



1、项目介绍
Spark微博舆情分析系统 情感分析 爬虫 Hadoop和Hive 贴吧数据 双平台 讲解视频 大数据 毕业设计
技术栈:
论坛数据(百度、微博)
Python语言、requests爬虫技术、 Django框架、SnowNLP 情感分析、MySQL数据库、Echarts可视化
Hadoop、 spark、hive 大数据技术、虚拟机
2、项目界面
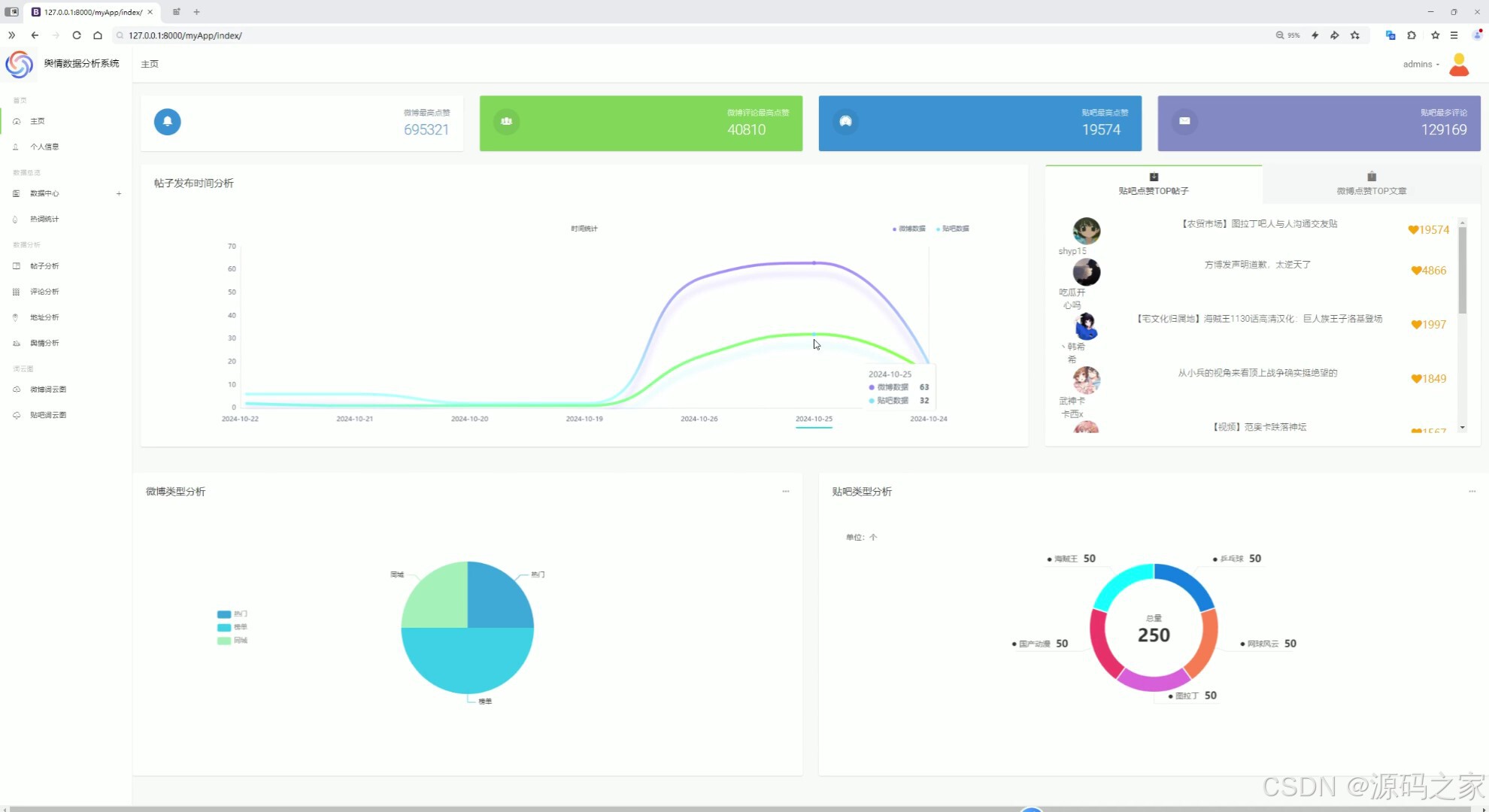
