



似曾相识

初中的时候就有过这样的题目:”给出一部分点,要求根据这些点去得到一个函数曲线去尽可能的拟合所有的点”,那时候更多的都是拟合一条直线。
在这个房价预测的例子中我们也可以去这么做,这好像是回到了初中时代,而实际上房价预测的机器学习方法思想和这个那么相近,那丝毫不虚呀(PS:实际上这一块看了特多资料,还是虚)
言归正传
在《统计学习方法》中:“回归问题的学习等价于函数拟合:拟合一条函数曲线去很好的拟合现有的数据并能很好的用于预测数据”,也就是给定一组数据 xi,yi,i=1,2,3... x i , y i , i = 1 , 2 , 3... ,得到一个函数 Y=f(X) Y = f ( X ) 。
下面是Andrew Ng的视频课中的一幅图:

在回归问题中最常见的问题就是线性回归,也是这篇博客(笔记)的学习对象,在周志华老师的西瓜书中这样说:
给定的 x=(x1,x2,...xd) x = ( x 1 , x 2 , . . . x d ) ,其中x中的每个分量是一个属性,线性模型(linear model)试图学的一个通过属性的线性组合来进行预测的函数,即
f(x)=w1x1+w2x2+...+wdxd+b f ( x ) = w 1 x 1 + w 2 x 2 + . . . + w d x d + b
我们期待根据 f(x)=wTx+b f ( x ) = w T x + b 计算得到的 f(xi)≈y f ( x i ) ≈ y
在这个公式中w的每个分量表示权重(weight),在吴恩达的视频里是把 θ=(θ0,θ1...) θ = ( θ 0 , θ 1 . . . ) ,其中 θ0 θ 0 是表示b,后面的分量则是w的内容。
西瓜捡软的捏
在线性回归中根据输入变量的个数分为一元回归和多元回归。从一元入手来看,易于画图,比较直观。
在李宏毅的课件中将机器学习分为了三个阶段:
1. 列出一组函数模型
f1,f2...
f
1
,
f
2
.
.
.
2. 评价各个模型的好坏程度
3. 选出最好的一个模型
选择恐惧症呀

