







 本文探讨了在dom4j库中Element和Node的区别,Element主要用于获取子元素,而Node则适用于通过XPath进行深层次定位。Element是Node的子类,具备更多特性。在实际使用中,二者可以相互转换,但需要注意转换带来的对象丢失或增加的问题。
本文探讨了在dom4j库中Element和Node的区别,Element主要用于获取子元素,而Node则适用于通过XPath进行深层次定位。Element是Node的子类,具备更多特性。在实际使用中,二者可以相互转换,但需要注意转换带来的对象丢失或增加的问题。
Element和Node的异同
Element是使用dom4j一开始就能用到的。一般就是使用Element对象调用elements()方法获取其下的所有子元素(就只是子元素,没有孙子元素)。这样一来有个缺点,就是当树很深的话,一次只能遍历一层,你得循环套循环,才能找到孙子的孙子。
所以就有Xpath的技术了,它就可以迅速定位到你要的位置,不管多深(前提你得知道树的层次,作为参数传送到位置)。在这一块我们用的Node。
但是我用的过程中,发现Element和Node对象可以互相转化。这就让我很疑惑,它俩啥关系?而且啥时候用Element啥时候用Node呢?
翻阅文档可以看出,Node是父类,Element是它的间接子类。



可以说Element对它自己的要求更高些,因为它是在Node的基础上扩建的。所以Element里面的东西更为丰富。
看下面这个代码:
Demo.xml
<?xml version="1.0" encoding="UTF-8"?>
<companys>
<company id="1001">
<name>万科A</name>
<address>广东深圳</address>
</company>
<company id="1002">
<name>恒大B</name>
<address>广东广州</address>
</company>
<company id="1003">
<name>金地C</name>
<address>北京</address>
</company>
<company id="1006">
<name>绿地D</name>
<address>上海</address>
</company>
</companys>
TestXML.java
import java.io.File;
import java.util.Iterator;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
public class TestNode {
public static void main(String args[]) {
try {
SAXReader reader = new SAXReader();
File xmlFile = new File("E:\\demo.xml");
Document doc = reader.read(xmlFile);
// 得到根标签
Element root = doc.getRootElement();
// 遍历根元素下的所有元素
Iterator<Element> it = root.elementIterator();
while(it.hasNext()) {
System.out.println(it.next());
}
System.out.println("----------------------------");
// 遍历根元素下的所有节点
for(int i=0;i<root.nodeCount();i++) {
System.out.println(root.node(i));
}
} catch(Exception e) {
e.printStackTrace();
}
}
}
输出结果如下:
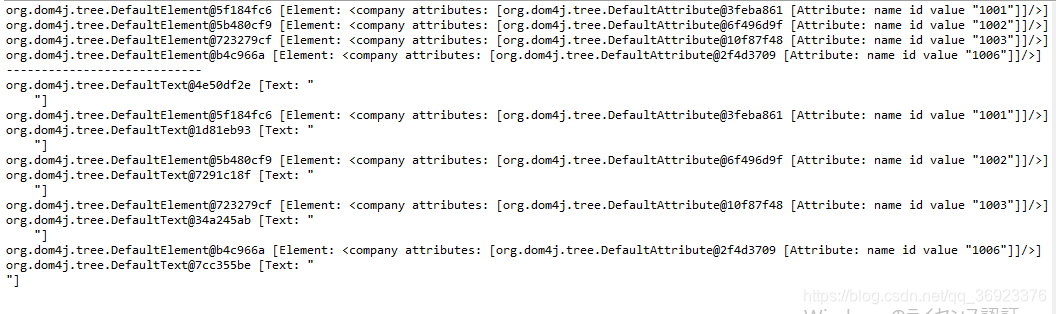
你会发现Node对象比Element对象多,仔细再看,你会发现Node对象不包含换行符和制表位,所以它才输出的多。
总结:Element是Node的子类,所以Element可以上转型为Node对象,也就是子类可以转换为父类。与此同时,Node也可以转为Element(这里姑且可认为下转型,但一般java中是不支持的,因为对于一个父类和子类,从父类转到子类,必然增加一些属性,java根本不知道值是多少,反之,则可以),这样,Node中势必会把换行符和制表符那些对象丢掉。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









