




在 Flink SQL 的 Connector 配置中,'format' = 'json' 和 'format' = 'raw' 用于指定数据的解析 / 序列化格式,二者的核心区别在于是否对数据进行结构化解析,具体差异如下:
1. 'format' = 'json':结构化解析
- 作用:将输入的字节流(如 Kafka 中的消息)解析为结构化数据(对应表定义的字段),或反之将结构化数据序列化为 JSON 格式的字节流。
- 工作方式:
- 读取数据时(Source):会按照表定义的字段名和类型,从 JSON 字符串中提取对应的值。例如,表定义为
(id INT, name STRING),则会从{"id": 1, "name": "flink"}中解析出id=1、name="flink"。 - 写入数据时(Sink):会将表中的结构化字段组合成 JSON 字符串输出(如上述示例会生成
{"id":1,"name":"flink"})。
- 读取数据时(Source):会按照表定义的字段名和类型,从 JSON 字符串中提取对应的值。例如,表定义为
- 依赖:需要 JSON 字符串的结构与表定义的字段完全匹配(字段名、类型兼容),否则会解析失败(抛出
JsonParseException)。 - 适用场景:处理有固定结构的 JSON 数据,如业务日志、API 接口数据等(大部分结构化数据场景)。
2. 'format' = 'raw':原样读取 / 写入
- 作用:将数据以原始字节流的形式直接处理,不进行任何结构化解析或序列化。
- 工作方式:
- 读取数据时(Source):无论原始数据是 JSON、字符串、二进制还是其他格式,都会被当作一个单一的字符串字段处理。表定义中通常只需要一个字段(如
data STRING),所有数据都会被存入该字段。 - 写入数据时(Sink):会将表中唯一的字符串字段直接作为字节流输出,不添加任何 JSON 格式的包装。
- 读取数据时(Source):无论原始数据是 JSON、字符串、二进制还是其他格式,都会被当作一个单一的字符串字段处理。表定义中通常只需要一个字段(如
- 特点:
- 无需关心数据的内部结构,适合处理格式不固定或未知的数据。
- 工作方式:
CREATE TABLE kafka_raw (
data STRING -- 所有数据都存在这个字段中
) WITH (
'connector' = 'kafka',
'topic' = 'raw_topic',
'format' = 'raw', -- 原始格式
...
);
- 适用场景:
- 处理非结构化数据(如纯文本日志、二进制文件内容)。
- 处理格式不固定的结构化数据(如不同 JSON 结构混存的场景)。
- 需要自定义解析逻辑(读取后再通过
JSON_VALUE等函数手动解析)。
总结对比表
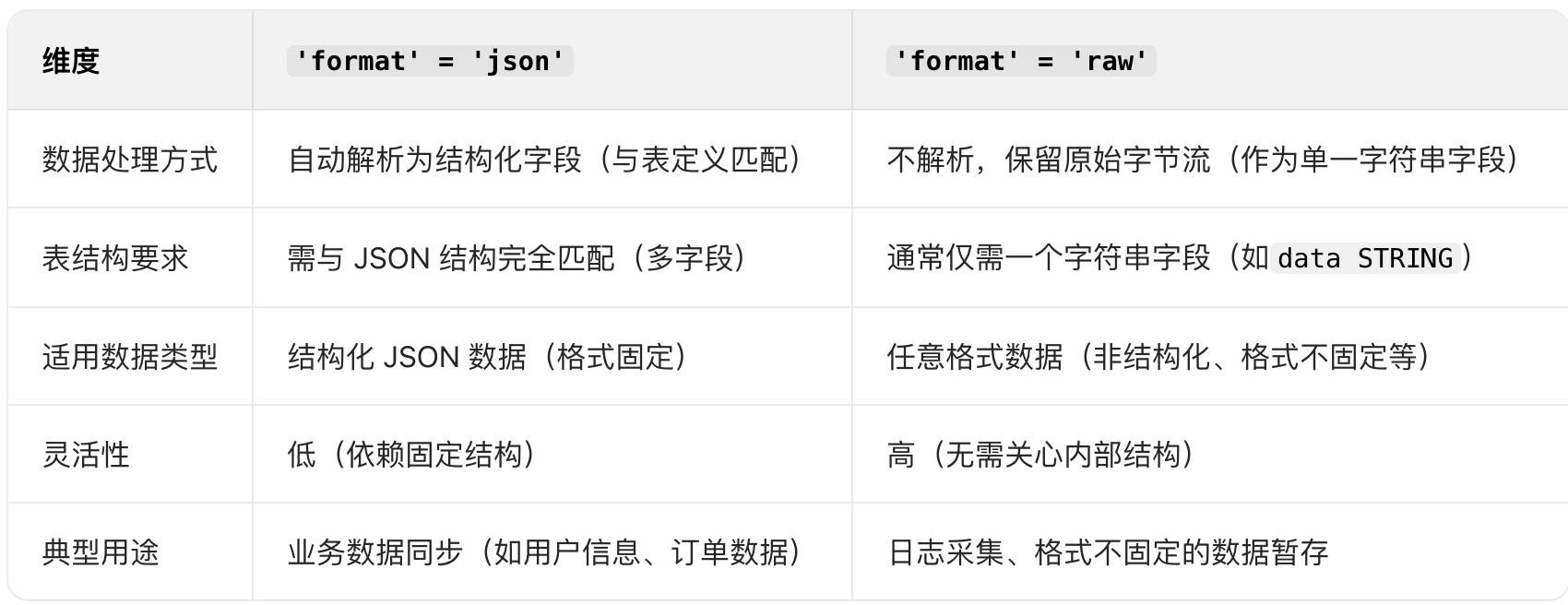
简单来说:json格式适合 “已知结构的数据”,自动完成结构化解析;raw格式适合 “未知 / 可变结构的数据”,保留原始内容由用户自行处理。

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









