







附录B GAN学习可能性
GAN到底能学到什么?这是一个很好的问题,但并没有一个显而易见的答案。
接下来,我们将以不使用过多数学术语的方式,对GAN所学习的内容进行直观的解释。让我们先从GAN不能学习什么开始吧。
B.1 GAN不会记忆训练数据
GAN不会学习记忆训练数据中的实例,包括任何实例中的具体部分。对于由人脸图像组成的训练数据,这意味着生成器不会记忆眼睛、耳朵、嘴唇或鼻子等元素。
另一方面,生成器不会直接看到训练数据。它所学习到的,只是来自鉴别器的反向传播误差反馈,而鉴别器本身只能做出图像真伪的二元判断。
其实,GAN学习的是训练数据中每个元素出现的可能性(likelihood)。
B.2 简单的例子
下图是一个非常小的、只有8幅图像的数据集。每幅图像也非常小,仅有3像素× 3像素。此外,像素只能是两个值中的一个,在这里表示为蓝色或白色。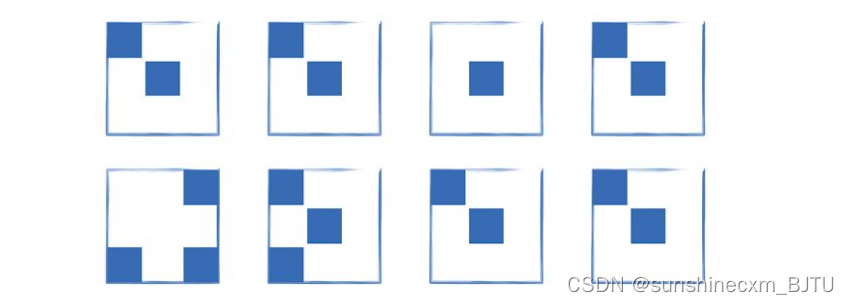
作为人类,如果我们被要求画出一幅图像,使它看起来属于这个数据集,我们可能会凭直觉把蓝色像素画在图像中心和左上角。我们也可能把蓝色像素画在左下角。
在这种直觉的背后,是对“一个像素有多大可能是蓝色”的理解。我们看到,大多数图像的中心像素是蓝色的。事实上,除了其中一幅图像之外,其他所有的图像都符合这一规律。许多图像的左上角也有一个蓝色像素。有几幅图像的左下角像素是蓝色。同时,有些位置,比如中上(中心像素上方)的像素,从来都不是蓝色的。
让我们看一下实际的计算过程。我们可以统计出每个像素点是蓝色的样本数。下面左图的矩阵中显示了这些统计。在8幅训练图像中,左上角的像素在6幅中都是蓝色的,而左下角是蓝色的只有2幅。中上的蓝色像素出现次数为0。因为中上的像素在任何一幅训练图像中都不是蓝色的。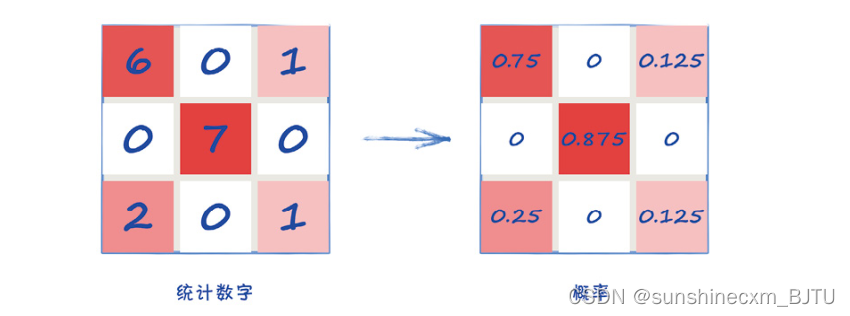
这些统计数字可以被转换成可能性,也被称为概率。转换过程只需要将每个数字除以可能出现的最大次数,这里是8。这些概率显示在上图右边的矩阵中。
右边的矩阵类似一个概率分布图。它显示了一幅3像素× 3像素的图像中,每个像素是蓝色的可能性。
B.3 从一个概率分布中生成图像
