







一、前言
本系列仅做个人笔记使用,内容大部分来自所引用文章,侵删。
| 日期 | 描述 |
|---|---|
| 2025.04.01 | 重写文章大部分内容 |
二、Redis Stream 简介
Redis Stream 是 Redis 5.0 引入的一种新的数据结构,它提供了一种强大的消息队列和日志记录解决方案,具有以下特点和用途:
- 消息队列:Redis Stream 可以用作高性能的消息队列。生产者可以将消息添加到流中,消费者可以从流中读取消息进行处理。它支持消费者组的概念,多个消费者可以组成一个组共同消费消息,并且可以记录每个消费者组的消费进度,确保消息不会被重复消费或遗漏。
- 有序日志记录:Stream 中的消息是有序的,每个消息都有一个唯一的 ID,格式为时间戳-序列号,时间戳精确到毫秒,序列号用于区分同一毫秒内的不同消息。 这个 ID 按照添加的顺序递增,这使得它非常适合用于记录系统的操作日志、事件日志等。
- 消息持久化:Redis Stream 通过 AOF 和 RDB 机制持久化消息,AOF 将写操作追加到日志文件,RDB 定期对数据进行快照。此外,Redis Cluster 模式下,Stream 数据会分布在多个节点,通过复制和故障转移机制保证高可用性。
- 消费消息:支持多种消费模式。XREAD命令用于读取消息,可从 Stream 头部或指定 ID 开始读取;XREADGROUP用于基于消费者组的消费,消费者组可让多个消费者协作处理消息,每个消费者组有唯一名称,组内消费者可独立记录消费进度。
Redis Stream 为处理消息队列和日志记录等场景提供了一种高效、可靠且灵活的解决方案,在分布式系统、微服务架构等中得到了广泛的应用。
1. 消息 ID 的生成规则
Redis Stream 的消息 ID 是消息的唯一标识,格式为时间戳-序列号,在消息管理、消费进度跟踪和消息排序等方面发挥关键作用。
-
消息 ID 格式:消息 ID 由两部分组成,即毫秒级时间戳和序列号,中间用-分隔。例如 1698824523123-0,其中1698824523123代表消息添加的时间戳,0为序列号,这意味着它是该毫秒内添加的第一条消息,1698824523123-1 则代表它是该毫秒内添加的第二条消息。
- 时间戳表示消息被添加到 Stream 的大致时间,精确到毫秒,它是个64位整型(int64)
- 序列号用于区分在同一毫秒内添加到 Stream 中的不同消息,它也是个64位整型。
由于一个redis命令的执行很快,所以在同一时间戳内,是通过序号递增来表示消息的。为了保证消息是有序的,因此Redis生成的ID是单调递增有序的。由于ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis的每个Stream类型数据都维护一个latest_generated_id属性,用于记录最后一个消息的ID。若发现当前时间戳退后(小于latest_generated_id所记录的),则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。
-
生成机制:当使用XADD命令向 Stream 添加消息时,若使用
*作为消息 ID 参数,Redis 会自动生成消息 ID。时间戳部分取自服务器当前时间的毫秒表示,序列号在同一毫秒内从0开始递增。若手动指定消息 ID,需确保格式正确且大于 Stream 中已有的最大消息 ID(部分场景下可用于特定消息插入或覆盖)。 -
唯一性保障:时间戳精确到毫秒,在不同时间添加的消息,其时间戳部分不同,消息 ID 自然不同。即使在同一毫秒内,序列号也会递增,保证同一毫秒内消息 ID 的唯一性。在高并发场景下,大量消息可能在同一毫秒到达,序列号的递增机制能确保每个消息都有唯一 ID。
2. 基础命令
2.1 向 Stream 中添加消息(XADD)
XADD 命令用于向指定的 Stream 中添加消息。每条消息由一个或多个字段 - 值对组成,并且会自动分配一个唯一的消息 ID。
# 向名为 mystream 的 Stream 中添加一条消息,自动生成消息 ID
XADD mystream * k1 v1 k2 v2
在上述命令中:
mystream是 Stream 的名称*表示让 Redis 自动生成消息 ID,k1 v1 k2 v2是消息的字段 - 值对。
命令执行结束后会返回当前消息的一个唯一ID,如下:

2.2 从 Stream 中读取消息(XREAD)
XREAD 命令用于从一个或多个 Stream 中读取消息。你可以指定从哪个消息 ID 开始读取,也可以设置阻塞模式等待新消息。
# 从 mystream 中读取从 $(表示最新消息之后)开始的新消息
XREAD BLOCK 0 STREAMS mystream $
在上述命令中
BLOCK 0表示无限期阻塞,直到有新消息到来;STREAMS后面跟着 Stream 名称 (mystream)$表示 起始消息 ID :使用 0 表示从第一条消息开始。在阻塞模式中,可以使用$,表示最新的消息ID。需要注意的是:在非阻塞模式下 $ 无意义,且消息队列ID是单调递增的,所以通过设置起点,可以向后读取。
XREAD 具体操作如下:
-
基本读取操作:在非阻塞模式下,XREAD从指定Stream的指定消息 ID 位置开始读取消息。若 ID 为0,表示从 Stream 起始位置读取;若为$,则从最新消息之后的位置读取(即获取新消息)。例如从mystream的起始位置读取消息:
XREAD STREAMS mystream 0 -
指定读取数量:COUNT参数用于限定读取消息的数量。比如从mystream中最多读取 3 条消息:
XREAD COUNT 3 STREAMS mystream 0 -
阻塞读取:BLOCK参数可使XREAD进入阻塞模式。设置的milliseconds为阻塞等待新消息的时长(单位毫秒),若设置为0,则无限期阻塞,直到有新消息到来。假设阻塞等待mystream中的新消息,最长等待 5000 毫秒:
XREAD BLOCK 5000 STREAMS mystream $ -
多 Stream 读取:XREAD能同时读取多个Stream的消息。例如从stream1和stream2中读取消息:
XREAD STREAMS stream1 0 stream2 0
2.3 创建消费者组(XGROUP CREATE)
XGROUP CREATE 命令用于为指定的 Stream 创建一个消费者组。消费者组可以让多个消费者协作处理消息。
消费者组是 Redis Stream 提供的一种消息消费模式,多个消费者可以组成一个消费者组,共同消费同一个 Stream 中的消息。每个消费者组都有一个唯一的名称,消费者组中的每个消费者会独立记录自己消费的消息偏移量。
# 为 mystream 创建一个名为 mygroup 的消费者组,从 $(最新消息之后)开始消费
XGROUP CREATE mystream mygroup $
在上述命令中
mystream mygroup表示 为 mystream 创建一个名为 mygroup 的消费者组(如果 mystream 不存在则会一并创建)$表示从 $(最新消息之后)开始消费,如果是 0,则表示该组从第一条消息开始消费。(意义与XREAD的0一致)
2.4 从消费者组中消费消息(XREADGROUP)
XREADGROUP 命令用于从指定的消费者组中消费消息。
# 从 mygroup 消费者组中,以 myconsumer 消费者的身份从 mystream 中读取消息
XREADGROUP GROUP mygroup myconsumer COUNT 1 STREAMS mystream >
在上述命令中:
GROUP mygroup myconsumer中 GROUP 后面跟着消费者组名称和消费者名称;COUNT 1表示每次读取一条消息>表示读取未被该消费者组处理过的最新消息。
2.5 确认消息已处理(XACK)
XACK 命令用于确认指定消费者组中的消息已被处理。
# 确认 mygroup 消费者组中 ID 为 1640995200000-0 的消息已处理
XACK mystream mygroup 1640995200000-0
在上述命令中:
mystream mygroup表示 mystream 的 mygroup 消费者组1640995200000-0表示从 ID 为该值的消息被 ACK。
2.6 查看 Stream 信息(XLEN、XINFO)
-
XLEN 命令用于获取指定 Stream 中的消息数量。
# 获取 mystream 中的消息数量 XLEN mystream -
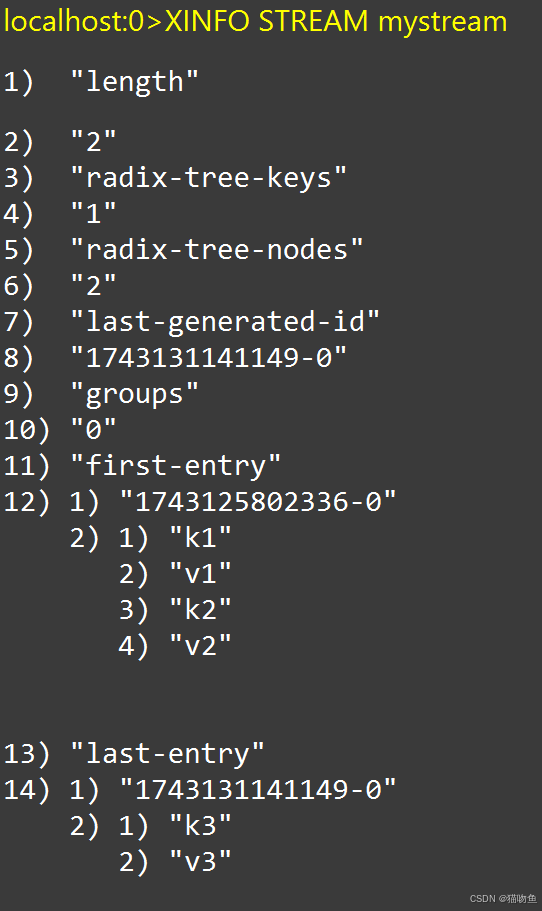
XINFO 命令用于获取 Stream 或消费者组的详细信息.
