







 本文详细介绍了如何将PyTorch模型转换为ONNX格式,并在TensorRT中进行推理。首先,使用PyTorch训练模型并导出.pth文件,然后将.pth转换为ONNX模型,重点在于处理ONNX不支持的操作符。接着,使用onnxruntime验证模型转换的正确性。最后,在TensorRT环境中加载并执行ONNX模型,涉及CUDA、CUDNN的配置,以及TensorRT的构建、执行和释放等步骤。整个流程涵盖了模型转换、验证和部署的关键环节。
本文详细介绍了如何将PyTorch模型转换为ONNX格式,并在TensorRT中进行推理。首先,使用PyTorch训练模型并导出.pth文件,然后将.pth转换为ONNX模型,重点在于处理ONNX不支持的操作符。接着,使用onnxruntime验证模型转换的正确性。最后,在TensorRT环境中加载并执行ONNX模型,涉及CUDA、CUDNN的配置,以及TensorRT的构建、执行和释放等步骤。整个流程涵盖了模型转换、验证和部署的关键环节。
一、整体流程概览
- 使用pytorch训练模型,生成*.pth文件
- 将*.pth转换成onnx模型
- 在tensorrt中加载onnx模型,并转换成trt的object
- 在trt中使用第三步转换的object进行推理
二、pth转换成onnx
- 转换的具体步骤请参考我之前的文章<使用NCNN在移动端部署深度学习模型>
- 需要特别说明的地方在于关于onnx支持的操作算子问题,目前onnx的最新版本已经基本支持绝大部分的pytorch操作符,但是由于最终是要在tensorrt下运行的,所以需要了解trt具体支持的操作符。目前tensorrt7.2支持到optset11,关于具体支持哪些操作符请参考:https://github.com/onnx/onnx-tensorrt/blob/master/docs/operators.md
- 对于不支持的操作符解决方案
- 在python代码中使用基本运算进行重写。在重写的时候需时刻注意onnx的转换机制。其核心思想就是tracing。简单来说就是在运行转换代码的时候,onnx会将网络跑一遍,把运行的内容记录下来,但并不是所有的运行内容都被记录,比如:print()语句就不会被记录。具体来说,只有ATen操作会被记录下来。ATen可以被理解为一个Pytorch的基本操作库,一切的Pytorch函数都是基于这些零部件构造出来的(比如ATen就是加减乘除,所有Pytorch的其他操作,比如平方,算sigmoid,都可以根据加减乘除构造出来)。还需要注意有些变量tracing的时候发现不是被计算出来的将会被看作常数保存,利用这点可以优化计算过程,但也很可能成为隐藏的bug!(在改写einsum()函数的时候就被坑了)。如果需要了解更详细的tracing内容请参考:《Pytorch转ONNX-实战篇1(tracing机制)》
- 为了避免出现转换的时候出各种问题,也可以不在python中进行改写,在tensorrt调用的时候通过新增plugin的方式定义trt中不支持的操作符。这个后面重新用一篇文章来写。
- 使用onnxruntime进行验证
- 安装onnxruntime
pip install onnxruntime - 使用onnxruntime验证
import onnxruntime as ort ort_session = ort.InferenceSession('xxx.onnx') img = cv2.imread('test.jpg') net_input = preprocess(img) # 你的预处理函数 outputs = ort_session.run(None, {ort_session.get_inputs()[0].name: net_input}) print(outputs) - 上面的这段代码有一点需要注意,可以发现通过ort_session.get_inputs()[0].name可以得到输入的tensor名称,同理,也可以通过ort_session.get_outputs()[0].name来获得输出tensor的名称,如果你的网络有两个输出,则使用ort_session.get_outputs()[0].name和ort_session.get_outputs()[1].name来获得,这里得到的名称在后续tensorrt调用中会使用!
