



提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:本篇介绍如何利用python opencv 工具制作分类器,关于分类器如何使用见我的前面文章:
在平时做目标检测的时候需要用到自定义目标来做检测,官方的分类器已经不够用了,那么就需要我们自己来制作分类器。
一、级联分类器是什么?
分类器是我们平时使用的xml文件,他包含了对检测目标的描述,当然OpenCV官方也提供了像人眼,人脸等分类器可以直接使用,本篇介绍如何在平时项目里制作个人分类器。
级联分类器(Cascade Classifier)是一种高效的目标检测方法,常用于人脸检测、行人检测等任务。其中的“级联”(Cascade)指的是一种多阶段分类器结构,通过逐步过滤的方式快速排除非目标区域,从而提高检测效率。
二、使用步骤
1. 安装依赖和工具
安装OpenCV:
pip install opencv-python opencv-python-headless
安装训练工具:
访问 OpenCV官网 ,安装适合自己系统的版本,将opencv_createsamples 和 opencv_traincascade,opencv_annotation 添加到环境变量(也可以在安装目录直接使用)。
注意:opencv_createsamples 和 opencv_traincascade ,opencv_annotation是 OpenCV 的额外工具,通常包含在 OpenCV 的完整安装包中,而不是通过 pip 安装的 Python 包。
由于OpenCV2以后官方把分类器制作工具取消了,所以建议下载老版本,下载链接:opencv-2.4.13.6-vc14.exe。
下载完成后,在 opencv\build\x64\vc14\bin 目录下找到相应的工具。
2. 样本预处理
对于样本,需要进行预处理,主要是进行灰度化和resize, 那是由于通常样本量都是很大的,而且尺寸也有可能不一样,我们统一灰度处理和定义尺寸更方便后面对样本训练。
代码如下 (更改输出尺寸):
"""
import os
import cv2
def trans_to_gray(folder: str):
index = 0
for item in os.listdir(folder):
index += 1
item_path = os.path.join(folder, item)
if os.path.isfile(item_path):
gray = cv2.imread(item_path, cv2.IMREAD_GRAYSCALE)
img = cv2.resize(gray, (400, 400))
cv2.imwrite('pos2/' + str(index) + ".jpg", img)
3. 生成正标注文件
所谓的正标注文件,就是个人要检测的目标,被称为正样本。标注文件标注了正样本图片的路径,目标在图片中的起始像素和目标的大小,我们使用opencv_annotation 工具生成标注文件。