# 获取 mystream 的详细信息 XINFO STREAM mystream # 获取 mygroup 消费者组的详细信息 XINFO GROUPS mystream如下图:
2.7 删除消息(XDEL)
XDEL 命令用于从指定的 Stream 中删除指定 ID 的消息。
# 从 mystream 中删除 ID 为 1640995200000-0 的消息
XDEL mystream 1640995200000-0
2.8 修剪 Stream(XTRIM)
XTRIM 命令用于修剪 Stream,只保留指定数量的最新消息。
# 修剪 mystream,只保留最新的 100 条消息
XTRIM mystream MAXLEN 100
在使用 XTRIM 命令时需要考虑到下面几点:
- 数据丢失:修剪操作会删除 Stream 中的旧消息,这可能导致数据丢失。在执行修剪操作前,务必充分考虑业务需求,明确哪些数据可以安全删除。
- 性能与精度平衡:使用近似修剪(approximateTrimming 为 true)可以提高性能,但修剪结果可能不够精确;而精确修剪(approximateTrimming 为 false)能保证结果的准确性,但在处理大规模 Stream 时可能会影响性能。需要根据实际情况权衡使用。
在 Spring 中 RedisTemplate 也提供了相应的方法来完成修剪。如下:
redisTemplate.getRedisTemplate().opsForStream().trim()
这里 tirm 方法存在两个重载方法,如下:
/**
/* key:代表 Redis Stream 的键名。
/* count:表示修剪后 Stream 允许保留的最大消息数量。
/* 返回值:返回被删除的消息数量。
*/
@Nullable
Long trim(K key, long count);
/**
/* key:代表 Redis Stream 的键名。
/* count:表示修剪后 Stream 允许保留的最大消息数量。
/* approximateTrimming:一个布尔值,用于决定是否使用近似修剪。当设置为 true 时,Redis 会采用近似修剪策略,这能提高修剪操作的性能,但修剪结果可能不会精确到指定的消息数量;当设置为 false 时,Redis 会精确地将 Stream 修剪到指定的消息数量。
/* 返回值:返回被删除的消息数量。
*/
@Nullable
Long trim(K key, long count, boolean approximateTrimming);
三、消费模式
1. 独立消费
独立消费指的是脱离消费组的直接消费 Stream 中的消息,是使用 xread 方法读取流中的数据,流中的数据在读取后并不会被删除,还是存在的。如果多个程序同时使用xread读取,都是可以读取到消息的。
需要注意的是,XREAD 是 Redis Stream 用于从流中读取消息的命令,它单纯地负责获取消息,因此使用该种方式读取消息会失去消息队列的一些特性,如:
- 不支持消费者组的消息唯一性:XREAD读取时没有消费者组概念,所以如果多个程序同时使用xread读取,都是可以读取到消息的。
- 不支持消息的 ACK 特性 :Redis Stream 中消息确认机制主要与消费者组相关,消费者组中的消息确认操作是通过 XACK 命令来完成的。因此使用 XREAD 读取方式无法完成消息 ACK。
在 SpringBoot 中 独立消费方式消费消息的示例代码如下:
@Slf4j
@Component
public class RedisStreamUtil {
@Resource
private RedisTemplate<String, Object> redisTemplate;
@PostConstruct
public void init() {
// 消息生产者每隔 5s 投递一个消息
Executors.newSingleThreadScheduledExecutor()
.scheduleAtFixedRate(() -> {
final ObjectRecord<String, Book> record = StreamRecords.newRecord()
.in(Cosntants.STREAM_KEY_001)
.ofObject(new Book(DateUtil.now(), "test"))
.withId(RecordId.autoGenerate());
final RecordId recordId = redisTemplate.opsForStream()
.add(record);
log.info("[Redis 消息投递][recordId = {}]", recordId);
}, 0, 10, TimeUnit.SECONDS);
// 消息消费者
StreamReadOptions streamReadOptions = StreamReadOptions.empty()
// 如果没有数据,则阻塞1s 阻塞时间需要小于`spring.redis.timeout`配置的时间
.block(Duration.ofMillis(5000))
// 一直阻塞直到获取数据,可能会报超时异常
// .block(Duration.ofMillis(0))
// 1次获取10个数据
.count(10);
StringBuilder readOffset = new StringBuilder("0-0");
Executors.newSingleThreadExecutor()
.execute(() -> {
while (true) {
List<ObjectRecord<String, Book>> reads = redisTemplate.opsForStream()
.read(Book.class, streamReadOptions,
StreamOffset.create(
Cosntants.STREAM_KEY_001, ReadOffset.from(readOffset.toString())));
if (CollectionUtils.isEmpty(reads)) {
log.info("[Redis 消息消费][readOffset = {}, 没有获取到数据]", readOffset);
}
for (ObjectRecord<String, Book> read : reads) {
log.info("[Redis 消息消费][id = {}, book = {}]", read.getId(), read.getValue());
readOffset.setLength(0);
// 设置消息偏移量,下次获取消息从该 id 之后
readOffset.append(read.getId());
}
}
});
}
}
运行日志如下:

Redis 中消费后的消息仍存在,如下图:

可以看到通过 XREAD 方式可以正确读取处消息,但是这种方式如果作为一个消息队列明显是不合适的,缺少了很多特性,因此还存在一种消费者组消费的方式,详见下面【消费者组】部分的内容。
2. 消费者组
XREAD 的方式如果作为一个消息队列明细是不合适的,因此Redis 提供了通过消费者组的方式来对 Stream 处理。Redis Stream 中的消费者组的概念在其他MQ 组件中也有类似实现(RocketMQ、Kafka 中的消费者组、RabbitMQ 中的 Queue 等),Redis Stream 中的消费者组实现了如下功能:
- 消息分配与负载均衡
- 消息分配:消费者组中的多个消费者可以共同消费同一个流中的消息。当有新消息进入流时,Redis 会将消息分配给组内的某个消费者进行处理。例如,在一个订单处理系统中,多个消费者可以同时处理订单消息,提高处理效率。
- 负载均衡:Redis 会自动在消费者组的各个消费者之间实现负载均衡,将消息均匀地分发给不同的消费者,避免某个消费者负载过重。比如,有三个消费者 consumer1、consumer2 和 consumer3 在同一个消费者组中,新消息会依次轮流分配给它们。
- 消息确认机制
- 消息状态跟踪:消费者组会跟踪每条消息的状态,当消息被分配给某个消费者后,该消息会被标记为 “已交付(pending)”,直到消费者使用 XACK 命令确认消息已处理完毕。例如,消费者从流中读取到一条消息后,在完成业务逻辑处理后调用 XACK 命令,将该消息从 pending 列表中移除。
- 避免消息丢失:通过消息确认机制,即使消费者在处理消息过程中出现故障,未确认的消息仍然会保留在 pending 列表中,待消费者恢复后可以继续处理,确保消息不会丢失。
- 消费进度记录
- 独立进度:每个消费者组都有自己独立的消费进度记录,不同的消费者组可以从流的不同位置开始消费消息。例如,有两个消费者组 group1 和 group2,group1 可以从流的第一条消息开始消费,而 group2 可以从流的中间某个位置开始消费。
- 持续消费:消费者组会记录每个消费者的消费进度,当消费者重启或重新连接时,可以从上次停止的位置继续消费消息,保证消息的连续处理。
- 消息重试机制
- 失败重试:如果消费者在处理消息时失败,可以不确认该消息,该消息会一直保留在 pending 列表中,Redis 会定期将这些未确认的消息重新分配给组内的其他消费者或原消费者进行重试。例如,在一个数据同步系统中,如果某个消费者在同步数据时出现网络异常导致失败,消息会被重新分配处理。
- 重试次数控制:虽然 Redis 本身没有直接提供重试次数的控制,但可以在应用层实现重试次数的限制,避免无限重试。
- 可扩展性
- 动态添加消费者:可以随时向消费者组中动态添加新的消费者,以应对流量高峰或提高处理能力。例如,在电商大促期间,可以临时增加消费者来处理大量的订单消息。
- 支持分布式系统:消费者组非常适合分布式系统,多个消费者可以分布在不同的节点上,共同处理流中的消息,提高系统的整体性能和可靠性。
- 消息历史回溯
- 指定位置消费:消费者组可以从流的任意位置开始消费消息,包括历史消息。通过指定消息 ID 作为起始位置,消费者可以回溯到之前的某个时间点开始处理消息。例如,在进行数据修复或数据分析时,可以从特定的历史消息开始重新处理。
在 SpringBoot 中消费者组方式消费消息的示例代码如下:(这里直接使用芋道源码封装好的内容):
-
准备工作 :定义各种扩展接口
/** * {@link AbstractRedisMessage} 消息拦截器 * 通过拦截器,作为插件机制,实现拓展。 * 例如说,多租户场景下的 MQ 消息处理 * * @author 芋道源码 */ public interface RedisMessageInterceptor { default void sendMessageBefore(AbstractRedisMessage message) { } default void sendMessageAfter(AbstractRedisMessage message) { } default void consumeMessageBefore(AbstractRedisMessage message) { } default void consumeMessageAfter(AbstractRedisMessage message) { } } /** * Redis 消息抽象基类 * * @author 芋道源码 */ @Data public abstract class AbstractRedisMessage { /** * 头 */ private Map<String, String> headers = new HashMap<>(); public String getHeader(String key) { return headers.get(key); } public void addHeader(String key, String value) { headers.put(key, value); } } /** * Redis Channel Message 抽象类 * * @author 芋道源码 */ public abstract class AbstractRedisChannelMessage extends AbstractRedisMessage { /** * 获得 Redis Channel,默认使用类名 * * @return Channel */ @JsonIgnore // 避免序列化。原因是,Redis 发布 Channel 消息的时候,已经会指定。 public String getChannel() { return getClass().getSimpleName(); } } -
