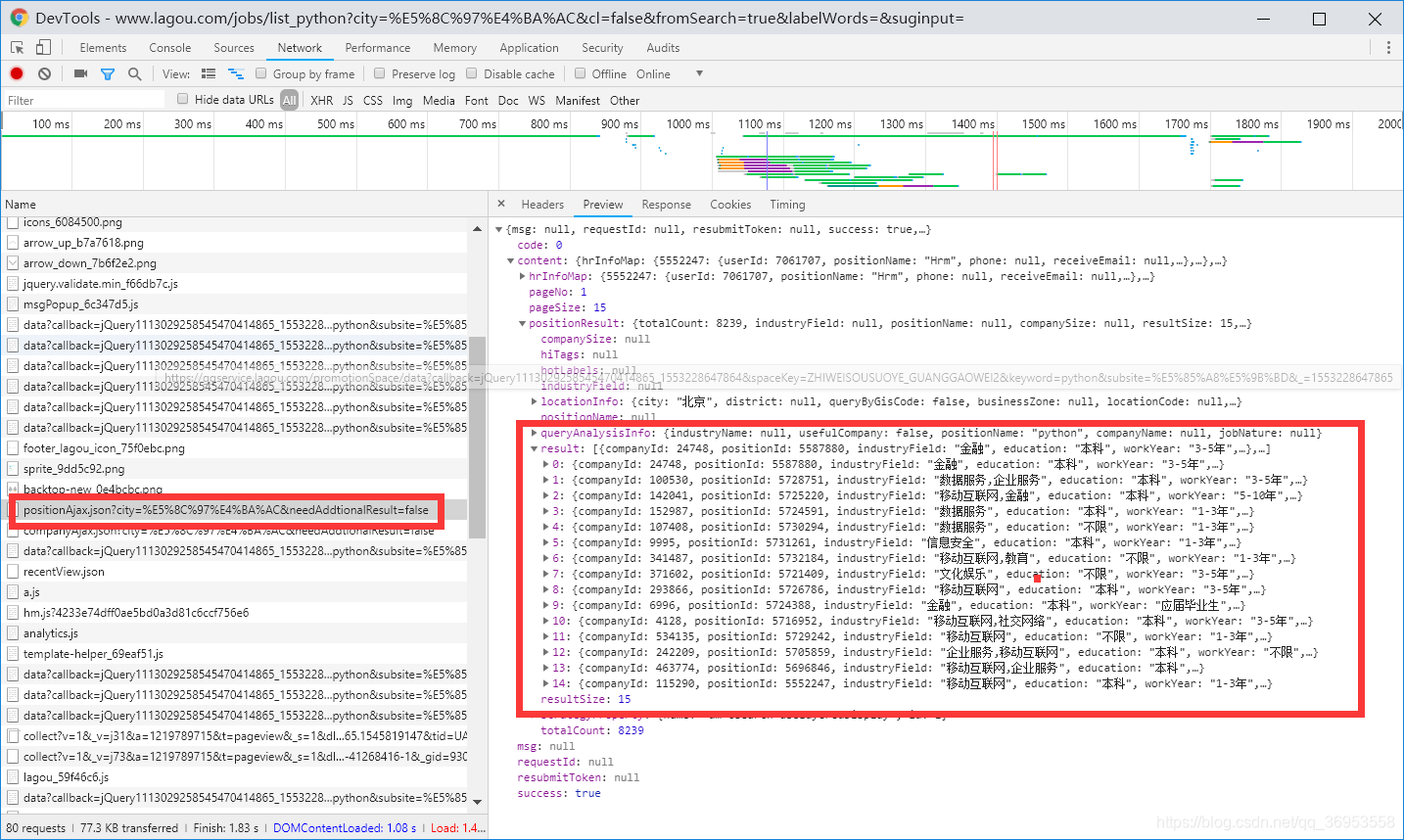
我们找到了那个包 开始分析接口

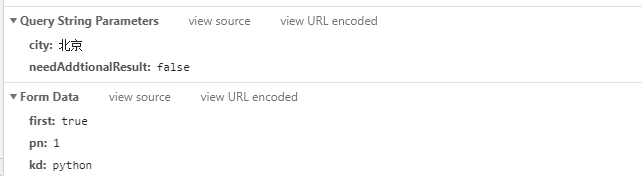
那么我们开始写代码
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_php?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput=',
}
data = {'first': True,
'kd': 'python',
'pn': 1}
response = requests.post(
'https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false', # ajax接口地址
headers=headers,
data=data)
p = response.json()
print(p)我们把这个接口进行post请求时发现并不能返回有效的信息,而是提示
{"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"42.185.150.216","state":2402}但是我们只访问了一次 不可能操作太频繁,这一定是被反爬检测到了。
后来我加上了cookie 也不行,经过了很长时间的测试,终于让我找到了如何爬取。
原来是访问这个接口之前一定要获取到请求原网页的cookie 然后带着这个cookie来访问接口
于是我使用了request.Session() 会话,先get访问一回原网页,再post接口,果不其然,爬到了真正的职位信息
![]()
如何查询下一页的信息呢 在data中可以看到pn=1 翻到第二页时 pn=2 所以 只需要把pn递增就好了
拉勾网每次都要重新获得一次原网页给的cookie 所以我们循环每次都要去get一次原网页,还有每爬一页都要暂停5s以上 我第一次就没写time.sleep() 结果ip被封了 只能用代理 然后加了睡眠 可以爬取下来全站的职位信息。
所有代码如下:
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_php?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput=',
}
data = {'first': True,
'kd': 'python',
'pn': 1}
proxies = {
'HTTPS':'117.90.7.156:9999'
