






K-means聚类算法的一般步骤:
- 初始化。输入基因表达矩阵作为对象集X,输入指定聚类类数N,并在X中随机选取N个对象作为初始聚类中心。设定迭代中止条件,比如最大循环次数或者聚类中心收敛误差容限。
- 进行迭代。根据相似度准则将数据对象分配到最接近的聚类中心,从而形成一类。初始化隶属度矩阵。
- 更新聚类中心。然后以每一类的平均向量作为新的聚类中心,重新分配数据对象。
- 反复执行第二步和第三步直至满足中止条件。
下面来看看K-means是如何工作的:
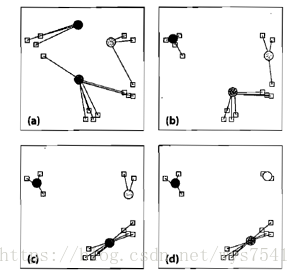
图中圆形为聚类中心,方块为待聚类数据,步骤如下:
(a)选取聚类中心,可以任意选取,也可以通过直方图进行选取。我们选择三个聚类中心,并将数据样本聚到离它最近的中心;
(b)数据中心移动到它所在类别的中心;
(c)数据点根据最邻近规则重新聚到聚类中心;
(d)再次更新聚类中心;不断重复上述过程直到评价标准不再变化
评价标准:
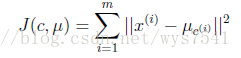
K-means面临的问题以及解决办法:
1.它不能保证找到定位聚类中心的最佳方案,但是它能保证能收敛到某个解决方案(不会无限迭代)。
解决方法:多运行几次K-means,每次初始聚类中心点不同,最后选择方差最小的结果。
2.它无法指出使用多少个类别。在同一个数据集中,例如上图例,选择不同初始类别数获得的最终结果是不同的。
解决方法:首先设类别数为1,然后逐步提高类别数,在每一个类别数都用上述方法,一般情况下,总方差会很快下降,直到到达一个拐点;这意味着再增加一个聚类中心不会显著减少方差,保存此时的聚类数。
MATLAB函数Kmeans
使用方法:
Idx=Kmeans(X,K)
[Idx,C]=Kmeans(X,K)
[Idx,C,sumD]=Kmeans(X,K)
[Idx,C,sumD,D]=Kmeans(X,K)
[…]=Kmeans(…,’Param1’,Val1,’Param2’,Val2,…)
各输入输出参数介绍:
X: N*P的数据矩阵,N为数据个数,P为单个数据维度
K: 表示将X划分为几类,为整数
Idx: N*1的向量,存储的是每个点的聚类标号
C: K*P的矩阵,存储的是K个聚类质心位置
sumD: 1*K的和向量,存储的是类间所有点与该类质心点距离之和
D: N*K的矩阵,存储的是每个点与所有质心的距离
[…]=Kmeans(…,'Param1',Val1,'Param2',Val2,…)
这其中的参数Param1、Param2等,主要可以设置为如下:
1. ‘Distance’(距离测度)
‘sqEuclidean’ 欧式距离(默认时,采用此距离方式)
‘cityblock’ 绝度误差和,又称:L1
‘cosine’ 针对向量
‘correlation’ 针对有时序关系的值
‘Hamming’ 只针对二进制数据
2. ‘Start’(初始质心位置选择方法)
‘sample’ 从X中随机选取K个质心点
‘uniform’ 根据X的分布范围均匀的随机生成K个质心
‘cluster’ 初始聚类阶段随机选择10%的X的子样本(此方法初始使用’sample’方法)
matrix 提供一K*P的矩阵,作为初始质心位置集合
3. ‘Replicates’(聚类重复次数) 整数
案例一:
-
%随机获取
150个点
-
X = [randn(
50,
2)+ones(
50,
2);randn(
50,
2)-ones(
50,
2);randn(
50,
2)+[ones(
50,
1),-ones(
50,
1)]];
-
opts = statset(
'Display',
'final');
-
-
%调用Kmeans函数
-
%X N*P的数据矩阵
-
%Idx N*
1的向量,存储的是每个点的聚类标号
-
%Ctrs K*P的矩阵,存储的是K个聚类质心位置
-
%SumD
1*K的和向量,存储的是类间所有点与该类质心点距离之和
-
%D N*K的矩阵,存储的是每个点与所有质心的距离;
-
-
[Idx,Ctrs,SumD,D] = kmeans(X,
3,
'Replicates',
3,
'Options',opts);
-
-
%画出聚类为
1的点。X(Idx==
1,
1),为第一类的样本的第一个坐标;X(Idx==
1,
2)为第二类的样本的第二个坐标
-
plot(X(Idx==
1,
1),X(Idx==
1,
2),
'r.',
'MarkerSize',
14)
-
hold on
-
plot(X(Idx==
2,
1),X(Idx==
2,
2),
'b.',
'MarkerSize',
14)
-
hold on
-
plot(X(Idx==
3,
1),X(Idx==
3,
2),
'g.',
'MarkerSize',
14)
-
-
%绘出聚类中心点,kx表示是圆形
-
plot(Ctrs(:,
1),Ctrs(:,
2),
'kx',
'MarkerSize',
14,
'LineWidth',
4)
-
plot(Ctrs(:,
1),Ctrs(:,
2),
'kx',
'MarkerSize',
14,
'LineWidth',
4)
-
plot(Ctrs(:,
1),Ctrs(:,
2),
'kx',
'MarkerSize',
14,
'LineWidth',
4)
-
-
legend(
'Cluster 1',
'Cluster 2',
'Cluster 3',
'Centroids',
'Location',
'NW')
-
-
Ctrs
-
SumD
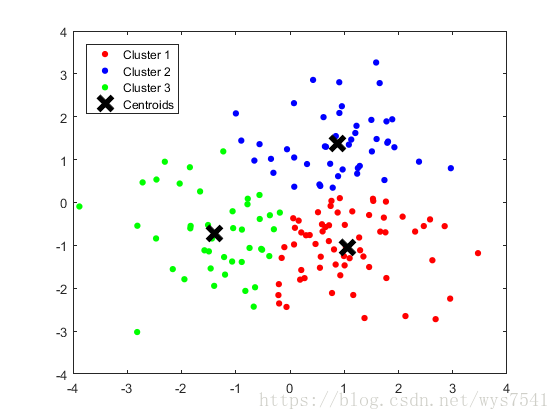
结果图片:
案例二:
-
%K-means聚类
-
clc,clear;
-
load tyVector;
-
X=tyVector
'; %列向量变成行向量,209*180矩阵
-
[x,y]=size(X);
-
opts = statset('Display
','final
');
-
K=11; %将X划分为K类
-
repN=50; %迭代次数
-
-
%K-mean聚类
-
