







 本文详细介绍了如何使用朴素贝叶斯网络对邮件进行分类,从数据预处理、特征提取到模型构建,包括分词技巧、词汇表构建、模型公式详解以及生词处理方法。通过交叉验证评估模型性能,适用于实际邮件过滤应用。
本文详细介绍了如何使用朴素贝叶斯网络对邮件进行分类,从数据预处理、特征提取到模型构建,包括分词技巧、词汇表构建、模型公式详解以及生词处理方法。通过交叉验证评估模型性能,适用于实际邮件过滤应用。
朴素贝叶斯网络进行邮件分类
将以前做的邮件分类做个总结!
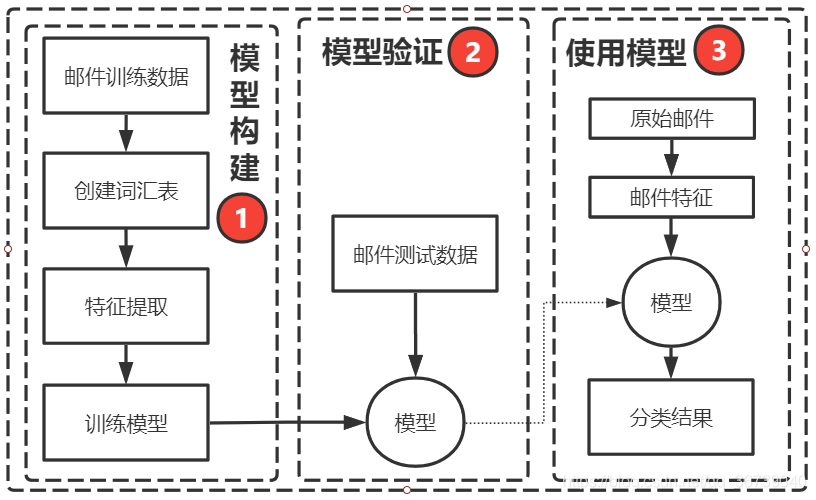
总体框架
-
下面我们将通过以下几个步骤,编写一个现实可用的垃圾邮件过滤器:
- 准备邮件数据;
- 创建词汇表;
- 特征提取;
- 训练模型;
- 模型验证;
-
使用模型。
分词与词汇表创建
-
删除可能是噪音的词
- 这一类词主要包括了副词、连词、语气助词、连词等,如常见的“在”、“的”、“而且”之类,其没有明确语义,对垃圾邮件过滤问题没有太大意义。 统一表示与词汇表
- 邮件体文本是不能被计算机所直接识别的,需要将其转换成计算机能够理解的形式;
- 一般形式是:[(‘您好’, 1) , (‘恭喜’, 0) , …, (‘谢谢’, 1) ], 前者是出现的词,后者是在对应邮件是否出现。
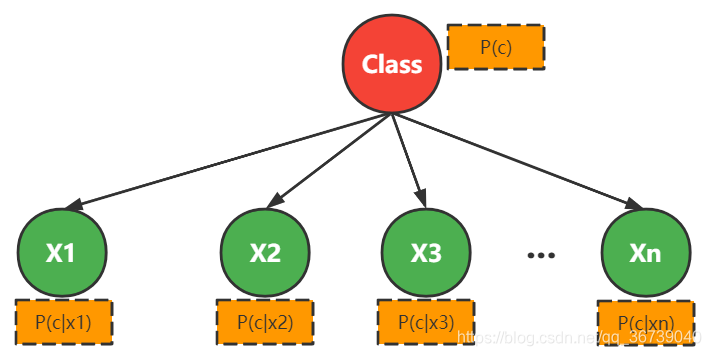
模型公式与其含义
样本: M封邮件,每份邮件被标记为垃圾邮件或者非垃圾邮件;
目标: 第 M+1封邮件来的时候,判断是否是垃圾邮件;
类别c: 垃圾邮件 c 1 c1 c1,非垃圾邮件 c 2 c2 c2
词汇表: 统计M封邮件中出现的所有单词,记单词数目为N,即形成词汇表。
将每个样本si向量化: 初始化N维向量
x
i
x_i
xi,若词
w
j
w_j
wj在
s
i
s_i
si中出现,则
x
i
j
=
1
x_{ij}=1
xij=1,否则,为0。从而得到1000个
N
N
N维向量
x
x
x。
P
(
c
∣
x
)
=
P
(
c
)
P
(
x
∣
c
)
P
(
x
)
=
P
(
c
)
P
(
x
)
∏
i
=
1
N
P
(
x
i
∣
c
)
P(c|x) = \frac{P(c)P(x|c)}{P(x)} = \frac{P(c)}{P(x)}\prod_{i=1}^N P(x_i|c)
P(c∣x)=P(x)P(c)P(x∣c)=P(x)P(c)i=1∏NP(xi∣c)
对于所有类别来说,
P
(
x
)
P(x)
P(x) 的值是一致的,所以使用一般直接计算:
c
=
a
r
g
m
a
x
c
i
∈
C
P
