






传送门
SpringMVC的源码解析(精品)
Spring6的源码解析(精品)
SpringBoot3框架(精品)
MyBatis框架(精品)
MyBatis-Plus
SpringDataJPA
SpringCloudNetflix
SpringCloudAlibaba(精品)
Shiro
SpringSecurity
java的LOG日志框架
Activiti(敬请期待)
JDK8新特性
JDK9新特性
JDK10新特性
JDK11新特性
JDK12新特性
JDK13新特性
JDK14新特性
JDK15新特性
JDK16新特性
JDK17新特性
JDK18新特性
JDK19新特性
JDK20新特性
JDK21新特性
其他技术文章传送门入口
前言
本文第一代SpringCloudNetflix和第二代SpringCloudAlibaba都有讲解。参考尚硅谷周阳老师的资料。
下面文章不定期更新中。。。
SpringCloud服务注册中心
SpringCloud服务调用
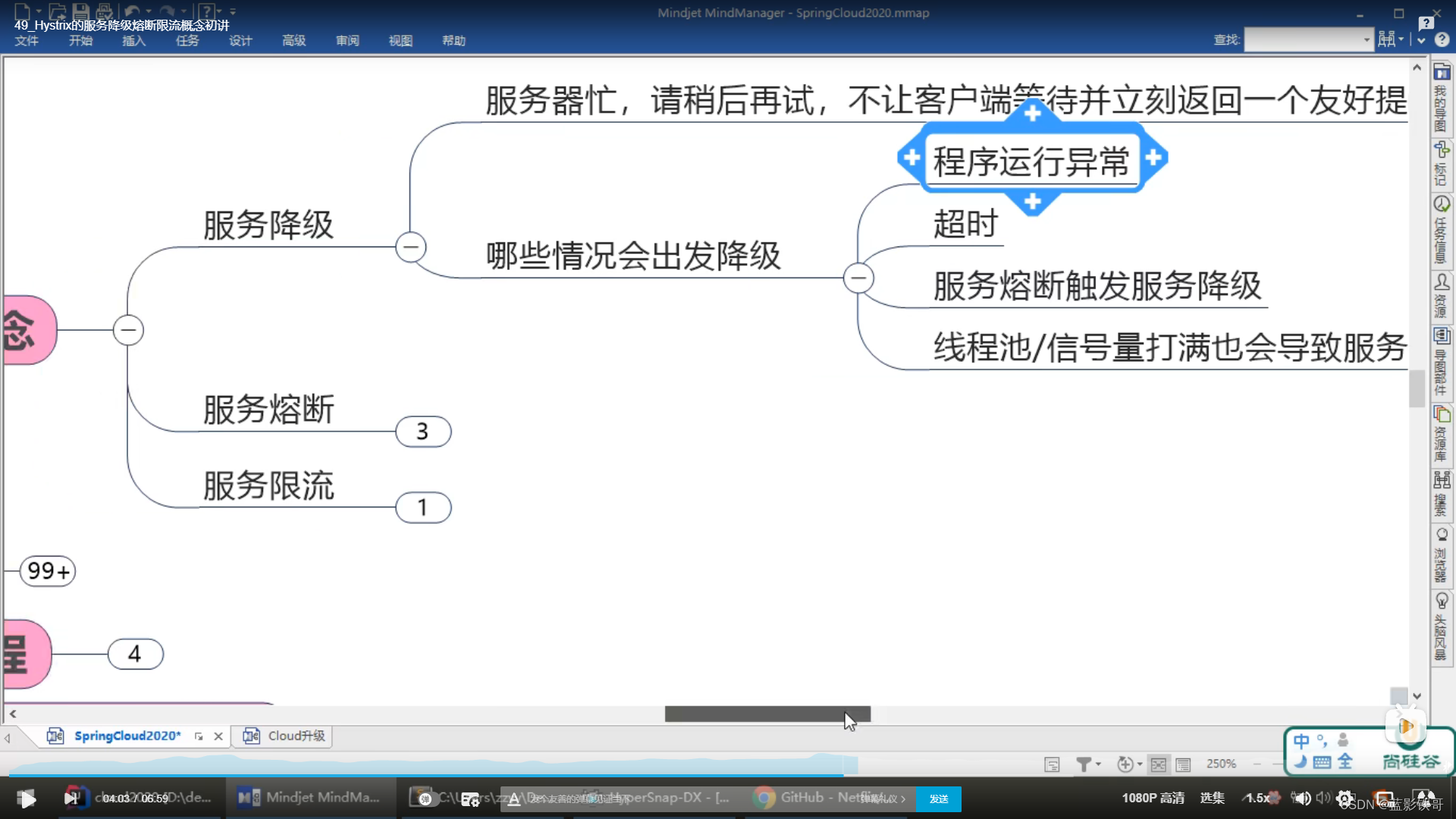
SpringCloud服务降级
SpringCloud服务网关
SpringCloud服务配置
SpringCloud服务总线
SpringCloud消息驱动
SpringCloud链路跟踪
SpringCloud分布式事务
总共两个服务降级:Hystrix、Sentinel
一、Hystrix
1、概念
Netflix公司停止更新了,但是由于设计太优秀了,出道既是巅峰,给后面框架提供了非常优秀的借鉴。
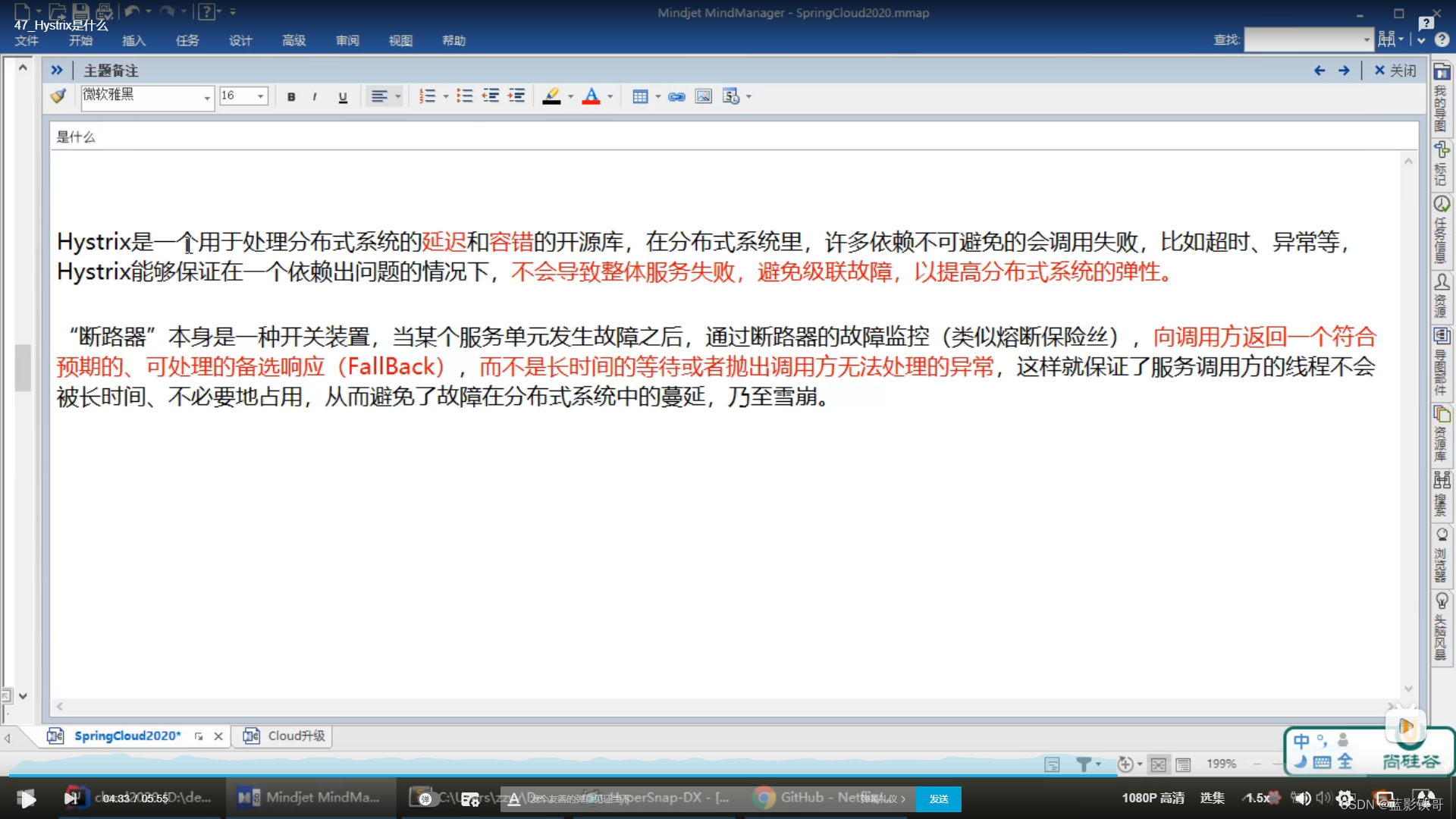
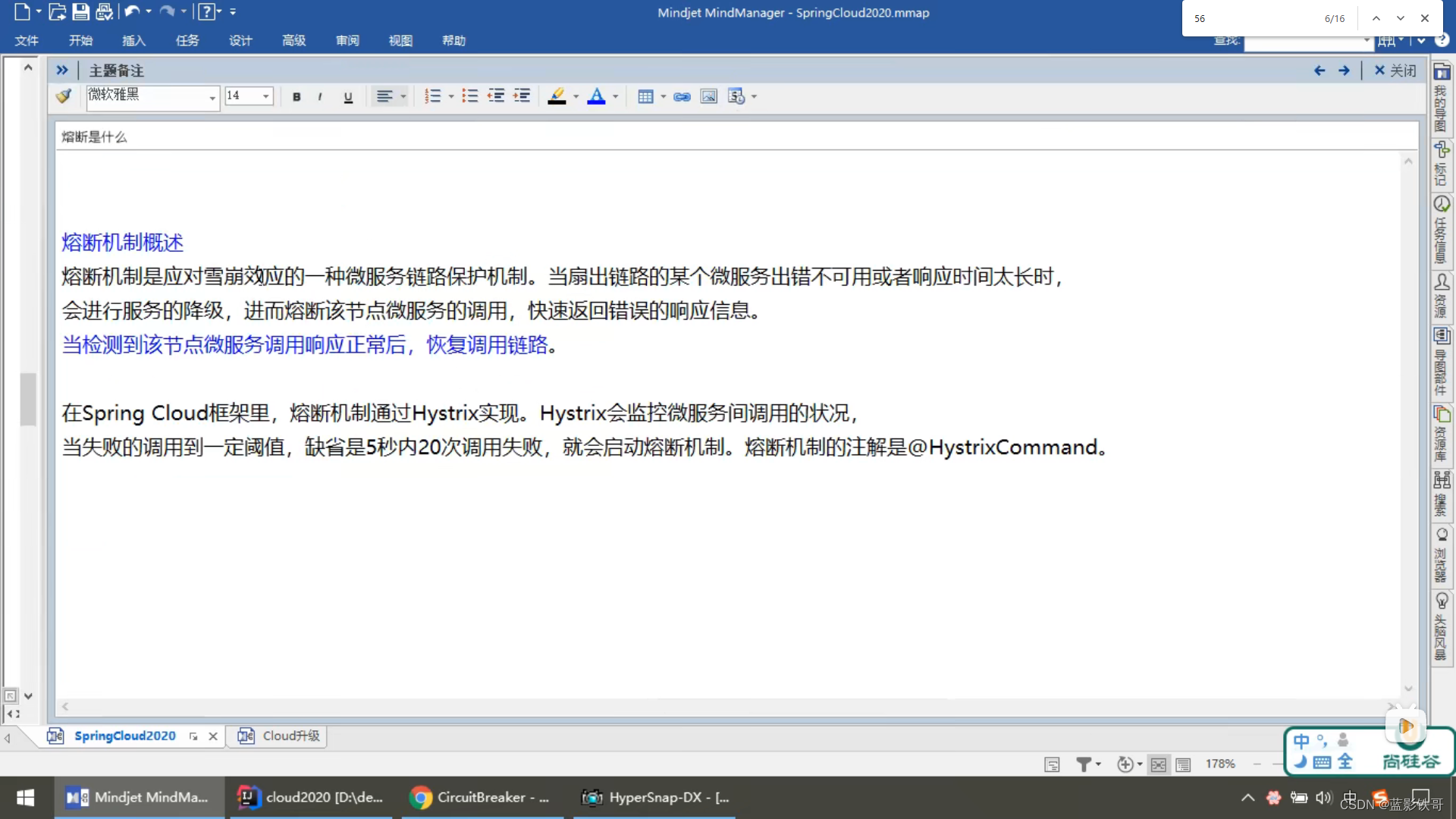
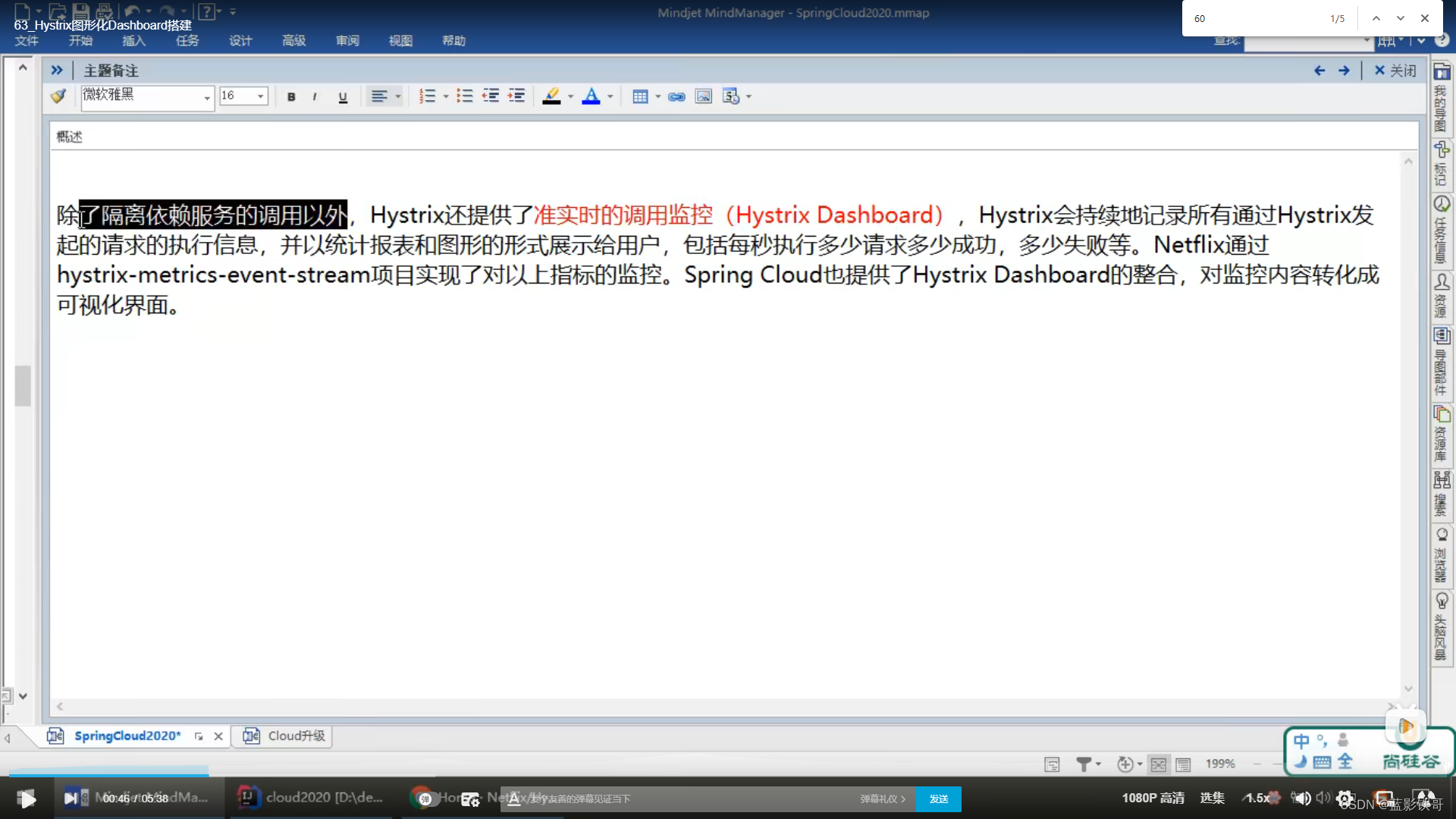
Hystrix是Netflix开源的一款用于处理分布式系统的延迟和容错的库。在Spring Cloud中,Hystrix被用于实现服务的容错保护和服务降级。它通过将每个服务包装在一个独立的线程池中,并根据配置的阈值来判断服务是否出现问题,从而实现服务的快速失败和降级。此外,Hystrix还提供了实时的监控、告警和仪表盘功能,帮助开发人员实时了解服务的状态和性能。
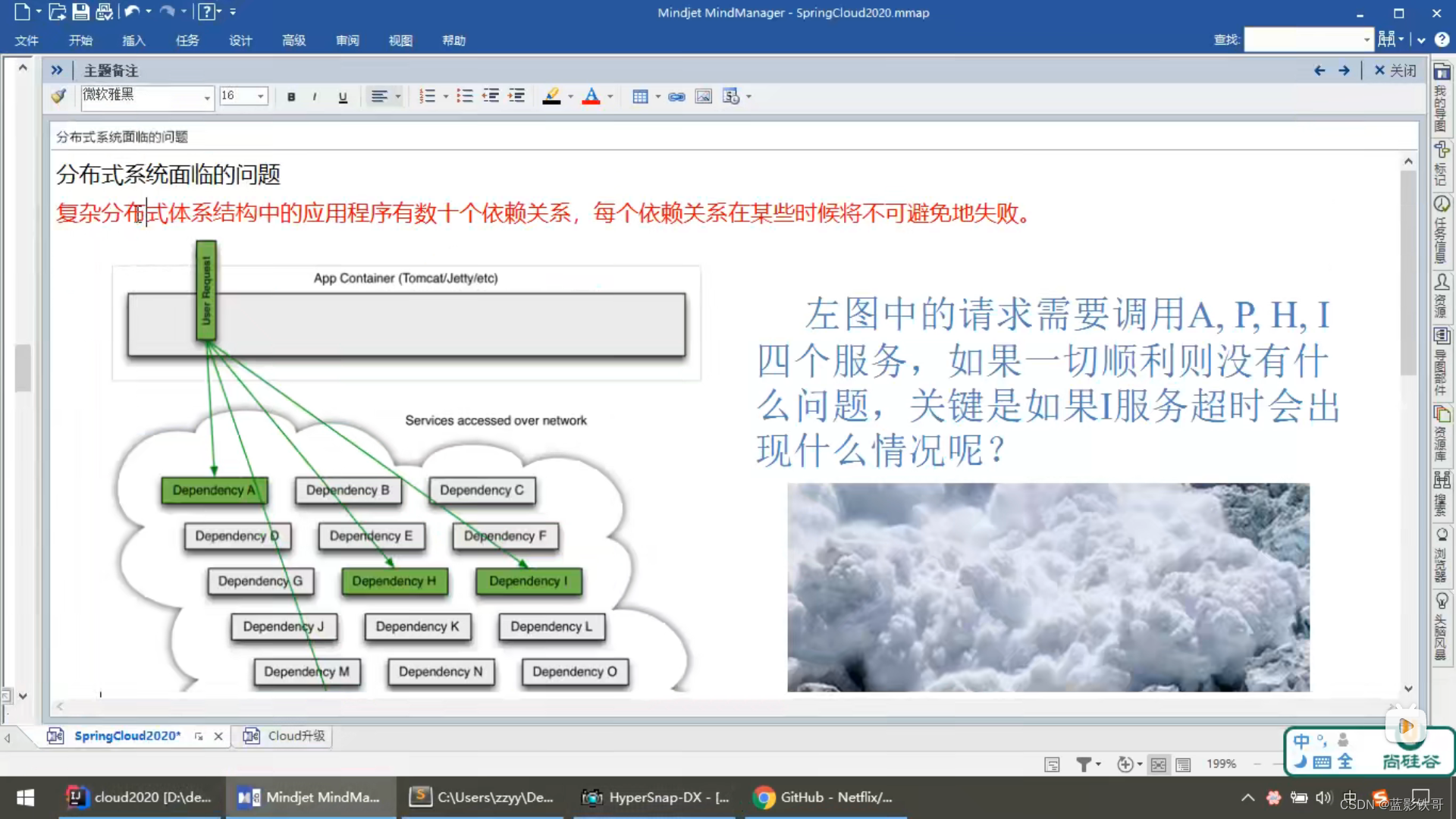
服务降级
经典例子,给电信运营商打电话的时候,会遇到提示说人工客服忙,继续等待请按1,返回上级请按2。这个提示语就是一个fallback。
fallback感觉就是个备胎,不会让错误直接返给客户端,用另一种更优秀的表达返给客户端。而且这个时候服务绝对是能用的。

