






clickhouse安装部署与问题处理记录
clickhouse安装
安装部分网上资料很多,不再赘述,附上参考文档地址
单机版安装:https://www.jianshu.com/p/fa6bf0a4a903
集群安装:以下两种方式都是三分片两副本的方式
6节点安装教程:https://blog.youkuaiyun.com/lusklusklusk/article/details/134741272
3节点安装教程:https://blog.youkuaiyun.com/qq_36933421/article/details/128283423
注意:clickhouse集群安装最佳实践是分片数*副本数=实例数,因此,3节点部署实际是在一个节点上起了2个实例,6节点部署则是一个节点起一个实例
使用问题处理记录
Code: 241. DB::Exception: Memory limit (total) exceeded: would use 6.32 GiB (attempt to allocate chunk of 4360416 bytes), maximum: 6.27 GiB. OvercommitTracker decision: Query was selected to stop by OvercommitTracker. (MEMORY_LIMIT_EXCEEDED) (version 23.8.8.20 (official build))
java.sql.BatchUpdateException: Code: 241. DB::Exception: Memory limit (total) exceeded: would use 6.32 GiB (attempt to allocate chunk of 4360416 bytes), maximum: 6.27 GiB. OvercommitTracker decision: Query was selected to stop by OvercommitTracker. (MEMORY_LIMIT_EXCEEDED) (version 23.8.8.20 (official build))
, server ClickHouseNode [uri=http://10.127.228.145:18123/default, options={compress=0,use_time_zone=Asia/Shanghai,use_server_time_zone=false}]@-236135211
at com.clickhouse.jdbc.SqlExceptionUtils.batchUpdateError(SqlExceptionUtils.java:107)
at com.clickhouse.jdbc.internal.InputBasedPreparedStatement.executeAny(InputBasedPreparedStatement.java:154)
at com.clickhouse.jdbc.internal.AbstractPreparedStatement.executeLargeBatch(AbstractPreparedStatement.java:85)
at com.clickhouse.jdbc.internal.ClickHouseStatementImpl.executeBatch(ClickHouseStatementImpl.java:752)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils
.
s
a
v
e
P
a
r
t
i
t
i
o
n
(
J
d
b
c
U
t
i
l
s
.
s
c
a
l
a
:
667
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
d
a
t
a
s
o
u
r
c
e
s
.
j
d
b
c
.
J
d
b
c
U
t
i
l
s
.savePartition(JdbcUtils.scala:667) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils
.savePartition(JdbcUtils.scala:667)atorg.apache.spark.sql.execution.datasources.jdbc.JdbcUtils
a
n
o
n
f
u
n
anonfun
anonfunsaveTable
1.
a
p
p
l
y
(
J
d
b
c
U
t
i
l
s
.
s
c
a
l
a
:
834
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
d
a
t
a
s
o
u
r
c
e
s
.
j
d
b
c
.
J
d
b
c
U
t
i
l
s
1.apply(JdbcUtils.scala:834) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils
1.apply(JdbcUtils.scala:834)atorg.apache.spark.sql.execution.datasources.jdbc.JdbcUtils
a
n
o
n
f
u
n
anonfun
anonfunsaveTable
1.
a
p
p
l
y
(
J
d
b
c
U
t
i
l
s
.
s
c
a
l
a
:
834
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
r
d
d
.
R
D
D
1.apply(JdbcUtils.scala:834) at org.apache.spark.rdd.RDD
1.apply(JdbcUtils.scala:834)atorg.apache.spark.rdd.RDD
a
n
o
n
f
u
n
anonfun
anonfunforeachPartition
1
1
1
a
n
o
n
f
u
n
anonfun
anonfunapply
28.
a
p
p
l
y
(
R
D
D
.
s
c
a
l
a
:
935
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
r
d
d
.
R
D
D
28.apply(RDD.scala:935) at org.apache.spark.rdd.RDD
28.apply(RDD.scala:935)atorg.apache.spark.rdd.RDD
a
n
o
n
f
u
n
anonfun
anonfunforeachPartition
1
1
1
a
n
o
n
f
u
n
anonfun
anonfunapply
28.
a
p
p
l
y
(
R
D
D
.
s
c
a
l
a
:
935
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
S
p
a
r
k
C
o
n
t
e
x
t
28.apply(RDD.scala:935) at org.apache.spark.SparkContext
28.apply(RDD.scala:935)atorg.apache.spark.SparkContext
a
n
o
n
f
u
n
anonfun
anonfunrunJob
5.
a
p
p
l
y
(
S
p
a
r
k
C
o
n
t
e
x
t
.
s
c
a
l
a
:
2121
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
S
p
a
r
k
C
o
n
t
e
x
t
5.apply(SparkContext.scala:2121) at org.apache.spark.SparkContext
5.apply(SparkContext.scala:2121)atorg.apache.spark.SparkContext
a
n
o
n
f
u
n
anonfun
anonfunrunJob
5.
a
p
p
l
y
(
S
p
a
r
k
C
o
n
t
e
x
t
.
s
c
a
l
a
:
2121
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
c
h
e
d
u
l
e
r
.
R
e
s
u
l
t
T
a
s
k
.
r
u
n
T
a
s
k
(
R
e
s
u
l
t
T
a
s
k
.
s
c
a
l
a
:
90
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
c
h
e
d
u
l
e
r
.