(
c
i
)
∏
i
=
1
N
P
(
x
i
∣
c
)
c = arg max_{c_i \in C } P(c_i) \prod_{i=1}^N P(x_i|c)
c=argmaxci∈CP(ci)i=1∏NP(xi∣c)
P
(
c
∣
x
i
)
=
m
a
x
c
i
∈
C
P
(
c
i
)
∏
i
=
1
N
P
(
x
i
∣
c
)
P(c|x_i) = max_{c_i \in C } P(c_i) \prod_{i=1}^N P(x_i|c)
P(c∣xi)=maxci∈CP(ci)i=1∏NP(xi∣c)
具有最大概率的作为 样本
x
i
x_i
xi 的类别
P
(
c
i
)
=
∣
D
c
i
∣
+
1
∣
D
∣
+
C
i
P(c_i) = \frac{|D_{c_i}| + 1}{ |D| + C_i}
P(ci)=∣D∣+Ci∣Dci∣+1
P
(
x
i
∣
c
i
)
=
∣
D
c
i
,
x
i
∣
+
1
∣
D
c
i
∣
+
S
i
P(x_i | c_i) = \frac{|D_{c_i,x_i}| + 1}{ |D_{c_i}| + S_i}
P(xi∣ci)=∣Dci∣+Si∣Dci,xi∣+1
∣ D ∣ |D| ∣D∣:样本总数目(在这儿就是邮件数目)
∣ D c i ∣ |D_{c_i}| ∣Dci∣:第 i 个类别的样本数目Or 类别为 c i c_i ci的样本数目(比如:垃圾邮件的数目,正常邮件的数目)
∣ D c i , x i ∣ |D_{c_i, x_i}| ∣Dci,xi∣:属性值为 x i x_i xi ,类别为 c i c_i ci的样本数目
C C C:数据集中可能的决策属性(类属性)。(比如:邮件分类是个二分类任务,这儿就是 {0,1})
C n C_n Cn:数据集中可能的决策属性(类属性)的取值数目。(比如:邮件分类是个二分类任务,这儿的取值就是 2 了)
S i S_i Si:第 i 个属性可能的取值数,比如:某个词(属性)存在则取值1,不存在则为0,所以该属性的取值为[0, 1]
-
遇到生词怎么办?
- + 1 + 1 +1 的目的是进行平滑(常常使用拉普拉斯修正):这是由于 ∣ D c i ∣ |D_{c_i}| ∣Dci∣ 或者 ∣ D x i , c i ∣ |D_{x_i, c_i}| ∣Dxi,ci∣ 的取值可能为 0,而计算的时候是累积 ∏ \prod ∏ 计算。 如何判定该分类器的正确率?
- 交叉验证
相关资料

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