通过在终端执行 opencv_annotation 可以看到相关的参数:
-images # 正样本文件目录
-annotations # 输出文件名

执行运行依次出现提示让框选目标,依次框选直到完成,快捷键如下:
-
使用鼠标在图像中绘制矩形框,标注目标对象。
-
按 c 确认当前标注。
-
按 d 删除上一个标注。
-
按 n 切换到下一张图像。
-
按 ESC 退出标注工具。
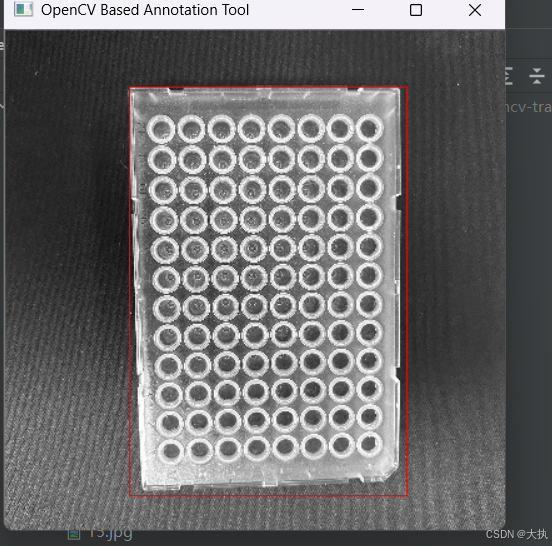
执行完毕,生成标注文件,如下:
4. 生成负标注文件
负标注文件来自于负样本,负样本可以通过在网上下载素材,也就是和检测目标不相关的文件,可以理解成背景。通过同样方法生成负样本标注文件。
更为方便可以通过代码方式生成(因为负样本不需要找起始像素点):
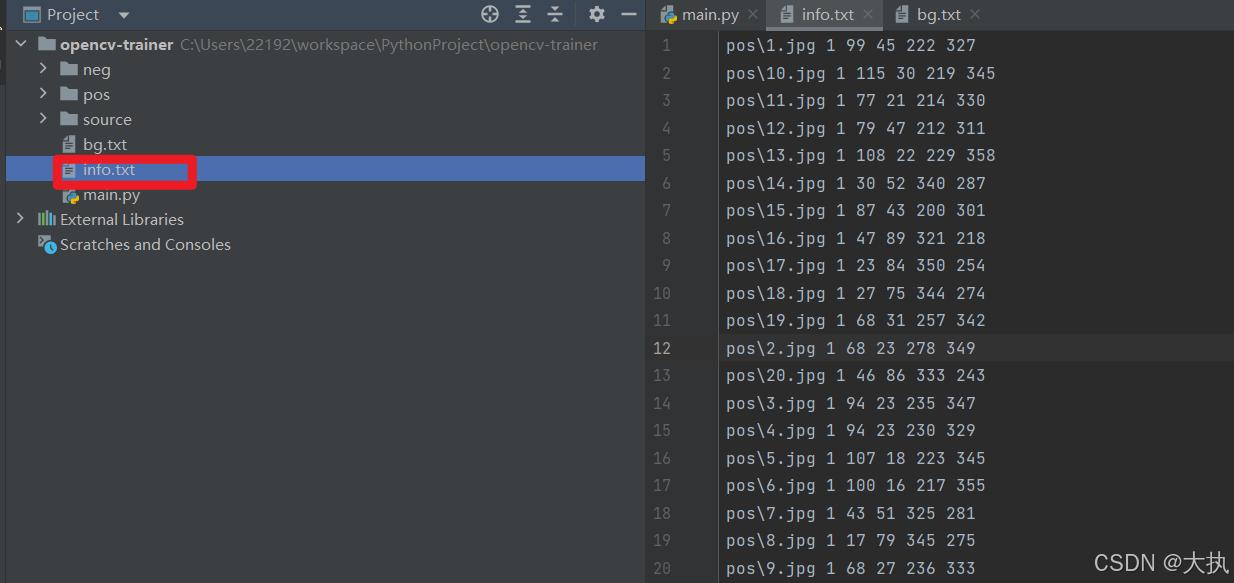
def create_pos_n_neg():
for file_type in ['pos', 'neg']: # 此处修改pos或neg即可生成正负样本的描述文件,pos是生成正样本描述文件info.txt
index = 0
for img in os.listdir(file_type):
index += 1
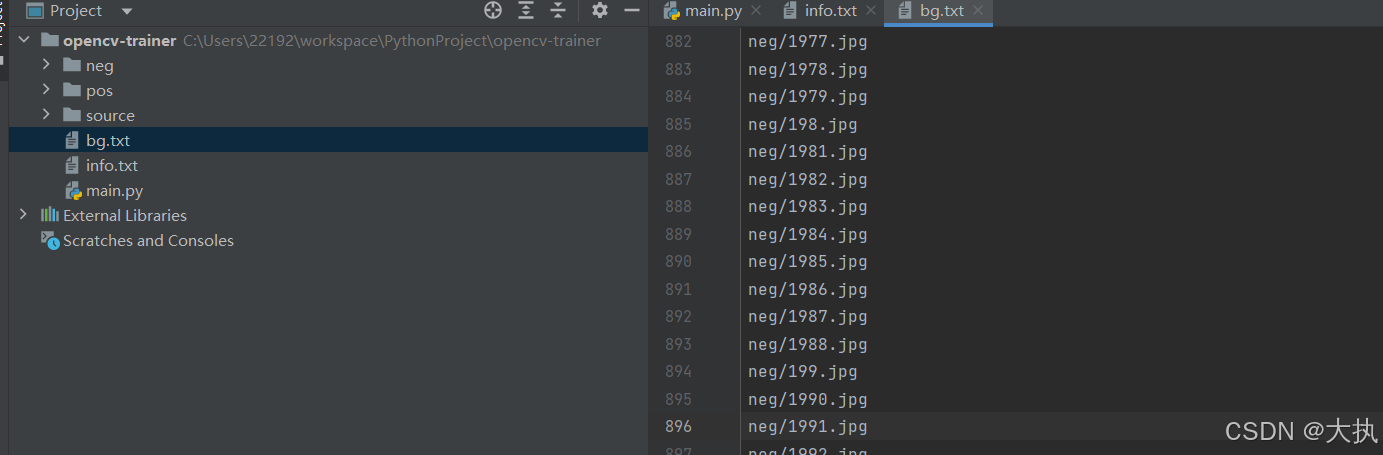
if (file_type == 'neg'):
line = file_type + '/' + img + '\n'
with open('bg.txt', 'a') as f:
f.write(line)
elif (file_type == 'pos'):
line = file_type + '/' + img + ' 1 0 0 400 400\n' # 1是编号,0 0是起始像素点,40 40是图片大小,要和程序1的大小一样
with open('info.txt', 'a') as f:
f.write(line)
生成的负样本:
5. 生成样本描述文件(.vec)
样本描述文件是利用前面的标注文件,将样本信息包含到标注文件里面,标注文件包含样本量,输出尺寸信息,使用 opencv_createsamples工具来获得。
[-info <collection_file_name>] # 正样本标注文件
[-img <image_file_name>] # 指定文件为输入(忽略)
[-vec <vec_file_name>] # 输出描述文件名
[-bg <background_file_name>] # 负样本标注文件
[-num <number_of_samples = 1000>] # 样本量,按最大填,如果不够自动使用实际的样本量
[-bgcolor <background_color = 0>]
[-inv] [-randinv] [-bgthresh <background_color_threshold = 80>]