在我们有了一组模型,那么我们自然会想这些备选中哪个更好,我们就需要一个手段来进行评价。
代价函数(不能怂)
选择当然得尽量客观,那一个数学公式自然是极好的,还得雨露均沾。比较常见的方法就是均方差公式。
这个函数是用来评价模型有多坏的,根据我们预期,加入训练数据中的每个数据都在拟合的曲线上面,那么这个代价函数的值自然是0,但这个比较难以得到。
实际上我们很难去给出所有的可能性之后再去评比选择,但换个思路考虑,cost function是
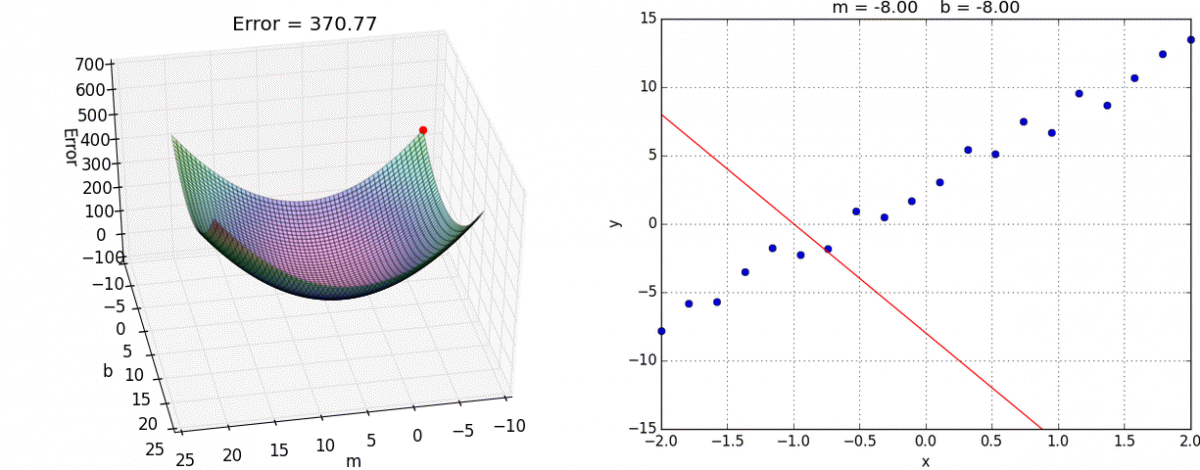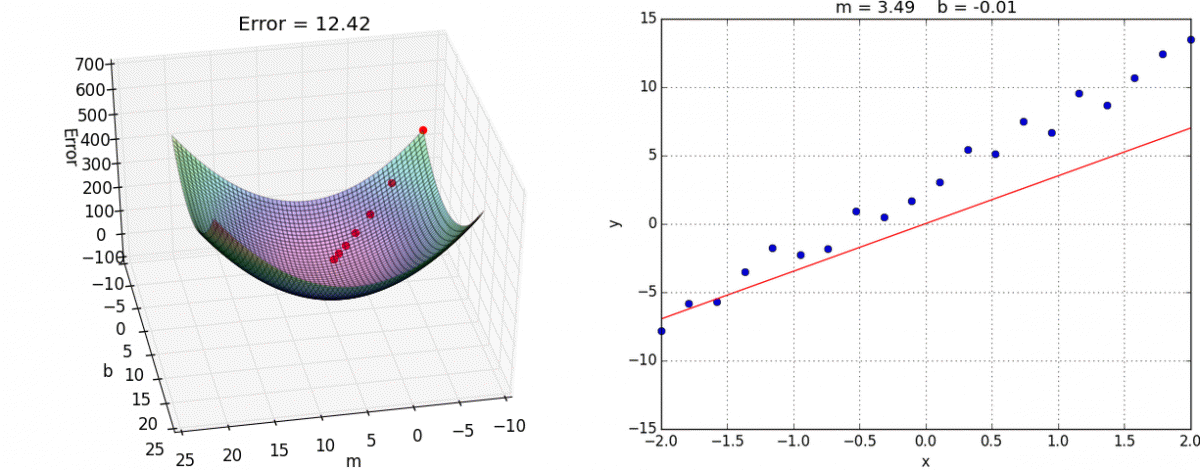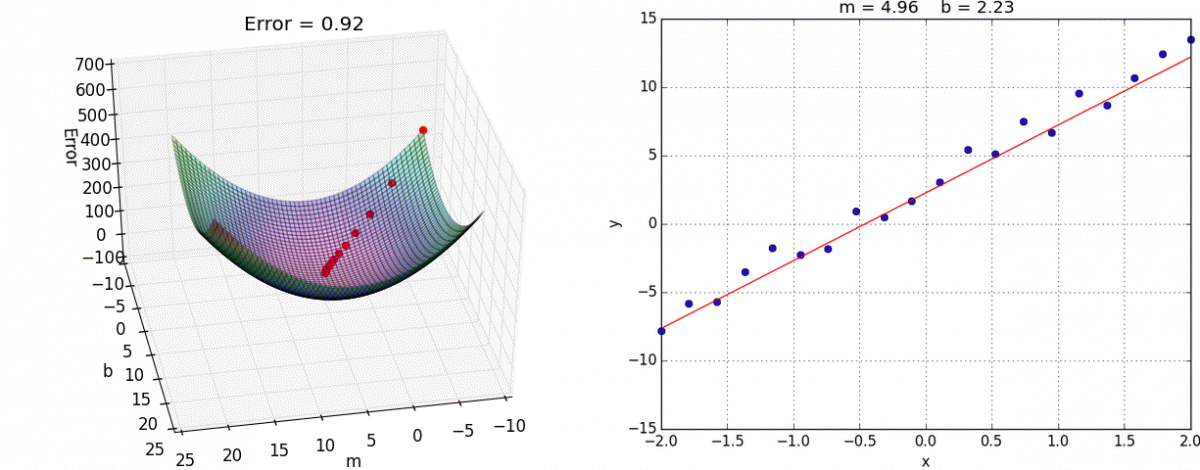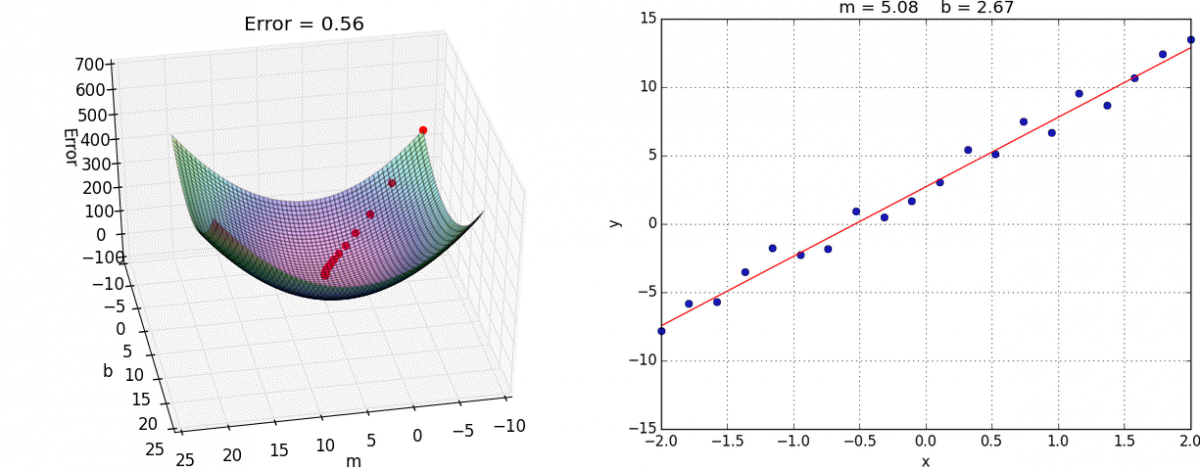
求代价函数的最小值