(1)首页–数据概况
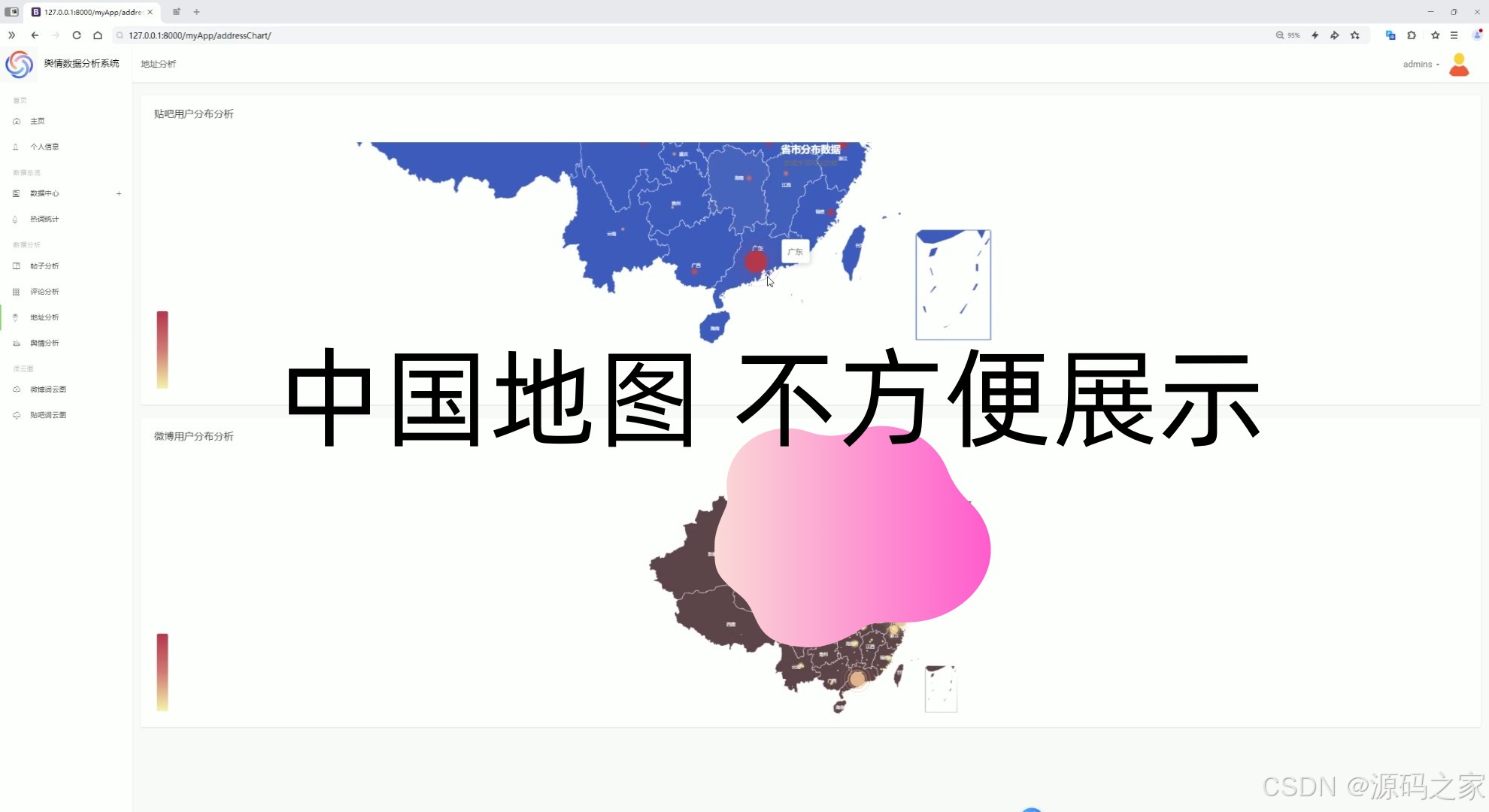
(2)贴吧用户地址分布分析、微博用户地址分布分析(中国地图)
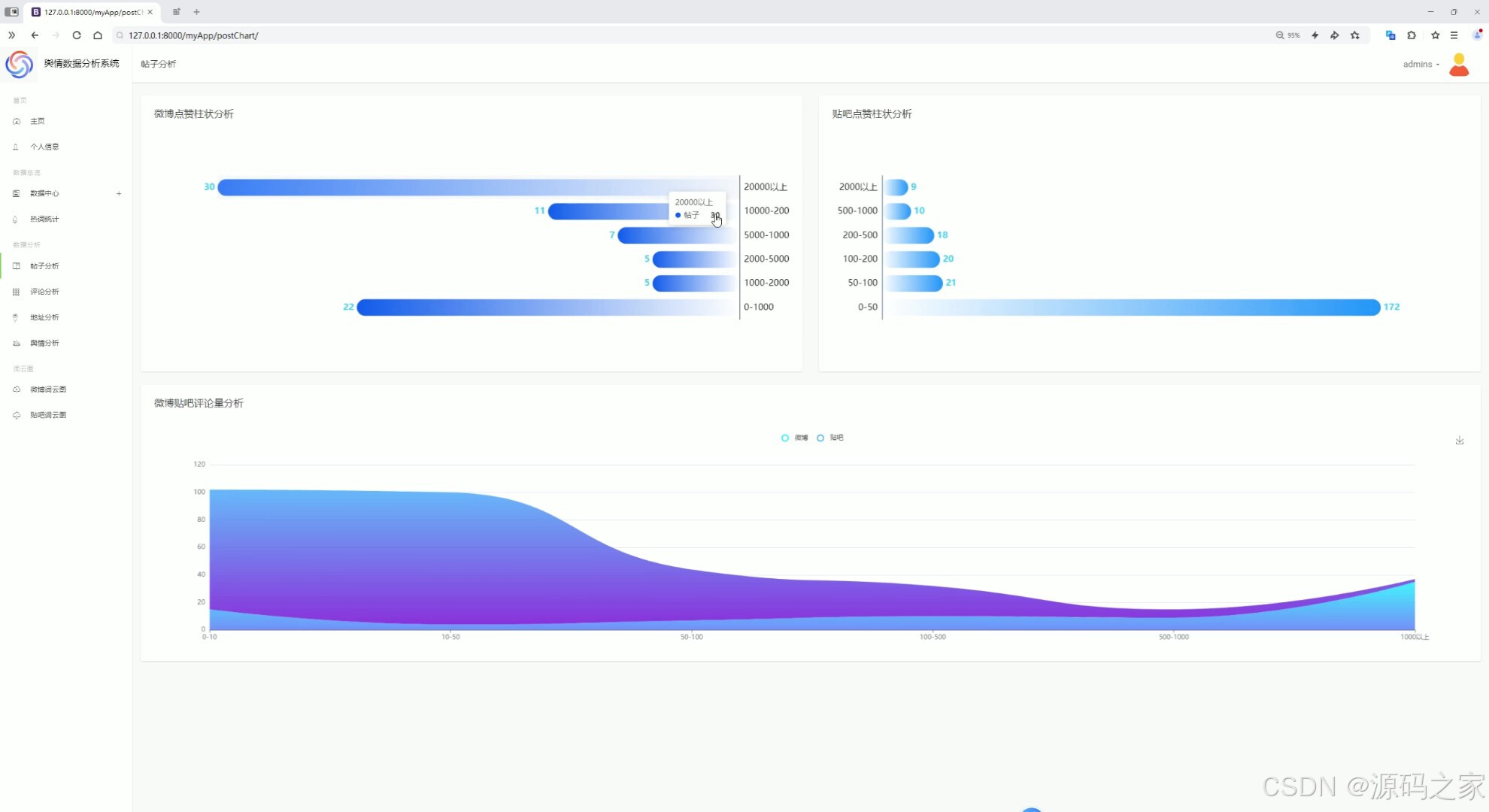
(3)帖子分析
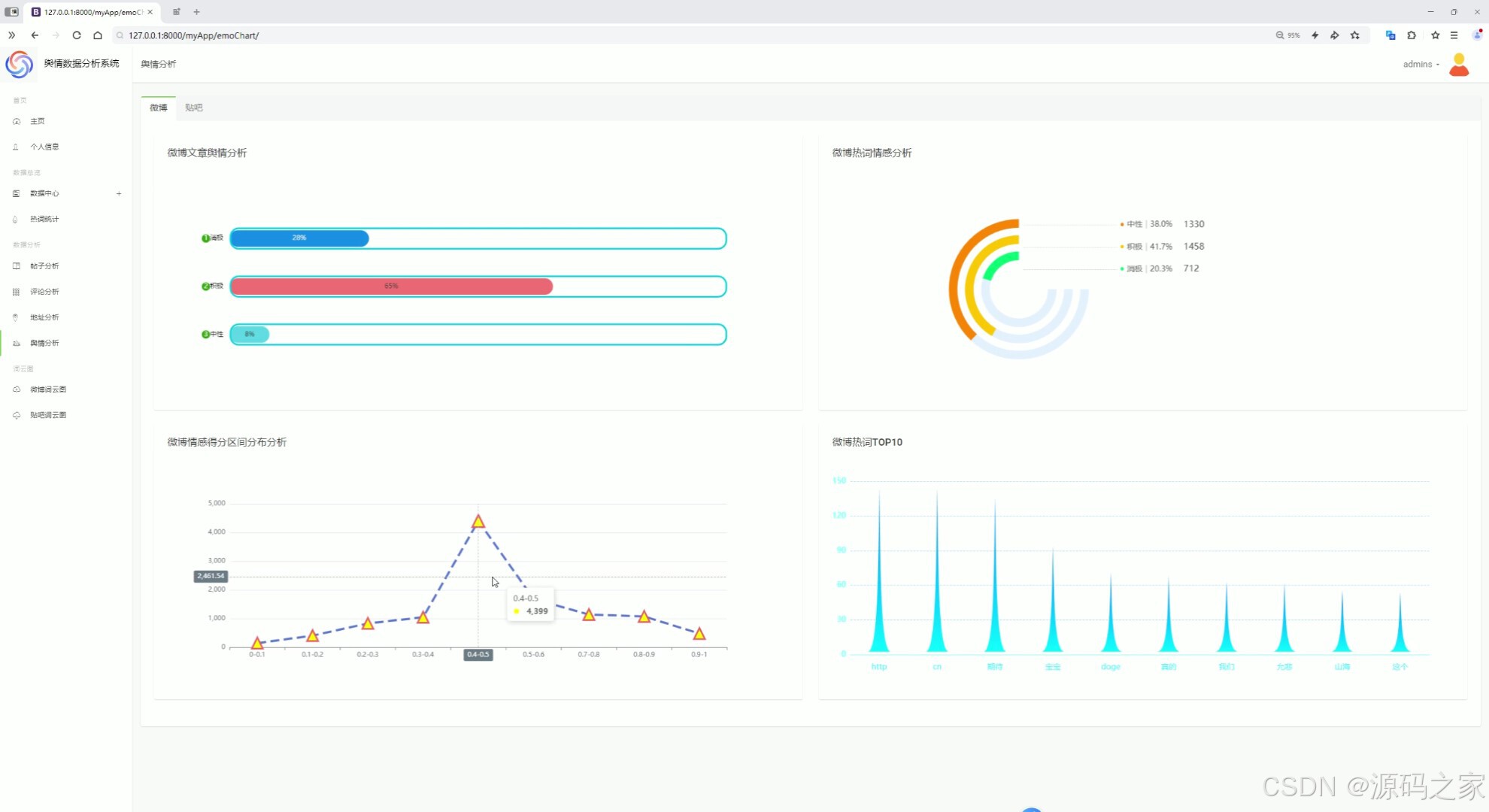
(4)舆情分析