- 安装onnxruntime
三、 在TensorRT中使用onnx模型
环境准备
- 配置好本地的cuda和cudnn,记住路径
- 在NVIDIA官网下载与本地cuda版本对应的tensorrt,下载时需要使用nvidia的账号登录
- 解压到本地,解压后根目录下的samples文件夹下是自带的例子项目,include是我们项目需要的头文件,lib是编译的时候需要链接的库文件。需要特别说明的是,在samples下有个common文件夹,在项目的头文件包含路径中也是要添加的!主要是用到了里面的logger.h,如果你的项目还用到了命令行参数,那么samples\common\windows这个路径也需要包含!
配置VS
- 打开工程属性页面,定位到“vc++目录"->“包含目录”,添加opencv、tensorrt、cuda的include路径,将以下路径修改成你的本机路径。
D:\opencv\build\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
G:\software\program_tools\TensorRT-7.0.0.11\samples\common
G:\software\program_tools\TensorRT-7.0.0.11\include
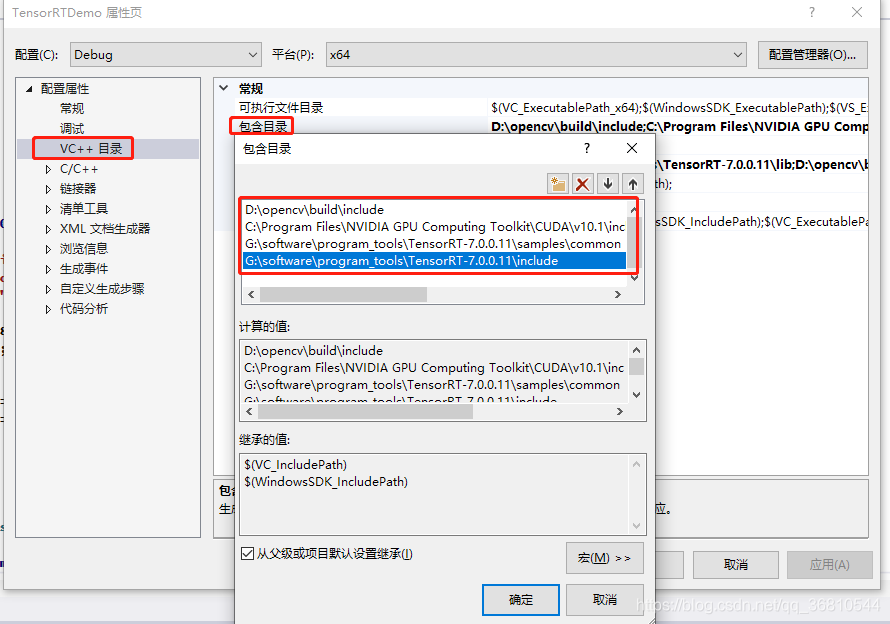
- 添加对应的lib文件路径。定位到“vc++目录"->“库目录”,添加opencv、tensorrt、cuda的lib文件夹路径,同样将以下的路径换成你的本地路径
G:\software\program_tools\TensorRT-7.0.0.11\lib
D:\opencv\build\x64\vc15\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64
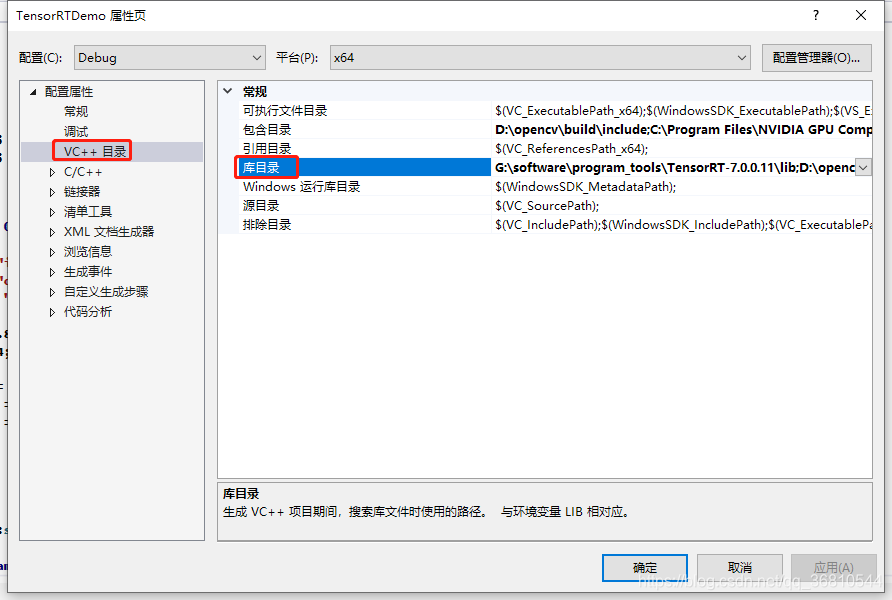
- 定位到“链接器”->“输入","附加依赖项"中添加需要链接的lib文件,根据本地的版本修改文件名
opencv_world340d.lib
%(AdditionalDependencies)
G:\software\program_tools\TensorRT-7.0.0.11\lib*.lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64*.lib
TensorRT调用步骤
- TeensorRT调用概览
- 创建IBuilder的指针builder
- 设置推理的显存大小
- 设置推理的模式,float或者int
- 利用builder创建ICudaEngine的实例engine
- 由engine创建上下文context
- 利用context进行推理,得到结果
- 释放显存空间
- 加载onnx模型
首先TensorRT并不能直接使用onnx模型进行推理运算,需要先转换成trt的模型才行,而且这个转换过程有点慢,所以通常做法是先将onnx转换成trt的模型并序列化后保存,以后直接加载trt的模型而不再做转换!下面的转换代码运行的有点慢,运行时还需耐心等待!
bool onnxToTRTModel(const std::string& modelFile, // name of the onnx model
unsigned int maxBatchSize, // batch size - NB must be at least as large as the batch we want to run with
IHostMemory*& trtModelStream) // output buffer for the TensorRT model
{
// 1. create the builder
IBuilder* builder = createInferBuilder(gLogger.getTRTLogger());
assert(builder != nullptr);
// 创建一个空的nerwork对象,里面的属性还没有值
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(maxBatchSize);
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
// 创建一个onnx的解析对象,
auto parser = nvonnxparser::createParser(*network, gLogger.getTRTLogger());
// 调用parseFromFile函数对network对象进行填充,将onnx里的tensor解析成tensorrt中的tensor
// locateFile()函数是common.cpp中的辅助函数
if (!parser->parseFromFile(locateFile(modelFile, gArgs.dataDirs).c_str(), static_cast<int>(gLogger.getReportableSeverity())))
{
gLogError << "Failure while parsing ONNX file" << std::endl;
return false;
}
// 设置工作空间
builder->setMaxWorkspaceSize(1_GiB);
config->setMaxWorkspaceSize(1_GiB);
// 设置推理模式
builder->setFp16Mode(gArgs.runInFp16);
//builder->setInt8Mode(gArgs.runInInt8);
if (gArgs.runInInt8)
{
config->setFlag(BuilderFlag::kINT8);
samplesCommon::setAllTensorScales(network, 127.0f, 127.0f);
}