创建一个 RedisTemplate 代理类,用于扩展 Redis Stream 相关功能
@AllArgsConstructor public class RedisMQTemplate { @Getter private final RedisTemplate<String, ?> redisTemplate; /** * 拦截器数组 */ @Getter private final List<RedisMessageInterceptor> interceptors = new ArrayList<>(); /** * 发送 Redis 消息,基于 Redis pub/sub 实现 * * @param message 消息 */ public <T extends AbstractRedisChannelMessage> void send(T message) { try { sendMessageBefore(message); // 发送消息 redisTemplate.convertAndSend(message.getChannel(), JSON.toJSONString(message)); } finally { sendMessageAfter(message); } } /** * 发送 Redis 消息,基于 Redis Stream 实现 * * @param message 消息 * @return 消息记录的编号对象 */ public <T extends AbstractRedisStreamMessage> RecordId send(T message) { try { sendMessageBefore(message); // 发送消息 return redisTemplate.opsForStream().add(StreamRecords.newRecord() .ofObject(JSON.toJSONString(message)) // 设置内容 .withStreamKey(message.getStreamKey())); // 设置 stream key } finally { sendMessageAfter(message); } } /** * 添加拦截器 * * @param interceptor 拦截器 */ public void addInterceptor(RedisMessageInterceptor interceptor) { interceptors.add(interceptor); } private void sendMessageBefore(AbstractRedisMessage message) { // 正序 interceptors.forEach(interceptor -> interceptor.sendMessageBefore(message)); } private void sendMessageAfter(AbstractRedisMessage message) { // 倒序 for (int i = interceptors.size() - 1; i >= 0; i--) { interceptors.get(i).sendMessageAfter(message); } } } -
创建 AbstractRedisStreamMessageListener 抽象类,在其中实现了消息拦截器的逻辑,用于各个消费者实现
/** * Redis Stream 监听器抽象类,用于实现集群消费 * * @param <T> 消息类型。一定要填写噢,不然会报错 * @author 芋道源码 */ public abstract class AbstractRedisStreamMessageListener<T extends AbstractRedisStreamMessage> implements StreamListener<String, ObjectRecord<String, String>> { /** * 消息类型 */ private final Class<T> messageType; /** * Redis Channel */ @Getter private final String streamKey; /** * Redis 消费者分组,默认使用 spring.application.name 名字 */ @Value("${spring.application.name}") @Getter private String group; /** * RedisMQTemplate */ @Setter private RedisMQTemplate redisMQTemplate; @SneakyThrows protected AbstractRedisStreamMessageListener() { this.messageType = getMessageClass(); this.streamKey = messageType.getDeclaredConstructor().newInstance().getStreamKey(); } @Override public void onMessage(ObjectRecord<String, String> message) { // 消费消息 T messageObj = JSON.parseObject(message.getValue(), messageType); try { consumeMessageBefore(messageObj); // 消费消息 this.onMessage(messageObj); // ack 消息消费完成 redisMQTemplate.getRedisTemplate().opsForStream().acknowledge(group, message); // TODO 芋艿:需要额外考虑以下几个点: // 1. 处理异常的情况 // 2. 发送日志;以及事务的结合 // 3. 消费日志;以及通用的幂等性 // 4. 消费失败的重试,https://zhuanlan.zhihu.com/p/60501638 } finally { consumeMessageAfter(messageObj); } } /** * 处理消息 * * @param message 消息 */ public abstract void onMessage(T message); /** * 通过解析类上的泛型,获得消息类型 * * @return 消息类型 */ @SuppressWarnings("unchecked") private Class<T> getMessageClass() { Type type = TypeUtil.getTypeArgument(getClass(), 0); if (type == null) { throw new IllegalStateException(String.format("类型(%s) 需要设置消息类型", getClass().getName())); } return (Class<T>) type; } private void consumeMessageBefore(AbstractRedisMessage message) { assert redisMQTemplate != null; List<RedisMessageInterceptor> interceptors = redisMQTemplate.getInterceptors(); // 正序 interceptors.forEach(interceptor -> interceptor.consumeMessageBefore(message)); } private void consumeMessageAfter(AbstractRedisMessage message) { assert redisMQTemplate != null; List<RedisMessageInterceptor> interceptors = redisMQTemplate.getInterceptors(); // 倒序 for (int i = interceptors.size() - 1; i >= 0; i--) { interceptors.get(i).consumeMessageAfter(message); } } } -
向容器中注入 StreamMessageListenerContainer 对象。
/** * 创建 Redis Stream 集群消费的容器 * <p> * 基础知识:<a href="https://www.geek-book.com/src/docs/redis/redis/redis.io/commands/xreadgroup.html">Redis Stream 的 xreadgroup 命令</a> */ @Bean(initMethod = "start", destroyMethod = "stop") @ConditionalOnBean(AbstractRedisStreamMessageListener.class) // 只有 AbstractStreamMessageListener 存在的时候,才需要注册 Redis pubsub 监听 public StreamMessageListenerContainer<String, ObjectRecord<String, String>> redisStreamMessageListenerContainer( RedisMQTemplate redisMQTemplate, List<AbstractRedisStreamMessageListener<?>> listeners) { RedisTemplate<String, ?> redisTemplate = redisMQTemplate.getRedisTemplate(); checkRedisVersion(redisTemplate); // 第一步,创建 StreamMessageListenerContainer 容器 // 创建 options 配置 StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String, ObjectRecord<String, String>> containerOptions = StreamMessageListenerContainer.StreamMessageListenerContainerOptions.builder() .batchSize(10) // 一次性最多拉取多少条消息 .targetType(String.class) // 目标类型。