







 该博客介绍了如何使用Python读取大量单词及其汉译数据,并通过自定义的笛卡尔积算法将数字转换为可能的字母组合,从而找到对应的英文单词。在实现过程中,作者对比了列表和字典两种数据结构的效率,并提供了主函数来接收用户输入并展示找到的单词。整个程序旨在优化数字到单词的查找过程。
该博客介绍了如何使用Python读取大量单词及其汉译数据,并通过自定义的笛卡尔积算法将数字转换为可能的字母组合,从而找到对应的英文单词。在实现过程中,作者对比了列表和字典两种数据结构的效率,并提供了主函数来接收用户输入并展示找到的单词。整个程序旨在优化数字到单词的查找过程。
这里写自定义目录标题
python字典
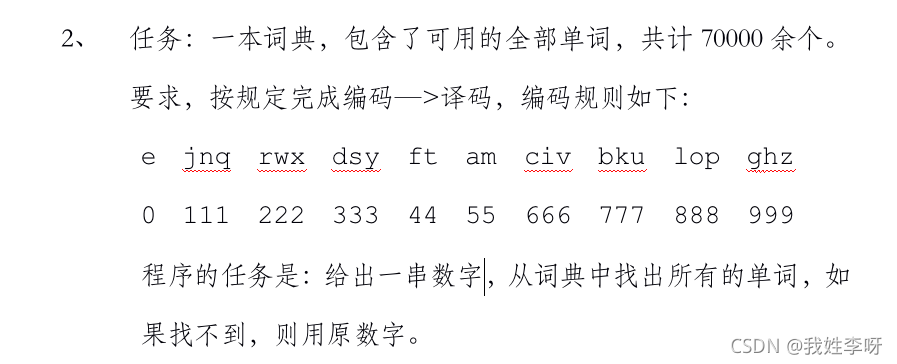
1.准备20W条单词及其对应汉译。Github地址:https://github.com/jiang2032863815/wordDb
2.读取数据
# 文本转换成字典
def getTextList():
txt = open("../data/words-en-zh.txt", "r").read()
list = txt.split()
return list
# 文本转换成字典
def getTextDict():
all_Dict = {}
txt = open("../data/words-en-zh.txt", "r")
for line in txt.readlines():
line = line.strip()
k = line.split(" ")[0]
v = line.split(" ")[1]
all_Dict[k] = v
return all_Dict
# 建立数字对应的字母字典
def Dictionaries():
dict = {
0: ["e"],
1: ["j", "n", "q"],
2: ["r", "w", "x"],
3: ["d", "s", "y"],
4: ["f", "t"],
5: ["a", "m", ""],
6: ["c", "i", "v"],
7: ["b", "k", "u"],
8: ["l", "o", "p"],
9: ["g", "h", "z"]
}
return dict
核心代码 笛卡尔积 负责排列组合
# 笛卡尔积
def cartesian_product(a, b):
l = []
for x in a:
for y in b:
l.append(x + y)
return l
优化后的笛卡尔积
def cartesian_product2(a,b):
return [x+y for x in a for y in b]
主函数
def main(Numbers):
# 字典分别用列表存储和hash结构存储
all_list = getTextList()
all_Dict = getTextDict()
# 规则字典
dict = Dictionaries()
# 获取输入数字长度
length = len(Numbers)
Numbers = eval(Numbers)
i = 0
word_list = [] # 二为列表所有的字母列表 例如有 【【a b c】 【d e】】
words_list = [] #拼凑成的单词列表
Find_list = [] #已经找到的单词列表
Find_list_zh = [] # 已经找到的单词列表中文
while i < length:
i = i + 1
num = Numbers % 10
Numbers = int(Numbers / 10)
word_list.append(dict[num])
#length_list = len(dict[num])
# 二为列表要逆转
word_list.reverse()
if len(word_list)==1:
c = cartesian_product(word_list[0], word_list[0])
else:
c = cartesian_product(word_list[0], word_list[1])
for index in c:
words_list.append(index[0] + index[1])
# 输入的数字位数大于2
i = 1
while i < len(word_list) - 1:
i = i + 1
c = cartesian_product(words_list, word_list[i])
words_list.clear()
words_list = c
for word in words_list:
#切换hash结构查找
#if word in all_Dict:
if word in all_list:
Find_list.append(word)
poi = all_list.index(word)
Find_list_zh.append(all_list[poi+1])
return Find_list,Find_list_zh
调用函数
if __name__ == '__main__':
print("请输入合法数字")
while True:
Numbers = input()
if Numbers.isdigit():
start = time.time()#程序开始时间
Find_list,Find_list_zh = main(Numbers)
if len(Find_list)==0:
print(Numbers)
else:
for en,zh in zip(Find_list,Find_list_zh):
print(en+":"+zh)
# print(Find_list)
# print(Find_list_zh)
end = time.time()
print("程序执行时间:" + str(end - start))
break
else:
print("输入的不是纯数字,请重新输入!")
我认为核心代码是 笛卡尔积。python有笛卡尔积函数itertools.product(a, b),但是老师规定要自己写算法不可调用已有的函数,其实就是嵌套一个for循环即可。
完成字母拼接的单词后 去字典里边进行比较,如果是合法单词 append列表中,
字典有两种数据结构 一种是 python的字典类型 一种是列表类型,hash结构的字典运算速度比列表的快很多很多,速度相差N倍。。。。。


over!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