[-maxidev <max_intensity_deviation = 40>]
[-maxxangle <max_x_rotation_angle = 1.100000>]
[-maxyangle <max_y_rotation_angle = 1.100000>]
[-maxzangle <max_z_rotation_angle = 0.500000>]
[-show [<scale = 4.000000>]] # 显示输出过程
[-w <sample_width = 24>] # 压缩的样本大小
[-h <sample_height = 24>]
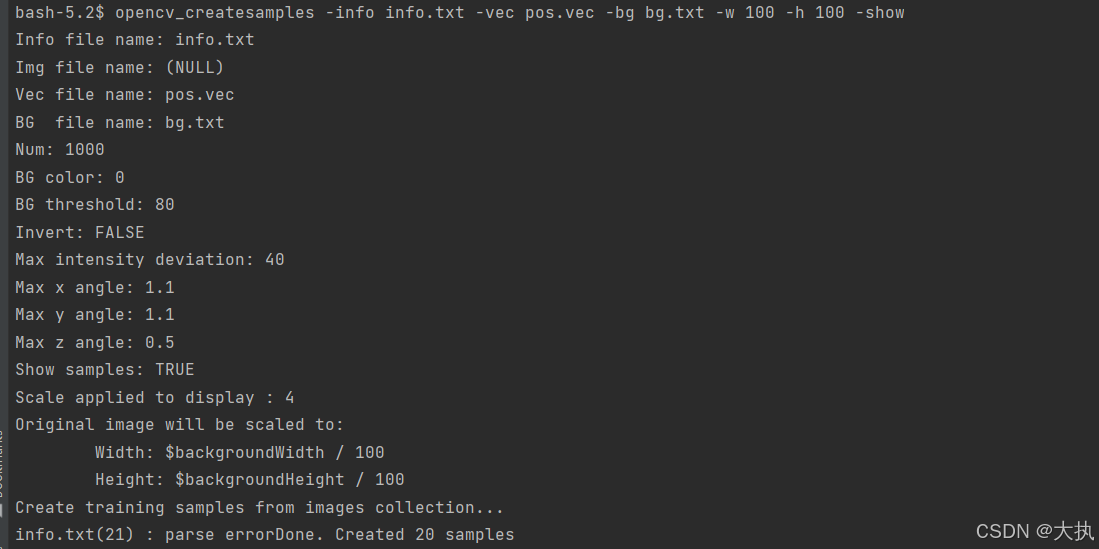
执行 opencv_createsamples -info info.txt -vec pos.vec -bg bg.txt -w 100 -h 100 -show , show出图片后按 C 继续,输出如下:
6. 训练输出分类器
使用opencv_traincascade工具来训练分类器,输出xml文件,参数如下:
-data <cascade_dir_name> # 输出目录(需要空目录)
-vec <vec_file_name> # 描述文件
-bg <background_file_name> # 负样本标注
[-numPos <number_of_positive_samples = 2000>] # 正样本数量,需要小于真实数量
[-numNeg <number_of_negative_samples = 1000>] # 负样本数量,需要小于真实数量
[-numStages <number_of_stages = 20>] # 级联数
[-precalcValBufSize <precalculated_vals_buffer_size_in_Mb = 1024>] # 电脑提供的缓存大小,根据电脑配置给
[-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb = 1024>]
[-baseFormatSave]
[-acceptanceRatioBreakValue <value> = -1>]
--cascadeParams--
[-stageType <BOOST(default)>]
[-featureType <{HAAR(default), LBP, HOG}>]
[-w <sampleWidth = 24>] # 根据描述文件尺寸填宽和高
[-h <sampleHeight = 24>]
--boostParams--
[-bt <{DAB, RAB, LB, GAB(default)}>]
[-minHitRate <min_hit_rate> = 0.995>]
[-maxFalseAlarmRate <max_false_alarm_rate = 0.5>]