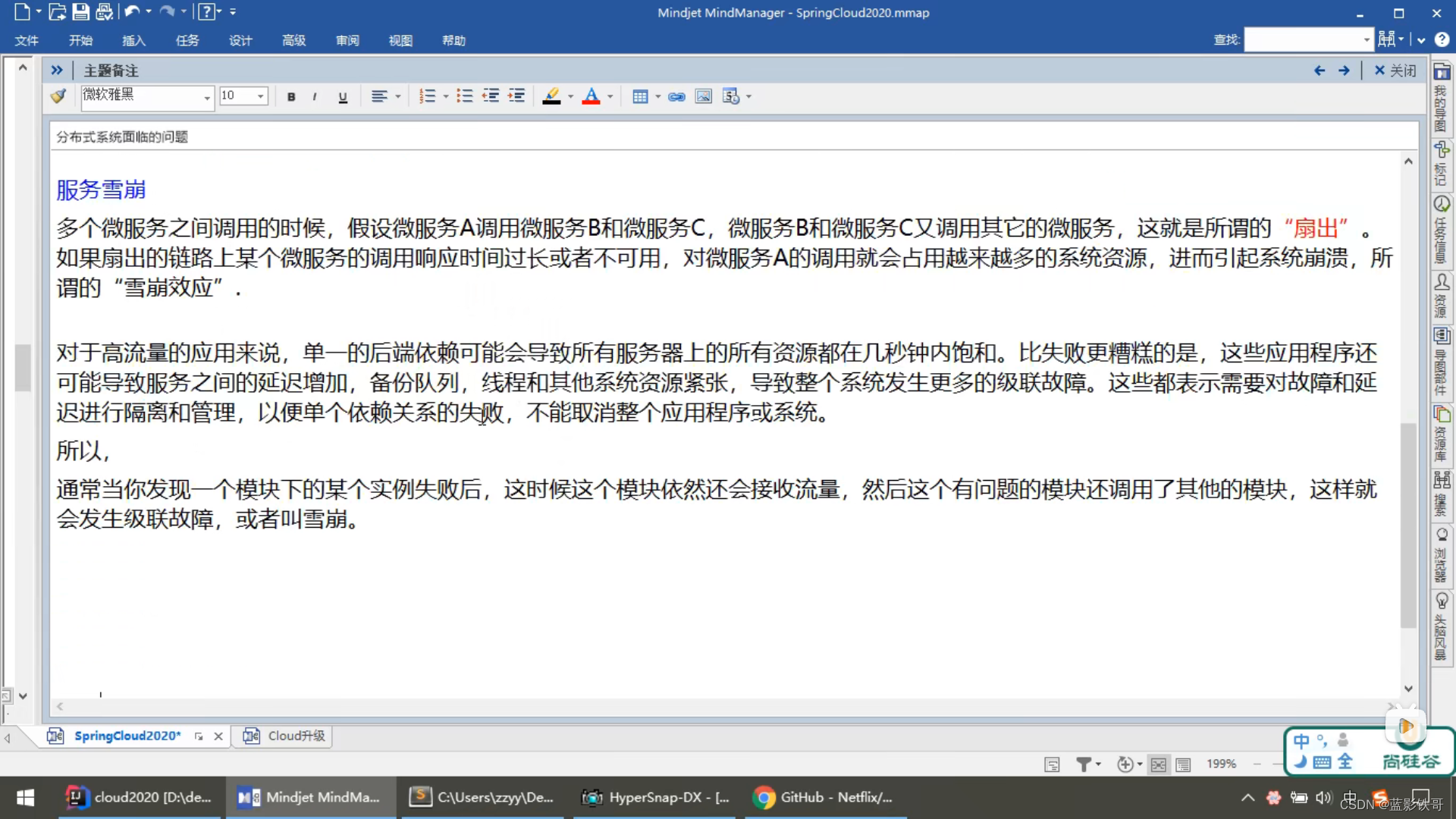
服务熔断
经典例子,一个插线板n多个高功率电器在用,结果超负荷,保险丝断了。注意,这个是个break,服务直接拒绝访问了,用不了。但是关掉大的使用电器后,还能恢复使用。这个服务熔断比起服务降级,有点能自我修复的意思,服务降级直接就备份错误提示不管了。(案例的测试结果截图 说明很详细)
服务限流
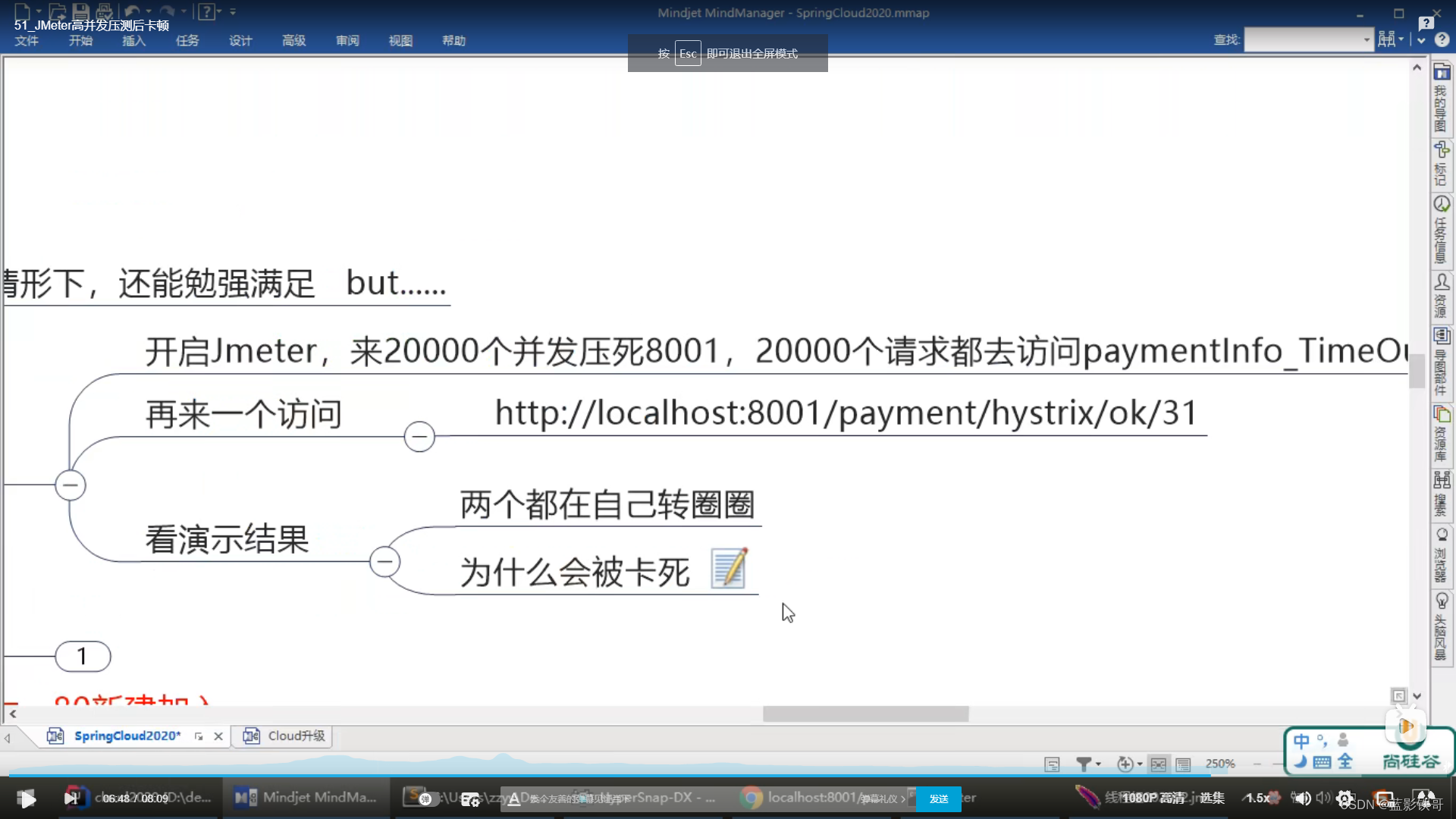
2、JMeter高压测试
不加Hystrix的测试
2.1、 服务提供者修改
改POM
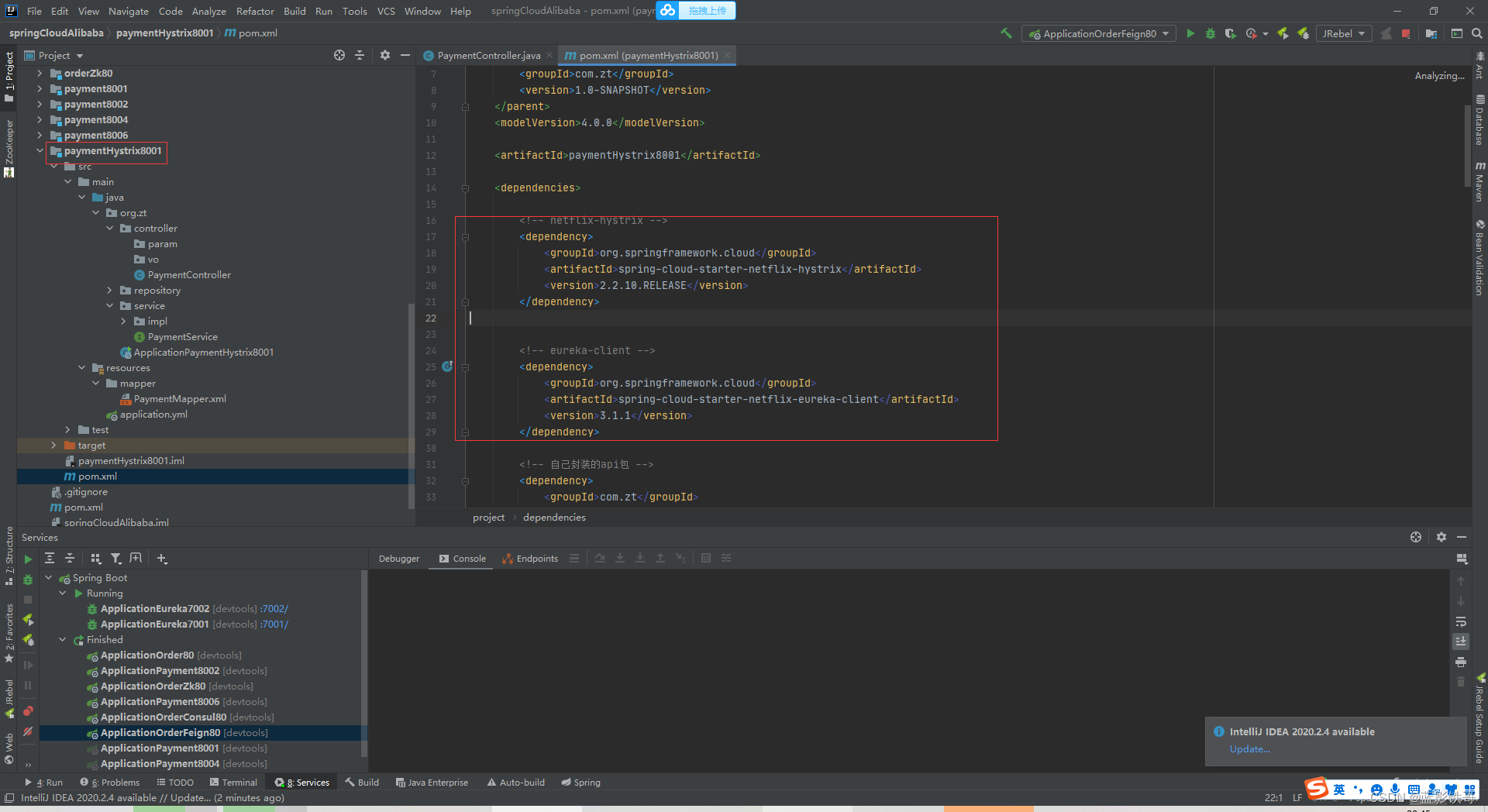
yml只引入注册中心
先不改动什么
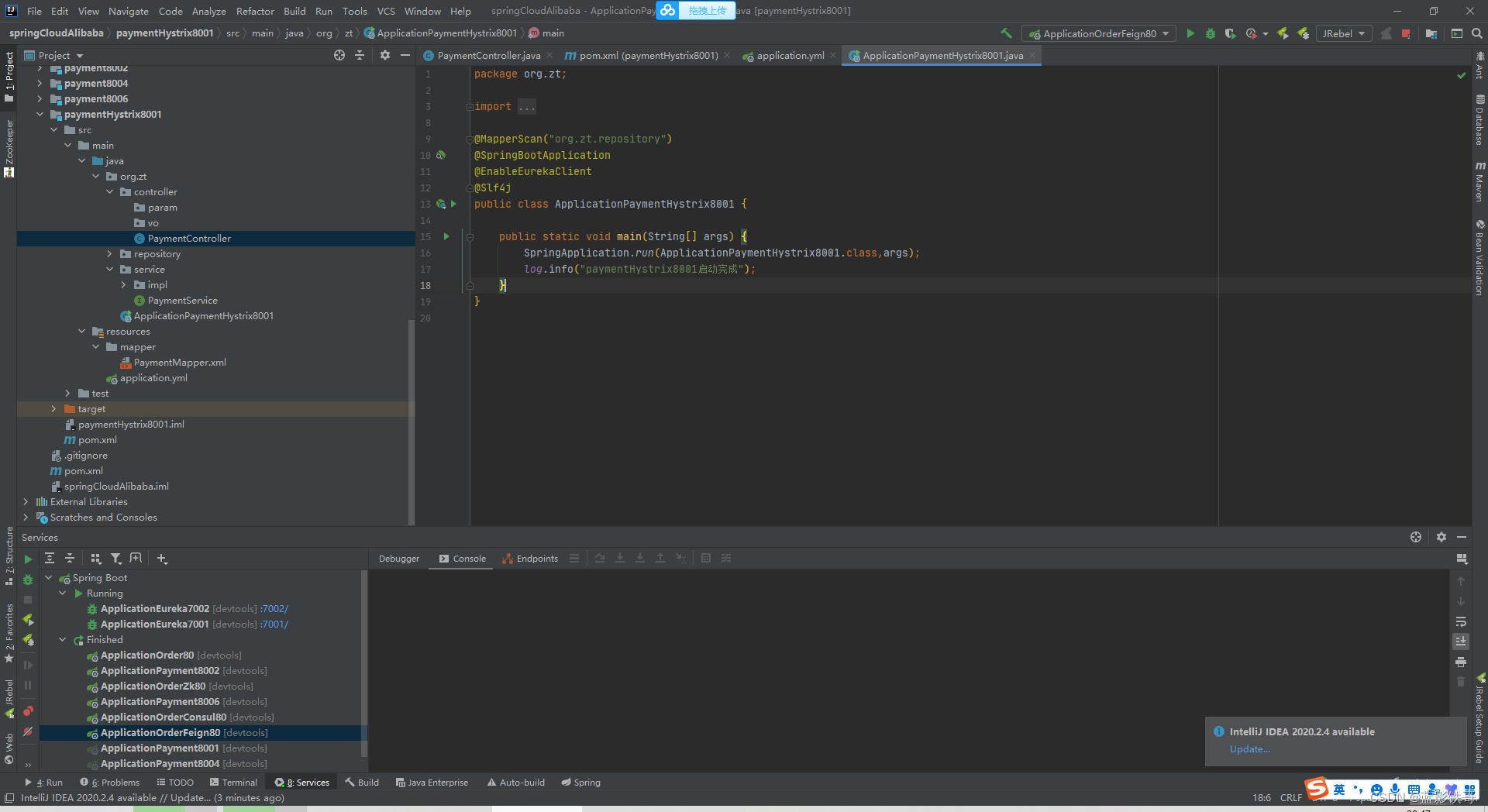
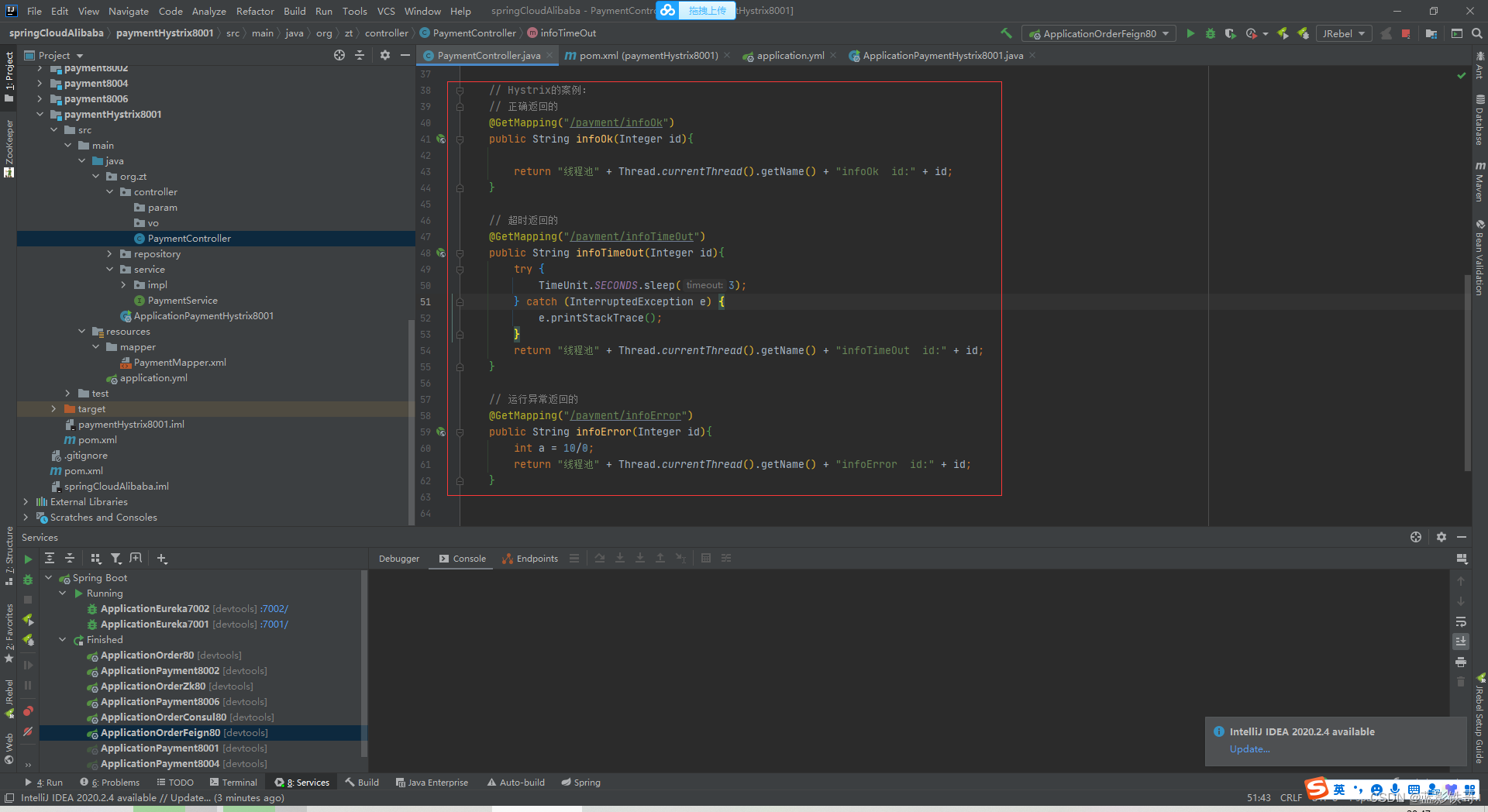
controller 增加了三个方法
2.2、消费者修改
改POM
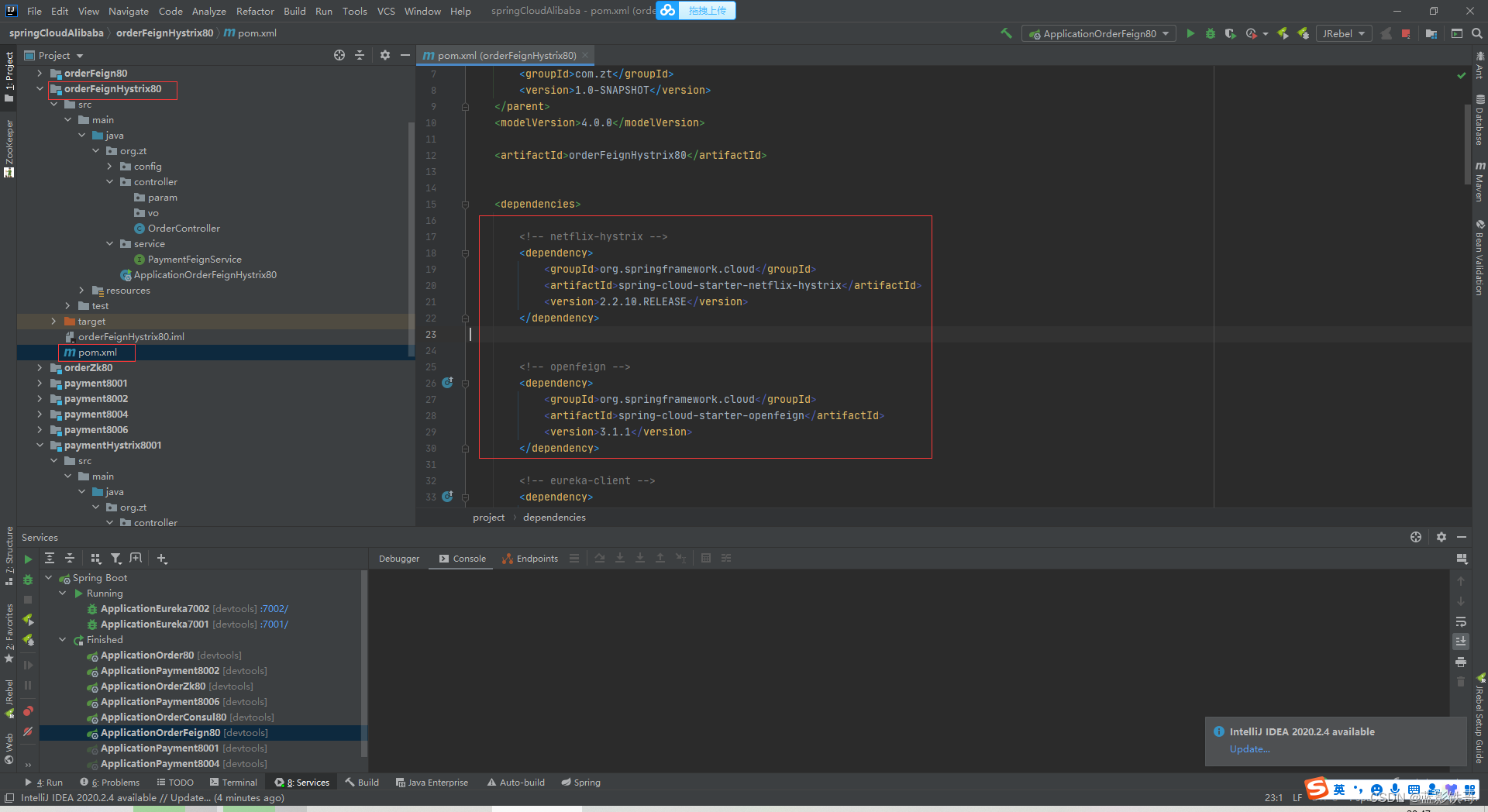
yml用OpenFeign一套,因为要用OpenFeign调用上面截图的服务提供者
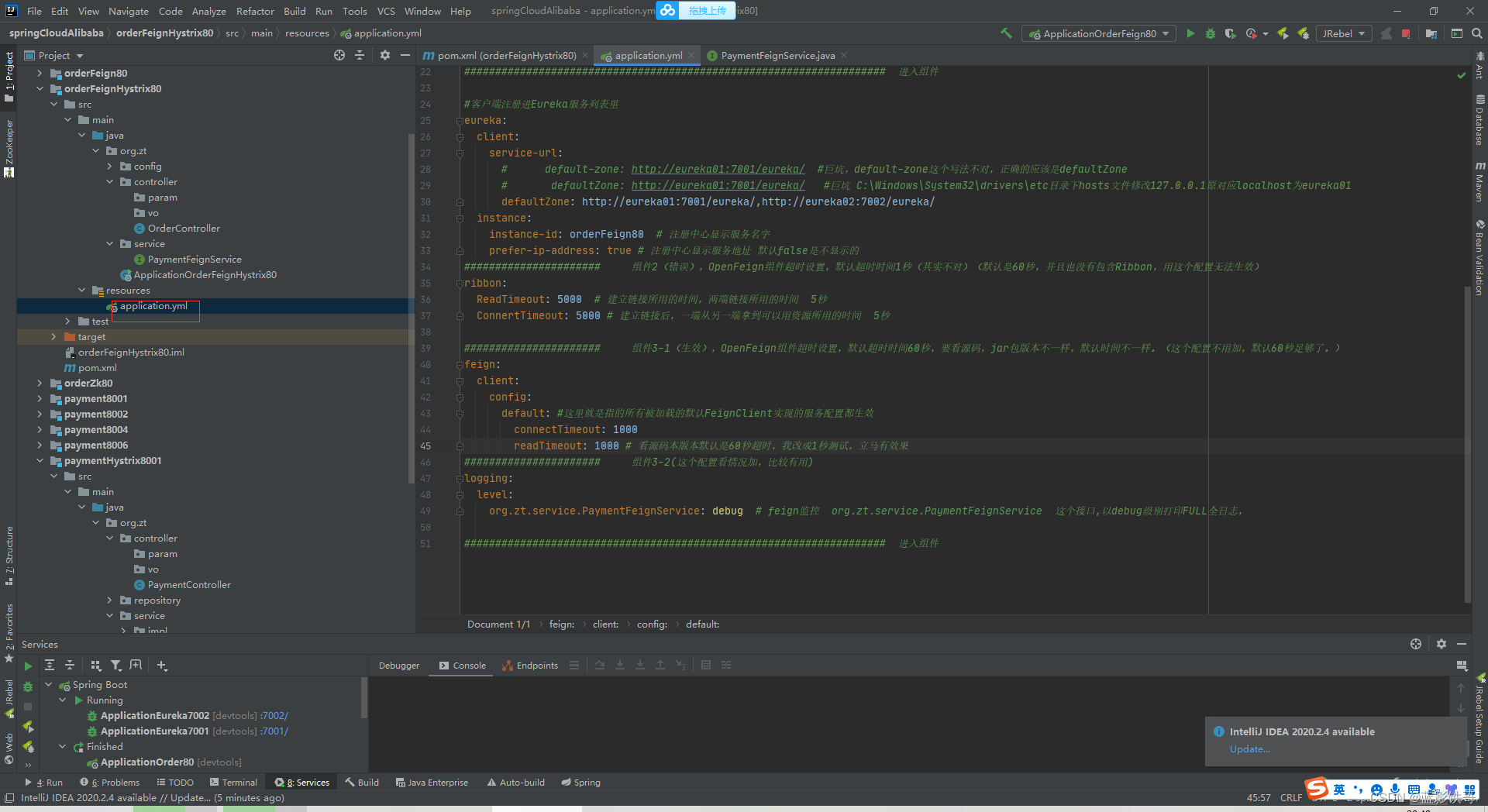
为OpenFeign封装下接口用来调用服务提供者
启动类不改
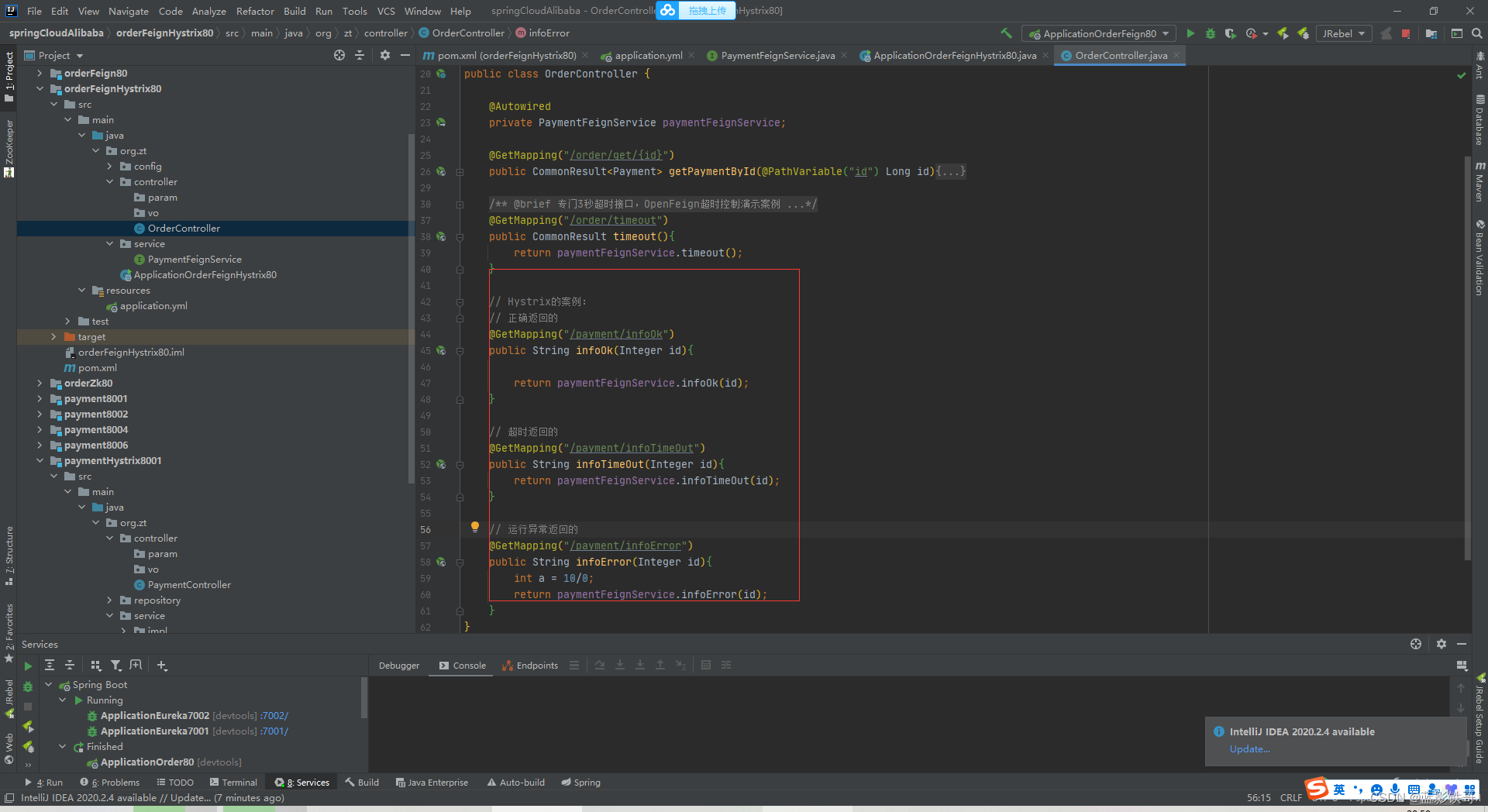
Controller增加三个方法
2.3、测试结果
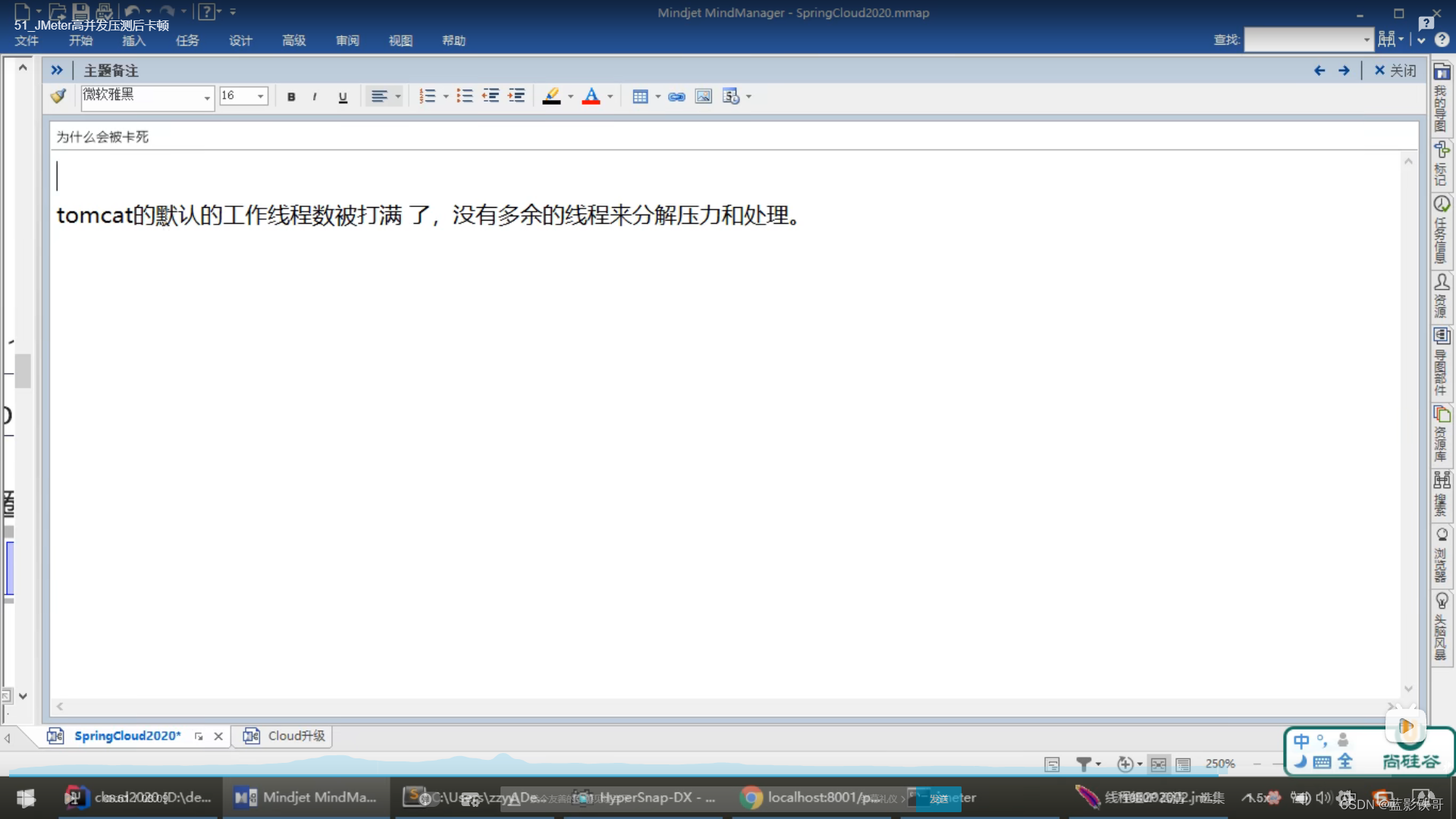
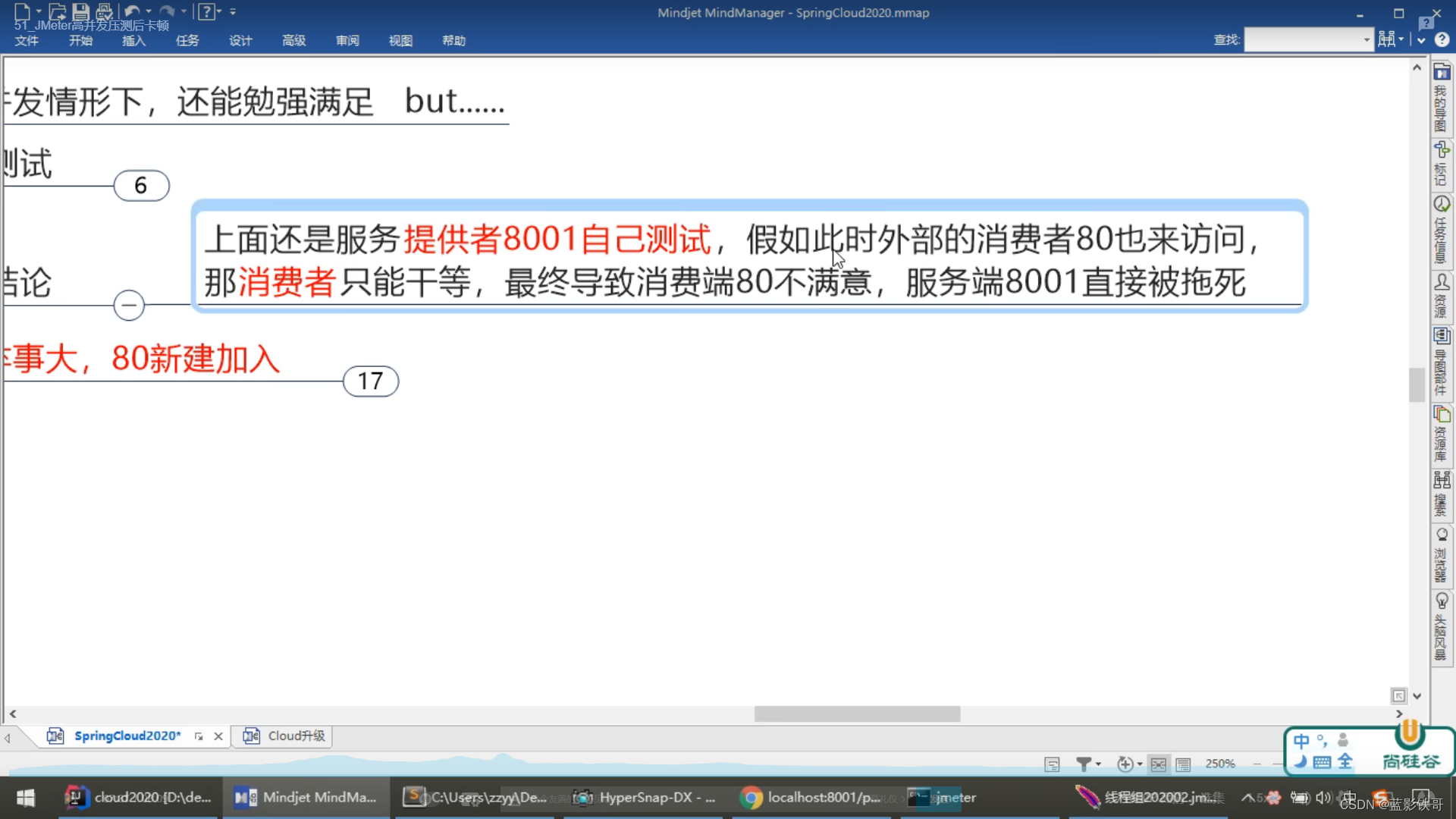
测试结果,8001本身2万个高压,导致本身就很慢了,而且还会直接影响本身上面的其他接口,相当于所有接口都影响了。然后80再去调用8001,更是雪上加霜。
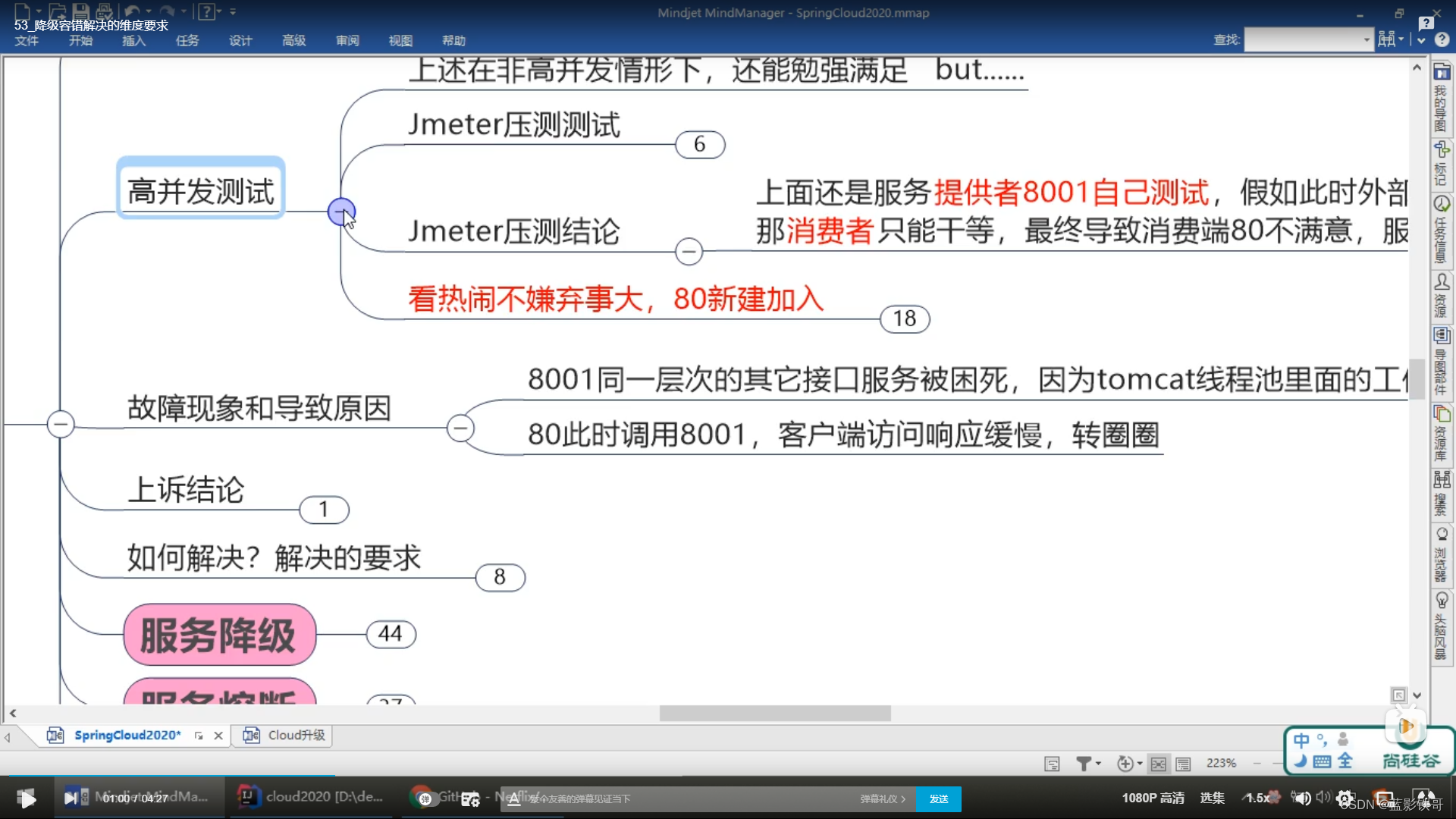
80自己要求自己时间超过自己规定后自己降级
在JMeter高压测试下,我们分别利用Hystrix做优化
分别有服务降级、服务熔断、服务限流
3、服务降级案例
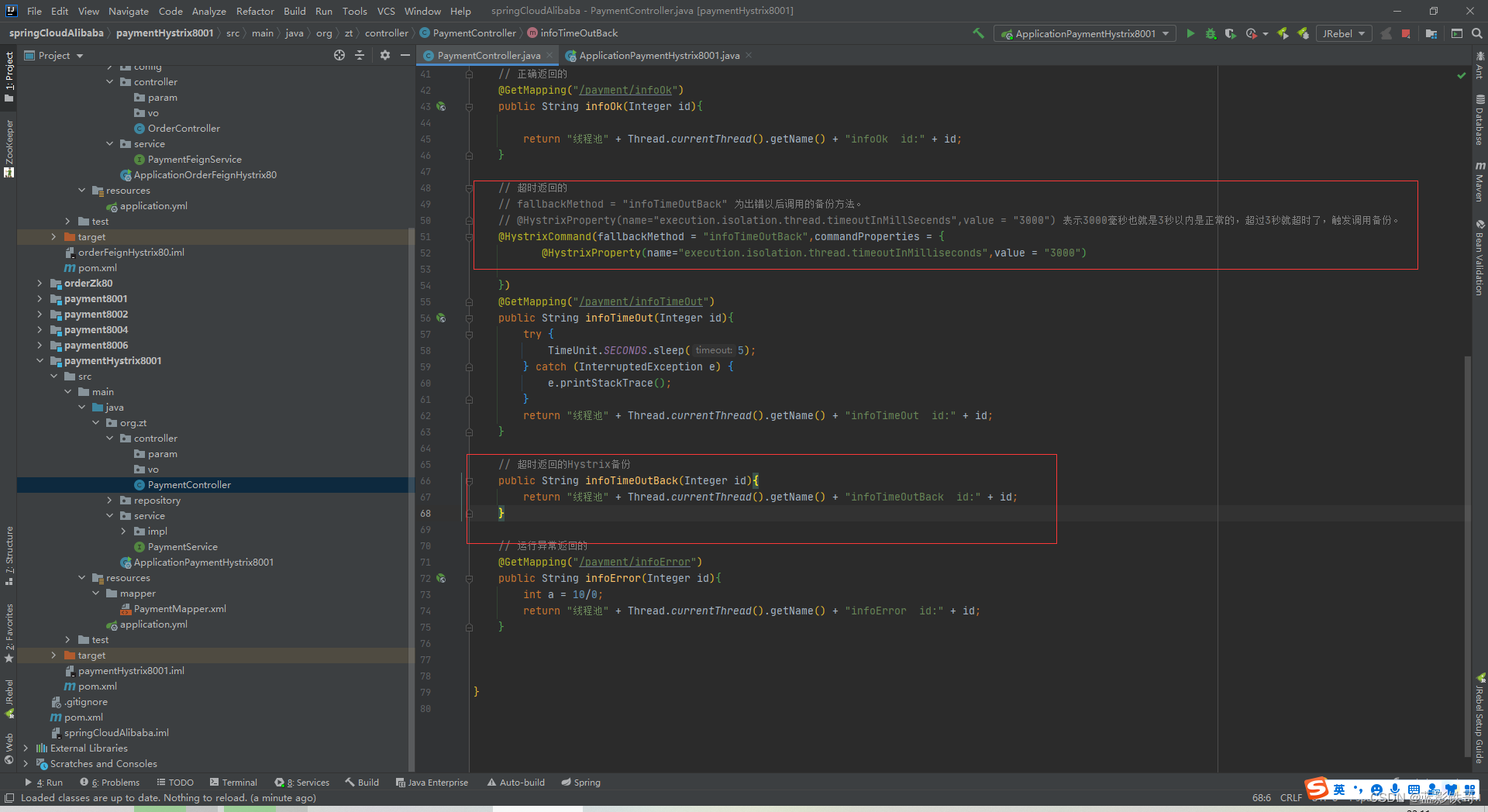
3.1、服务提供者修改(优化自己)
多了个注解,多个备份方法
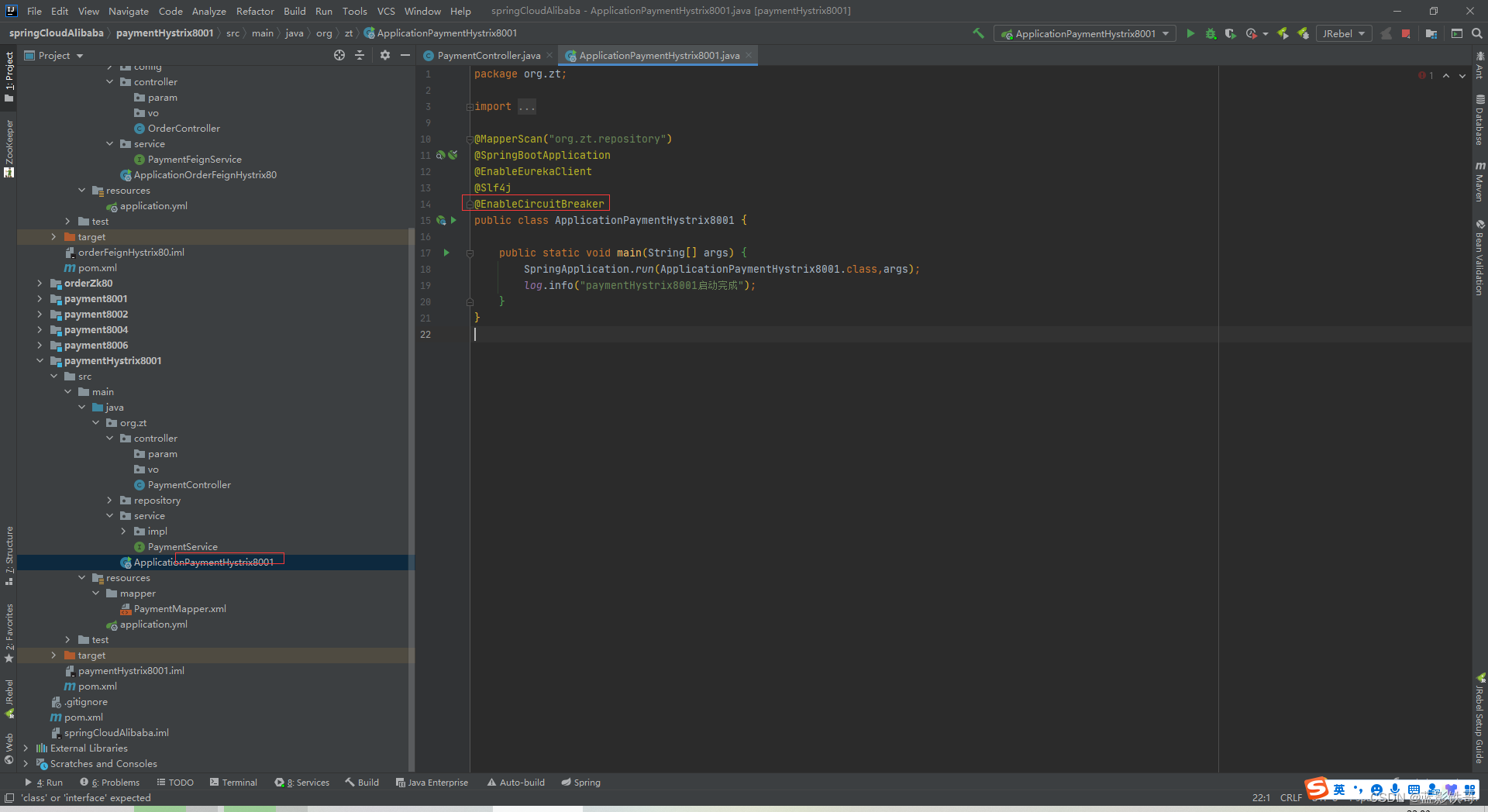
修改启动类
测试结果
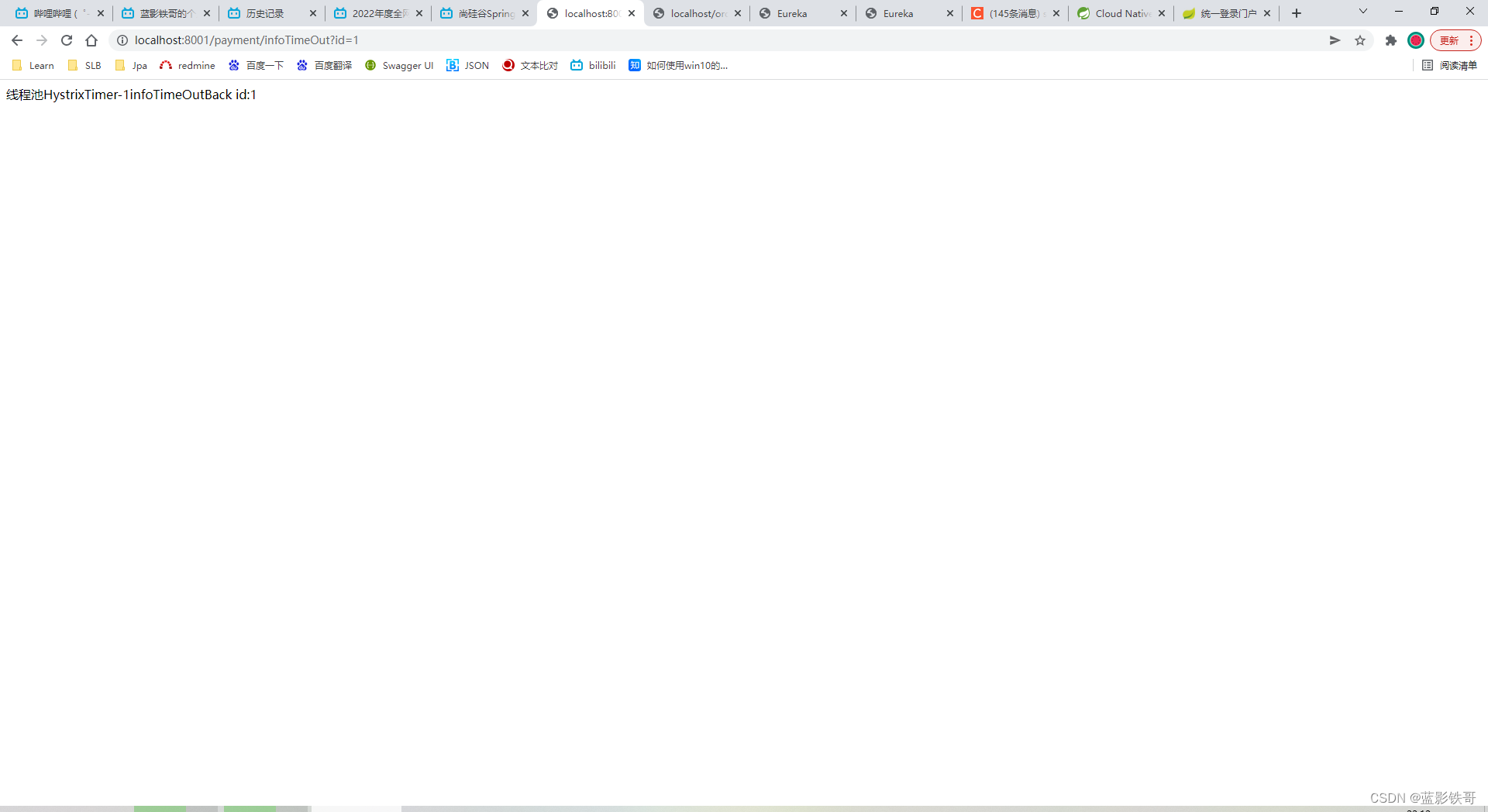
3.2、消费者修改(优化自己,一般用于消费者)
改yml(比服务提供者多的一步,因为用了Feign调用)
