







 本文详细介绍了Spark SQL的使用,包括初始化SparkContext、创建DataFrame、使用Case Class、选择、过滤、分组等操作,以及与RDD、JSON文档、HiveContext和Parquet文件的交互。内容涵盖SQLContext的初始化、DataFrame的创建与操作、Hive表的管理和查询,展示了Spark SQL在数据处理中的强大功能。
本文详细介绍了Spark SQL的使用,包括初始化SparkContext、创建DataFrame、使用Case Class、选择、过滤、分组等操作,以及与RDD、JSON文档、HiveContext和Parquet文件的交互。内容涵盖SQLContext的初始化、DataFrame的创建与操作、Hive表的管理和查询,展示了Spark SQL在数据处理中的强大功能。
目录
SQLContext
SQLContext是一个类,用于初始化Spark SQL的功能。Spark SQL提供对读取和写入自动捕获原始数据模式的镶木地板文件的支持。
1.初始化SparkContext命令
进入spark bin目录中,输入:spark-shell,SparkContext对象在spark-shell启动时用namesc初始化(默认)。
D:\spark-2.4.3-bin-hadoop2.7\bin> spark-shell显示:
如上所示,出现scala,表示成功进入scala。
2.创建SQLContext命令:
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)显示:

(1)Spark中使用toDF函数创建DataFrame
//命令生成SQLContext,scmeans是SparkContext对象.
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
//用于将RDD隐式转换为DataFrame的所有SQL函数
scala> import sqlcontext.implicits._
scala> val df = Seq(
(1, "First datetime", java.sql.Date.valueOf("2019-08-01")),
(2, "Last datatime", java.sql.Date.valueOf("2019-08-30"))
).toDF("index", "string_column", "date_column")
//查看数据
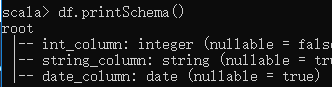
scala> df.show
//查看DataFrame的Structure(Schema)
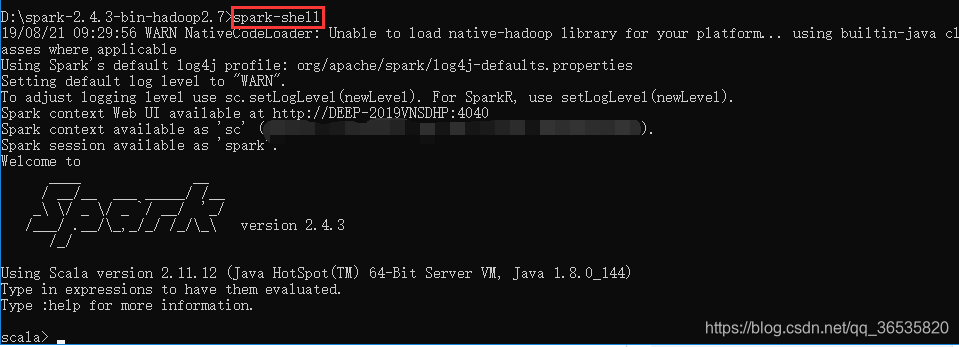
scala> df.printSchema()显示:
![]()

Spark读取本地TXT文件创建DataFrame
通过使用以下命令从名为ceshi.txt的文本文件读取数据来创建RDD DataFrame。
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
scala> import sqlcontext.implicits._
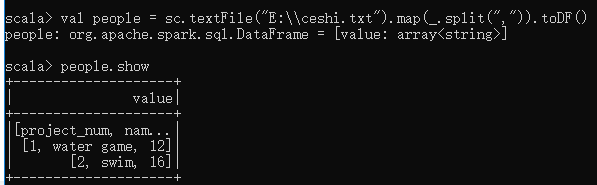
scala> val people = sc.textFile("E:\\ceshi.txt").map(_.split(",")).toDF()
scala> people.show注:.map(_.split(“,”)):将文本记录分割成字段。
toDF()方法:用于将具有模式的案例类对象转换为DataFrame。
显示:
(2)创建Case Class
必须使用案例类定义记录数据的模式。 以下命令用于根据给定数据(id,name,num)声明Case Class。
scala> case class  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1852
1852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









