




 本文深入探讨了MySQL的架构,重点讲解了并发控制,包括读写锁、锁粒度和事务隔离级别。还详细介绍了多版本并发控制(MVCC),解释了InnoDB的MVCC实现以及其在不同事务隔离级别下的工作原理。此外,文章还讨论了存储引擎的选择,建议在非事务需求下可以选择MyISAM,而InnoDB更适合事务处理和高性能场景。
本文深入探讨了MySQL的架构,重点讲解了并发控制,包括读写锁、锁粒度和事务隔离级别。还详细介绍了多版本并发控制(MVCC),解释了InnoDB的MVCC实现以及其在不同事务隔离级别下的工作原理。此外,文章还讨论了存储引擎的选择,建议在非事务需求下可以选择MyISAM,而InnoDB更适合事务处理和高性能场景。
(一) mysql 架构
1.1 逻辑架构

第二层:查询解析,分析,优化,缓存以及所有的内置函数(日期,时间,数学等等),以及所有的夸存储引擎的功能:存储过程、触发器、视图等
第三层:包含存储引擎,存储引擎是负责数据的存储和提取的。存储引擎都实现了同样的接口,屏蔽了不同ing存储引擎的差异。
存储引擎API 的底层函数,用于执行"开始事务"或者"根据主键提取一行记录"等操作
注意:存储引擎不会去解析sql 1^11,不同存储引擎间不互相通信,只是简单响应上层服务器的请求
1_11 InnoDB 是一个例外,会解析外键定义,因为mysql服务器本身没有实现该功能
1.2 并发控制
-
问题
多个查询需要在同一时刻修改数据
类比邮件,如果两封邮件同时到达同一个收件人服务器,入过不控制,会发生两封邮件内容相互追加 -
读写锁
写操作: 加锁(独占锁),只能有一个线程在写
读操作:只能在没有写锁存在的情况下才能获取(共享锁),可多个线程读
注:一个写锁或阻塞其他的写锁与读锁 -
锁粒度
含义:锁定的数据量越少,则系统的并发程度越高(比如jdk1.7 与jdk1.8 的hashmap 的实现区别)
3.1表锁(tabkle lock)
写操作对整张表加锁(锁开销小),会同时阻塞其他用户对该表的读、写操作
3.2 行锁(row lock)
特点: 最大程度支持并发处理(锁开销最大)
注:行级锁只在存储引擎实现1.3 事务
- 含义