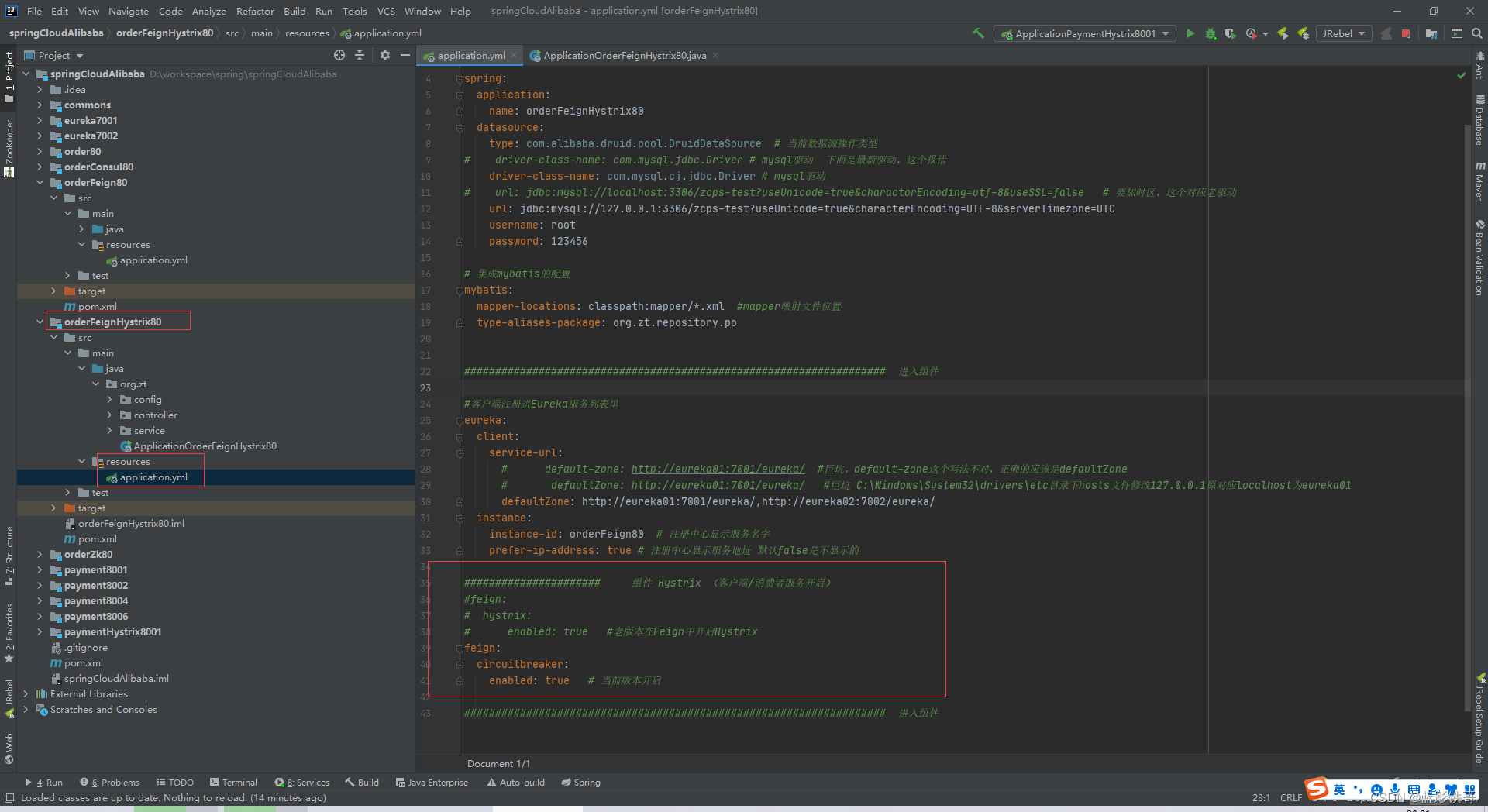
改启动类
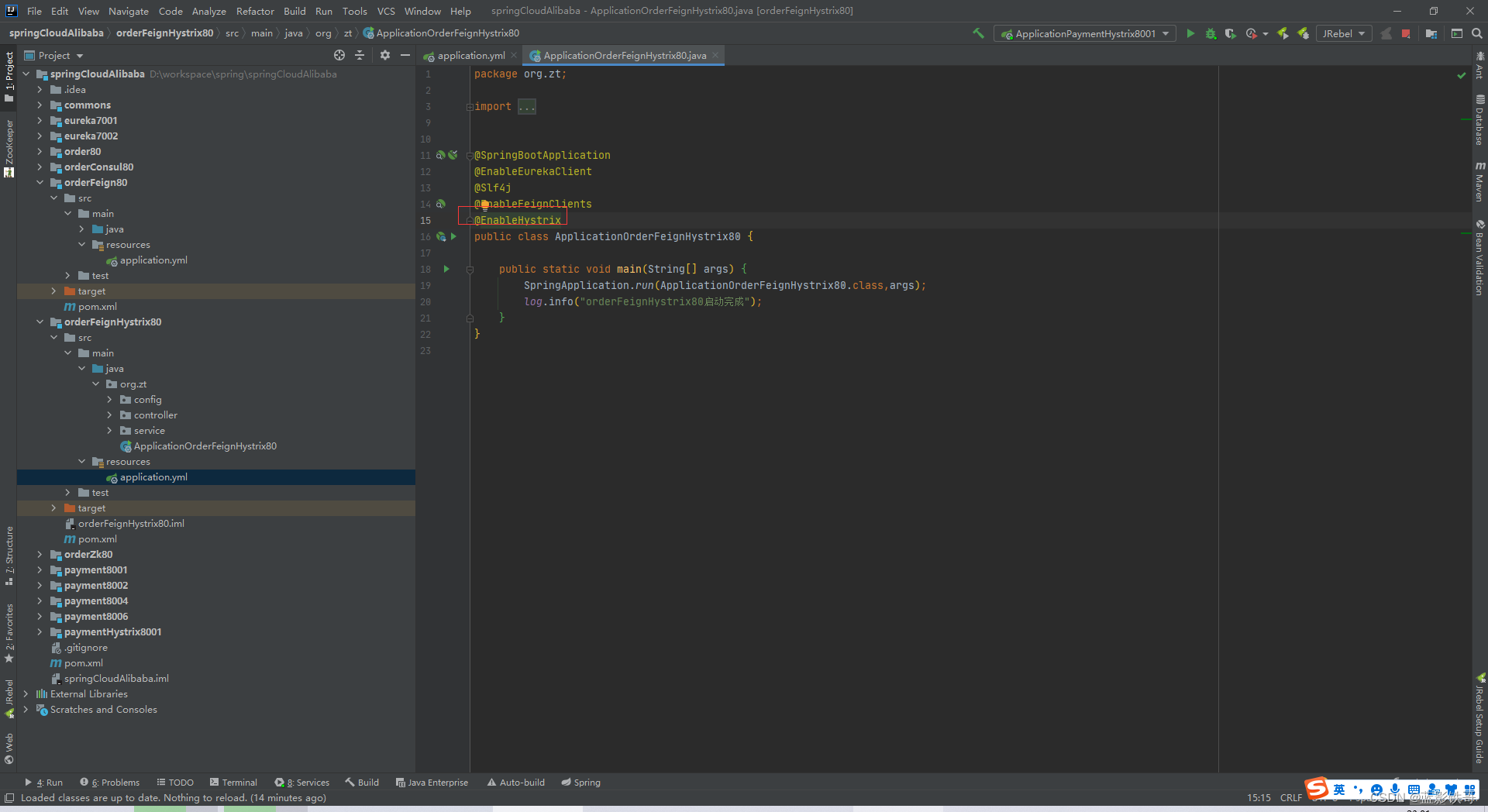
备份方法加上
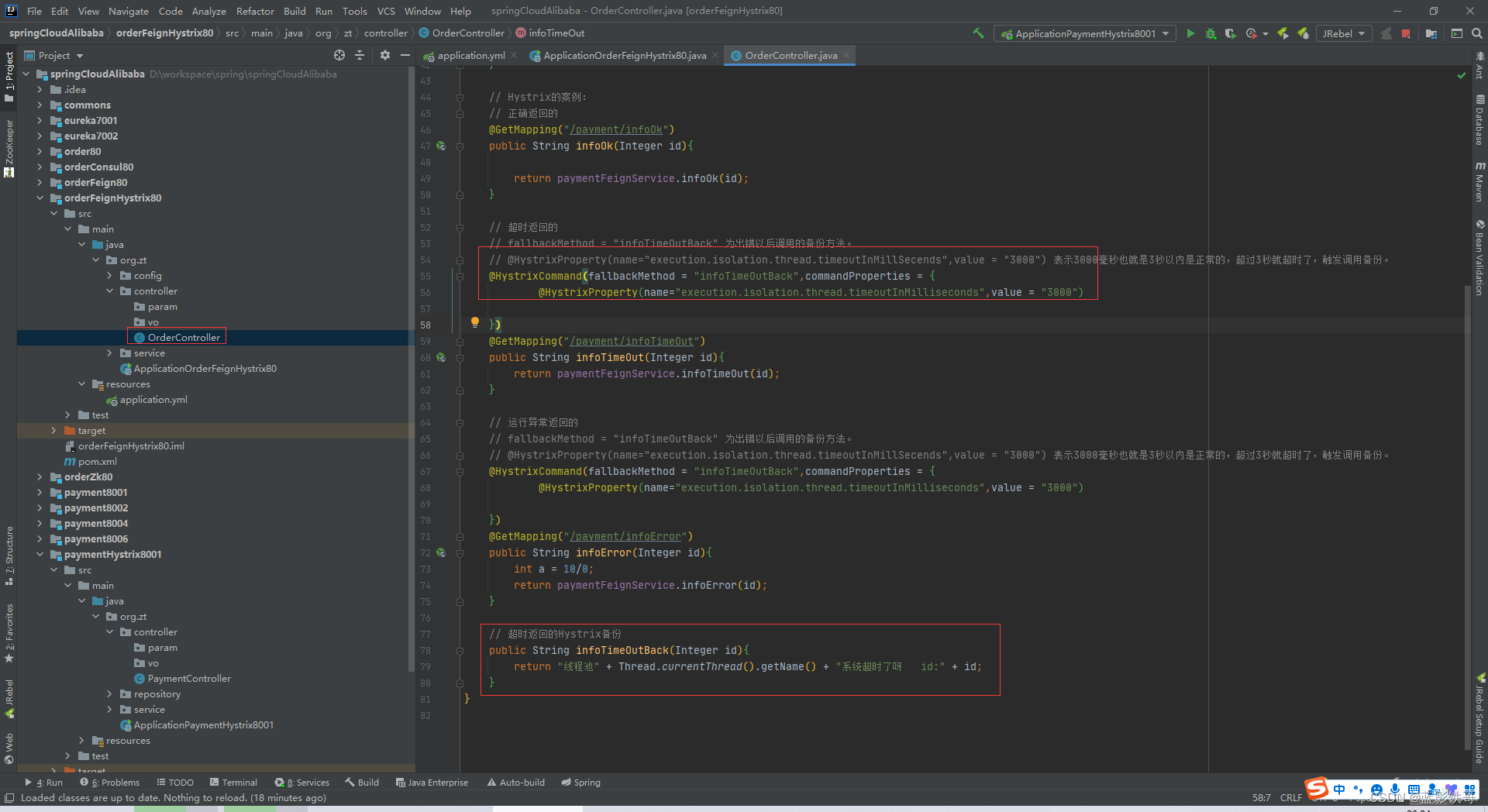
上面方式缺点:
业务代码和服务降级揉到一块了,几乎每个需要的方法都得写一次
解决办法:统一和自定义的分开
3.3、消费者修改(二次优化,服务提供者同理)
Controller的优化1,增加通用备份方法,注意不能有参数。
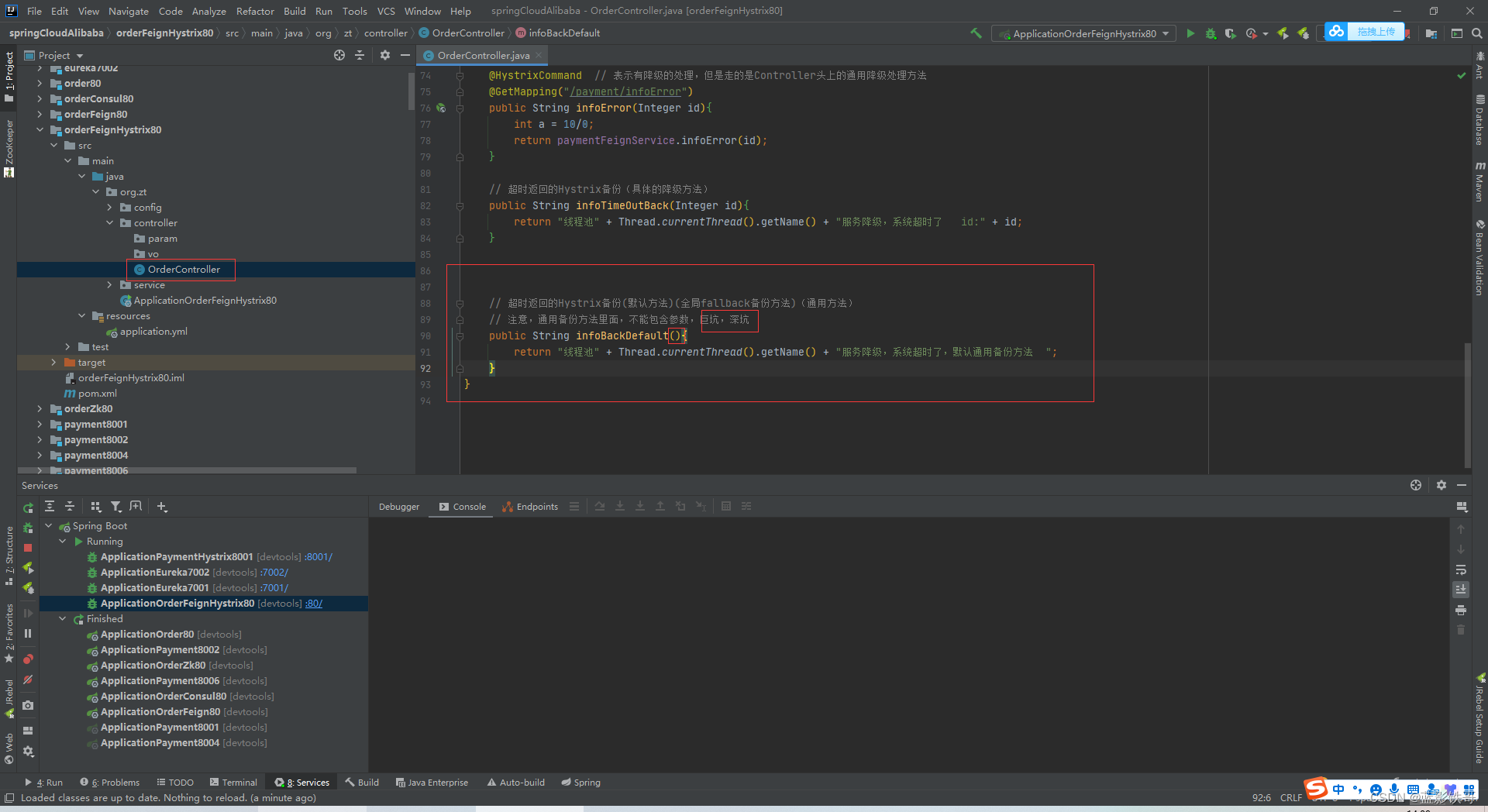
Controller的优化2,头部上面的方法,和通用备份方法要一对一,方法名字要一样
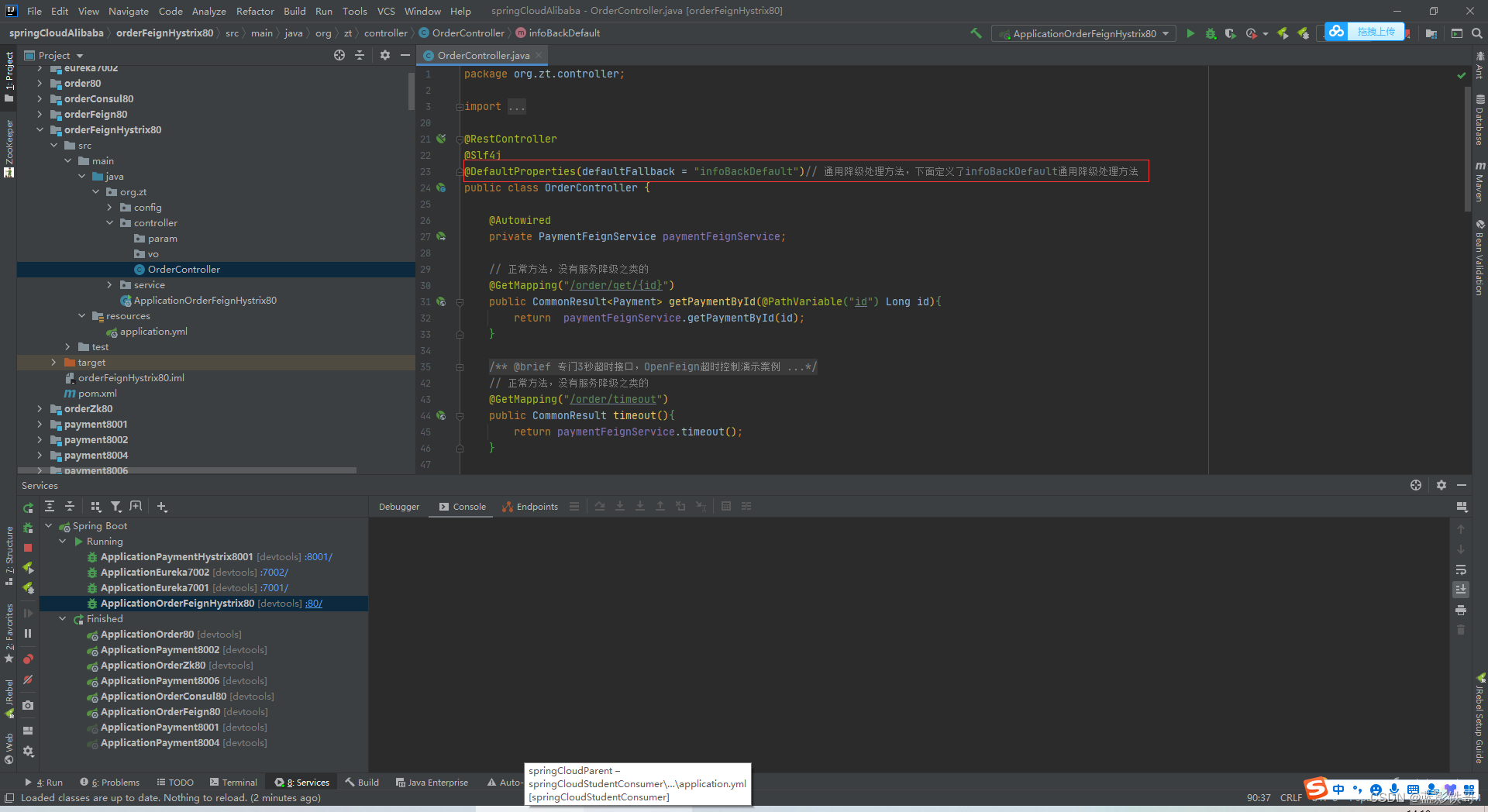
Controller的优化3,这种不指定具体备份方法的,就出错时都走Controller头上的指定的通用方法了。
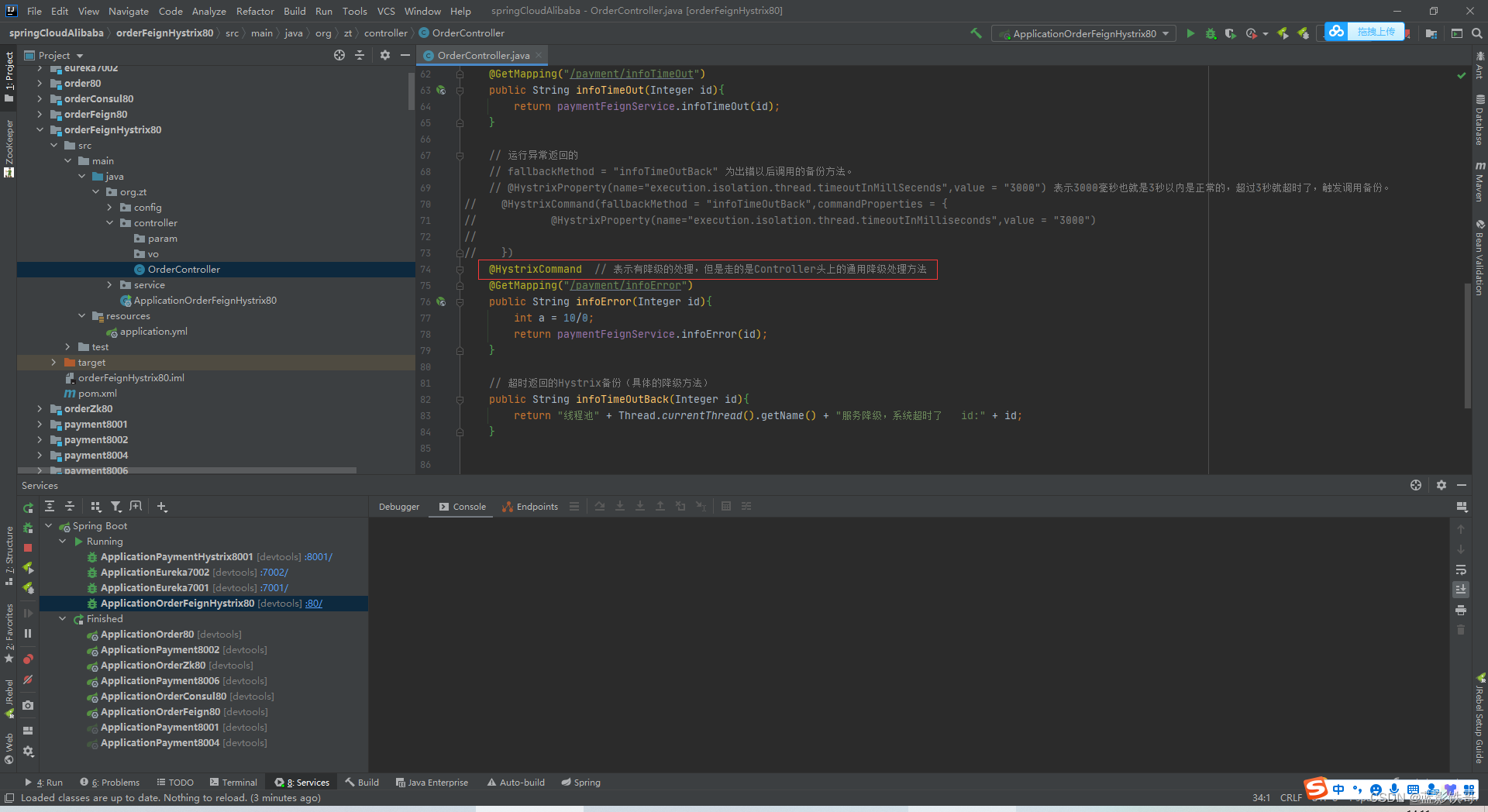
上面方式缺点:
业务和备份容错方法太耦合了,在Controller里面做了太多东西。
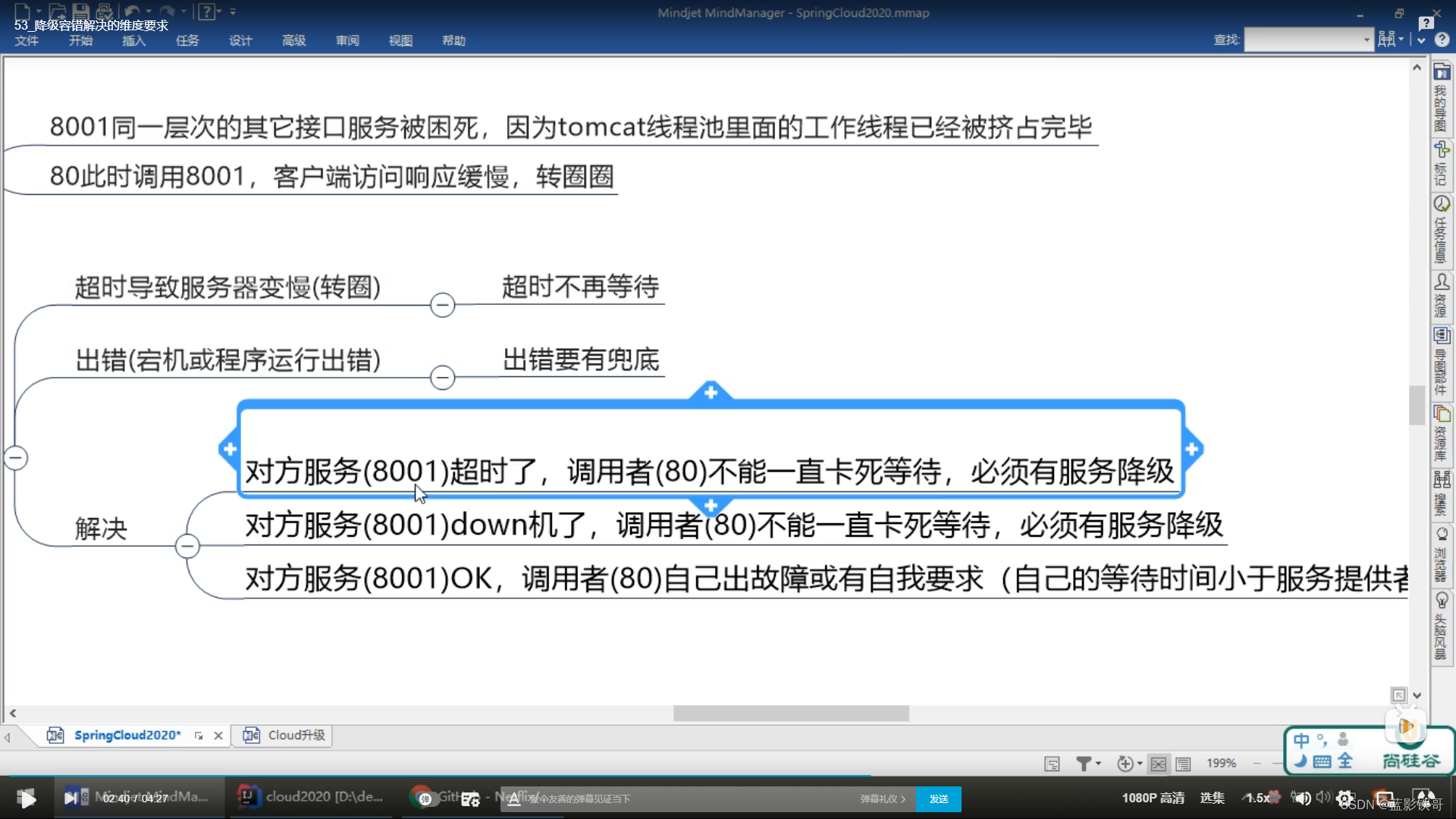
解决方法:order是微服务调用者,是消费者,能消费是因为service接口下面的PaymentServcie调用服务,所以在这边统一处理,这样业务是业务的,服务降级是服务降级的。(基于Feign调用的前提)。这种情况下,Controller什么都不用增加有关服务降级的东西,逻辑隔离和解耦非常好。而且由于是实现类,接口所有的都复现一次,所以就没有通用备份一说了,各是各的备份,虽写起来繁琐,但是逻辑隔离的好处远大于弊端。
上面截图要么是超时,要么是运行时异常,下面截图以服务宕机来演示案例
3.4、消费者修改(三次优化)
说明:
这个时候消费者order的Controller里面有三类接口,前提都是Feign的服务调用,没有服务调用,Hystrix也不用弄。
第一类是没有加@HystrixCommand的服务调用方法;
第二类是加了@HystrixCommand的服务调用方法,但是里面没有什么参数,就是走通用方法的;
第三类是加了@HystrixCommand的服务调用方法,里面有自己参数,比如截图中超时就走自己备份方法的;
Controller在方法二优化下,不做什么变动。
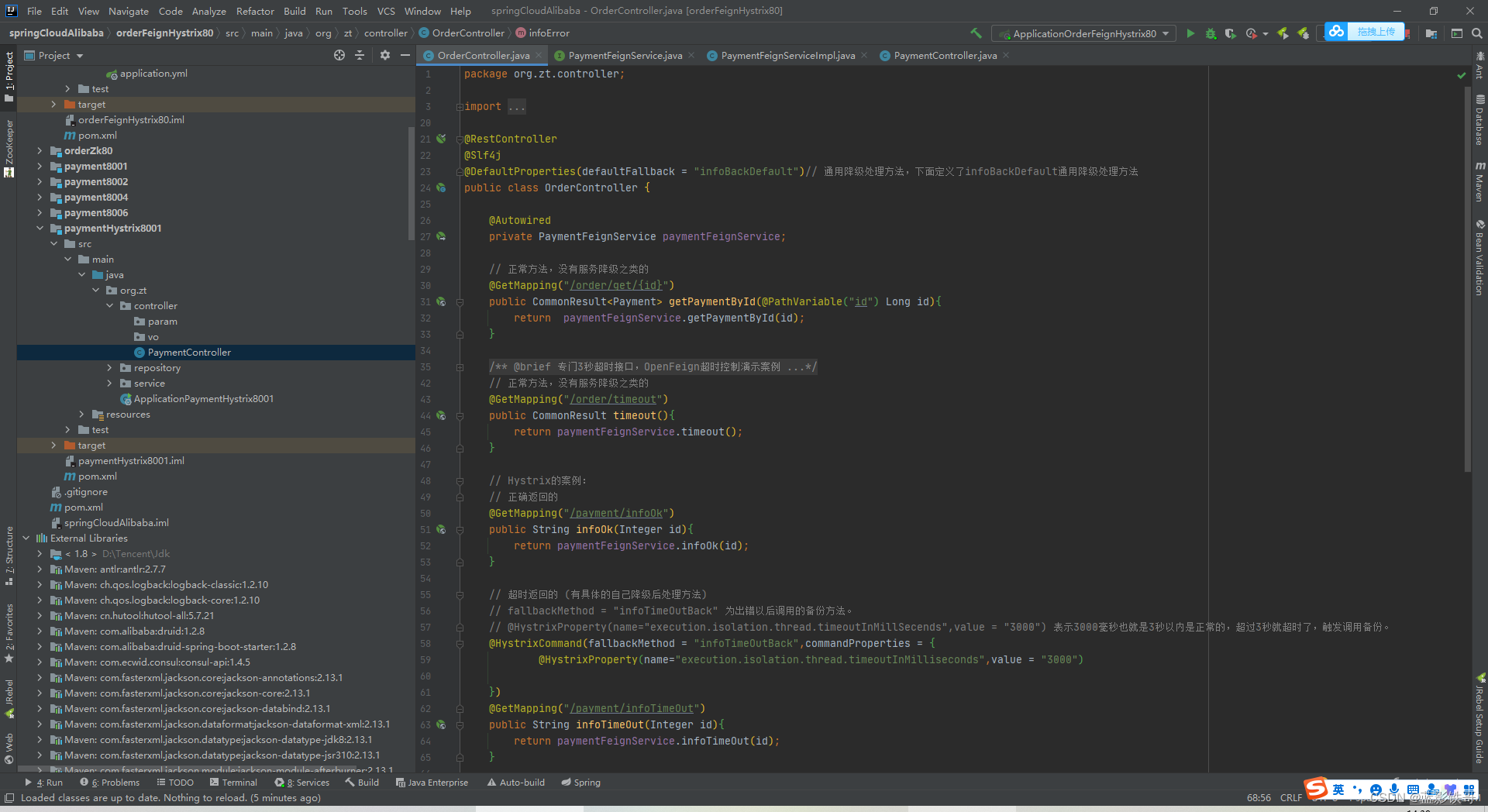
三次优化的核心就是写一个服务调用类的实现类,在异常时,就走这边复现的方法了,非异常则正常走逻辑。
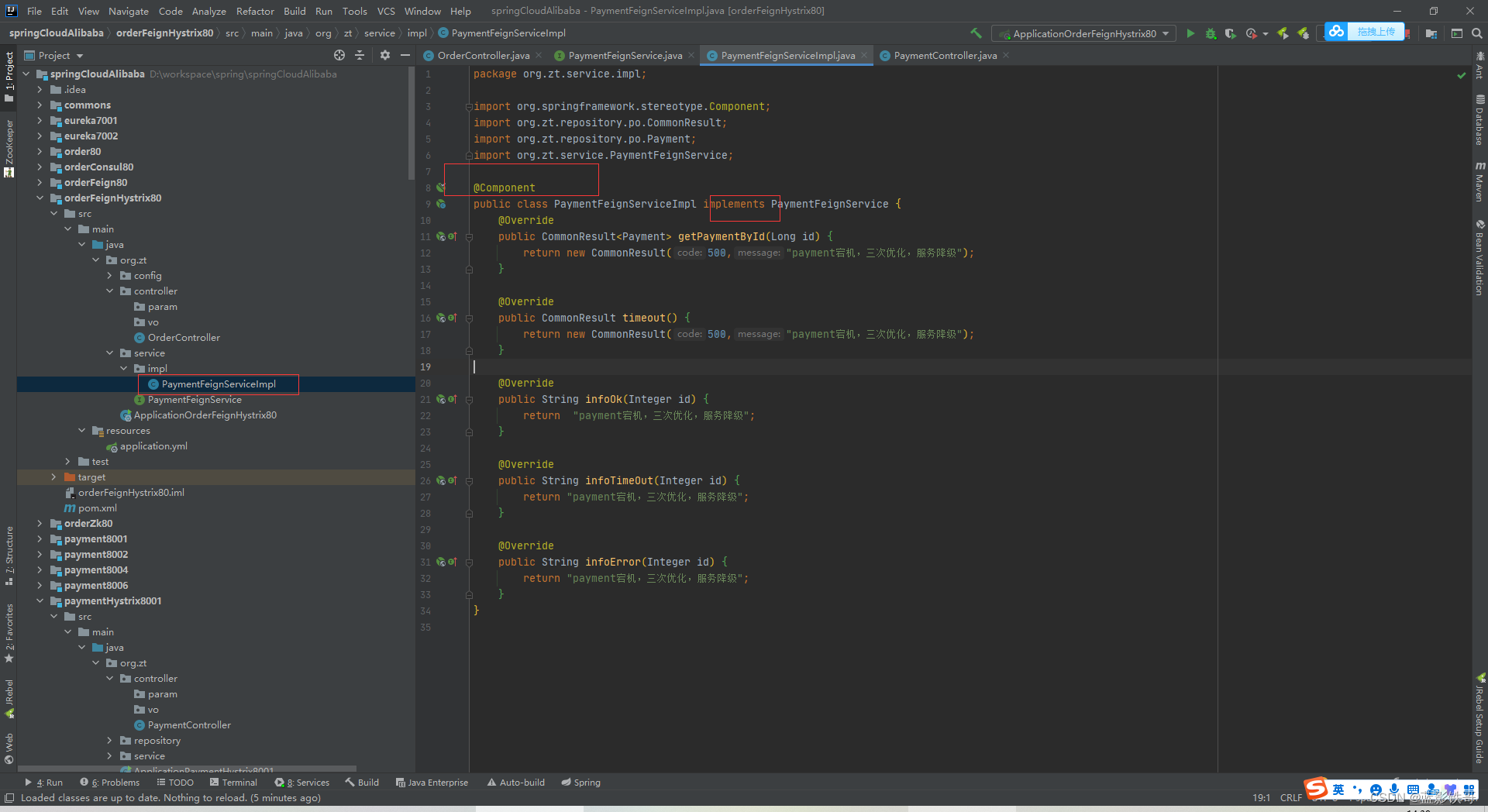
