







k8s_day06_03
deployment
deployment 主要是控制无状态应用的
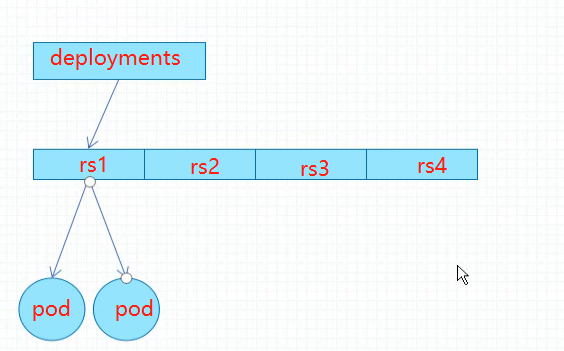
deployment 借助一到多个rs 间接的管理pod。 deployment 是rs 控制器,但是 deploy在定义的时候完全用不到rs 相关的配置。deployments 在更新时候 会创建新的rs和pod。但是k8s 会保存 历史版本的rs 信息, k8s 默认最多保存10个版本的rs 信息 (revisionHistoryLimit),但是只有最近的版本的rs 的pod 才会被创建出来,之前版本rs replicas 为0
资源字段说明
apiVersion: apps/v1 # API群组及版本
kind: Deployment # 资源类型特有标识
metadata:
name <string> # 资源名称,在作用域中要唯一
namespace <string> # 名称空间;Deployment隶属名称空间级别
spec:
minReadySeconds <integer> # Pod就绪后多少秒内任一容器无crash方可视为“就绪”
replicas <integer> # 期望的Pod副本数,默认为1
selector <object> # 标签选择器,必须匹配template字段中Pod模板中的标签
template <object> # Pod模板对象
revisionHistoryLimit <integer> # 滚动更新历史记录数量,默认为10
strategy <Object> # 滚动更新策略
type <string> # 滚动更新类型,可用值有Recreate和RollingUpdate;
rollingUpdate <Object> # 滚动更新参数,专用于RollingUpdate类型
maxSurge <string> # 更新期间可比期望的Pod数量多出的数量或比例;默认25%
maxUnavailable <string> # 更新期间可比期望的Pod数量缺少的数量或比例,Defaults to 25%
progressDeadlineSeconds <integer> # 滚动更新故障超时时长,默认为600秒
paused <boolean> # 是否暂停部署过程
strategy: 有Recreate和RollingUpdate种
Recreate 表示 批量删除重新建立,缺点就是会导致service 访问中断 ; RollingUpdate 表示滚动更新
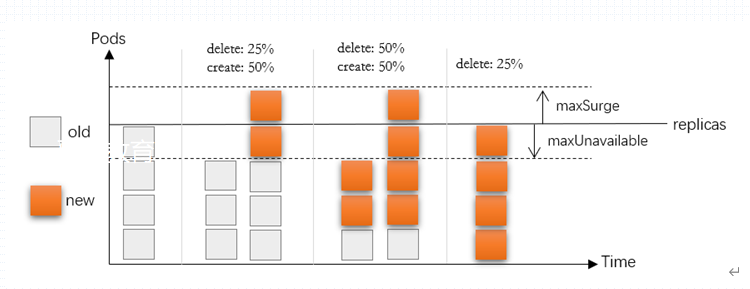
滚动更新时的策略有3种,用于控制滚动时是先删除还是先创建pod . 通过maxSurge maxUnavailable2 个参数来控制。注意maxSurge maxUnavailable 不能同时设置为0 否则无法完成滚动更新。
下面这个图白色/黄色的表示 旧/新版本pod , 若replicas 设置为4. maxSurge maxUnavailable 各设置为1,最少经过4轮才能完成更新
创建deploy 资源
例子
[root@node01 chapter8]# VERSION=v1.0 envsubst < deployment-demo.yaml |kubectl apply -f -
deployment.apps/deployment-demo created
service/demoapp-deploy created
[root@node01 chapter8]# cat deployment-demo.yaml
# VERSION: demoapp version
# Maintainer: MageEdu <mage@magedu.com>
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-demo
spec:
replicas: 4
selector:
matchLabels:
app: demoapp
release: stable
template:
metadata:
labels:
app: demoapp
release: stable
spec:
containers:
- name: demoapp
image: ikubernetes/demoapp:${VERSION}
ports:
- containerPort: 80
name: http
---
apiVersion: v1
kind: Service
metadata:
name: demoapp-deploy
spec:
selector:
app: demoapp
release: stable
ports:
- name: http
port: 80
targetPort: 80
[root@node01 chapter8]#
查看deploy 资源
查看创建deployment
[root@node01 chapter8]# kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-demo 4/4 4 4 2m demoapp ikubernetes/demoapp:v1.0 app=demoapp,release=stable
up-to-date 表示的是 最新版本的pod
查看deployment 创建的rs
[root@node01 chapter8]# kubectl describe deploy/deployment-demo
RollingUpdateStrategy: 25% max unavailable, 25% max surg
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set deployment-demo-fb544c5d8 to 4
通过describe 可以查到 对应的rs
[root@node01 chapter8]# kubectl get rs/deployment-demo-fb544c5d8
NAME DESIRED CURRENT READY AGE
deployment-demo-fb544c5d8 4 4 4 13m
[root@node01 chapter8]#
deployment 类型控制器创建的pod 名字有特殊意义
如下有3段
[root@node01 chapter8]# kubectl get po
NAME READY STATUS RESTARTS AGE
deployment-demo-fb544c5d8-897ww 1/1 Running 0 23m
deployment-demo-fb544c5d8-dpvl8 1/1 Running 0 23m
deployment-demo-fb544c5d8-l44fc 1/1 Running 0 23m
deployment-demo-fb544c5d8-rj498 1/1 Running 0 23m
