



 本文探讨了通过对抗训练提升文本分类准确率的方法,利用Fast Gradient Sign Method生成扰动,优化Word Embedding,防止过拟合,提升模型鲁棒性。
本文探讨了通过对抗训练提升文本分类准确率的方法,利用Fast Gradient Sign Method生成扰动,优化Word Embedding,防止过拟合,提升模型鲁棒性。
[201605] ADVERSARIAL TRAINING METHODS FOR SEMI-SUPERVISED TEXT CLASSIFICATION
关于 Adversarial Training 在 NLP 领域的一些思考
这篇文章的核心思想:通过 Goodfellow 提出的 Fast Gradient Sign Method (FGSM) 来计算出扰动,添加到到连续的 Word Embedding 上产生 X_adv, 再一次喂给 model,得到 Adversarial Loss,通过和原来的 Classification Loss(Cross-Entropy)做一个相加得到新的 Loss。通过优化这个 Loss,能够在文本分类任务上取得超过目前 State-of-art 的表现。
Perturbation on Word Embedding
这一点在前一篇阅读笔记中谈到了,和图像领域不同,组成文本的词语一般都是以 one-hot vector 或者是 word index vector 来表示的,可以视作是离散的,而非连续的 RGB 值。这就导致如果我们直接在 raw text 上进行扰动,则可能扰动的方向和大小都没有任何明确的语义对应。但文章认为 word embedding 的表示是可以认为是连续的:
Because the set of high-dimensional one-hot vectors does not admit infinitesimal perturbation,we define the perturbation on continuousword embeddings instead of discrete word inputs.
因而这个扰动可以在一定程度上 make sense,至于更详细的原因,后面还会谈到。
Why State of Art
文章提到,这种 Adversarial Training 和图像中有所不同,其通过 FGSM 产生的 X_adv 并不能是做一种对抗样本,因为扰动之后的 Word Embedding 有极大可能并不能映射到一个真实存在的词语上,这和图像中 RGB 的扰动能够产生人眼无法分辨区别的对抗样本是不一样的。所以作者认为,这种 Adversarial Training 更类似于一种 Regularization 的手段,能够使得 word embedding 的质量更好,避免 overfitting,从而取得出色的表现。
Adversarial Training 能够提升 Word Embedding 质量的一个原因是:
有些词与比如(good 和 bad),其在语句中 Grammatical Role 是相近的,我理解为词性相同(都是形容词),并且周围一并出现的词语也是相近的,比如我们经常用来修饰天气或者一天的情况(The weather is good/bad; It’s a good/bad day),这些词的 Word Embedding 在是非常相近的。文章中用 Good 和 Bad 作为例子,找出了其最接近的 10 个词:
可以发现在 Baseline 和 Random 的情况下, good 和 bad 出现在了彼此的邻近词中,而经过喂给模型经过扰动之后的 X-adv 之后,也就是 Adversarial 这一列,这种现象就没有出现,事实上, good 掉到了 bad 接近程度排第 36 的位置。
我们可以猜测,在 Word Embedding 上添加的 Perturbation 很可能会导致原来的 good 变成 bad,导致分类错误,计算的 Adversarial Loss 很大,而计算 Adversarial Loss 的部分是不参与梯度计算的,也就是说,模型(LSTM 和最后的 Dense Layer)的 Weight 和 Bias 的改变并不会影响 Adversarial Loss,模型只能通过改变 Word Embedding Weight 来努力降低它,进而如文章所说:
Adversarial training ensures that the meaning of a sentence cannot be
inverted via a small change, so these words with similar grammatical
role but different meaning become separated.