[Idx,Ctrs,SumD,D] = kmeans(X,K,'Replicates
',repN,'Options
',opts);
-
%Idx N*1的向量,存储的是每个点的聚类标号
-
-
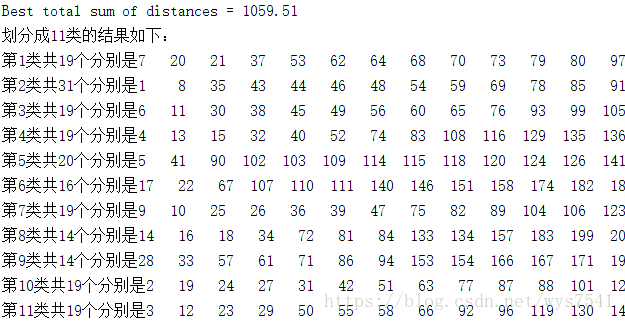
%打印结果
-
fprintf('划分成%d类的结果如下:\n
',K)
-
for i=1:K
-
tm=find(Idx==i); %求第i类的对象
-
tm=reshape(tm,1,length(tm)); %变成行向量
-
fprintf('第%d类共%d个分别是%s\n
',i,length(tm),int2str(tm)); %显示分类结果
-
end
<li class="tool-item tool-active is-like "><a href="javascript:;"><svg class="icon" aria-hidden="true"> <use xlink:href="#csdnc-thumbsup"></use> </svg><span class="name">点赞</span> <span class="count">9</span> </a></li> <li class="tool-item tool-active is-collection "><a href="javascript:;" data-report-click="{"mod":"popu_824"}"><svg class="icon" aria-hidden="true"> <use xlink:href="#icon-csdnc-Collection-G"></use> </svg><span class="name">收藏</span></a></li> <li class="tool-item tool-active is-share"><a href="javascript:;"><svg class="icon" aria-hidden="true"> <use xlink:href="#icon-csdnc-fenxiang"></use> </svg>分享</a></li> <!--打赏开始--> <!--打赏结束--> <li class="tool-item tool-more"> <a> <svg t="1575545411852" class="icon" viewBox="0 0 1024 1024" version="1.1" xmlns="http://www.w3.org/2000/svg" p-id="5717" xmlns:xlink="http://www.w3.org/1999/xlink" width="200" height="200"><defs><style type="text/css"></style></defs><path d="M179.176 499.222m-113.245 0a113.245 113.245 0 1 0 226.49 0 113.245 113.245 0 1 0-226.49 0Z" p-id="5718"></path><path d="M509.684 499.222m-113.245 0a113.245 113.245 0 1 0 226.49 0 113.245 113.245 0 1 0-226.49 0Z" p-id="5719"></path><path d="M846.175 499.222m-113.245 0a113.245 113.245 0 1 0 226.49 0 113.245 113.245 0 1 0-226.49 0Z" p-id="5720"></path></svg> </a> <ul class="more-box"> <li class="item"><a class="article-report">文章举报</a></li> </ul> </li> </ul> </div> </div> <div class="person-messagebox"> <div class="left-message"><a href="https://blog.youkuaiyun.com/wys7541"> <img src="https://profile.csdnimg.cn/2/5/7/3_wys7541" class="avatar_pic" username="wys7541"> <img src="https://g.csdnimg.cn/static/user-reg-year/2x/2.png" class="user-years"> </a></div> <div class="middle-message"> <div class="title"><span class="tit"><a href="https://blog.youkuaiyun.com/wys7541" data-report-click="{"mod":"popu_379"}" target="_blank">勿幻想</a></span> </div> <div class="text"><span>发布了49 篇原创文章</span> · <span>获赞 109</span> · <span>访问量 18万+</span></div> </div> <div class="right-message"> <a href="https://im.youkuaiyun.com/im/main.html?userName=wys7541" target="_blank" class="btn btn-sm btn-red-hollow bt-button personal-letter">私信 </a> <a class="btn btn-sm bt-button personal-watch" data-report-click="{"mod":"popu_379"}">关注</a> </div> </div> </div>

















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