samplesCommon::enableDLA(builder, config, gArgs.useDLACore);
// 2. build engine
ICudaEngine* engine = builder->buildCudaEngine(*network);
assert(engine);
// we can destroy the parser
parser->destroy();
// serialize the engine, then close everything down
trtModelStream = engine->serialize();
engine->destroy();
network->destroy();
builder->destroy();
// 序列化到磁盘,方便后续调用
std::ofstream ofs(trtModelName.c_str(), std::ios::out | std::ios::binary);
ofs.write((char*)(trtModelStream->data()), trtModelStream->size());
ofs.close();
trtModelStream->destroy();
DebugP("Trt model save success!");
return true;
}
- 加载序列化后的trt模型
struct TensorRT {
IExecutionContext* context;
ICudaEngine* engine;
IRuntime* runtime;
};
TensorRT* LoadNet(const char* trtFileName)
{
std::ifstream t(trtFileName, std::ios::in | std::ios::binary);
std::stringstream tempStream;
tempStream << t.rdbuf();
t.close();
DebugP("TRT File Loaded");
tempStream.seekg(0, std::ios::end);
const int modelSize = tempStream.tellg();
tempStream.seekg(0, std::ios::beg);
void* modelMem = malloc(modelSize);
tempStream.read((char*)modelMem, modelSize);
IRuntime* runtime = createInferRuntime(gLogger);
if (runtime == nullptr)
{
DebugP("Build Runtime Failure");
return 0;
}
if (gArgs.useDLACore >= 0)
{
runtime->setDLACore(gArgs.useDLACore);
}
ICudaEngine* engine = runtime->deserializeCudaEngine(modelMem, modelSize, nullptr);
if (engine == nullptr)
{
DebugP("Build Engine Failure");
return 0;
}
IExecutionContext* context = engine->createExecutionContext();
if (context == nullptr)
{
DebugP("Build Context Failure");
return 0;
}
TensorRT* trt = new TensorRT();
trt->context = context;
trt->engine = engine;
trt->runtime = runtime;
DebugP("Build trt Model Success!");
return trt;
}
- 进行推理运算
const char* INPUT_BLOB_NAME = "input";
const char* OUTPUT_LOC_NAME = "output";
const char* OUTPUT_CONF_NAME = "3612";
void doInference(IExecutionContext& context, float* input, float** output, int batchSize)
{
const ICudaEngine& engine = context.getEngine();
// input and output buffer pointers that we pass to the engine - the engine requires exactly IEngine::getNbBindings(),
// of these, but in this case we know that there is exactly one input and one output.
assert(engine.getNbBindings() == 3);
// 用于后续GPU开辟显存
void* buffers[3];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
const int outputLocIndex = engine.getBindingIndex(OUTPUT_LOC_NAME);
const int outputConfIndex = engine.getBindingIndex(OUTPUT_CONF_NAME);
DebugP(inputIndex); DebugP(outputLocIndex); DebugP(outputConfIndex);
// create GPU buffers and a stream
