



 本文深入解析了SQL查询优化的重要性和EXPLAIN命令的使用方法,包括EXPLAIN EXTENDED和EXPLAIN PARTITIONS的特性,详细阐述了id、select_type、table、type等列的意义,以及possible_keys、key、key_len、ref、rows、Extra列的作用,帮助读者理解如何通过EXPLAIN分析SQL执行计划,进而优化查询效率。
本文深入解析了SQL查询优化的重要性和EXPLAIN命令的使用方法,包括EXPLAIN EXTENDED和EXPLAIN PARTITIONS的特性,详细阐述了id、select_type、table、type等列的意义,以及possible_keys、key、key_len、ref、rows、Extra列的作用,帮助读者理解如何通过EXPLAIN分析SQL执行计划,进而优化查询效率。
这篇文档属于一种文档性质的,是一种记录,也是一种总结。希望可以给大家带来一定的用处,在工作中,自认为这个挺重要的,这个也是判断自己sql优化的程度。
EXPLAIN EXTENDED
explain extended 会在 explain 的基础上额外多出一个filtered 列,这个列是半分比的值:rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表),并且 额外提供一些查询优化的信息。
explain extended select * from t_bill where id = 544;

优化信息可以在explain extended 的sql语句后面使用 show warnings 命令,便可以查询到优化后的查询语句,从而看出优化器优化了什么,可以根据这个优化来调整自己的sql。
show warnings;

explain partitions
相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
介绍explain
EXPLAIN命令是查看优化器如何决定执行查询的主要方法,我们可一利用这个来优化我们的sql。和添加索引。
explain 的列
id列
id列是查询语句的顺序列,有几个查询就有几个id,并且按照查询顺序id递增。id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
explain select temp.* from t_bill temp where secret_key = (SELECT secret_key FROM t_commercial_tenant where id = 8);

图上,是先执行id = 2的sql语句,然后再执行id =1 的sql语句。
select_type列
select_type 表示的是对应查询sql的查询类型:简单子查询、派生表(from语句中的子查询)、union 查询。
- simple:简单查询。查询不包含子查询和union。
explain SELECT secret_key FROM t_commercial_tenant where id = 8;

- primary:复杂查询中最外层的 select。
- subquery:包含在 select 中的子查询(不在 from 子句中)
- derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表。
EXPLAIN SELECT
(SELECT 1 FROM actor WHERE id = 1)
FROM
(SELECT * FROM film WHERE id = 1) der;

- union:在 union 中的第二个和随后的 select
explain select * from t_bill union all select * FROM t_bill;

table列
这一列表示 explain 的一行sql访问表的名字。
当 from 子句中有子查询时,table列是 格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。
explain select temp.* from (select * from t_bill union all select * FROM t_bill) temp;

type列
表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
性能排序:system > const > eq_ref > ref > range > index > ALL 很明显All是最差的 ,查找范围也是全表查询。
一个好的查询,至少要不低于range这个级别的。
Null: 先上代码和结果。
EXPLAIN select min(id) from t_bill

提问:我明明是查询的t_bill表,但是为什么会使用EXPLAIN 关键字却不显示表名呢?
上篇我们谈过索引的数据结构,这里给一些提示:
- 主键是自动生成的索引。
- 主键索引的数据结构。
- sql的调用方式。
通过上面的提示希望读者可以得到答案。如果得到答案欢迎评论到下方,如果没办法回答出来,下周我会把答案补全。
const, system: mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。用于 primary key 或 unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速度比较快。system是const的特例,表里只有一条元组匹配时为system

索引是Unique或者是主键id自动生成的索引。这样如果是查询是 = 一个固定的值的匹配。则会是const、system
EXPLAIN EXTENDED SELECT * FROM t_bill WHERE order_id = '163830086670221312';

那么我们在看看show warnings给出的结果。
show warnings;

maessge:/* select#1 */ select '527' AS `id`,'17' AS `user_id`,NULL AS `account`,'0' AS `platform`,'2088232153826073' AS `auth_id`,'让出自己' AS `nick_name`,'163830086670221312' AS `order_id`,NULL AS `client_order_id`,'0.01' AS `actual_amount`,'0.01' AS `order_price`,'0.00' AS `pump_price`,'' AS `order_remark`,'耐克 女鞋' AS `random_remark`,'2' AS `order_state`,'1' AS `order_type`,'2019-05-30 17:28:58' AS `created_at`,'2019-06-01 15:21:14' AS `updated_at`,'2019-05-30 17:32:58' AS `expire_at`,NULL AS `trade_no`,'FE1B6954806584A44C90A10305FBE4E4' AS `secret_key` from `bill_management`.`t_bill` where ('163830086670221312' = '163830086670221312')
我们很明显就能看出来,他是直接将这个常量数据给打印出来的。
eq_ref: 这种类型是出现在复杂查询中的,primary key 或 unique key 索引的所有部分被连接使用 ,连接查询是属于一对一的连接查询。这样type是eq_ref类型的, 这可能是最好的联接查询类型了。简单的查询是不可能出现eq_ref类型的。
EXPLAIN SELECT c.* , a.* FROM t_commercial_tenant c INNER JOIN t_account a ON c.id = a.merchant_id;