指的是一组原子性的sql查询,或者是说是一个独立的工作单元(单元内的sql要么都成功,要么全部失败) - 事物特性以及隔离级别
原子+一致+持久+隔离 - 隔离级别:
- read uncommitted
- read committed
- repeatble read(mysql 默认的事务隔离级别)
- serilizable (完全牺牲并发性,只能串行操作,隔离级别最高)
- 不考虑隔离性可能出现的问题:
详细参见另一篇博客
https://blog.youkuaiyun.com/qq_36922927/article/details/89326635
-
死锁
含义:两个或多个 -
事务日志
日志:顺序io
磁盘io:是随机io
预写日志: -
mysql 中的事务
- auto commit
- set transaction isolation level (设置事务隔离级别)
- 同一个事务中使用多种存储引擎不可靠(事务是在存储引擎中实现的)
- 事务回滚,如果事务中包含非事务型表,那么该表不会回滚,也不会报错,可能有提示
1.4 多版本并发控制(MVCC)
Mysql,Oracle,PostgreSQL 等关系数据库都实现了MVCC(无统一标准,实现机制可能不同)
- 含义:
- 可理解为是行级锁的变种
- 根据事务开始的时间不同,每个事物对同一张表,同一时刻看到的数据可能是不一样的
- InnoDB 的MVCC
- 两个隐藏列,分别保存行的创建时间,行的过期时间(这里的时间不是实际时间值,而是指版本号)
- 事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号比较
InnodDB 在repeatable read 隔离级别下的curd 操作逻辑如下
- select
a. 只查找版本号≤\leq≤ 当前事务版本号的行(也就是只查找版本早于当前事务的数据行)
查到的行 要么是事务开始前存在的,要么是自身插入或者修改过的
b. 行的删除版本要么未定义,要么大于当前事务版本号。这是确保事务读取到的行,在事务开始之前未被删除 - insert
为新插入的行以当前系统版本号作为行版本号 - update