统一使用 String,通过自己封装的 AbstractStreamMessageListener 去反序列化 // .executor(executor) // 运行 Stream 的 poll task // .keySerializer(RedisSerializer.string()) // 可以理解为 Stream Key 的序列化方式 // .hashKeySerializer(RedisSerializer.string()) // 可以理解为 Stream 后方的字段的 key 的序列化方式 // .hashValueSerializer(RedisSerializer.string()) // 可以理解为 Stream 后方的字段的 value 的序列化方式 // .pollTimeout(Duration.ofSeconds(1)) // Stream 中没有消息时,阻塞多长时间,需要比 `spring.redis.timeout` 的时间小 // .objectMapper(new ObjectHashMapper()) // ObjectRecord 时,将 对象的 filed 和 value 转换成一个 Map 比如:将Book对象转换成map // .errorHandler(t -> log.error("发生了异常", t)) // 获取消息的过程或获取到消息给具体的消息者处理的过程中,发生了异常的处理 .build(); // 创建 container 对象 StreamMessageListenerContainer<String, ObjectRecord<String, String>> container = StreamMessageListenerContainer.create(redisMQTemplate.getRedisTemplate().getRequiredConnectionFactory(), containerOptions); // // 独立消费 // String streamKey = Cosntants.STREAM_KEY_001; // container .receive(StreamOffset.fromStart(streamKey), // new AsyncConsumeStreamListener("独立消费", null, null)); // // // 消费组A,不自动ack // // 从消费组中没有分配给消费者的消息开始消费 // container .receive(Consumer.from("group-a", "consumer-a"), // StreamOffset.create(streamKey, ReadOffset.lastConsumed()), new AsyncConsumeStreamListener("消费组消费", "group-a", "consumer-a")); // // 从消费组中没有分配给消费者的消息开始消费 // container .receive(Consumer.from("group-a", "consumer-b"), // StreamOffset.create(streamKey, ReadOffset.lastConsumed()), new AsyncConsumeStreamListener("消费组消费A", "group-a", "consumer-b")); // // // 消费组B,自动ack // container .receiveAutoAck(Consumer.from("group-b", "consumer-a"), // StreamOffset.create(streamKey, ReadOffset.lastConsumed()), new AsyncConsumeStreamListener("消费组消费B", "group-b", "consumer-bb")); // 第二步,注册监听器,消费对应的 Stream 主题 String consumerName = buildConsumerName(); listeners.parallelStream().forEach(listener -> { log.info("[redisStreamMessageListenerContainer][开始注册 StreamKey({}) 对应的监听器({})]", listener.getStreamKey(), listener.getClass().getName()); // 创建 listener 对应的消费者分组 try { redisTemplate.opsForStream().createGroup(listener.getStreamKey(), listener.getGroup()); } catch (Exception ignore) { } // 设置 listener 对应的 redisTemplate listener.setRedisMQTemplate(redisMQTemplate); // 创建 Consumer 对象 Consumer consumer = Consumer.from(listener.getGroup(), consumerName); // 设置 Consumer 消费进度,以最小消费进度为准 StreamOffset<String> streamOffset = StreamOffset.create(listener.getStreamKey(), ReadOffset.lastConsumed()); // 设置 Consumer 监听 StreamMessageListenerContainer.StreamReadRequestBuilder<String> builder = StreamMessageListenerContainer.StreamReadRequest .builder(streamOffset).consumer(consumer) .autoAcknowledge(false) // 不自动 ack .cancelOnError(throwable -> false); // 默认配置,发生异常就取消消费,显然不符合预期;因此,我们设置为 false container.register(builder.build(), listener); log.info("[redisStreamMessageListenerContainer][完成注册 StreamKey({}) 对应的监听器({})]", listener.getStreamKey(), listener.getClass().getName()); }); return container; } /** * 构建消费者名字,使用本地 IP + 进程编号的方式。 * 参考自 RocketMQ clientId 的实现 * * @return 消费者名字 */ private static String buildConsumerName() { return String.format("%s@%d", SystemUtil.getHostInfo().getAddress(), SystemUtil.getCurrentPID()); } /** * 校验 Redis 版本号,是否满足最低的版本号要求! */ private static void checkRedisVersion(RedisTemplate<String, ?> redisTemplate) { // 获得 Redis 版本 Properties info = redisTemplate.execute((RedisCallback<Properties>) RedisServerCommands::info); String version = MapUtil.getStr(info, "redis_version"); // 校验最低版本必须大于等于 5.0.0 int majorVersion = Integer.parseInt(StrUtil.subBefore(version, '.', false)); if (majorVersion < 5) { throw new IllegalStateException(StrUtil.format("您当前的 Redis 版本为 {},小于最低要求的 5.0.0 版本!", version)); } } -
编写具体监听类, 当调用 “/redis/stream/sendMessage” 时 TestRedisStreamMessageListener 会收到 MQ 中的消息
@Slf4j @Component public class TestRedisStreamMessageListener extends AbstractRedisStreamMessageListener<TestRedisStreamMessageListener.TestMessage> { @Override public void onMessage(TestMessage message) { log.info("[收到 Redis Stream 消息内容 : {}]", message.message); } @Data public static class TestMessage extends AbstractRedisStreamMessage { private String message; public TestMessage() { } public TestMessage(String message) { this.message = message; } } } @RestController @RequestMapping("/redis/stream") public class RedisStreamController { @Resource private RedisMQTemplate redisMQTemplate; @PostMapping("sendMessage") public String sendMessage(String message) { return redisMQTemplate.send(new TestRedisStreamMessageListener.TestMessage(message)).getValue(); } }消息接收如下图:

3. StreamListener 简析
Redis Stream 并不是 推 方式将消息发送给消费者,而是靠消费者主动 拉 消息,不过可以通过阻塞操作模拟出类似推(Push)的效果。那么既然本质上是 拉 消息, 自然是有一个循环或者定时任务在不停拉取消息的。
在上述代码中 spring-boot-starter-data-redis 为我们提供了一个 org.springframework.data.redis.stream.StreamListener 接口,我们只需要实现这个接口就可以完成Redis Stream 的监听。因此,循着 StreamListener 我们可以找到 org.springframework.data.redis.stream.StreamPollTask,在其中存在如下方法:
@Override
public void run() {
// 启动轮询状态,将状态设置为 starting
pollState.starting();
try {
// 标记当前线程处于事件循环中
isInEventLoop = true;
// 将轮询状态设置为 running,表示事件循环正在运行
pollState.running();
// 执行事件循环的核心逻辑
doLoop();
} finally {
// 事件循环结束,标记当前线程不在事件循环中
isInEventLoop = false;
}
}
private void doLoop() {
do {
try {
// 允许线程被中断
Thread.sleep(0);
// 从 Redis Stream 中读取消息记录
List<ByteRecord> raw = readRecords();
// 反序列化消息记录并将其发送出去进行处理
deserializeAndEmitRecords(raw);
} catch (InterruptedException e) {
// 若线程被中断,取消订阅
cancel();
// 重新设置中断状态,以便上层代码可以感知到中断
Thread.currentThread().interrupt();
} catch (RuntimeException e) {
// 根据异常情况判断是否取消订阅
if (cancelSubscriptionOnError.test(e)) {
cancel();
}
// 调用错误处理程序处理异常
errorHandler.handleError(e);
}
} while (pollState.isSubscriptionActive());
}
private List<ByteRecord> readRecords() {
// 这里的 readFunction 是从 org.springframework.data.redis.stream.DefaultStreamMessageListenerContainer#getReadFunction 方法获取的
return readFunction.apply(pollState.getCurrentReadOffset());
}
这里的 org.springframework.data.redis.stream.DefaultStreamMessageListenerContainer#getReadFunction,其实现如下
