






前言
春节期间deepseek大火,到现在为止一个多月的时间各家都开始疯狂卷AI,对于程序员来说(或者说对于所有打工人来说)蹭上这股热潮、利用AI来辅助自己工作增加工作效率就成了必要的技能了,接下来分享几个最近一段时间用AI的例子
AI例子
下面的所有例子的代码都是由AI直接生成的且经过测试可以使用的
直接写代码
敏感信息脱敏
API返回的敏感信息(如手机号、身份证等)需要脱敏可谓是常规需求了,直接用AI生成的代码如下(spring boot框架,用的是注解的方式)
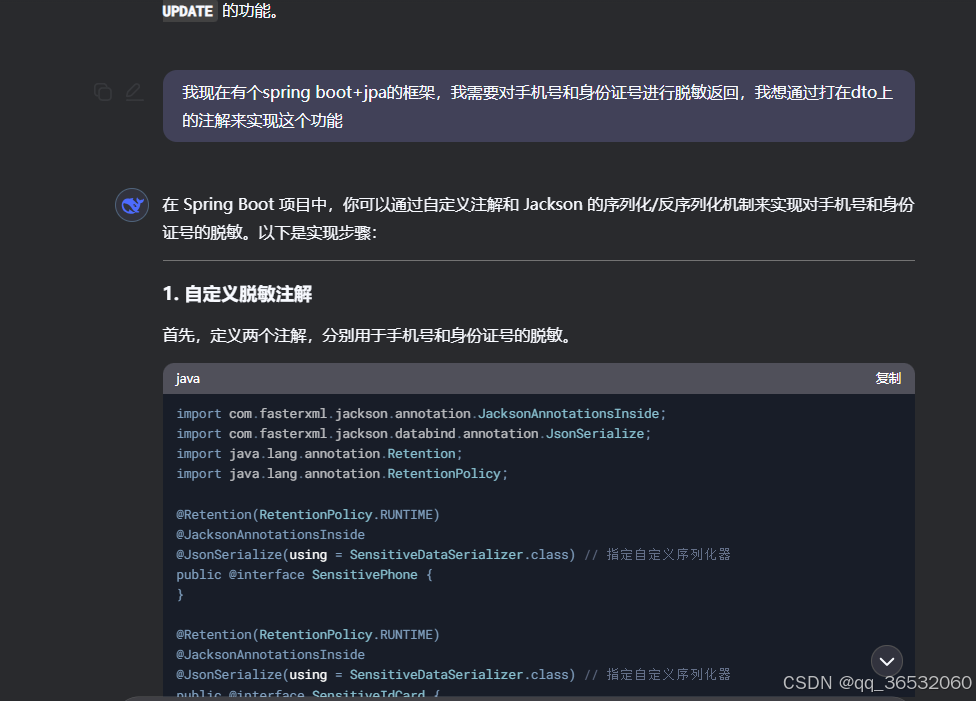
import com.fasterxml.jackson.core.JsonGenerator;
import com.fasterxml.jackson.databind.JsonSerializer;
import com.fasterxml.jackson.databind.SerializerProvider;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import java.io.IOException;
public class IdCardSerializer extends JsonSerializer<String> {
@Override
public void serialize(String value, JsonGenerator gen, SerializerProvider serializers) throws IOException {
if (value != null && value.length() == 18) {
// 身份证号脱敏:保留前3位和后4位,中间用*代替
String maskedIdCard = value.substring(0, 3) + "*************" + value.substring(16);
gen.writeString(maskedIdCard);
} else {
gen.writeString(value);
}
}
}
import com.fasterxml.jackson.core.JsonGenerator;
import com.fasterxml.jackson.databind.JsonSerializer;
import com.fasterxml.jackson.databind.SerializerProvider;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import java.io.IOException;
public class MobileSerializer extends JsonSerializer<String> {
@Override
public void serialize(String value, JsonGenerator gen, SerializerProvider serializers) throws IOException {
if (value != null && value.length() == 11) {
// 手机号脱敏:保留前3位和后4位,中间用*代替
String maskedMobile = value.substring(0, 3) + "****" + value.substring(7);
gen.writeString(maskedMobile);
} else {
gen.writeString(value);
}
}
}
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import lombok.Data;
@Data
public class UserLoginDto {
@JsonSerialize(using = MobileSerializer.class)
private String phone;
}
import com.fasterxml.jackson.annotation.JsonFormat;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import lombok.experimental.SuperBuilder;