插入一行新纪录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为删除标识
table(id,col1,col2,col3)// 表定义
原行:
(1,a,b,c,1,) //最后两列是版本号 // 假设当前系统版本号是100
// 事务开始时,取当前系统版本号作为事务版本号,然后系统版本号自增
操作 update table set col1 =f where id=1;// 此事务版本号为100 , 事务开始时,系统版本号自增为101
结果:
新增一条行记录:
(1,f,b,c,101,);//当前系统版本号101 作为行标识(行版本号)
修改原记录:当前系统版本号作为删除标志
(1,a,b,c,1,101);//
- delete
为删除的每一行保存当前系统版本号作为行版本号
注: InnoDB 的mvcc 只在Repeatable read ,read committed 这两个事务级别下工作
read uncommitted 总是读取最新的数据行,而不是符合当前事务版本的数据行
serializable:对所有读取的行都加锁
1.5 mysql的存储引擎
- InnoDB
- 设计用来处理大量的短期事务,短期事务大部分是正常提交的,很少被回滚
- 性能和自动崩溃恢复特性,在非事务性存储场景也很流行
- 表基于聚簇索引(主键查询性能很高,但是二级索引中必须包含主键列,如果主键列很大,那么其他索引都会很大)
- MyIsAM
- 全文索引,压缩,空间函数
- 不支持事务和行级锁(只能表加锁(这也是性能瓶颈所在))
- 延迟更新索引
- 压缩表 (数据不再修改的数据表)
- 执行表修复可能导致一些数据丢失
- 存储引擎的选择-
- 除非需要用到innodb 不具备的特性,否则优先选择innodb
- 除非万不得已,不要选择混合的存储影青
- 事务,如果不需要事务,那么可以选择MyIsam
- 备份:在线热备份,innodb
- 崩溃恢复:MyIsAm 崩溃后损坏概率比InnoDB高很多,而且恢复速度慢
一些场景:
- 日志型应用:对插入速度要求高,考虑MyISAM
- 读多写少,如果不介意MyISAM 的崩溃恢复问题(这个问题可以在测试环境拔掉电源测试),可以选择MyISAM
