







文章目录
引用扩展
ubuntu@ubuntu-Lenovo:/work/python$ cat 1-引用-扩展.py
a = 100 #不可变类型
def test(num):
num += num
print(num)
test(a)
print(a)
#结果
ubuntu@ubuntu-Lenovo:/work/python$ python3 1-引用-扩展.py
200
100
#a = 100 #不可变类型
a = [100] #可变类型
def test(num):
num += num #num指向谁就直接修改里面的值
# num = num + num # num = [100] + [100] =>num = [100,100]意思是让num指向一个新的值
#,原来a的指向不变
print(num)
test(a)
print(a)
#结果:
ubuntu@ubuntu-Lenovo:/work/python$ python3 1-引用-扩展.py
[100, 100]
[100, 100]
#a = 100 #不可变类型
a = [100] #可变类型
def test(num):
# num += num #num指向谁就直接修改里面的值
num = num + num # num = [100] + [100] =>num = [100,100]意思是让num指向一个新的值
#,原来a的指向不变
print(num)
test(a)
print(a)
#结果:
ubuntu@ubuntu-Lenovo:/work/python$ python3 1-引用-扩展.py
[100, 100]
[100]
变量交换
a = 1
b = 2
#方法一
tmp = 0
tmp = a
a = b
b = tmp
#方法二
a = a+b
b = a-b
a = a-b
#方法三
a,b = b,a
字符串的常用操作
文件操作
Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。
open() 方法
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
file object = open(file_name [, access_mode][, buffering])
各个参数的细节如下:
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读®。
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
不同模式打开文件的完全列表:
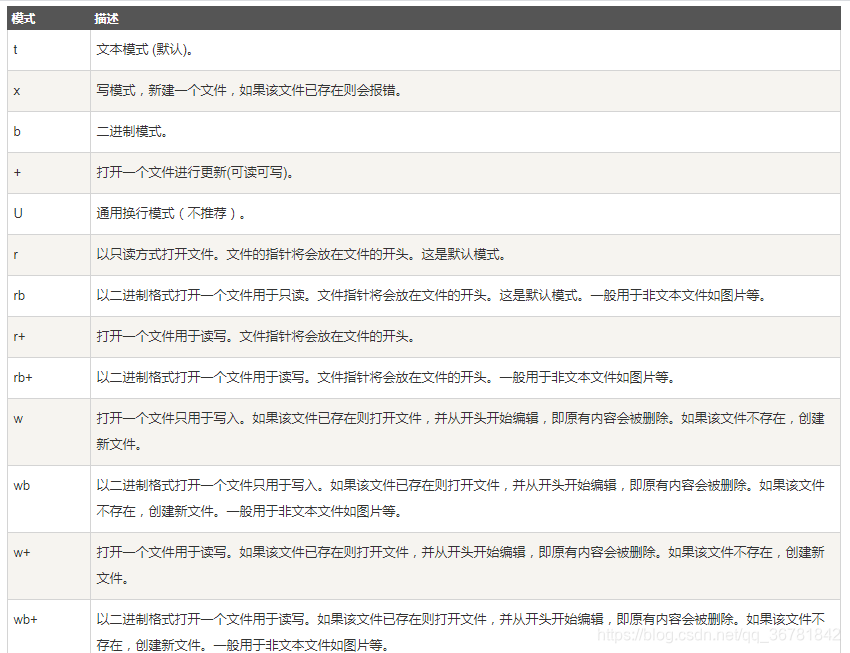
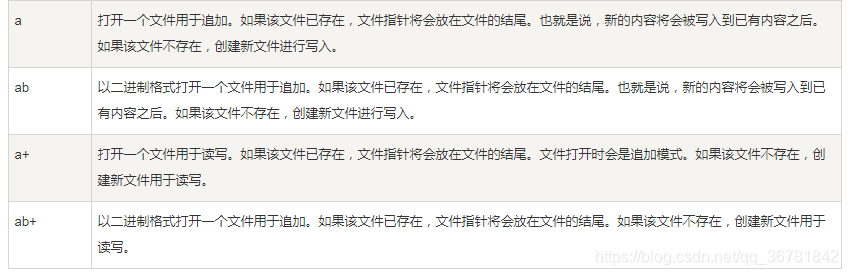
In [30]: f = open("test.txt" , "w")#以写的方式打开文件,文件不存在则创建,文件存在则覆盖原来内容
In [31]: ls -l test.txt
-rw-rw-r-- 1 ubuntu ubuntu 0 六月 13 13:42 test.txt
close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:
fileObject.close()
In [32]: f.close()
In [33]:
def write_test():
f = open("./test.txt","w")#打开文件
f.write("hello world") #写入字符串
f.close() #关闭文件
write_test()
def read_test():
chr = 0
f = open("test.txt","r")
while chr != '':#判断读到的数据不是''空,认为文件中还有数据,为空结束
chr = f.read(1)#读一个字符
print(chr)
f.close()#关闭文件
print("read end")
read_test()
#结果:
ubuntu@ubuntu-Lenovo:/work/python$ python3 5-write.py
ubuntu@ubuntu-Lenovo:/work/python$ python3 4-read.py
h
e
l
l
o
w
o
r
l
d
read end
文件copy
ubuntu@ubuntu-Lenovo:/work/python/5-day$ cat test.txt
kdsafkhakjkjafjkdsahfkjabkj
------------------------------------
#获取要复制的文件名
old_file_name = input("请输入你要复制的文件名:")
#打开要复制的文件
f_read = open(old_file_name,"r")
#获得新的文件名称
position = old_file_name.find(".")