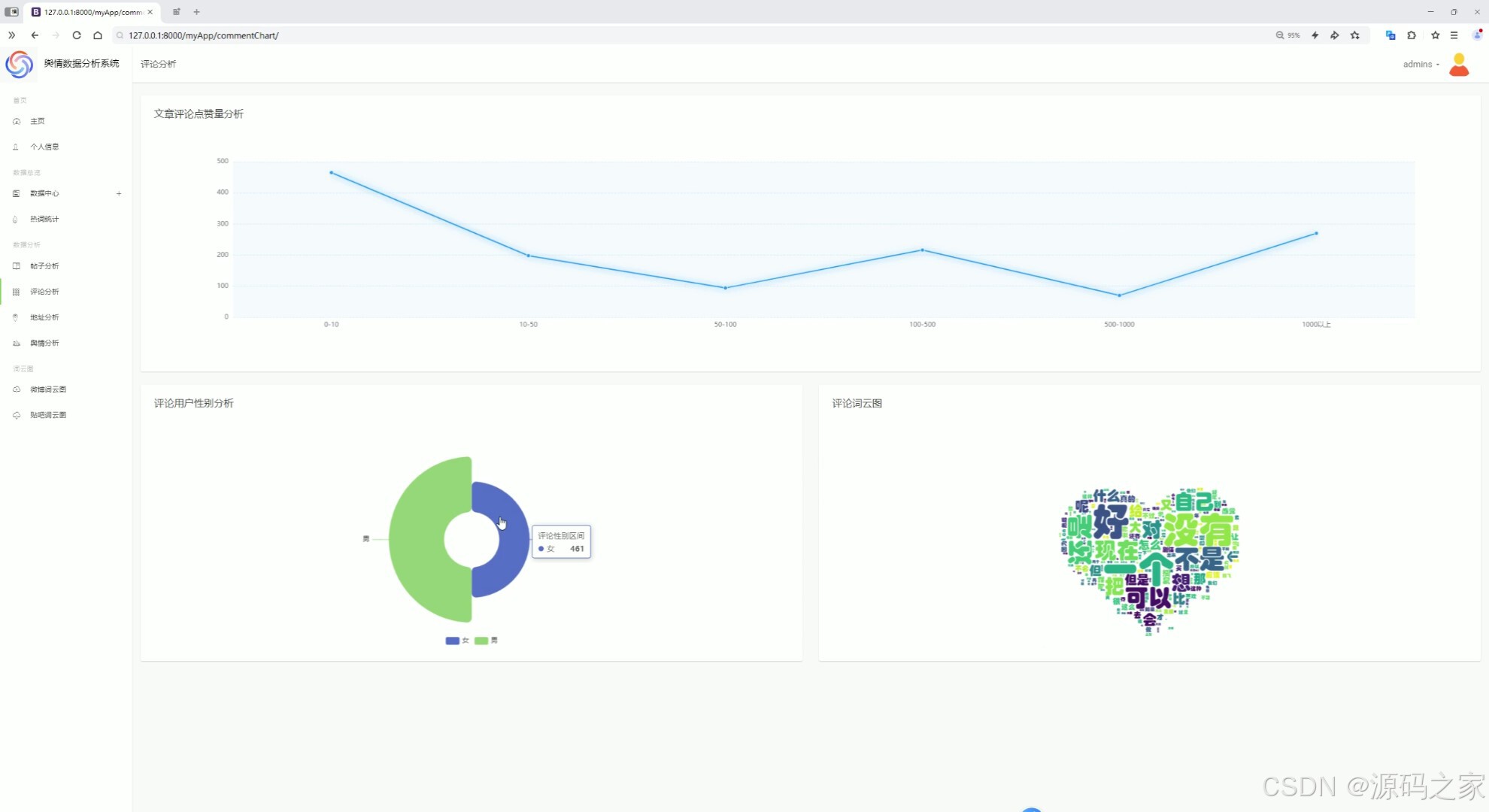
(5)评论分析
(6)词云图分析

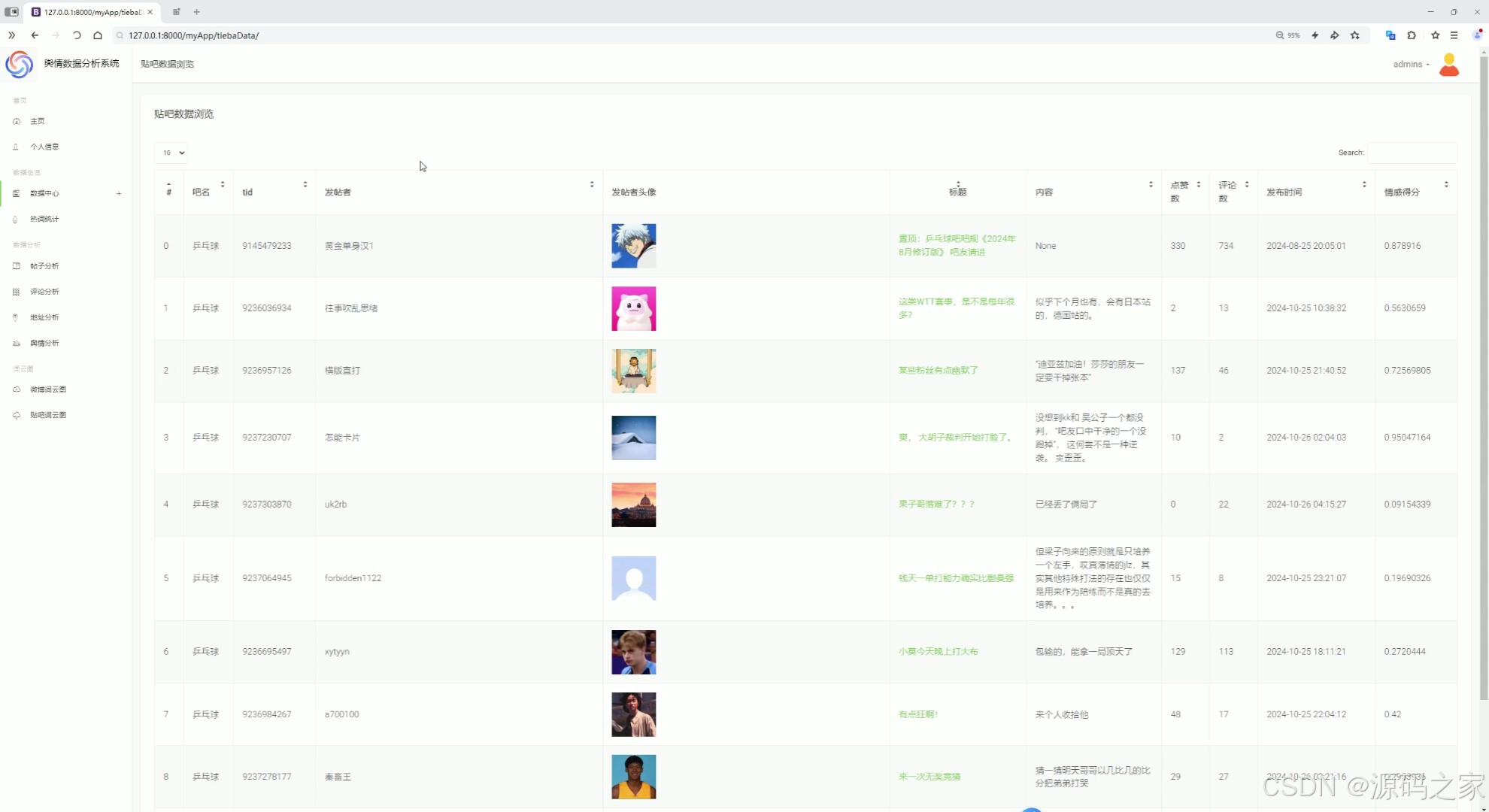
(7)贴吧数据中心、微博数据中心
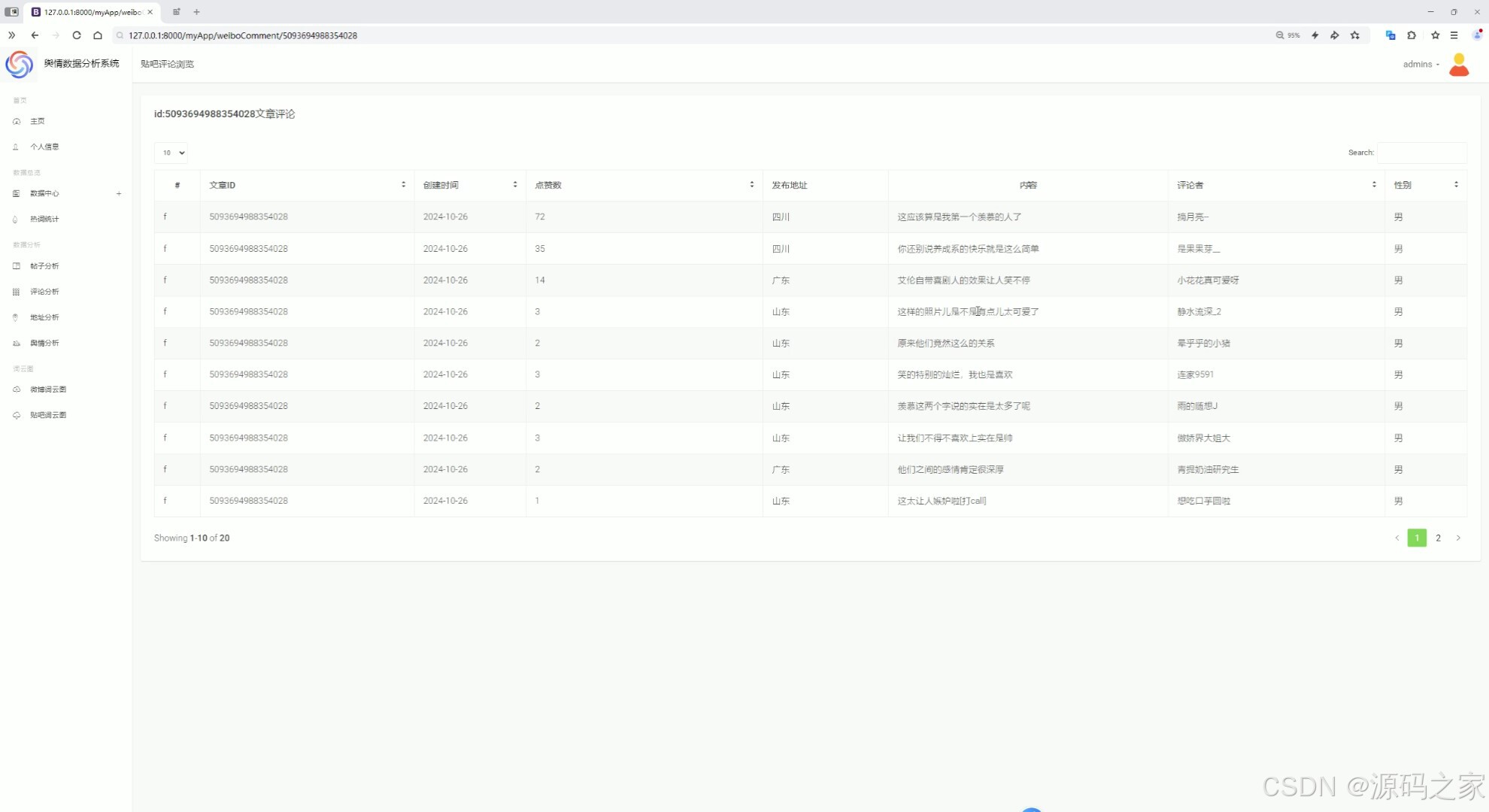
(8)微博评论中心、贴吧评论中心
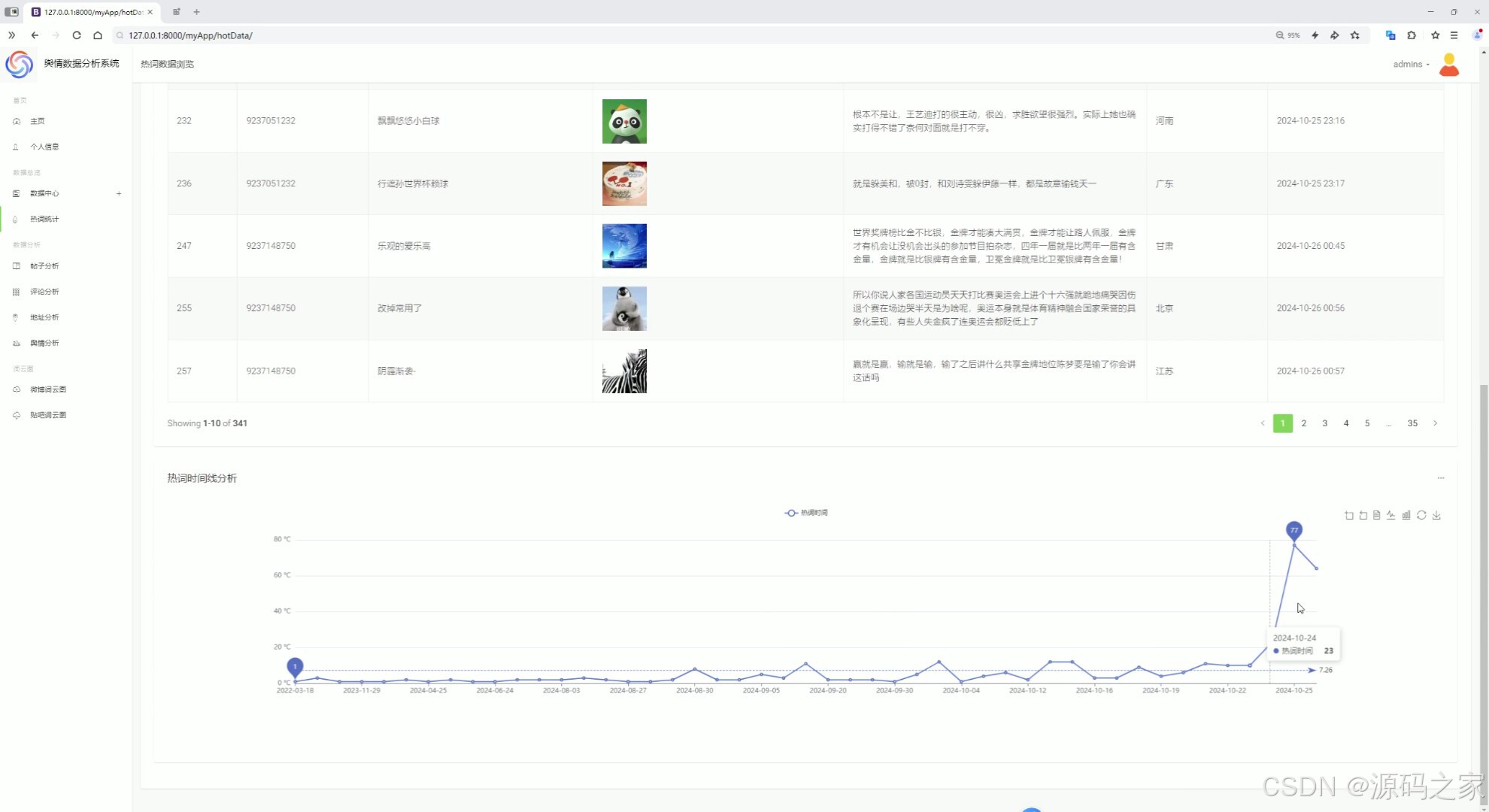