- 订单处理:支持事务是必要选项,INNODB
(二) 剖析mysql 查询
2.1 服务器负载
含义:找出效率低下的查询,定位和优化"坏"查询,提高应用性能
工具:
-
慢查询日志:找出代价高的查询(慢查询日志开销低,精度高)
-
通用日志:在查询请求到服务器时进行记录,所以不包含响应时间和执行计划等重要信息
-
pt-query-digest:分析查询日志的工具,可以将慢查询日志生成剖析报告
剖析报告示例:
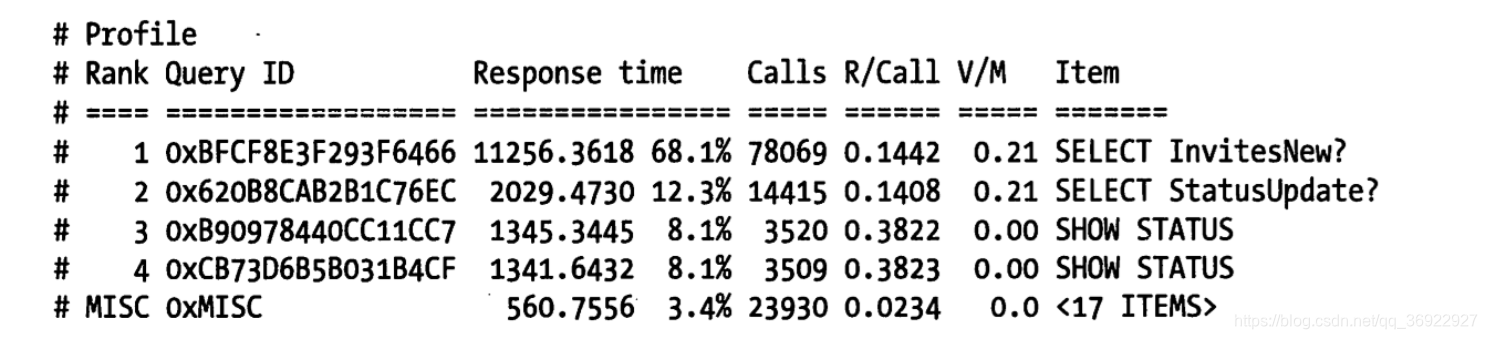 参数解读:
参数解读:
| 参数 | 含义 |
|---|---|
| Rank | 排名,越慢越靠前 |
| Query ID | 对查询语句计算出的哈希指纹 |
| V/M | 方差均值比(离差指数),与查询对应的执行时间正相关 |
| Item | 相关查询的简写,至于那个? 是 替代了表名后面的分片标识(这里的分片是什么我暂时不清楚) |
剖析报告后面还有详细报告
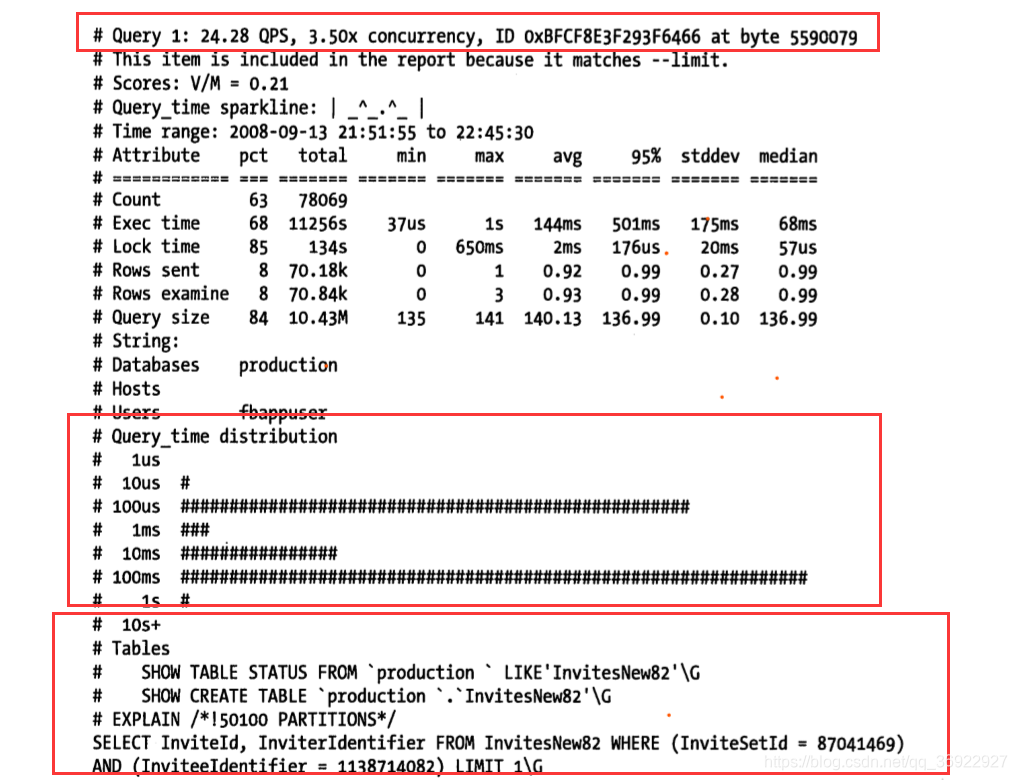
顶部包含:查询执行的频率,平均并发度,以及查询性能最差的一次执行在日志文件中的字节偏移值
接着是直方图:Query_time distribution,查询时间分布
2.2 剖析单条查询
- show profile:MySql 5.1以后的版本引入(默认是禁用的)
SET profiling =1;
启用后,在服务器上执行的所有sql语句都会测量其耗费的时间,其他一些查询状态变更的数据
当一条查询提交到服务器时,此工具会记录剖析信息到一张临时表中,斌哥且给查询赋予一个从1开始的整数标识符
执行:show profile ; 显示剖析结果
mysql 默认的时间只会精确到两位小数
但是 show frofile 是显示了 7位小数,精度是很高的
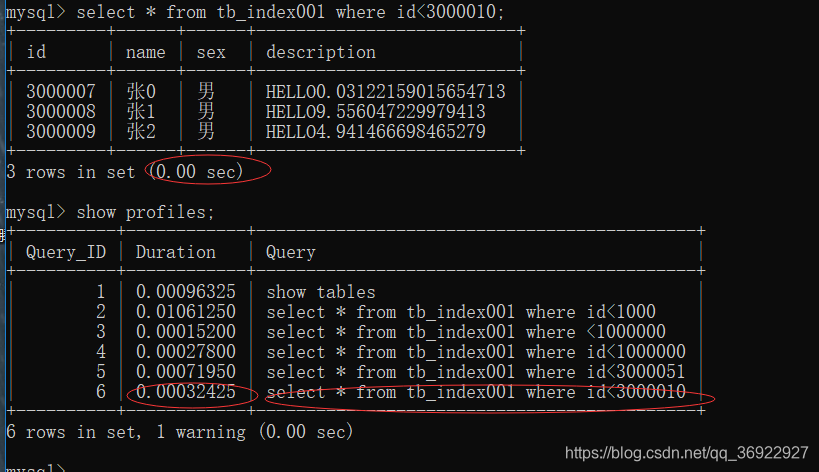 来查看下Query_Id=6 的查询的具体数据
来查看下Query_Id=6 的查询的具体数据
show profile for query 6;
