







 本文深入探讨了循环神经网络(RNN)的反向传播算法,修正了花书《深度学习》中关于梯度计算的错误,并详细推导了RNN模型中各个参数的梯度计算公式。
本文深入探讨了循环神经网络(RNN)的反向传播算法,修正了花书《深度学习》中关于梯度计算的错误,并详细推导了RNN模型中各个参数的梯度计算公式。
最近在阅读花书《深度学习》10.2循环神经网络,对该节公式(10.21)有所疑惑,主要是发现该公式的梯度表示维度计算有问题,且与(10.22)~(10.28)有矛盾,因此本文基于刘建平老师原文原文链接:循环神经网络(RNN)模型与前向反向传播算法,添加了部分基础知识和更细节的公式推导,探究问题所在。感谢刘老师!!!刘建平老师博客地址
1 预备数学
1.1 tanh与导数
tanh函数是一种激活函数,也称双曲正切函数,取值范围为[-1,1],计算公式如下。
f
(
z
)
=
tanh
(
z
)
=
e
z
−
e
−
z
e
z
+
e
−
z
f(z) = \tanh (z) = \frac{{{e^z} - {e^{ - z}}}}{{{e^z} + {e^{ - z}}}}
f(z)=tanh(z)=ez+e−zez−e−z
其中z是标量,根据复合函数求导,其导数为:
f
′
(
z
)
=
d
e
z
−
e
−
z
e
z
+
e
−
z
d
z
=
(
e
z
+
e
−
z
)
(
e
z
+
e
−
z
)
−
(
e
z
−
e
−
z
)
(
e
z
−
e
−
z
)
(
e
z
+
e
−
z
)
2
=
1
−
(
f
(
z
)
)
2
\begin{aligned} f^{\prime}(z) &=\frac{d \frac{e^{z}-e^{-z}}{e^{z}+e^{-z}}}{d z}=\frac{\left(e^{z}+e^{-z}\right)\left(e^{z}+e^{-z}\right)-\left(e^{z}-e^{-z}\right)\left(e^{z}-e^{-z}\right)}{\left(e^{z}+e^{-z}\right)^{2}} \\ &=1-(f(z))^{2} \end{aligned}
f′(z)=dzdez+e−zez−e−z=(ez+e−z)2(ez+e−z)(ez+e−z)−(ez−e−z)(ez−e−z)=1−(f(z))2
若z是d维向量,则导数为对角矩阵(diag不加转置的原因是diag是对角,加不加都一样)
f
′
(
z
)
=
∂
f
(
z
)
∂
z
=
d
i
a
g
(
1
−
(
f
(
z
)
)
2
)
=
∂
d
i
a
g
(
1
−
(
f
(
z
)
)
2
)
z
∂
z
      
z
∈
R
d
      
f
′
(
z
)
∈
R
d
×
d
f'({\bf{z}}) = \frac{{\partial f({\bf{z}})}}{{\partial {\bf{z}}}} = diag(1 - {(f({\bf{z}}))^2}) = \frac{{\partial diag(1 - {{(f({\bf{z}}))}^2}){\bf{z}}}}{{\partial {\bf{z}}}}\;\;\;{\bf{z}} \in {R^d}\;\;\;f'({\bf{z}}) \in {R^{d \times d}}
f′(z)=∂z∂f(z)=diag(1−(f(z))2)=∂z∂diag(1−(f(z))2)zz∈Rdf′(z)∈Rd×d
1.2 softmax
在分类任务中,通常用交叉熵(Cross Entropy)衡量预测分布与真实分布的相近程度,其公式为
C
E
(
y
,
y
^
)
=
−
∑
y
i
log
y
^
i
CE({\bf{y}},{\bf{\hat y}}) = - \sum {{y_i}\log {{\hat y}_i}}
CE(y,y^)=−∑yilogy^i
其中y是真实分布,one-hot编码,y_hat是预测分布,经由softmax产生且有
y ^ = softmax ( θ ) ∂ C E ∂ θ = y ^ − y \begin{aligned} \hat{\mathbf{y}} &=\operatorname{softmax}(\boldsymbol{\theta}) \\ \frac{\partial C E}{\partial \boldsymbol{\theta}} &=\hat{\mathbf{y}}-\mathbf{y} \end{aligned} y^∂θ∂CE=softmax(θ)=y^−y
2 RNN前向传播
2.1 RNN结构

上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。
1)
x
(
t
)
{x^{(t)}}
x(t)代表在序列索引号t时训练样本的输入。同样的,
x
(
t
−
1
)
{x^{(t-1)}}
x(t−1)和
x
(
t
+
1
)
{x^{(t+1)}}
x(t+1)代表在序列索引号t−1和t+1时训练样本的输入.