@SuperBuilder
@Data
public class StudentDto {
@Schema(description = "身份证号")
@JsonSerialize(using = IdCardSerializer.class)
private String idCard;
}
敏感信息加密
同样,对于敏感信息很多要求数据库存储的时候加密存储,同样在AOP层实现
EncryptedApiUtils是之前实现的加密解密类
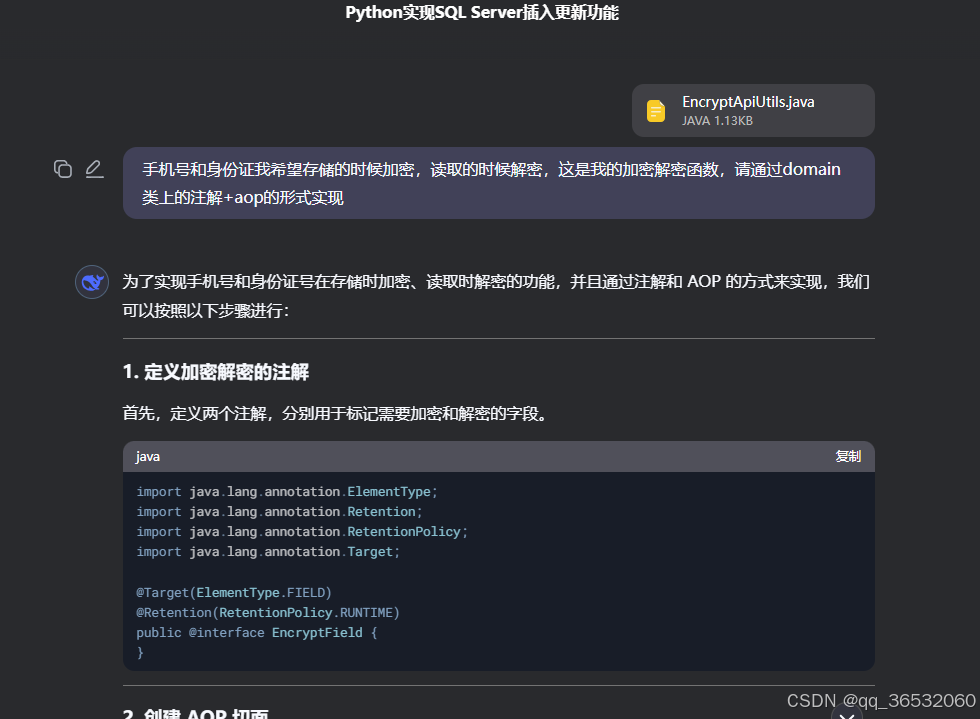
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.persistence.PostLoad;
import javax.persistence.PrePersist;
@Component
public class StudentEntityListener {
@Autowired
private EncryptApiUtils encryptApiUtils;
@PrePersist
public void encryptFields(Student student) {
if (StringUtils.isNotEmpty(student.getIdCard())) {
student.setIdCard(encryptApiUtils.encrypt(student.getIdCard()));
}
}
@PostLoad
public void decryptFields(Student student) {
if (StringUtils.isNotEmpty(student.getIdCard())) {
student.setIdCard(encryptApiUtils.decrypt(student.getIdCard()));
}
}
}
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.persistence.PostLoad;
import javax.persistence.PrePersist;
@Component
public class UserEntityListener {
@Autowired
private EncryptApiUtils encryptApiUtils;
@PrePersist
public void encryptFields(User user) {
if (StringUtils.isNotEmpty(user.getPhone())) {
user.setPhone(encryptApiUtils.encrypt(user.getPhone()));
}
}
@PostLoad
public void decryptFields(User user) {
if (StringUtils.isNotEmpty(user.getPhone())) {
user.setPhone(encryptApiUtils.decrypt(user.getPhone()));
}
}
@NoArgsConstructor
@SuperBuilder
@Getter
@Setter
@Entity
@EntityListeners(StudentEntityListener.class)
@Table
public class Student extends AbstractModel{
}
@SuperBuilder
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Setter
@DynamicUpdate
@EntityListeners(UserEntityListener.class)
@Entity
@Table(name = "\"user\"",schema = "SUOS", indexes = {
// @Index(name = "idx_email", columnList = "email"),
// @Index(name = "idx_phone", columnList = "phone"),
// @Index(name = "idx_username", columnList = "username")
})