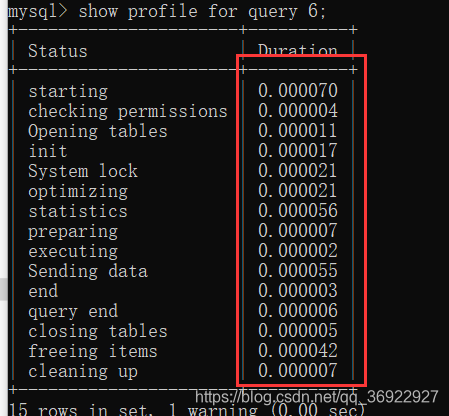
发现并不是按照耗时时间排序的,我想知道的是耗时较多的是哪些步骤
以下步骤格式化输出:
SET @query_id=6;
SELECT
state,
SUM(DURATION) AS Total_R,
ROUND(
100 * SUM(duration) / (
SELECT
SUM(duration)
FROM
information_schema.PROFILING
WHERE
QUERY_ID =@query_id
),2)AS Pct_R,
COUNT(*) as Calls,
SUM(duration)/COUNT(*) as "R/Call"
from information_schema.PROFILING
where QUERY_ID=@query_id
GROUP BY STATE
ORDER BY Total_R DESC;
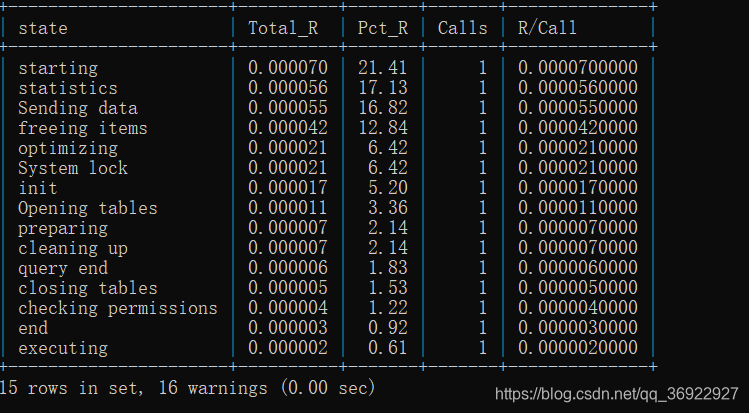 以上是单表查询,没有发现特别耗时的条目。
以上是单表查询,没有发现特别耗时的条目。
- show status
计数器,显示某些活动如读索引的频繁程度,但无法给出消耗多少时间
参数很多,以后用到再来细究
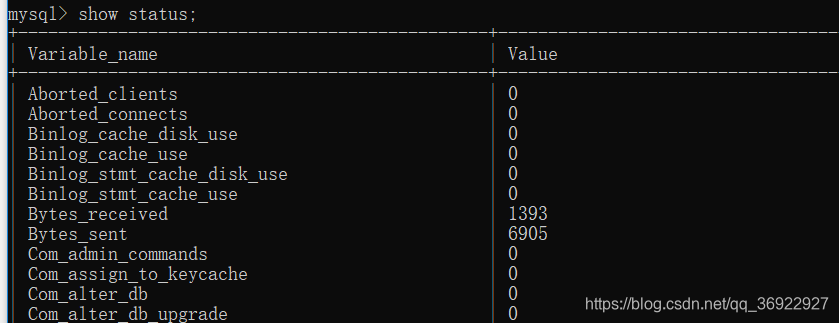
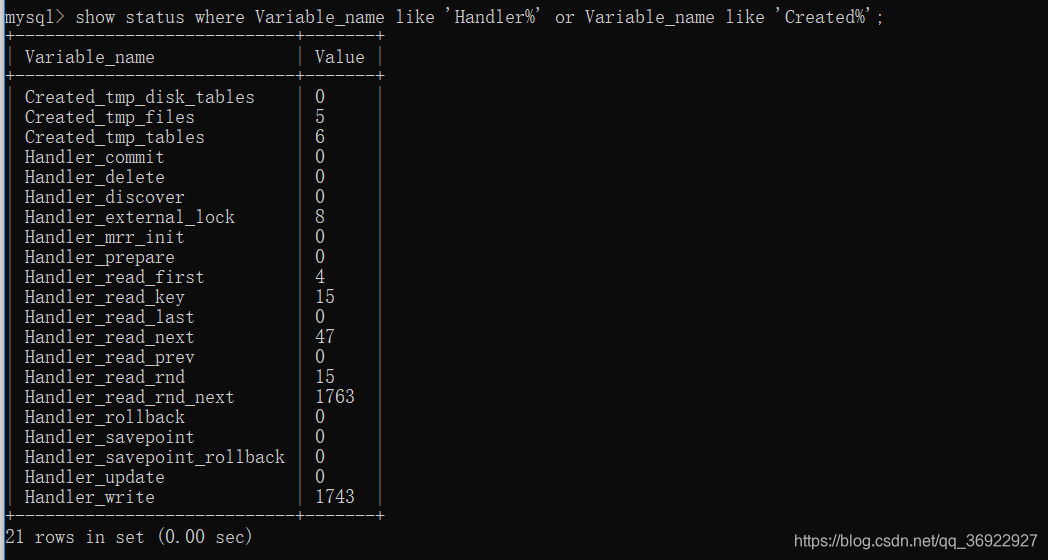
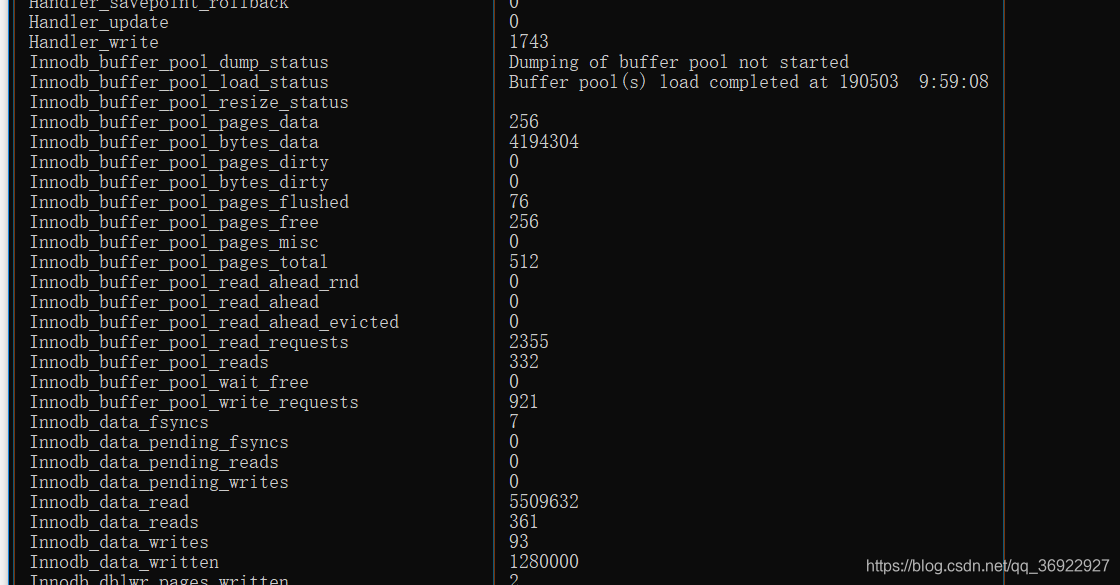 注:show status 会区分内存临时表和磁盘临时表
注:show status 会区分内存临时表和磁盘临时表
这点在explain 中是不能区别的
下图中:
磁盘临时表:Created_tmp_disk_table 0个
总的临时表:Created_tmp_tables 6
内存临时表: 总的临时表数-磁盘=6
未使用索引的读:Handler_read_rnd_next
2.3 诊断间歇性问题
含义:间歇性问题是指系统偶尔停顿或者慢查询
计数器表
为了统计网站的访问数
- 单独的表来统计数据,只有一行数据