deployment-demo 其实是 deploy名称 fb544c5d8 是rs 名称来自于模板的hash码 ,897ww 是随机数
更新deploy 资源
直接应用新版本的资源清单即可
[root@node01 chapter8]# VERSION=v1.1 envsubst < deployment-demo.yaml |kubectl delete -f -
deployment.apps "deployment-demo" deleted
service "demoapp-deploy" deleted
kubectl rollout
滚动命令
kubectl rollout SUBCOMMAND [options]
Valid resource types include:
* deployments
* daemonsets
* statefulsets
Available Commands:
history View rollout history
pause Mark the provided resource as paused
restart Restart a resource
resume Resume a paused resource
status Show the status of the rollout
undo Undo a previous rollout
查看更新状态
[root@node01 chapter8]# kubectl rollout status deployments/deployment-demo
deployment "deployment-demo" successfully rolled out
查看历史版本
[root@node01 chapter8]# kubectl rollout history deployments/deployment-demo
deployment.apps/deployment-demo
REVISION CHANGE-CAUSE
1 <none>
2 <none>
查看完整的升级过程
[root@node01 chapter8]# VERSION=v1.2 envsubst < deployment-demo.yaml |kubectl apply -f - && kubectl rollout status deployments/deployment-demo
deployment.apps/deployment-demo configured
service/demoapp-deploy unchanged
Waiting for deployment "deployment-demo" rollout to finish: 0 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 1 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 2 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 2 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 2 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 3 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 3 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 3 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 3 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 3 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "deployment-demo" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "deployment-demo" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "deployment-demo" rollout to finish: 3 of 4 updated replicas are available...
deployment "deployment-demo" successfully rolled out
回滚
[root@node01 chapter8]# kubectl rollout history deploy/deployment-demo
deployment.apps/deployment-demo
REVISION CHANGE-CAUSE
1 <none>
2 <none>
3 <none>
当前版本是1.2
[root@node01 chapter8]# kubectl get svc/demoapp-deploy -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
demoapp-deploy ClusterIP 10.100.246.250 <none> 80/TCP 66m app=demoapp,release=stable
[root@node01 chapter8]# curl 10.100.246.250
iKubernetes demoapp v1.2 !! ClientIP: 10.244.1.1, ServerName: deployment-demo-77d46c4794-glvts, ServerIP: 10.244.1.40!
[root@node01 chapter8]#
由于版本是号是递进的,所以越来越大,4版本其实就是之前的2版本
[root@node01 chapter8]# kubectl rollout undo deployments/deployment-demo
deployment.apps/deployment-demo rolled back
[root@node01 chapter8]# kubectl rollout history deploy/deployment-demo
deployment.apps/deployment-demo
REVISION CHANGE-CAUSE
1 <none>
3 <none>
4 <none>
验证结果 现在是1.1 版本
[root@node01 chapter8]# curl 10.100.246.250
iKubernetes demoapp v1.1 !! ClientIP: 10.244.1.1, ServerName: deployment-demo-867c7d9d55-ffwbr, ServerIP: 10.244.1.41!
