




 本文介绍了Spark与MapReduce的速度差异,重点讲解了Spark的四种运行模式:Local、Standalone、Yarn和Mesos。此外,文章深入探讨了Spark的RDD核心概念,包括其定义、特性以及需要注意的问题。还详细阐述了Spark的算子分类,如Transformation和Action,并提及持久化算子如cache和persist的重要性和使用注意事项。最后,文章提到了Spark集群搭建的基本步骤和Spark Pi任务的提交方法。
本文介绍了Spark与MapReduce的速度差异,重点讲解了Spark的四种运行模式:Local、Standalone、Yarn和Mesos。此外,文章深入探讨了Spark的RDD核心概念,包括其定义、特性以及需要注意的问题。还详细阐述了Spark的算子分类,如Transformation和Action,并提及持久化算子如cache和persist的重要性和使用注意事项。最后,文章提到了Spark集群搭建的基本步骤和Spark Pi任务的提交方法。
1.Spark & MR相对速度快的原因?(以及两者的比较)
都是分布式计算框架,
Spark基于内存,MR基于磁盘(HDFS)。
Spark处理数据的能力一般是MR的十倍以上,
Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。
MR中只有map,reduce和join,而Spark中有各种场景的算子
2.完成Spark java版本WordCount & Scala版本WordCount 编写,默写Scala版本。
val conf = new SparkConf().setAppName("wc").setMaster("local")
//SparkContext是通往spark集群的唯一通道
val sc = new SparkContext(conf)
sc.textFile("./words").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).foreach(println)
sc.stop()
3.Spark的运行模式有哪些?
Ø Local
多用于本地测试,如在eclipse,idea中写程序测试等。
Ø Standalone
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Ø Yarn
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn。
Ø Mesos(国外用的多)
资源调度框架。
4.Spark核心RDD
1).什么是RDD?
弹式分布数据集
2).RDD的五大特性?
1.RDD是由一系列的partition组成的
2.RDD之间具有依赖关系
3.RDD作用在partition是上
4.partition作用在具有(k,v)格式的数据集
5.partition对外提供最佳计算位置,利于数据本地化的处理
3).Spark RDD需要注意的问题
1.textFile方法底层封装的是读取方法和MR读取文件的方式一样,读取文件之前先split,默认split大小是一个block大小。
2.RDD****实际上不存储数据,这里方便理解,暂时理解为存储数据。
3.什么是K,V格式的RDD?
Ø 如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。
4. 哪里体现RDD的弹性(容错)?
Ø partition数量,可多可少,体现了RDD的弹性。
Ø RDD之间具有依赖关系,可以基于上一个RDD重新计算出RDD。
5.哪里体现RDD的分布式?
Ø RDD是由Partition组成,partition是分布在不同节点上的。
5.Spark 算子分为哪几类?
1.Transformation:懒执行的,需要Action触发才能执行
map
将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。
特点:输入一条,输出一条数据。
flatmap
先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
fliter
过滤符合条件的记录数,true保留,false过滤掉。
reduceBykey
将相同的Key根据相应的逻辑进行处理。
sortByKey/sortBy
作用在K,V格式的RDD上,对key进行升序或者降序排序
sample
随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。
2.Action:行动算子,触发Transformation类算子执行,有一个Action算子就有一个job
foreach
循环遍历数据集中的每个元素,运行相应的逻辑。
count
返回数据集中的元素数。会在结果计算完成后回收到Driver端。
collecrt
将计算结果回收到Driver端。
first
first=take(1),返回数据集中的第一个元素。
take
返回一个包含数据集前n个元素的集合。
3.持久化算子
cache
默认将数据存放到 内存中,懒执行
def cache(): this.type = persist()
persist
可以指定持久化的级别。
最常用的是MEMORY_ONLY和MEMORY_AND_DISK。
”_2”表示有副本数。尽量避免使用_2和DISK_ONLY级别
cache和persist的 注意点
1.都是懒执行,需要action触发执行,最小单位是partition
2.对一个RDD进行cache或者persist之后,下次直接使用这个变量,就是使用持久化的数据
3.如果使用第二种方式,不能紧跟action算子
chackpoint
与persist(StorageLevel.DISK_ONLY)的区别
1.cache和persist之后的数据当application执行完成之后会清空,checkpoint的数据不会清空和
2.chackpoint还可以存储元数据,用在RDD的持久化时不多,还可以切断RDD之间的依赖关系
6.Spark代码执行的流程?