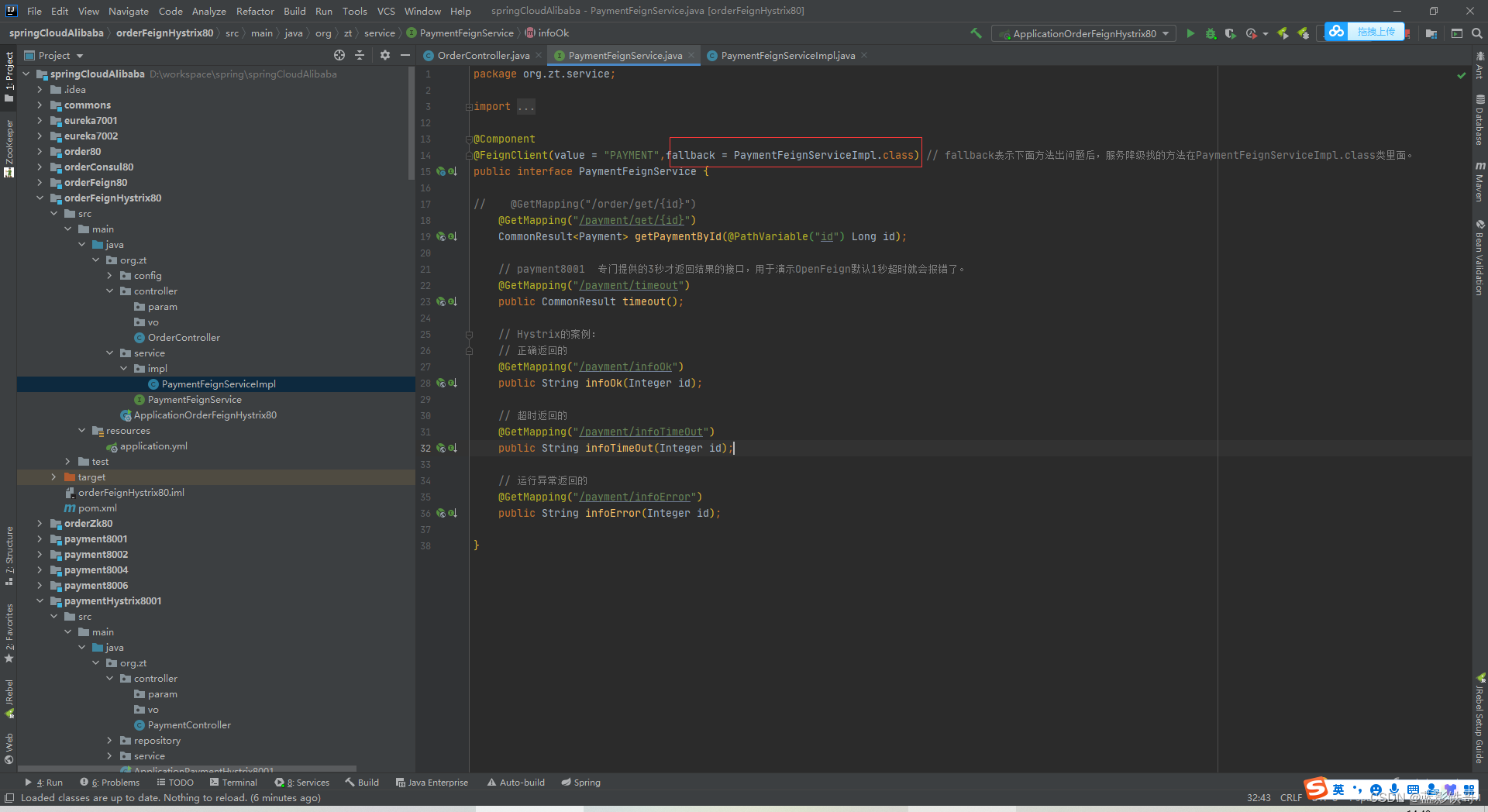
三次优化核心,服务调用接口这边开启异常宕机等等调用的备份方法。
三次优化测试结果
1、在运行异常或者超时的情况下,Controller上面添加的服务降级方法优先处理,还轮不到实现类的备份方法。
2、在宕机的情况下,经过我测试,发现本来Controller上面标注的优先级最高,结果呢第三类有自己备份方法的没有走自己备份方法,反而走了实现类里面的方法了。这个我猜测是超时那个参数引起的,因为异常还是走了通用方法了。
4、服务熔断案例
4.1、服务提供者修改
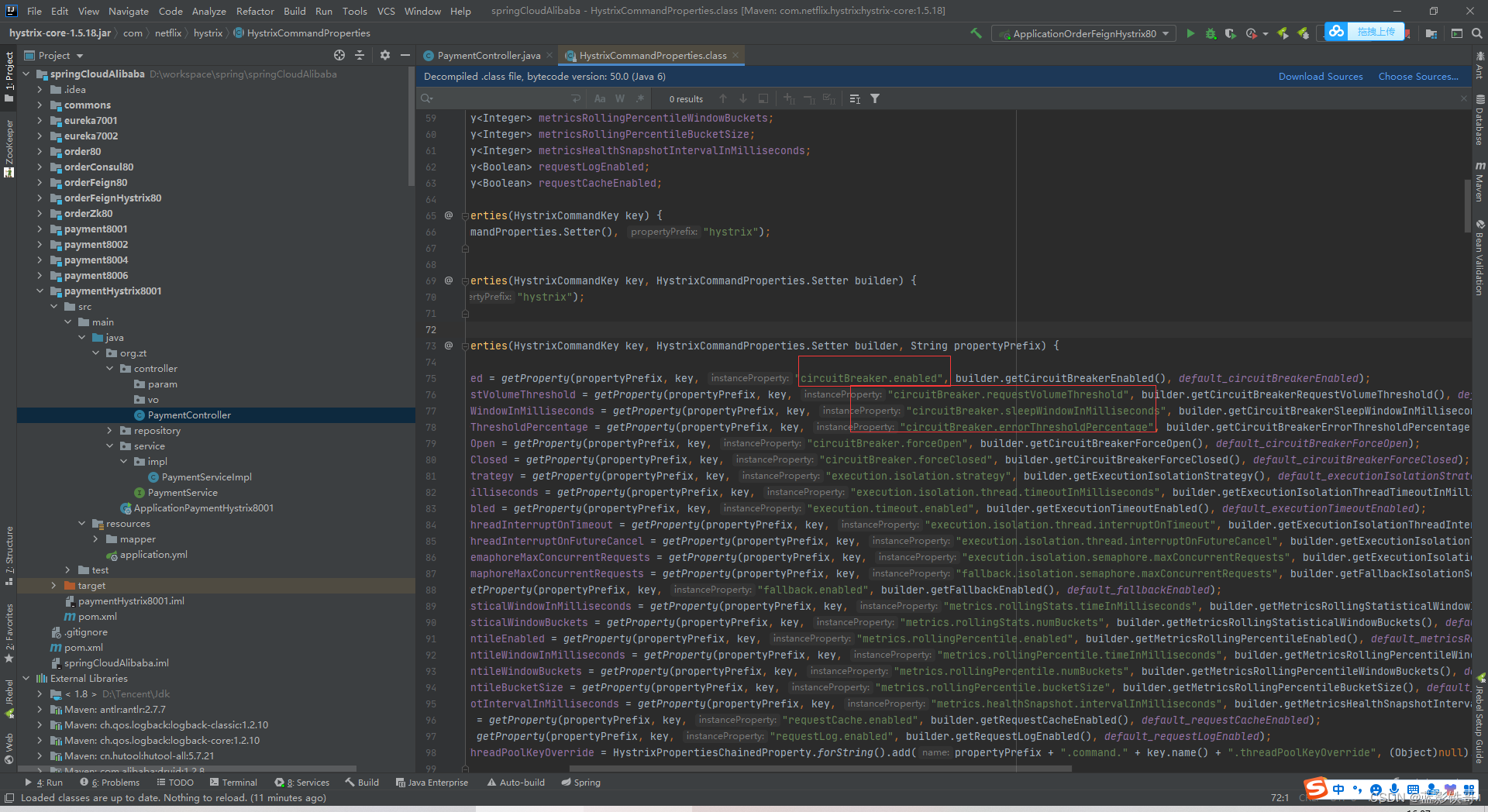
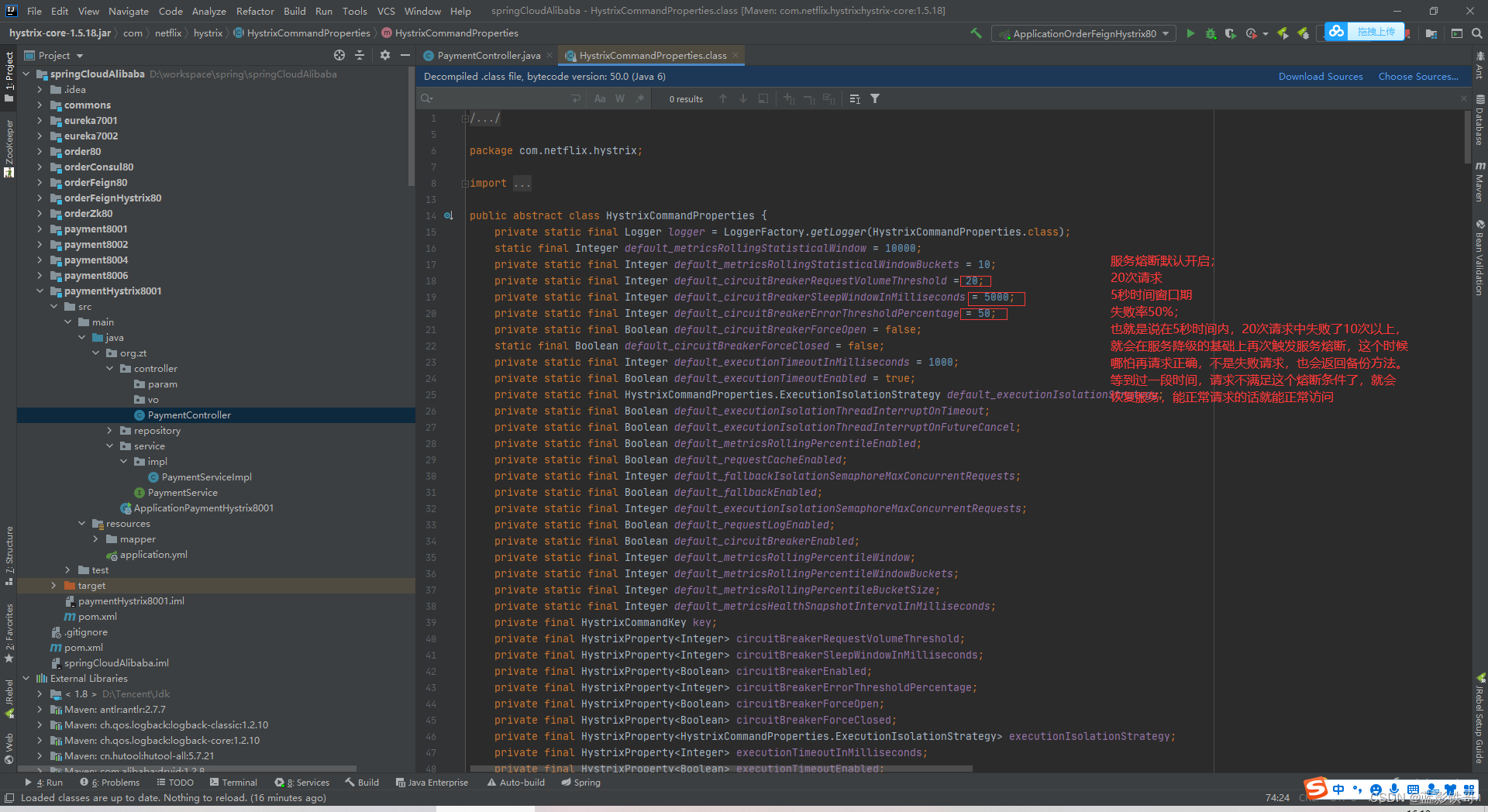
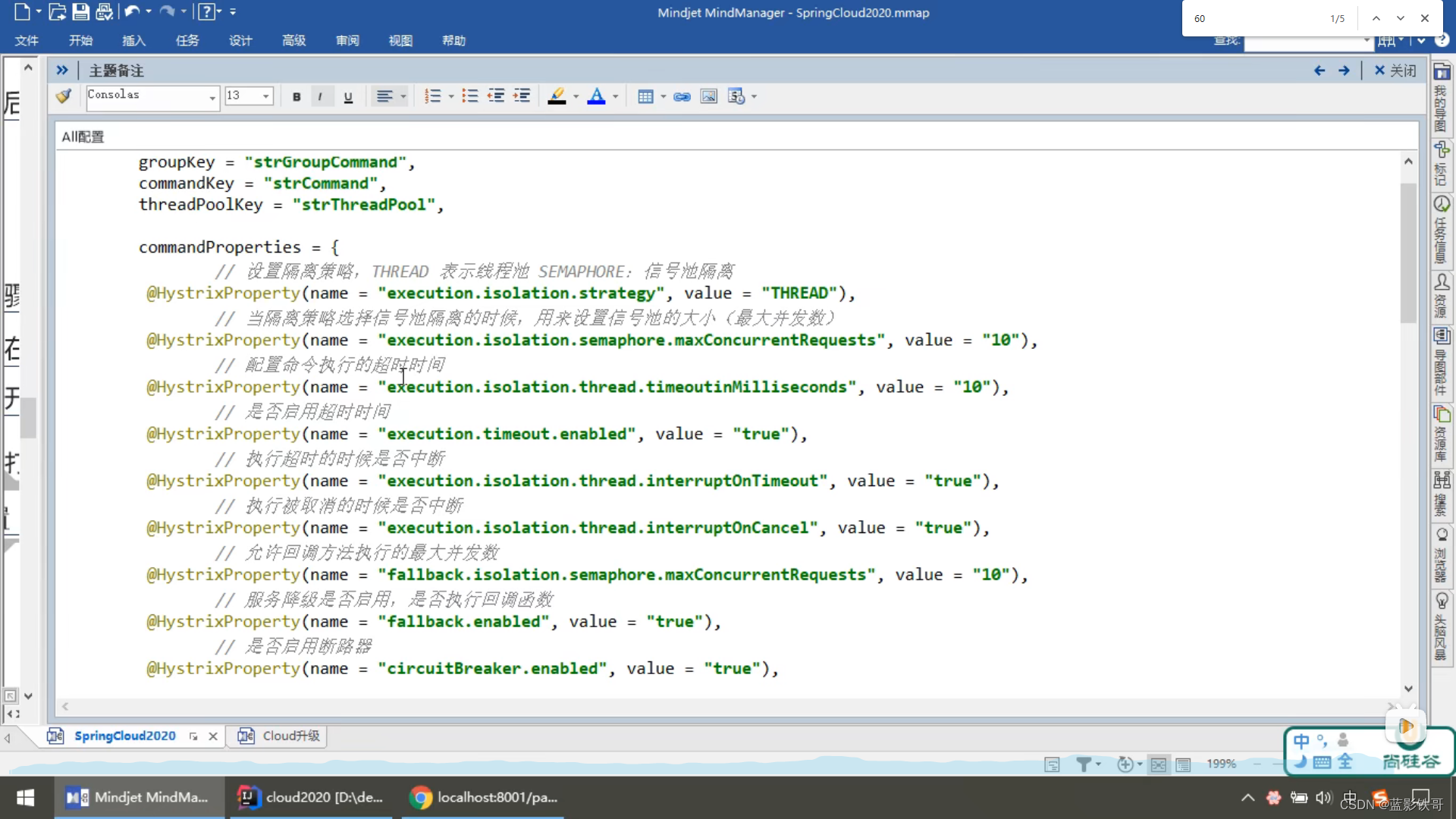
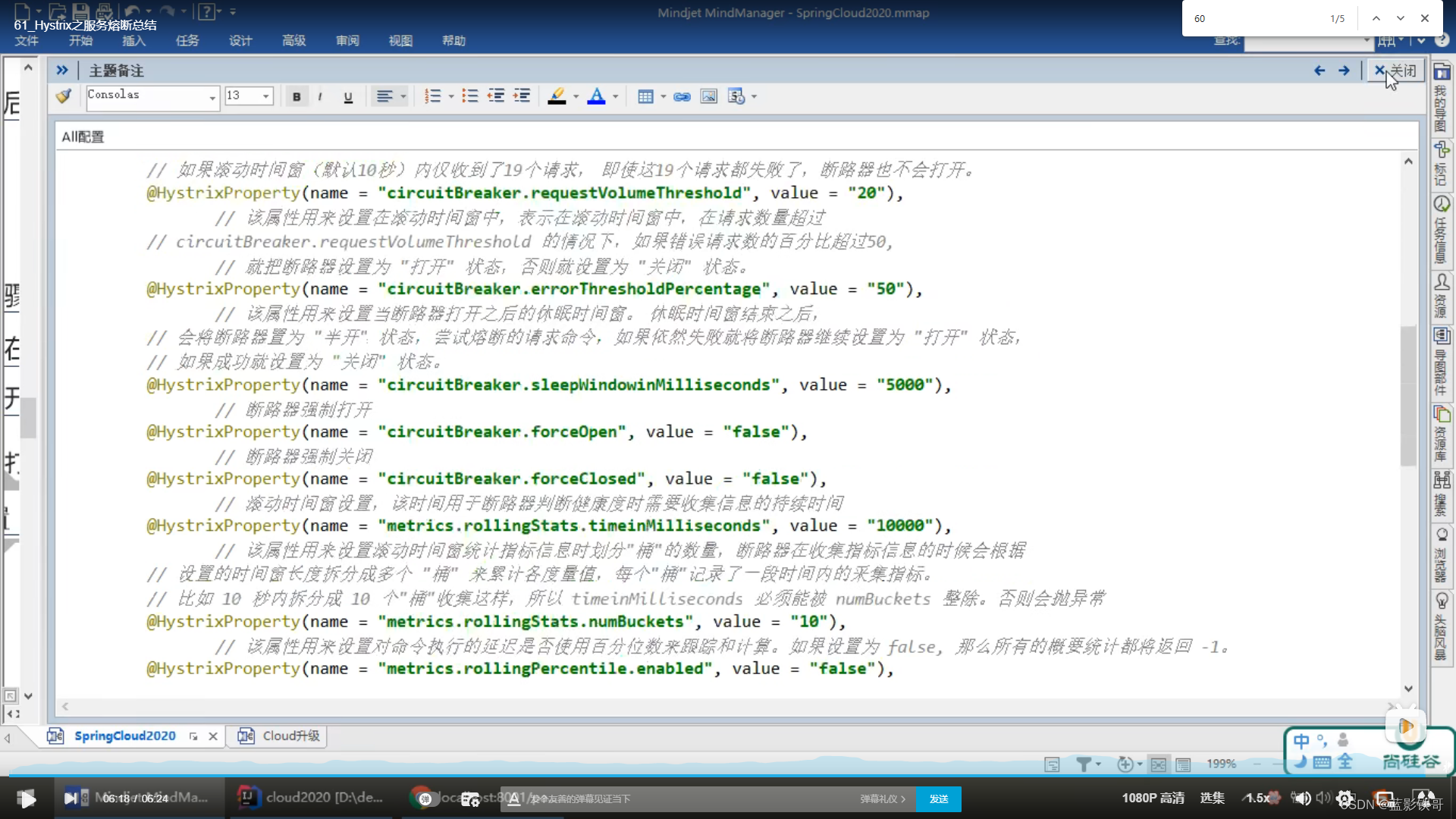
Controller增加一些测试方法,并且增加Hystrix的注解。其中里面的参数在后面截图的配置文件中找。
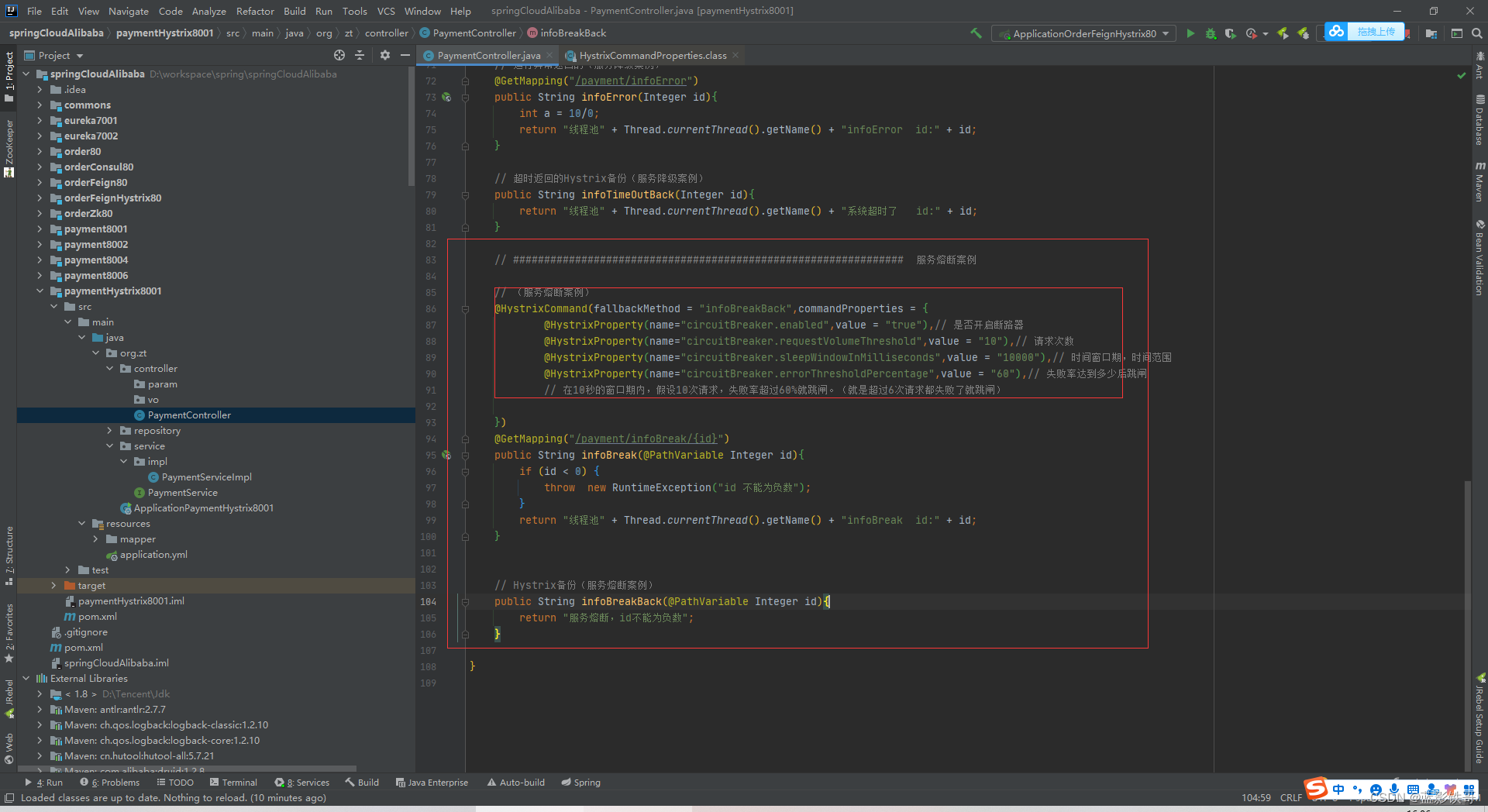
配置文件都设置了默认值的,默认这个熔断其实是开启的。
4.2、测试结果
服务降级- >服务熔断->服务恢复
截图说明非常详细。注意,我引入的版本(看后面截图),服务熔断默认是开启的。
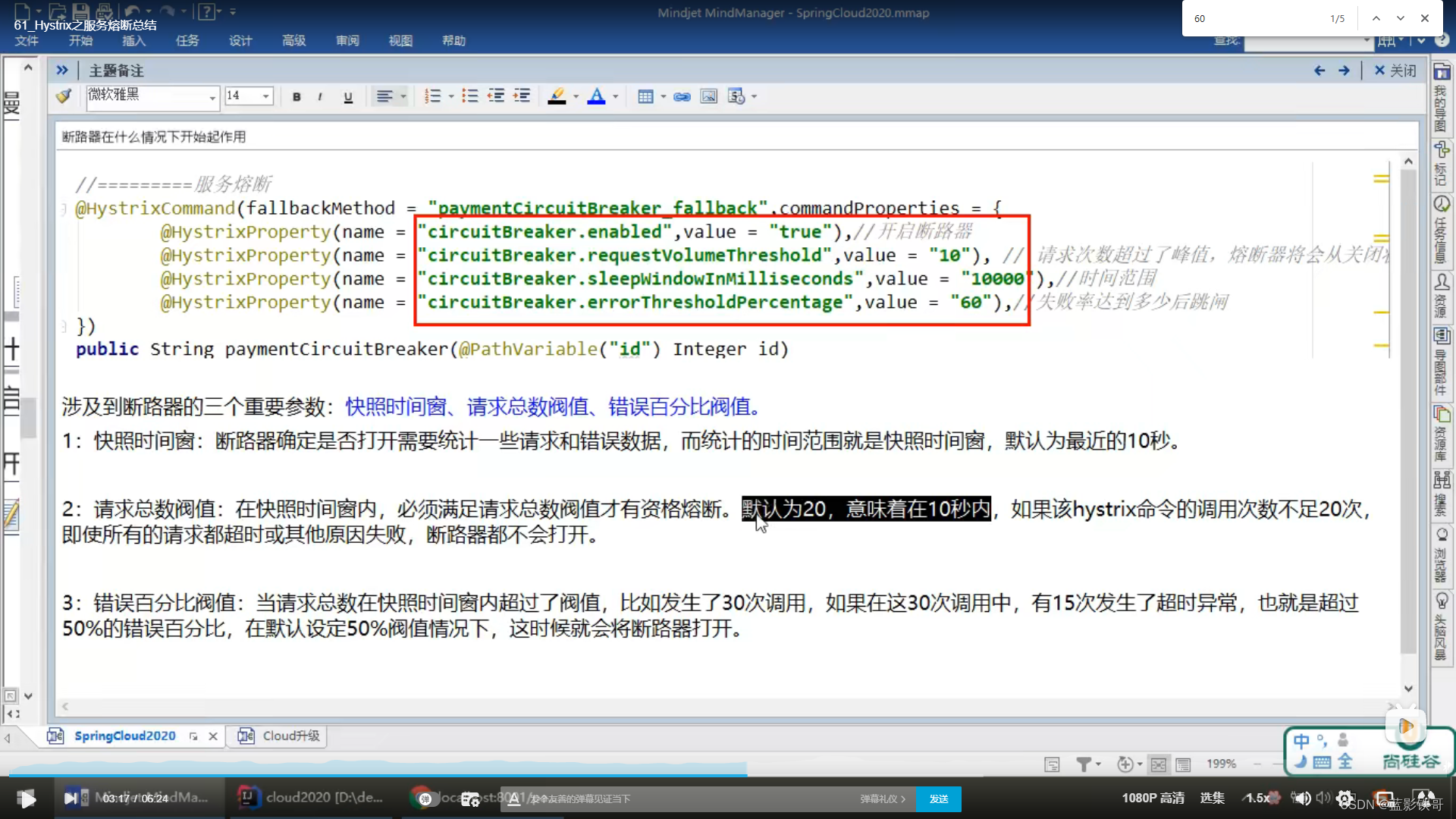
正数请求时运行正常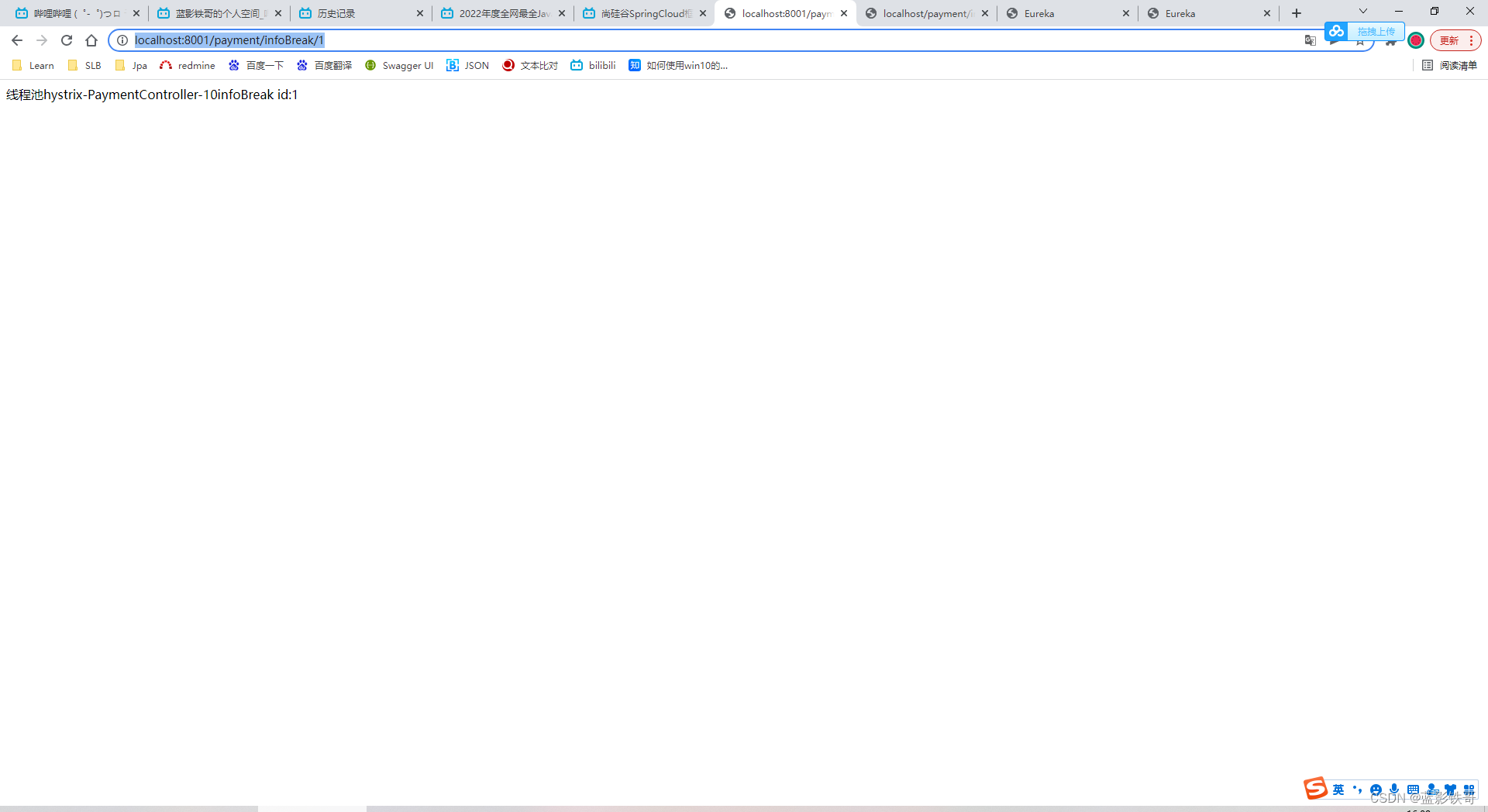
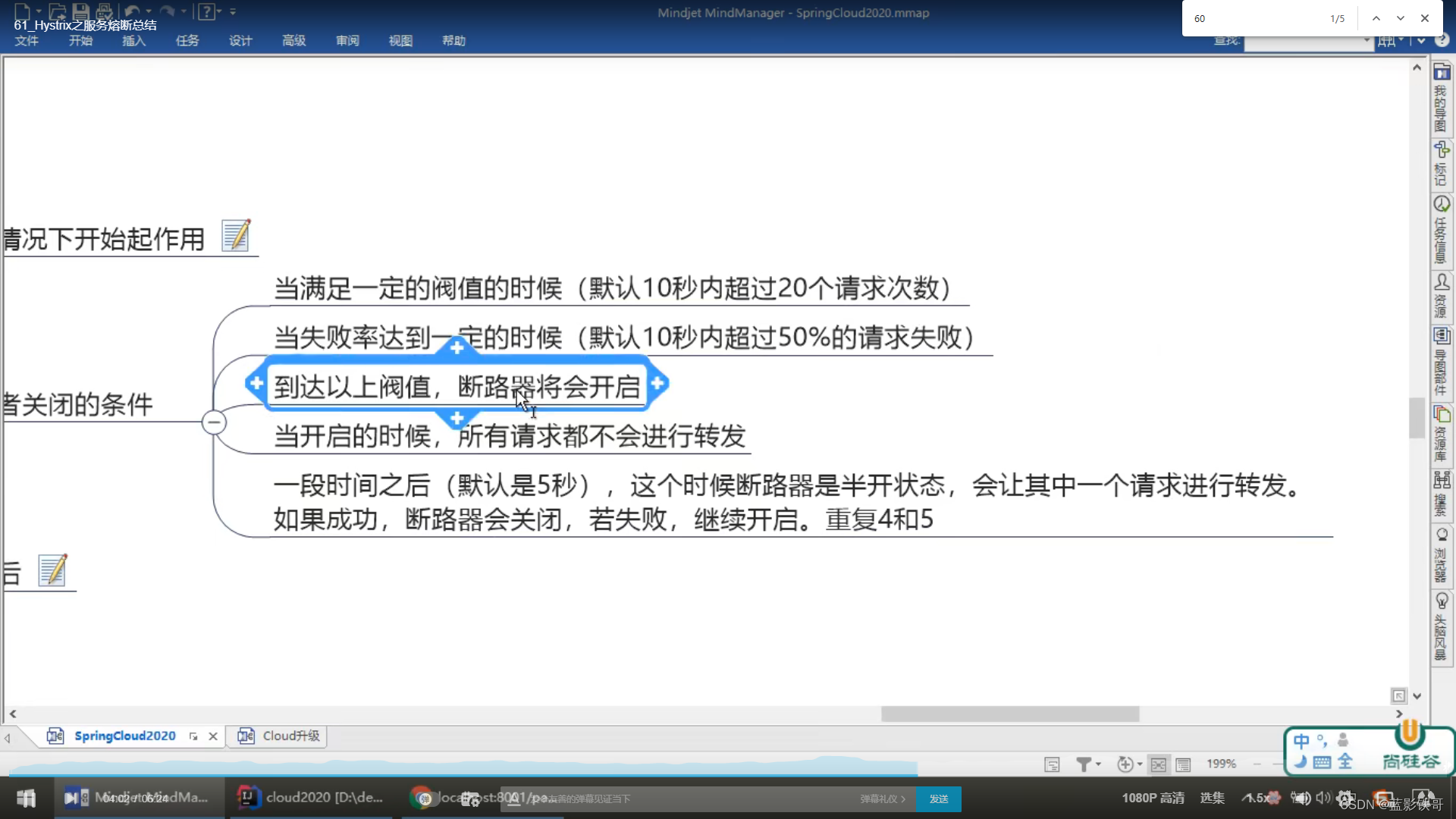
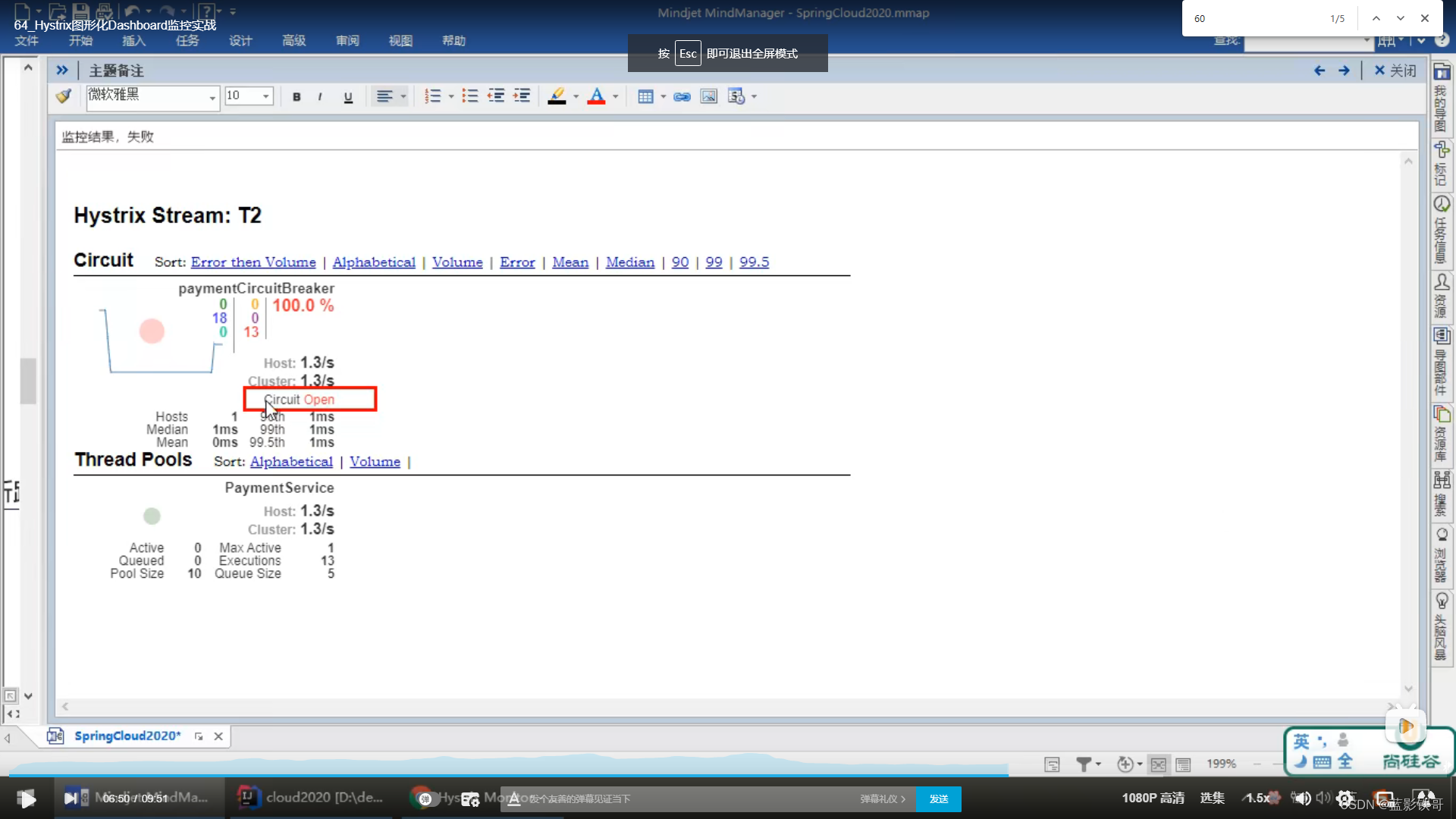
负数请求报异常,会触发服务降级走备份方法,当狂点刷新,达到配置中的10次请求6次失败(就是走备份方法),这个时候请求正数,会发现正数也失败了(说明不仅服务降级了,还熔断了,不能用了。)
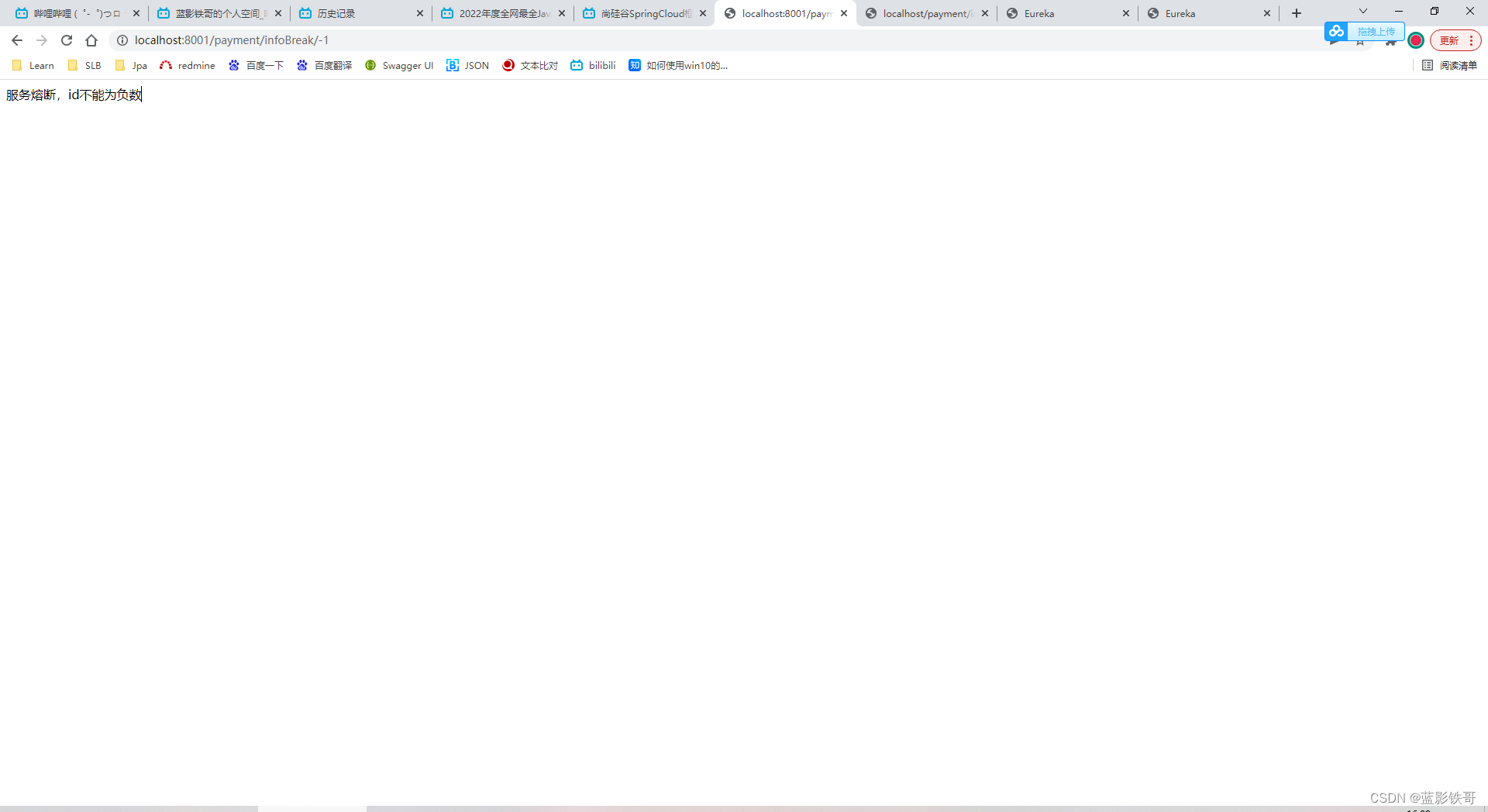
熔断了,正数请求也走备份方法了。但是过一段时间后,再次请求,又会发现正常。就是服务降级- >服务熔断->服务恢复 的过程
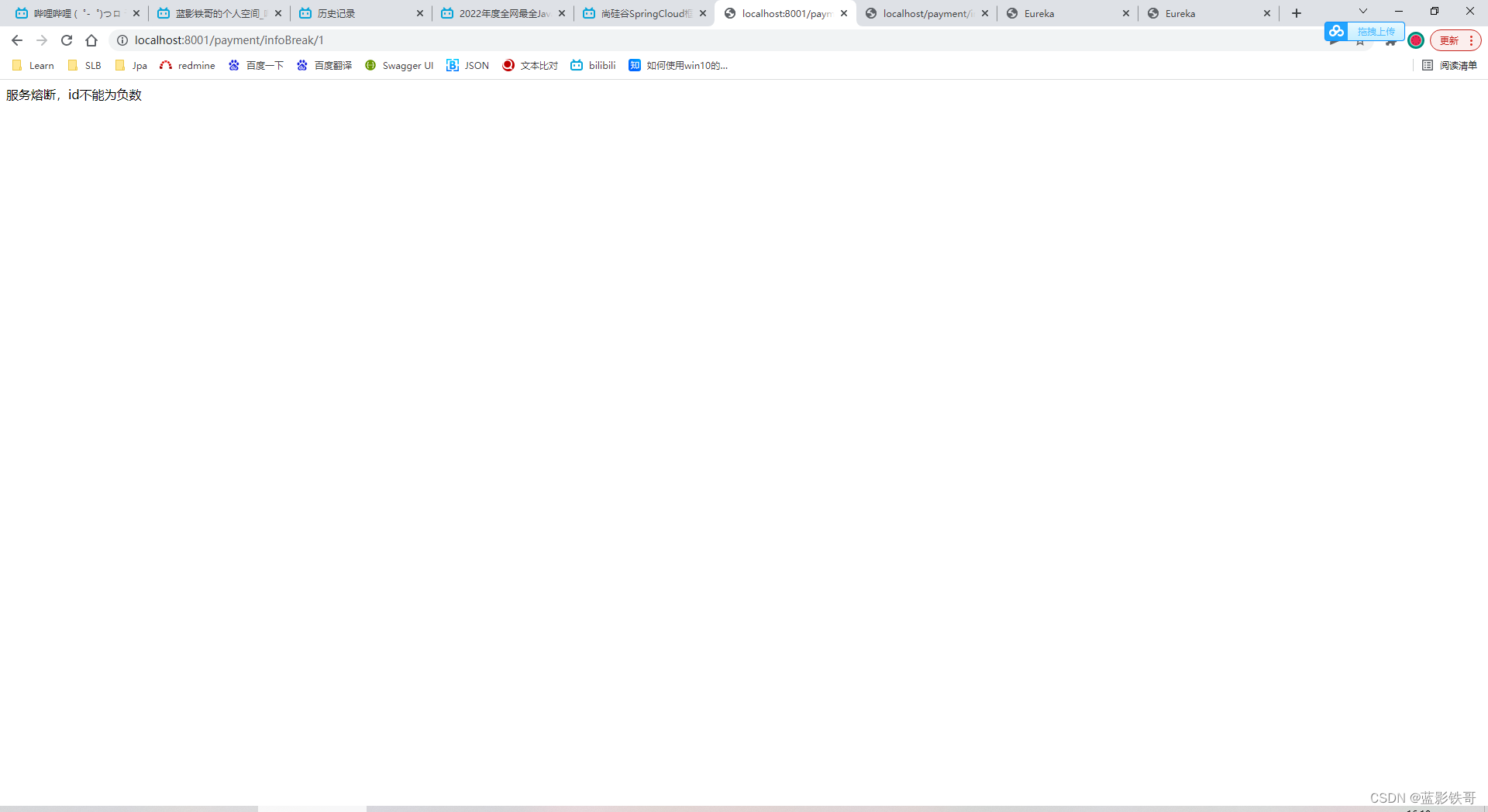
测试结果
5、服务限流看Alibaba的Sentinel(后面)
6、豪猪哥HystrixDashboard
6.1、概念
6.2、监控端修改
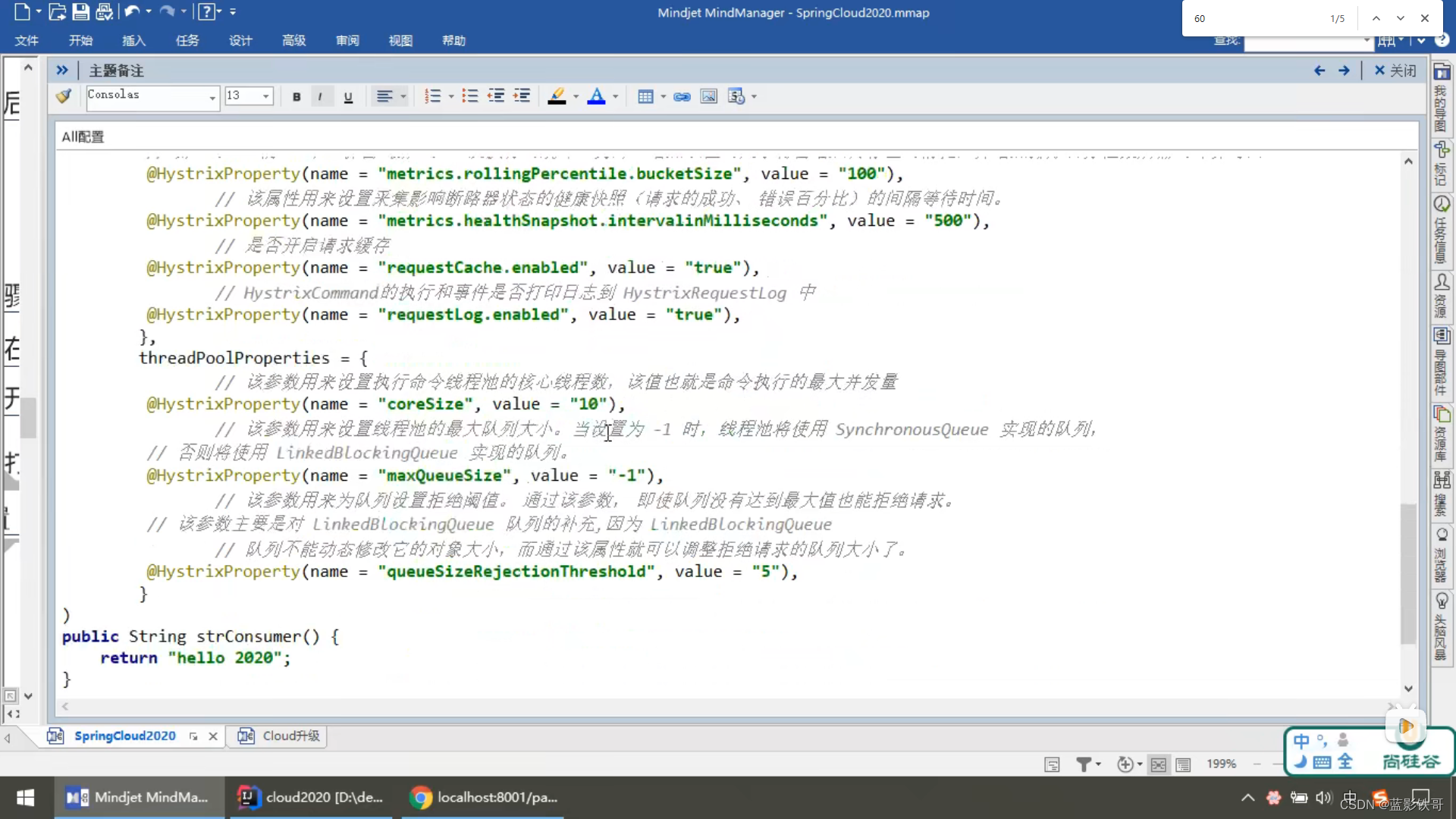
改POM