如果再次执行 kubectl rollout history deploy/deployment-demo 那么就会 实现2个版本内一直切换,而不是最开始的上上次的那个第1个版本(1.0)
[root@node01 chapter8]# kubectl rollout history deploy/deployment-demo
deployment.apps/deployment-demo
REVISION CHANGE-CAUSE
1 <none>
4 <none>
5 <none>
[root@node01 chapter8]# curl 10.100.246.250
iKubernetes demoapp v1.2 !! ClientIP: 10.244.1.0, ServerName: deployment-demo-77d46c4794-qx9tg, ServerIP: 10.244.3.58!
想要回到指定的版本 得用–to-revision
kubectl rollout undo --help
# Roll back to daemonset revision 3
kubectl rollout undo daemonset/abc --to-revision=3
模拟金丝雀发布
金丝雀发布 也是灰度发布 ,是滚动更新策略的一种
当前是1.1版本
[root@node01 chapter8]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deployment-demo-fb544c5d8-b7thl 1/1 Running 0 112s
deployment-demo-fb544c5d8-dfcj7 1/1 Running 0 111s
deployment-demo-fb544c5d8-gsvq9 1/1 Running 0 110s
deployment-demo-fb544c5d8-td5pc 1/1 Running 0 112s
pod-11729 1/1 Running 0 6h20m
rs-blue-gdwp7 1/1 Running 1 5h34m
rs-blue-qz572 1/1 Running 0 5h34m
rs-gree-vbvzz 1/1 Running 0 5h21m
rs-gree-zm8gx 1/1 Running 0 5h21m
[root@node01 chapter8]# curl 10.100.246.250
iKubernetes demoapp v1.0 !! ClientIP: 10.244.1.0, ServerName: deployment-demo-fb544c5d8-gsvq9, ServerIP: 10.244.3.61!
模拟金丝雀发布 升级1.1
[root@node01 chapter8]# VERSION=v1.1 envsubst < deployment-demo.yaml |kubectl apply -f - && kubectl rollout pause deployments/deployment-demo
deployment.apps/deployment-demo configured
service/demoapp-deploy unchanged
deployment.apps/deployment-demo paused
[root@node01 chapter8]#
这里发现 ,处于滚动更新的第一步 ,删除一个旧pod (fb544c5d8-dfcj7) , 添加2个新pod (867c7d9d55)
[root@node01 chapter8]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deployment-demo-867c7d9d55-8bpkm 1/1 Running 0 63s
deployment-demo-867c7d9d55-x2kxf 1/1 Running 0 63s
deployment-demo-fb544c5d8-b7thl 1/1 Running 0 3m41s
deployment-demo-fb544c5d8-dfcj7 1/1 Running 0 3m40s
deployment-demo-fb544c5d8-td5pc 1/1 Running 0 3m41s
验证多个版本并存, 负比例大概是3:2
[root@node01 chapter8]# curl 10.100.246.250
iKubernetes demoapp v1.1 !! ClientIP: 10.244.1.0, ServerName: deployment-demo-867c7d9d55-x2kxf, ServerIP: 10.244.2.46!
[root@node01 chapter8]# curl 10.100.246.250
iKubernetes demoapp v1.0 !! ClientIP: 10.244.1.1, ServerName: deployment-demo-fb544c5d8-td5pc, ServerIP: 10.244.1.46!
就绪滚动就用resume
[root@node01 chapter8]# kubectl rollout resume deployments/deployment-demo
滚动策略示例
因为默认值是25% , 当pod 过多时,可能波及范围太广,所以可以自定义
deploy 清单
[root@node01 chapter8]# cat deployment-demo-with-strategy.yaml
# VERSION: demoapp version
# Maintainer: MageEdu <mage@magedu.com>
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-demo-with-strategy
spec:
replicas: 4
selector:
matchLabels:
app: demoapp
release: stable
env: dev
template:
metadata:
labels:
app: demoapp
release: stable
env: dev
spec:
containers:
- name: demoapp
image: ikubernetes/demoapp:${VERSION}
ports:
- containerPort: 80
name: http
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
[root@node01 chapter8]#
[root@node01 chapter8]# VERSION=v1.0 envsubst < deployment-demo-with-strategy.yaml |kubectl apply -f -
deployment.apps/deployment-demo-with-strategy created
策略是先减后加,一共4步完成滚动更新,每次先删除一个旧的再新增一个。
[root@node01 chapter8]# VERSION=v1.1 envsubst < deployment-demo-with-strategy.yaml |kubectl apply -f - && kubectl rollout status deploy/deployment-demo-with-strategy
deployment.apps/deployment-demo-with-strategy configured
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 0 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 1 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 1 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 1 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 2 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 2 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 2 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 3 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 3 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 3 out of 4 new replicas have been updated...