public class User {
}
sqlserver upsert语句
有个项目需要用到sqlserver,之前一直用的是mysql,很多语句会有一些区别,重新学习成本又太高,直接借助ai写代码
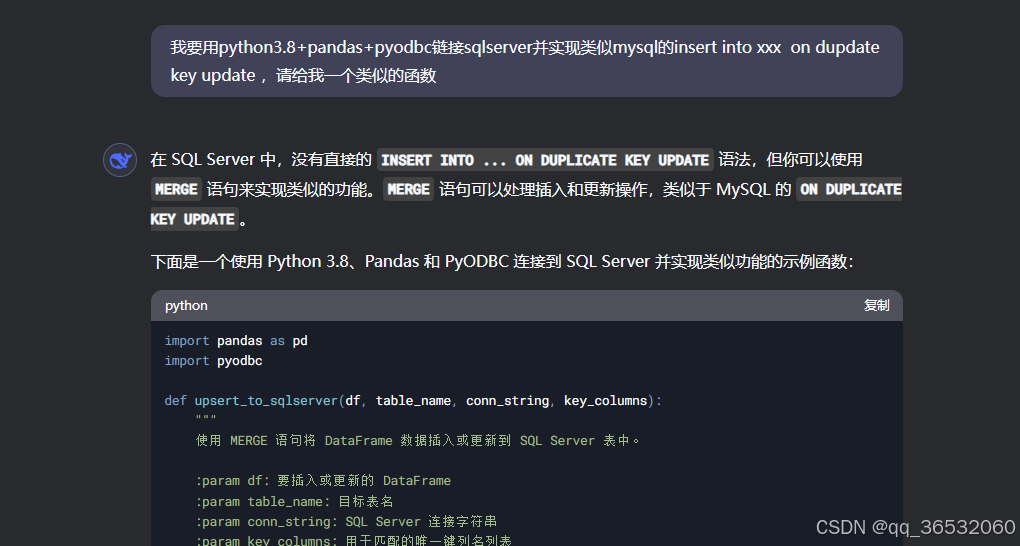
import pyodbc
import pandas as pd
def upsert_to_sqlserver(df: pd.DataFrame, connection: pyodbc.Connection, table_name: str, primary_keys: list):
"""
将 Pandas DataFrame 写入 SQL Server 表,实现类似 MySQL 的 INSERT ... ON DUPLICATE KEY UPDATE 功能。
使用 SQL Server 的 MERGE 语句实现。
参数:
df (pd.DataFrame): 要写入的数据。
connection (pyodbc.Connection): PyODBC 连接对象。
table_name (str): 目标表名。
primary_keys (list): 表的主键字段名列表。
"""
# 检查 DataFrame 是否为空
if df.empty:
print("DataFrame is empty. No data to insert or update.")
return
# 获取表的列名
columns = df.columns.tolist()
non_primary_columns = [col for col in columns if col not in primary_keys]
# 构建 MERGE 语句
merge_sql = f"""
MERGE INTO {table_name} AS target
USING (VALUES ({', '.join(['?' for _ in range(len(columns))])}))
AS source ({', '.join(columns)})
ON {' AND '.join([f'target.{pk} = source.{pk}' for pk in primary_keys])}
WHEN MATCHED THEN
UPDATE SET {', '.join([f'target.{col} = source.{col}' for col in non_primary_columns])}
WHEN NOT MATCHED THEN
INSERT ({', '.join(columns)})
VALUES ({', '.join([f'source.{col}' for col in columns])});
"""
# 将 DataFrame 转换为列表形式
data = [tuple(row) for row in df.values]
# 执行 MERGE 语句
cursor = connection.cursor()
cursor.fast_executemany = True # 提高性能
cursor.executemany(merge_sql, data)
connection.commit()
print(f"Data upserted successfully into {table_name}.")
def save_dataframe_to_sqlserver(df: pd.DataFrame, connection: pyodbc.Connection, table_name: str, schema: str = "dbo"):
"""
将 Pandas DataFrame 的数据批量插入到 SQL Server 数据库表中。
自动处理不规范的列名(如包含空格或特殊字符)。
参数:
df (pd.DataFrame): 要保存的数据。
connection (pyodbc.Connection): PyODBC 连接对象。
table_name (str): 目标表名。
schema (str): 数据库的 schema,默认为 "dbo"。
"""
# 检查 DataFrame 是否为空
if df.empty:
print("DataFrame is empty. No data to insert.")
