









 博客围绕大数据样例数据展开,介绍了取数据前两列的操作,强调分隔符使用需加引号。还详细说明了数据去重的多种方式,如去除重复行、查找非重复行等,以及文件排序的方法,包括确定分隔符、按数值排序等,亲测操作可行。
博客围绕大数据样例数据展开,介绍了取数据前两列的操作,强调分隔符使用需加引号。还详细说明了数据去重的多种方式,如去除重复行、查找非重复行等,以及文件排序的方法,包括确定分隔符、按数值排序等,亲测操作可行。
1.样例数据:
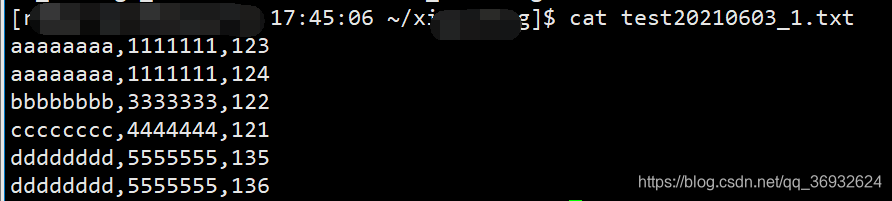
2.取数据前两列:
 注意:分隔符也可以用别的,需要加""
注意:分隔符也可以用别的,需要加""
3.让数据去重:

补充:
去除重复行
sort file |uniq
查找非重复行
sort file |uniq -u
查找重复行
sort file |uniq -d
统计
sort file | uniq -c
4.跟文件排序:

补充:
[root@testtest]# ls | sort -nzlib-1.2.10.tar.gz
abc-1.2.11.tar.gz
abc-1.2.12.tar.gz
abc-1.2.20.tar.gz
abc-1.2.3.tar.gz
abc-1.2.8.tar.gz
理想的结果
abc-1.2.3.tar.gz
abc-1.2.8.tar.gz
abc-1.2.10.tar.gz
abc-1.2.11.tar.gz
abc-1.2.12.tar.gz
abc-1.2.20.tar.gz
sort -t"." -k3,3n file-t 确定分隔符
-k 确定第几个域
-n 按数值排序
-r 逆序
补充:
数据去重:awk -F "," '{if($3>a[$1$2]) {a[$1$2]=$3;b[$1$2]=$0}}END{for(i in b) print b[i]}' a.txt

















 3368
3368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