(9)热词统计分析
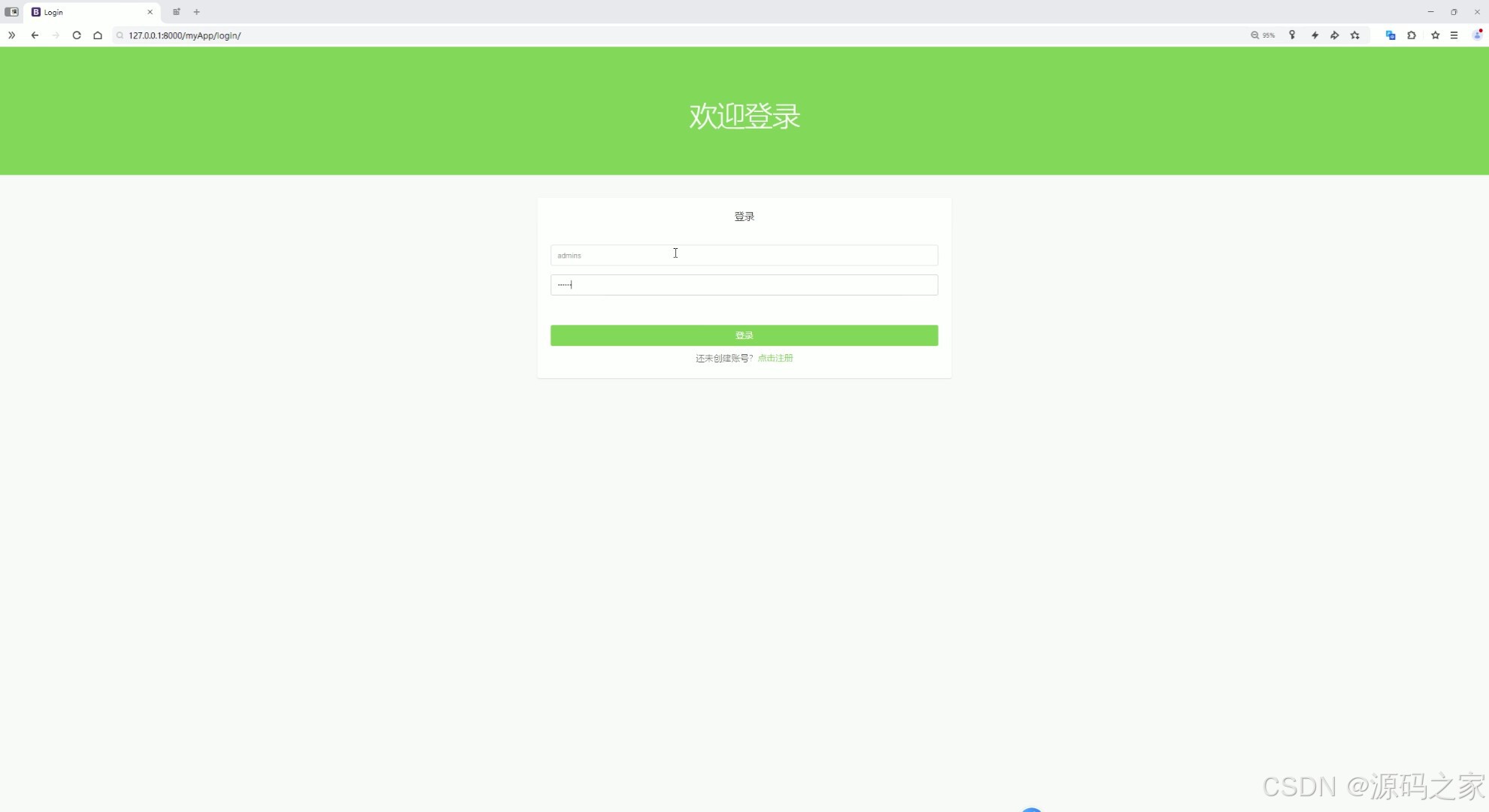
(10)注册登录
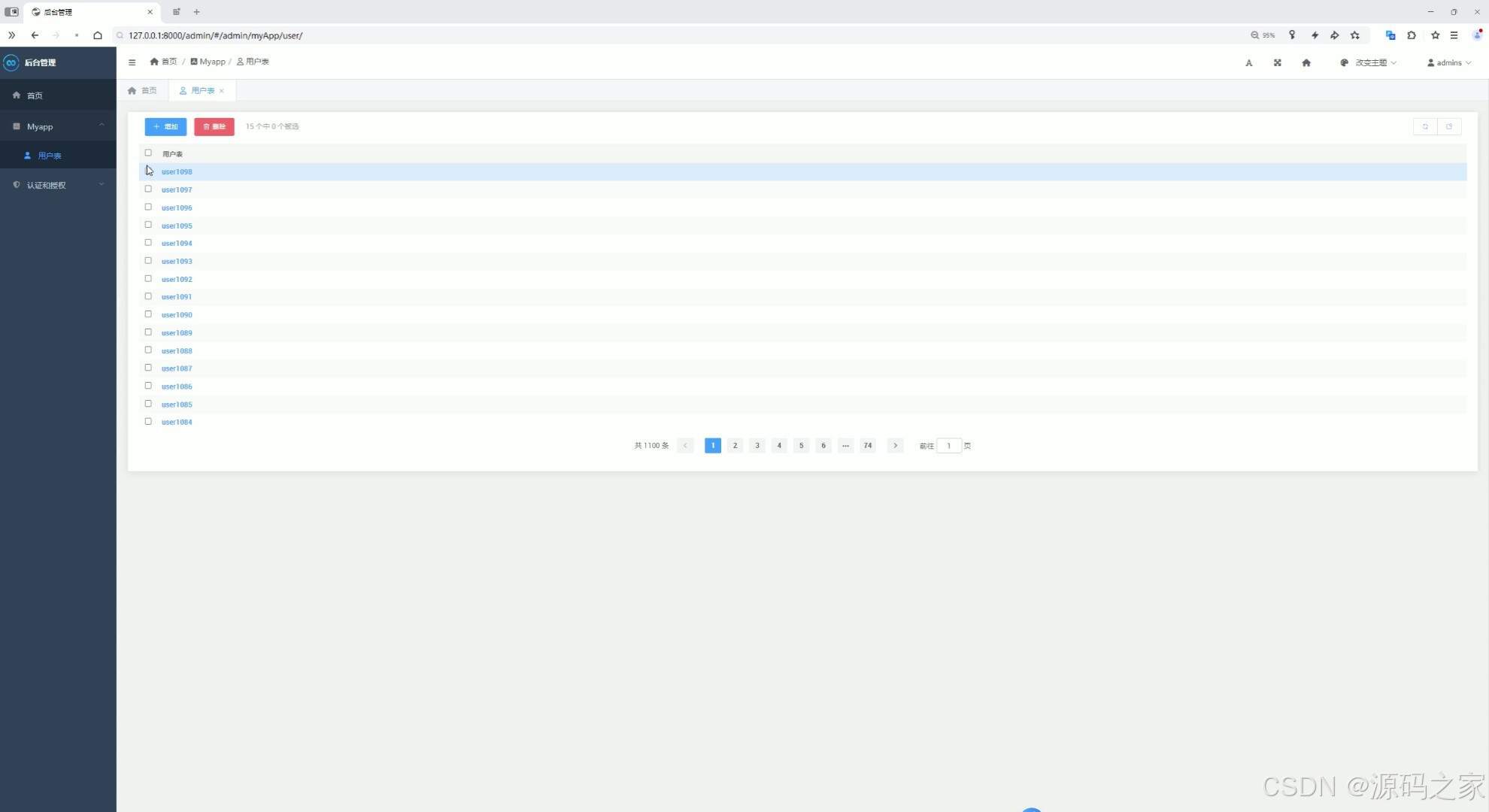
(11)后台管理
3、项目说明
3、项目说明
项目功能模块介绍
一、数据采集模块
微博爬虫
spiderWeiboNav.py:从微博导航分组接口获取分类信息并保存到本地文件。
spiderWeibo.py:根据分类信息爬取微博文章的详细内容。