CHECK(cudaMalloc(&buffers[inputIndex], batchSize * INPUT_C * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputLocIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputConfIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// DMA the input to the GPU, execute the batch asynchronously, and DMA it back:
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * INPUT_C * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CHECK(cudaMemcpyAsync(output[0], buffers[outputLocIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
CHECK(cudaMemcpyAsync(output[1], buffers[outputConfIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// release the stream and the buffers
cudaStreamDestroy(stream);
CHECK(cudaFree(buffers[inputIndex]));
CHECK(cudaFree(buffers[outputLocIndex]));
CHECK(cudaFree(buffers[outputConfIndex]));
}
- 这里需要说明的主要是engine.getBindingIndex(INPUT_BLOB_NAME);中的INPUT_BLOB_NAME和后续两句代码OUTPUT_LOC_NAME和OUTPUT_CONF_NAME怎么来的。这里就是前述在使用onnxruntime测试时利用ort_session.get_inputs()[0].name得到的值。
- void* buffers[3];定义成了3,是因为我的网络有两个输出加上一个输入所以是3,根据你的实际情况修改
- 在主函数中调用,根据你的需要改掉我的输入/输出预处理。代码主干来源于网络,我做了适当的修改,感谢原作者!如有侵权请给我留言,我删除。
============ 全部的工程代码 =================
main.cpp
#include <algorithm>
#include <assert.h>
#include <cmath>
#include <cuda_runtime_api.h>
#include <fstream>
#include <iomanip>
#include <iostream>
#include <sstream>
#include <sys/stat.h>
#include <time.h>
#include <opencv2/opencv.hpp>
#include <io.h>
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "argsParser.h"
#include "logger.h"
#include "common.h"
#include "image.h"
#include "tools.h"
#define DebugP(x) std::cout << "Line" << __LINE__ << " " << #x << "=" << x << std::endl
struct TensorRT {
IExecutionContext* context;
ICudaEngine* engine;
IRuntime* runtime;
};
using namespace nvinfer1;
static const int INPUT_H = 300;
static const int INPUT_W = 300;
static const int INPUT_C = 3;
const int OUTPUT_LEN = 5329;
const int CLASS_NUM = 4;
static const int OUTPUT_SIZE = OUTPUT_LEN * CLASS_NUM;
const char* INPUT_BLOB_NAME = "input";
const char* OUTPUT_LOC_NAME = "output";
const char* OUTPUT_CONF_NAME = "3612";
const float conf_threshold = 0.8;
const float nms_threshold = 0.4;
const std::string gSampleName = "TensorRT.object_detect";
const std::string trtModelName = "trt_model.pb";
const std::string onnxModeName = "";
samplesCommon::Args gArgs;
bool onnxToTRTModel(const std::string& modelFile, // name of the onnx model
unsigned int maxBatchSize, // batch size - NB must be at least as large as the batch we want to run with
IHostMemory*& trtModelStream) // output buffer for the TensorRT model
{
// create the builder
IBuilder* builder = createInferBuilder(gLogger.getTRTLogger());
assert(builder != nullptr);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(maxBatchSize);