new_file_name = old_file_name[0:position] + "复件" + old_file_name[position:]
#创建新的文件
f_write = open(new_file_name,"w")
#复制内容
#方法一:
#content = f_read.read()
#f_write.write(content)
#方法二:
#复制内容,为了解决大文件,小内存导致的卡死问题,一次性不读文件的全部
while True:
content = f_read.read(1024)
if len(content) == 0
break
f_write.write(content)
#关闭文件
f_read.close()
f_write.close()
#结果:
ubuntu@ubuntu-Lenovo:/work/python/5-day$ python3 6-file-copy.py
请输入你要复制的文件名:test.txt
ubuntu@ubuntu-Lenovo:/work/python/5-day$ ls
6-file-copy.py 7-big-file-copy.py 8-readline.py 9-文件位置.py test.txt test复件.txt
----------------------------------------
ubuntu@ubuntu-Lenovo:/work/python/5-day$ cat test复件.txt
kdsafkhakjkjafjkdsahfkjabkj
readline() 方法
概述
readline() 方法用于从文件读取整行,包括 “\n” 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 “\n” 字符。
语法
readline() 方法语法如下:
fileObject.readline(size)
参数
size – 从文件中读取的字节数。
返回值
返回从字符串中读取的字节。
In [2]: f = open("6-file-copy.py")
In [3]: f.rea
f.read f.readable f.readline f.readlines
In [3]: f.readl
f.readline f.readlines
In [3]: f.readline(2)#指定读出2个字节
Out[3]: '#获'
In [4]: f.readline(2)
Out[4]: '取要'
In [5]: f.readline(2)
Out[5]: '复制'
In [6]: f.readline(2)
Out[6]: '的文'
In [15]: f = open("6-file-copy.py")
In [16]: f.readline() #读取一行
Out[16]: '#获取要复制的文件名\n'
In [17]: f.readline()
Out[17]: 'old_file_name = input("请输入你要复制的文件名:")\n'
In [18]: f.readline()
Out[18]: '#打开要复制的文件\n'
readlines()方法
概述
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for… in … 结构进行处理。
如果碰到结束符 EOF 则返回空字符串。
语法
readlines() 方法语法如下:
fileObject.readlines( );
参数
无。
返回值
返回列表,包含所有的行
例子:
In [20]: f = open("6-file-copy.py")
In [21]: f.readlines() #读出文件中所有内容,以每一行为一个字符串保存到列表中
Out[21]:
['#获取要复制的文件名\n',
'old_file_name = input("请输入你要复制的文件名:")\n',
'#打开要复制的文件\n',
'f_read = open(old_file_name,"r")\n',
'\n',
'#获得新的文件名称\n',
'position = old_file_name.find(".")\n',
'new_file_name = old_file_name[0:position] + "复件" + old_file_name[position:] \n',
'\n',
'#创建新的文件\n',
'f_write = open(new_file_name,"w")\n',
'\n',
'#复制内容\n',
'content = f_read.read()\n',
'f_write.write(content)\n',
'\n',
'#关闭文件\n',
'f_read.close()\n',
'f_write.close()\n',
'\n',
'\n',
'\n',
'\n']
举栗子:
f = open("6-file-copy.py")
list = f.readlines()
print(list)
f.close
print("*"*100)
f = open("6-file-copy.py")
while True:
str = f.readline()
print(str,end='')
if str == '':
break
f.close
#结果:
ubuntu@ubuntu-Lenovo:/work/python/5-day$ python3 8-readline.py
['#获取要复制的文件名\n', 'old_file_name = input("请输入你要复制的文件名:")\n', '#打开要复制的文件\n', 'f_read = open(old_file_name,"r")\n', '\n', '#获得新的文件名称\n', 'position = old_file_name.find(".")\n', 'new_file_name = old_file_name[0:position] + "复件" + old_file_name[position:] \n', '\n', '#创建新的文件\n', 'f_write = open(new_file_name,"w")\n', '\n', '#复制内容\n', 'content = f_read.read()\n', 'f_write.write(content)\n', '\n', '#关闭文件\n', 'f_read.close()\n', 'f_write.close()\n', '\n', '\n', '\n', '\n']
****************************************************************************************************
#获取要复制的文件名
old_file_name = input("请输入你要复制的文件名:")
#打开要复制的文件
f_read = open(old_file_name,"r")
#获得新的文件名称
position = old_file_name.find(".")
