






数据库和缓存数据一致性
1、先删缓存,再更新数据库
请求A更新操作,请求B查询操作
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
上述情况就会导致数据不一致。如果不采用给缓存设置过期时间策略,该数据永远是脏数据。
/**
* 先删除缓存,再更新数据库
*/
@RequestMapping("/delCacheUp/{id}")
@ResponseBody
public String delCacheUp(@PathVariable int id) {
int count = 0;
try {
// 删除库存缓存
stockService.delStockCountCache(id);
// 完成扣库存下单
orderService.createPessimisticOrder(id);
} catch (Exception e) {
logger.error("购买失败:[{}]", e.getMessage());
return "购买失败,库存不足!";
}
return String.format("购买成功,剩余库存为:%d", count);
}
@Override
public void delStockCountCache(int id) {
String hashKey = CacheKey.STOCK_COUNT.getKey() + "_" + id;
RedisUtil.delete(hashKey);
logger.info("删除商品id:[{}] 缓存", id);
}
2、先更新数据库,再删缓存
请求A查询操作,请求B更新操作
(1)缓存刚好失效
(2)请求A查询数据库,得到一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存
步骤(3)的写操作比步骤(2)的读数据库耗时更短。依然会有问题,问题出现的可能性会因为上述原因,变得比较低!
/**
* 先更新数据库,再删缓存
*/
@RequestMapping("/upDelCache/{id}")
@ResponseBody
public String upDelCache(@PathVariable int id) {
int count = 0;
try {
// 完成扣库存下单事务
orderService.createPessimisticOrder(id);
// 删除库存缓存
stockService.delStockCountCache(id);
} catch (Exception e) {
LOGGER.error("购买失败:[{}]", e.getMessage());
return "购买失败,库存不足";
}
logger.info("购买成功,剩余库存为: [{}]", count);
return String.format("购买成功,剩余库存为:%d", count);
}
以上两种方式:没法做到强一致性,只能做到最终一致性。
3、延时双删
(1)先淘汰缓存
(2)再写数据库
(3)休眠一秒,再次淘汰缓存(将一秒内所造成的缓存脏数据,再次删除)
采用这种同步淘汰策略,吞吐量降低怎么办?
那就将第二次删除作为异步
最好的方法是开设一个线程池,在线程中删除key,而不是使用Thread.sleep进行等待,这样会阻塞用户的请求。
写数据的休眠时间在读数据业务逻辑的耗时基础上,加几百ms即可。确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
如果删除缓冲失败了,怎么搞?
那就采用删除缓冲重试机制,使用mq消息队列
/**
* 先删除缓存,再更新数据库,缓存延时再删
*/
@RequestMapping("/doubleDel/{id}")
@ResponseBody
public String doubleDel(@PathVariable int id) {
int count;
try {
// 删除库存缓存
stockService.delStockCountCache(id);
// 完成扣库存下单事务
count = orderService.createPessimisticOrder(id);
// 延时指定时间后再次删除缓存
cachedThreadPool.execute(new delCacheByThread(id));
} catch (Exception e) {
logger.error("购买失败:[{}]", e.getMessage());
return "购买失败,库存不足";
}
logger.info("购买成功,剩余库存为: [{}]", count);
return String.format("购买成功,剩余库存为:%d", count);
}
//延迟时间
private static final int DELAY_MILLSECONDS = 1000;
// 延时双删线程池
private static ExecutorService cachedThreadPool = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS,new SynchronousQueue());
/**
* 缓存再删除线程
*/
private class delCacheByThread implements Runnable {
private int id;
public delCacheByThread(int id) {