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
auto parser = nvonnxparser::createParser(*network, gLogger.getTRTLogger());
if (!parser->parseFromFile(locateFile(modelFile, gArgs.dataDirs).c_str(), static_cast<int>(gLogger.getReportableSeverity())))
{
gLogError << "Failure while parsing ONNX file" << std::endl;
return false;
}
// Build the engine
//builder->setMaxWorkspaceSize(1 << 20);
builder->setMaxWorkspaceSize(1_GiB);
config->setMaxWorkspaceSize(1_GiB);
builder->setFp16Mode(gArgs.runInFp16);
//builder->setInt8Mode(gArgs.runInInt8);
if (gArgs.runInInt8)
{
config->setFlag(BuilderFlag::kINT8);
samplesCommon::setAllTensorScales(network, 127.0f, 127.0f);
}
samplesCommon::enableDLA(builder, config, gArgs.useDLACore);
ICudaEngine* engine = builder->buildCudaEngine(*network);
assert(engine);
// we can destroy the parser
parser->destroy();
// serialize the engine, then close everything down
trtModelStream = engine->serialize();
engine->destroy();
network->destroy();
builder->destroy();
std::ofstream ofs(trtModelName.c_str(), std::ios::out | std::ios::binary);
ofs.write((char*)(trtModelStream->data()), trtModelStream->size());
ofs.close();
trtModelStream->destroy();
DebugP("Trt model save success!");
return true;
}
TensorRT* LoadNet(const char* trtFileName)
{
std::ifstream t(trtFileName, std::ios::in | std::ios::binary);
std::stringstream tempStream;
tempStream << t.rdbuf();
t.close();
DebugP("TRT File Loaded");
tempStream.seekg(0, std::ios::end);
const int modelSize = tempStream.tellg();
tempStream.seekg(0, std::ios::beg);
void* modelMem = malloc(modelSize);
tempStream.read((char*)modelMem, modelSize);
IRuntime* runtime = createInferRuntime(gLogger);
if (runtime == nullptr)
{
DebugP("Build Runtime Failure");
return 0;
}
if (gArgs.useDLACore >= 0)
{
runtime->setDLACore(gArgs.useDLACore);
}
ICudaEngine* engine = runtime->deserializeCudaEngine(modelMem, modelSize, nullptr);
if (engine == nullptr)
{
DebugP("Build Engine Failure");
return 0;
}
IExecutionContext* context = engine->createExecutionContext();
if (context == nullptr)
{
DebugP("Build Context Failure");
return 0;
}
TensorRT* trt = new TensorRT();
trt->context = context;
trt->engine = engine;
trt->runtime = runtime;
DebugP("Build trt Model Success!");
return trt;
}
void doInference(IExecutionContext& context, float* input, float** output, int batchSize)
{
const ICudaEngine& engine = context.getEngine();
// input and output buffer pointers that we pass to the engine - the engine requires exactly IEngine::getNbBindings(),
// of these, but in this case we know that there is exactly one input and one output.