new_file_name = old_file_name[0:position] + "复件" + old_file_name[position:]
#创建新的文件
f_write = open(new_file_name,"w")
#复制内容
content = f_read.read()
f_write.write(content)
#关闭文件
f_read.close()
f_write.close()
seek()方法
概述
seek() 方法用于移动文件读取指针到指定位置。
语法
seek() 方法语法如下:
fileObject.seek(offset[, whence])
参数
offset – 开始的偏移量,也就是代表需要移动偏移的字节数
whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
返回值
如果操作成功,则返回新的文件位置,如果操作失败,则函数返回 -1。
例子
f = open("test.txt",'r+')
str = f.read(1)
print(str)
f.seek(0,0) #seek(offset,position) #position: 0 代表文件开头,1 代表当前位置,2 代表文件结尾
str = f.read(1)
print(str)
f.write("hahahhahahha")
f.seek(0,0)
str = f.read()
print(str)
#结果:
ubuntu@ubuntu-Lenovo:/work/python/5-day$ python3 9-文件位置.py
k
k
kdsafkhakjkjafjkdsahfkjabkj
hahahhahahhahahahhahahhahahahhahahhahahahhahahha
模块
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
模块可以是自己定义,也可以是使用python自带的模块。
下例是个简单的模块 support.py:
support.py 模块:
def print_func( par ):
print "Hello : ", par
return
import 语句
模块的引入
模块定义好后,我们可以使用 import 语句来引入模块,语法如下:
import module1[, module2[,... moduleN]]
比如要引用模块 math,就可以在文件最开始的地方用 import math 来引入。在调用 math 模块中的函数时,必须这样引用:
模块名.函数名
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support.py,需要把命令放在脚本的顶端:
test.py 文件代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 导入模块
import support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob")
以上实例输出结果:
Hello : Runoob
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
OS 文件/目录方法
os 模块提供了非常丰富的方法用来处理文件和目录。常用的方法如下表所示:
https://www.runoob.com/python/os-file-methods.html
例子:批量修改文件名
import os
floder_name = input("请输入要修改的文件夹名称:")
#获取文件夹内所有文件名
file_names = os.listdir(floder_name)
'''
#方法一:修改文件名
#进入要修改的文件夹内
os.chdir(floder_name)
#找出每一个文件
for name in file_names:
j = 0
#print(name)
for i in name:
if i == '.':
break
j += 1
new_name = name[:j] + "-wql"+ name[j:]
print(new_name)
os.rename(name,new_name)
'''
#方法二:
for name in file_names:
old_name = "./" + floder_name + "/" + name
new_name = "./" + floder_name + "/" + "[new]-" + name
os.rename(old_name,new_name)
ubuntu@ubuntu16:/work/python/6-day$ ls
1-txt 2.txt 3.txt 4.txt 5.txt
#方法一:
ubuntu@ubuntu16:/work/python$ python3 modify_file_name.py
请输入要修改的文件夹名称:6-day
5-wql.txt
3-wql.txt
4-wql.txt
1-wql.txt
2-wql.txt
#方法二:
ubuntu@ubuntu16:/work/python$ python3 modify_file_name.py
请输入要修改的文件夹名称:6-day
ubuntu@ubuntu16:/work/python$ ls -l 6-day/
总用量 0
-rw-rw-r-- 1 ubuntu ubuntu 0 6月 16 21:53 [new]-1-wql.txt
-rw-rw-r-- 1 ubuntu ubuntu 0 6月 16 21:53 [new]-2-wql.txt
-rw-rw-r-- 1 ubuntu ubuntu 0 6月 16 21:53 [new]-3-wql.txt
-rw-rw-r-- 1 ubuntu ubuntu 0 6月 16 21:53 [new]-4-wql.txt
-rw-rw-r-- 1 ubuntu ubuntu 0 6月 16 21:53 [new]-5-wql.txt



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