这些含义不同而语言结构角色类似的词能够通过这种 Adversarial Training 的方法而被分离开,从而提升了 Word Embedding 的质量,帮助模型取得了非常好的表现。
先前也有工作通过在输入上增加 Noise 来作为 Regularization 手段,可能会有人问,这个 Perturbation 和 Noise 有什么区别?Perturbation 和 Noise 相比有什么好处呢? 在高维空间中,Noise 几乎和 cost 的梯度正交,没什么影响,而 Adversarial Perturbations 是对 cost 有很明显的影响的,也就是 Adversarial Cost 应该是较大的,但我在实验中做出来的 Adversarial Loss 远比 Classification Loss 要小,原因猜测是没有使用预训练的 Word Embedding 所导致。
Other Adversarial Training Methods
在 NLP 领域还有几种 Adversarial Training 的方法。
Papernot 提出的 Jacobian Saliency Map Approach(JSMA)原先应用在图像领域,同样有迁移到文本领域的应用,主要可以参考这篇 Paper,核心思想是通过计算 Jacobian Matrix 来衡量每个 Word Embedding 的改变对输出结果的影响,再依此在字典中寻找词语来进行替换
与此类似的还有这一篇 Towards Crafting Text Adversarial Samples,其提出了一种计算词语对最终分类标签的贡献的方式,并且构建一个候选词池(candidate pool),根据贡献大小排序后从池中选词进行替换,或者是去除和添加。
Why Adversarial Training
现在来谈谈在 NLP 领域中 Adversarial Training 是一个什么样的角色,或者说我们希望它们起到什么样的效果?
我认为,主要有以下四种主要的目的:
- 作为 Regularization 的手段,提升模型的性能(分类准确率),防止过拟合
- 产生对抗样本,攻击深度学习模型,产生错误结果(错误分类)
- 让上述的对抗样本参与的训练过程中,提升对对抗样本的防御能力,具有更好的泛化能力
- 利用 GAN 来进行自然语言生成
第四点并不在这篇文章的讨论范围内,而前三点事实上可以认为是两种不同的手段,而它们看似都是对模型泛化能力的提升,但其对于泛化标的是有所区别的,前者是通过提升 Word Embedding 质量,可以认为具有一定的普适性;而后者,则主要是对于对抗样本的适应和泛化。
但这两种方式各自也都存在着一些无法解释或者有些模糊不清的地方:
我们该如何理解前者的 Perturbation,仅仅是如上文所说的 good 和 bad 的问题吗?以及 Perturbation 的方向,仅仅是对 Cost 影响最大的方向,其在语言场景中有所对应吗?理解这个 Perturbation 对于 NLP 非常重要,其重要性甚至超出我们获得的所谓的“对抗样本”。
对于后者,在图像领域中个别像素点的 RGB 的值的改变如果可以认为是现实生活中常有发生的话,那么逐词的替换似乎就有点和我们创作文本的方式相悖:我会写一句 I feel good today 然后通过把 I 换成类似的 He 吗?首先语法上就出现了问题,其次这二者希望表达的完全不是一个意思。所以这种方式,对攻击神经网络模型很有效,但真的有意义吗?
这些问题,值得进一步的思考。—————————————————————————————
补充
Adversarial training是一种判别式有监督的对抗训练,在加入额外的扰动(perturbations)的情况下仍然具有较好的判别能力。
Virtual Adversarial training是Adversarial training的一种扩展,适用于半监督学习(loss与noise)。
文章的核心是:在word embedding(标准化处理)上增加扰动,从而增强模型的鲁棒性,提升分类器的准确率。
Adversarial training
扰动的选择: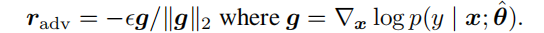
损失函数:
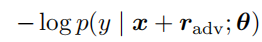
无论是r的选取还是loss函数,都是与标签y有关,因此对抗训练只是适用于有监督的方式。
选择的扰动r是最小化loss函数,从而提升鲁棒性。而g为loss函数的梯度,对应的是梯度上升,因此取-g方向。g//|g|是为了进行归一化处理。那么前面的e可以视为是调节扰动大小的一个值。
Virtual Adversarial training
扰动选择:
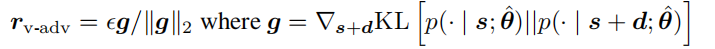
损失函数: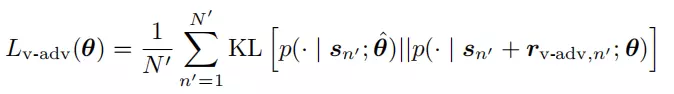
无论是r的选取还是loss函数,都只是与分布有关系,因此对抗训练使用于半监督的方式。
选择的扰动r是最大化KL散度,从而提升鲁棒性。因此用g的方向即可。
label data 和 unlabeld data
无标签的用Virtual Adversarial training,有标签的用Adversarial training,最后模型的loss为两个loss之和


















 9523
9523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