T
a
s
k
.
r
u
n
(
T
a
s
k
.
s
c
a
l
a
:
121
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
e
x
e
c
u
t
o
r
.
E
x
e
c
u
t
o
r
5.apply(SparkContext.scala:2121) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:121) at org.apache.spark.executor.Executor
5.apply(SparkContext.scala:2121)atorg.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)atorg.apache.spark.scheduler.Task.run(Task.scala:121)atorg.apache.spark.executor.ExecutorTaskRunner$$anonfun
11.
a
p
p
l
y
(
E
x
e
c
u
t
o
r
.
s
c
a
l
a
:
407
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
u
t
i
l
.
U
t
i
l
s
11.apply(Executor.scala:407) at org.apache.spark.util.Utils
11.apply(Executor.scala:407)atorg.apache.spark.util.Utils.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.executor.Executor
T
a
s
k
R
u
n
n
e
r
.
r
u
n
(
E
x
e
c
u
t
o
r
.
s
c
a
l
a
:
413
)
a
t
j
a
v
a
.
u
t
i
l
.
c
o
n
c
u
r
r
e
n
t
.
T
h
r
e
a
d
P
o
o
l
E
x
e
c
u
t
o
r
.
r
u
n
W
o
r
k
e
r
(
T
h
r
e
a
d
P
o
o
l
E
x
e
c
u
t
o
r
.
j
a
v
a
:
1149
)
a
t
j
a
v
a
.
u
t
i
l
.
c
o
n
c
u
r
r
e
n
t
.
T
h
r
e
a
d
P
o
o
l
E
x
e
c
u
t
o
r
TaskRunner.run(Executor.scala:413) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor
TaskRunner.run(Executor.scala:413)atjava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)atjava.util.concurrent.ThreadPoolExecutorWorker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
集群环境:3节点,4C8G,centos7
数据情况:kafka数据,少量数据,字段数据在4K以上
处理方式:
方式一
减少字段数量,参考资料:https://www.bilibili.com/read/cv17502956/
方式二
修改clickhouse配置 /etc/clickhouse-server/config.xml
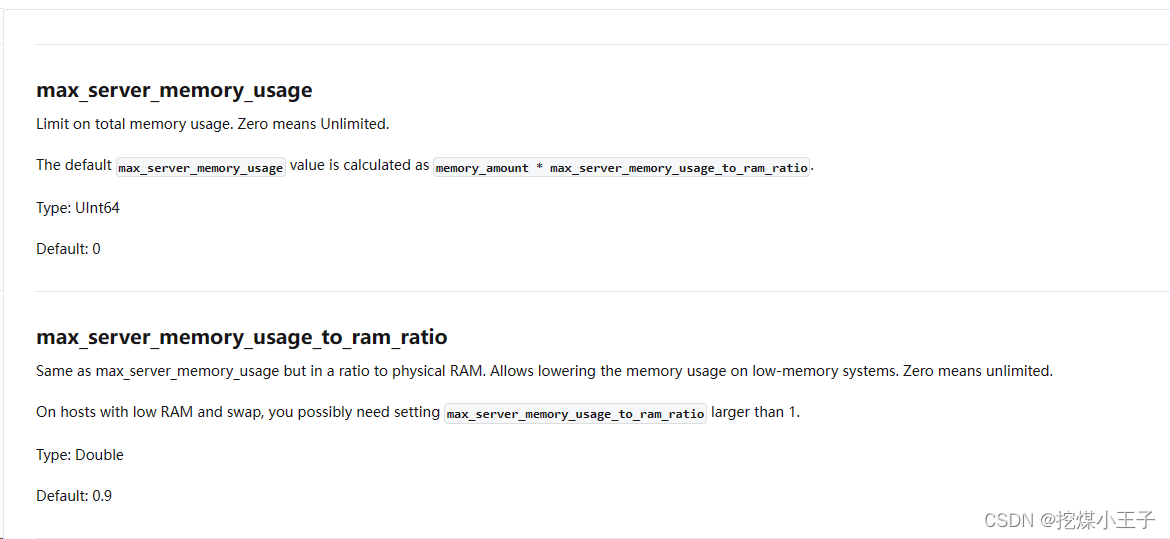
设置 max_server_memory_usage_to_ram_ratio 在机器内存小的情况下,可将此值设置的大于1
设置 max_server_memory_usage 为0
修改clickhouse配置 /etc/clickhouse-server/users.xml
修改profile中的配置,设置 <max_memory_usage> 128000000000</max_memory_usage> #128G,
如果没有那么多的内存可用,ClickHouse可以通过设置这个“溢出”数据到磁盘:
<max_bytes_before_external_group_by>20000000000</max_bytes_before_external_group_by>; #20G
<max_memory_usage>40000000000</max_memory_usage>; #40G
将max_memory_usage设置为max_bytes_before_external_group_by大小的两倍。
个人理解clickhouse会先申请内存,如果申请不到,就会报错退出;虽然申请的内存超过了本机内存大小,但是实际上,由于数据量可能不是那么多,因此在实际使用时,并没有用到那么大的内存,因此,可以将以上值设置的大一点。
参考资料:https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings

















 1793
1793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