2)
h
(
t
)
{h^{(t)}}
h(t)代表在序列索引号t时模型的隐藏状态。
h
(
t
)
{h^{(t)}}
h(t)由
x
(
t
)
{x^{(t)}}
x(t)和
h
(
t
−
1
)
{h^{(t-1)}}
h(t−1)共同决定。
3)
o
(
t
)
{o^{(t)}}
o(t)代表在序列索引号t时模型的输出。
o
(
t
)
{o^{(t)}}
o(t)只由模型当前的隐藏状态
h
(
t
)
{h^{(t)}}
h(t)决定。
4)
L
(
t
)
{L^{(t)}}
L(t)代表在序列索引号t时模型的损失函数。
5)
y
(
t
)
{y^{(t)}}
y(t)代表在序列索引号t时训练样本序列的真实输出。
6)
U
U
U,
W
W
W,
V
V
V这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。 也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。
2.1 RNN数学描述
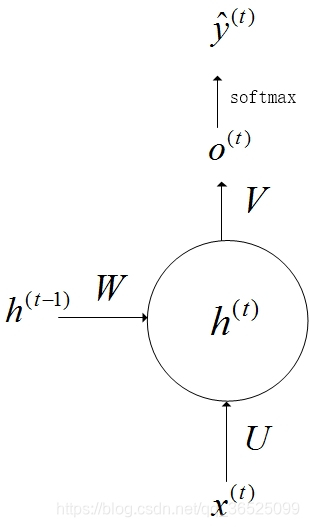
根据上图所示t时刻的隐藏状态
h
(
t
)
h^{(t)}
h(t)由t-1时刻的隐藏状态
h
(
t
−
1
)
h^{(t-1)}
h(t−1)和t时刻的输入
x
(
t
)
x^{(t)}
x(t)决定
h
(
t
)
=
σ
(
z
(
t
)
)
=
σ
(
U
x
(
t
)
+
W
h
(
t
−
1
)
+
b
)
{h^{(t)}} = \sigma ({z^{(t)}}) = \sigma (U{x^{(t)}} + W{h^{(t - 1)}} + b)
h(t)=σ(z(t))=σ(Ux(t)+Wh(t−1)+b)
其中
σ
\sigma
σ为激活函数,通常为tanh,t时刻的输出
o
(
t
)
o^{(t)}
o(t)和预测
y
^
(
t
)
{\hat y^{(t)}}
y^(t)为
o ( t ) = V h ( t ) + c y ^ ( t ) = softmax ( o ( t ) ) \begin{array}{l}{o^{(t)}=V h^{(t)}+c} \\ {\hat{y}^{(t)}=\operatorname{softmax}\left(o^{(t)}\right)}\end{array} o(t)=Vh(t)+cy^(t)=softmax(o(t))
3 RNN反向传播
有了RNN前向传播算法的基础,就容易推导出RNN反向传播算法的流程了。RNN反向传播算法的思路和DNN是一样的,即通过梯度下降法一轮轮的迭代,得到合适的RNN模型参数U,W,V,b,c。由于我们是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through time)。当然这里的BPTT和DNN也有很大的不同点,即这里所有的U,W,V,b,c在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
为了简化描述,这里的损失函数我们为交叉熵损失函数,输出的激活函数为softmax函数,隐藏层的激活函数为tanh函数。
对于RNN,由于我们在序列的每个位置都有损失函数,因此最终的损失L为:
L
=
∑
t
=
1
T
L
(
t
)
L = \sum\limits_{t = 1}^T {{L^{(t)}}}
L=t=1∑TL(t)
其中
L
(
t
)
L^{(t)}
L(t)为t时刻的预测值与真实值的交叉熵,即
L
(
t
)
=
C
E
(
y
^
(
t
)
,
y
(
t
)
)
{L^{(t)}} = CE({\hat y^{(t)}},{y^{(t)}})
L(t)=CE(y^(t),y(t))
根据1.2有
∂
L
(
t
)
∂
o
(
t
)
=
y
^
(
t
)
−
y
(
t
)
\frac{{\partial {L^{(t)}}}}{{\partial {o^{(t)}}}} = {\hat y^{(t)}} - {y^{(t)}}
∂o(t)∂L(t)=y^(t)−y(t)
OK,那我们就来计算各个参数的梯度了,首先对
c
c
c和
V
V
V求导
∂
L
∂
c
=
∑
t
=
1
T
∂
L
(
t
)
∂
c
=
∑
t
=
1
T
∂
L
(
t
)
∂
o
(
t
)
∂
o
(
t
)
∂
c
=
∑
t
=
1
T
y
^
(
t
)
−
y
(
t
)
\frac{{\partial L}}{{\partial c}} = \sum\limits_{t = 1}^T {\frac{{\partial {L^{(t)}}}}{{\partial c}}} = \sum\limits_{t = 1}^T {\frac{{\partial {L^{(t)}}}}{{\partial {o^{(t)}}}}} \frac{{\partial {o^{(t)}}}}{{\partial c}} = \sum\limits_{t = 1}^T {{{\hat y}^{(t)}}} - {y^{(t)}}
