




 本文探讨了生产者消费者模型在数据处理中的应用,通过队列解决生产与消费速度不匹配的问题,介绍了Python的queue模块及其实现,包括FIFO队列的创建与操作。同时,展示了如何使用多线程并行处理数据,实现数据的分发与分析。
本文探讨了生产者消费者模型在数据处理中的应用,通过队列解决生产与消费速度不匹配的问题,介绍了Python的queue模块及其实现,包括FIFO队列的创建与操作。同时,展示了如何使用多线程并行处理数据,实现数据的分发与分析。
分发
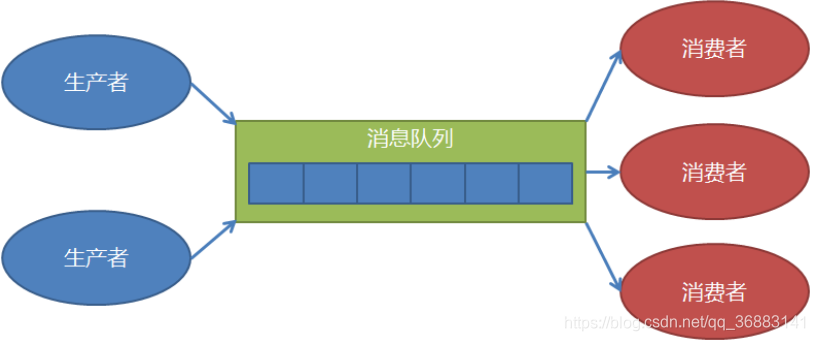
生产者消费者模型
一个系统健康的运行,需要监控并处理很多数据,包括日志,对其中已有数据进行采集,分析。被监控对象就是数据的生产者,数据的处理程序就是数据的消费者
生产者消费者传统模型

生产者和消费者之间总会出现难以匹配的现象,比如说生产者生产能力大于消费者消费能力,或者生产者生产能力低于消费者消费能力等问题
队列
队列queue能够很好的解决生成和消费的速度不能很好的匹配的问题
数据处理所需模块
queue模块–队列
queue模块提供了一个先进先出的队列Queue
queue.Queue(maxsize=0)
创建FIFO队列,返回Queue对象。
maxsize小于等于0,队列长度没有限制
Queue.get(block=True,timeout=None)
从队列中移除元素并返回这个元素
block为阻塞,timeout为超时。
如果block为True是阻塞,timeout=None就是一直阻塞
如果block是阻塞,但是timeout有值,就阻塞到一定秒数抛出Empty异常。
block为False,是非阻塞,timeout将被忽略,要么成功返回一个元素,要么抛出empty异常
Queue.get_nowait()
等价于get(False),也就是说要么成功返回一个元素,要么抛出empty异常。
但是queue的这种阻塞效果,需要多线程
Queue.put(item,block=True,timeout=None)
把一个元素加入到队列中去。
block=True,timeout=None,一直阻塞直至空位放元素。
block=True,timeout=5,阻塞5秒就抛出Full异常
block=False,timeout失效,立即返回,能塞进去就塞进去,不能则返回排除Full异常
Queue.put_nowait(item)
等价于put(item,false),也就是能塞进去就塞进去,不能则返回排除Full异常
#queue测试
from queue import Queue
q=Queue()
q.put(1)
q.put(3)
print(q.get())
print(q.get())
print(q.get_nowait())

threading–线程
import threading
def handle(a,b):
print(a,b)
print('-'*30)
#定义线程
#target线程中运行的函数:args这个函数运行时需要的实参的元组
t=threading.Thread(target=handle,args=(4,5))
#启动线程
t.start()

数据处理流程
生产者(数据源)生产数据,缓冲到消息队列中
数据处理流程:

分发器的实现
数据分析的程序有好多,例如PV分析、IP分析、UserAgent分析等
同一套数据可能要被多个分析程序并行处理:
- 需要使用多线程来并行处理
- 多个分析程序又需要同一份数据,这就是一份变多份
数据处理流程:
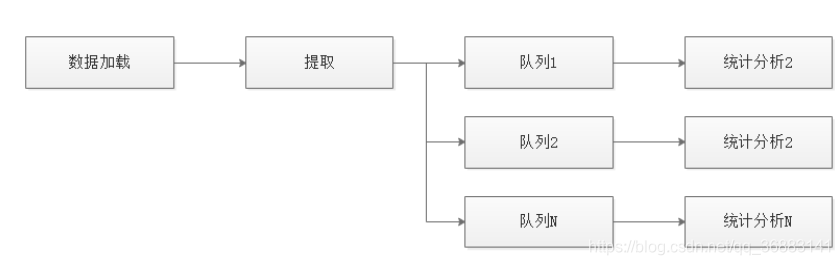
这是一个典型的分发器:
- 注册统计分析函数,并为其提供一个单独的数据队列
- 收集日志数据
- 将一份日志数据发送到多个已注册的分析函数的队列中去
- 为了并行,每一行分析函数都在一个独立的线程中执行
from queue import Queue
import threading
#消息队列,分发
def dispatcher(src):
handlers=[]
queues=[]
def reg(handle):
q=Queue()
queues.append(q)
t=threading.Thread(target=handle,args=(q,))
handlers.append(t)
def run():
for t in handlers:
t.start() #启动线程,运行所有的处理函数
for item in src:
for q in queues:
q.put(item)
return reg,run
reg,run=dispatcher(load('/logs'))

















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









