







基于GoogLeNetde的inceptionV3模型实现图像分类,其实inceptionV3模型已经被训练好了,可以直接拿来使用,就好比给了你一个黑盒子,告诉你这个黑盒子有什么功能,然后给你接口让你使用,我本人还是很不喜欢这种东西,但导师要求这么来干,就先这么实现吧。
首先,就是对于inceptionV3 数据集模型的获取;
可以运行程序的时候再下载(太慢了,动不动就不走了),我这里直接给出已经下载好的链接,可以直接下载,再存到对应的路径(C:\Users\.keras\models),可以直接通过我的百度网盘进行下载。链接:https://pan.baidu.com/s/1T7KWPaIH1VJPsldFszcivw
提取码:y777
完事以后你执行代码并产生这个的话,说明已经导入成功: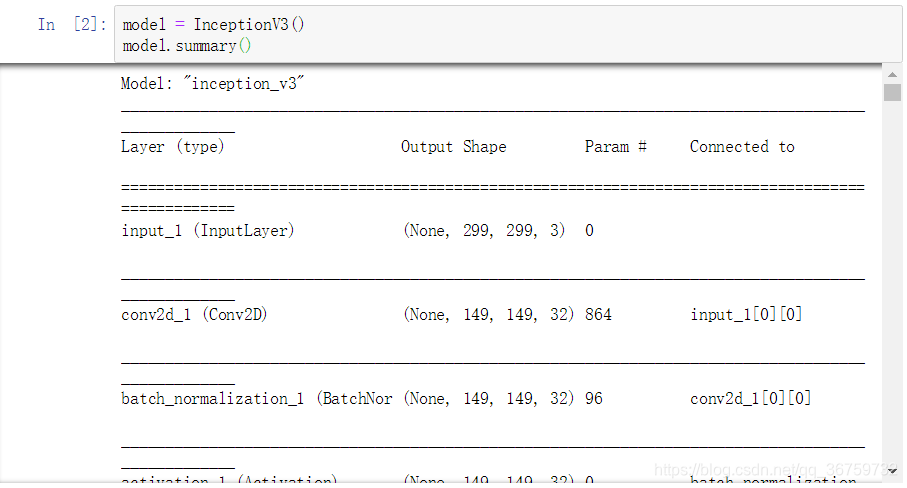
导入数据集以后,就要准备要识别的图像,我随便在网上下载了一个图片。

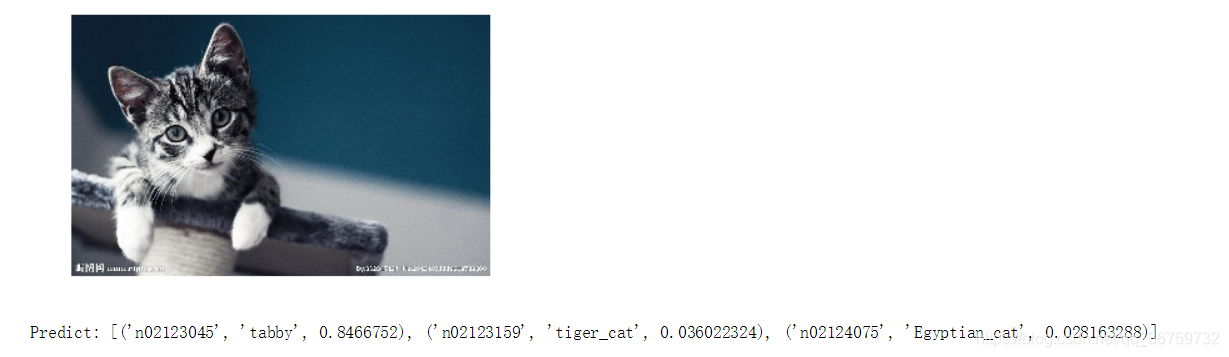
然后获取当前图片的路径存入image_path。如果有多张图片,可以通过for 循环来找到该文件夹下所有图片并依次识别。有很多需要注意的问题,最后了提一下,先识别图像吧。导入图片(299*299)以后,将其转化为矩阵形式,然后导入模型进行识别,最后输出图片和识别的结果(模型最后一层经过softmax变成概率形式)。
输出结果为概率最大的5个结果(降序)。
下面,全部代码在github上,链接:https://github.com/litongtong10067/CNN
最后给出识别结果:

可能出现的问题:地址识别出差,注意地址的写法( \\ 而不是 \ ,代码转义字符),想用 ' \ ' 也行,要注意写法(r'image_path'),可能显示图像出现的问题,都不难,要不就是地址问题,要不就是调用不正确,都不难,请自行解决!

















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