在这个图像中底面的坐标轴是
θ
θ
也等效于
w、b
w
、
b
,这个图比较有说明性(主要是偷懒,现成的图好用)。
梯度下降(gradient decent)
这是最小化代价函数比较通用的一个方式,直观的图像当然是比较好的例子(图片来自李宏毅ml的课件)

这里实际上简化了代价函数(视b=0),我们期待损失函数(Loss function)每次都在减少。而通过梯度下降方法中的参数更新公式:
如果 ∂J∂w>0 ∂ J ∂ w > 0 我们取 α>0 α > 0 ,则有w减小
如果 ∂J∂w<0 ∂ J ∂ w < 0 我们取 α>0 α > 0 ,则有w增大
从而我们可以见到对上述图像来说损失函数不断地减小,直到偏导数为0,即到达一个局部最小值(PS:在当前情景下实际上就是全局的最小值)。
高等数学中求函数极值的一种方法就是利用一阶导数(first-order derivative),梯度下降就是求得一阶导数为0的点,而一阶导数为0的点可能是三类情况:
1. 极大值的点
2. 极小值的点
3. 不是极值的驻点
因此这里有一点就需要注意,关于梯度下降的使用,想要求得正确的答案前提是代价函数是凸函数(这几天就被凸优化弄的疯了),在李宏毅的课上有说到线性回归中不会出现非凸的情况,因此可以放心使用 。
一元函数的极值问题有了头绪,那考虑多元函数的极值问题就很容易接受了,实际上我们就是通过不断地迭代知道达到函数的一个极值点。
直观的演示一波(此图网址: 下述图片的网址)

对于梯度下降有下列通用的算法流程:
1. 选取一个学习率(learning rate)
2. 随机的选定初始的参数值(w、b)
3. 执行更新策略如下:
在梯度下降的问题中学习率的选取是一个比较麻烦的点,学习率是一种超参数(hyperparameter),是程序员对算法的调节旋钮
超参数的选择是一个比较麻烦的点
- α α 如果选择的比较小,则需要迭代的次数很多,收敛的慢
-
α
α
选择的大,每一次迭代损失函数值不一定降低,导致无法收敛
谷歌的教程中有设置学习率的演示程序,多次设置了解使用
在使用梯度回归方法的时候有一个小技巧可以用来加速迭代的过程。以二元的情况为例 (Andrew Ng)课上的一张图片如下:

从左边图可以看出迭代的更新会在某个变量上有多次的更新,而在右图就会好很多,
两种特征缩放(Feature Scaling)的方法:
方法一. 用下面的规则更新每个参数xi=xi−μxmax x i = x i − μ x m a x
方法二. 更新规则:xi=xixmax x i = x i x m a x
正规方程(Normal Equation)
上面提到说求解的过程就是求取极小值的过程,回想高数的求解过程,我们是直接联立求解所有偏导数为0这一情况。
将推导过程向量化直接得到应用公式:
这一方法的使用局限:
当 XTX X T X 是满秩矩阵或者正定矩阵时使用,而且对于计算机来说,当特征数量较多时使用的成本较高,求解过程相当慢。
Reference
- 李宏毅machine learning 视频课程
- Andrew Ng 的机器学习课程
- 《Getting Started With MachineLearning》
- Google速成课程
有不对的地方希望诸位指正,不胜感激

















 3194
3194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}