









 本文详细介绍了如何使用Scrapyd部署爬虫项目,包括安装Scrapyd和scrapyd-client,配置scrapy.cfg,以及通过命令行进行项目上传、启动和管理等关键步骤。
本文详细介绍了如何使用Scrapyd部署爬虫项目,包括安装Scrapyd和scrapyd-client,配置scrapy.cfg,以及通过命令行进行项目上传、启动和管理等关键步骤。
scrapyd部署爬虫项目
功能:它就相当于是一个服务器,用于将自己本地的爬虫代码,打包上传到服务器上,让这个爬虫在服务器上运行,可以实现对爬虫的远程管理。(远程启动爬虫,远程关闭爬虫,远程查看爬虫的一些日志。)
- scrapyd的安装
pip install scrapyd
- scrapyd-client的安装
pip install scrapy-client
注意:请务必保持scrapyd和scrapyd-client的版本号一致,如果最新版本号不一致,请直接指定版本号安装pip install 第三方库名(scrapyd-client)==版本号(1.2.0a1)
3. 上述服务和客户端安装完成之后,打开cmd输入scrapyd
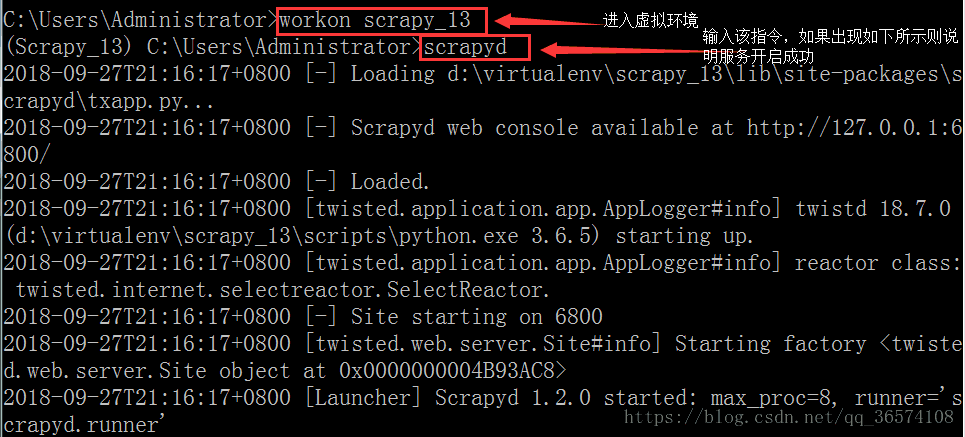
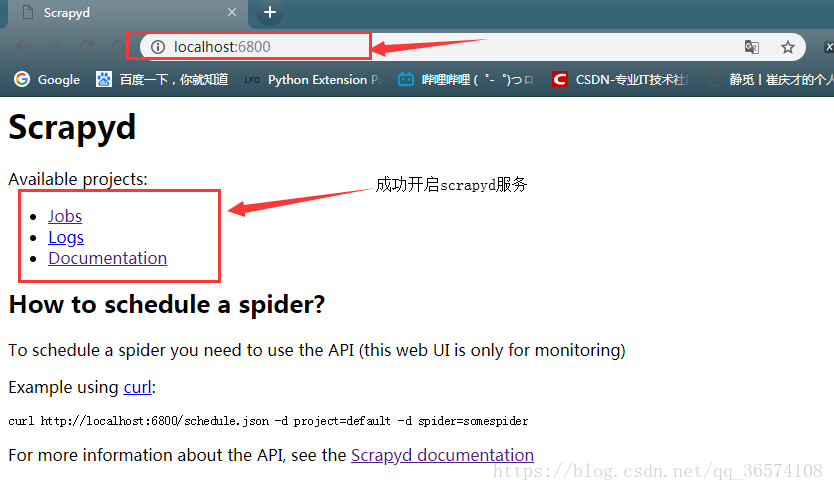
然后打开浏览器访问127.0.0.1:6800,出现图则说明成功开启scrapyd服务
4. 打开已经完成的爬虫项目
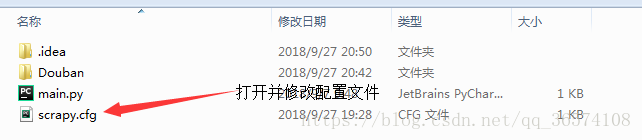
修改scrapy.cfg文件

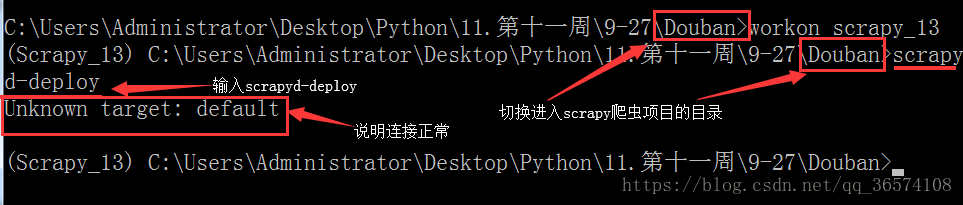
5. 此时打开一个新的cmd命令窗口,使用scrapyd-client客户端连接scrapyd服务
a> 查看连接是否正常,命令:scrapyd-deploy
b>查看当前可用于打包上传的爬虫项目,命令:scrapyd-deploy -l