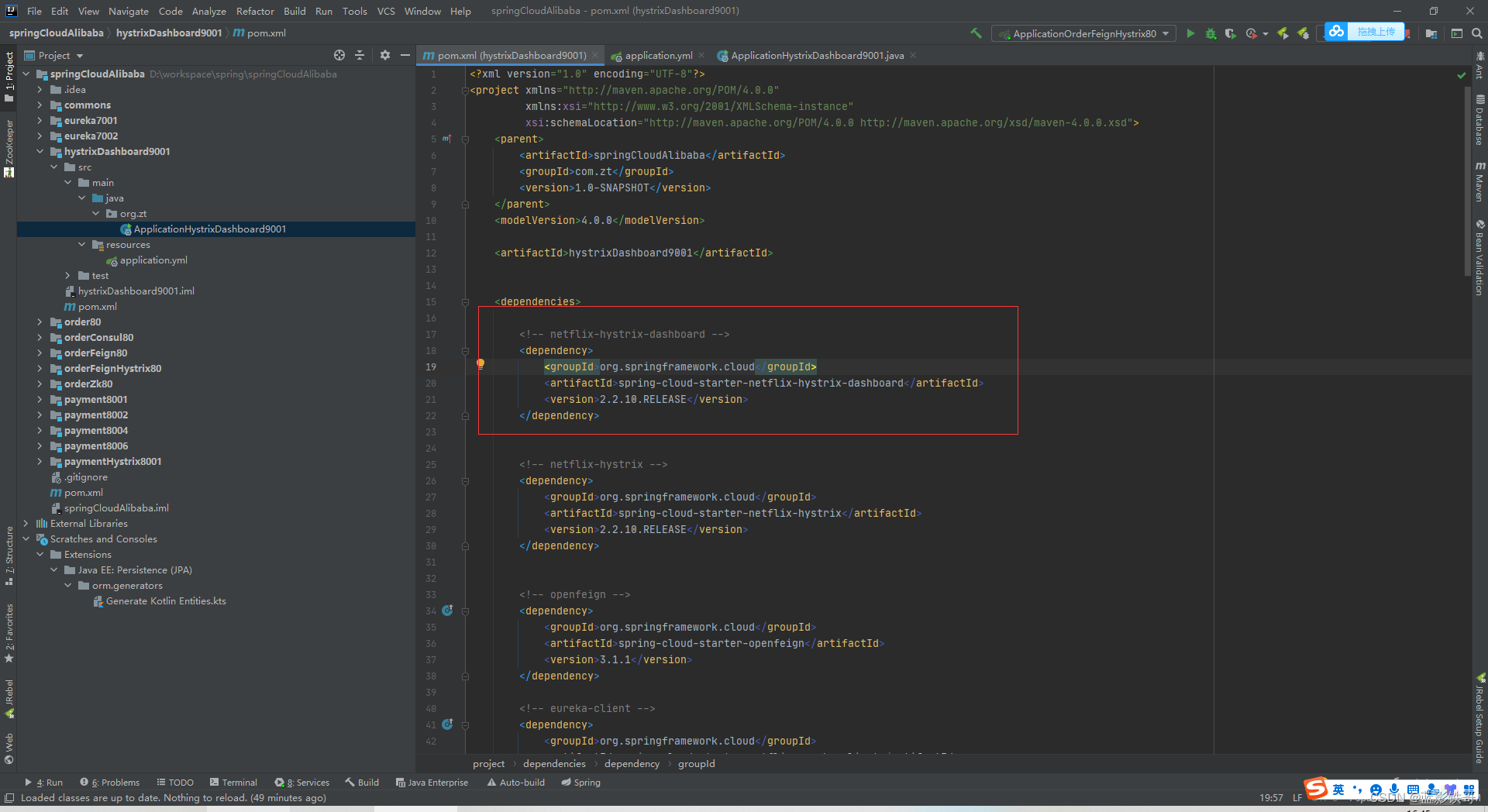
简单yml(有坑,看下面截图)
改启动类
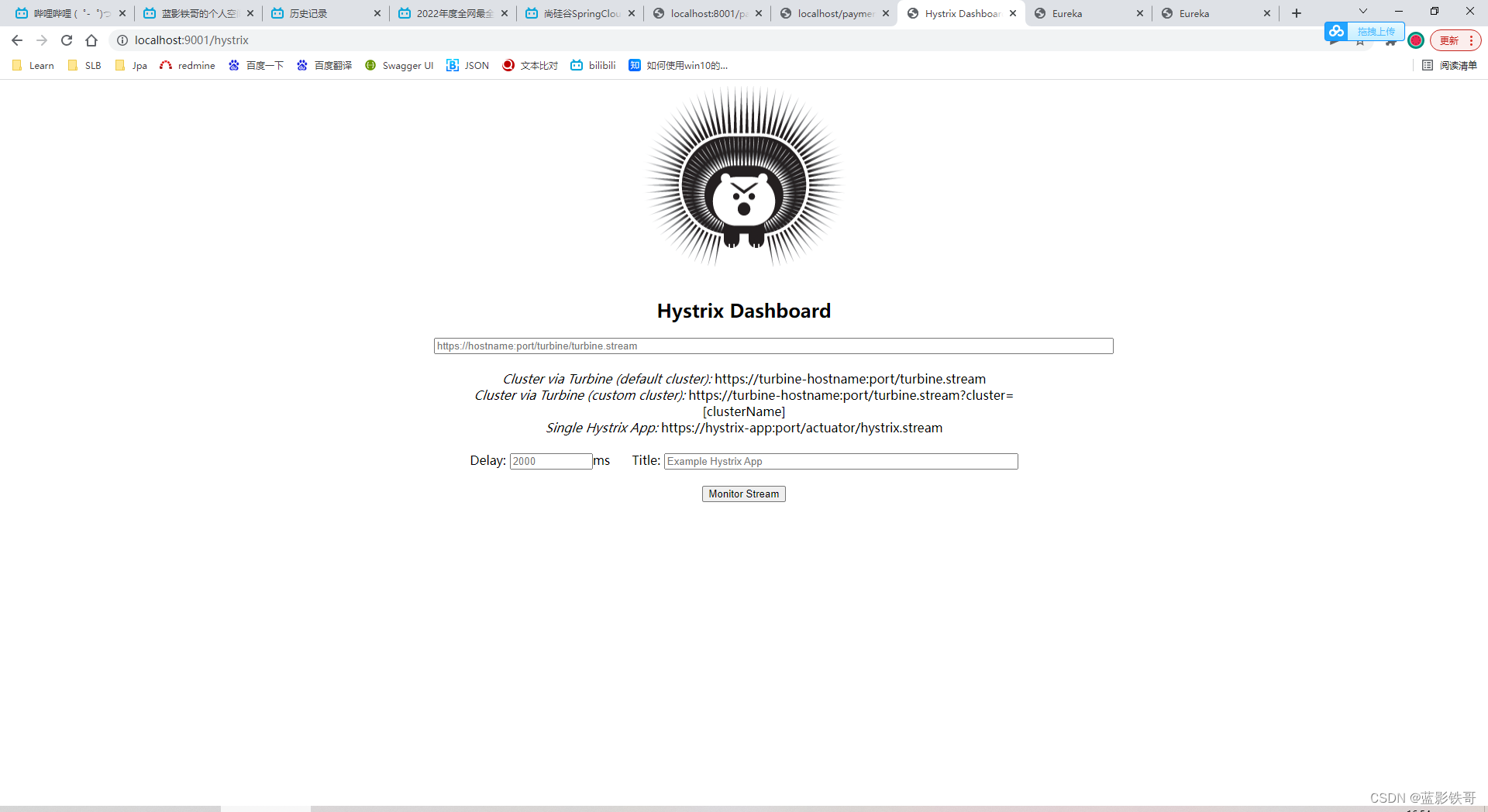
放问地址 : http://localhost:9001/hystrix
http://localhost:8001/hystrix.stream 注意截图有错误,stream写错了steam

6.3、服务提供者修改(被监控端)
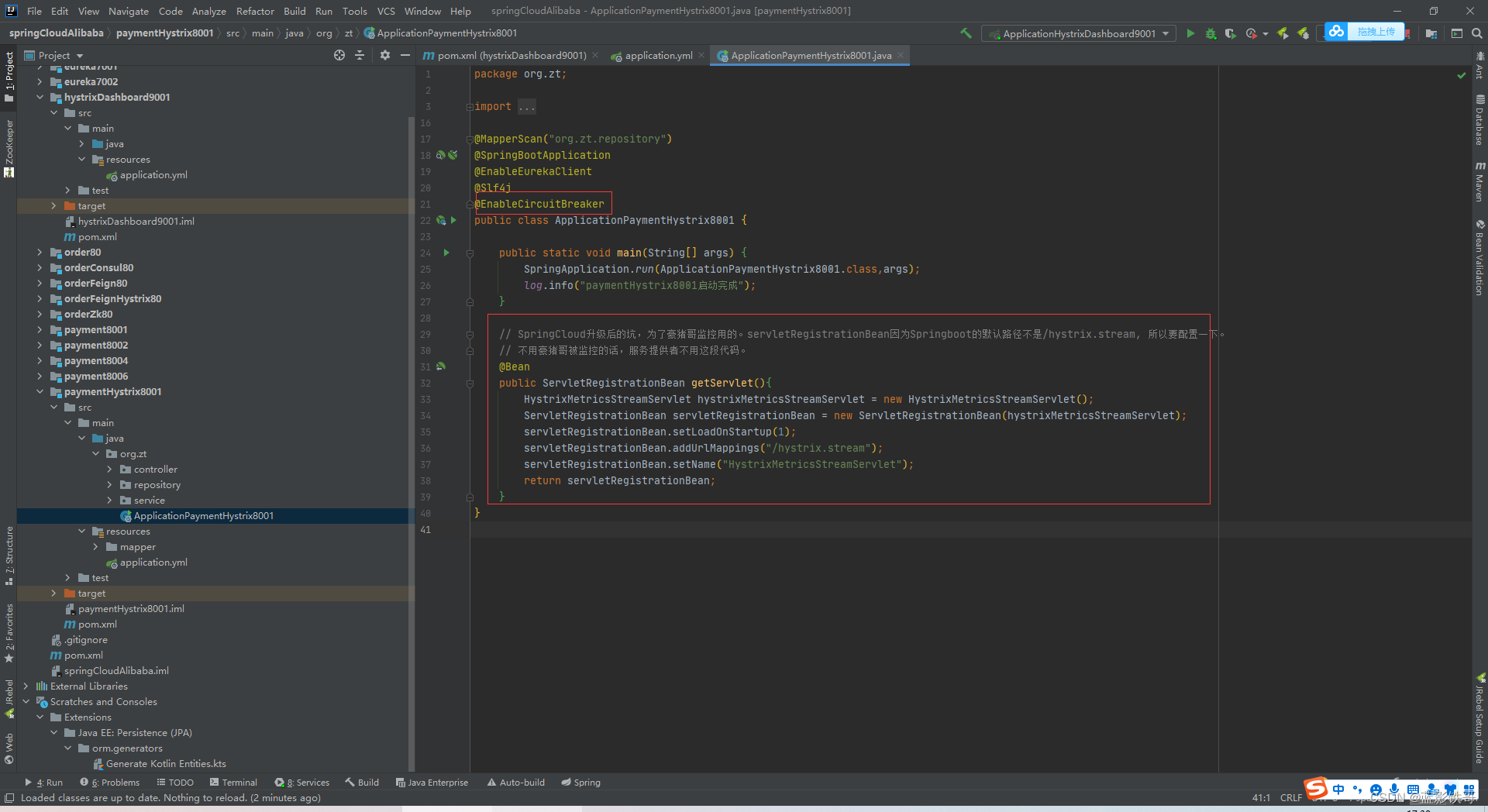
6.4、坑有3处
监控端要加这个,不然 http://localhost:8001/hystrix.stream会报错,日志提示要加入xxxList之类的,需要这边加配置
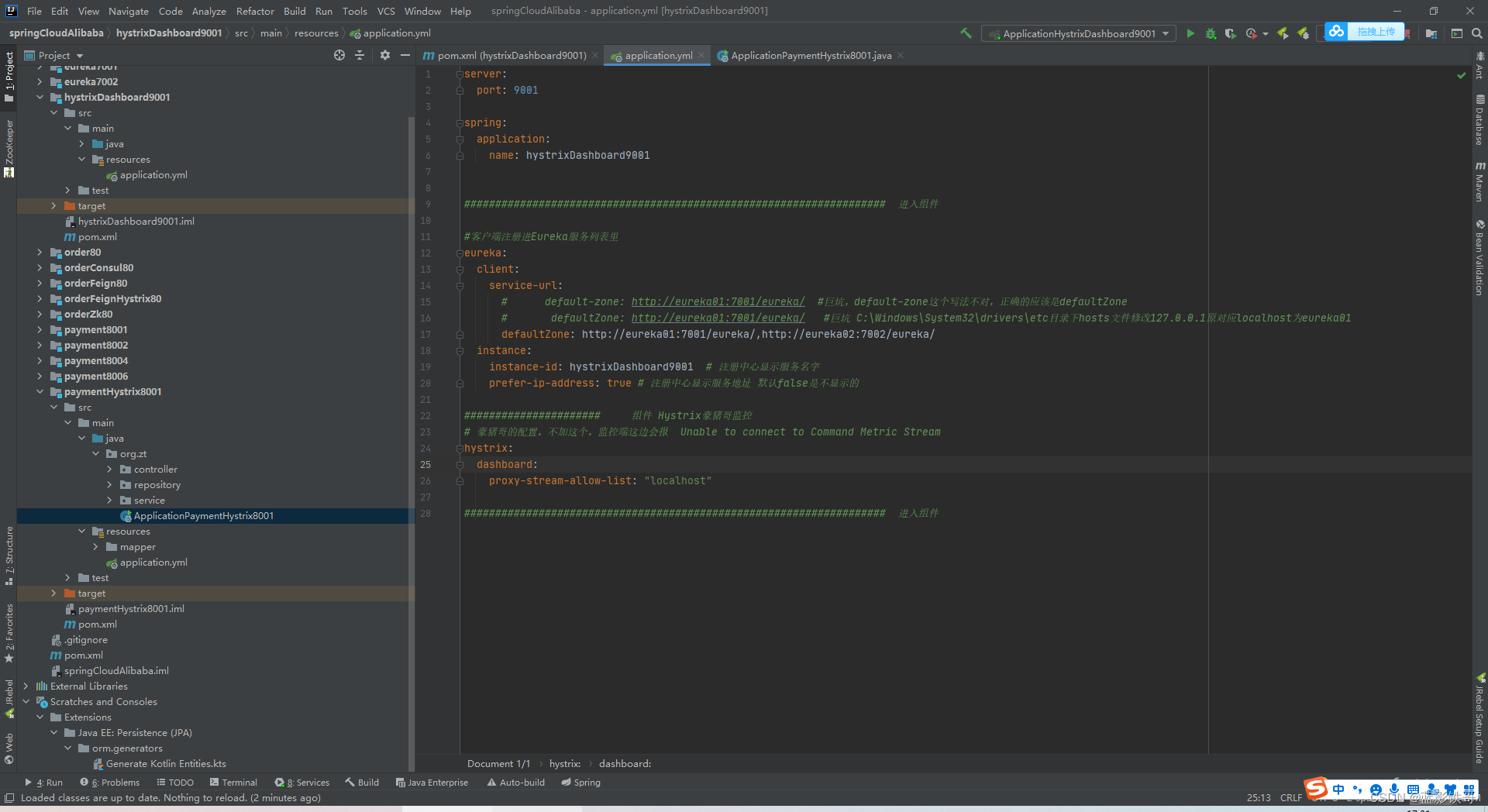
这段代码不加,http://localhost:8001/hystrix.stream会报404错误
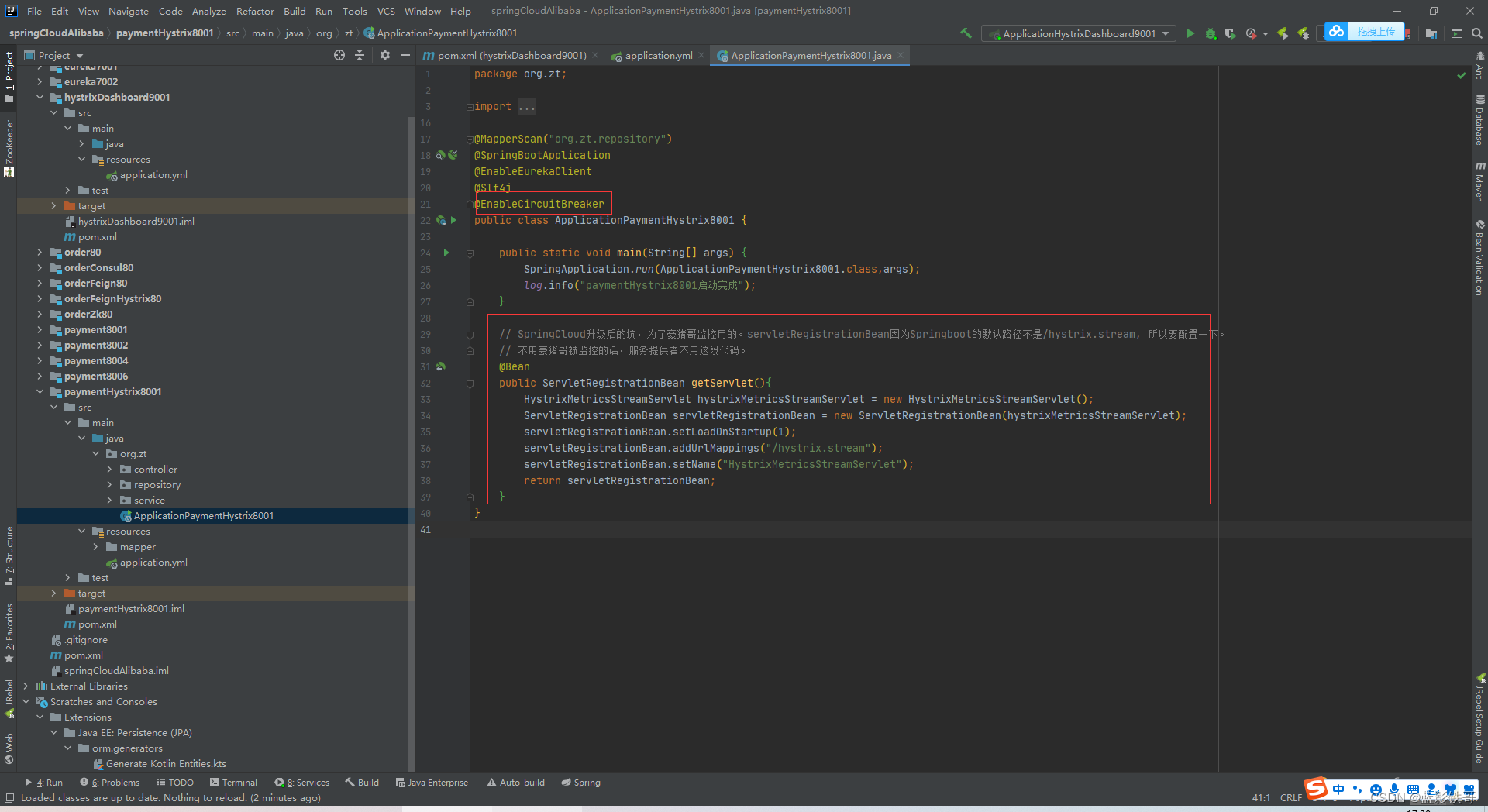
这个监控信息要加,不然也会报错。

6.5、测试结果
二、Sentinel
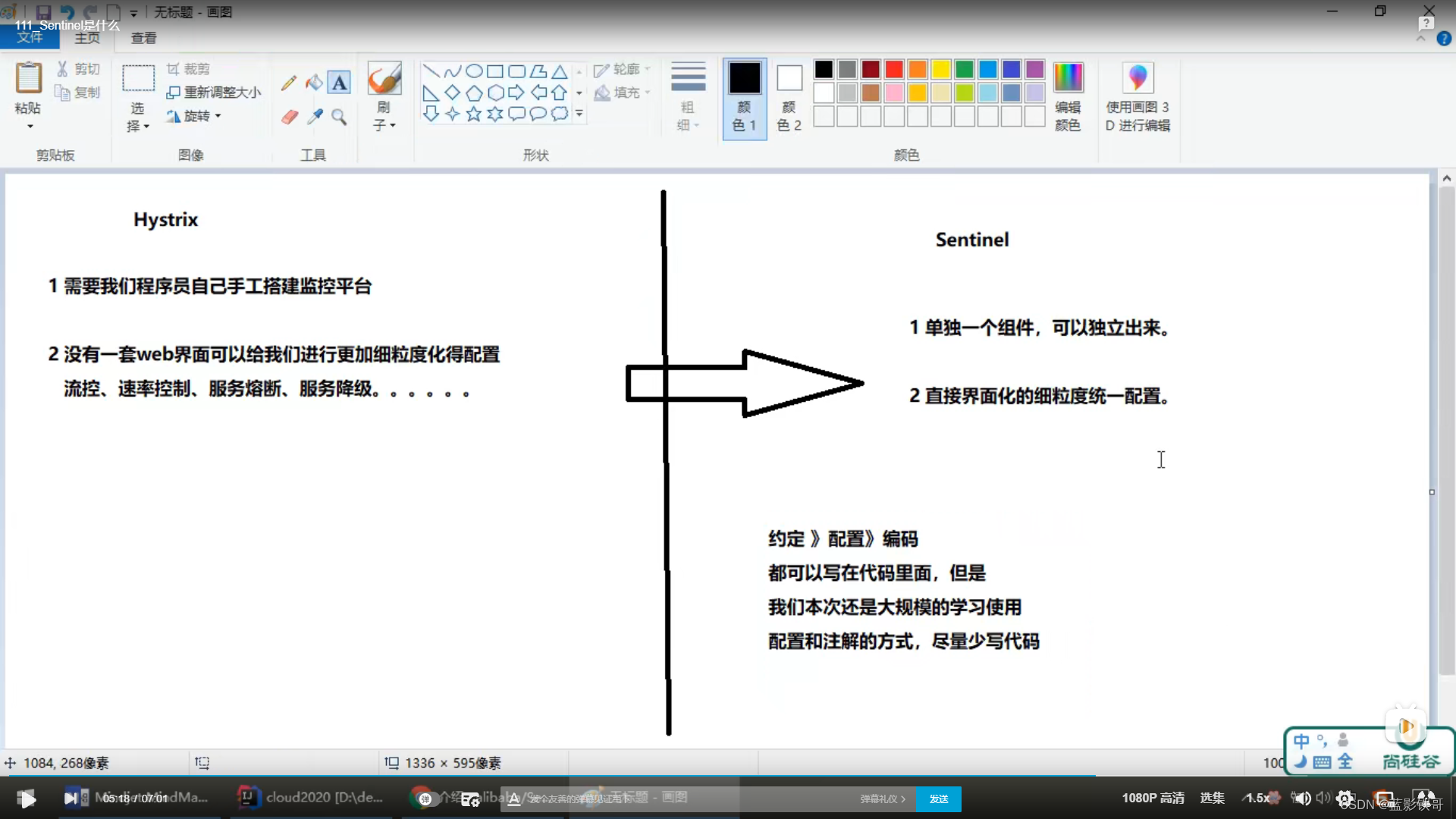
1、概念
2、安装运行
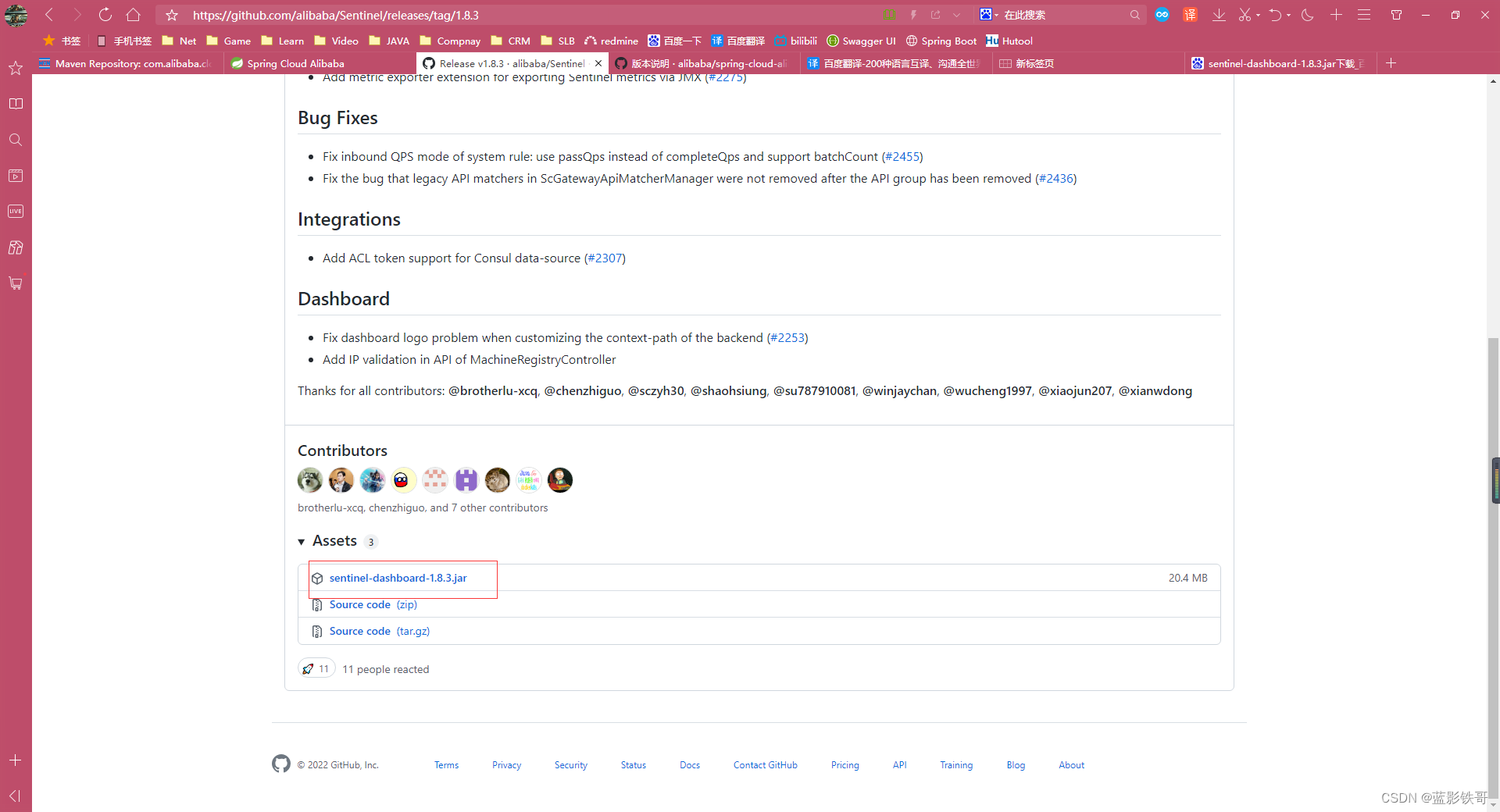
一定要下载匹配nacos等的版本,这个是个jar包,运行的话直接java -jar运行 java -Dserver.port=指定的端口号 -jar jar文件全名。
cd /usr/local/sentinel
nohup java -Xmx512m -Xms512m -Dserver.port=8080 -jar sentinel-dashboard-1.8.3.jar >/dev/null 2>&1 &
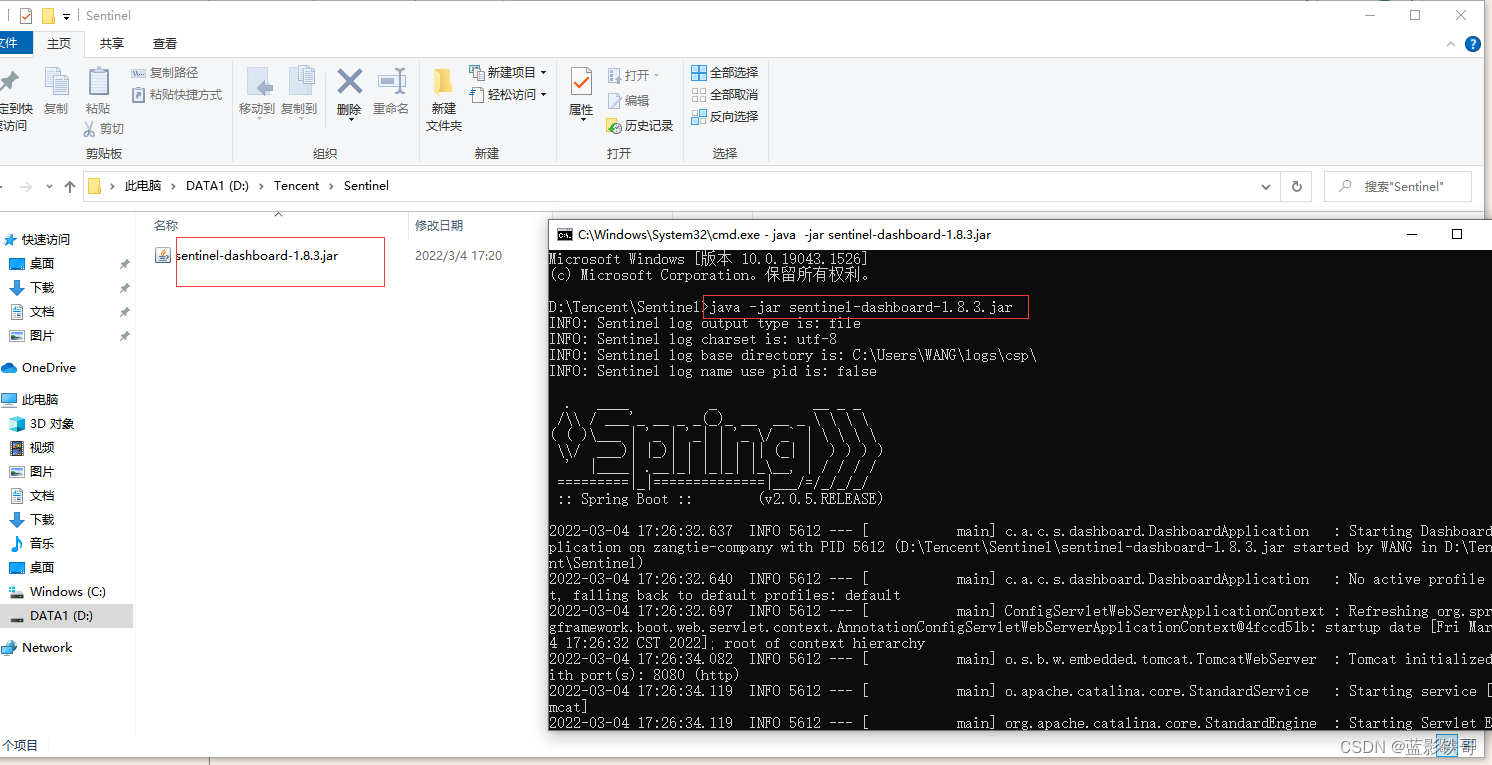
运行

http://localhost:8080/ 账号密码默认都是 sentinel
3、入门案例
3.1、配置一个客户端
改POM
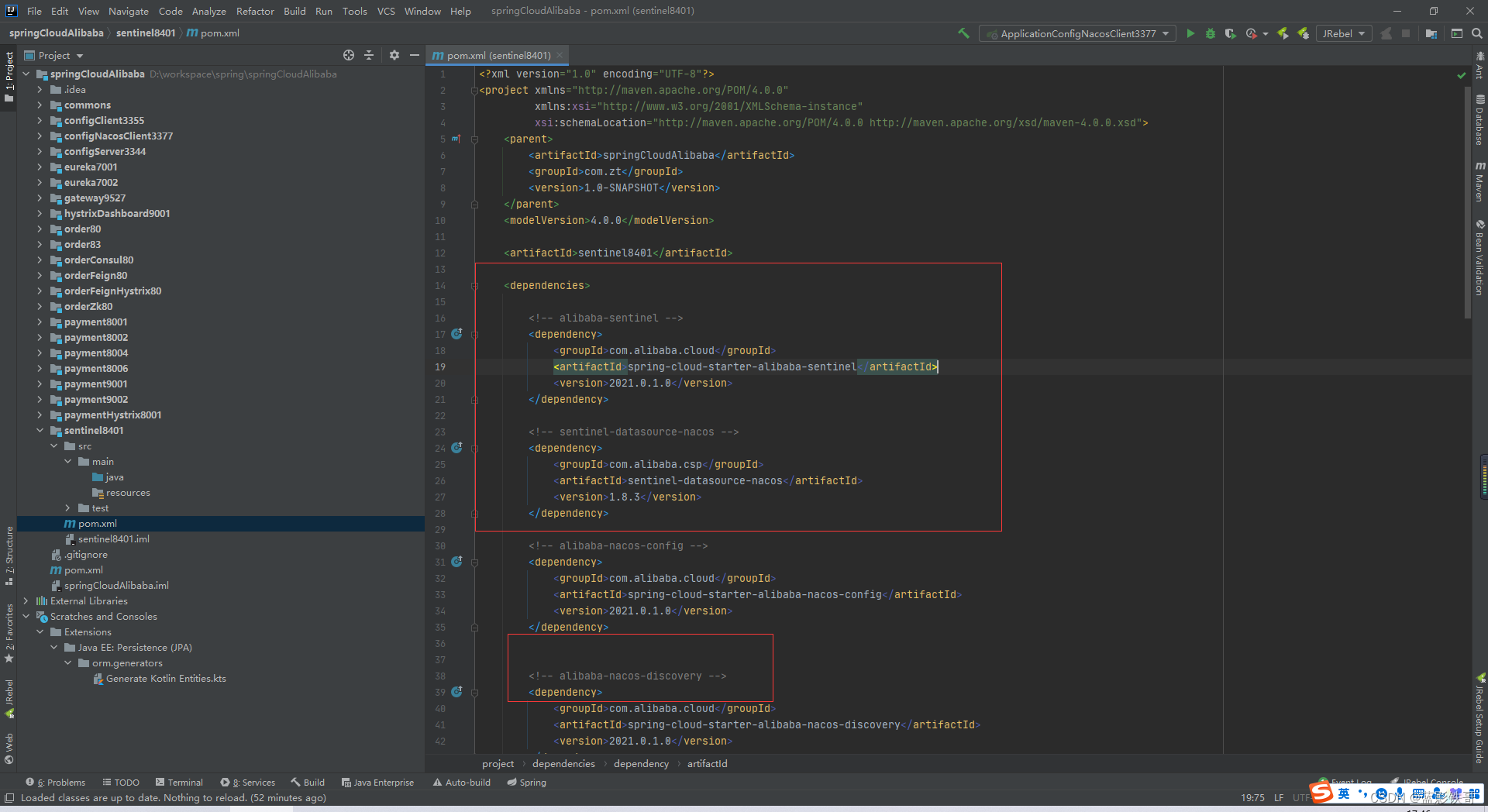
改yml
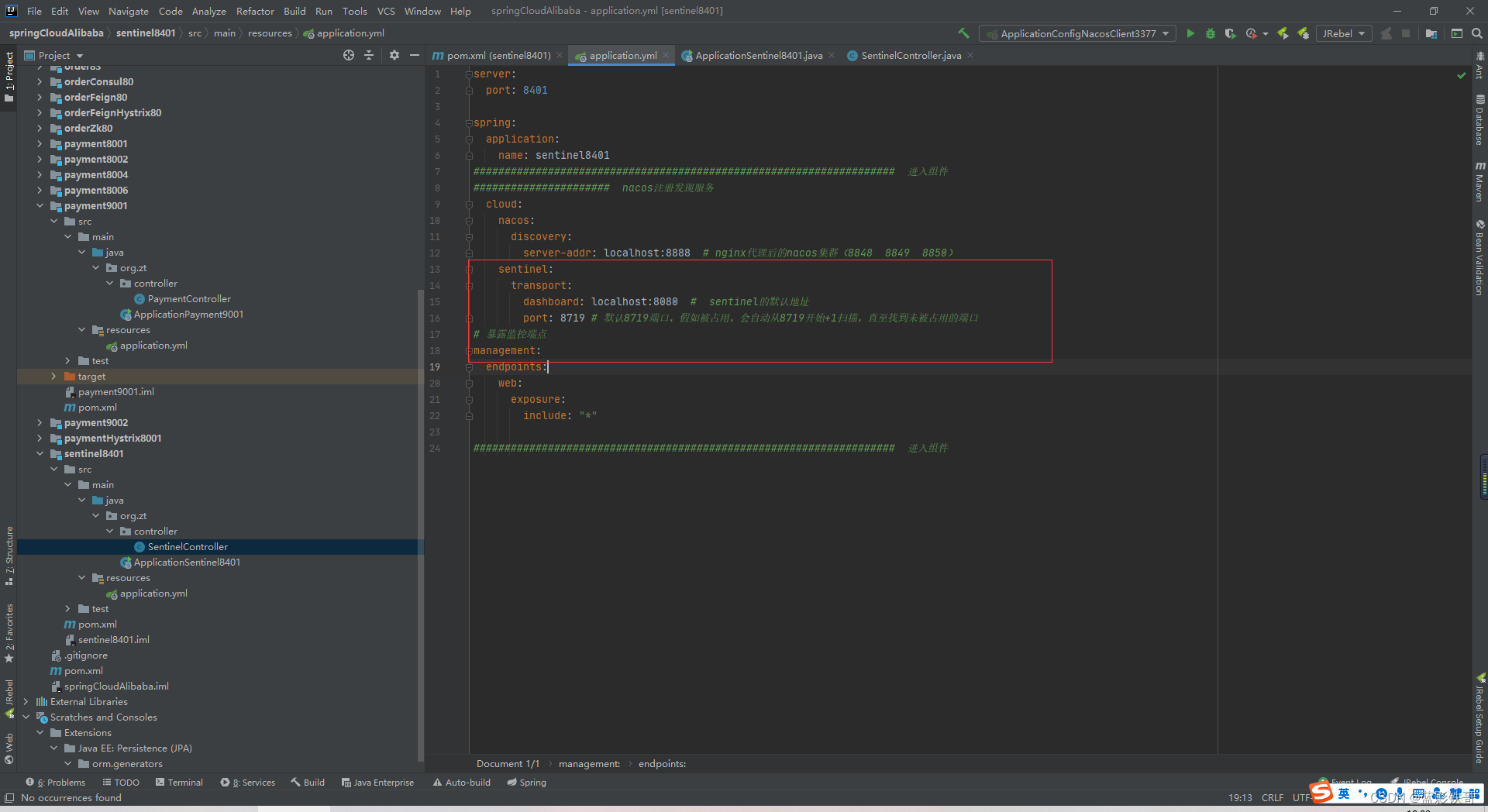
改启动类
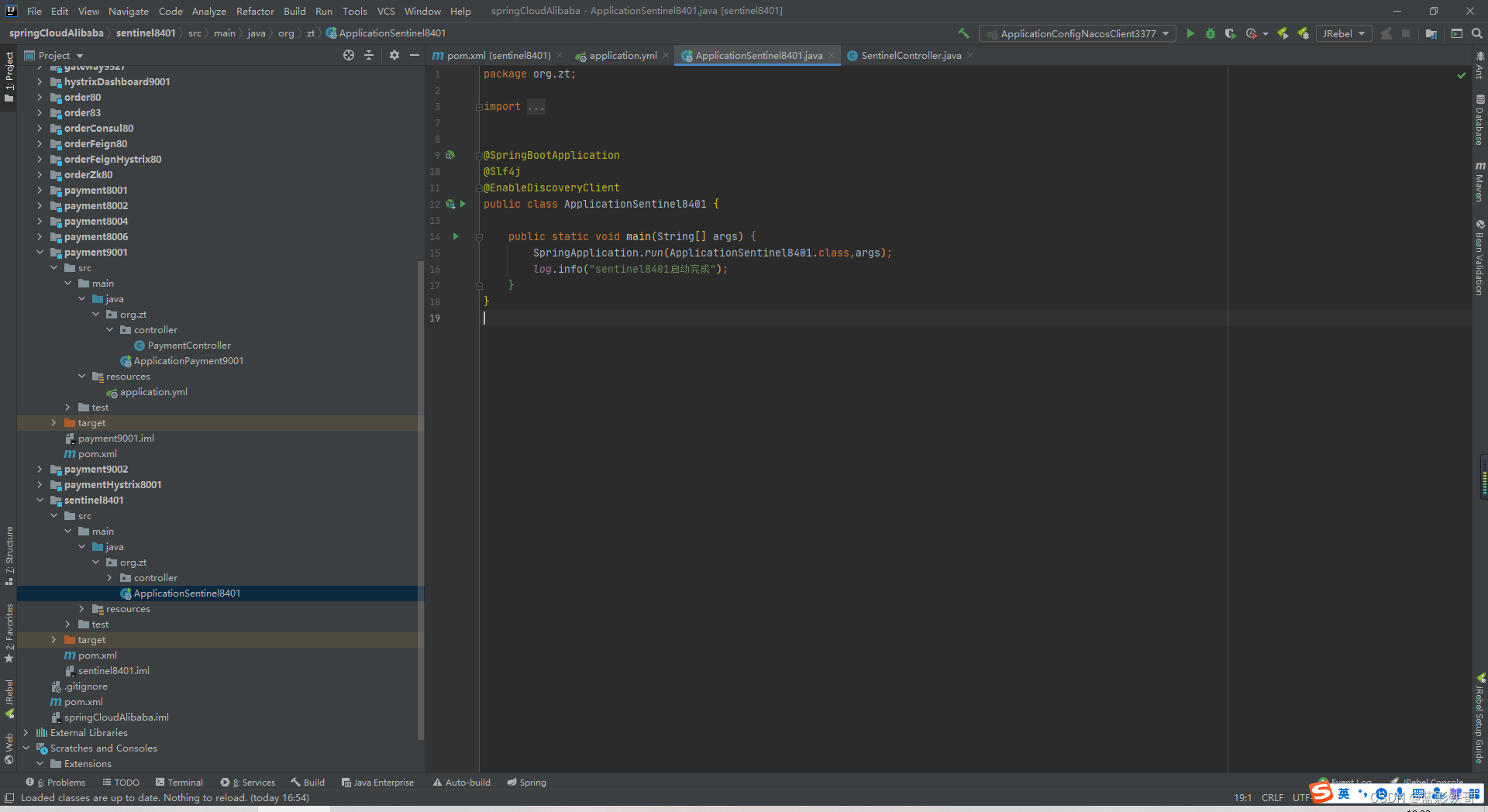
业务类
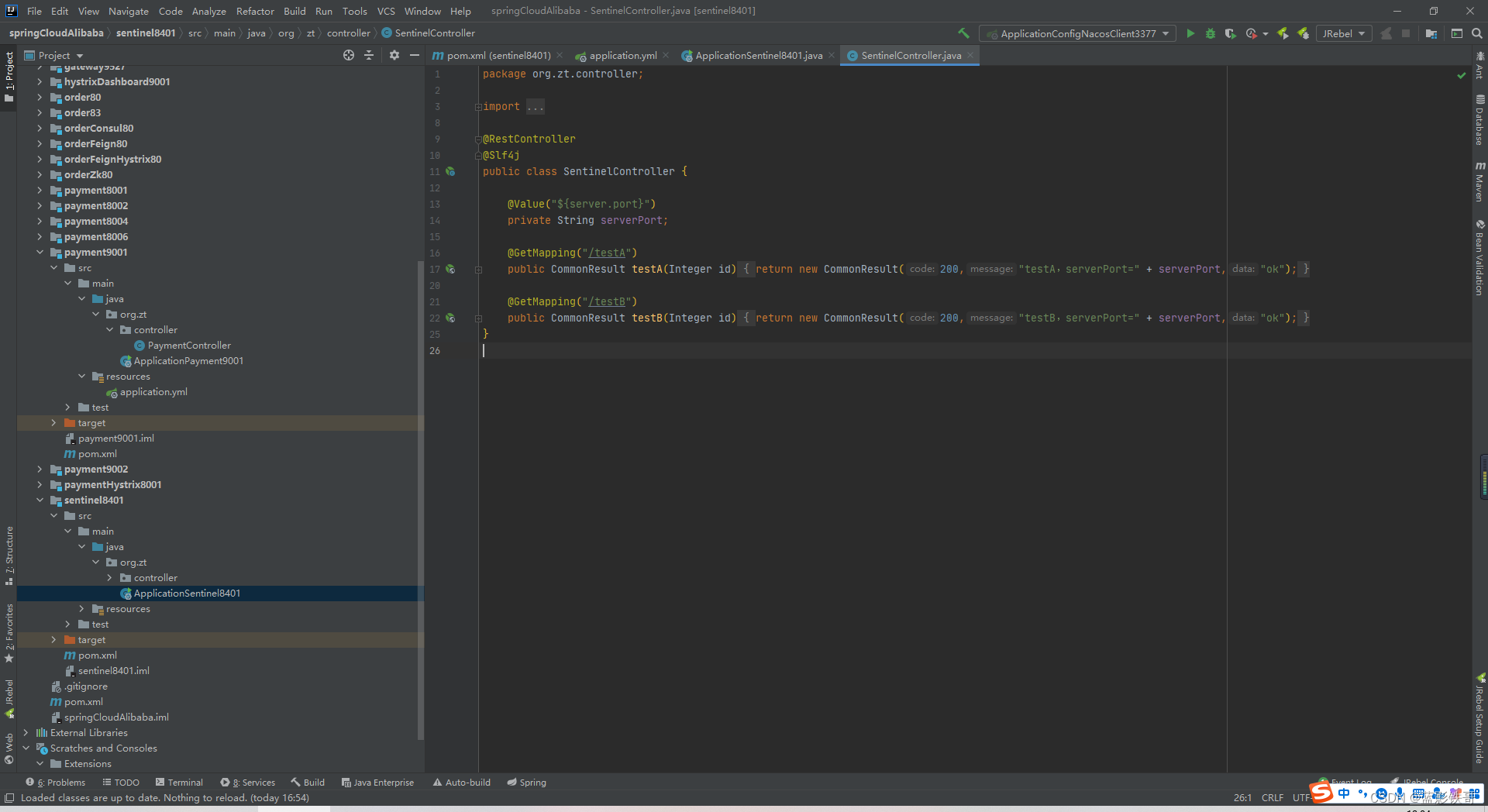
3.2、测试结果
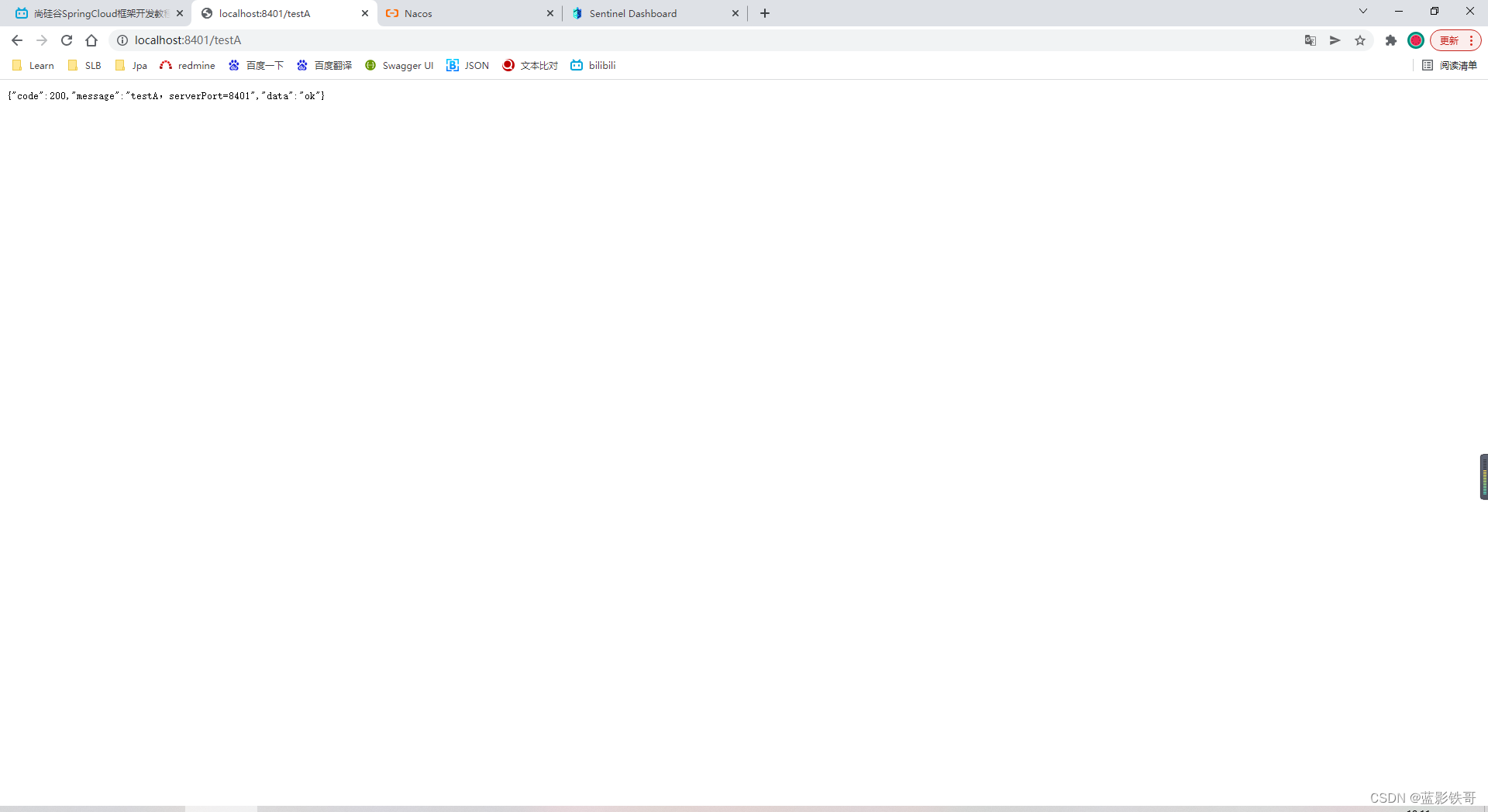