assert(engine.getNbBindings() == 3);
void* buffers[3];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
const int outputLocIndex = engine.getBindingIndex(OUTPUT_LOC_NAME);
const int outputConfIndex = engine.getBindingIndex(OUTPUT_CONF_NAME);
DebugP(inputIndex); DebugP(outputLocIndex); DebugP(outputConfIndex);
// create GPU buffers and a stream
CHECK(cudaMalloc(&buffers[inputIndex], batchSize * INPUT_C * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputLocIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputConfIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// DMA the input to the GPU, execute the batch asynchronously, and DMA it back:
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * INPUT_C * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CHECK(cudaMemcpyAsync(output[0], buffers[outputLocIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
CHECK(cudaMemcpyAsync(output[1], buffers[outputConfIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// release the stream and the buffers
cudaStreamDestroy(stream);
CHECK(cudaFree(buffers[inputIndex]));
CHECK(cudaFree(buffers[outputLocIndex]));
CHECK(cudaFree(buffers[outputConfIndex]));
}
void Flaten2Matrix(float* src, int row_num, int clo_num, float** out_mat)
{
for (int i=0;i<row_num;i++)
{
out_mat[i] = new float[clo_num];
for (int j = 0; j < clo_num; j++)
{
out_mat[i][j] = src[i * clo_num + j];
}
}
}
inline bool cmp(ObjInfo a, ObjInfo b)
{
return a.prob > b.prob;
}
void PostProcessing(float** loc, float** conf, ImagePaddingInfo &img_pad_info, std::vector<ObjInfo> &obj)
{
std::vector<box> anchor;
CreateAnchor(anchor, INPUT_W, INPUT_H);
std::vector<ObjInfo> total_box;
// get NMS result
box tmp, tmp1;
for (int i = 0; i < anchor.size(); ++i)
{
const float *boxes = loc[i];
const float *scores = conf[i];
for (int class_id = 1; class_id < CLASS_NUM; class_id++)
{
if (scores[class_id] > conf_threshold)
{
tmp = anchor[i];
ObjInfo result;
tmp1.cx = tmp.cx + boxes[0] * 0.1 * tmp.sx;
tmp1.cy = tmp.cy + boxes[1] * 0.1 * tmp.sy;
tmp1.sx = tmp.sx * exp(boxes[2] * 0.2);
tmp1.sy = tmp.sy * exp(boxes[3] * 0.2);
result.x1 = ((tmp1.cx - tmp1.sx / 2) * INPUT_W - img_pad_info.left) / img_pad_info.scale;
result.y1 = ((tmp1.cy - tmp1.sy / 2) * INPUT_H - img_pad_info.top) / img_pad_info.scale;
result.x2 = ((tmp1.cx + tmp1.sx / 2) * INPUT_W - img_pad_info.left) / img_pad_info.scale;
result.y2 = ((tmp1.cy + tmp1.sy / 2) * INPUT_H - img_pad_info.top) / img_pad_info.scale;
result.prob = *(scores + 1);
result.class_id = class_id;
total_box.push_back(result);
}
}
}
std::sort(total_box.begin(), total_box.end(), cmp);
NMS(total_box, nms_threshold);
for (int j = 0; j < total_box.size(); ++j) {
obj.push_back(total_box[j]);
}
}
int main(int argc, char** argv)
{
// create a TensorRT model from the onnx model and serialize it to a stream
IHostMemory* trtModelStream{ nullptr };
TensorRT* ptensor_rt;
IExecutionContext* context = nullptr;
IRuntime* runtime = nullptr;
ICudaEngine* engine = nullptr;
if (_access(trtModelName.c_str(), 0) != 1)