∂c∂L=t=1∑T∂c∂L(t)=t=1∑T∂o(t)∂L(t)∂c∂o(t)=t=1∑Ty^(t)−y(t)
∂
L
∂
V
=
∑
t
=
1
T
∂
L
(
t
)
∂
V
=
∑
t
=
1
T
∂
L
(
t
)
∂
o
(
t
)
∂
o
(
t
)
∂
V
=
∑
t
=
1
T
(
y
^
(
t
)
−
y
(
t
)
)
∂
V
h
(
t
)
∂
V
=
∑
t
=
1
T
∂
V
h
(
t
)
(
y
^
(
t
)
−
y
(
t
)
)
T
∂
V
=
∑
t
=
1
T
(
y
^
(
t
)
−
y
(
t
)
)
(
h
(
t
)
)
T
\begin{aligned} \frac{\partial L}{\partial V} &=\sum_{t=1}^{T} \frac{\partial L^{(t)}}{\partial V}=\sum_{t=1}^{T} \frac{\partial L^{(t)}}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial V} \\ &=\sum_{t=1}^{T}\left(\hat{y}^{(t)}-y^{(t)}\right) \frac{\partial V h^{(t)}}{\partial V}=\sum_{t=1}^{T} \frac{\partial V h^{(t)}\left(\hat{y}^{(t)}-y^{(t)}\right)^{\mathrm{T}}}{\partial V} \\ &=\sum_{t=1}^{T}\left(\hat{y}^{(t)}-y^{(t)}\right)\left(h^{(t)}\right)^{\mathrm{T}} \end{aligned}
∂V∂L=t=1∑T∂V∂L(t)=t=1∑T∂o(t)∂L(t)∂V∂o(t)=t=1∑T(y^(t)−y(t))∂V∂Vh(t)=t=1∑T∂V∂Vh(t)(y^(t)−y(t))T=t=1∑T(y^(t)−y(t))(h(t))T
但是W,U,b的梯度计算就比较的复杂了。从RNN的模型可以看出,在反向传播时,在在某一序列位置t的梯度损失由当前位置的输出对应的梯度损失和序列索引位置t+1时的梯度损失两部分共同决定。对于W在某一序列位置t的梯度损失需要反向传播一步步的计算。我们定义序列索引t位置的隐藏状态的梯度为:
δ
(
t
)
=
∂
L
∂
h
(
t
)
{\delta ^{(t)}} = \frac{{\partial L}}{{\partial {h^{(t)}}}}
δ(t)=∂h(t)∂L
这样我们可以像DNN一样从
δ
(
t
+
1
)
{\delta ^{(t + 1)}}
δ(t+1)递推
δ
(
t
)
{\delta ^{(t)}}
δ(t),因此
δ
(
t
)
{\delta ^{(t)}}
δ(t)计算公式如下:
δ
(
t
)
=
∂
L
∂
h
(
t
+
1
)
∂
h
(
t
+
1
)
∂
h
(
t
)
+
∂
L
∂
o
(
t
)
∂
o
(
t
)
∂
h
(
t
)
{\delta ^{(t)}} = \frac{{\partial L}}{{\partial {h^{(t + 1)}}}}\frac{{\partial {h^{(t + 1)}}}}{{\partial {h^{(t)}}}} + \frac{{\partial L}}{{\partial {o^{(t)}}}}\frac{{\partial {o^{(t)}}}}{{\partial {h^{(t)}}}}
δ(t)=∂h(t+1)∂L∂h(t)∂h(t+1)+∂o(t)∂L∂h(t)∂o(t)
前一部分为下一时刻t+1带来的梯度,后一部分为t时刻的输出带来的梯度,展开可得:
δ
(
t
)
=
δ
(
t
+
1
)
∂
h
(
t
+
1
)
∂
z
(
t
+
1
)
∂
z
(
t
+
1
)
∂
h
(
t
)
+
(
y
^
(
t
)
−
y
(
t
)
)
∂
V
h
(
t
)
∂
h
(
t
)
=
δ
(
t
+
1
)
∂
diag
(
1
−
(
h
(
t
+
1
)
)
2
)
z
(
t
+
1
)
z
(
t
+
1
)
∂
W
h
(
t
)
∂
h
(
t
)
+
(
y
^
(
t
)
−
y
(
t
)
)
∂
V
h
(
t
)
∂
h
(
t
)
=
∂
(
δ
(
t
+
1
)
)
T
diag
(
1
−
(
h
(
t
+
1
)
)
2
)
z
(
t
+
1
)
∂
h
(
t
)
+
V
T
(
y
^
(
t
)
−
y
(
t
)
)
=
diag
(
1
−
(
h
(
t
+
1
)
)
2
)
δ
(
t
+
1
)
∂
W
h
(
t
)
∂
h
(
t
)
+
V
T
(
y
^
(
t
)
−
y
(
t
)
)
=
W
T
diag
(
1
−
(
h
(
t
+
1
)
)
2
)
δ
(
t
+
1
)
+
V
T
(
y
^
(
t
)
−
y
(
t
)
)