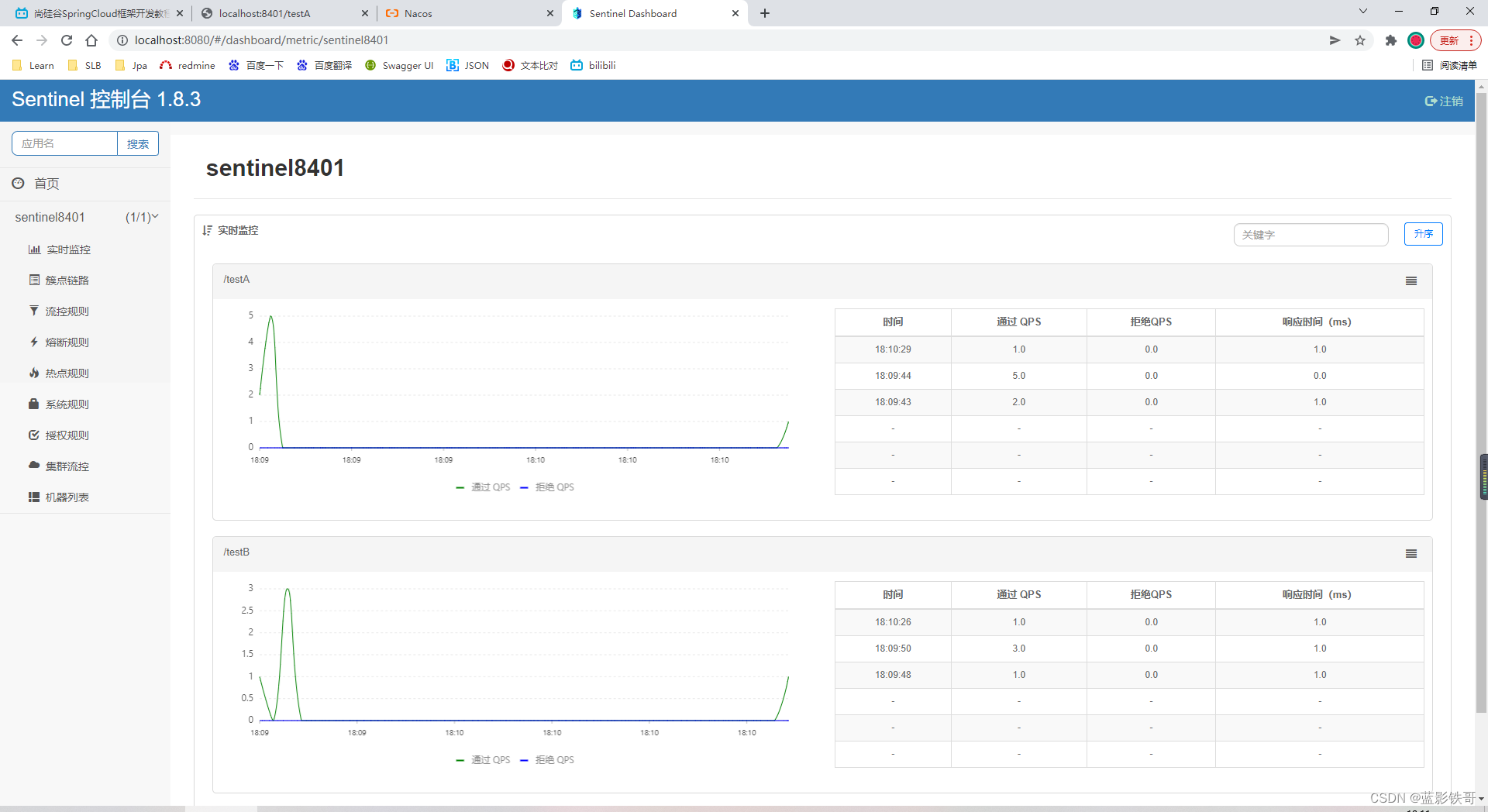
4、流控规则
4.1、概念大纲
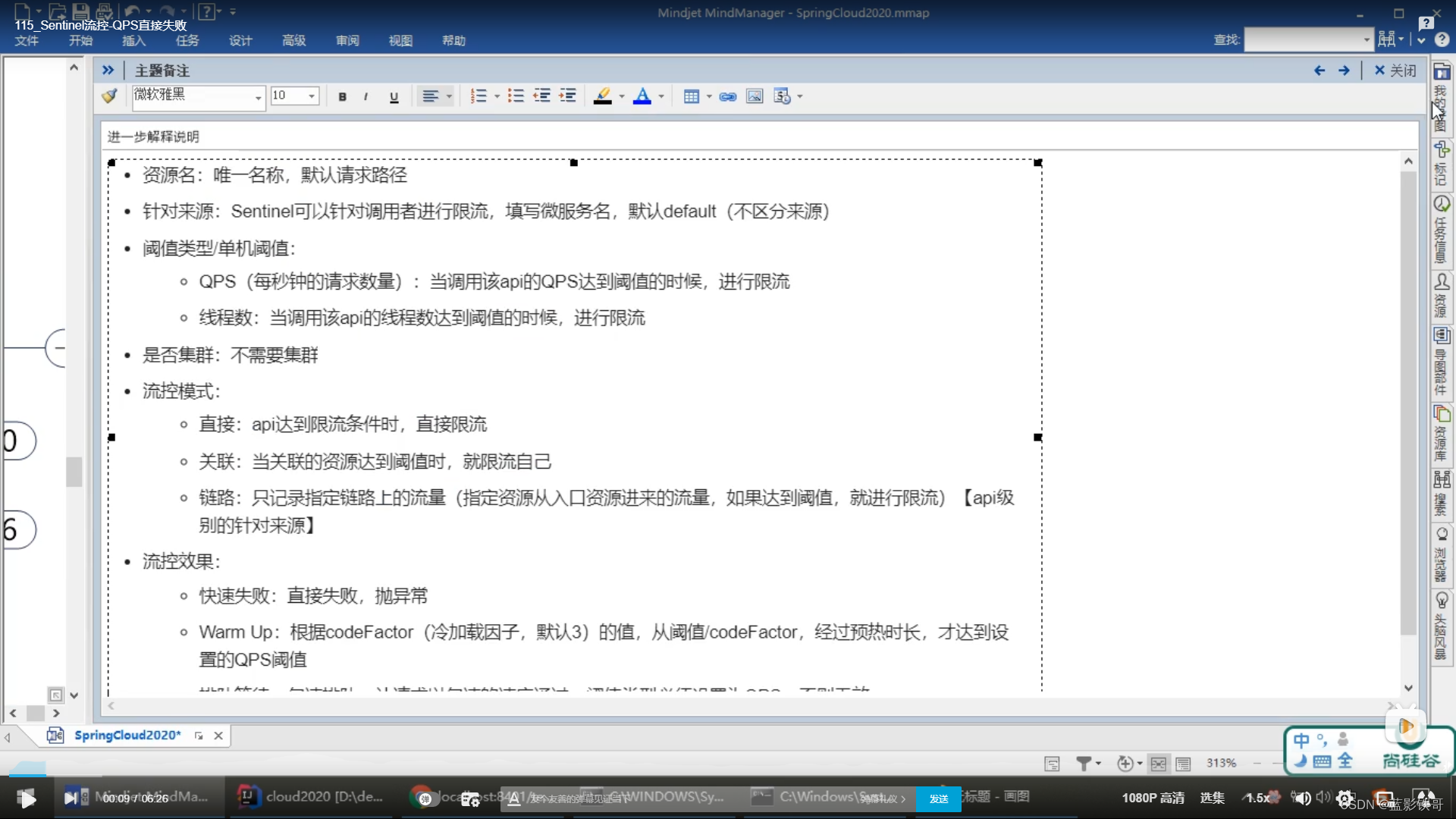
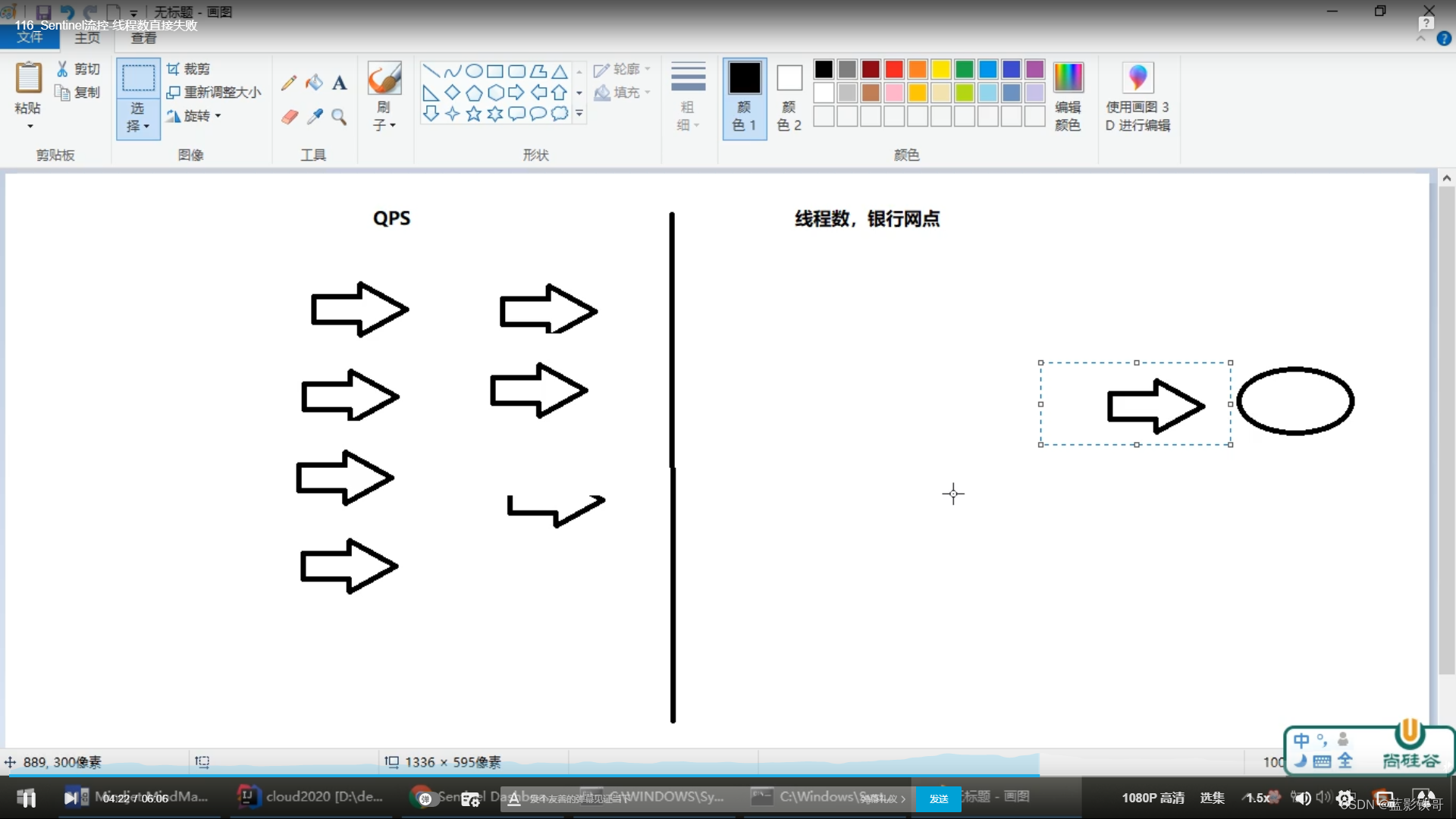
4.2、QPS和线程数
QPS(每秒钟请求数量)
QPS御敌于国门之外(没有进来,当设置为1秒的时候,1秒内狂点请求,只有第一个有效,其他都被拦截了。),线程数放进来关门打狗(进来了,但是只有一个工作人员处理,如果处理时间比较长比如处理一个接口长达1秒,那么1秒内的其他同样请求就会被拦截。)
5、流控模式
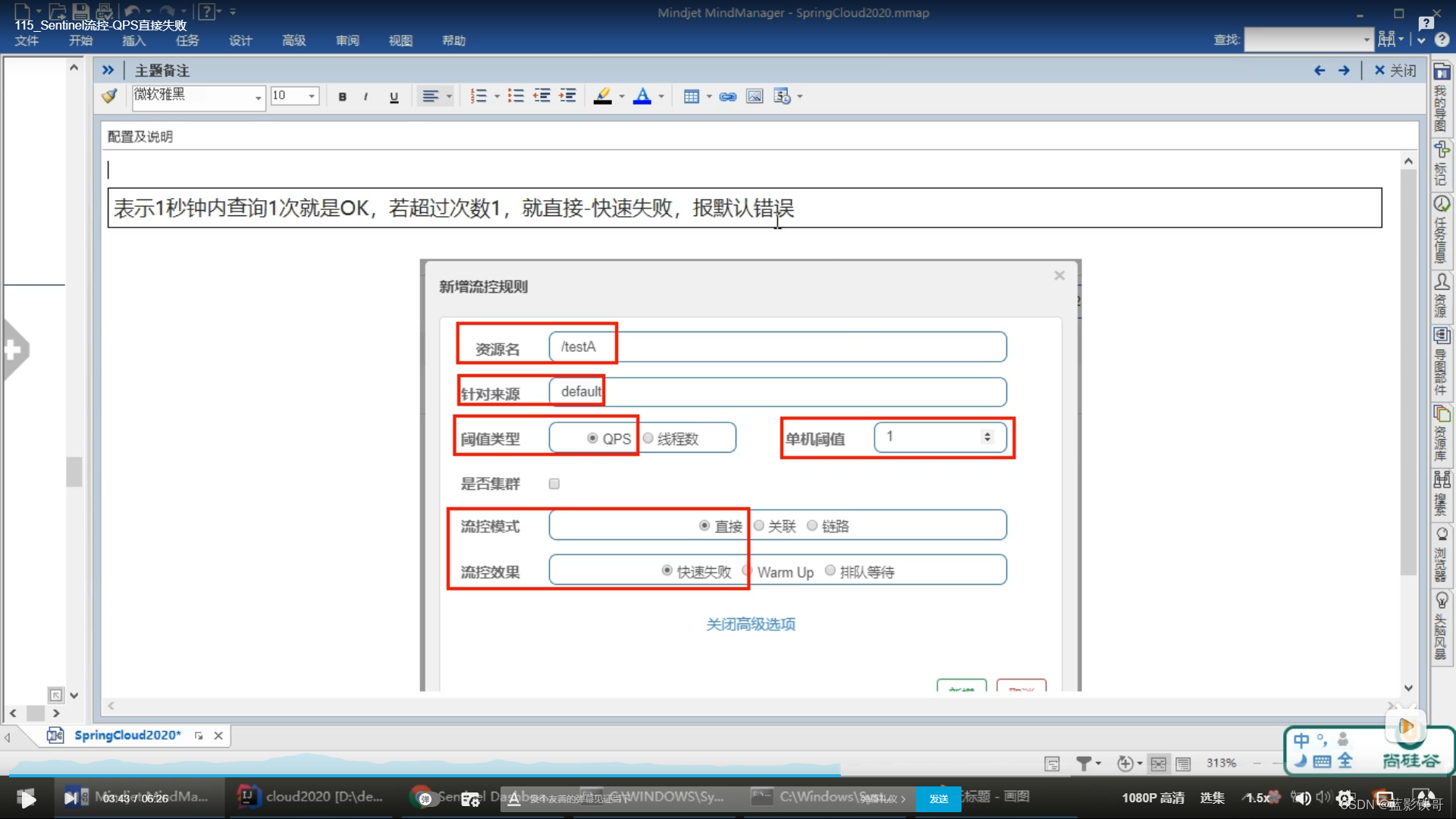
5.1、直接(默认模式)
默认报错
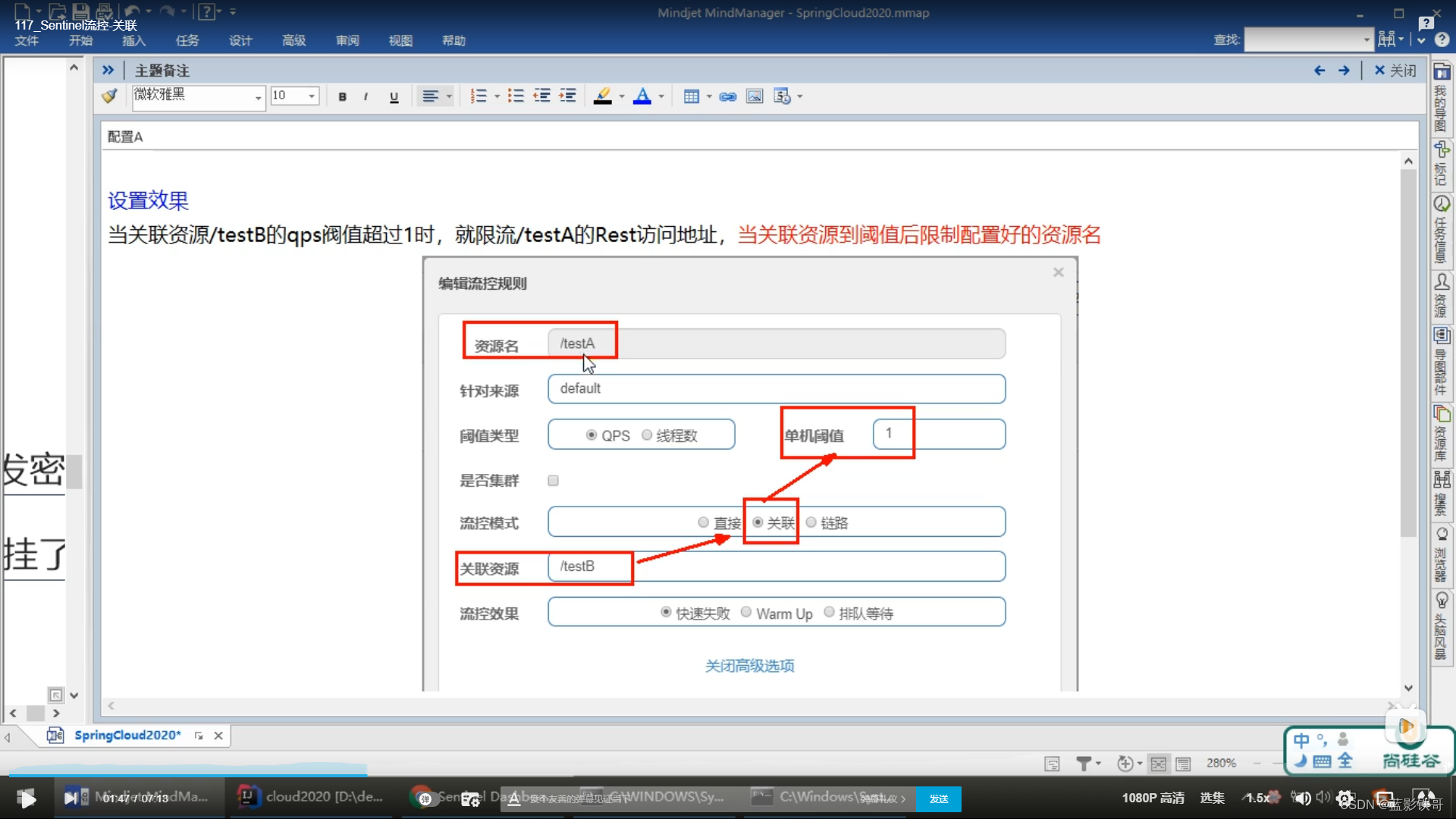
5.2、关联
比如支付接口高请求,就限流下订单的接口
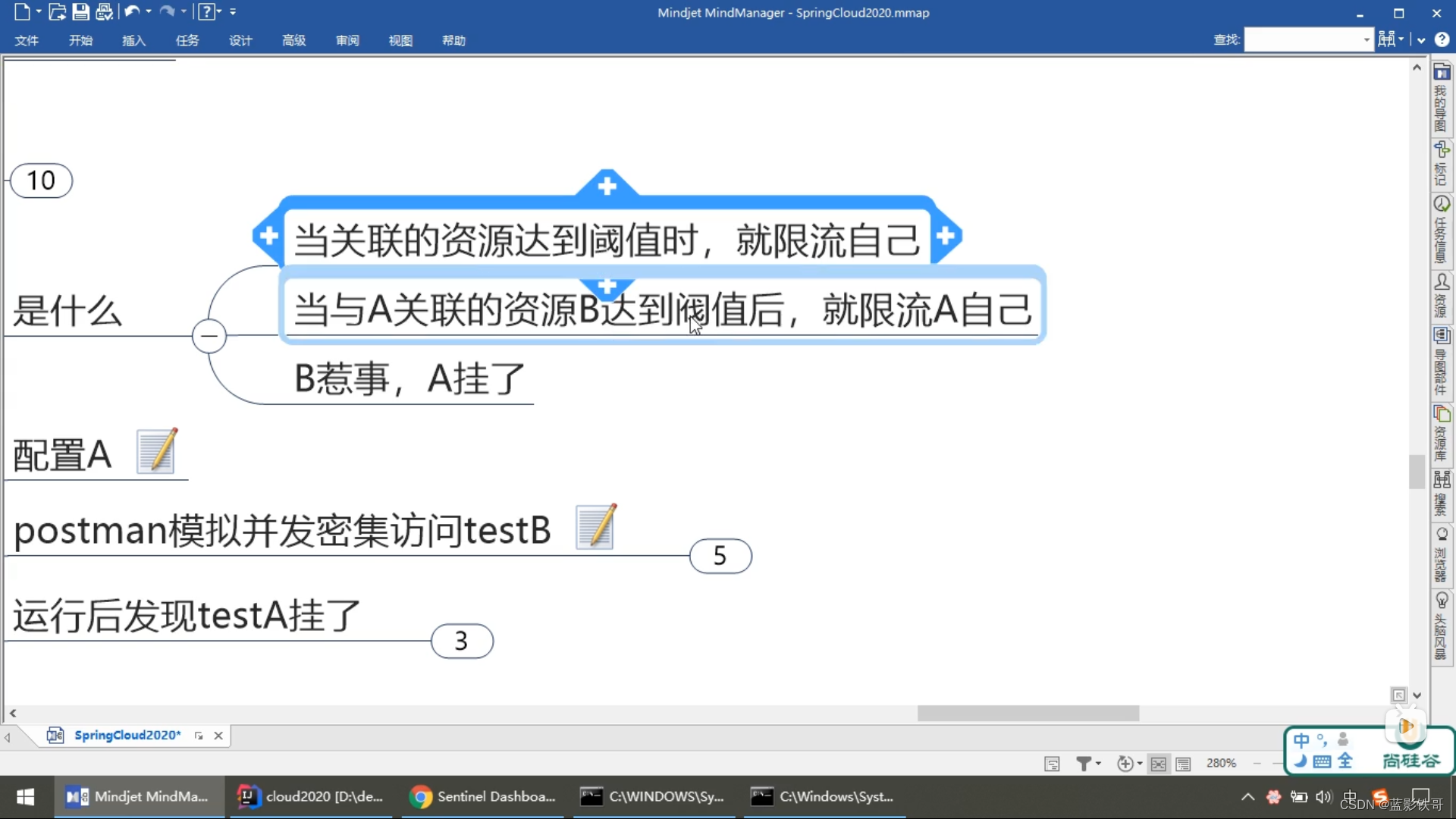
配置A 这种就是B满了(支付),A就要被限流了(下订单)
6、流控效果
6.1、直接(默认模式)
同5.1上图,默认报错
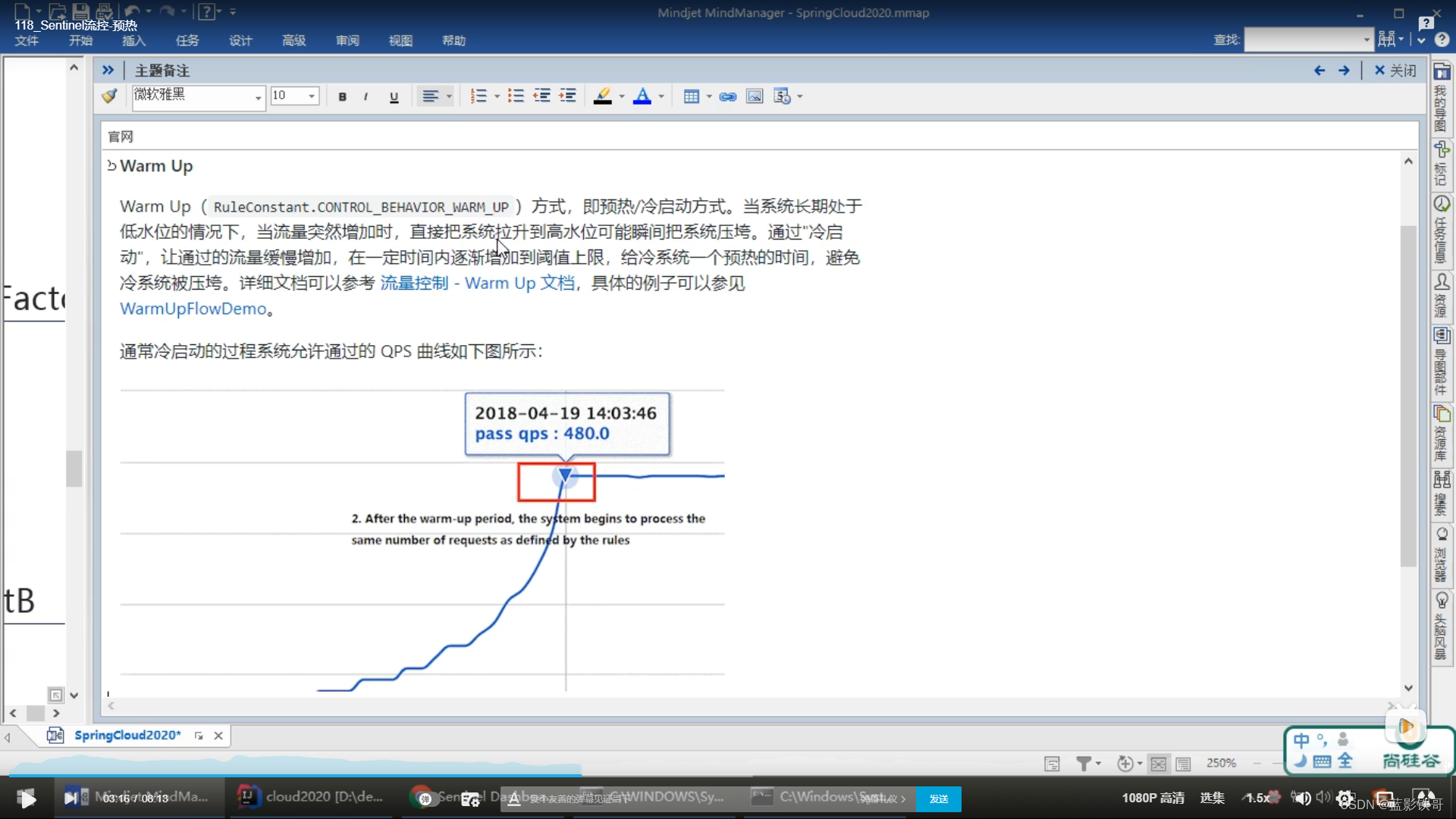
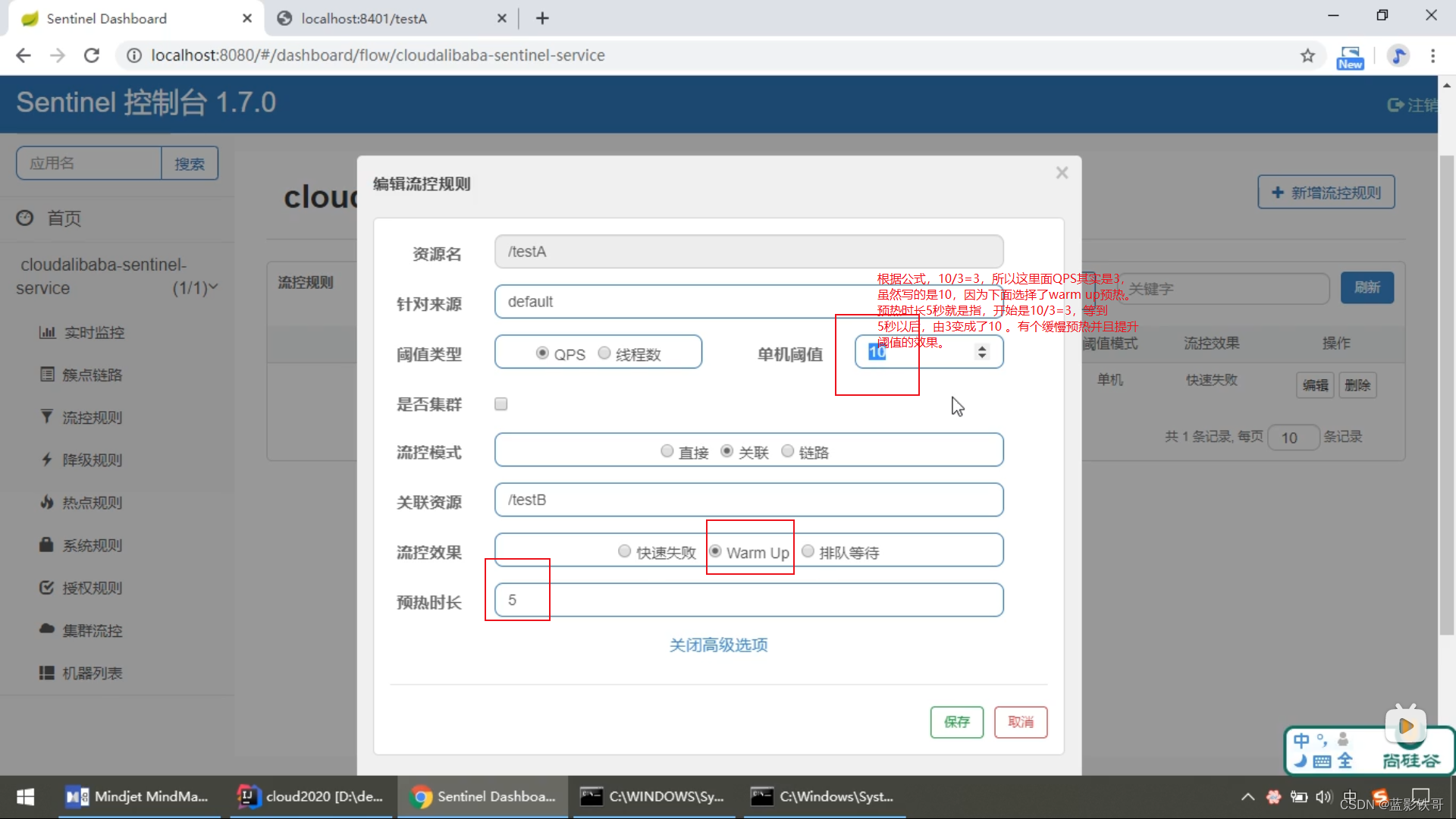
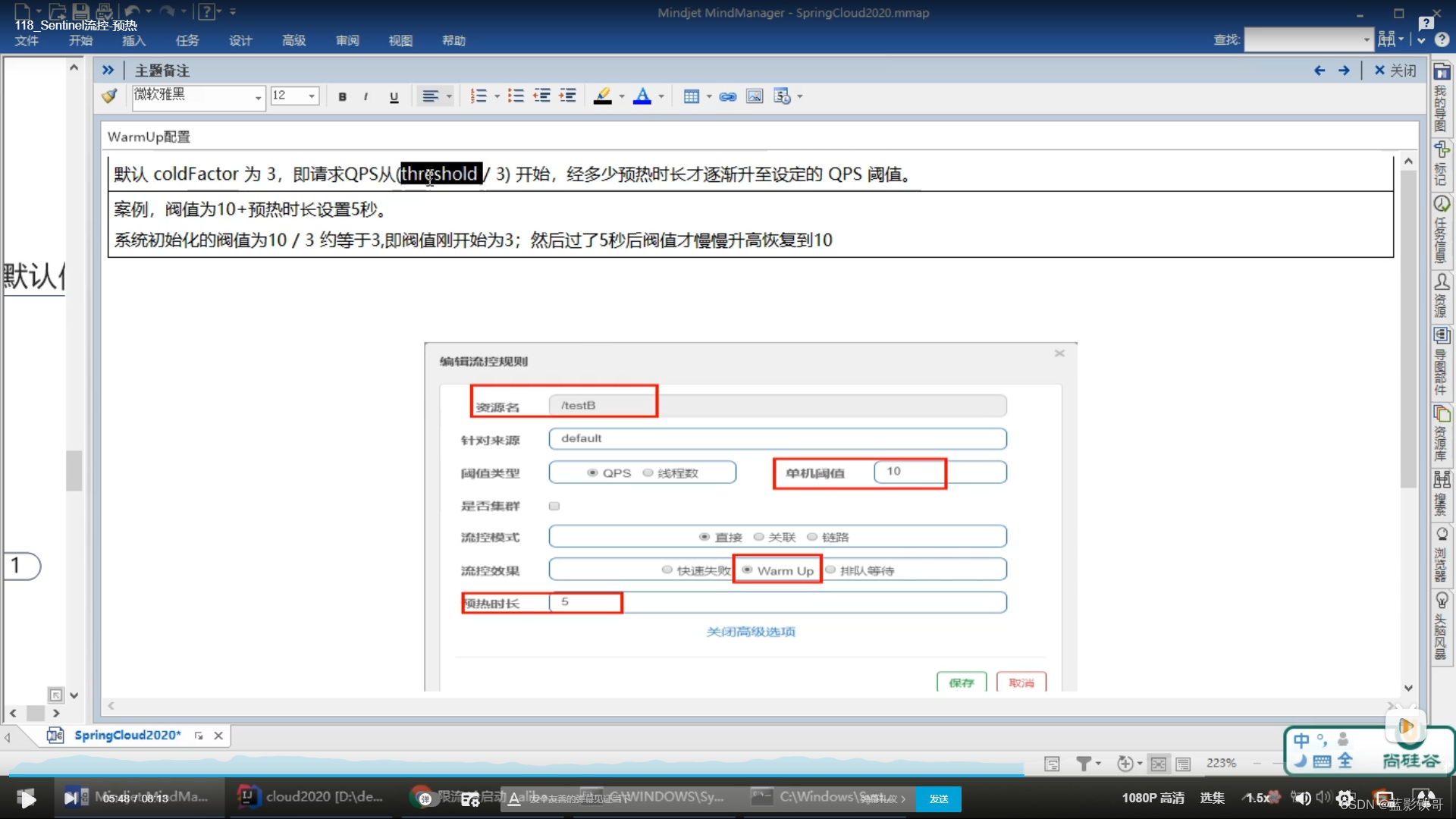
6.2、warm up(预热)
理论,就是平时可能0访问,一下子10万访问量,瞬间就把系统搞崩
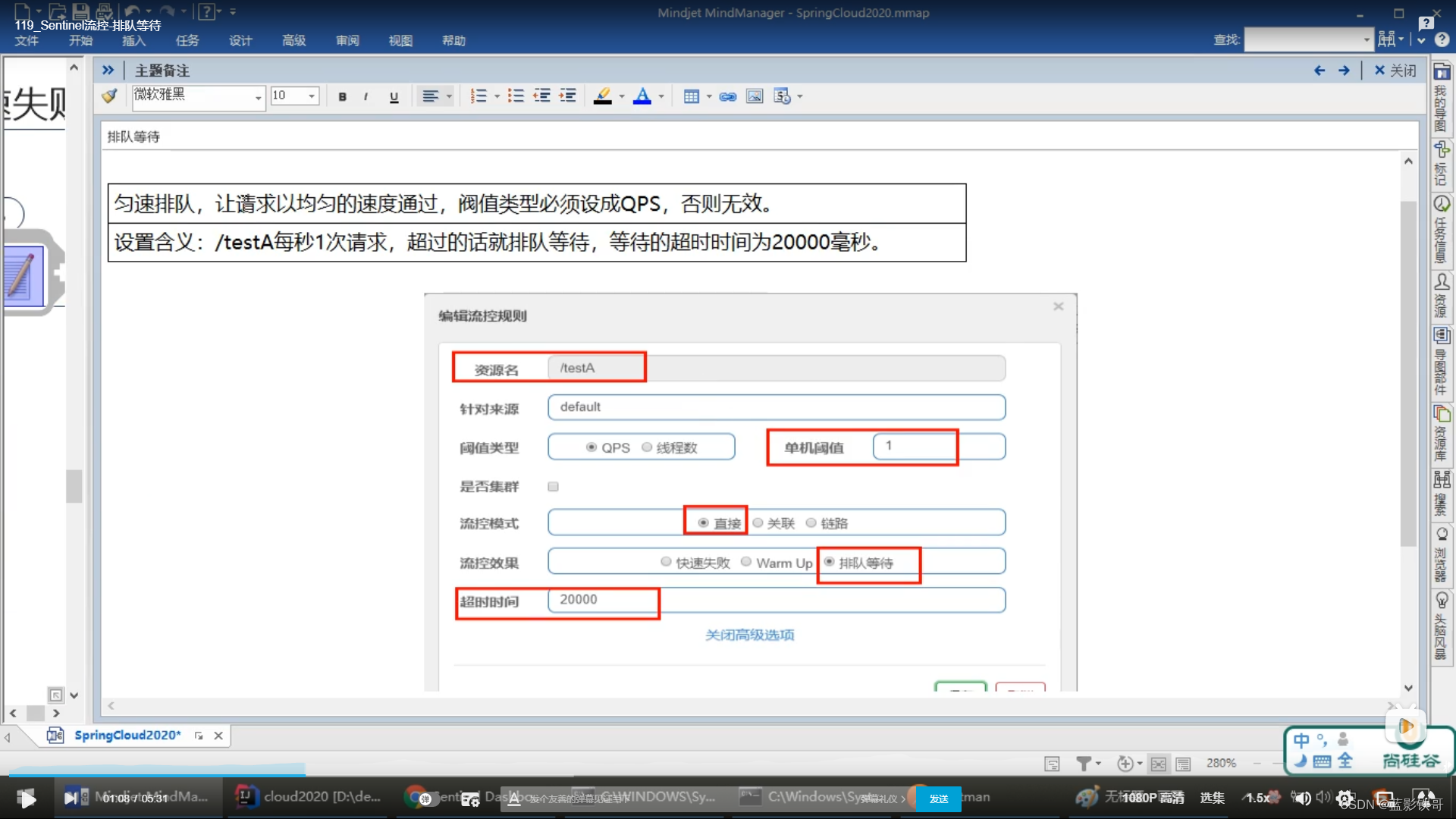
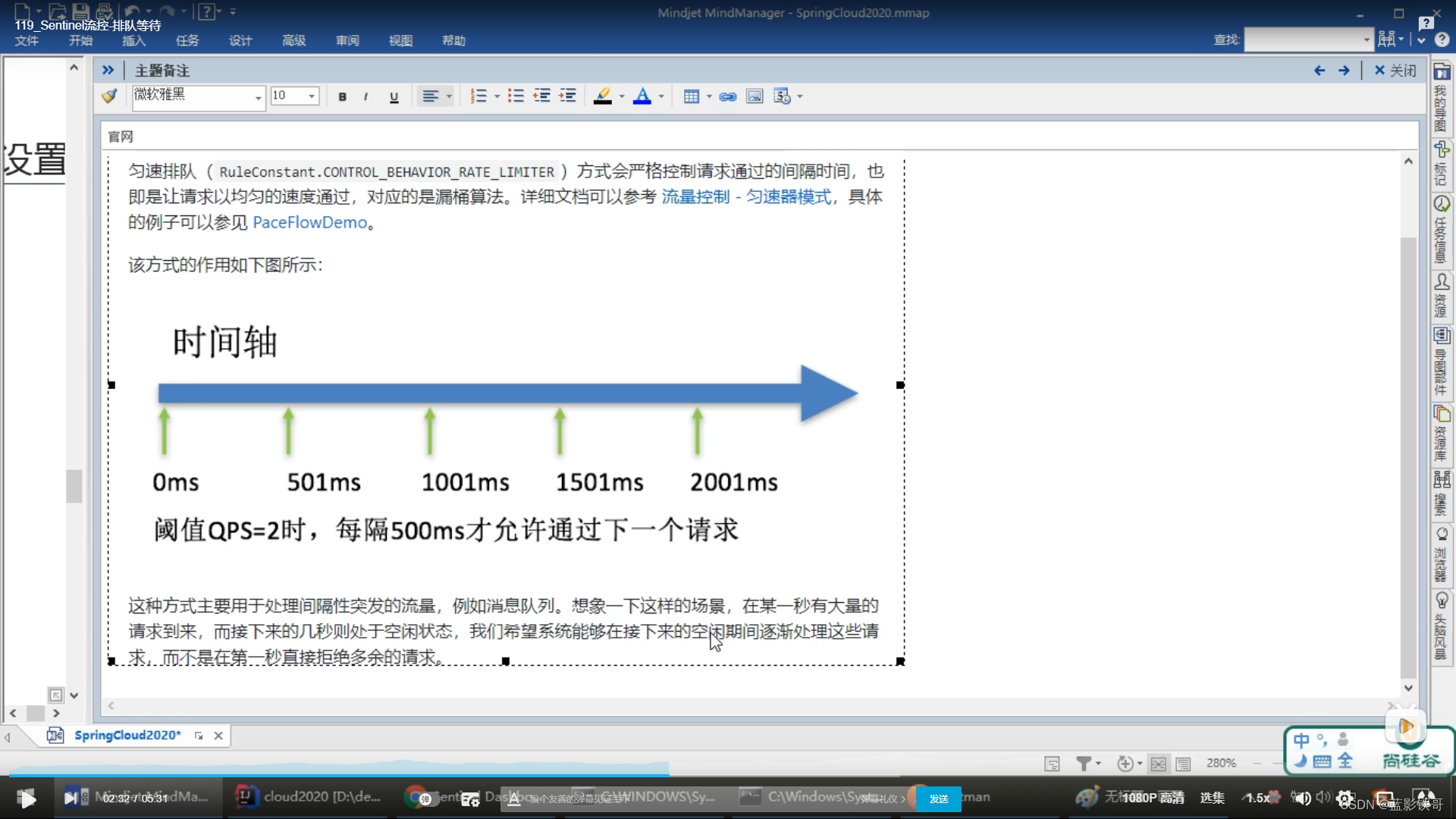
5.3、排队等待
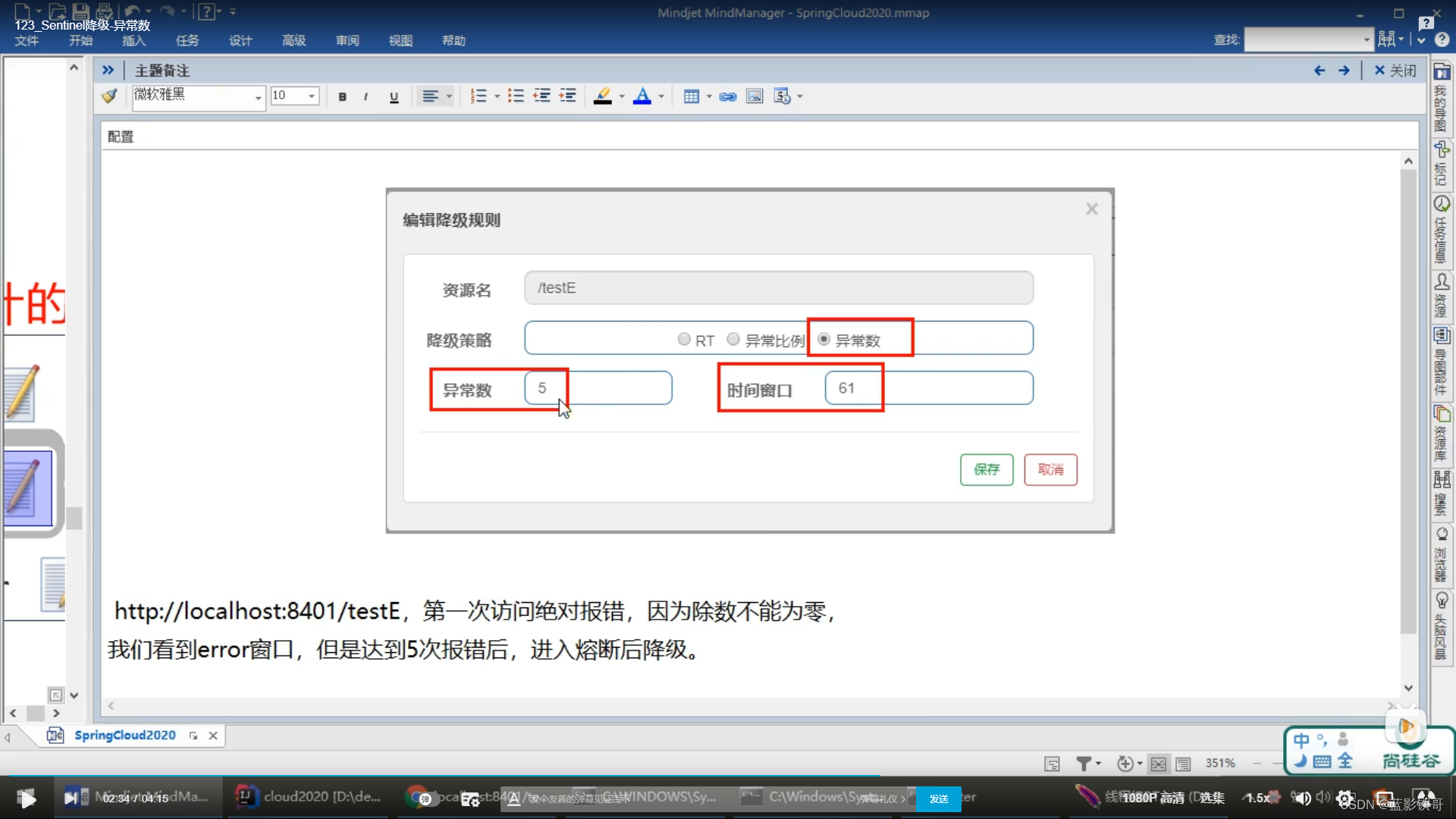
7、降级规则
7.1、概念
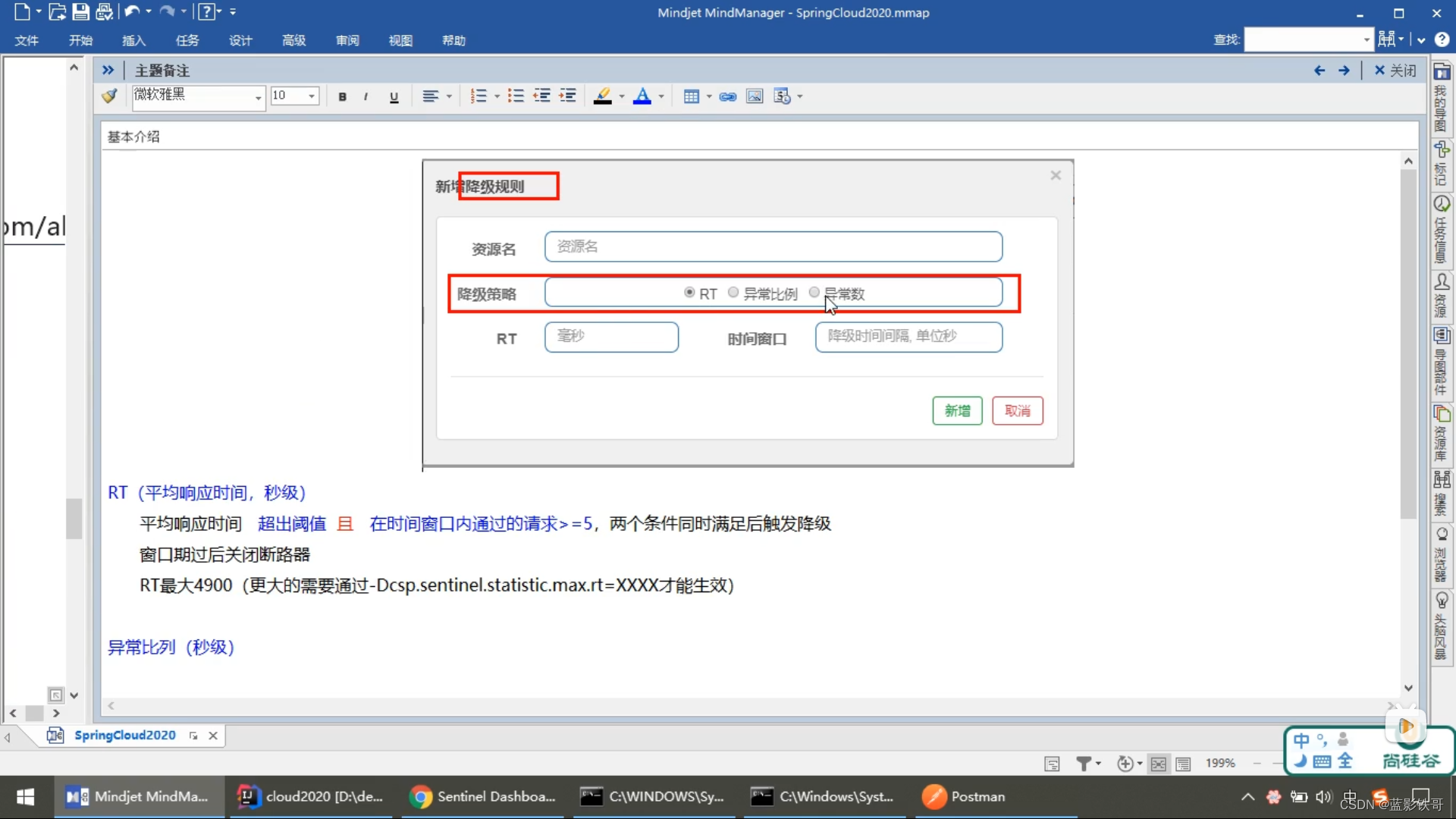
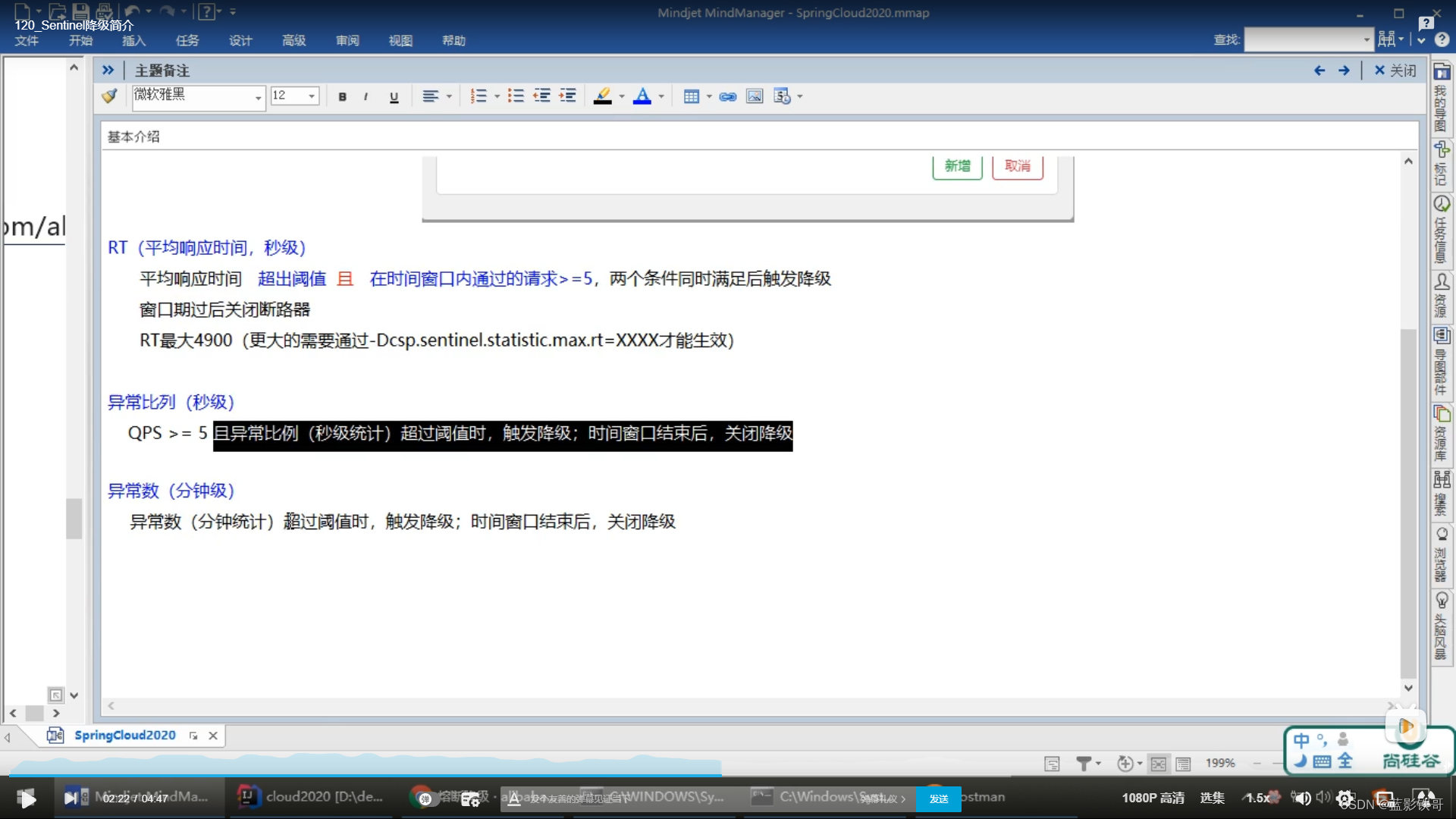
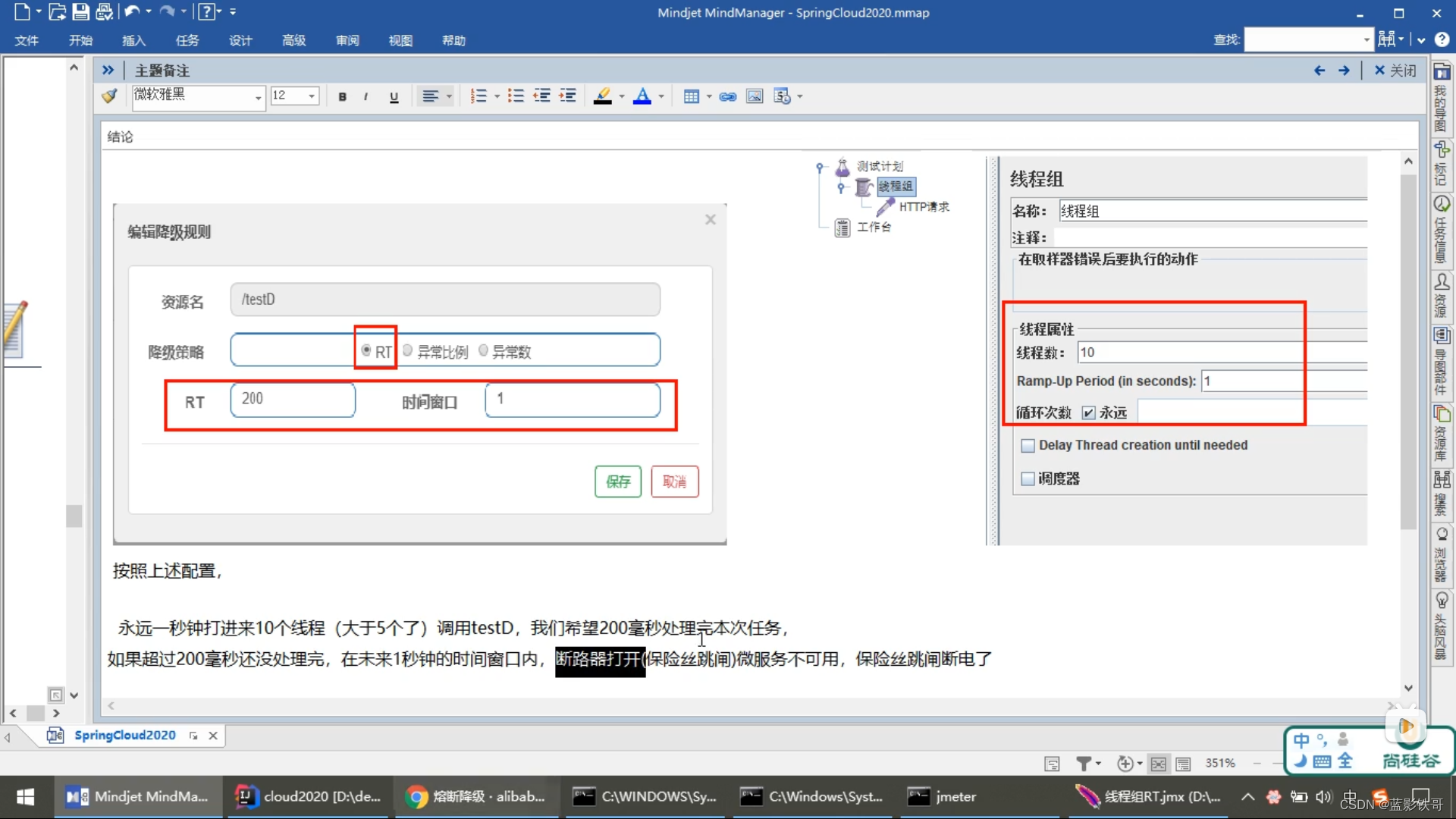
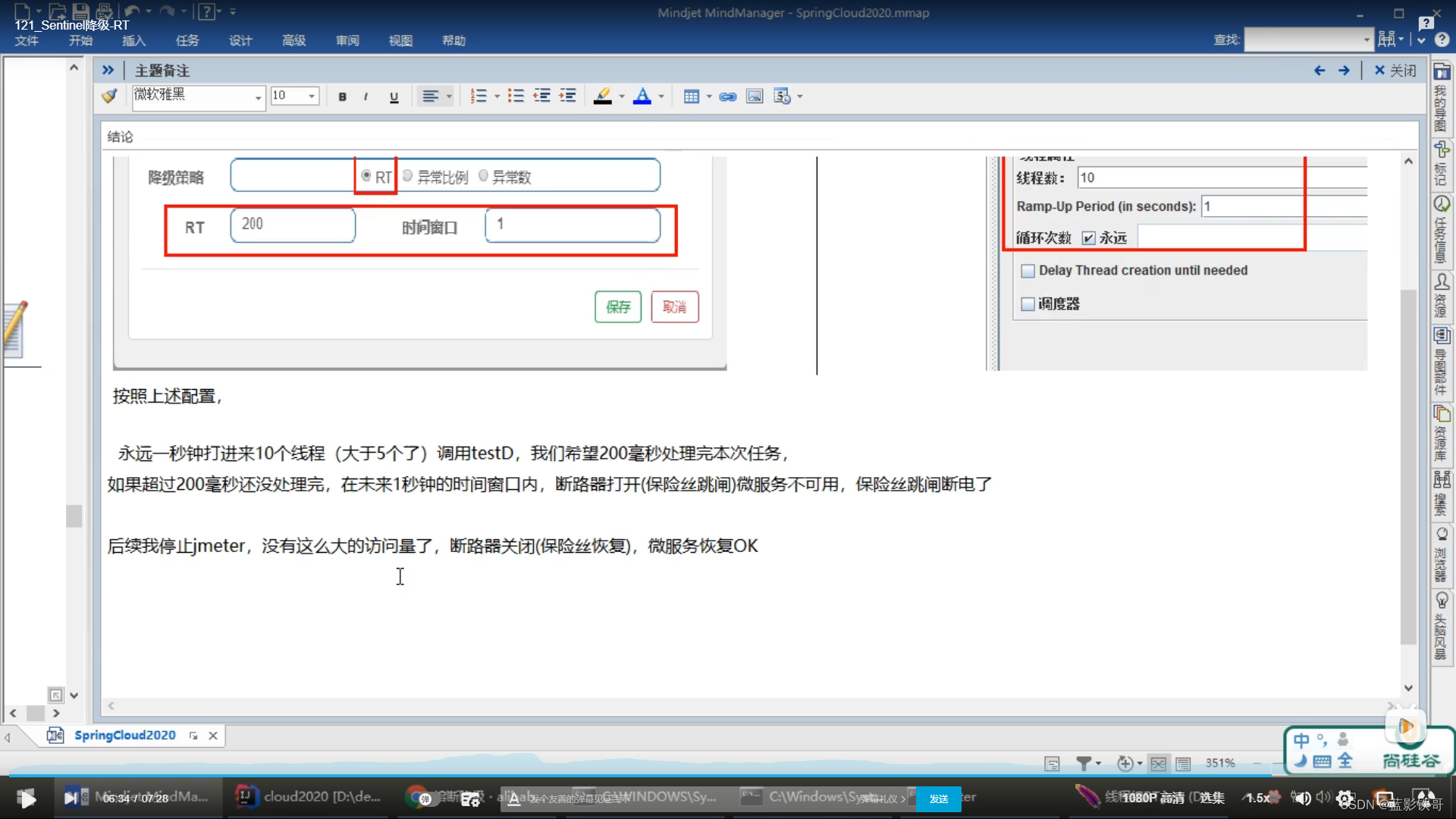
7.2、RT
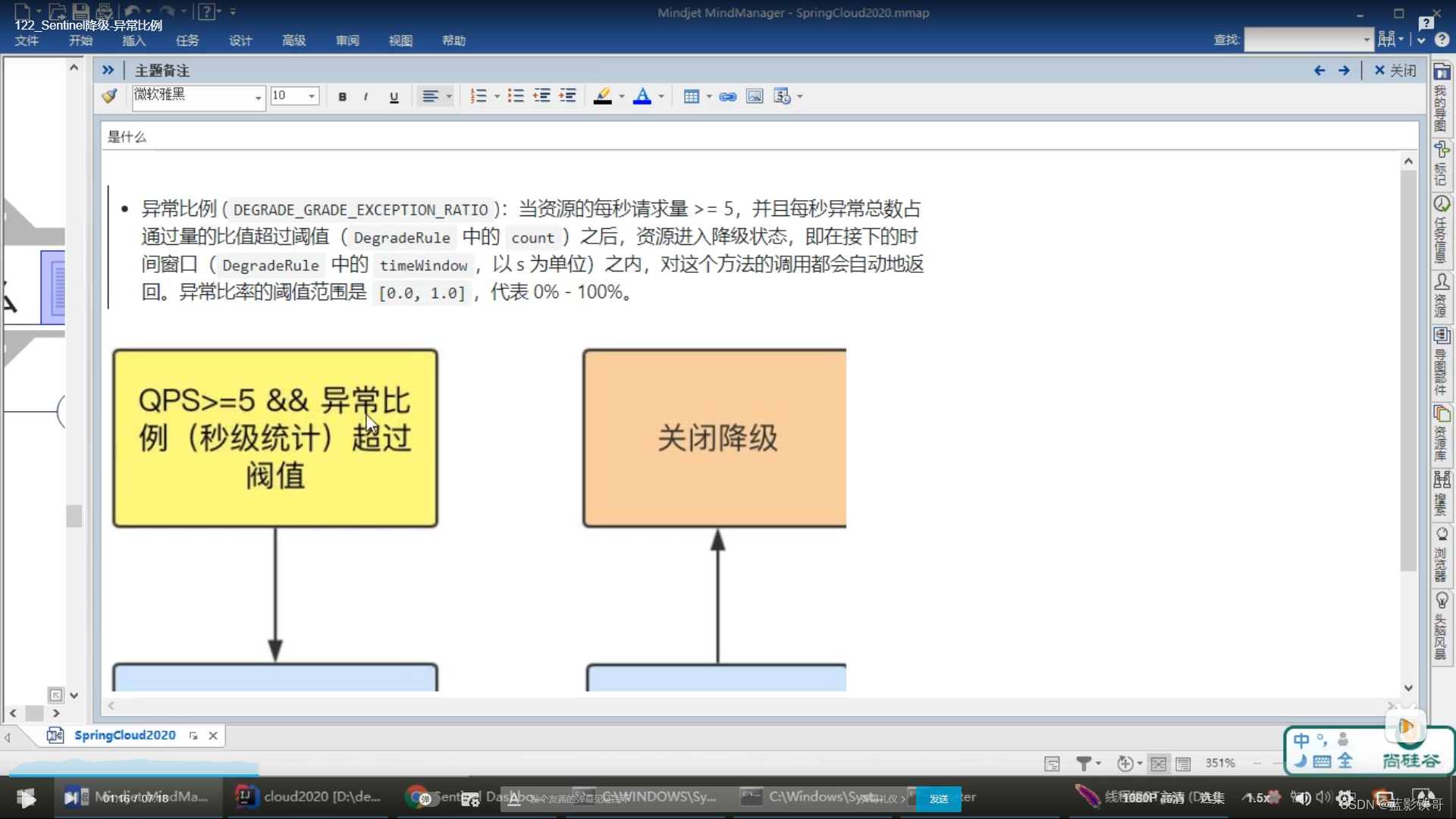
7.3、异常比例
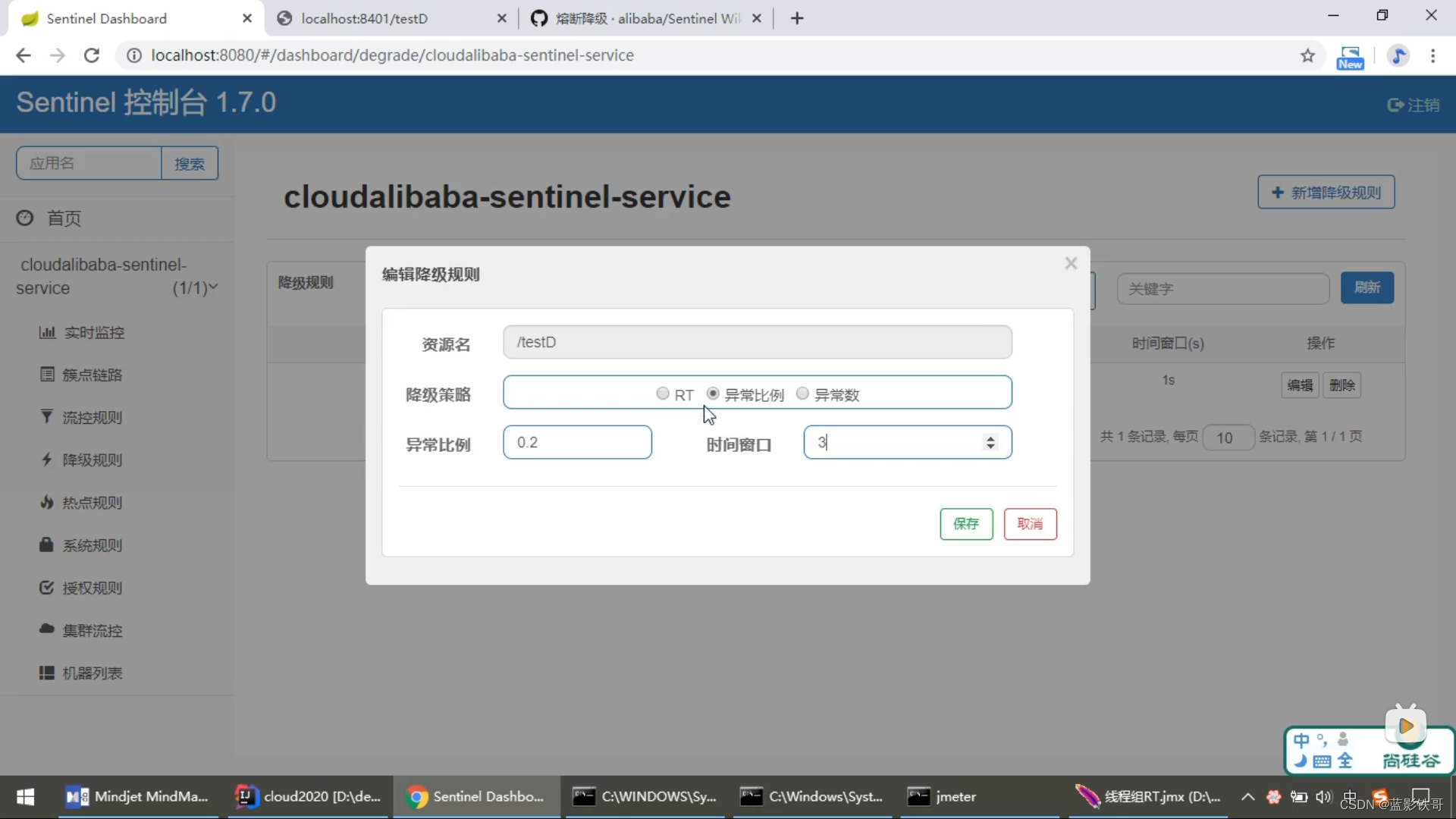
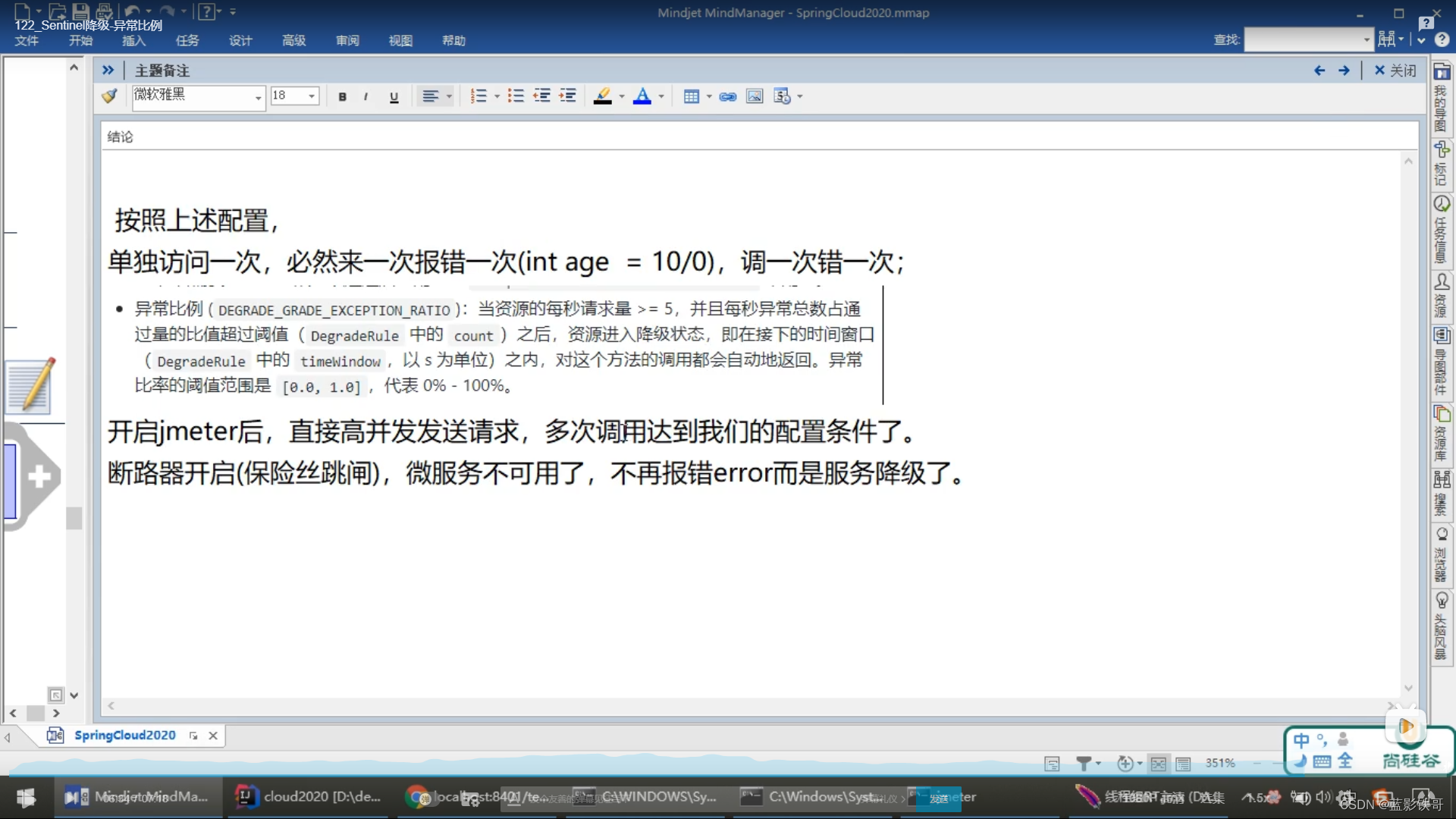
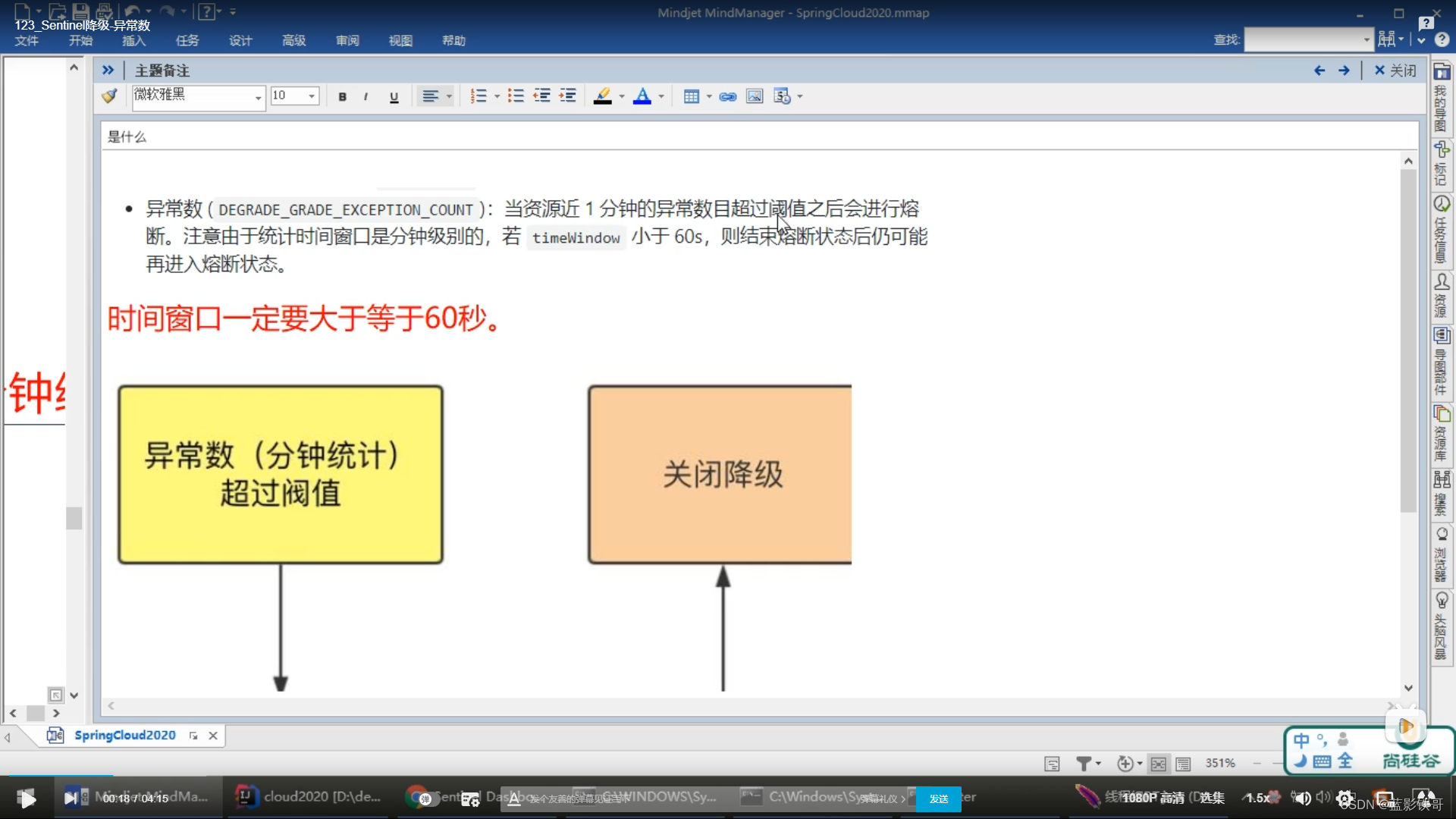