[-weightTrimRate <weight_trim_rate = 0.95>]
[-maxDepth <max_depth_of_weak_tree = 1>]
[-maxWeakCount <max_weak_tree_count = 100>]
--haarFeatureParams--
[-mode <BASIC(default) | CORE | ALL
--lbpFeatureParams--
--HOGFeatureParams--
使用如下命令开始训练, opencv_traincascade -data data2 -vec pos.vec -bg bg.txt -numPos 19 -numNeg 500 -precalcValBufSize 5000 -w 100 -h 100, 等待训练完成。
7. 使用级联分类器
通过训练,data文件夹将会出现cascade.xml文件,通过加载这个分类器,来识别目标,代码如下:
import cv2
# 1. 加载预训练的 Haar 级联分类器
face_cascade = cv2.CascadeClassifier('data2/cascade.xml')
# 2. 读取图像
image = cv2.imread('p2.jpg') # 替换为你的图像路径
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转换为灰度图像
target = face_cascade.detectMultiScale(
gray, # 灰度图像
scaleFactor=1.1, # 图像缩放比例
minNeighbors=5, # 检测目标的邻居数量
)
print("Target ", target)
# 4. 画出检测到的对象
for (x, y, w, h) in target:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2) # 画出矩形框
# 5. 显示结果
cv2.imshow('Detected', image)
cv2.waitKey(0) # 等待按键
cv2.destroyAllWindows() # 关闭窗口
运行显示结果如下:

可以看到,分类器还是帮我们找到了目标,但是找的位置有偏差。由于样本量太少,经过5分钟的训练达到的精准度是远远不够的。
总结
以上就是本篇介绍的如何利用openCV工具生成分类器,以及如何使用分类器,如果想要顺利精准的构造可用的分类器总结经验如下:
- 样本尽量尺寸小一点,摆放的方向尽量一致
- 拍摄的光线尽量统一一些
- 拍摄的角度多样,并且保证足够量的样本数量
- 正样本和负样本尺寸必须满足生成生成分类器定义的尺寸,假如正样本或负样本尺寸比定义的尺寸小,会出现训练失败问题。

















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