}
for i in range(1, 20):
data['pn'] = i
session = requests.Session()
session.get(
'https://www.lagou.com/jobs/list_python?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput=',
# 请求原网页以便获得cookie
headers=headers,proxies=proxies)
response = session.post(
'https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false', # ajax接口地址
headers=headers,
data=data,
proxies=proxies)
p = response.json()
print(p)
position_list = p["content"]["positionResult"]["result"]
for position in position_list:
print(position["positionId"], position["companyShortName"], position["positionName"], position["workYear"],
position["education"],
position["salary"])
session.close()
time.sleep(10)爬取结果如下:
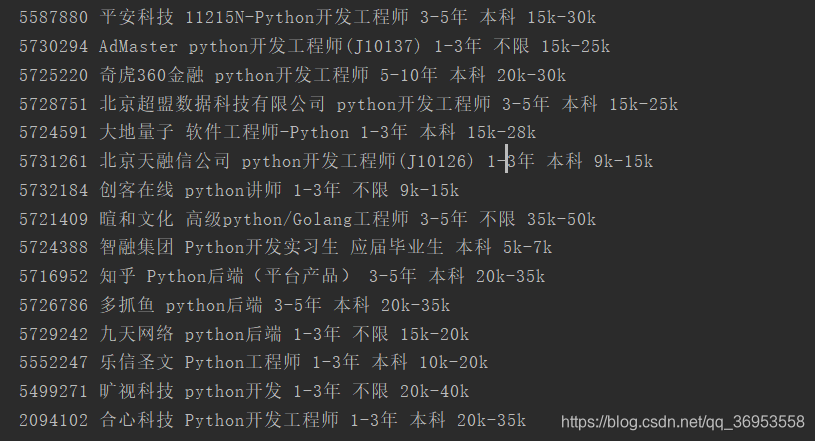
拉勾网的反爬虫机制做的真的挺好的,很适合做初学爬虫的练习。切记 不要爬取的太快 一定要sleep几秒再爬下一页
如果想爬每个职位的详细信息。只需要把每个职位信息里面的positionId 与这个url进行拼接就可以了 访问用get+正常的请求头就好了,请求头必须要有Referer和User-Agent。
比如职位的详情信息是这个url:https://www.lagou.com/jobs/5587880.html 其中5587880就是positionId
我们去get "https://www.lagou.com/jobs/"+str(position["positionId"])+".html"就可以了

















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