a.SparkConf
b.SparkContext
c.创建RDD
d.对RDD使用transformation算子转换
e.对RDD使用action算子触发执行
f.sc.stop()
7.掌握今天算子代码编写
//0.1-》随机抽样比例为0.1 (抽取的数据量是在10%左右) //指定seed,执行结果不变
val result: RDD[String] = lines.sample(true,0.1,10L)
result.foreach(println)
// val words = lines.flatMap(line => {line.split(" ")})
// val pairWords = words.map(one => {(one,1)})
// val reduceResult: RDD[(String, Int)] = pairWords.reduceByKey((v1: Int, v2: Int) => {v1 + v2})
//排序(默认升序,加false降序)
//reduceResult.sortBy(tp =>{tp._2},false).foreach(println)
//通过sortByKey()排序
//拿到二元组,进行翻转,排序后再翻转就好了
// val value: RDD[(Int, String)] = reduceResult.map(tp =>{tp.swap})
// val result: RDD[(Int, String)] = value.sortByKey(false)//默认升序
// val lastValue = result.map(tp =>{tp.swap})
// lastValue.foreach(println)
/**
* filter
* 过滤符合条件的记录数,true保留,false过滤掉。
*/
// val rdd1 = lines.flatMap(_.split(" "))
// rdd1.filter("hello".equals(_)).foreach(println)
/**
* flatMap
* 先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
* faltmap 一对多
*/
//lines.flatMap(_.split(" ")).foreach(println)
/**
* map
* 将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。
* 特点:输入一条,输出一条数据。
*/
//lines.map(line =>{
// line+"#"
// }).foreach(println(_))
//返回集合中的 前 5条数据
val values: Array[String] = lines.take(5)
values.foreach(println)
//返回集合中的第一条数据 first=take(1)
val str1: String = lines.first()
println(str1)
//collect将计算结果回收到Driver端。
val str: Array[String] = lines.collect()//结果放在driver中内存中
str.foreach(println)
//count返回数据集中的元素数。会在结果计算完成后回收到Driver端
val l: Long = lines.count() //放在driver中内存中
println(l)
8.Spark 持久化算子有哪些?各自的特点是什么?需要注意的问题?
cache
默认将数据存放到 内存中,懒执行
def cache(): this.type = persist()
persist
可以指定持久化的级别。
最常用的是MEMORY_ONLY和MEMORY_AND_DISK。
”_2”表示有副本数。尽量避免使用_2和DISK_ONLY级别
cache和persist的 注意点
1.都是懒执行,需要action触发执行,最小单位是partition
2.对一个RDD进行cache或者persist之后,下次直接使用这个变量,就是使用持久化的数据
3.如果使用第二种方式,不能紧跟action算子
chackpoint
与persist(StorageLevel.DISK_ONLY)的区别
1. cache和persist之后的数据当application执行完成之后会清空,checkpoint的数据不会清空和
2.chackpoint还可以存储元数据,用在RDD的持久化时不多,还可以切断RDD之间的依赖关系
当RDD的lineage某些逻辑非常复杂,还可以使用checkpoint对RDD进行持久化
不要经常对RDD使用checkpoint,这样会导致application执行缓慢
checkpoint执行流程
1.当spark执行完成之后,Spark框架会从后往前回溯,回溯,回溯找到chekpointRDD进行标记
2.回溯完成之后,Spark会重新启动Job,计算揣测查看pointRDD的数据吗,将数据放在指定的持久化目录中
3.切断RDD之间的依赖关系
优化:持久化之前最好先cache下
9.Spark集群搭建。
(以spark2.3.1为例)
1.配置jdk
jdk的版本要求是jdk8及以上
2.安装spark
1)解压spark
tar -zxvf spark-2.3.1-bin-hadoop2.6.tgz
2)更改下名字(太长了)
mv spark-2.3.1-bin-hadoop2.6 spark-2.3.1
3)在slaves中配置work节点
进入到conf目录下
cd conf
拷贝一份slaves.template
cp slaves.template slaves
编辑slaves
写入你的work节点
node2
node3
4)配置spark-env.sh
如下图所示
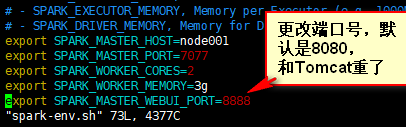
5)完成,验证
到spark的sbin下执行 (注意不要丢掉“./”)
./start-all.sh
通过jps可以可以看到node1为master,node2,node3是worker
在浏览器输入node1:8888可以访问到页面、
10.完成Spark pi 任务提交
在bin目录下:
./spark-submit --master spark://node001:8888 --class org.apache.spark.examples.SparkPi …/examples/jars/spark-examples_2.11-2.3.1.jar
即可提交运行
11.单词统计
/**
*
作业:使用sample抽样找出出现次数最多的单词,过滤掉统计剩余单词的个数,并由大到小排序。
*/
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test")
conf.setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("error")
val lines = sc.textFile("./data/wordsCount")
//随机抽样
val result: RDD[String] = lines.sample(true,0.3,10L)
//对随机抽样数据按降序排序
val value = result.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).sortBy(tp =>{tp._2},false)
//拿到出现最多的那条数据(tuple2格式)
val tuple = value.first()
//获取出现最多的单词
val maxVlaue = tuple._1
//过滤得到结果
lines.flatMap(_.split(" ")).filter(!maxVlaue.equals(_)).map((_, 1)).reduceByKey(_ + _).sortBy(tp =>{tp._2},false).foreach(println)
}

















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









