










问题:给定原串origin,求target 串在原串第一次出现的位置,若不存在,输出-1
例如: origin:abcdef
target:bc
输出:1
朴素算法
最直观的思路(朴素算法):
- 取target的首元素与origin的首元素比较,如果相同,执行2
- 两个字符相同,继续比较两个串的下一个元素
- 如果出现元素不同
3.1 如果上一个元素是匹配的(也就是当前比较的不是target串的首字符),那么需要将target的指针回退到头部,origin的指针回退到 第一个匹配字符的下一个字符位置(也就是此次匹配只是缩小了origin的一个字符的范围),继续2
3.2 ,如果上一个元素也是不匹配(也就是当前比较的仍然是taget的首字符),那么只需要将origin 串的指针向后一个字符,继续2
算法实现:
public static int matchMethod1(char[] origin, char[] target) {
if (target.length > origin.length) {
return -1;
}
int i = 0;
int j = 0;
for (; j < origin.length && i < target.length; ) {
if (target[i] == origin[j]) {
//1,如果是target的最后一个字符匹配,表示完全匹配
if (i == target.length - 1) {
return j - target.length + 1;
}
i++;
j++;
} else {
j++;
//2,之前匹配上一部分字符,突然匹配中断,那么就得从target 头部开始,重新匹配
if (i != 0) {
j =j- i+1;//3,从原字符串origin的第一次匹配字符的下一个位置开始
i = 0;
}
}
}
return -1;
}
朴素算法存在的问题,效率
则是如果出现不匹配,origin 串的回退步数的问题,需要回退很多步,而这些回退中,有一些是无效的.
例如:origin:abcbcd
target :bcd
初始:i=0;j=0;
target[0]=b!=origin[0]
i++ ------ i=1
origin[1]=b==target[0] (开始出现匹配)
i++ and j++ ----- i=2 ,j=1
origin[2]=c=target[1] (第二个字符也匹配)
i++ and j++ -----i=3,j=2
origin[3]=b != target[2] (匹配出现中断)
朴素算法会将i=i-j+1=2,即:origin的字符指针指向第一个匹配字符的下一个字符位置,同时 j!=0,需要target的字符指针指向target头部,即j=0;
接下来重复之前的操作,发现 i=2,明显不匹配,i=3才开始出现匹配,那么如何能避免过大的回退呢?比如这里就只是回退到3(也就是相当于没有回退)??? 这里就该kmp算法上场了.
比较高效的算法:KMP
处理target 串,将其中的一些信息提取出来,形成一个回退序列,方便在匹配到第i个字符出现匹配中断,快速得到应该origin回退backSteps[i] 个长度
java 实现:
/**
* 使用kmp 算法,提高匹配效率,需要对目的串target 进行预处理,获取一些比较重要的数据,减少回退次数
*
* @param origin
* @param target
* @return
*/
public static int matchMethodKMP(char[] origin, char[] target) {
int[] backSteps = preHandleKmp(target);//这是核心部分
int i = 0;
int j = 0;
while (j < target.length) {
if (origin[i] == target[j]) {
i++;
j++;
} else {
//之前有匹配过,target 需要回退,目的串需要回退
if (j != 0) {
j = backSteps[j - 1];
} else {
i++;
}
}
//目标串最后一个字符已经匹配,需要返回第一个字符匹配位置
if (j == target.length) {
return i - j;
}
}
return -1;
}
对目的串的预处理核心代码:
private static int[] preHandleKmp(char[] target) {
//比如字符串target: abababc
//当前匹配到target下标为 k (最大长度)
//k=0 前缀: a 后缀:空 公共长度: 0
//k=1 前缀:a 后缀:b 公共长度:0
//k=2 前缀:a ,ab, 后缀:ba,a 公共长度:1(a)
//k=3 前缀:a, ab,aba 后缀: bab ,ab ,b 公共长度:2(ab)
//k=4 前缀:a, ab,aba,abab后缀: baba ,aba ,ba ,a 公共长度:3(aba)
//k=5 前缀:a, ab,aba,abab,ababa后缀: babab ,abab ,bab ,ab,b 公共长度:4(abab)
//k=6 前缀:a, ab,aba,abab,ababa,ababab后缀: bababc ,ababc ,babc ,abc,bc,c 公共长度:0
int m = target.length;
int[] lps = new int[m];
int k = 0;//前缀
int q = 1;//后缀
while (q < m) {
//出现公共前.后缀,公共前后缀 长度+1
if (target[k] == target[q]) {
k++;
lps[q] = k;
q++;
} else {
//k!=0,表示之前有公共前缀,那么就使用之前的公共前缀长度
if (k != 0) {
k = lps[k - 1];
}
//k=0,表示一次公共前缀都没出现过,那么公共前缀就是为0
else {
lps[q] = 0;
q++;
}
}
}
return lps;
}
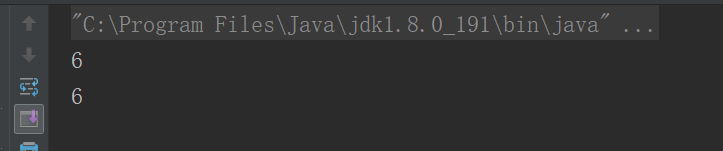
附上测试输出:
origin:abcdcdefcd
target:efcd
public static void main(String[] args) {
char[] origin = "abcdcdefcd".toCharArray();
char[] target = "efcd".toCharArray();
System.out.println(matchMethod1(origin, target));
System.out.println(matchMethodKMP(origin, target));
}
结果:
参考博客:https://www.cnblogs.com/gaochundong/p/string_matching.html

















 2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