private Function<ReadOffset, List<ByteRecord>> getReadFunction(StreamReadRequest<K> streamRequest) {
// 将 StreamReadRequest 中的流键进行序列化
byte[] rawKey = ((RedisSerializer<K>) template.getKeySerializer())
.serialize(streamRequest.getStreamOffset().getKey());
// 判断请求是否为消费者组读取请求
if (streamRequest instanceof StreamMessageListenerContainer.ConsumerStreamReadRequest) {
// 将请求转换为消费者组读取请求类型
ConsumerStreamReadRequest<K> consumerStreamRequest = (ConsumerStreamReadRequest<K>) streamRequest;
// 根据是否自动确认消息,选择合适的读取选项
StreamReadOptions readOptions = consumerStreamRequest.isAutoAcknowledge() ? this.readOptions.autoAcknowledge()
: this.readOptions;
// 获取消费者信息
Consumer consumer = consumerStreamRequest.getConsumer();
// 返回一个函数,用于从消费者组中读取消息
return (offset) -> template.execute((RedisCallback<List<ByteRecord>>) connection -> connection.streamCommands()
.xReadGroup(consumer, readOptions, StreamOffset.create(rawKey, offset)));
}
// 如果不是消费者组读取请求,返回一个普通读取消息的函数
return (offset) -> template.execute((RedisCallback<List<ByteRecord>>) connection -> connection.streamCommands()
.xRead(readOptions, StreamOffset.create(rawKey, offset)));
}
总的来说:StreamListener 就是 Spring 框架帮我们封装好了消息拉取的逻辑。
四、Redis Stream 配置项
1. 常用配置项
在上面,通过 StreamMessageListenerContainer.StreamMessageListenerContainerOptions 各项属性来为 StreamMessageListenerContainer 设置各种配置项,下面是常见几个配置项的作用:
1.1 pollTimeout
-
作用 :设置轮询 Redis Stream 以获取新消息的超时时间。当达到该超时时间后,如果没有新消息,轮询操作会返回,然后再次进行轮询。
-
示例:下面代码将轮询超时时间设置为 100 毫秒,意味着每隔 100 毫秒检查一次是否有新消息。
StreamMessageListenerContainerOptions<String, ?> options = StreamMessageListenerContainerOptions.builder() .pollTimeout(Duration.ofMillis(100)) .build(); -
注意:StreamMessageListenerContainerOptions#pollTimeout 设置的时长不能超过配置 Redis 连接超时时间(
spring.redis.timeout),否则会抛出io.lettuce.core.RedisCommandTimeoutException: Command timed out after X second(s)异常
1.2 executor
- 作用:指定用于执行消息处理任务的线程池。通过设置线程池,可以控制消息处理的并发度,提高消息处理的效率。
- 示例:上述代码创建了一个固定大小为 5 的线程池,并将其配置到 StreamMessageListenerContainerOptions 中,这样就可以同时处理 5 条消息。
ExecutorService executorService = Executors.newFixedThreadPool(5); StreamMessageListenerContainerOptions<String, ?> options = StreamMessageListenerContainerOptions.builder() .executor(executorService) .build(); - 注意:下面【消息堆积】部分详解。
1.3 batchSize
- 作用:设置每次从 Redis Stream 中读取的消息数量。如果设置了该值,StreamMessageListenerContainer 会尝试一次性读取指定数量的消息,以减少与 Redis 的交互次数,提高性能。
- 示例:下面代码将每次读取的消息数量设置为 10 条。
StreamMessageListenerContainerOptions<String, ?> options = StreamMessageListenerContainerOptions.builder() .batchSize(10) .build(); - 注意:下面【等待列表】部分详解。
1.4 autoStartup
-
作用:设置 StreamMessageListenerContainer 是否在应用启动时自动启动。如果设置为 true,则容器会在应用启动时自动开始监听 Redis Stream;如果设置为 false,则需要手动调用 start() 方法来启动容器。
-
示例:下面代码将 autoStartup 设置为 false,表示容器不会在应用启动时自动启动。
StreamMessageListenerContainerOptions<String, ?> options = StreamMessageListenerContainerOptions.builder() .autoStartup(false) .build();
1.5 errorHandler
-
作用:指定消息处理过程中发生异常时的错误处理器。当消息处理过程中抛出异常时,errorHandler 会被调用,你可以在其中进行异常处理,如记录日志、重试等。
-
示例:下面代码定义了一个 StreamListenerErrorHandler,并将其配置到 StreamMessageListenerContainerOptions 中,当消息处理过程中发生异常时,会打印错误信息。
import org.springframework.data.redis.stream.StreamListenerErrorHandler; StreamListenerErrorHandler errorHandler = (message, exception) -> { // 处理异常 System.err.println("Error processing message: " + message + ", exception: " + exception.getMessage()); }; StreamMessageListenerContainerOptions<String, ?> options = StreamMessageListenerContainerOptions.builder() .errorHandler(errorHandler) .build();
2. 消息堆积
上面我们提到 StreamMessageListenerContainerOptions#executor 的作用指定用于执行消息处理任务的线程池。通过设置线程池,可以控制消息处理的并发度,提高消息处理的效率,需要注意,这个配置项并不能解决单一队列的消息堆积情况。
在 Redis Stream 中,容器中的每一个消费者(监听器)都是一个任务,而并非是每一条消息都是一个任务,Redis Stream 会为每个任务分配一个单独的线程来处理。
如下:我们可以通过 StreamMessageListenerContainer#receive 或 StreamMessageListenerContainer#register 注册监听器,(最后都会是调用 StreamMessageListenerContainer#register ),如下:
public Subscription register(StreamReadRequest<K> streamRequest, StreamListener<K, V> listener) {
// 1. getReadTask(streamRequest, listener) 将监听器封装成一个 Task
// 2. doRegister() 将 task 注册到 taskExecutor中
return doRegister(getReadTask(streamRequest, listener));
}
private Subscription doRegister(Task task) {
Subscription subscription = new TaskSubscription(task);
// 加锁,保证并非
synchronized (lifecycleMonitor) {
this.subscriptions.add(subscription);
// 确保 start() 方法执行结束
if (this.running) {
// 将封装好的监听器提交到 taskExecutor, taskExecutor就是我们通过
// StreamMessageListenerContainerOptions#executor 设置的执行器
taskExecutor.execute(task);
}
}
return subscription;
}
上面可以看到 Spring Redis Stream 将每个任务(监听器)当做一个任务执行(分配单独线程执行),也就是一个任务对应一个线程。那么就会存在,如果这个任务执行特别耗时,就会导致任务中的消息堆积。
在默认情况下,如果不配置 StreamMessageListenerContainerOptions#executor,那么默认使用的执行器是org.springframework.core.task.SimpleAsyncTaskExecutor。SimpleAsyncTaskExecutor 并不是池化实现,这意味着他不会重用线程,每次提交一个务,SimpleAsyncTaskExecutor 都会为其启动一个新线程,这意味着如果短时间内提交大量任务,可能会创建大量线程,对系统资源造成较大压力。虽然可以通过设置SimpleAsyncTaskExecutor#setConcurrencyLimit 属性来限制并发线程的数量,避免创建过多线程导致系统资源耗尽。但 StreamMessageListenerContainerOptionsBuilder(StreamMessageListenerContainerOptions 的构造器)并没有进行限制,因此可能任务过多时可能会导致资源被严重占用。因此我们可以通过 StreamMessageListenerContainerOptions#executor 配置项来指定一个线程池,通过线程复用的功能来减少资源占用,但这并不会提高消息的消费吞吐量,因此该造成堆积的情况还是会堆积。
以下面代码为例:(我们以上述【消费者组】的代码为基础)
- 构建 StreamMessageListenerContainer 时,我们的 StreamMessageListenerContainerOptions 配置如下(使用固定 5 个线程的线程池):
StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String, ObjectRecord<String, String>> containerOptions =