Waiting for deployment "deployment-demo-with-strategy" rollout to finish: 3 of 4 updated replicas are available...
deployment "deployment-demo-with-strategy" successfully rolled out
DaemonSet
用于精确保证在集群上运行的工作负载有多少个实例,比如有10个节点,则在每个节点上只运行一个。也可以给节点打标签 ,让它只运行在特定节点上,每个节点只运行一个,所以replicas不用定义,根据标签选择器匹配。 主要是执行系统级任务。比如日志采集客户端、监控客户端。
DaemonSet 简称ds
比如 kube-flannel 、kube-proxy 在每个节点都会运行一个
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-flannel-ds 4 4 4 4 4 <none> 8d
kube-proxy 4 4 4 4 4 kubernetes.io/os=linux 8d
[root@node01 chapter8]# kubectl get po -n kube-system -o wide|grep flan
kube-flannel-ds-hb98t 1/1 Running 1 8d 192.168.2.3 node02 <none> <none>
kube-flannel-ds-lzh57 1/1 Running 1 8d 192.168.2.1 master01 <none> <none>
kube-flannel-ds-mng4k 1/1 Running 2 8d 192.168.2.4 node03 <none> <none>
kube-flannel-ds-zk8nf 1/1 Running 1 8d 192.168.2.2 node01 <none> <none>
ds清单字段
apiVersion: apps/v1 # API群组及版本
kind: DaemonSet # 资源类型特有标识
metadata:
name <string> # 资源名称,在作用域中要唯一
namespace <string> # 名称空间;DaemonSet资源隶属名称空间级别
spec:
minReadySeconds <integer> # Pod就绪后多少秒内任一容器无crash方可视为“就绪”
selector <object> # 标签选择器,必须匹配template字段中Pod模板中的标签
template <object> # Pod模板对象;
revisionHistoryLimit <integer> # 滚动更新历史记录数量,默认为10;
updateStrategy <Object> # 滚动更新策略
type <string> # 滚动更新类型,可用值有OnDelete和RollingUpdate;
rollingUpdate <Object> # 滚动更新参数,专用于RollingUpdate类型
maxUnavailable <string> # 更新期间可比期望的Pod数量缺少的数量或比例
RollingUpdate 是默认的策略,类似deploy的同名策略,但是不支持maxSugre, 因为ds类型的pod 只可能存在一个,且是系统资源, 只能允许先减少后加
Ondelete 是在相应节点的pod 资源删除后 重为建新版本,从而允许用户手动编排更新过程
eg:
[root@node01 chapter8]# cat daemonset-demo.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-demo
namespace: default
labels:
app: prometheus
component: node-exporter
spec:
selector:
matchLabels:
app: prometheus
component: node-exporter
template:
metadata:
name: prometheus-node-exporter
labels:
app: prometheus
component: node-exporter
spec:
containers:
- image: prom/node-exporter:v0.18.0
name: prometheus-node-exporter
ports:
- name: prom-node-exp
containerPort: 9100
hostPort: 9100
livenessProbe:
tcpSocket:
port: prom-node-exp
initialDelaySeconds: 3
readinessProbe:
httpGet:
path: '/metrics'
port: prom-node-exp
scheme: HTTP
initialDelaySeconds: 5
hostNetwork: true
hostPID: true
查看ds
注意 ,因为污点容忍度的关系, 所以主节点不会存在
[root@node01 chapter8]# kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset-demo 3 3 3 3 3 <none> 71s
[root@node01 chapter8]# kubectl describe ds/daemonset-demo
Name: daemonset-demo
Selector: app=prometheus,component=node-exporter
更新
验证滚动更新策略
[root@node01 chapter8]# kubectl set image ds/daemonset-demo prometheus-node-exporter=v0.18.1 && kubectl rollout status ds/daemonset-demo
job
对于rs、deploy、ds 都是 长久运行在后台的服务, 有些时候需要执行单次任务 比如备份、批处理(任务是一个,但是需要单批次反复执行多次同个步骤才行, 比如找出你生命中最重要的五个人,每次删除5个,执行n次 ,最后一个肯定是最重要的), 就应该用job.