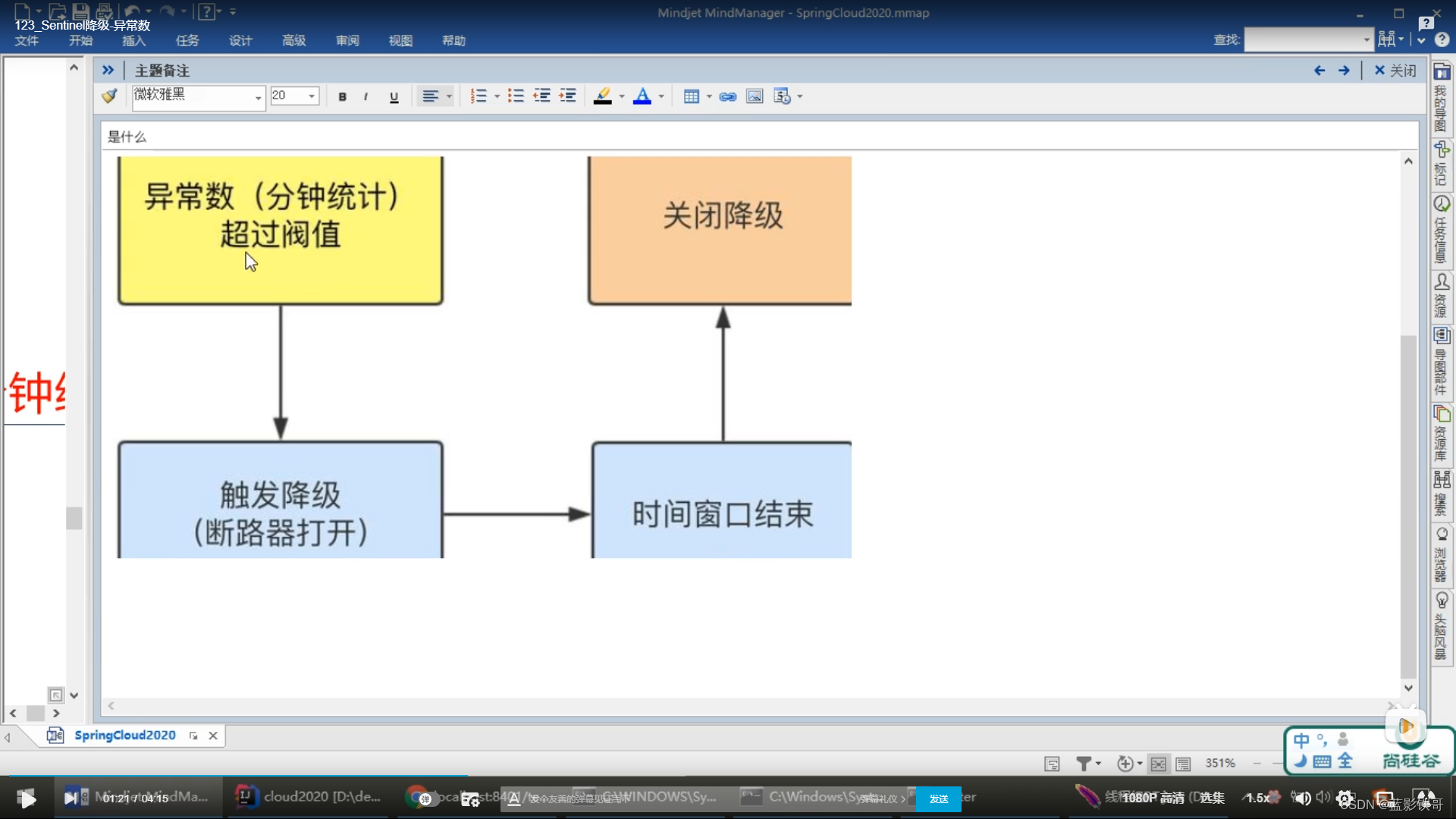
7.4、异常数
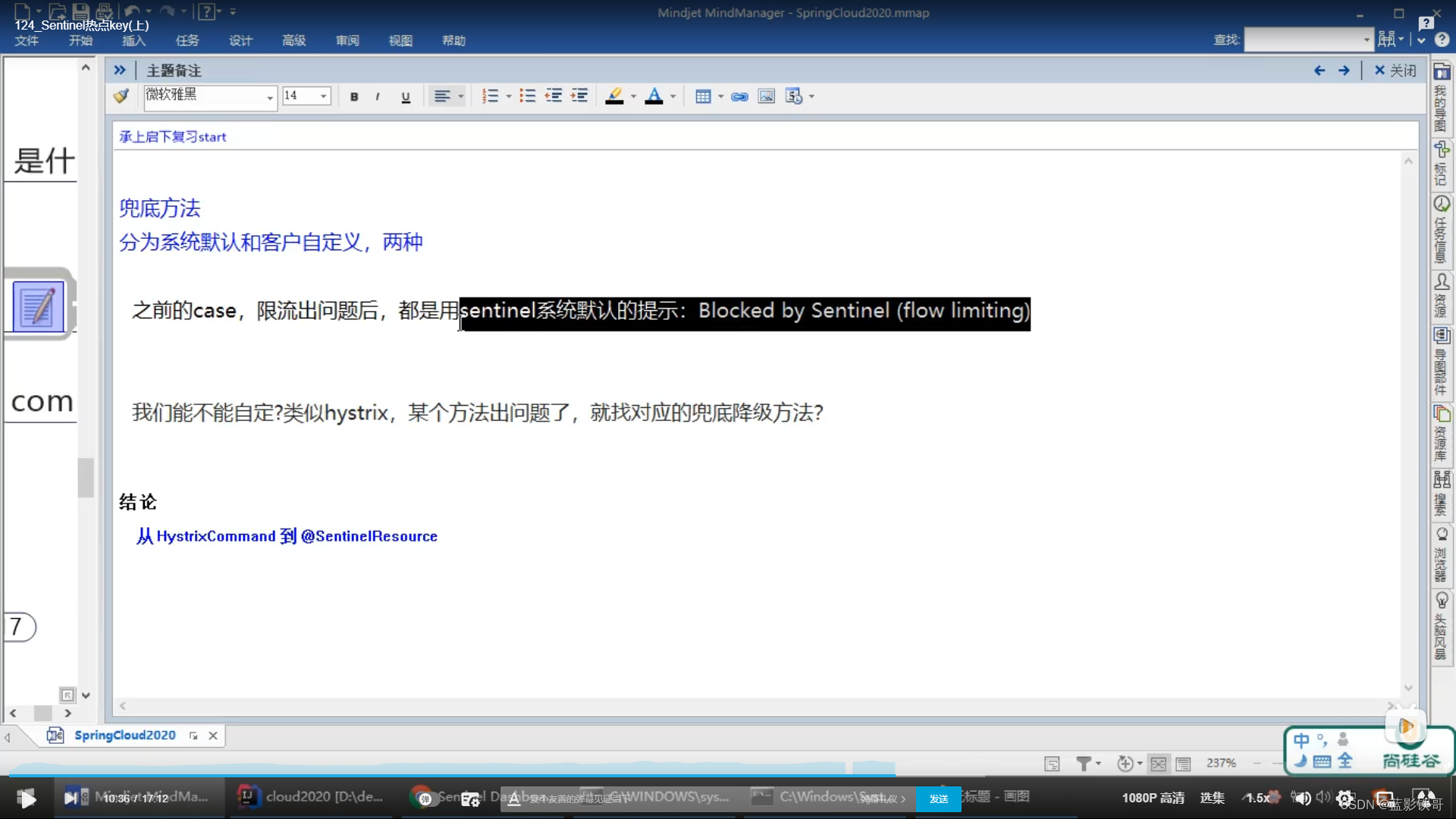
8、热点规则(热点key限流)
8.1、概念
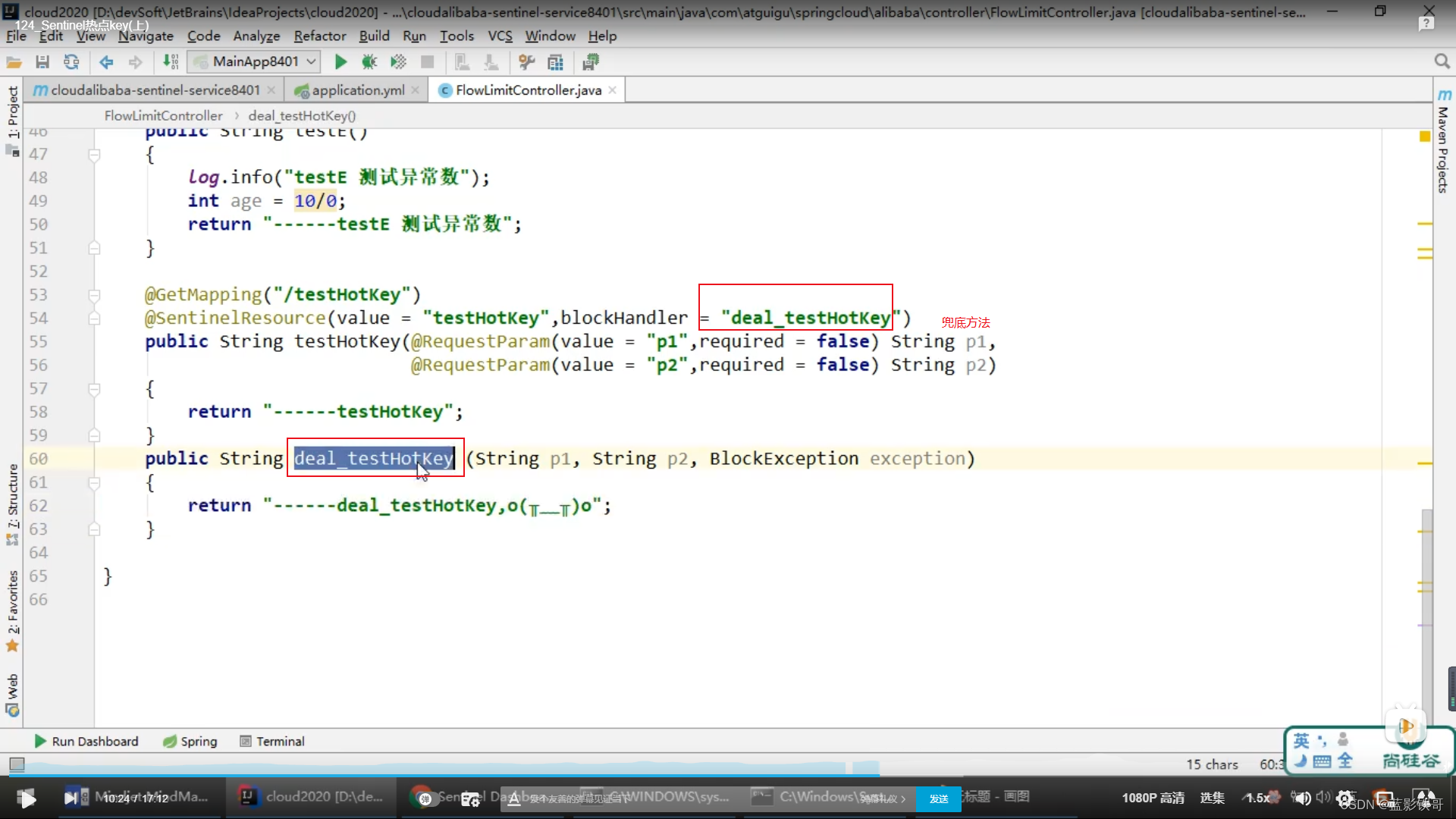
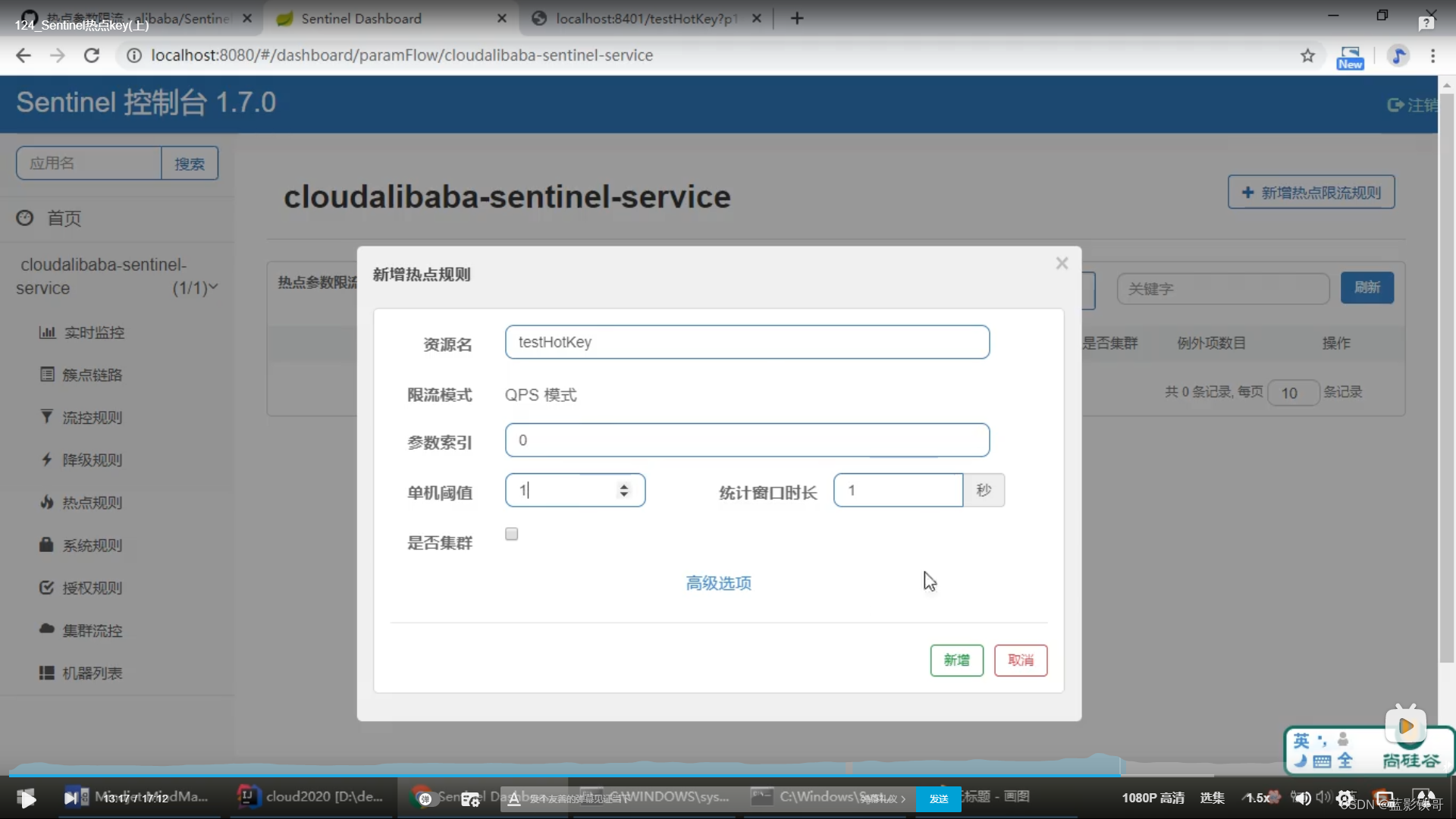
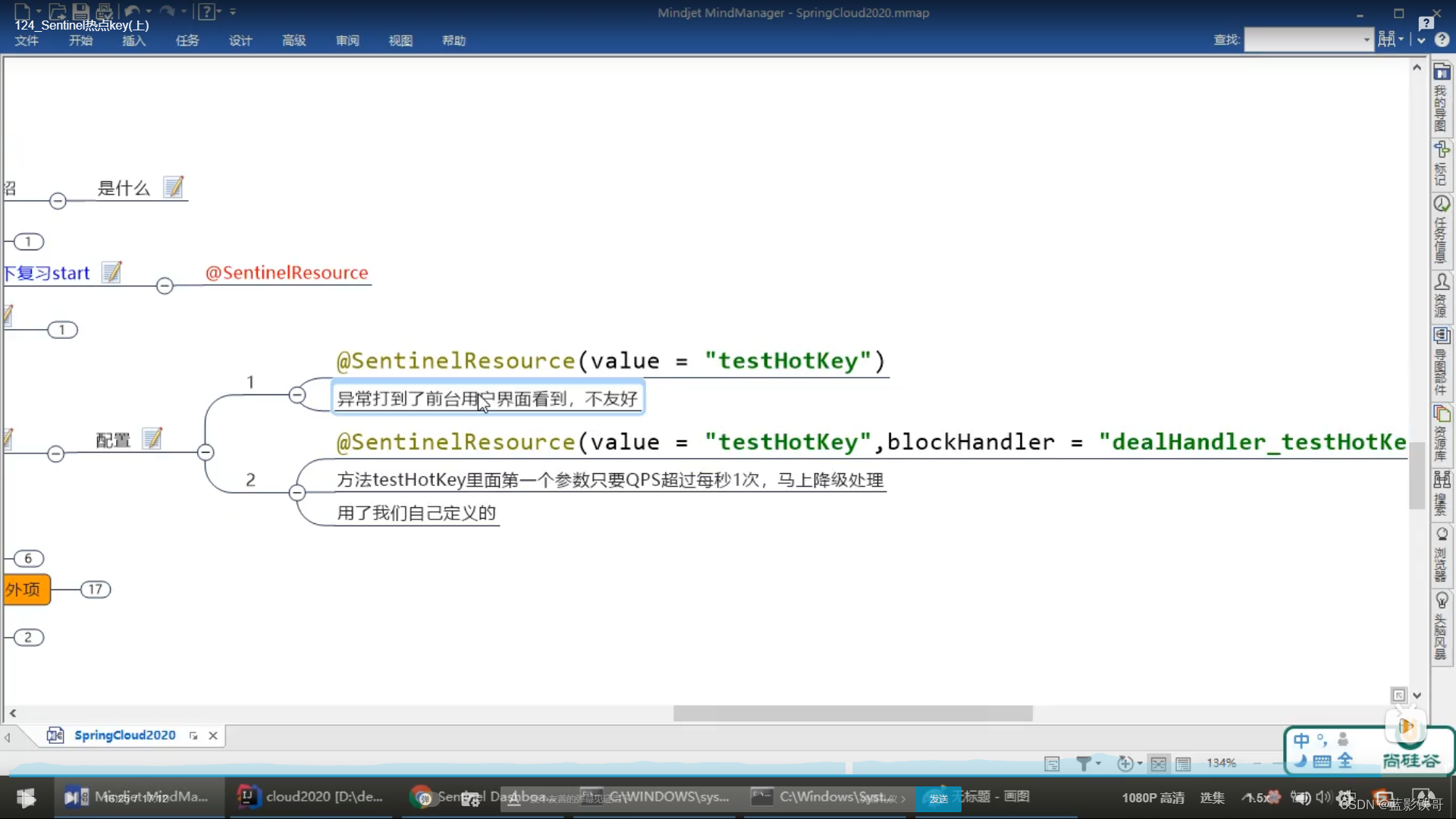
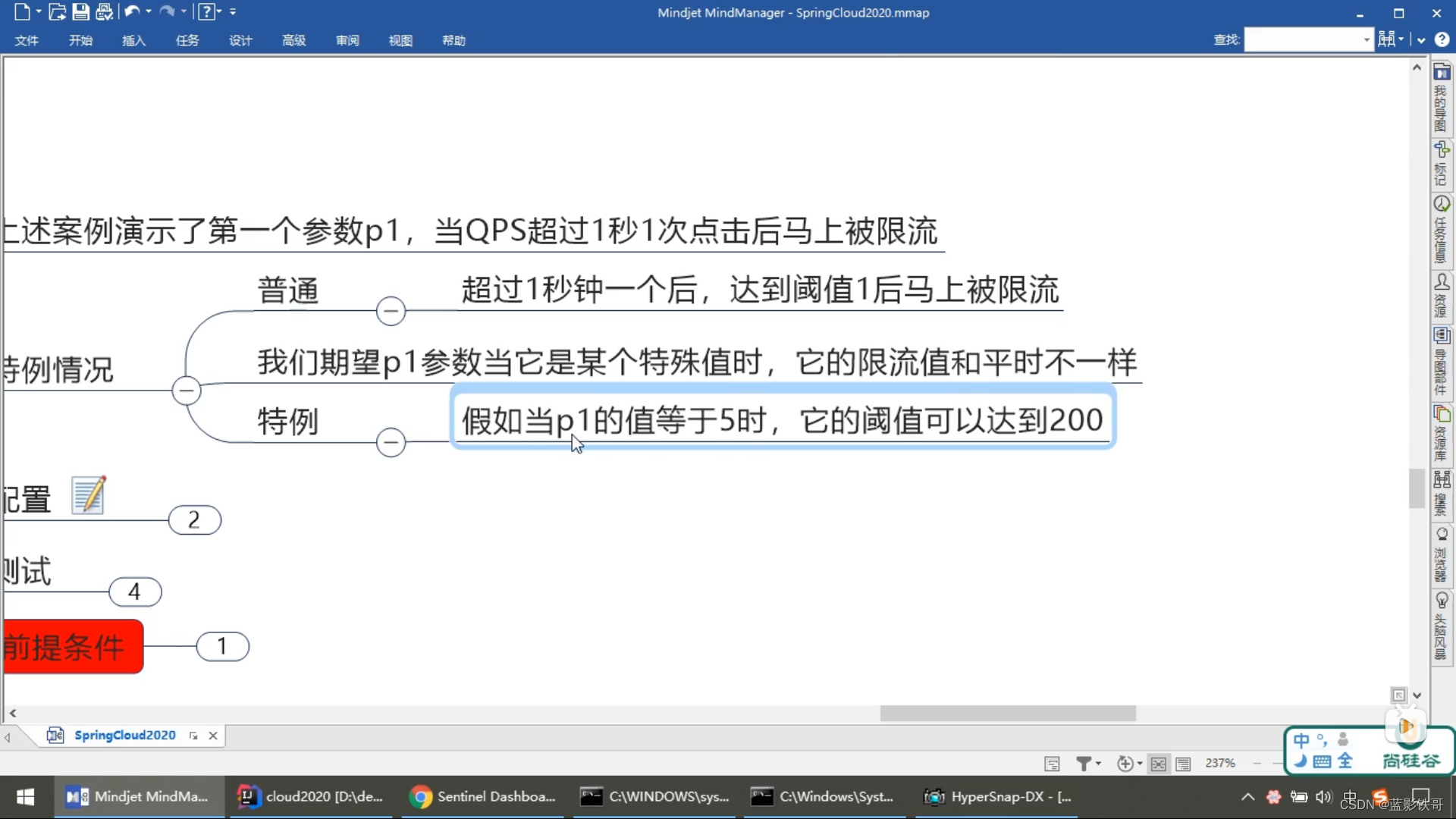
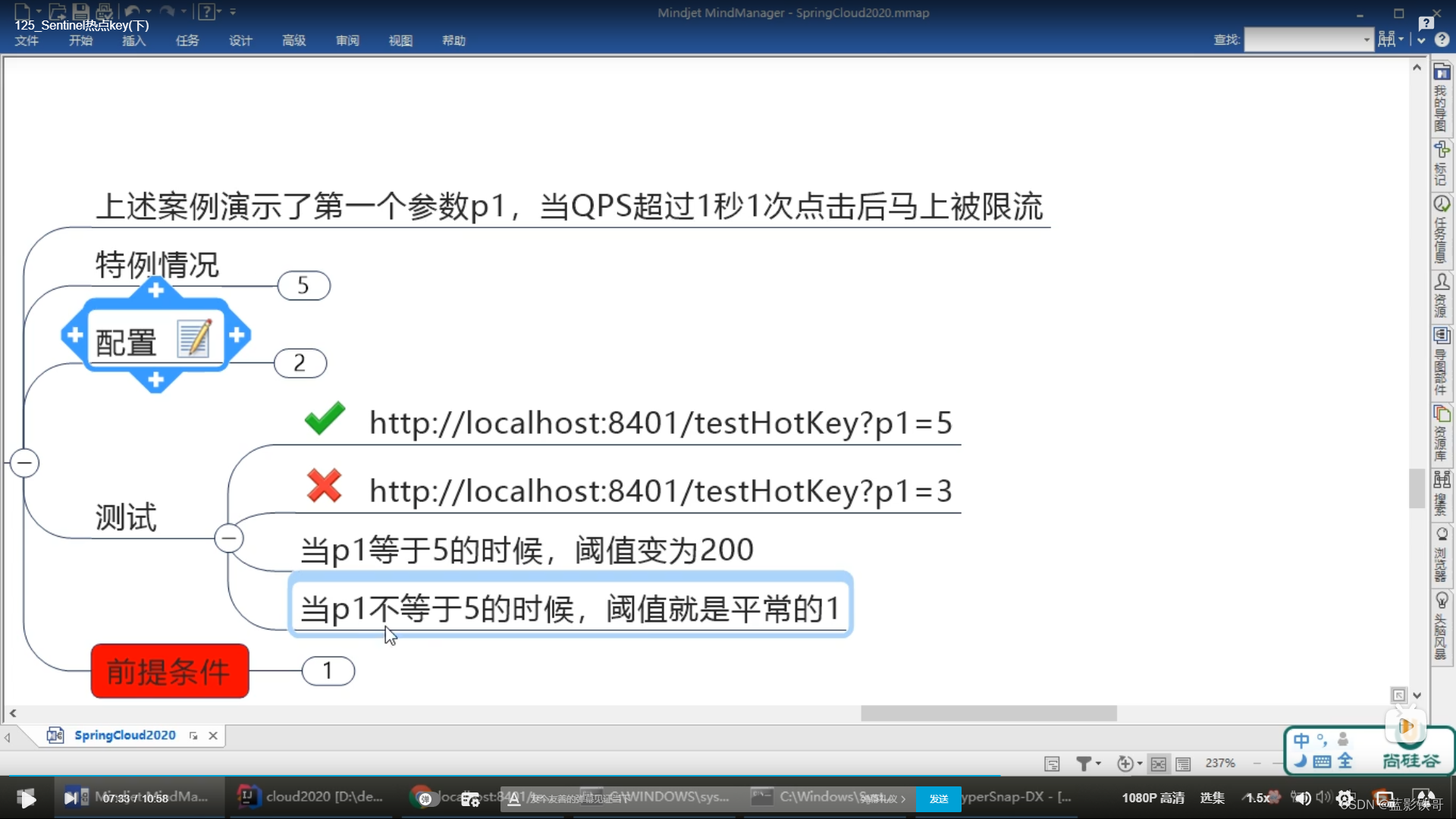
8.2、参数例外项
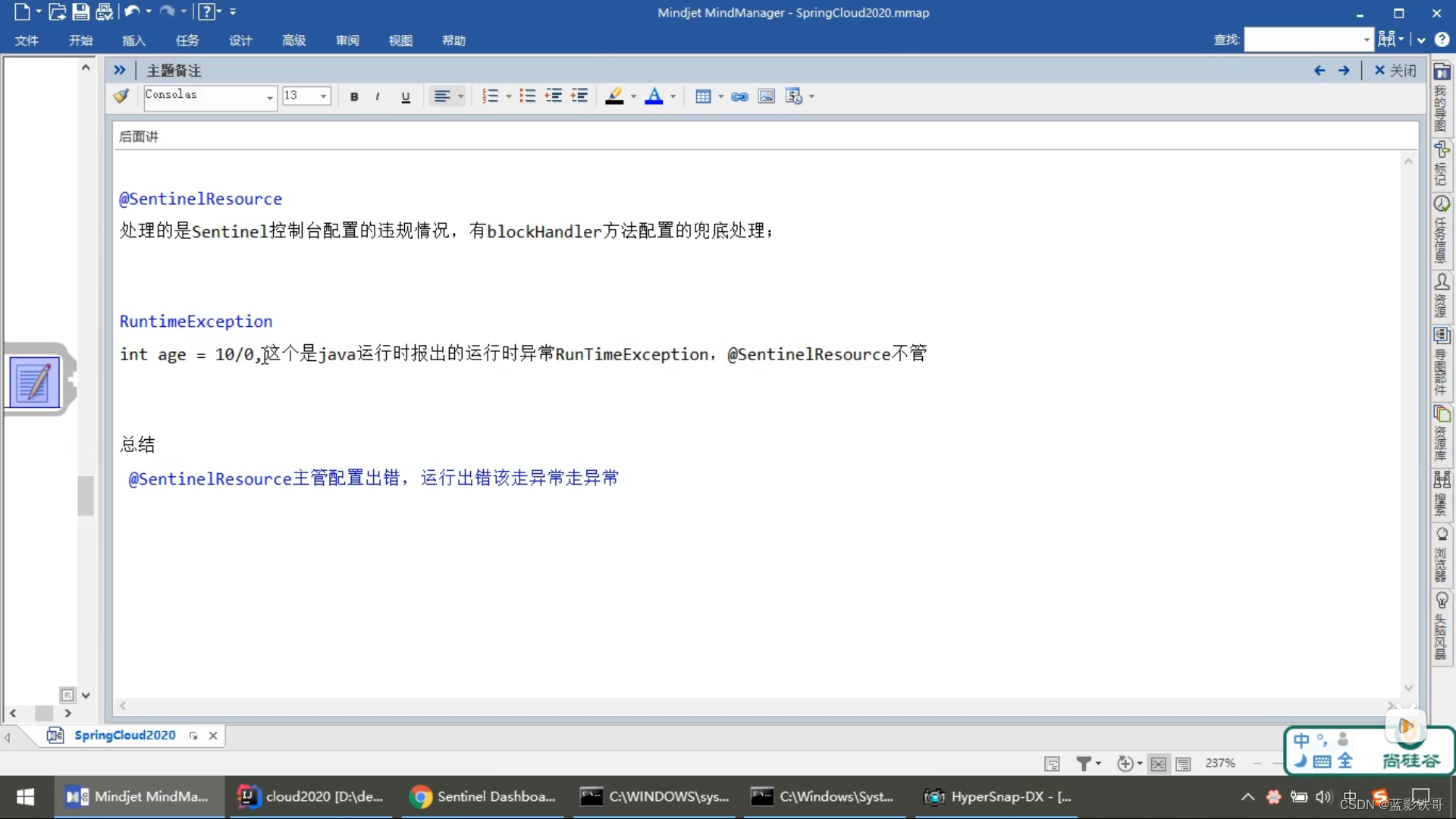
9、SentinelResource
9.1、按资源名称限流
要配置规则
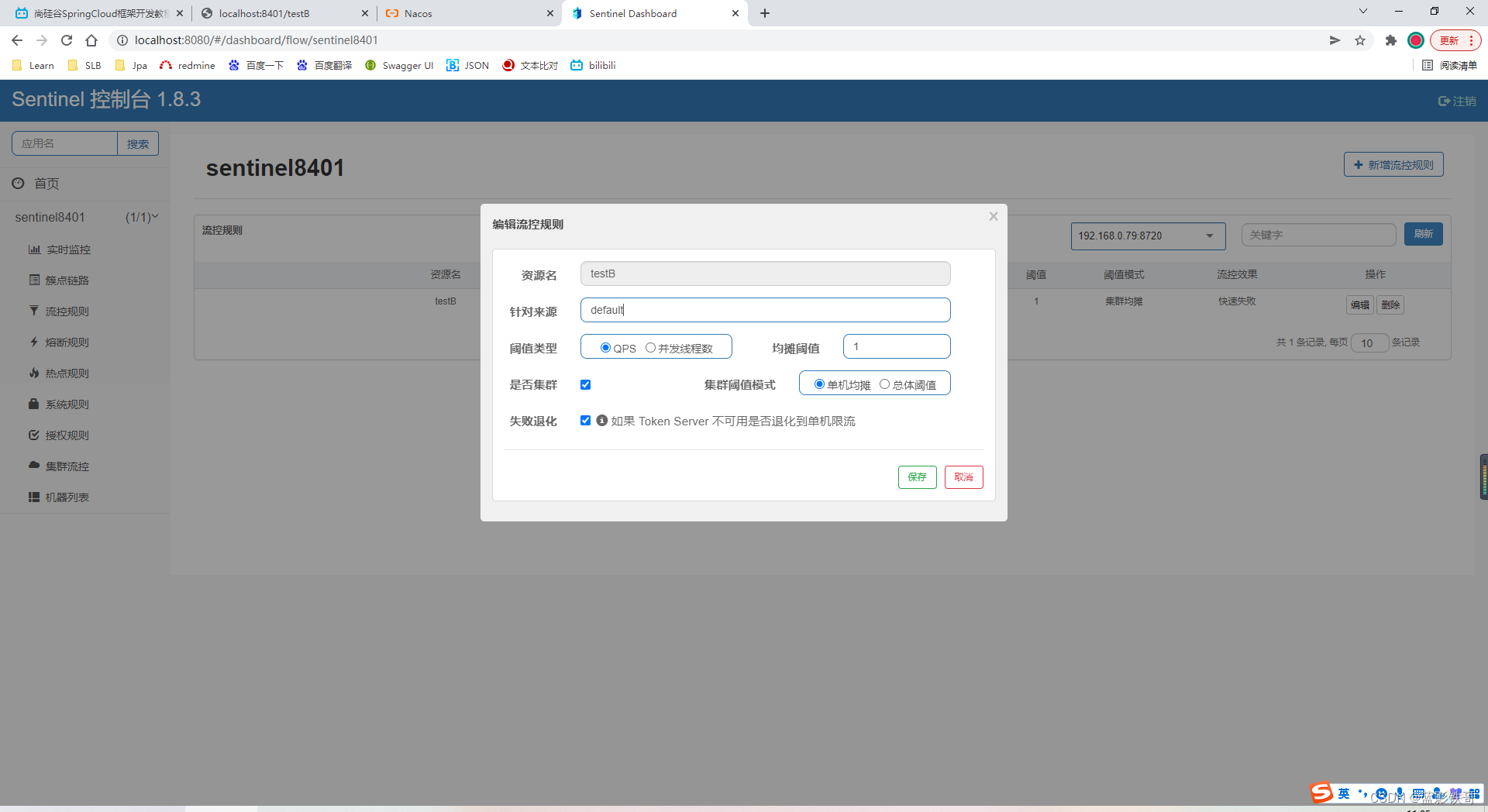
一重启微服务,前面配置的流控就没了,还得重新配置,搞毛线(注意,testA不加注解的话,配置流控规则就不会生效的)
9.2、按url地址限流
配置规则
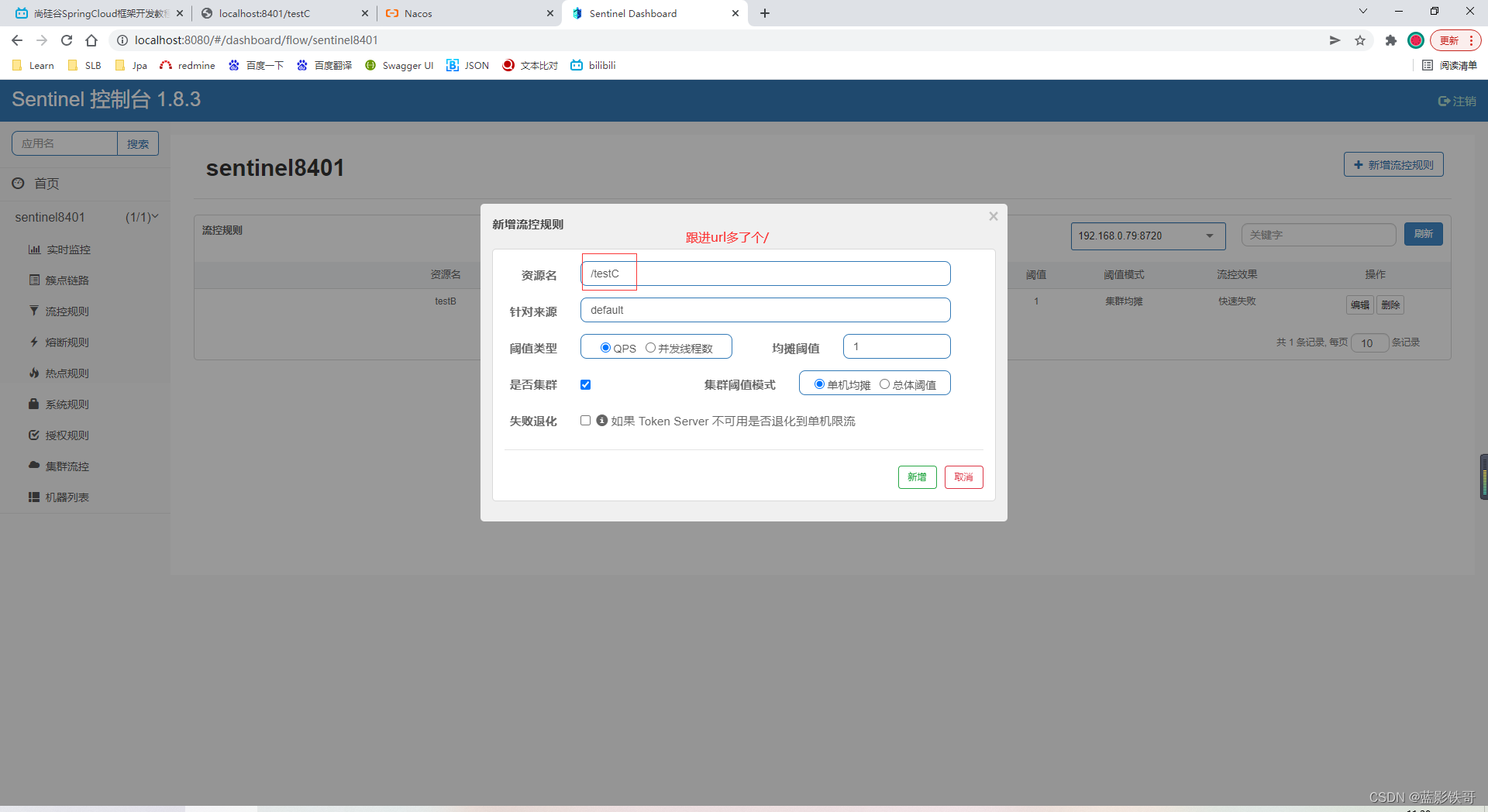
注意,这个时候是根据GetMapping里面的值来配置 url地址的,和注解里面的value就没有关系了(重启微服务规则也没了)
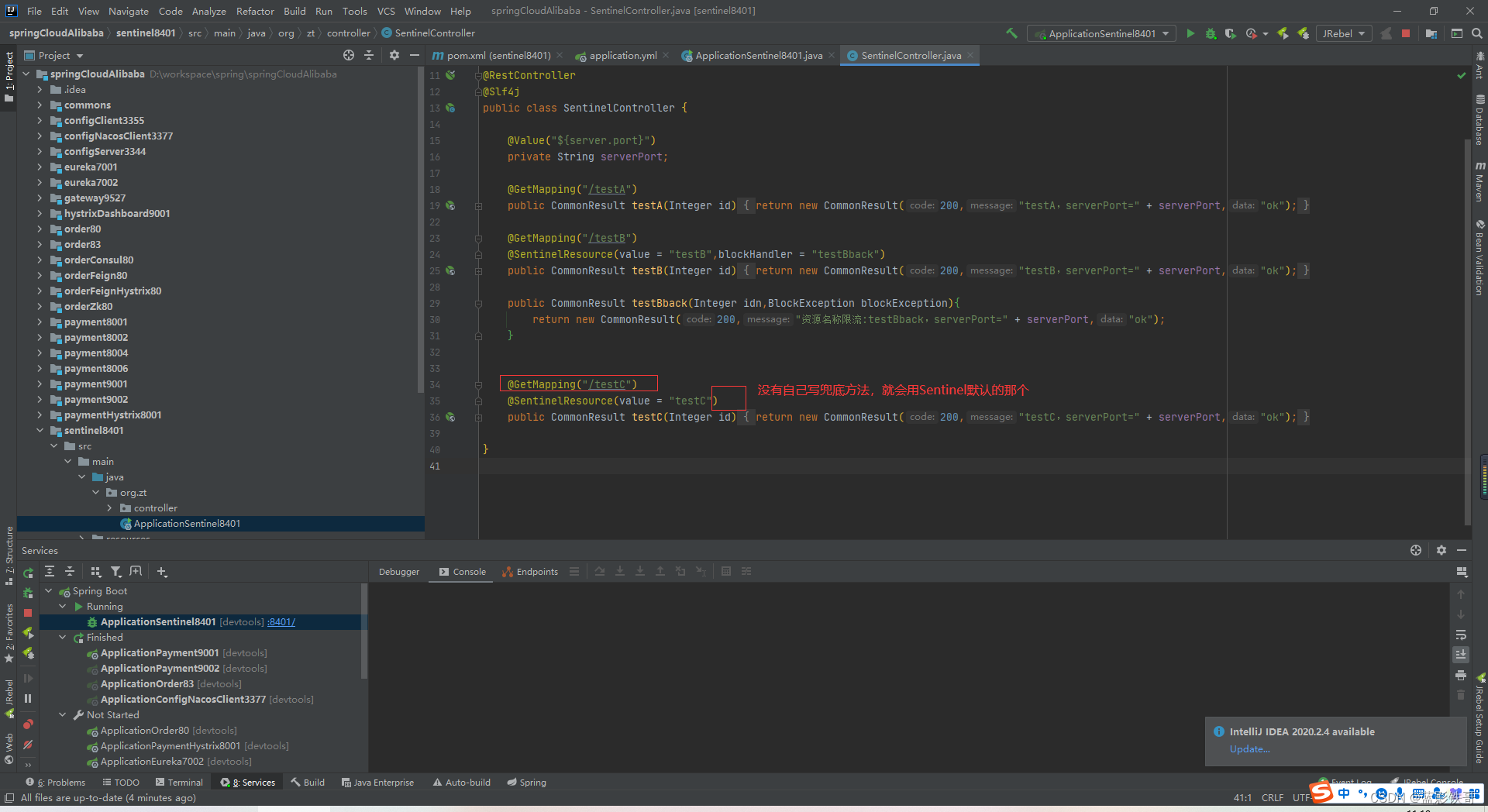
Sentinel的默认提示
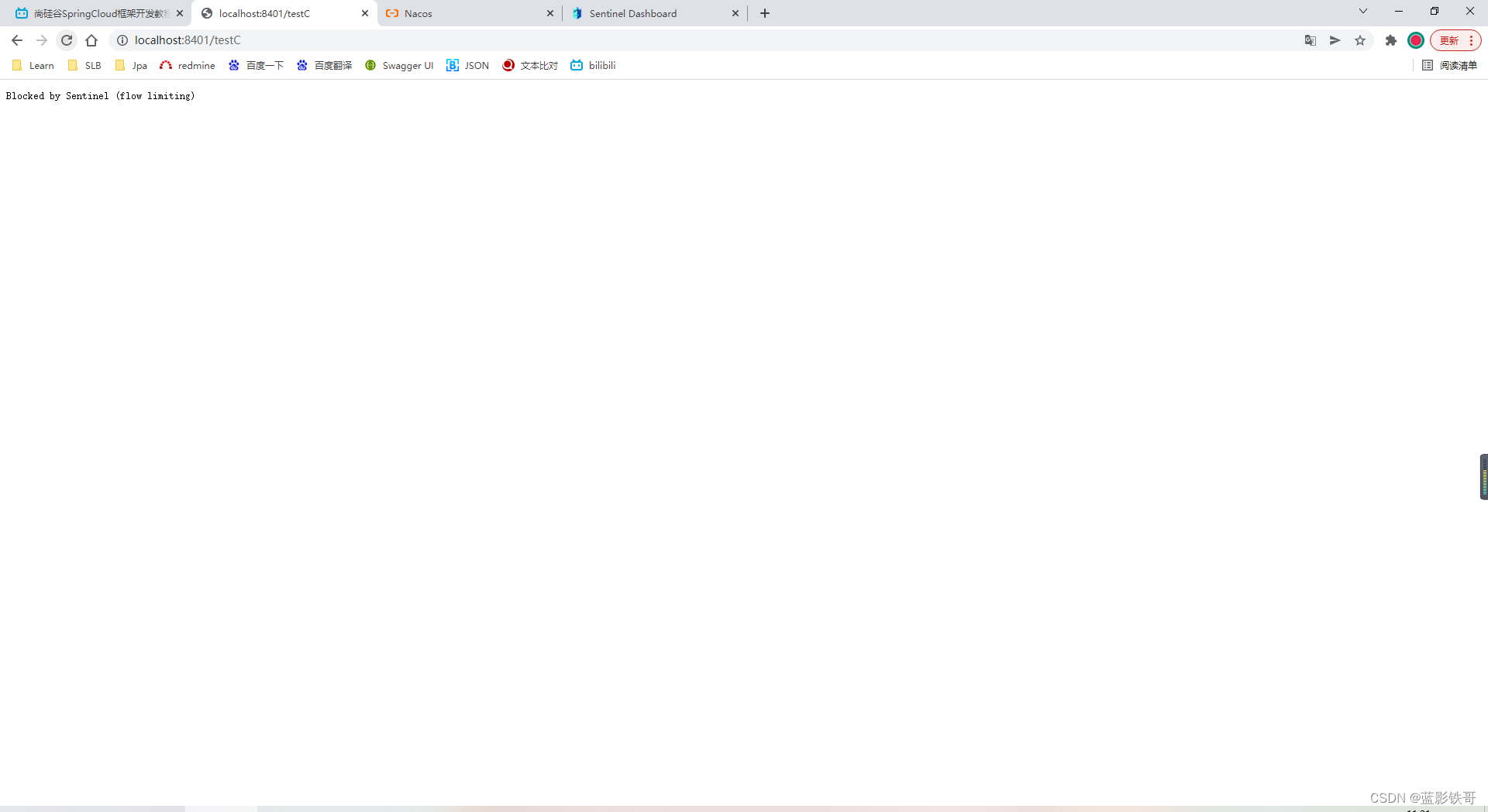
9.3、上面遇到的问题
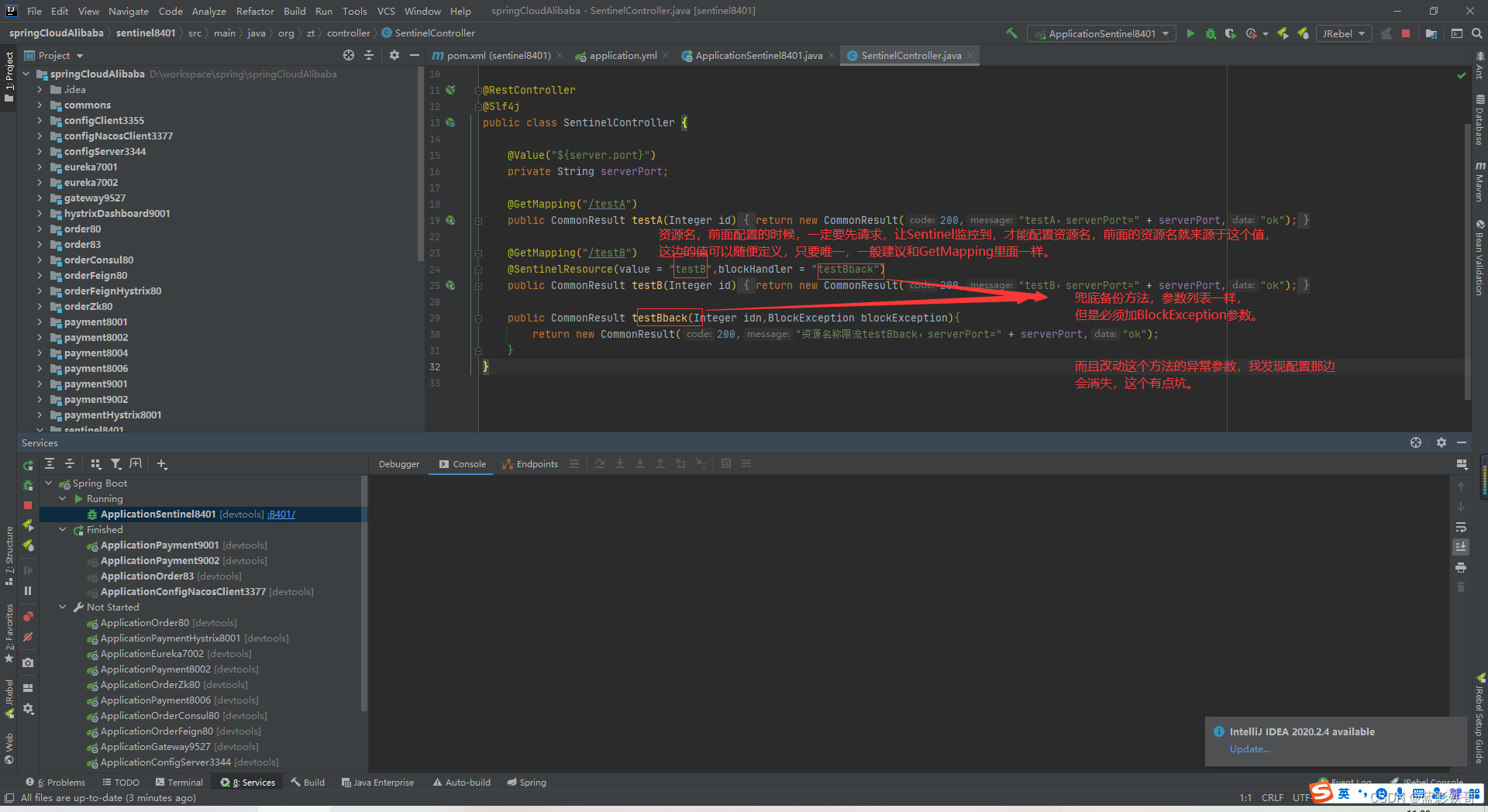
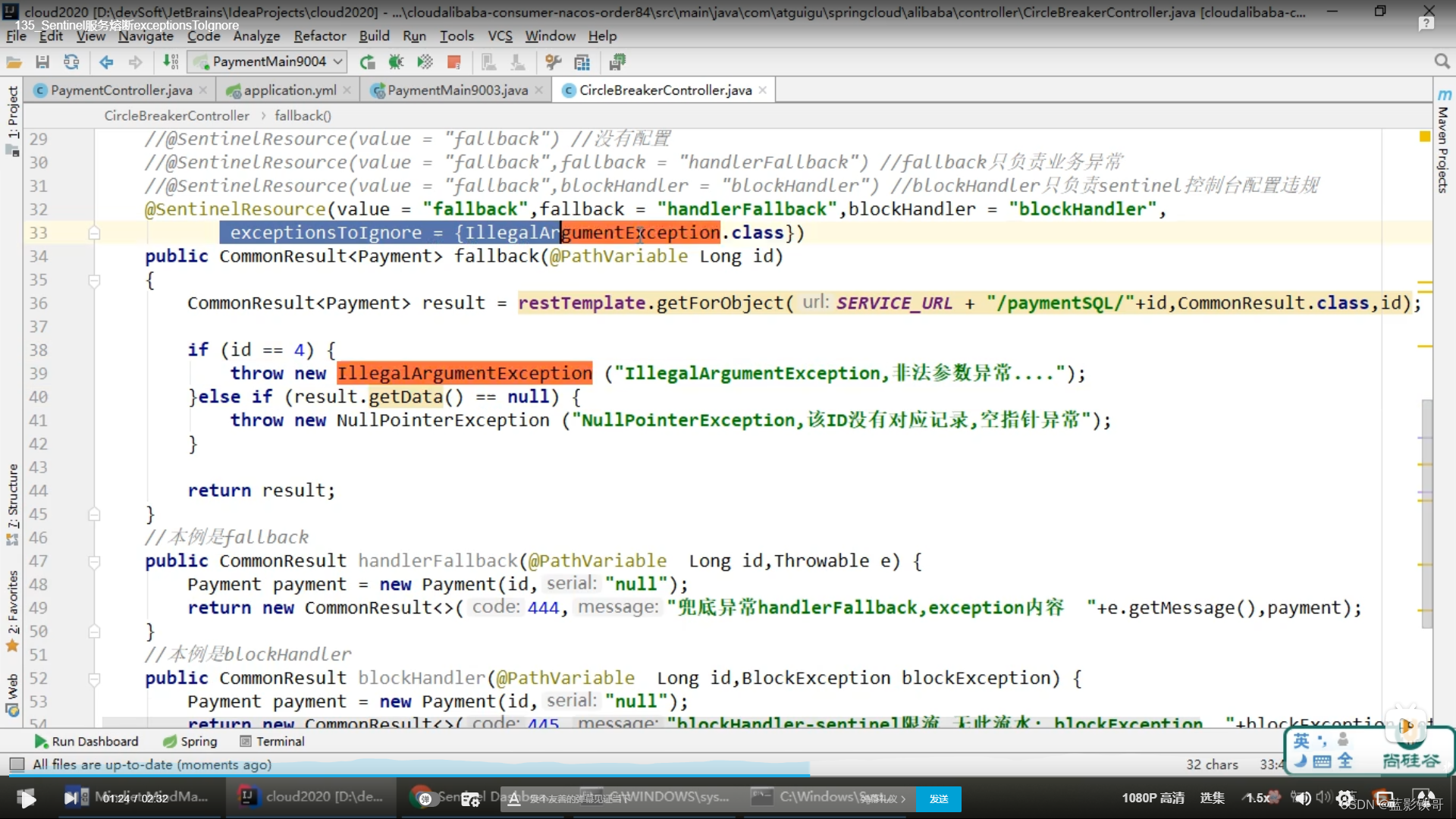
9.4、自定义限流
坑(这截图不对,里面的blockHandler方法里面必须加一个额外的参数BlockException,否则报null)
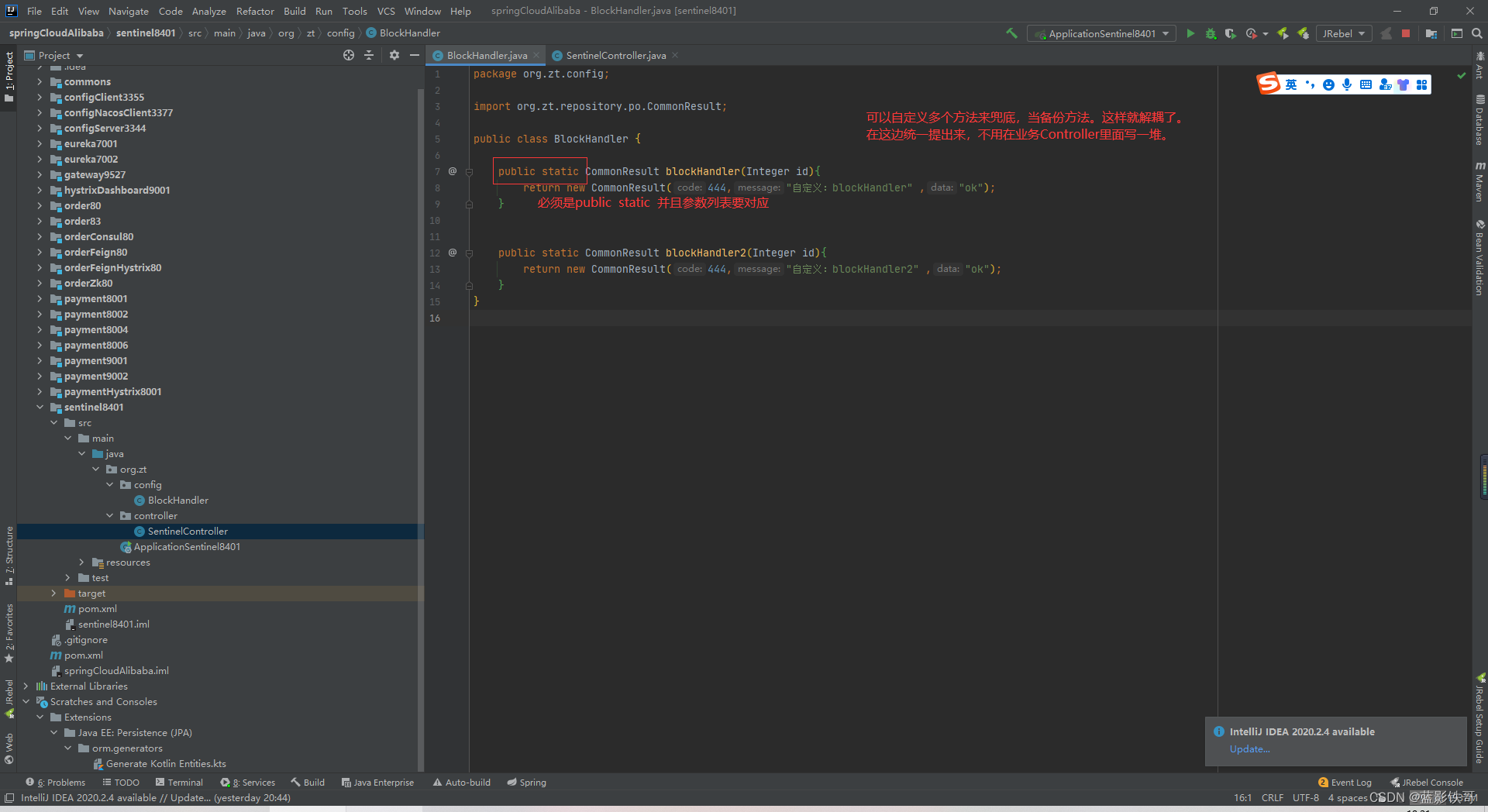
全局处理(配合sentinel配置)
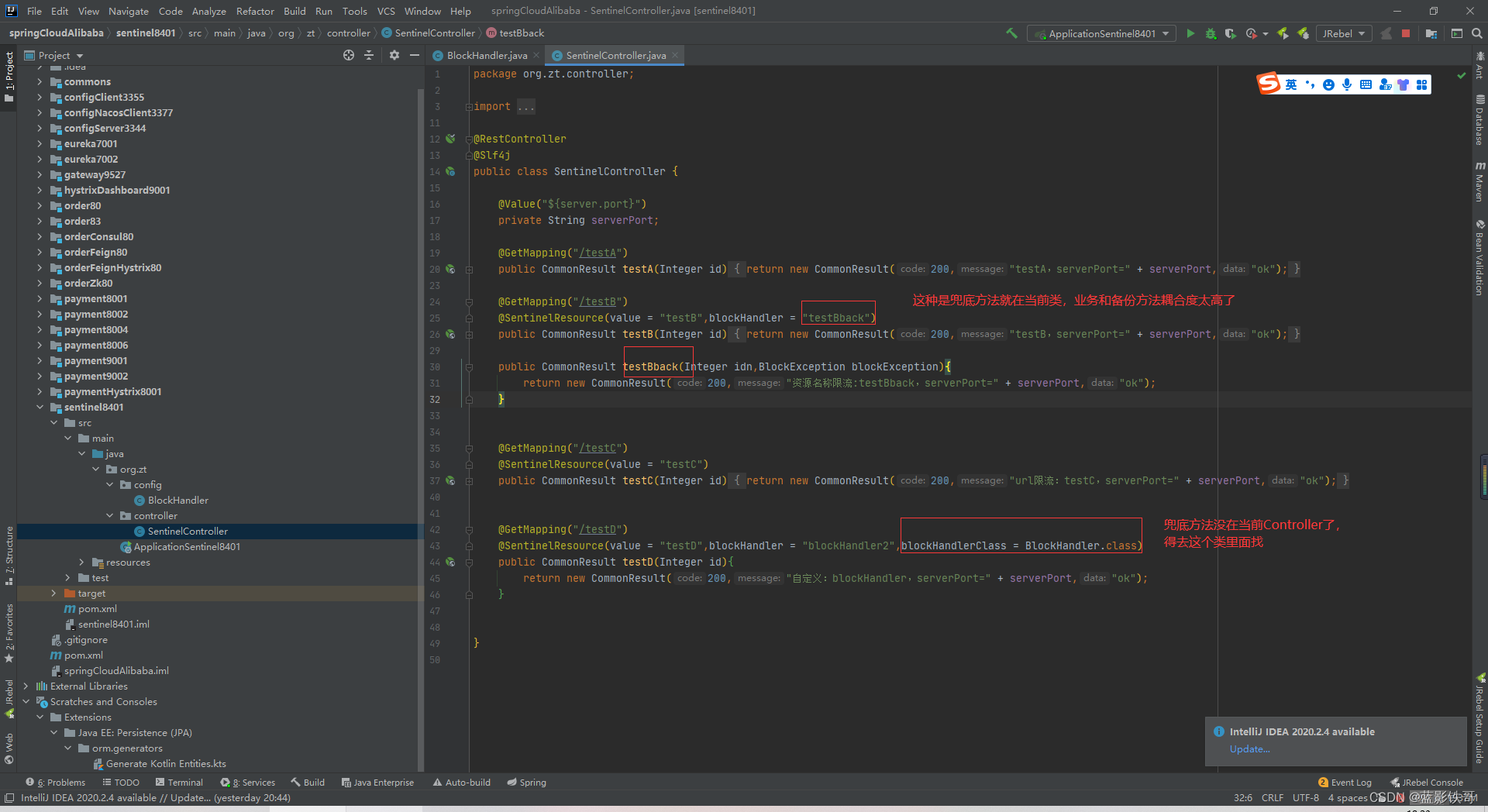
视频截图对比
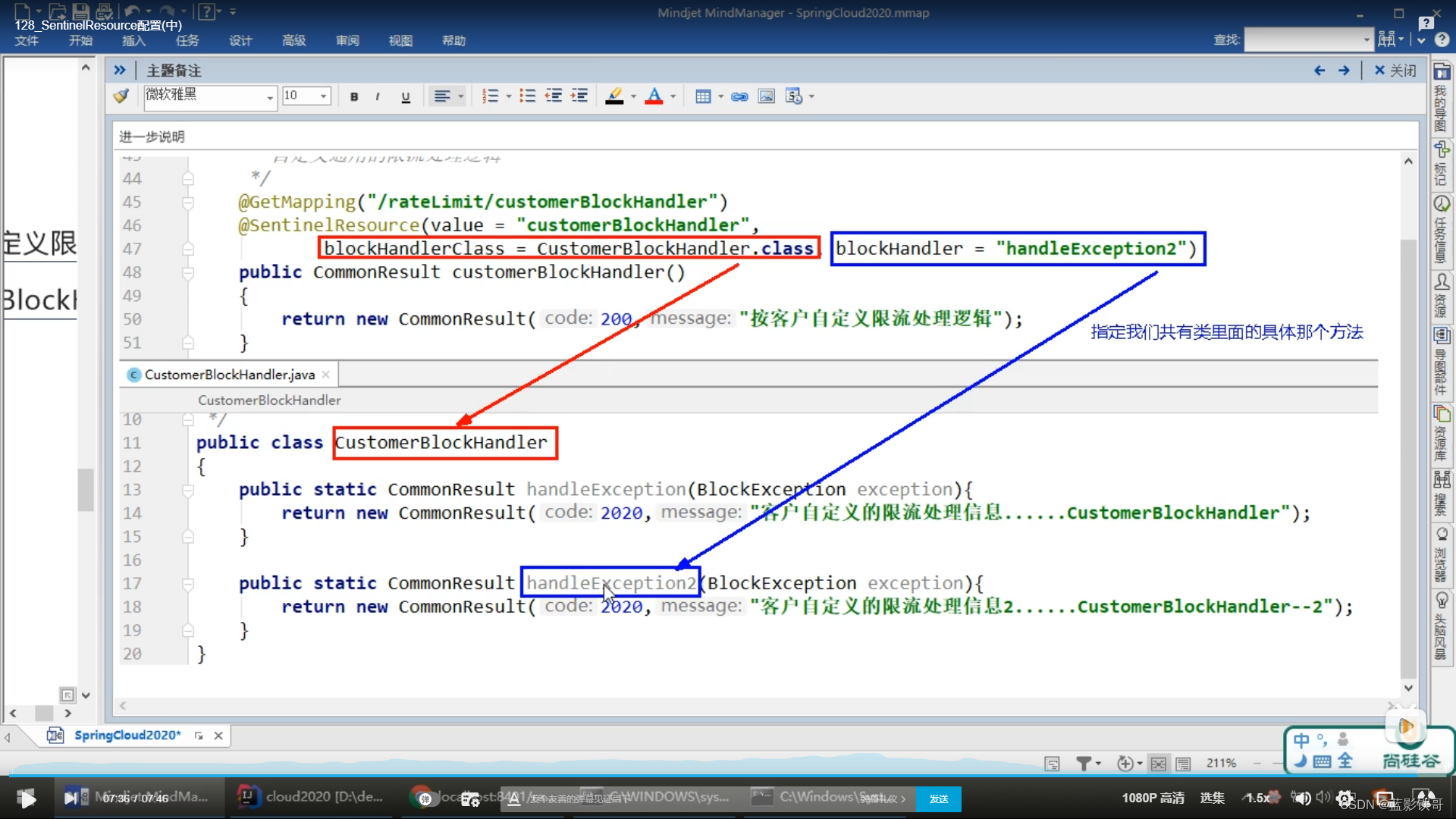
9.5、其他属性
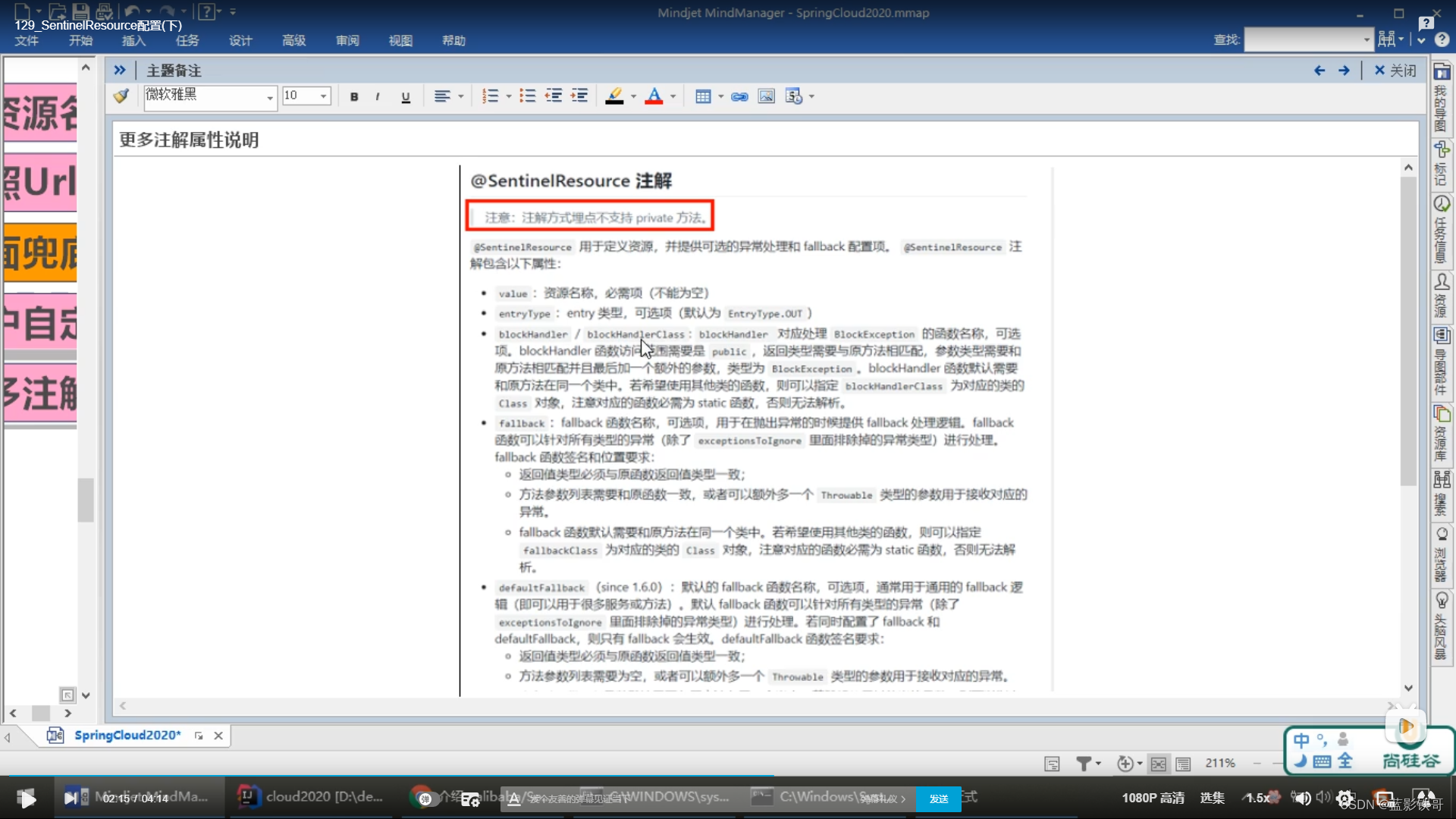

fallbcak像服务降级,可以管java的运行异常,错误等(不需要配置流控)
blockHandler必须和sentinel搭配,需要配置流控,而且不管你java的报错异常等