StreamMessageListenerContainer.StreamMessageListenerContainerOptions.builder()
.executor(Executors.newFixedThreadPool(5))
.pollTimeout(Duration.ofSeconds(3))
.batchSize(3) // 一次性最多拉取多少条消息
.targetType(String.class) // 目标类型。统一使用 String,通过自己封装的 AbstractStreamMessageListener 去反序列化
.build();
- 创建一个消息生产者,调用一次发送10条消息。
@PostMapping("sendMessage")
public String sendMessage(String message) {
for (int i = 0; i < 10; i++) {
redisMQTemplate.send(new HelloRedisStreamMessageListener.HelloMessage(message + "-" + i));
log.info("[消息发送][Hello {} 发送完毕]", message + "-" + i);
}
return "success";
}
-
监听器如下:
@Slf4j @Component public class HelloRedisStreamMessageListener extends AbstractRedisStreamMessageListener<HelloRedisStreamMessageListener.HelloMessage> { @SneakyThrows @Override public void onMessage(HelloMessage message) { log.info("[收到 Redis Stream 消息内容 : {}]", message.message); // 模拟业务处理耗时 Thread.sleep(5000); log.info("[结束 Redis Stream 消息内容 : {}]", message.message); } @Data public static class HelloMessage extends AbstractRedisStreamMessage { private String message; public HelloMessage() { ... } public HelloMessage(String message) { this.message = "hello : " + message; } } } -
当我们调用 sendMessage 接口时,会在一瞬间产生 10 条消息,如下图,消息消费具有明显滞后性(因为单线程的消费,
executor(Executors.newFixedThreadPool(5))的多线程配置并不适用于单个任务中的多条消息 ),如果消息量过大即使线程池中存在空闲线程仍会造成消息堆积。

因此,如果想要避免这种情况有两种方案:
- 在单一消费者中开启多线程处理消息,每条消息处理完成之后 ACK。
- 可以将一个监听器多次注册到 StreamMessageListenerContainer 中以注册多个 任务,实现多线程的消费。
需要注意这两种方案在不追加其他处理的情况下都无法保证消息的有序性。
3. 等待列表
在上面还存在一个 StreamMessageListenerContainerOptions#batchSize 参数,这个设置项是设置每次从 Redis Stream 中读取的消息数量。如果设置了该值,StreamMessageListenerContainer 会尝试一次性读取指定数量的消息,以减少与 Redis 的交互次数,提高性能。
那么这里存在一个问题:Redis Stream 是如何知道哪些消息被客户端拉取但是未 ACK 的呢?Redis 通过 内部的一个 Pending 列表还保存这些消息,用来保证消息的不丢失。
3.1 基本概念
当消费者组中的某个消费者使用 XREADGROUP 命令从 Redis Stream 中读取消息时,这些消息会被标记为已被该消费者组获取。在消费者调用 XACK 命令确认处理完这些消息之前,它们会一直存在于消费者组的 Pending 列表中。也就是说,Pending 列表记录了所有处于 “已获取但未确认” 状态的消息。
3.2 作用
- 保证消息不丢失:如果消费者在处理消息的过程中出现故障(例如崩溃、重启等),那么 Pending 列表中的消息不会被其他消费者获取和处理。当该消费者恢复后,它可以继续从 Pending 列表中获取未确认的消息并进行处理,从而保证消息不会因为消费者的故障而丢失。
- 消息处理跟踪:通过查看 Pending 列表,用户可以了解到消费者组中哪些消息正在被处理,哪些消息还未处理完成。这对于监控和管理消息处理流程非常有帮助。
- 消息重试机制:对于处理失败的消息,消费者可以不进行确认,这样消息就会一直保留在 Pending 列表中。之后,消费者可以在适当的时候重新处理这些消息,实现消息的重试机制。
3.3 相关命令
- XPENDING:该命令用于获取消费者组 Pending 列表的相关信息。例如,
XPENDING mystream mygroup可以获取名为 mystream 的 Stream 中 mygroup 消费者组的 Pending 列表信息,包括 Pending 消息的数量、最早的未确认消息 ID、最晚的未确认消息 ID 等。还可以通过一些可选参数获取更详细的信息,如指定消费者获取该消费者的 Pending 消息等。如
XPENDING key group [start end count] [consumer]- key:代表 Redis Stream 的名称,也就是消息流的标识。
- group:是消费者组的名称,用于对消费者进行分组管理。
- start 和 end:这两个参数用于指定消息 ID 的范围,- 表示最小的消息 ID,+ 表示最大的消息 ID。;
- count:指定要返回的 Pending 消息数量
consumer(可选):若指定了该参数,只会返回特定消费者的 Pending 消息。
- XPENDINGRANGE:用于获取 Pending 列表中指定范围内的消息。例如,
XPENDINGRANGE mystream mygroup <start-message-id> <end-message-id>可以获取 mystream 中 mygroup 消费者组的 Pending 列表中,消息 ID 在指定范围内的消息。 - XCLAIM:当某个消费者出现故障长时间未处理消息时,可以使用 XCLAIM 命令将 Pending 列表中的消息重新分配给其他消费者。例如,
XCLAIM mystream mygroup newconsumer <message-id>0 可以将 mystream 中 mygroup 消费者组的 Pending 列表中指定 message-id 的消息分配给 newconsumer 消费者。
3.4 示例
我们以下面代码为例:
- StreamMessageListenerContainer 配置 batchSize 一次拉取 5 条
StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String, ObjectRecord<String, String>> containerOptions =
StreamMessageListenerContainer.StreamMessageListenerContainerOptions.builder()
.executor(Executors.newFixedThreadPool(5))
.pollTimeout(Duration.ofSeconds(3))
.batchSize(5) // 一次性最多拉取多少条消息
.targetType(String.class) // 目标类型。统一使用 String,通过自己封装的 AbstractStreamMessageListener 去反序列化
.build();
-
HelloRedisStreamMessageListener 监听器处理消息
@Slf4j @Component public class HelloRedisStreamMessageListener extends AbstractRedisStreamMessageListener<HelloRedisStreamMessageListener.HelloMessage> { @SneakyThrows @Override public void onMessage(HelloMessage message) { log.info("[收到 Redis Stream 消息内容 : {}]", message.message); Thread.sleep(5000); log.info("[结束 Redis Stream 消息内容 : {}]", message.message); } @Data public static class HelloMessage extends AbstractRedisStreamMessage { private String message; public HelloMessage() { } public HelloMessage(String message) { this.message = "hello : " + message; } } } -
调用接口 投递 15 条消息到 HelloMessage 队列中
@PostMapping("sendMessage")
public String sendMessage(String message) {
for (int i = 0; i < 15; i++) {
redisMQTemplate.send(new HelloRedisStreamMessageListener.HelloMessage(message + "-" + i));
log.info("[消息发送][Hello {} 发送完毕]", message + "-" + i);
}
return "success";
}
-
通过命令行(
XPENDING {StreamKey} {Consume Group})查看 Pending 队列中的数据,如下:# step1: 开始拉取 5 条消息准备消费 127.0.0.1:0>XPENDING HelloMessage group-01 1) "5" # 5个已读取但未处理的消息 2) "1743399579740-0" # 起始ID 3) "1743399579744-0" # 结束ID 4) 1) 1) "192.168.72.1@11968" # 消费者组 192.168.72.1 (代码以机器 IP 为消费者组名称) 有5条读取的消息但未消费 2) "5" # step2: 还剩 2 条消息未消费 127.0.0.1:0>XPENDING HelloMessage group-01 1) "2" 2) "1743399579743-0" 3) "1743399579744-0" 4) 1) 1) "192.168.72.1@11968" 2) "2" # step3: 前面拉取的 5 条消息消费完成,重新拉取 127.0.0.1:0>XPENDING HelloMessage group-01 1) "5" 2) "1743399579744-1" 3) "1743399579746-1" 4) 1) 1) "192.168.72.1@11968" 2) "5" # step4: 所有消息消费完成 127.0.0.1:0>XPENDING HelloMessage group-01 1) "0" 2) null 3) null 4) null
上面我们已经看到 Pending 列表中保存了那些被客户端拉取但是还没有 ACK的消息。
4. 消息转移
经过上面的分析,我们知道了 Pending 列表中保存了那些被客户端拉取但是还没有 ACK的消息。假设 StreamMessageListenerContainerOptions#batchSize 设置为 5,那么一次性会从 Redis 中拉取 5条消息,如果此时客户端在消费了1条消息后宕机,那这一批次剩余的4条消息应当如何处理?