我们对应代码看一下结果。a表对应的是t_account表,c表对应的是t_commercial_tenant表,我们可以看到t_commercial_tenant表的type是eq_ref的,但是t_account表是All,因为连接字段是t_commercial_tenant的主键id,和t_account表的merchant_id,主键id是主键索引的,而merchant_id是没有索引的。所以是全表查询。所以这种type时是必须连接字段是primary key 或 unique key 索引,并且是一对一的关系,这样就是eq_ref了。
ref: 相比eq_ref而言,不使用单一的唯一索引,使用符合索引的前部分前缀索引,索引要和某个值相比较,并且可能会获得多个结果。
- 简单表查询: name 为普通索引(非唯一索引)
EXPLAIN SELECT * FROM film WHERE name = "film1";

- 关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id部分。
EXPLAIN SELECT film_id FROM film LEFT JOIN film_actor on film.id = film_actor.film_id;

这里film_actor的 索引是 film_id和actor_id的联合索引 ,而链表查询只用到了联合查询的部分前缀索引,所以会是ref类型。
range: 使用范围条件查询。例如:in(), between ,> ,<,>=,<=,<>,%kk,%kk%。
EXPLAIN SELECT * FROM t_bill WHERE id <> 530;

index: 扫描全表索引,比类型ALL快一些。区别:index扫描的是内存中的索引,而ALL是扫描的磁盘的全表。
EXPLAIN SELECT `name`, secret_key, uri FROM t_commercial_tenant;

那么这个是走的什么样的索引呢 ??
这里在select后面的字段也是可以走索引的。如果索引是你所查询的字段的话,即便是全表查询,也会走索引,这样就是全表索引查询了。
ALL: 这是全表查询,是查询中最慢的一中类型。意味着需要在磁盘中,需要从头到尾的查询。这种情况下需要增加索引,如果是全表查询的话,增加索引还是可以提升到index级别的。
EXPLAIN SELECT * FROM t_bill

possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。
key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
例如:t_commercial_tenant表的联合索引 id_name是有 id, name 两个字段组成的的联合索引。
EXPLAIN SELECT * FROM t_commercial_tenant WHERE id = 2
我这里使用了id,id的类型是bigint, 每个长度为8

而我这里key_len = 8那么如果要是使用的id_name索引的话,则是使用的id列的字段。
key_len 计算规则:
-
字符串
char(n):n字节长度 varchar(n):2字节存储字符串长度,如果是utf-8,则长度 3n + 2 -
数值类型
tinyint:1字节 smallint:2字节 int:4字节 bigint:8字节 -
时间类型
date:3字节 timestamp:4字节 datetime:8字节 -
如果字段允许为 NULL,则需要额外1字节记录是否为 NULL。
注意: 一个字段的索引最大长度为768字节,如果长度超过了这个字节,那么mysql将按照这个范围分块,然后按照类似最左前缀原理处理。
ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id)
rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
Extra列
Using index: 查询字段为索引字段,或者使用索引的前导列为查询字段,对于innoDB 来说,如果是辅助索引,性能会提高不少。和where查询语句无关
EXPLAIN SELECT merchant_id,bank_no FROM t_account WHERE merchant_id = 2;

我的索引是merchant_id_bank_no,由merchant_id和bank_no字段作为联合索引。即便我不使用where条件筛选也没关系。
Using where: 使用了where条件,无论加不加索引,都会是这个类型。最低保证不是全表查询。
注意:但是不能是联合索引的部分前导列 的where条件。
EXPLAIN SELECT * FROM t_account WHERE bank_no = 6228481101100634315;

Using where Using index: 这里就不多说了。这个只是Using where 和Using index 的组合体,查询时只要符合Using where 和 Using index的条件即可。但是也有一些区别。
EXPLAIN SELECT merchant_id, bank_no FROM t_account WHERE bank_no = 6228481101100634315;

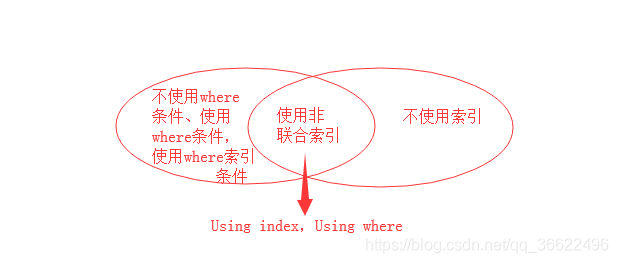
由上图我们可以看出,Using where Using index 出现的条件是查询字段使用联合索引 字段,然后where条件为非联合索引。但是必须使用索引。因为不使用索引优先级是Using index,所以属于Using index 类型。
NULL: 查询字段非联合索引的字段,where条件筛选为联合索引的前导列,意味着使用了索引,但是没有完全使用,是通过索引然后通过“回表” 获取数据字段。对于速度有一定的提升。
EXPLAIN SELECT * FROM t_account WHERE merchant_id = 2

Using index condition: 查询字段不是索引字段。有where查询字段,where查询字段可以是联合查询的所有列的条件筛选。
EXPLAIN SELECT * FROM t_account WHERE merchant_id = 2 AND bank_no = 6228481101100634315;

我的索引merchant_id_bank_no,是由merchant_id 和bank_no 字段组成。
Using temporary: mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
- t_account.balance没有索引,此时创建了张临时表来
EXPLAIN SELECT distinct balance FROM t_account

- t_account.balance建立了balance索引,此时查询时extra是using index,没有用临时表
EXPLAIN SELECT distinct balance FROM t_account

Using filesort: mysql 会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。此时mysql会根据联接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下一般也是要考虑使用索引来优化的。
t_account.balance 会浏览t_account整个表,保存排序关键字balance和对应的id,然后排序balance并检索行记录
EXPLAIN SELECT * FROM t_account ORDER BY balance;


















 2445
2445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