两个都配置,blockHandler优先级高
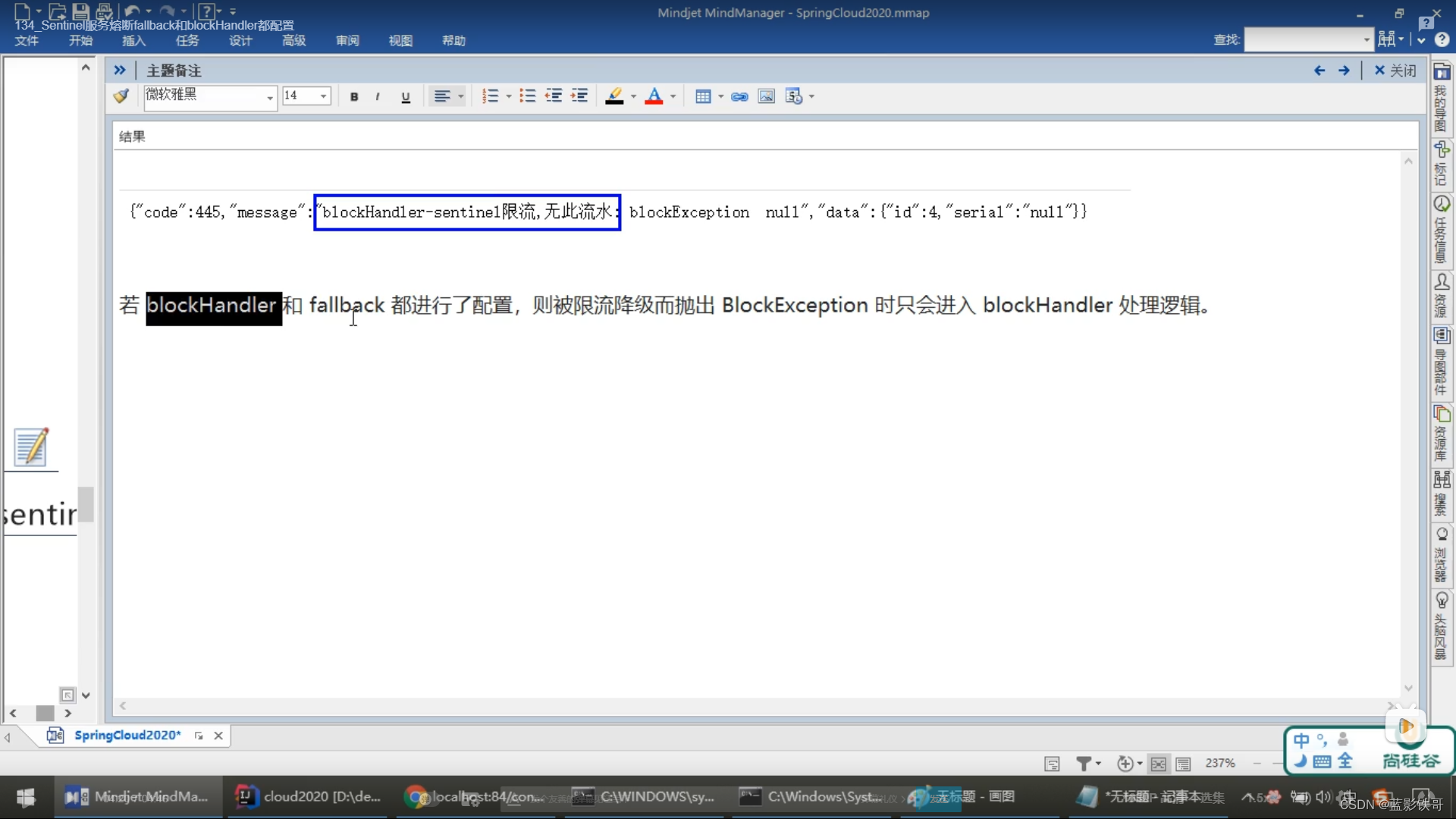
这种方式可以间接让fallback的优先级提高
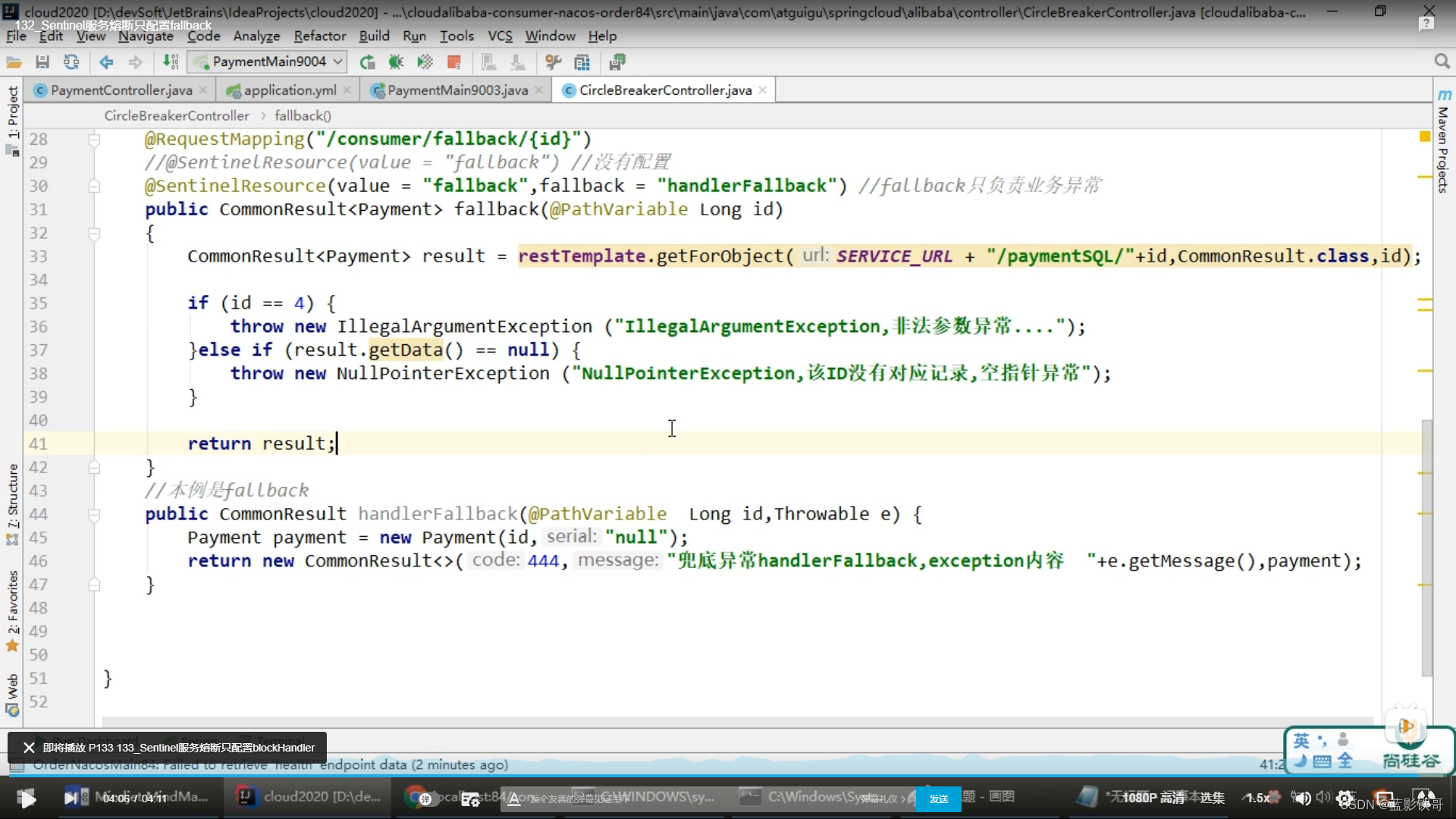
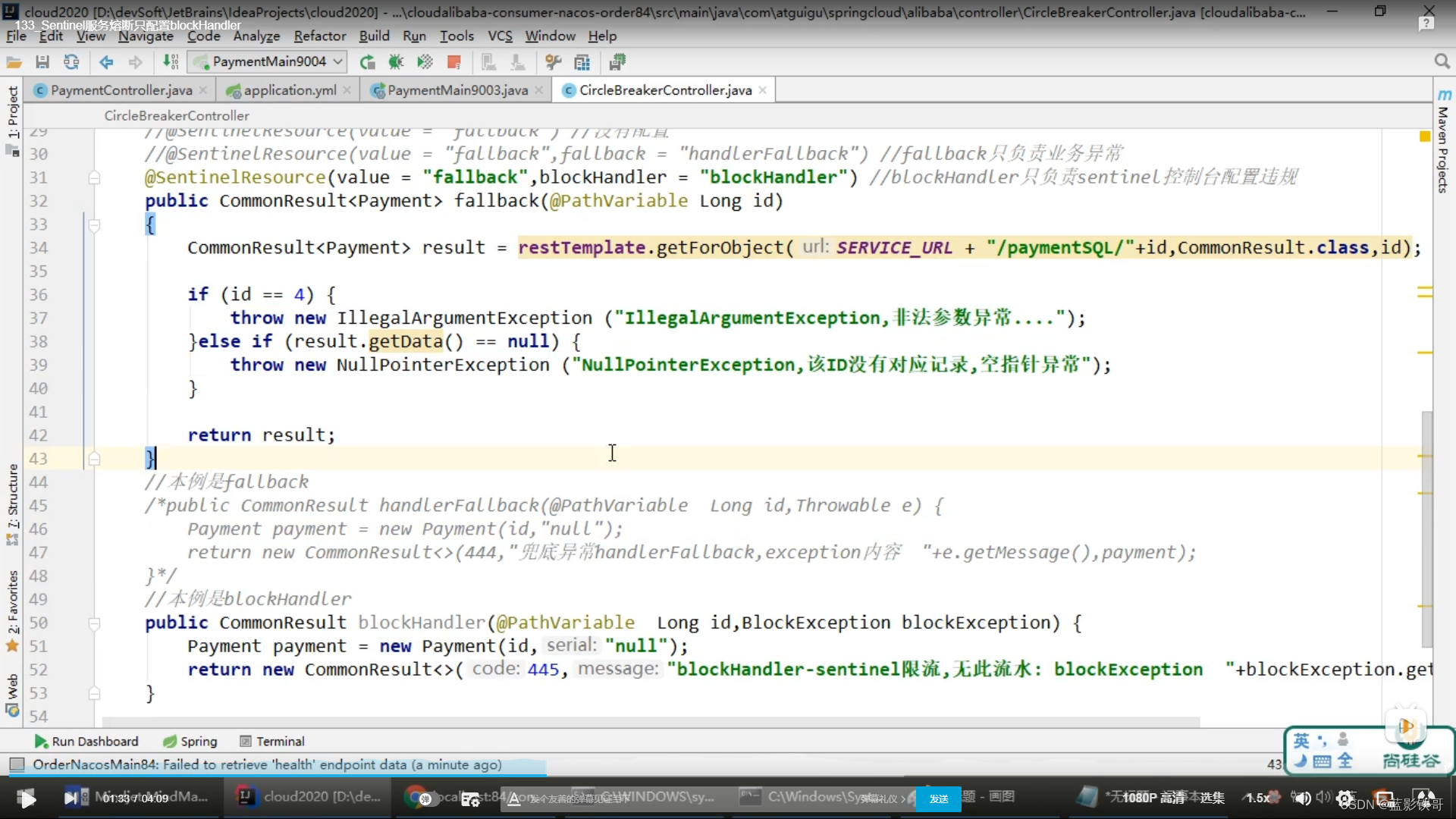
10、服务熔断结合OpenFeign
改POM
改yml
改启动类 (坑:注意加有关OpenFeign的注解的,不加会调用失败,然后也啥报错提示)
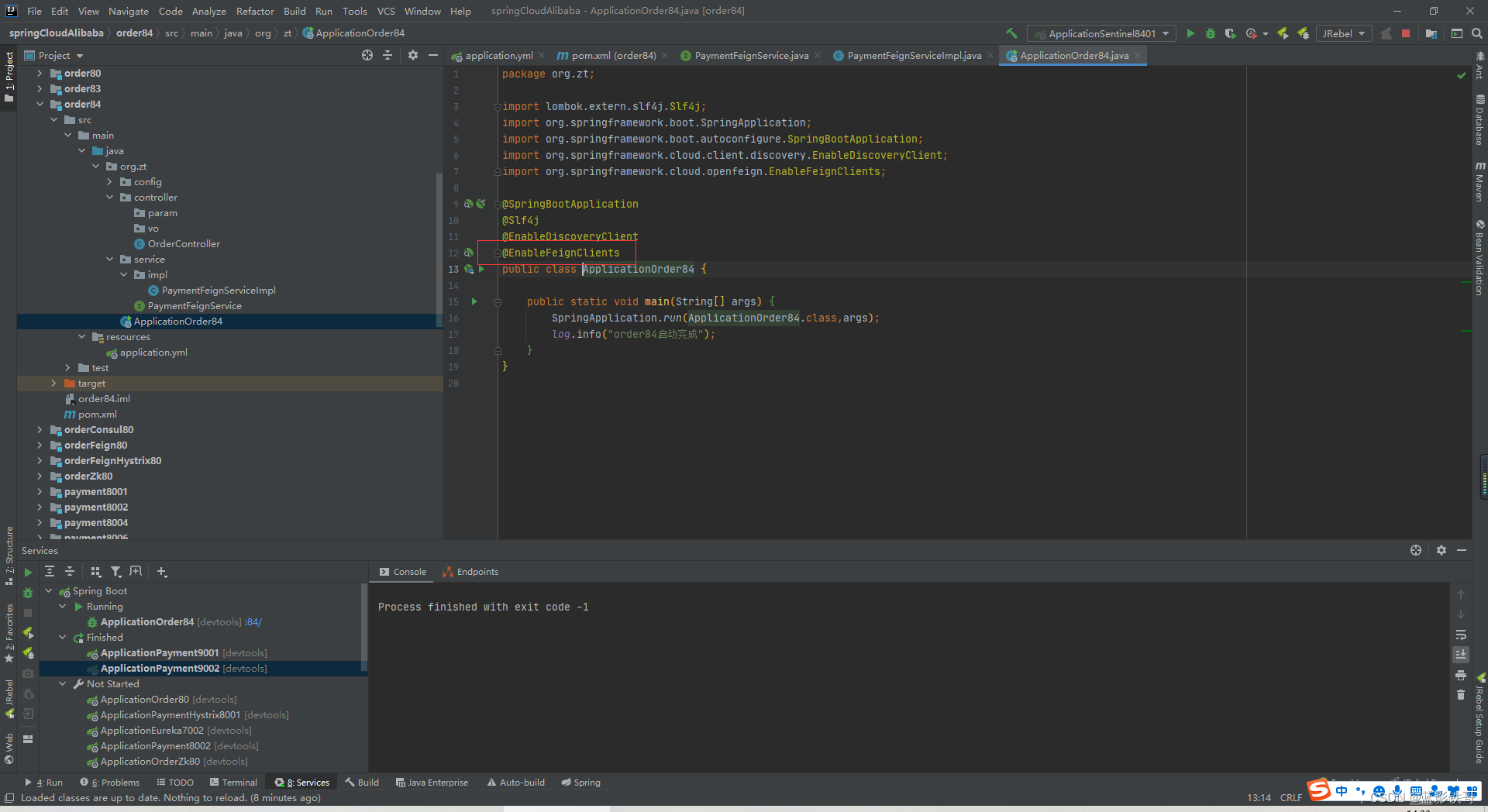
封装Feign接口(坑:注意微服务名字是小写了)
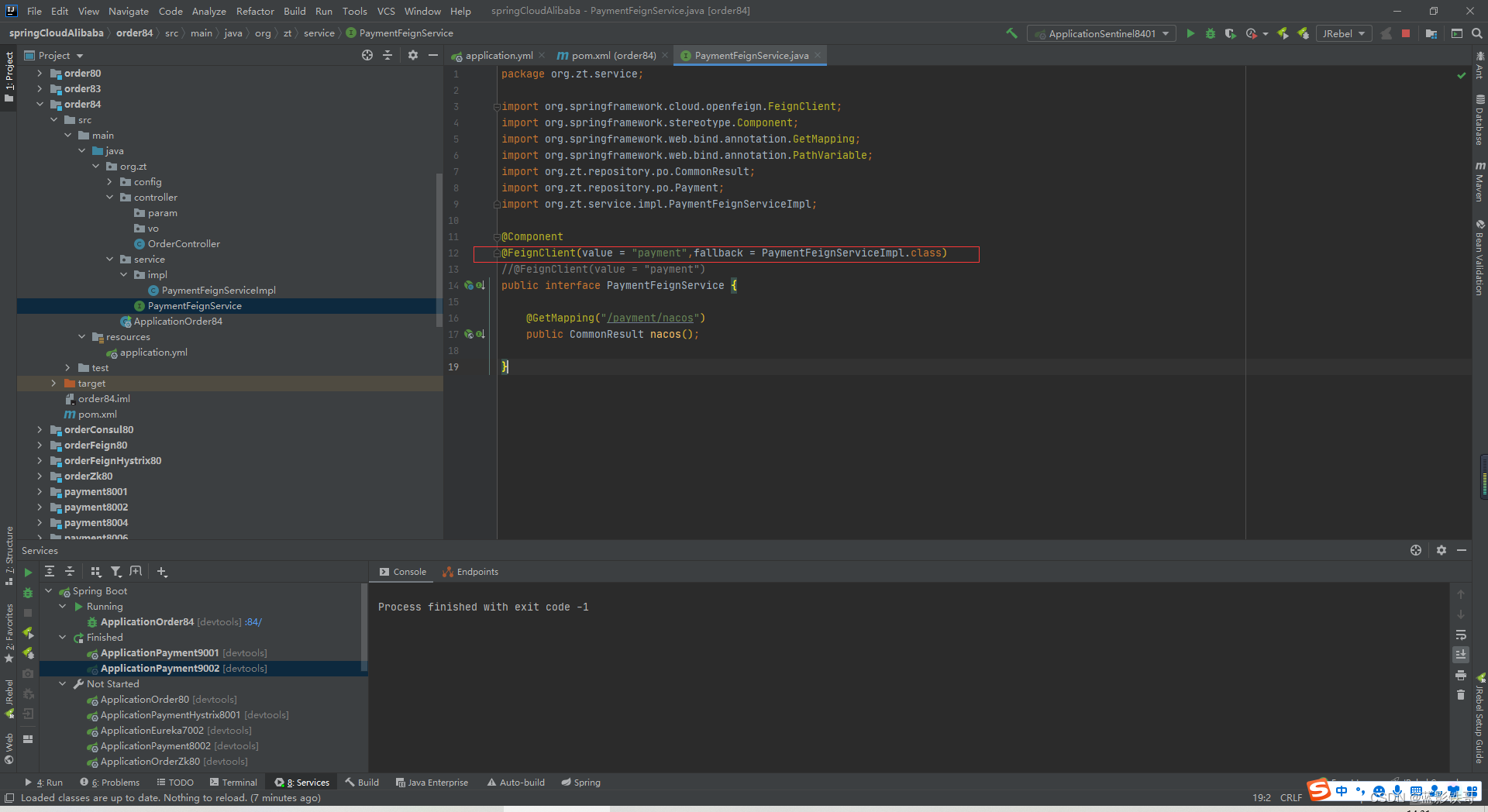
封装兜底实现类
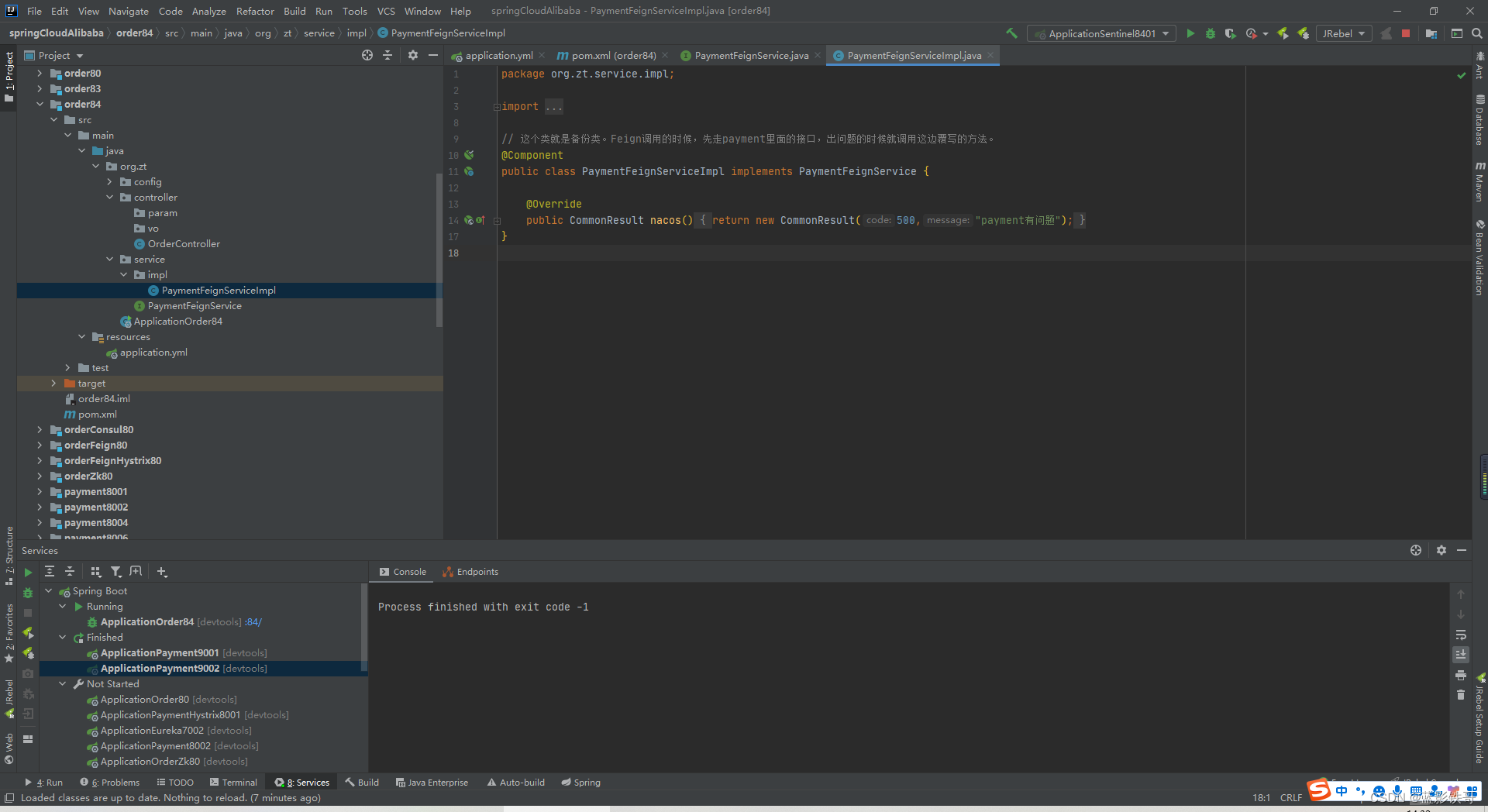
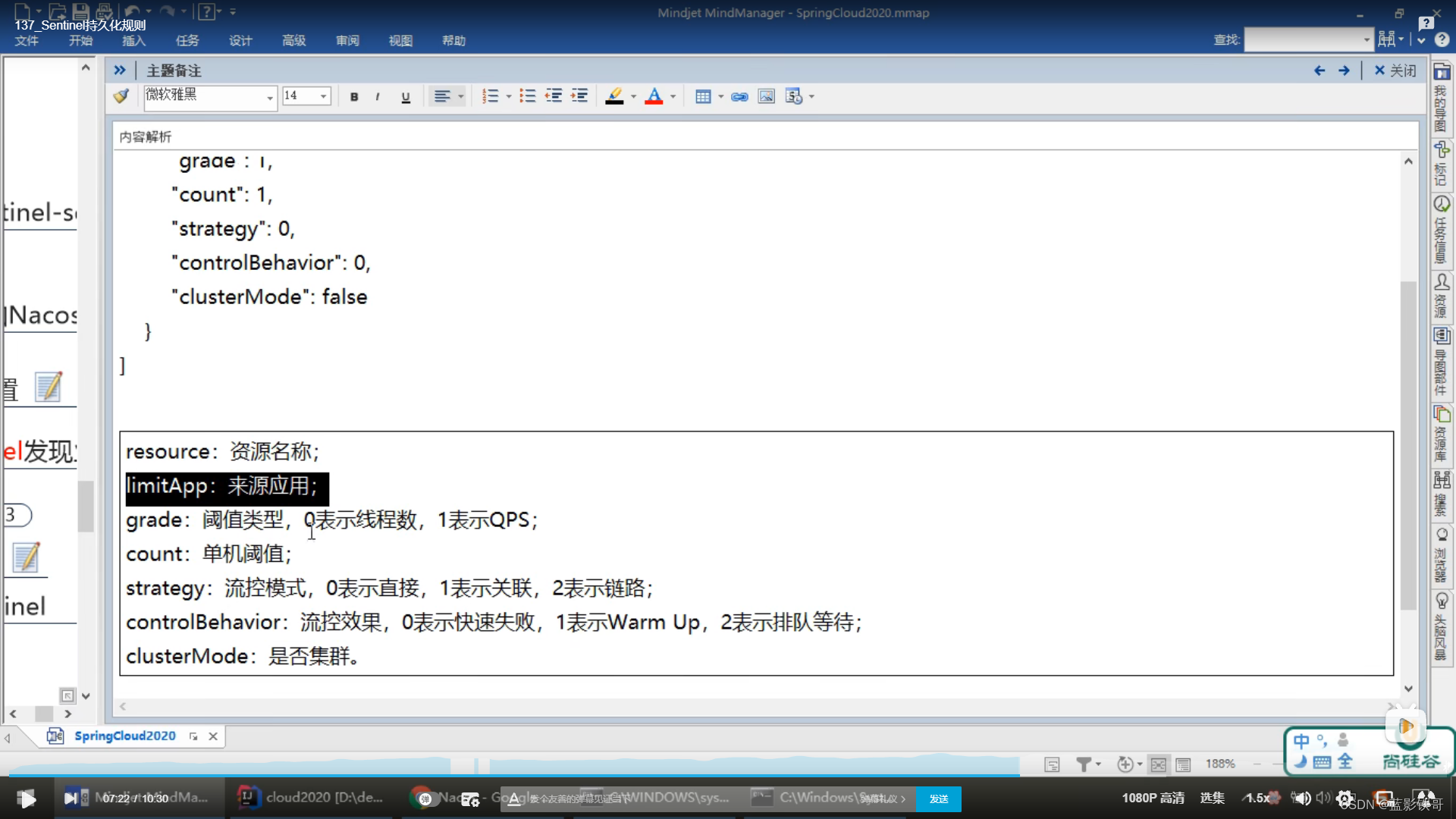
11、规则持久化
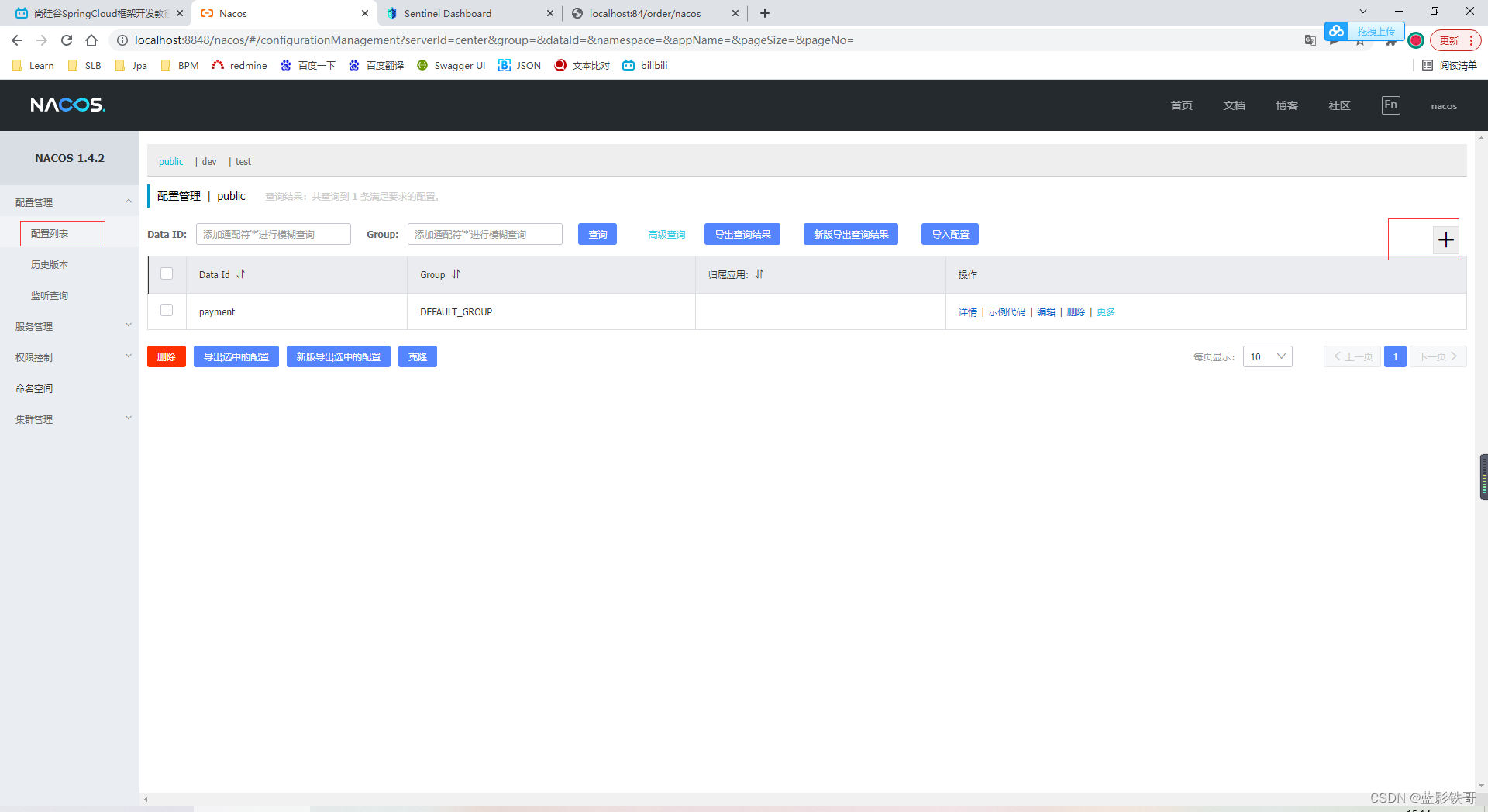
需要整合到nacos中,在nacos做好json那种流控配置,在重启微服务后,Sentinel还是会丢失流控,但是nacos是存着的,重新请求接口地址后,sentinel就会看到。
以payment9001为例子,任何一个微服务都可以是客户端,都可以加这个配置(这个坑多,字母和格式一定要对)
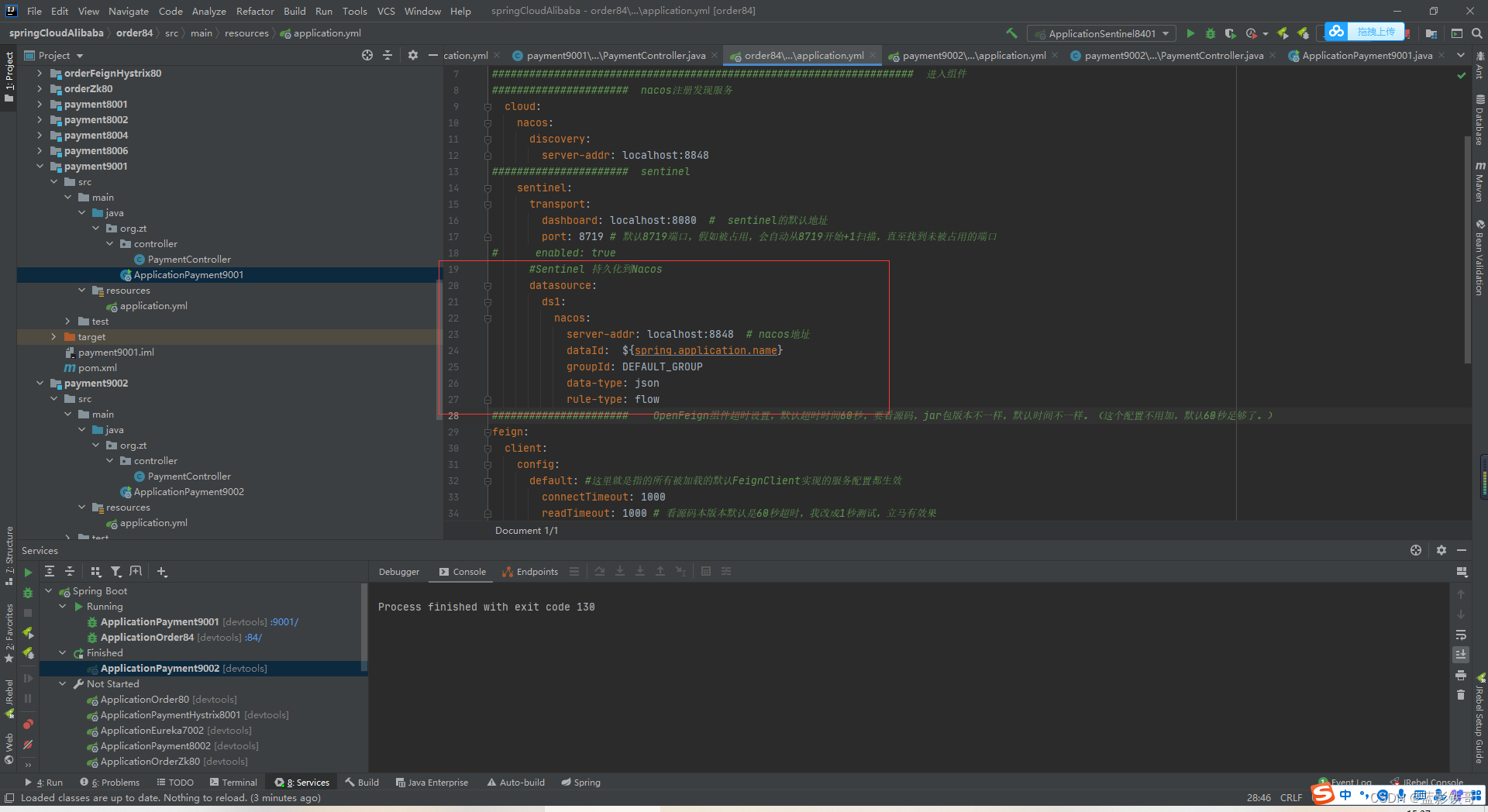
对应Sentinel的流控
新建
配置(坑:注意url地址要匹配对,不然没有效果,还有个坑就是yml配置的,一定要配置格式对,多个空格少个空格,写错个字母都不行)
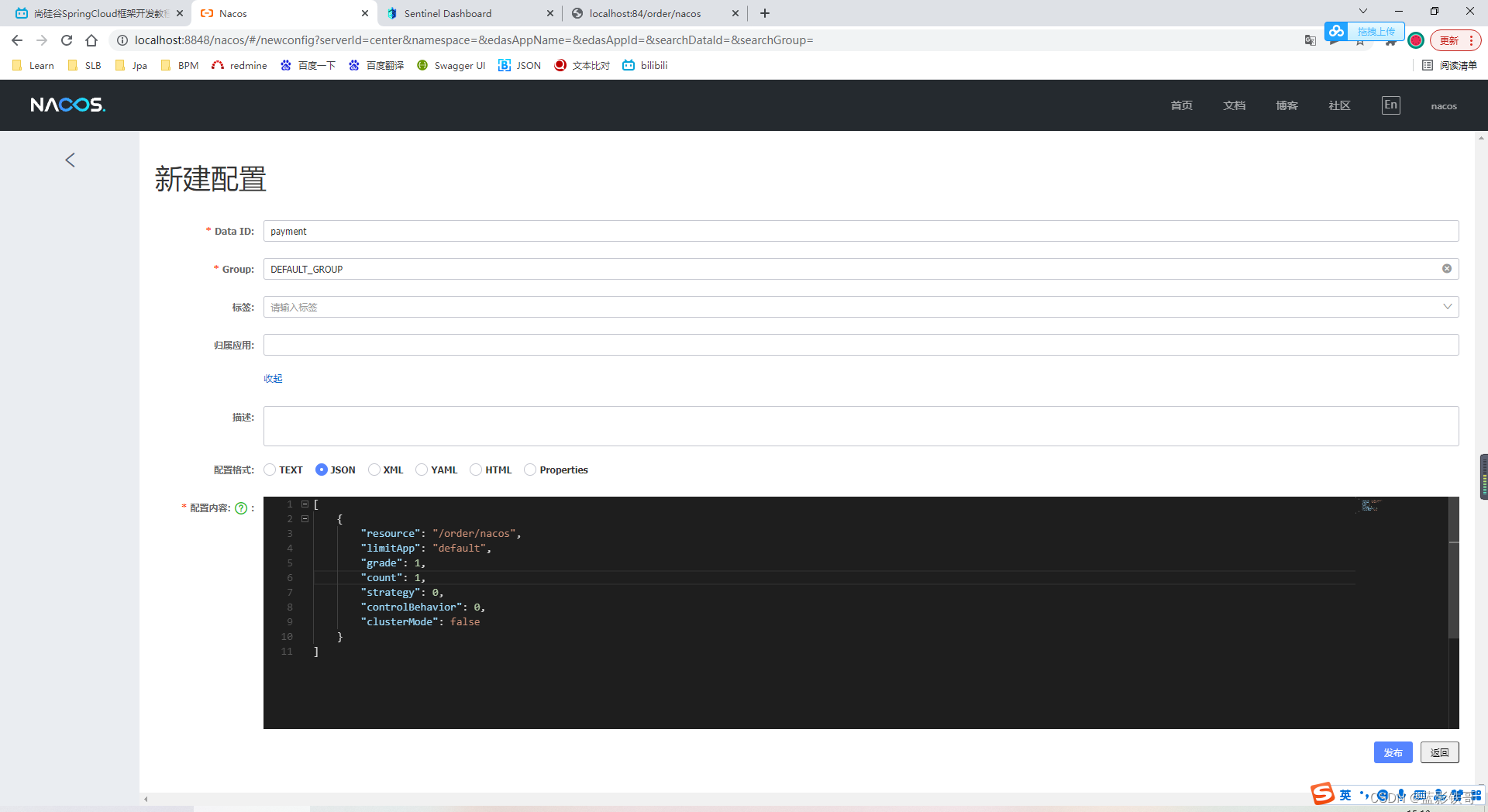
#Sentinel 持久化到Nacos
datasource:
ds1:
nacos:
server-addr: localhost:8848 # nacos地址
dataId: ${spring.application.name}
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
[
{
"resource": "/payment/nacos",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]


















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