如果我们是一个生成器,我们可能会在决定一个像素是不是蓝色之前,先看看它的概率。比如,左上角的像素为蓝色的概率就相当高,达到0.75。而中上的像素是蓝色的概率是0,我们永远也不会将它涂成蓝色。
使用这个方法,我们可以生成24种不同的图像。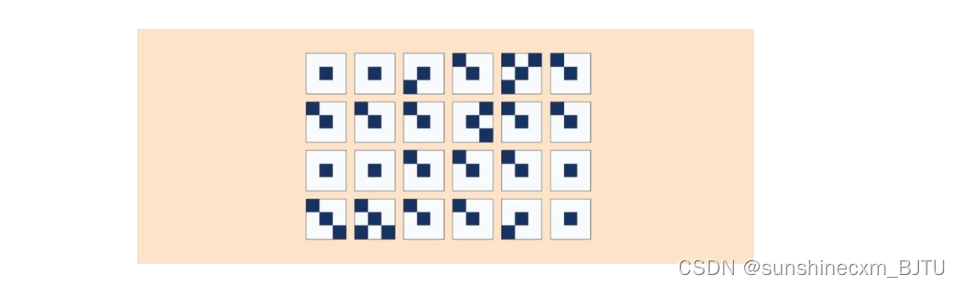
它们看起来都像来自训练数据集的图像。
从概率分布中生成图像的关键在于,我们并非从训练数据中复制整幅图像或者某个部分,而是按照训练图像中各元素出现的可能性生成图像。
B.4 为图像特征学习像素组合
在上面的简单例子中,我们只考虑了单个像素的可能性。对于MNIST数字或CelebA人脸图像这样更逼真的图像来说,其实是不够的。
让我们考虑一下人脸图像中的微笑表情。如果有些像素的嘴唇是红色的,那么我们需要附近的像素也是红色的。我们不能让附近的像素代表不同的笑容,比如紫色的嘴唇。这样的结果看起来会很乱、不真实。
这说明,生成器神经网络也会通过与相邻像素有关的方式,学习一个像素为某种颜色的可能性。 如果生成器生成一个红色像素,将其作为嘴唇的一部分,那么学习到的网络权重也会增加相邻像素是红色的机会。
下图用一个简单的生成器网络来解释这个想法。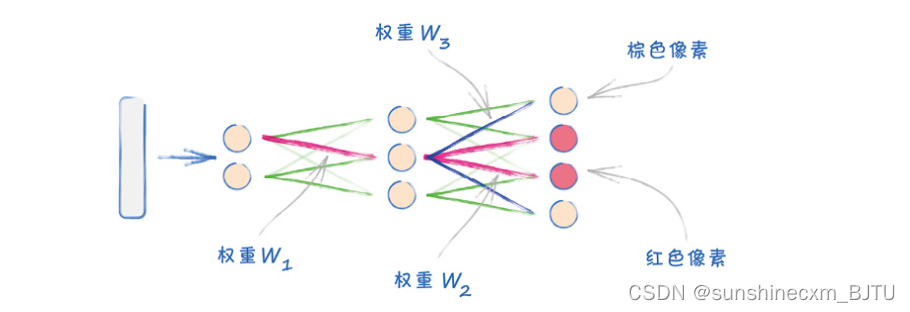
我们看到,较高的权重w1激活中间层的中间节点。从该节点输出的信号,通过较高权重的w2继续激活产生红色像素。同样被w1激活的节点,也通过权重较高的w3激活红色像素周围的皮肤色像素。
通过这种方式,权重共同学会了为嘴唇画成红色像素组合,同时将嘴唇周围的脸部画成非红色像素。
B.5 多模式以及模式崩溃
如果我们使用MNIST数据集进行训练,我们希望生成器能够生成所有的10个数字。这意味着它要学习所有10个数字的概率分布。
生成器所面对的挑战是同时学习多个概率分布来对应每一种图像。它可以通过学习正确的权重来实现。这样,不同的随机种子会激活网络的不同路径,从而对应一种概率分布。
这并不是一个简单的任务。这也正是GAN很难训练成功的原因。
当出现模式崩溃时,说明生成器只学会了一类图像的概率分布。

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