\begin{aligned} \delta^{(t)} &=\delta^{(t+1)} \frac{\partial h^{(t+1)}}{\partial z^{(t+1)}} \frac{\partial z^{(t+1)}}{\partial h^{(t)}}+\left(\hat{y}^{(t)}-y^{(t)}\right) \frac{\partial V h^{(t)}}{\partial h^{(t)}} \\ &=\delta^{(t+1)} \frac{\partial \operatorname{diag}\left(1-\left(h^{(t+1)}\right)^{2}\right) z^{(t+1)}}{z^{(t+1)}} \frac{\partial W h^{(t)}}{\partial h^{(t)}}+\left(\hat{y}^{(t)}-y^{(t)}\right) \frac{\partial V h^{(t)}}{\partial h^{(t)}} \\ &=\frac{\partial\left(\delta^{(t+1)}\right)^{\mathrm{T}} \operatorname{diag}\left(1-\left(h^{(t+1)}\right)^{2}\right) z^{(t+1)}}{\partial h^{(t)}}+V^{\mathrm{T}}\left(\hat{y}^{(t)}-y^{(t)}\right) \\ &=\operatorname{diag}\left(1-\left(h^{(t+1)}\right)^{2}\right) \delta^{(t+1)} \frac{\partial W h^{(t)}}{\partial h^{(t)}}+V^{\mathrm{T}}\left(\hat{y}^{(t)}-y^{(t)}\right) \\ &=W^{\mathrm{T}} \operatorname{diag}\left(1-\left(h^{(t+1)}\right)^{2}\right) \delta^{(t+1)}+V^{\mathrm{T}}\left(\hat{y}^{(t)}-y^{(t)}\right) \end{aligned}
δ(t)=δ(t+1)∂z(t+1)∂h(t+1)∂h(t)∂z(t+1)+(y^(t)−y(t))∂h(t)∂Vh(t)=δ(t+1)z(t+1)∂diag(1−(h(t+1))2)z(t+1)∂h(t)∂Wh(t)+(y^(t)−y(t))∂h(t)∂Vh(t)=∂h(t)∂(δ(t+1))Tdiag(1−(h(t+1))2)z(t+1)+VT(y^(t)−y(t))=diag(1−(h(t+1))2)δ(t+1)∂h(t)∂Wh(t)+VT(y^(t)−y(t))=WTdiag(1−(h(t+1))2)δ(t+1)+VT(y^(t)−y(t))
与花书公式(10.21)不同,区别在于
δ
(
t
+
1
)
{\delta^{(t+1)}}
δ(t+1)与diag的位置顺序,但根据维度计算后发现,花书应该有误,上述公式正确。
因为T是序列最后一个时刻,所以
δ
(
T
)
{\delta ^{(T)}}
δ(T)的梯度只来自于T时刻的输出,即
δ
(
T
)
=
∂
L
∂
o
(
T
)
∂
o
(
T
)
∂
h
(
T
)
=
(
y
^
(
T
)
−
y
(
T
)
)
∂
V
h
(
T
)
∂
h
(
T
)
=
V
T
(
y
^
(
T
)
−
y
(
T
)
)
{\delta ^{(T)}} = \frac{{\partial L}}{{\partial {o^{(T)}}}}\frac{{\partial {o^{(T)}}}}{{\partial {h^{(T)}}}} = ({{\hat y}^{(T)}} - {y^{(T)}})\frac{{\partial V{h^{(T)}}}}{{\partial {h^{(T)}}}} = {V^{\rm{T}}}({{\hat y}^{(T)}} - {y^{(T)}})
δ(T)=∂o(T)∂L∂h(T)∂o(T)=(y^(T)−y(T))∂h(T)∂Vh(T)=VT(y^(T)−y(T))
则对于W,b,U的梯度为:
∂
L
∂
W
=
∑
t
=
1
T
∂
L
∂
h
(
t
)
∂
h
(
t
)
∂
W
=
∑
t
=
1
T
δ
(
t
)
∂
h
(
t
)
∂
z
(
t
)
∂
z
(
t
)
∂
W
=
∑
t
=
1
T
diag
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
∂
W
h
(
t
−
1
)
∂
W
=
∑
t
=
1
T
diag
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
(
h
(
t
−
1
)
)
T