return
# 获取表的列名,并处理不规范的列名
columns = df.columns.tolist()
safe_columns = [f"[{col}]" for col in columns] # 使用方括号包裹列名
# 构建 INSERT 语句
insert_sql = f"""
INSERT INTO {schema}.{table_name} ({', '.join(safe_columns)})
VALUES ({', '.join(['?' for _ in columns])})
"""
# 将 DataFrame 转换为列表形式
data = [tuple(row) for row in df.values]
# 执行批量插入
cursor = connection.cursor()
cursor.fast_executemany = True # 提高性能
cursor.executemany(insert_sql, data)
connection.commit()
print(f"Data successfully inserted into {schema}.{table_name}.")
这上面分别是insert语句和upsert语句的实现
辅助纯工作量类型工作
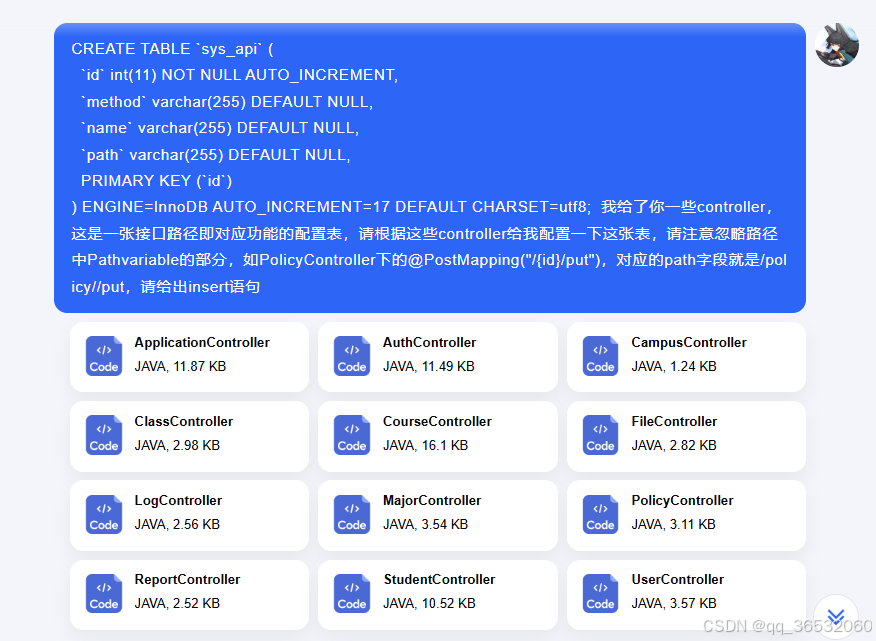
根据controller生成api信息
用户行为分析属于是常用的功能,而通常接口保存的日志只有接口路径,所以需要手动配置一张配置表来记录接口url和实际接口名称之间的映射关系,而这张配置表的配置完全可以通过AI来进行
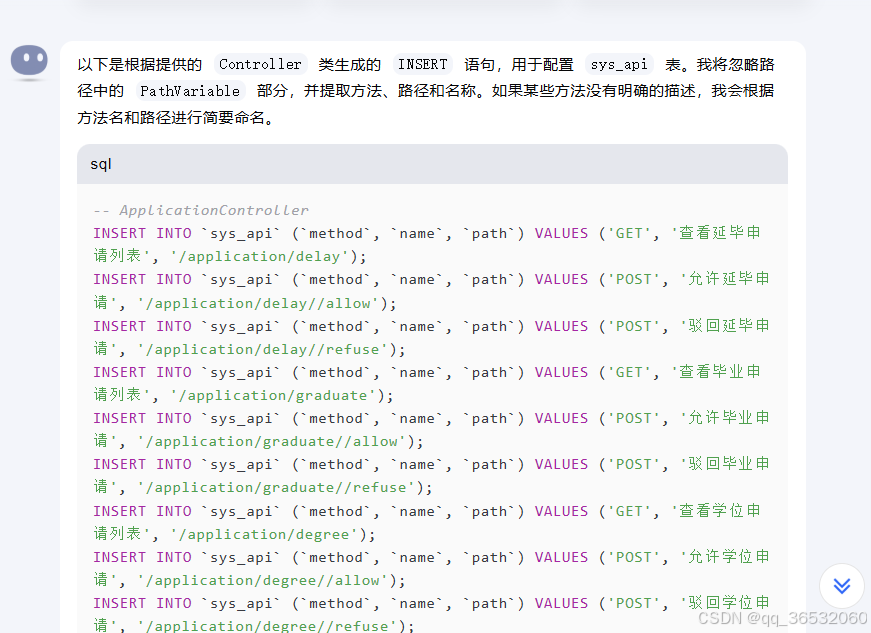
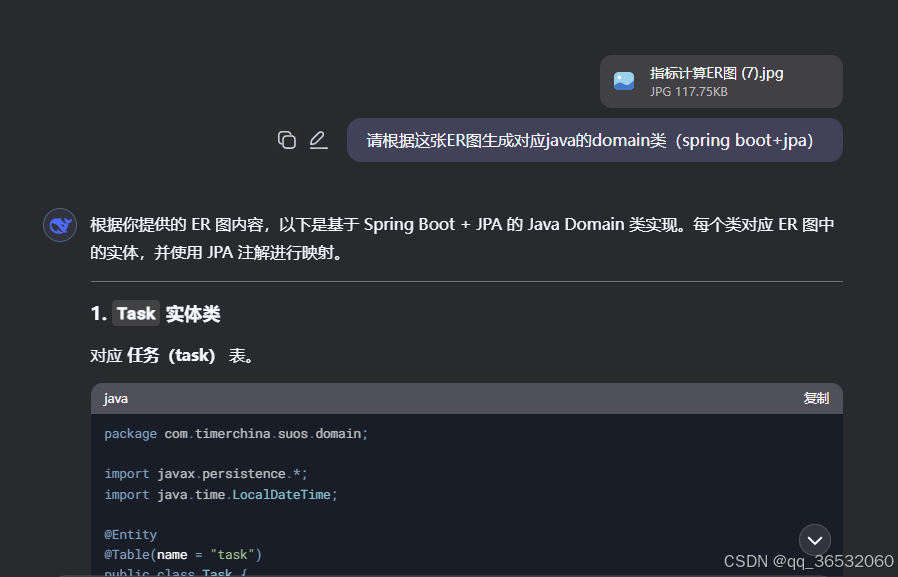
根据er图生成JAVA类
通常来说设计阶段设计的数据结构都是ER图的形式,而将ER图转成java代码里的domain类也是纯堆工作量的事情,也可以通过AI解决
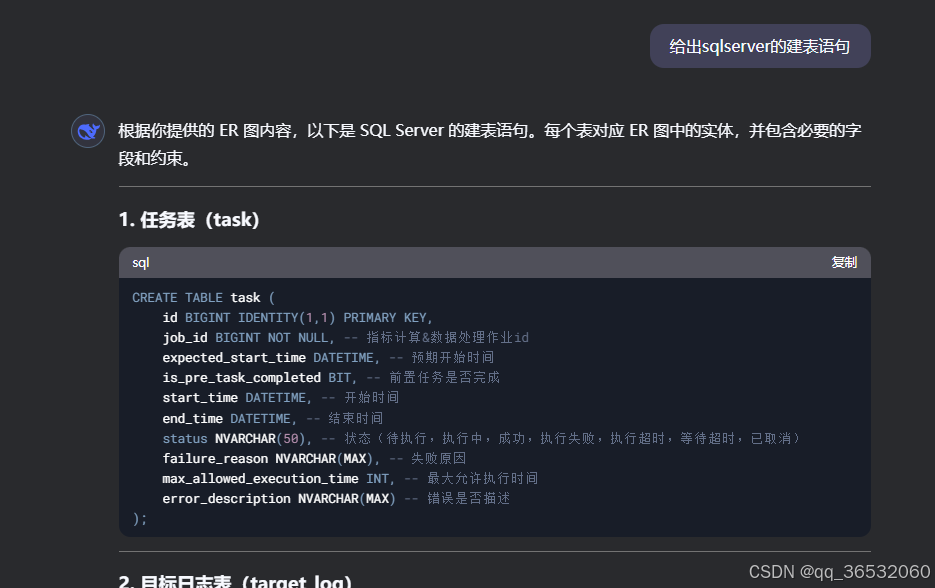
根据er图转sql建表语句
同样的也可以根据er图直接生成create table语句


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