{
ptensor_rt = LoadNet(trtModelName.c_str());
context = ptensor_rt->context;
runtime = ptensor_rt->runtime;
engine = ptensor_rt->engine;
}
else
{
if (!onnxToTRTModel(onnxModeName, 1, trtModelStream))
return 1;
assert(trtModelStream != nullptr);
std::cout << "Successfully parsed ONNX file!!!!" << std::endl;
// deserialize the engine
runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
if (gArgs.useDLACore >= 0)
{
runtime->setDLACore(gArgs.useDLACore);
}
engine = runtime->deserializeCudaEngine(trtModelStream->data(), trtModelStream->size(), nullptr);
assert(engine != nullptr);
trtModelStream->destroy();
context = engine->createExecutionContext();
assert(context != nullptr);
}
// 输入预处理
std::cout << "Start reading the input image!!!!" << std::endl;
cv::Mat image = cv::imread(locateFile("test.jpg", gArgs.dataDirs), cv::IMREAD_COLOR);
cv::Mat dst;
ImagePaddingInfo img_pad_info;
ImageScaleAndPadding(image, dst, INPUT_H, img_pad_info);
DebugP(dst.size());
float* net_input = normal(dst);
float* out[2];
out[0] = new float[OUTPUT_LEN * 4];
out[1] = new float[OUTPUT_LEN * CLASS_NUM];
typedef std::chrono::high_resolution_clock Time;
typedef std::chrono::duration<double, std::ratio<1, 1000>> ms;
typedef std::chrono::duration<float> fsec;
double total = 0.0;
// run inference and cout time
auto t0 = Time::now();
doInference(*context, net_input, out, 1);
auto t1 = Time::now();
fsec fs = t1 - t0;
ms d = std::chrono::duration_cast<ms>(fs);
total += d.count();
//网络输出的后处理
float* loc[OUTPUT_LEN];
float* conf[OUTPUT_LEN];
std::vector<ObjInfo> obj;
Flaten2Matrix(out[0], OUTPUT_LEN, 4, loc);
Flaten2Matrix(out[1], OUTPUT_LEN, CLASS_NUM, conf);
PostProcessing(loc, conf, img_pad_info, obj);
// destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
std::cout << std::endl << "Running time of one image is:" << total << "ms" << std::endl;
return 0;
}
image.h
#pragma once
#include <opencv2/opencv.hpp>
typedef struct {
int w;
int h;
int c;
float *data;
} image;
typedef struct {
int top;
int left;
float scale;
}ImagePaddingInfo;
float* normal(cv::Mat img);
int ImageScaleAndPadding(cv::Mat src_img, cv::Mat &dst_img, int target_size, ImagePaddingInfo &img_pad_info);
image.cpp
#include "image.h"
static const float kMean[3] = { 0.485f, 0.456f, 0.406f };
static const float kStdDev[3] = { 0.229f, 0.224f, 0.225f };
float* normal(cv::Mat img) {
//cv::Mat image(img.rows, img.cols, CV_32FC3);
float * data;
data = (float*)calloc(img.rows*img.cols * 3, sizeof(float));
for (int c = 0; c < 3; ++c)
{
for (int i = 0; i < img.rows; ++i)
{ //获取第i行首像素指针
cv::Vec3b *p1 = img.ptr<cv::Vec3b>(i);
//cv::Vec3b *p2 = image.ptr<cv::Vec3b>(i);
for (int j = 0; j < img.cols; ++j)
{
data[c * img.cols * img.rows + i * img.cols + j] = (p1[j][c] / 255.0f - kMean[c]) / kStdDev[c];
}
}
}
return data;
}
int ImageScaleAndPadding(cv::Mat src_img, cv::Mat &dst_img, int target_size, ImagePaddingInfo &img_pad_info)
{
int w = src_img.cols;
int h = src_img.rows;
int im_max_size = w > h ? w : h;