\begin{aligned} \frac{\partial L}{\partial W} &=\sum_{t=1}^{T} \frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial W}=\sum_{t=1}^{T} \delta^{(t)} \frac{\partial h^{(t)}}{\partial z^{(t)}} \frac{\partial z^{(t)}}{\partial W} \\ &=\sum_{t=1}^{T} \operatorname{diag}\left(1-\left(h^{(t)}\right)^{2}\right) \delta^{(t)} \frac{\partial W h^{(t-1)}}{\partial W} \\ &=\sum_{t=1}^{T} \operatorname{diag}\left(1-\left(h^{(t)}\right)^{2}\right) \delta^{(t)}\left(h^{(t-1)}\right)^{\mathrm{T}} \end{aligned}
∂W∂L=t=1∑T∂h(t)∂L∂W∂h(t)=t=1∑Tδ(t)∂z(t)∂h(t)∂W∂z(t)=t=1∑Tdiag(1−(h(t))2)δ(t)∂W∂Wh(t−1)=t=1∑Tdiag(1−(h(t))2)δ(t)(h(t−1))T
∂
L
∂
b
=
∑
t
=
1
T
∂
L
∂
h
(
t
)
∂
h
(
t
)
∂
b
=
∑
t
=
1
T
δ
(
t
)
∂
h
(
t
)
∂
z
(
t
)
∂
z
(
t
)
∂
b
=
∑
t
=
1
T
diag
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
∂
b
∂
b
=
∑
t
=
1
T
diag
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
\begin{aligned} \frac{\partial L}{\partial b} &=\sum_{t=1}^{T} \frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial b}=\sum_{t=1}^{T} \delta^{(t)} \frac{\partial h^{(t)}}{\partial z^{(t)}} \frac{\partial z^{(t)}}{\partial b} \\ &=\sum_{t=1}^{T} \operatorname{diag}\left(1-\left(h^{(t)}\right)^{2}\right) \delta^{(t)} \frac{\partial b}{\partial b} \\ &=\sum_{t=1}^{T} \operatorname{diag}\left(1-\left(h^{(t)}\right)^{2}\right) \delta^{(t)} \end{aligned}
∂b∂L=t=1∑T∂h(t)∂L∂b∂h(t)=t=1∑Tδ(t)∂z(t)∂h(t)∂b∂z(t)=t=1∑Tdiag(1−(h(t))2)δ(t)∂b∂b=t=1∑Tdiag(1−(h(t))2)δ(t)
∂
L
∂
U
=
∑
t
=
1
T
∂
L
∂
h
(
t
)
∂
h
(
t
)
∂
U
=
∑
t
=
1
T
δ
(
t
)
∂
h
(
t
)
∂
z
(
t
)
∂
U
x
(
t
)
∂
U
=
∑
t
=
1
T
diag
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
∂
U
x
(
t
)
∂
U
=
∑
t
=
1
T
diag
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
(
x
(
t
)
)
T
\begin{aligned} \frac{\partial L}{\partial U} &=\sum_{t=1}^{T} \frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial U}=\sum_{t=1}^{T} \delta^{(t)} \frac{\partial h^{(t)}}{\partial z^{(t)}} \frac{\partial U x^{(t)}}{\partial U} \\ &=\sum_{t=1}^{T} \operatorname{diag}\left(1-\left(h^{(t)}\right)^{2}\right) \delta^{(t)} \frac{\partial U x^{(t)}}{\partial U} \\ &=\sum_{t=1}^{T} \operatorname{diag}\left(1-\left(h^{(t)}\right)^{2}\right) \delta^{(t)}\left(x^{(t)}\right)^{\mathrm{T}} \end{aligned}
∂U∂L=t=1∑T∂h(t)∂L∂U∂h(t)=t=1∑Tδ(t)∂z(t)∂h(t)∂U∂Ux(t)=t=1∑Tdiag(1−(h(t))2)δ(t)∂U∂Ux(t)=t=1∑Tdiag(1−(h(t))2)δ(t)(x(t))T


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