c>打包并上传项目,命令:scrapyd-deploy douban -p doubanspider
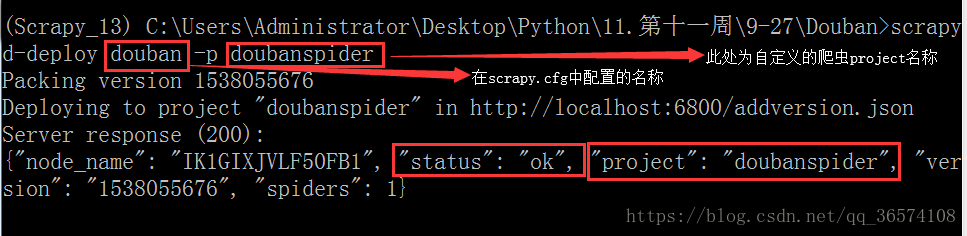
d>上传成功之后,启动爬虫,命令:curl http://localhost:6800/schedule.json -d project=doubanspider -d spider=douban

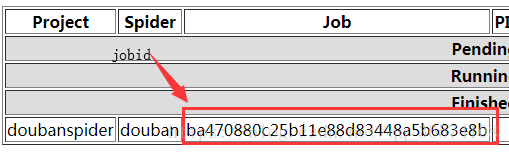
6. 查看信息

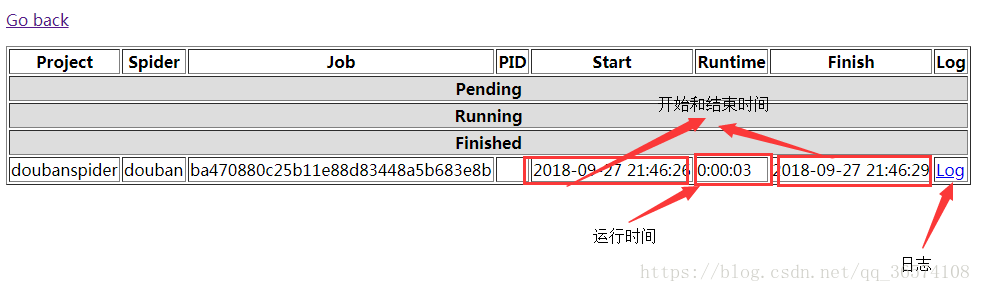
后记:
一、
- 由于部署scrapyd需要curl指令,curl命令是linux中的指令,如果想要在windows中运行,就需要下载并安装curl命令。
百度网盘下载地址:链接: https://pan.baidu.com/s/1N2gMo_NewgX7sIu94pelmg 提取码: suwk
官方下载地址(请下载对应版本):https://curl.haxx.se/download.html - 下载对应文件后解压,进入bin目录下
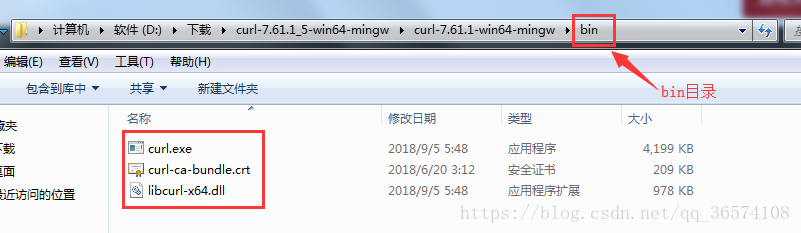
输入cmd命令(切换进入刚刚解压的curl文件路径):当出现下图所示时,说明该版本curl文件可用,然后复制bin路径,并添加到环境变量。例如(D:\software\curl-7.61.1_5-win64-mingw\curl-7.61.1-win64-mingw\bin)

- 添加环境变量,找到Path变量,点击编辑,在末尾处粘贴刚才复制的bin文件夹路径
环境变量之间一定要以英文分号间隔;
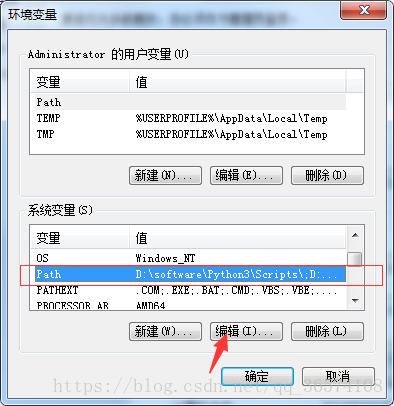
添加完成之后,点击确定,就可以使用curl指令了
二、
关于操作上传爬虫项目的一些常用但是不必须的指令(以下命令均在cmd中使用) - 查看已经上传至scrapyd服务的项目,命令:curl http://localhost:6800/listprojects.json
curl http://localhost:6800/listprojects.json
- 查看某一个项目中所有爬虫的名称,命令:curl http://localhost:6800/listspiders.json?project=爬虫的项目名称
curl http://localhost:6800/listspiders.json?project=doubanspider
- 删除失效的项目,命令:curl http://localhost:6800/delproject.json -d project=爬虫的项目名称
curl http://localhost:6800/delproject.json -d project=doubanspider
- 取消爬虫任务,命令:curl http://localhost:6800/cancel.json -d project=爬虫的项目名称 -d job=jobid
curl http://localhost:6800/cancel.json -d project=doubanspider -d job=ba470880c25b11e88d83448a5b683e8b

















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