float ratio = target_size * 1.0 / im_max_size;
cv::Mat resize_img;
cv::resize(src_img, resize_img, cv::Size(), ratio, ratio, cv::INTER_LINEAR);
int resize_w = resize_img.cols;
int resize_h = resize_img.rows;
int dh = target_size - resize_h;
int dw = target_size - resize_w;
int top = dh / 2;
int bottom = dh - top;
int left = dw / 2;
int right = dw - left;
cv::copyMakeBorder(resize_img, dst_img, top, bottom, left, right, cv::BORDER_CONSTANT, 0);
img_pad_info.left = left;
img_pad_info.top = top;
img_pad_info.scale = ratio;
return 0;
}
tools.h
#pragma once
#include <iostream>
#include <vector>
#include <algorithm>
struct bbox {
float x1;
float y1;
float x2;
float y2;
float score;
};
struct box {
float cx;
float cy;
float sx;
float sy;
};
struct ObjInfo {
float x1; //bbox的left
float y1; //bbox的top
float x2; //bbox的right
float y2; //bbox的bottom
float prob; //置信度
int class_id;
};
void NMS(std::vector<ObjInfo> &input_boxes, float NMS_THRESH);
void CreateAnchor(std::vector<box> &anchor, int w, int h);
tools.cpp
#include "tools.h"
void CreateAnchor(std::vector<box> &anchor, int w, int h)
{
anchor.clear();
std::vector<std::vector<int> > feature_map(4), min_sizes(4);
float steps[] = { 8, 16, 32, 64 };
for (int i = 0; i < feature_map.size(); ++i) {
feature_map[i].push_back(ceil(h / steps[i]));
feature_map[i].push_back(ceil(w / steps[i]));
}
std::vector<int> minsize1 = { 10, 16, 24 };
min_sizes[0] = minsize1;
std::vector<int> minsize2 = { 32, 48 };
min_sizes[1] = minsize2;
std::vector<int> minsize3 = { 64, 96 };
min_sizes[2] = minsize3;
std::vector<int> minsize4 = { 128, 192, 256 };
min_sizes[3] = minsize4;
for (int k = 0; k < feature_map.size(); ++k)
{
std::vector<int> min_size = min_sizes[k];
for (int i = 0; i < feature_map[k][0]; ++i)
{
for (int j = 0; j < feature_map[k][1]; ++j)
{
for (int l = 0; l < min_size.size(); ++l)
{
float s_kx = min_size[l] * 1.0 / w;
float s_ky = min_size[l] * 1.0 / h;
float cx = (j + 0.5) * steps[k] / w;
float cy = (i + 0.5) * steps[k] / h;
box axil = { cx, cy, s_kx, s_ky };
anchor.push_back(axil);
}
}
}
}
}
void NMS(std::vector<ObjInfo> &input_boxes, float NMS_THRESH)
{
std::vector<float>vArea(input_boxes.size());
for (int i = 0; i < int(input_boxes.size()); ++i)
{
vArea[i] = (input_boxes.at(i).x2 - input_boxes.at(i).x1 + 1)
* (input_boxes.at(i).y2 - input_boxes.at(i).y1 + 1);
}
for (int i = 0; i < int(input_boxes.size()); ++i)
{
for (int j = i + 1; j < int(input_boxes.size());)
{
float xx1 = (std::max)(input_boxes[i].x1, input_boxes[j].x1);
float yy1 = (std::max)(input_boxes[i].y1, input_boxes[j].y1);
float xx2 = (std::min)(input_boxes[i].x2, input_boxes[j].x2);
float yy2 = (std::min)(input_boxes[i].y2, input_boxes[j].y2);
float w = (std::max)(float(0), xx2 - xx1 + 1);
float h = (std::max)(float(0), yy2 - yy1 + 1);
float inter = w * h;
float ovr = inter / (vArea[i] + vArea[j] - inter);
if (ovr >= NMS_THRESH)
{
input_boxes.erase(input_boxes.begin() + j);
vArea.erase(vArea.begin() + j);
}
else
{
j++;
}
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