那么对于每一个想更新这一行的事务来说,这条记录上都有一个全局的互斥锁,变为串行,并发性能堪忧 - 为了提高把并发性能,可以设置多行
预先设置100行,每个事务随机选取一行来更新
所有行数据累加即得最终结果
如果不想预先生成行,可以使用 on duplicate key

3. 如果为了减少表数据的行数
可以使用定时任务,将数据统计到地0行,然后删除其他行
加快alter table
alter table 操作可能导致服务停止,耗时
解决方案:
- 先在不提供服务的数据库上进行alter 操作,完成后,和主库切换
- “影子拷贝”,建立一张和源表无关的表,然后重命名,删除操作来交换两张表
- 不是所有的alter table 都会导致表重建,alter 对应的列即可


索引基础
B_Tree 索引
名字是Btree ,但是底层实现可能是B+,T_Tree 结构存储这种索引
B_Tree:
- 所有值是按顺序存储的,每一个叶子到根的距离相同
- 指针实际上定义子节点页中值得上限和下限
- 最终存储引擎要么找到对应的值,要么不存在
如何能使用上索引
满足最左原则即可
索引列必须按照建立索引的顺序使用,不能跳过,如果跳过,那么只能在跳过列之前的索引生效
. 如果不是按照索引的最左列开始查找,则无法使用索引
. 不能跳过索引列
. 如果有某个列的范围查询,则其右边的列无法使用索引优化查询
hash 索引(Memory 殷勤支持
hash 表实现
索引=hash 值+数据行的指针
注意:
- hash 索引只包含哈希值和行指针
- hash 索引数据不是按照索引值顺序存储,故无法用于排序
- hash 索引只支持等值查询 =,IN(),<>
不支持任何范围查询,例如where price》100 - 访问hash 速度快,除非hash 冲突很多,如果有哈市冲突,存储引擎必须便利链表的所有行指针,逐行进行比较
- 如果hash 冲突很多,一些索引维护操作的代价很高。删除一行,需要遍历对应hash 值链表的每一行,找到并删除对应行的引用,冲突越多,代价越大
innodb 的自适应hash 索引:
innnodb 在察觉到某些索引使用率很高,自动在B-tree 上建立一层hash 索引,快速定位到节点