job 什么时候用 什么时候启动就行
Job的配置规范
apiVersion: batch/v1 # API群组及版本
kind: Job # 资源类型特有标识
metadata:
name <string> # 资源名称,在作用域中要唯一
namespace <string> # 名称空间;Job资源隶属名称空间级别
spec:
selector <object> # 标签选择器,必须匹配template字段中Pod模板中的标签
template <object> # Pod模板对象
completions <integer> # 期望的成功完成的作业次数(一个pod执行一次,一个作业执行多少次),成功运行结束的Pod数量
ttlSecondsAfterFinished <integer> # 终止状态作业的生存时长,超期将被删除
parallelism <integer> # 作业的最大并行度,默认为1
backoffLimit <integer> # 将作业标记为Failed之前的重试次数,默认为6
activeDeadlineSeconds <integer> # 作业启动后可处于活动状态的时长
eg:
串行任务示例
[root@node01 chapter8]# cat job-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
spec:
template:
spec:
containers:
- name: myjob
image: alpine:3.11
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 60"]
restartPolicy: Never
completions: 2
ttlSecondsAfterFinished: 3600
backoffLimit: 3
activeDeadlineSeconds: 300
[root@node01 chapter8]# kubectl get po|grep job
job-demo-m4ddn 1/1 Running 0 18s
并行示例
apiVersion: batch/v1
kind: Job
metadata:
name: job-para-demo
spec:
template:
spec:
containers:
- name: myjob
image: alpine:3.11
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 60"]
restartPolicy: Never
completions: 12
parallelism: 2
ttlSecondsAfterFinished: 3600
backoffLimit: 3
activeDeadlineSeconds: 1200
验证结果: 最多出现2个pod
[root@node01 chapter8]# kubectl get po|grep job
job-demo-hpnjt 1/1 Running 0 6s
job-demo-m4ddn 0/1 Completed 0 67s
job-para-demo-7572g 1/1 Running 0 3s
job-para-demo-qvvql 1/1 Running 0 3s
[root@node01 chapter8]# kubectl get job
NAME COMPLETIONS DURATION AGE
job-demo 1/2 113s 113s
job-para-demo 0/12 49s 49s
[root@node01 chapter8]#
CronJob
cronjob 借助job 来完成周期性工作
CronJob的配置规范
apiVersion: batch/v1beta1 # API群组及版本
kind: CronJob # 资源类型特有标识
metadata:
name <string> # 资源名称,在作用域中要唯一
namespace <string> # 名称空间;CronJob资源隶属名称空间级别
spec:
jobTemplate <Object> # job作业模板,必选字段
metadata <object> # 模板元数据
spec <object> # 作业的期望状态
schedule <string> # 调度时间设定,必选字段
concurrencyPolicy <string> # 并发策略,可用值有Allow、Forbid和Replace。 指的是上一个job 没有执行完成时,下一个周期时间到了,新旧任务是否同时运行还是前后替代
failedJobsHistoryLimit <integer> # 失败作业的历史记录数,默认为1
successfulJobsHistoryLimit <integer> # 成功作业的历史记录数,默认为3, 不是为了回滚,只是为了查看
startingDeadlineSeconds <integer> # 因错过时间点而未执行的作业的可超期时长
suspend <boolean> # 是否挂起后续的作业,不影响当前作业,默认为false
concurrencyPolicy
示例
[root@node01 chapter8]# cat cronjob-demo.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cronjob-demo
namespace: default
spec:
schedule: "*/2 * * * *"
jobTemplate:
metadata:
labels:
controller: cronjob-demo
spec:
parallelism: 1
completions: 1
ttlSecondsAfterFinished: 600
backoffLimit: 3
activeDeadlineSeconds: 60
template:
spec:
containers:
- name: myjob
image: alpine
command:
- /bin/sh
- -c
- date; echo Hello from CronJob, sleep a while...; sleep 10
restartPolicy: OnFailure
startingDeadlineSeconds: 300
查看cronjob
[root@node01 chapter8]# kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob-demo */2 * * * * False 1 19s 53s
[root@node01 chapter8]# kubectl get po|grep cron
cronjob-demo-1640064600-x44lp 0/1 Completed 0 51s


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