spiderWeiboDetail.py:爬取微博评论数据并保存。
changeData.py:对微博数据进行清理,去除换行符等。
贴吧爬虫
spiderTieba.py:爬取百度贴吧指定主题的数据。
spiderTiebaDetail.py:爬取帖子的回复内容。
hotWordDeal.py:对帖子内容进行词频统计并提取热词。
二、数据分析与可视化模块
数据概况
展示微博和贴吧数据的总体情况,如数据量、来源等。
用户地址分布分析
使用中国地图展示微博和贴吧用户的地域分布。
帖子分析
对贴吧帖子的内容、热度等进行分析。
舆情分析
分析微博和贴吧的舆情趋势,如情感倾向等。
评论分析
对微博和贴吧的评论进行分析,提取关键信息。
词云图分析
通过词云图展示高频词汇,直观呈现热点话题。
热词统计分析
统计并展示微博和贴吧中的热门词汇。
三、数据存储与管理模块
贴吧数据中心
存储和管理贴吧相关的数据。
微博数据中心
存储和管理微博相关的数据。
评论中心
存储和管理微博和贴吧的评论数据。
四、用户交互模块
注册登录
提供用户注册和登录功能,方便用户使用系统。
后台管理
提供后台管理功能,方便管理员管理数据和用户权限。
五、技术架构
数据采集:使用 Python 的 requests 爬虫技术。
情感分析:使用 SnowNLP 进行情感分析。
数据存储:使用 MySQL 数据库存储数据。
大数据处理:使用 Hadoop、Spark 和 Hive 进行大数据处理。
可视化:使用 Echarts 进行数据可视化。
Web 框架:使用 Django 框架构建前端界面。
4、核心代码
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 2521
2521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