创建自定义hash 索引
比如:在存储大量URL,根据URL查找,如果使用B+Tree 存储URL,内容很大,可以存储一个索引列(hash)
hash 列可以使用触发器来在插入数据时,自动插入hash 值


空间数据索引(R-Tree)
可以用作地理数据存储,无需前缀查询,从所有维度来索引数据
全文索引
查找的是文本中的关键词,而不是直接比较琐索引的值
索引的优点
- 减少服务器需要扫描的数据量
- 避免排序和临时表
- 将随机io变为顺序IO
如果数据表数据小,全表扫描效率更高
中,大型表,索引非常有效
特大型表。建立和使用索引的代价随之增长,可以使用分区技术查出需要的一组数据,而不是一条一条记录的去匹配

聚簇索引
聚簇索引不是一种单独的索引类型,而是一种数据存储方式。具体细节依赖于实现方式,但是Innodb 的聚簇索引实际在同一个结构中保存了B-Tree索引和数据行。
数据行实际上存放在索引的叶子页中。
“聚簇”表示数据和相邻的减值紧凑的存放在一起。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
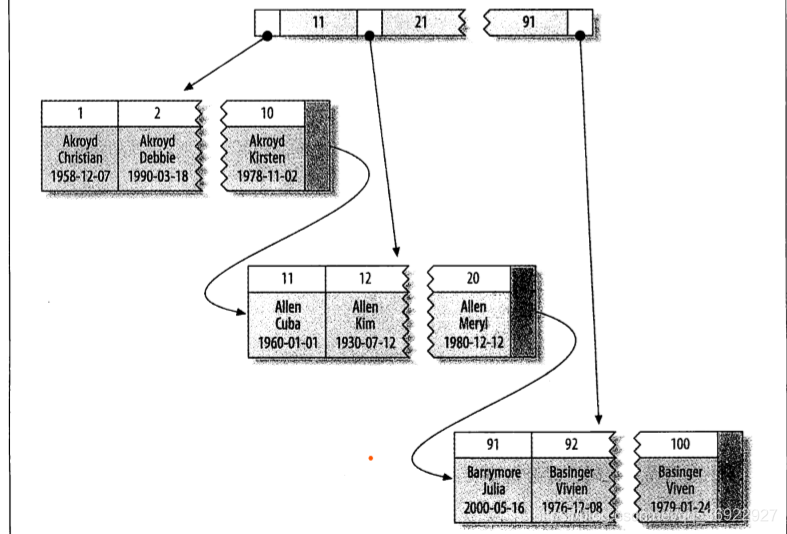 聚集的优点:
聚集的优点:
- 相关数据存储在一起,如电子邮箱实现时,可以将ID 来聚集数据,只需要从磁盘读取少数数据也就能获取某个用户的全部邮件。如果不适用聚簇,可能每封邮件发生一次IO
- 数据访问更加快(相对于非聚集索引)
- 使用覆盖索引扫描的查询可以直接使用叶节点的主键值
缺点:
覆盖索引
使用索引直接获取列的数据,这样不需要读取数据行。如果一个索引包含(或者是覆盖)所有要查询的字段的值,称之为“覆盖索引”
好处:
- 索引条目通常远小于数据行大小,如果只需要读取索引,那么mysql 就会极大的减少数据访问量
- 索引通常是按照列值顺序存储的(至少在单个页内是如此)
- 一些存储引擎如MyIsam,在内存中只缓存索引,数据则依赖操作系统来缓存,因此访问数据需要一次系统调用
— 未完待续

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