我们可以通过 Pending 命令来查看这一批消息的详情,如下:
127.0.0.1:0>XPENDING HelloMessage group-01 - + 10
1) 1) "1743400572893-1" # 消息ID
2) "192.168.72.1@11968" # 所属消费者
3) "31869" # IDLE,已读取时长
4) "1" # delivery counter,消息被读取次数
2) 1) "1743400572893-2"
2) "192.168.72.1@11968"
3) "31869"
4) "1"
3) 1) "1743400572894-0"
2) "192.168.72.1@11968"
3) "31869"
4) "1"
4) 1) "1743400572894-1"
2) "192.168.72.1@11968"
3) "31869"
4) "1"
执行上面命令后,Redis 会返回一个列表,列表中的每个元素代表一条 Pending 消息,包含以下信息:
- 消息 ID:消息在 Stream 中的唯一标识。
- 消费者名称:获取该消息的消费者的名称。
- 消息被获取的时间(以毫秒为单位):记录消息被消费者获取的时间。被转移的消息的IDLE会被重置,用以保证不会被重复转移,以为可能会出现将过期的消息同时转移给多个消费者的并发操作,设置了IDLE
- 消息被获取的次数:统计该消息被消费者获取的次数(消息转移也算一次),这在消息重试等场景中很有用。
通过 Pending 命令,我们可以很清楚的知道哪些消息被客户端读取了多久但仍未 ACK ,并对其中处理时间过长的消息进行消息转移。
4.1 基本概念
消息转移的操作是将某个消费者A Pending 列表中的消息转移到另一个消费者B 的Pending 列表中。这样当消费者 A 因为异常原因宕机后,可以由消费者 B 来接收处理消费者 A 的 Pending 列表中的消息
4.2 基本操作
XCLAIM 是 Redis 里用于操作消费者组 Pending 列表的命令,借助它可以将 Pending 列表中的消息重新分配给其他消费者,从而实现消息转移。下面从命令介绍、操作步骤、示例代码等方面详细讲解如何使用 XCLAIM 实现 Pending 列表的消息转移。
XCLAIM 格式如下:
XCLAIM key group new_consumer min-idle-time message-id [message-id ...] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [FORCE] [JUSTID]
- key:Redis Stream 的名称。
- group:消费者组的名称。
- new_consumer:接收转移消息的新消费者名称。
- min-idle-time:消息在 Pending 列表中处于空闲状态的最小毫秒数,只有满足该条件的消息才会被转移。
- message-id:要转移的消息的 ID,可以指定多个。
- IDLE ms(可选):设置转移后消息的空闲时间。
- TIME ms-unix-time(可选):设置转移后消息的最后活跃时间。
- RETRYCOUNT count(可选):设置转移后消息的重试次数。
- FORCE(可选):即使消息不在 Pending 列表中,也尝试转移。
- JUSTID(可选):只返回转移的消息 ID,而不返回消息内容。
4.3 示例
基本操作流程如下:
# 查看 consumer1 的 Pending 列表
XPENDING orders order_processors - + 10 consumer1
# 假设查看到消息 ID 为 1609459200000-0 的消息在 Pending 列表中,且该消息已空闲 10000 毫秒
# 将该消息转移给 consumer2
XCLAIM orders order_processors consumer2 10000 1609459200000-0
实例如下:
# 查看 【group-01】 消费者 pending 列表中的消息
127.0.0.1:0>XPENDING HelloMessage group-01 - + 10
1) 1) "1743402647230-0"
2) "192.168.72.1@14584"
3) "4586"
4) "1"
2) 1) "1743402647231-0"
2) "192.168.72.1@14584"
3) "4586"
4) "1"
3) 1) "1743402647231-1"
2) "192.168.72.1@14584"
3) "4586"
4) "1"
4) 1) "1743402647232-0"
2) "192.168.72.1@14584"
3) "4586"
4) "1"
5) 1) "1743402647232-1"
2) "192.168.72.1@14584"
3) "4586"
4) "1"
# 将 消费者组 【group-01】中 Stream Key 为 【HelloMessage】的消息中,获取时间超过【4000】毫秒的消息ID为 【1743402647230-0】的消息,转移到消费者【HelloBakConsumer】中
127.0.0.1:0>XCLAIM HelloMessage group-01 HelloBakConsumer 4000 1743402647230-0
1) 1) "1743402647230-0"
2) 1) "payload"
2) "{"headers":{},"message":"hello : 晚上好-1","streamKey":"HelloMessage"}"
# 可以通过指定多个 MessageId 的方式实现批量转移
127.0.0.1:0>XCLAIM HelloMessage group-01 HelloBakConsumer 4000 1743402647231-0 1743402647231-1 1743402647232-0 1743402647232-1
1) 1) "1743402647231-0"
2) 1) "payload"
2) "{"headers":{},"message":"hello : 晚上好-2","streamKey":"HelloMessage"}"
2) 1) "1743402647231-1"
2) 1) "payload"
2) "{"headers":{},"message":"hello : 晚上好-3","streamKey":"HelloMessage"}"
3) 1) "1743402647232-0"
2) 1) "payload"
2) "{"headers":{},"message":"hello : 晚上好-4","streamKey":"HelloMessage"}"
4) 1) "1743402647232-1"
2) 1) "payload"
2) "{"headers":{},"message":"hello : 晚上好-5","streamKey":"HelloMessage"}"
# 消息转移后的数据
127.0.0.1:0>XPENDING HelloMessage group-01 - + 10
1) 1) "1743402647230-0"
2) "HelloBakConsumer"
3) "610669"
4) "3"
2) 1) "1743402647231-0"
2) "HelloBakConsumer"
3) "259790"
4) "2"
3) 1) "1743402647231-1"
2) "HelloBakConsumer"
3) "259790"
4) "2"
4) 1) "1743402647232-0"
2) "HelloBakConsumer"
3) "259790"
4) "2"
5) 1) "1743402647232-1"
2) "HelloBakConsumer"
3) "259790"
4) "2"
需要注意的是:上述操作是将 消费者组 【group-01】中,消费者名称为【192.168.72.1@14584】中 StreamKey为【HelloMessage】 的Pending 列表中的消息转移到了 消费者组 【group-01】中,消费者名称为【HelloBakConsumer】 中 StreamKey为【HelloMessage】的Pending 列表中。
但是对于 SpringBoot 来说,默认情况下,StreamMessageListenerContainer(Spring Data Redis 用于监听 Redis Stream 的容器) 会从它记录的偏移量(通常是上次消费的位置)开始继续消费消息,而不是主动去处理 Pending 列表中的消息。因此,如果在 SpringBoot 中操作 Redis Stream ,那么 【HelloBakConsumer】 并不会从自己的 Pending列表中拉取被转移过来的消息,所以如果想实现消息转移还需要在代码中编写处理。
当消费者启动或者重新上线时,若没有特殊配置,Spring Boot 中的 StreamMessageListenerContainer 会依据 ReadOffset 配置来决定从哪里开始消费消息。常见的 ReadOffset 配置有:
- ReadOffset.lastConsumed():从上次消费的位置继续消费新消息,不会处理 Pending 列表中的消息。
- ReadOffset.from(“0”):从 Stream 的起始位置开始消费所有消息,包括已经在 Pending 列表中的消息。
在 芋道源码 中,通过定时任务实现了 “消息转移” 的功能,其逻辑是从 Pending 列表中读取出需要转移的消息,重新投递到 Redis Stream 中,并将 Pending 列表中的消息 ACK 确认掉。具体实现如下:
/**
* 这个任务用于处理,crash 之后的消费者未消费完的消息
*/
@Slf4j
@AllArgsConstructor
public class RedisPendingMessageResendJob {
private static final String LOCK_KEY = "redis:pending:msg:lock";
/**
* 消息超时时间,默认 5 分钟
* <p>
* 1. 超时的消息才会被重新投递
* 2. 由于定时任务 1 分钟一次,消息超时后不会被立即重投,极端情况下消息5分钟过期后,再等 1 分钟才会被扫瞄到
*/
private static final int EXPIRE_TIME = 15 * 60;
private final List<AbstractRedisStreamMessageListener<?>> listeners;
private final RedisMQTemplate redisTemplate;
private final String groupName;
private final RedissonClient redissonClient;
/**
* 一分钟执行一次,这里选择每分钟的35秒执行,是为了避免整点任务过多的问题
*/
@Scheduled(cron = "35 * * * * ?")