this.sid = id;
}
public void run() {
try {
LOGGER.info("异步执行缓存再删除,商品id:[{}], 首先休眠:[{}] 毫秒", sid, DELAY_MILLSECONDS);
Thread.sleep(DELAY_MILLSECONDS);
stockService.delStockCountCache(id);
logger.info("再次删除商品id:[{}] 缓存", id);
} catch (Exception e) {
logger.error("delCacheByThread执行出错", e);
}
}
}
重试机制:
@Configuration
public class RabbitMqConfig {
@Bean
public Queue delCacheQueue() {
return new Queue("delCache");
}
}
@Component
@RabbitListener(queues = "delCache")
public class DelCacheReceiver {
private static final Logger logger = LoggerFactory.getLogger(DelCacheReceiver.class);
@Autowired
private StockService stockService;
@RabbitHandler
public void process(String message) {
logger.info("DelCacheReceiver收到消息: " + message + ",开始删除缓存");
stockService.delStockCountCache(Integer.parseInt(message));
}
}
/**
* 先更新数据库,再删缓存,删除缓存重试机制
*/
@RequestMapping("/upDelRep/{id}")
@ResponseBody
public String upDelRep(@PathVariable int id) {
int count;
try {
// 完成扣库存下单事务
count = orderService.createPessimisticOrder(id);
// 删除库存缓存
stockService.delStockCountCache(sid);
// 延时指定时间后再次删除缓存
// cachedThreadPool.execute(new delCacheByThread(id));
// 假设上述再次删除缓存没成功,通知消息队列进行删除缓存
sendDelCache(String.valueOf(id));
} catch (Exception e) {
LOGGER.error("购买失败:[{}]", e.getMessage());
return "购买失败,库存不足";
}
LOGGER.info("购买成功,剩余库存为: [{}]", count);
return String.format("购买成功,剩余库存为:%d", count);
}
4、MySQL的读写分离
一个请求A进行更新操作,另一个请求B进行查询操作
(1)请求A进行写操作,删除缓存
(2)请求A将数据写入数据库了,
(3)请求B查询缓存发现,缓存没有值
(4)请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值
(5)请求B将旧值写入缓存
(6)数据库完成主从同步,从库变为新值
依旧使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
重试机制1(不可取,造成代码侵入):
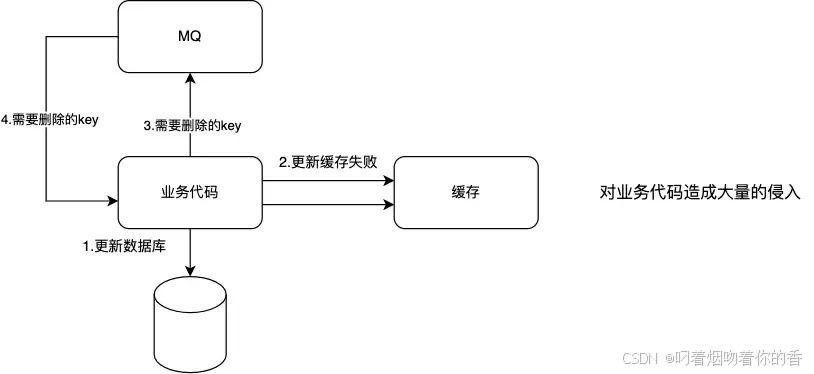
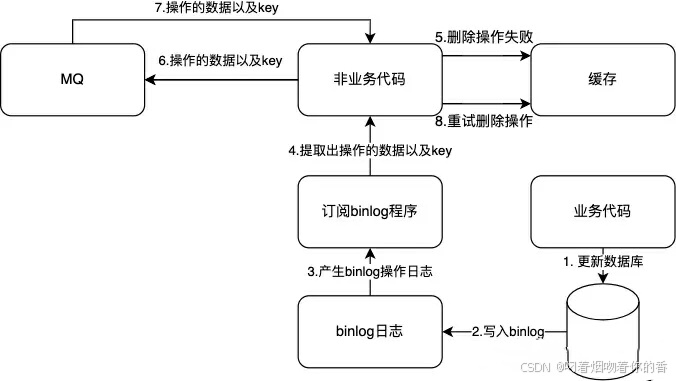
重试机制2(需要使用阿里开源canal):
概念
Canal 是一款基于 MySQL 数据库增量日志解析的开源项目。它模拟了 MySQL 的 slave 节点,通过解析 MySQL 的 binlog 日志来获取数据库的变更信息,如数据的插入、更新和删除操作。这些变更信息可以被 Canal 捕获并发送到其他存储系统、消息队列或者进行自定义的处理,从而实现数据的实时同步和其他相关业务逻辑。
架构
Canal 主要由 Server 和 Client 两部分组成。
Canal Server 负责连接到 MySQL 数据库,解析 binlog 日志。它包括了多个组件,如 instance(实例),每个 instance 可以对应一个或多个数据库表的解析。
Canal Client 则从 Canal Server 获取解析后的变更数据,并进行后续的处理。例如,可以将数据发送到 Kafka 消息队列或者存储到 Elasticsearch 中。
原理
MySQL 的 binlog 是一种二进制格式的日志文件,记录了数据库的所有更改操作。Canal 通过伪装成 MySQL 的 slave 向 MySQL master 发送 dump 协议请求 binlog 数据。然后,它利用自己的解析引擎对 binlog 进行解析,将二进制数据转换为可读的变更记录。

















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