public void messageResend() {
RLock lock = redissonClient.getLock(LOCK_KEY);
// 尝试加锁
if (lock.tryLock()) {
try {
execute();
} catch (Exception ex) {
log.error("[messageResend][执行异常]", ex);
} finally {
lock.unlock();
}
}
}
/**
* 执行清理逻辑
*
* @see <a href="https://gitee.com/zhijiantianya/ruoyi-vue-pro/pulls/480/files">讨论</a>
*/
private void execute() {
StreamOperations<String, Object, Object> ops = redisTemplate.getRedisTemplate().opsForStream();
listeners.forEach(listener -> {
PendingMessagesSummary pendingMessagesSummary = Objects.requireNonNull(ops.pending(listener.getStreamKey(), groupName));
// 每个消费者的 pending 队列消息数量
Map<String, Long> pendingMessagesPerConsumer = pendingMessagesSummary.getPendingMessagesPerConsumer();
pendingMessagesPerConsumer.forEach((consumerName, pendingMessageCount) -> {
log.info("[processPendingMessage][StreamKey = {}, 消费者({}) 消息数量({})]", listener.getStreamKey(), consumerName, pendingMessageCount);
// 每个消费者的 pending消息的详情信息
PendingMessages pendingMessages = ops.pending(listener.getStreamKey(), Consumer.from(groupName, consumerName), Range.unbounded(), pendingMessageCount);
if (pendingMessages.isEmpty()) {
return;
}
pendingMessages.forEach(pendingMessage -> {
// 获取消息上一次传递到 consumer 的时间,
long lastDelivery = pendingMessage.getElapsedTimeSinceLastDelivery().getSeconds();
if (lastDelivery < EXPIRE_TIME) {
return;
}
// 获取指定 id 的消息体
List<MapRecord<String, Object, Object>> records = ops.range(listener.getStreamKey(),
Range.of(Range.Bound.inclusive(pendingMessage.getIdAsString()), Range.Bound.inclusive(pendingMessage.getIdAsString())));
if (CollUtil.isEmpty(records)) {
return;
}
// 重新投递消息
redisTemplate.getRedisTemplate().opsForStream().add(StreamRecords.newRecord()
.ofObject(records.get(0).getValue()) // 设置内容
.withStreamKey(listener.getStreamKey()));
// ack 消息消费完成
redisTemplate.getRedisTemplate().opsForStream().acknowledge(groupName, records.get(0));
log.info("[processPendingMessage][消息({})重新投递成功]", records.get(0).getId());
});
});
});
}
}
5. Dead Letter
如果某个消息,不能被消费者处理,也就是不能被XACK,这是要长时间处于Pending列表中,即使被反复的转移给各个消费者也是如此。此时该消息的delivery counter就会累加,当累加到某个我们预设的临界值时,我们就认为是坏消息(也叫死信,DeadLetter,无法投递的消息),由于有了判定条件,我们将坏消息处理掉即可,删除即可。删除一个消息,使用XDEL语法:
XDEL key id [id ...]
各个参数如下:
- key:这是必需参数,代表 Redis Stream 的名称,也就是你要从中删除消息的 Stream。
- id:同样是必需参数,指的是要删除的消息的 ID。你可以同时指定多个消息 ID,这样就能一次性删除多条消息。
需要注意:这里只是删除了 Stream 中的消息,对于消费者对应 Pending 列表中的消息并未删除,如果需要删除,则需要通过 XACK 命令:
XACK key group id [id ...]
各个参数如下:
- key:此为必需参数,代表 Redis Stream 的名称,即你要操作的具体 Stream。
- group:同样是必需参数,指的是消费者组的名称,用于标识消息所属的消费者组。
- id:也是必需参数,代表要确认的消息的 ID。你可以同时指定多个消息 ID,从而一次性确认多条消息。
6. 自动清理
当 Redis Stream 中的消息被消费后仍会被保存在 Redis 中,因此随着时间流逝,消息数量可能越来越多,因此就可能需要删除策略。具体策略有如下几个方案
6.1 使用 XDEL 手动清理
XDEL 命令删除的是 Redis Stream 中的消息,并不会对 Pending 列表中的消息进行处理,因此我们还需要使用 XACK 命令将 Pending 列表中的消息确认掉。
-
XACK 命令的语法如下(XACK 命令会返回被成功确认的消息数量。):
XACK key group id [id ...]- key:此为必选参数,代表 Redis Stream 的名称,也就是你要操作的具体 Stream。
- group:同样是必选参数,指的是消费者组的名称,用于明确消息所属的消费者组。
- id:还是必选参数,代表要确认的消息的 ID。你可以同时指定多个消息 ID,从而一次性确认多条消息。
-
XDEL 命令的语法如下(XDEL 命令会返回被成功删除的消息数量。):
XDEL key id [id ...]
- key:这是一个必需参数,代表 Redis Stream 的名称,也就是你要对哪个 Stream 进行消息删除操作。
- id:同样是必需参数,它指的是要删除的消息的 ID。你可以一次性指定多个消息 ID,这样就能同时删除多条消息。
综上,使用 XDEL 命令删除 死信消息的分为两步:
# 先确认 Pending 列表中的消息
XACK key group id [id ...]
# 再删除 Stream 中的消息
XDEL key id [id ...]
为了保证消息消费和清理操作的原子性,可以使用 Lua 脚本。在脚本中,先处理消息、确认消息,然后删除消息。
lua 脚本示例:
-- KEYS[1] 是 Stream 名称
-- KEYS[2] 是消费者组名称
-- ARGV[1] 是消费者名称
-- ARGV[2] 是消息 ID
-- 确认消息
redis.call('XACK', KEYS[1], KEYS[2], ARGV[2])
-- 删除消息
redis.call('XDEL', KEYS[1], ARGV[2])
return 1
6.2 设置 Stream 最大长度
使用 XADD 命令的 MAXLEN 选项,在添加新消息时自动清理旧消息,保证 Stream 中的消息数量不超过指定的最大长度。
示例代码:
# 添加消息时设置最大长度为 100
XADD my_stream MAXLEN 100 * k1 v1 k2 v2
6.3 使用 XTRIM 修剪
XTRIM 命令用于修剪 Stream,只保留指定数量的最新消息。这个命令在上面我们已经介绍过了,这里不再说明。


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











